

Базы данных |
БГУИР, ПОИТ |
|
|
6.1.15.SELECT: [LIMIT …]
Указание количества (и смещения) рядов выборки, которые нужно вернуть.
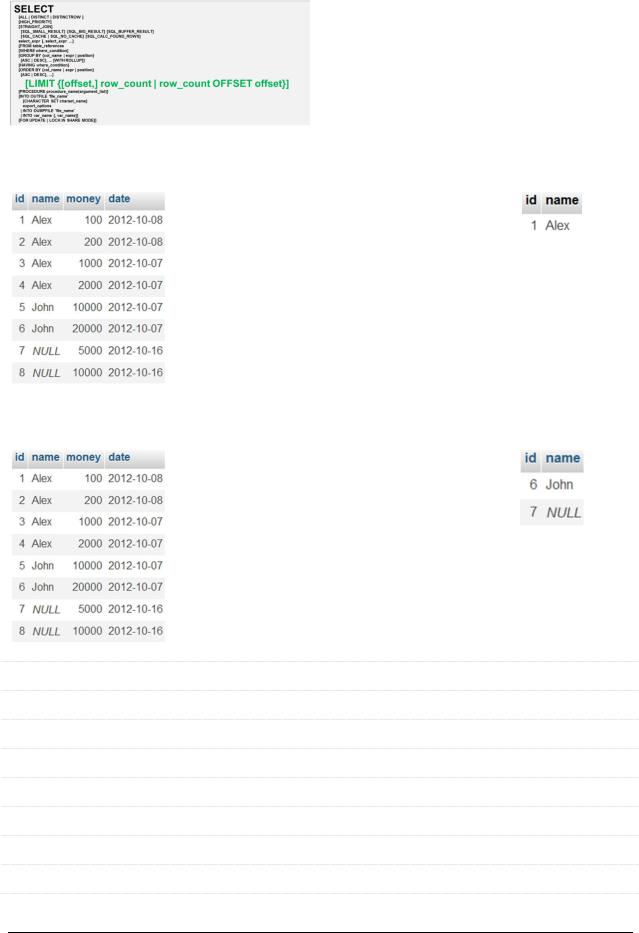
1) Вернуть первые N рядов выборки
Исходная таблица |
|
Запрос |
|
Результат |
|
|
|
|
|
|
|
SELECT `id`, `name` FROM |
|
|
|
|
`payment_with_date` LIMIT 1 |
|
|
|
|
|
|
|
2) Вернуть N рядов выборки, начиная с M-го |
|
|
||
|
|
|
|
|
Исходная таблица |
|
Запросы эквивалентны |
|
Результат |
|
|
|
|
|
|
|
SELECT `id`, `name` FROM |
|
|
|
|
`payment_with_date` LIMIT 5, 2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
SELECT `id`, `name` FROM |
|
|
|
|
`payment_with_date` LIMIT 2 |
|
|
|
|
OFFSET 5 |
|
|
|
|
|
|
|
Стр: 165/248
Базы данных БГУИР, ПОИТ
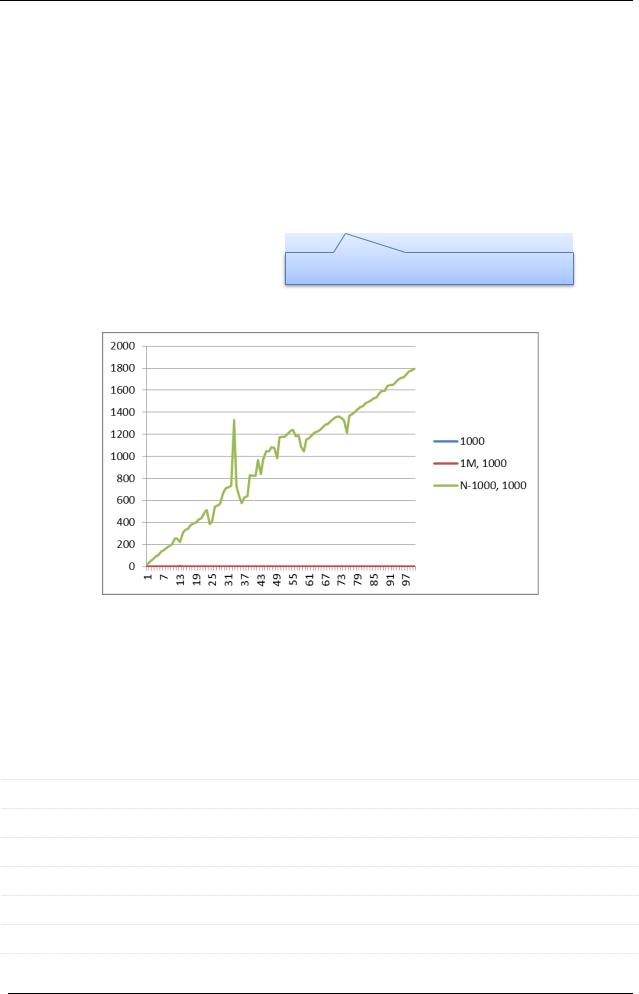
Q: Почему «тормозят» запросы вида “SELECT * FROM `t` LIMIT
10000000000000000, 5” ?
