

Базы данных |
БГУИР, ПОИТ |
|
|
Тема 6: Язык управления данными в MySQL
6.1. Оператор SELECT, общая структура
6.1.1. Обзор структуры и краткие пояснения
Поскольку общая структура оператора SELECT достаточно обширна, в начале каждого подраздела будет приведена небольшая картинка, на которой будет отмечено, какую часть структуры мы сейчас будем рассматривать.
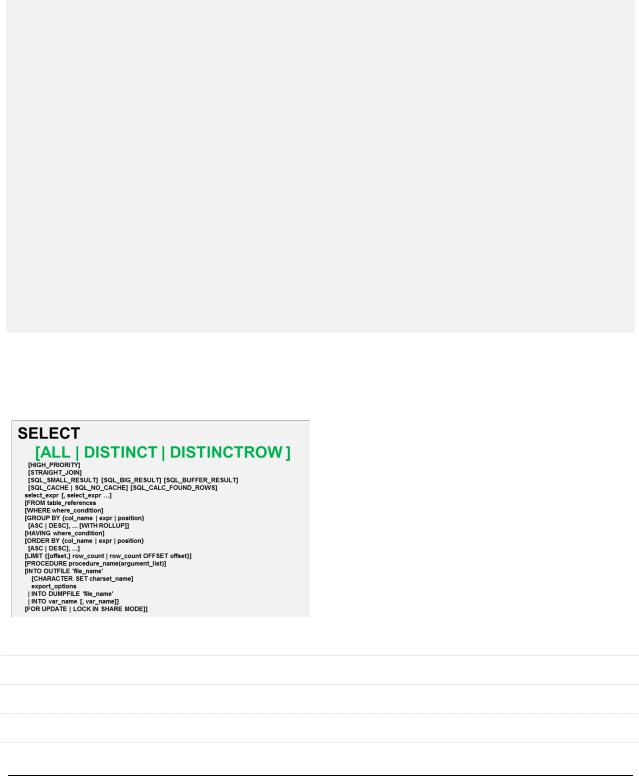
Итак, вся структура оператора SELECT выглядит следующим образом:
SELECT
[ALL | DISTINCT | DISTINCTROW ] [HIGH_PRIORITY] [STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT] [SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr [, select_expr ...] [FROM table_references
[WHERE where_condition]
[GROUP BY {col_name | expr | position} [ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position} [ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}] [PROCEDURE procedure_name(argument_list)]
[INTO OUTFILE 'file_name' [CHARACTER SET charset_name] export_options
| INTO DUMPFILE 'file_name' | INTO var_name [, var_name]]
[FOR UPDATE | LOCK IN SHARE MODE]]
6.1.2. SELECT: [ALL | DISTINCT | DISTINCTROW ]
ALL – вернуть все (в т.ч. повторяющиеся) ряды (значение по умолчанию).
DISTINCT (синоним DISTINCTROW) –
вернуть только уникальные ряды (повторяющиеся игнорировать).
Одновременно указывать ALL и DISTINCT нельзя.
Стр: 135/248

Базы данных БГУИР, ПОИТ
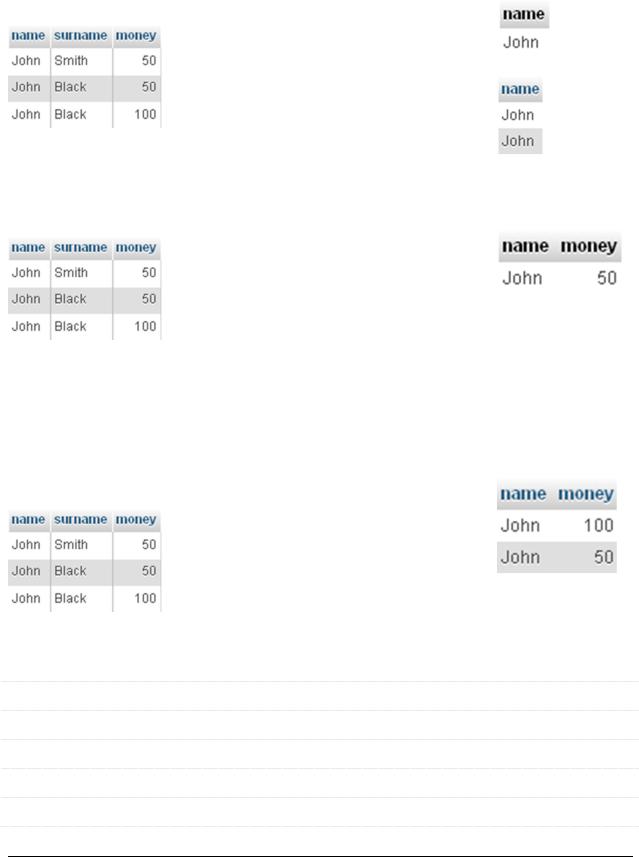
Для такой таблицы следующие запросы вернут одинаковые результаты (все ряды), т.к. дублированных рядов здесь нет.
