

Базы данных |
БГУИР, ПОИТ |
|
|
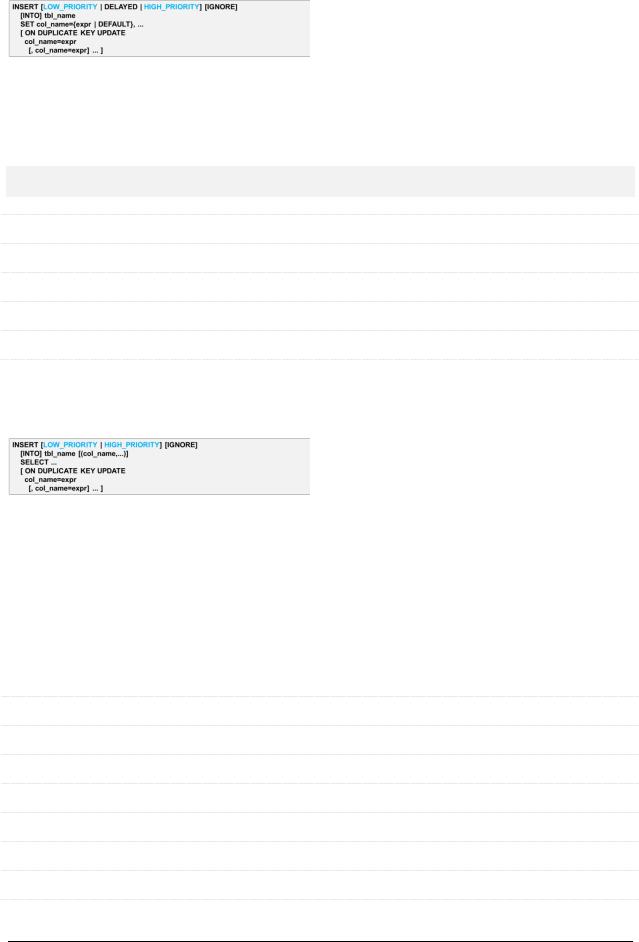
6.7.7. Синтаксис INSERT в стиле UPDATE
Все фрагменты оператора нам уже знакомы. Этот вариант синтаксиса лишь предполагает явное указание пар ПОЛЕ=ЗНАЧЕНИЕ. Совместим ответ на вопрос и пример.
Q: А можно ли тут не указывать значение автоинкрементируемого первичного ключа?
A: Да, например:
INSERT INTO `goods` SET `g_cat`=1, `g_name`='ABC', `g_price`=999, `g_quantity`=1, `g_top`=b'0'
6.7.8. Синтаксис INSERT … SELECT
Здесь тоже всё уже рассмотрено. Единственная особенность такого синтаксиса состоит в том, что источником данных является не набор переданных значений, а результат запроса.
Зачем это нужно?
Варианты использования INSERT … SELECT:
1.Копирование (фрагмента) древовидной структуры.
2.Копирование данных с некоторыми изменениями.
3.Перенос данных из одной БД в другую.
4.Денормализация (в целях кэширования).
5.Агрегация данных.
Стр: 230/248
Базы данных |
БГУИР, ПОИТ |
|
|
Рассмотрим пример агрегации данных.
Допустим, в интернет-магазине ОЧЕНЬ много товаров и категорий товаров. И при этом необходимо постоянно выводить информацию вида: «Товаров: X. Категорий: Y».
Логично будет кэшировать эту информацию в некоторой таблице, которая всё равно читается постоянно в сису служебных целей.
Варианты решения:
1. Очень заманчиво, но не работает (происходит JOIN, который тут не ну-
жен):
INSERT INTO `aggregation` (`ag_categories`, `ag_goods`)
SELECT COUNT(`goods`.`g_id`), COUNT(`categories`.`c_id`)
FROM `goods`, `categories`
2.Использовать хранимые подпрограммы. Но об этом – позже.
3.Использовать серию запросов, например, так:
SELECT COUNT(`goods`.`g_id`) INTO @goods FROM `goods`;
SELECT COUNT(`categories`.`c_id`) INTO @categories FROM `categories`; INSERT INTO `aggregation` (`ag_categories`, `ag_goods`) VALUES (@categories, @goods);
4. Использовать подзапросы:
INSERT INTO `aggregation` (`ag_categories`, `ag_goods`) VALUES ((SELECT COUNT(`categories`.`c_id`) FROM `categories`), (SELECT COUNT(`goods`.`g_id`) FROM `goods`))
Ещё INSERT … SELECT используется для кэширования данных путём денормализации. Например, для каких-то нетривиальных целей нам нужно свести в одну таблицу информацию обо всех комнатах и компьютерах. Сделать это можно так:
INSERT INTO `denormalisation` (`rooms`, `comps`) (SELECT `r_name`, `c_name` FROM `rooms`
LEFT OUTER JOIN `comps` USING(`r_id`)) UNION DISTINCT
(SELECT `r_name`, `c_name` FROM `rooms` RIGHT OUTER JOIN `comps` USING(`r_id`))
Стр: 231/248
Базы данных |
БГУИР, ПОИТ |
|
|
6.7.9. INSERT: важное напоминание, вопросы и ответы
ВАЖНО! При всех операциях, связанных с обновлением или вставкой данных, надо ВНИМАТЕЛЬНО следить за кодировками. В частности, попытка вставить UTF8 данные в поле с кодировкой latin1 с некоторой вероятностью приводит к падению запроса, даже несмотря на использование mysql_real_escape_string().
Q: Есть таблица, на которой построено много индексов. Надо вставить кучу данных. Тормозит. Как сделать, чтобы не тормозило?!
A: Вот так.
1. Отключить индексы (первичные ключи и уникальные индексы не отключаются!):
ALTER TABLE ... DISABLE KEYS
2.Вставить данные.
3.Включить индексы:
ALTER TABLE ... ENABLE KEYS
Q: Как перенести данные из одной базы данных к другой?
A: Нужно иметь доступ к обеим базам, а затем – всё просто:
INSERT INTO `db2`.`tbl1` … SELECT … FROM `db1`.`tbl1`
Q: Нужно ли брать в кавычки в запросах ключевые слова типа NULL, DEFAULT и
т.д.?
A: НЕТ! Иначе СУБД посчитает их текстовыми константами!
Стр: 232/248