A: Потому, что MySQL выбирает 10000000000000005 рядов, а потом отбра-
сывает первые 10000000000000000.
Проведём исследование. Во всё ту же таблицу, что мы использовали для теста производительности GROUP BY, будем добавлять по записи до миллиарда с шагом в 10 миллионов, и после каждой итерации будем выполнять три запроса.
Q1 |
|
SELECT * FROM `t_small_big` limit 1000 |
|
|
|
|
|
Q2 |
|
SELECT * FROM `t_small_big` limit 1000000, 1000 |
|
|
|
|
|
Q3 |
|
SELECT * FROM `t_small_big` limit {N-1000}, 1000 |
|
|
|
|
|
Количество записей на текущей
Как показало исследование, MySQL действительно испытывает проблемы с производительностью при использовании большого смещения (OFFSET) в конструкции LIMIT.
Решением этой ситуации может стать «разврачивание» выборки (тогда придётся возвращать несколько ПЕРВЫХ, а не ПОСЛЕДНИХ записей) или наложение дополнительных ограничений на выборку, существенно уменьшающих количество возвращённых рядов.
Стр: 166/248
Базы данных |
БГУИР, ПОИТ |
|
|
Q: Говорят, в Oracle можно обращаться к номеру ряда выборки? А в MySQL можно?
A: Пока – нет. Можно «костылями» эмулировать нумерацию рядов, например – так.
SET @rownum=0;
SELECT `name`, @rownum:=@rownum+1 AS `rn` FROM `payment` HAVING (`rn`>3 AND `rn`<6) ORDER BY `rn` ASC;
ВНИМАНИЕ! Это НЕ ДАСТ никакого ускорения. HAVING всё равно срабатывает после того, как MySQL выберет ВСЕ записи (что ещё хуже, чем в LIMIT, т.к. там будет выбрано только {LIMIT + OFFSET} записей).
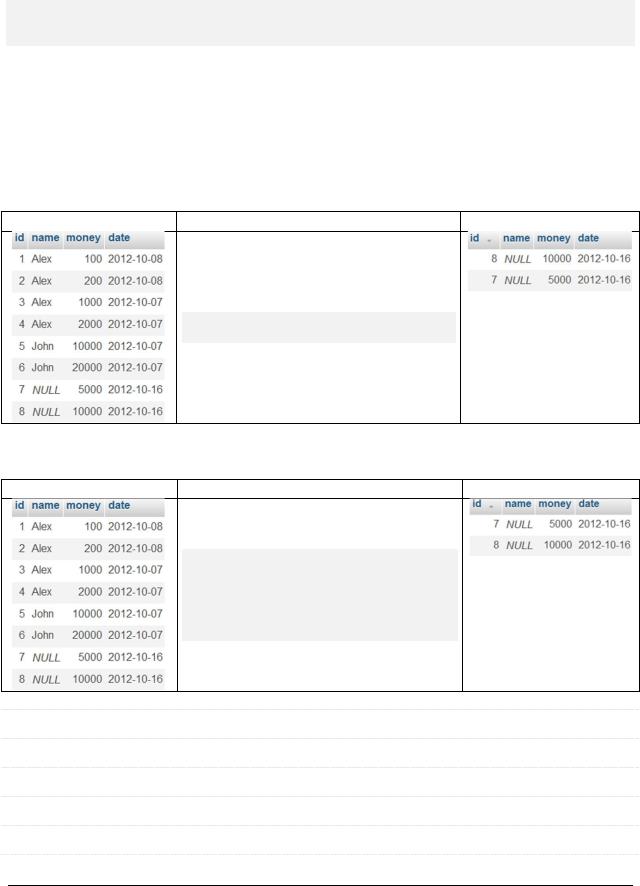
Q: Как взять последние N рядов выборки?
