

15
Peer-to-Peer SIP
Peer-to-peer (P2P) technologies have been becoming an important part of Internet applications. This chapter will introduce P2P technologies and ideas developed from file sharing applications and show how they can be applied to an Internet communications protocol such as SIP. Finally, emerging work in standardizing P2P SIP will be covered including the RELOAD Peer Protocol and Host Identity Protocol (HIP).
15.1 P2P Properties
P2P applications became popular on the Internet with the advent of file sharing applications. Today P2P concepts are used in other applications such as content delivery, distributed computing, application layer multicast, and also Internet communications. The most important properties of P2P systems are:
•Self organizing;
•Decentralized control;
•Direct unmediated communication.
A good overview of P2P architectures and how they relate to common P2P applications such as content delivery networks, distributed computing, and communications is in [1].
P2P systems have these properties to varying degrees. For example, some P2P systems still use a centralized server for authentication; others use centralized servers for NAT and firewall traversal, or use a hierarchy in which peers at the same level communicate but use other protocols (i.e., client-server) between levels in the hierarchy. The next section will discuss some P2P properties of SIP.
331
332 |
SIP: Understanding the Session Initiation Protocol |
15.2 P2P Properties of SIP
SIP [2] by design already has many P2P aspects and properties. For example, the only required element in a SIP network is a UA. UAs can communicate directly with peers: other UAs. In fact, all servers, including proxy, registrar, and redirect servers are optional in the SIP architecture. Compare this to other protocols such as H.323, where a gatekeeper is a required element, or Jabber, where a Jabber server is required—Jabber clients cannot communicate directly with another Jabber client without a server in the middle. Some other fundamental aspects of SIP are also P2P in nature. The dialog identifier—To tag, From tag, and Call-ID—is generated by and under the control of UAs. Servers play no role in its creation. SIP also has P2P call control modes, such as those enabled by the REFER method. Many features which can be implemented by UAs alone using REFER require the use of servers in other telephony architectures. The basic SIP call control model is inherently P2P [3].
However, for all these P2P properties, nearly all SIP deployments use various types of servers. The reason for this is that SIP servers, especially proxy servers, perform very essential roles in discovery, rendezvous, and NAT traversal, as discussed in previous chapters. For example, a SIP UA that uses DHCP and has a dynamic IP address does not have a constant SIP URI that can be used to reach it. While technologies such as dynamic DNS can be used to enable this, sending regular registrations to a SIP proxy is an excellent solution to this. Also, for a SIP UA behind a NAT, the proxy server serves the role of rendezvous server, allowing UAs to discover each other, and exchange candidate addresses for hole punching. Finally, servers must provide fallback for NAT traversal as TURN servers or media relays when hole punching fails.
In addition to proxy servers, many networks also employ B2BUAs as well, which greatly reduce the P2P functionality of SIP. An alternative architecture for SIP, known as simple SIP [4] shows how nearly all features and services can be implemented using P2P approaches and a small set of SIP extensions. This architecture only uses servers for rendezvous functionality. As a result, most SIP exchanges occur over a single SIP hop. Besides simplifying and reducing latency and complexity, this also greatly enhances security. Much of the complexity discussed in the previous chapter on security relate to having proxy servers and B2BUAs in the path between two UAs. For example, if TLS is used in a single hop between UAs, certificates can be used for mutual authentication. In addition, the resulting exchange has end-to-end integrity protection and confidentiality.
If a P2P approach could be developed to replace these discovery, rendezvous, and NAT traversal functions, SIP could be operated in a pure P2P manner, providing all the advantages of P2P systems.
Peer-to-Peer SIP |
333 |
15.3 P2P Overlays
P2P networks form a network known as an overlay, which sits on top of the usual Internet connections. When joining the P2P network, the host, known as a node or a peer, becomes a part of the overlay network. Messages are routed between nodes using overlay routing, which sits on top of normal IP routing. The protocol used to route and map messages across the overlay is known as a peer protocol.