Исходная таблица |
|
Запрос |
|
|
|
Результат |
||
|
|
|
|
|
|
|
|
|
|
|
SELECT * FROM `tbl` |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
SELECT ALL * FROM `tbl` |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
SELECT DISTINCT * |
FROM `tbl` |
|
|
|
|
|
|
|
|
|
|
|
|||
Но при выборе только первой колонки есть различия: |
|
|
||||||
|
|
|
|
|
||||
Исходная таблица |
|
Запрос |
|
Результат |
||||
|
|
|
|
|
|
|
|
|
|
|
SELECT ALL `name` FROM `tbl` |
|
|
||||
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
SELECT DISTINCT `name` FROM `tbl` |
|
|
||||
|
|
|
|
|||||
Чуть более необычная ситуация: допустим, мы хотим извлечь имена без |
||||||||
повторений, а также фамилии. |
|
|
||||||
|
|
|
|
|
||||
Исходная таблица |
|
Запрос |
|
Результат |
||||
|
|
|
|
|
|
|
|
|
|
|
SELECT DISTINCT(`name`), `surname` |
|
|
|
|||
|
|
FROM `tbl` |
|
|
|
|||
|
|
НЕ РАБОТАЕТ! |
|
|
||||
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
SELECT `name`, `surname` FROM `tbl` |
|
|
|
|||
|
|
GROUP BY `name` HAVING COUNT(*) >=1 |
|
|
|
|||
|
|
|
|
|
|
|
|
|
Стр: 136/248
Базы данных |
БГУИР, ПОИТ |
|
|
Q: Когда ALL (значение по умолчанию) надо указывать явно?
A: В случае с использованием UNION.
Допустим, мы хотим узнать, кто из пользователей внёс меньше всего и больше всего денег. Пусть у нас есть такая таблица.
Исходная таблица |
|
Запрос |
|
Результат |
|
|
(SELECT `name` FROM `t_all_distinct` |
|
|
|
|
ORDER BY `money` ASC LIMIT 1) |
|
|
|
|
UNION |
|
|
|
|
(SELECT `name` FROM `t_all_distinct` |
|
|
|
|
ORDER BY `money` DESC LIMIT 1) |
|
|
|
|
(SELECT `name` FROM `t_all_distinct` |
|
|
|
|
ORDER BY `money` ASC LIMIT 1) |
|
|
|
|
UNION ALL |
|
|
|
|
(SELECT `name` FROM `t_all_distinct` |
|
|
|
|
ORDER BY `money` DESC LIMIT 1) |
|
|
|
|
|
|
|
Можно ли как-то улучшить эти запросы (сделать их проще, быстрее, логичнее)? Как насчёт идеи с MAX() и MIN() вместо ORDER BY?
Исходная таблица |
|
Запрос |
|
Результат |
|
|
|
|
|
|
|
(SELECT `name`, `money` FROM |
|
|
|
|
`t_all_distinct` HAVING |
|
|
|
|
`money`=MAX(`money`)) |
|
|
|
|
UNION ALL |
|
|
|
|
(SELECT `name`, `money` FROM |
|
Странно, да?! |
|
|
`t_all_distinct` HAVING |
|
|
|
|
`money`=MIN(`money`)) |
|
|
|
|
|
|
|
Это – особенность MySQL. Другие СУБД могут вообще не выполнить такой запрос, а MySQL выполняет его с такой ошибкой.
Подробности – здесь: http://stackoverflow.com/questions/8072231/mysql-how- to-select-minium-and-maximum-in-one-union-query
И что делать?! Использовать подзапросы.