A: Отсортировать в обратном порядке и взять первые N рядов. Например, вот этот запрос вернёт два последних (по `id`) платежа.
Исходная таблица |
Запрос |
Результат |
SELECT * FROM `payment_with_date`
ORDER BY `id` DESC LIMIT 2
А как сделать, чтобы теперь здесь значения `id` шли по возрастанию?
Исходная таблица |
Запрос |
Результат |
SELECT * FROM
(SELECT * FROM `payment_with_date`
ORDER BY `id` DESC LIMIT 2) as `tmp`
ORDER BY `id` ASC
Стр: 167/248
Базы данных |
БГУИР, ПОИТ |
|
|
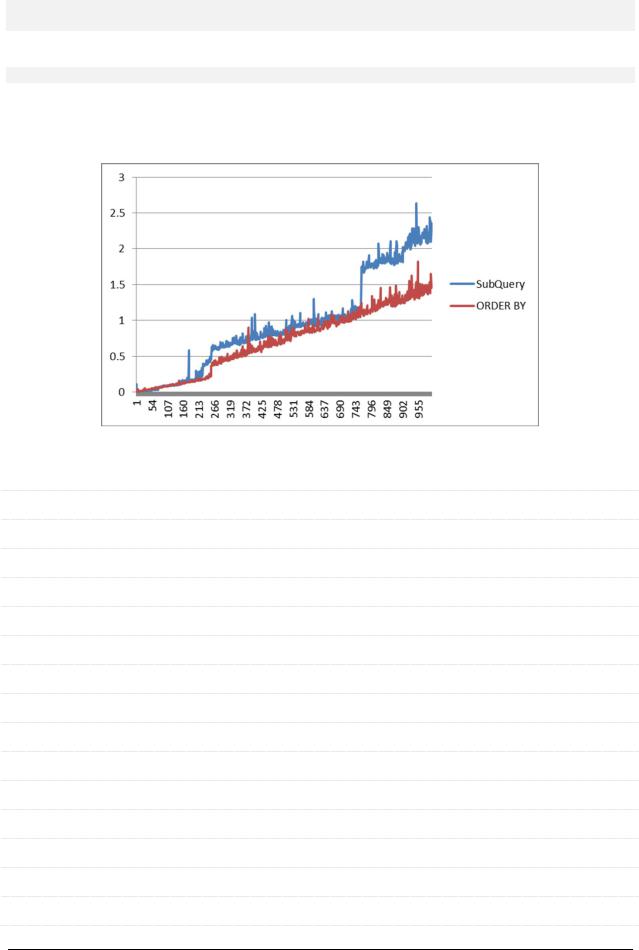
Q: Что быстрее работает?
SELECT * from `t_small_big` where `money` = (SELECT MAX(`money`) from `t_small_big`) LIMIT 1
или
SELECT * from `t_small_big` ORDER BY `money` DESC LIMIT 1
A: Проверим! Да-да, у нас есть всё та же отличная таблица, на которой мы выполняем наши тесты. С шагом в тысячу записей дойдём до миллиона, выполняя эти запросы (см. текст запросов в вопросе).
Итак, вариант с ORDER BY явно быстрее. Также следует помнить, что на скорость выполнения подобных запросов могут сильно повлиять индексы.
Стр: 168/248