P2P systems need an algorithm for distributing data across the overlay. Often, this is done using a distributed hash table or DHT. For an example of a DHT algorithm used to build a P2P overlay, consider the Chord Protocol [5]. Chord uses a ring architecture, where nodes organize themselves in the overlay using their node number n. If m bits are used for the node number, then there are a maximum of 2^m nodes in the overlay. For Chord, typically m = 160 is used, which can support an enormous number of nodes. A node in the overlay keeps track of the two closest nodes in the overlay: the predecessor node, the closest node with a lower node number; and the successor node, the closest node with a higher node number. Chord provides a distributed database function for nodes in the overlay. Each node stores a small amount of information on behalf of other nodes in the overlay. To locate information in the overlay, the search index for the information (confusingly known as a “key” in Chord even though it has nothing to do with encryption) is hashed to determine the node number of the node responsible for storing this information. For example, to find information about a file or service named “voicemail,” the message digest of the string “voicemail” would be calculated, and the result would point to the node in the overlay where information about this service or file would be located. Chord uses m = 160 and SHA-1 as the hash function, which returns a 160 bit value, so the hash will always return a valid node number in the overlay. Since not every node number in the overlay is occupied by a peer, the actual node responsible will be the successor node to that node location. As a result, a node in the overlay is responsible for storing data about all nodes between its own node number and the node number of the predecessor node. If a new node joins the overlay between the node and its predecessor node, the responsibility will shift, the new node will take over responsibility for the nodes between it and the old predecessor node, and the node will now have the new node as its predecessor.
This distributed database maintains the dynamic mapping between data elements and the Chord node number. The other part of the Chord algorithm is for routing messages between nodes in the overlay. There are two distinct problems:
1.How to find the actual node responsible for a piece of data that is going to be stored or retrieved, given that in most cases there will not be a
334 |
SIP: Understanding the Session Initiation Protocol |
node in the overlay with that exact node ID. As a result, the problem is to find the nearest node.
2.Having found that node ID, the problem becomes how to contact that node (i.e., node number to IP address resolution).
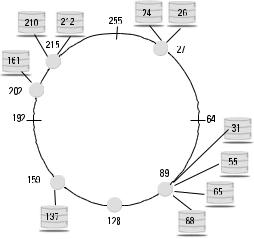
For the first problem, each node in Chord maintains a small routing table known as a finger table. A finger table is only a small subset of the entire routing table for the overlay. Chord does not attempt to build a complete routing table for the overlay since it would likely be too large and too dynamic to be useful. Instead, each node maintains a finger table with m entries. The table starts with the successor node, and the kth element in the finger table is the actual node in the overlay closest to the 2k + n, where n is node’s number. For example, consider the tiny Chord overlay in Figure 15.1 where m = 8. The chord finger table for node 27 is shown in Table 15.1.
In this example, node 27 wants to find the content whose location in the overlay is 210. The node consults the finger table and finds the closest node is node 159. Node 27 then queries node 159 for the location of node 210. Node 159 consults its finger table and returns node 202. Node 27 then contacts node 202 directly who returns node 215. Node 27 then contacts node 215 who responds indicating that it is responsible for node 210. At this point, node 27 can query node 215 for the desired information. Note that this type of routing is known as iterative routing, in that a number of iterations or steps are performed at the source to get to the destination. The source is always in control and can verify routing integrity. An alternative approach is recursive routing where the request goes around the overlay in hops until it gets to the destination. This is
Figure 15.1 Chord routing example.

Peer-to-Peer SIP |
335 |
Table 15.1
Chord Finger Table for Node 27 in Figure 15.1
k |
Node |
Actual |
||
Closest to |
Node |
|||
|
||||
0 |
20 |
+ 27 |
89 |
|
1 |
21 |
+ 27 |
89 |
|
2 |
22 |
+ 27 |
89 |
|
3 |
23 |
+ 27 |
89 |
|
4 |
24 |
+ 27 |
89 |
|
5 |
25 |
+ 27 |
89 |
|
6 |
26 |
+ 27 |
128 |
|
7 |
27 |
+ 27 |
159 |
|
typically faster than iterative routing and involves less processing on the source. The differences are shown in Figure 15.2.
This routing method in Chord can be shown to allow messages to be routed across the overlay in the order of log(m) hops. Since this number only grows logarithmically with the size of the overlay, Chord scales very well. In addition, the queries across the overlay, appearing geometrically as chords on a circle, give Chord its name.
The second aspect of overlay routing is the mapping of Node IDs to IP addresses. Most academic Chord networks assume that all nodes have a public IP address and hence are addressable. They then hash the host IP address (assumed to be unique due to the uniqueness of IP addresses on the Internet) to get the host number. Obviously, for most real Internet applications, the assumption of a public IP address is not realistic, and the IP address cannot be used to generate node IDs. Also, one cannot assume the transitivity of connections across an
Figure 15.2 Iterative verses recursive routing on an overlay.