Исходная таблица |
|
Запрос |
|
Результат |
||
|
|
(SELECT `name`, `money` FROM |
|
|
||
|
|
`t_all_distinct` WHERE `money`= |
|
|
||
|
|
(SELECT MAX(`money`) FROM |
|
|
|
|
|
|
`t_all_distinct`) |
|
|
|
|
|
|
LIMIT 1) |
|
|
||
|
|
UNION ALL |
|
|
||
|
|
(SELECT `name`, `money` FROM |
|
|
||
|
|
`t_all_distinct` WHERE `money`= |
|
|
||
|
|
(SELECT MIN(`money`) FROM |
|
|
|
|
|
|
`t_all_distinct`) |
|
|
|
|
|
|
LIMIT 1) |
|
|
||
|
|
|
|
|
|
|
Стр: 137/248
Базы данных |
БГУИР, ПОИТ |
|
|
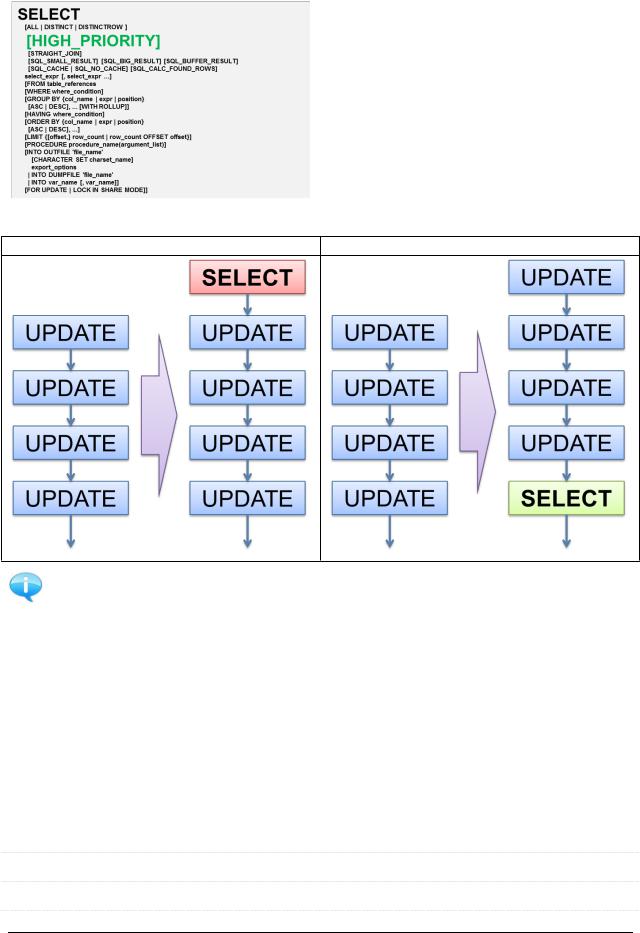
6.1.3. SELECT: [HIGH_PRIORITY]
Использование ключевого слова HIGH_PRIORITY позволяет при работе с таблицами на движках MyISAM, MEMORYи MERGE выставить SELECT-
запросу более высокий приоритет, чем модифицирующим запросам (INSERT,
UPDATE, DELETE, REPLACE).
Как это работает:
SELECT … |
SELECT HIGH_PRIORITY … |
В руководстве сказано…
Использовать HIGH_PRIORITY только с очень быстрыми запросами, которые обязательно надо выполнить прямо сейчас.
Использование HIGH_PRIORITY недопустимо с запросами в контексте UNION.
Использование ключевого слова HIGH_PRIORITY не имеет смысла с движком InnoDB, в котором используются блокировки уровня записи и «сообщения о намерении выставить блокировку»:
•Блокировка S (shared) – чтение записей.
•Блокировка X (exclusive) – модификация записей.
•Блокировка IS (intension shared) – транзакция собирается получить блокировку S.
•Блокировка IX (intension exclusive) – транзакция собирается получить блокировку X.
Стр: 138/248

|
Базы данных |
|
|
|
|
|
БГУИР, ПОИТ |
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Сводная таблица совместимости блокировок InnoDB: |
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
X |
|
|
IX |
|
|
S |
|
|
IS |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
X |
|
|
Conflict |
|
|
Conflict |
|
|
Conflict |
|
|
Conflict |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
IX |
|
|
Conflict |
|
|
Compatible |
|
|
Conflict |
|
|
Compatible |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
S |
|
|
Conflict |
|
|
Conflict |
|
|
Compatible |
|
|
Compatible |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
IS |
|
|
Conflict |
|
|
Compatible |
|
|
Compatible |
|
|
Compatible |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Подробно обо всём этом можно прочитать здесь: http://docs.oracle.com/cd/E17952_01/refman-5.5-en/innodb-lock-modes.html
Стр: 139/248