

4.3 New application development on solidDB UC
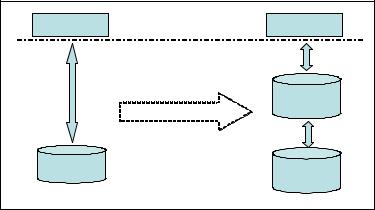
Database application architecture built on cache database or back-end database instead of a single database becomes more complicated. In a high-level conceptual diagram, the legacy back-end database is simply replaced with a cache database that sits between the back-end database and application making the database appear faster from an application perspective. There are no changes in the database interface layer. This concept is illustrated in Figure 4-6.
Application |
Application |
|
Database Interface layer |
|
Cache |
|
Database |
Database |
Backend |
|
Database |
Figure 4-6 Database interface layer
In reality, the conversion from single database system to a cache database system is not quite so straightforward. Consider the following issues, among others, in the application codes:
The application must be aware of the properties of two database connections, one to the cache database and the another to the back-end database. SQL pass-through can mask the two connections to one ODBC or JDBC connection but will require cache awareness in error processing.
Transactions combining data from the cache database and a back-end database are not supported.
Queries combining data from front-end and back-end database are not supported.
A combination of back-end and front-end database is not fully transactional although both individual components are transactional databases.
Support is limited for stored procedures.
Knowing these limitations or conditions of a cached database system enables taking them into account and avoiding them in the design phase.
84 IBM solidDB: Delivering Data with Extreme Speed
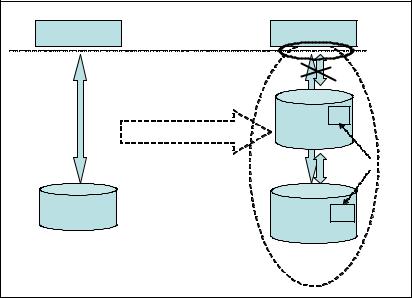
Based on the conditions, the architectural diagram becomes more complicated, as we have illustrated in Figure 4-7
Application |
|
Application |
1 |
|
|
|
|
|
Database Interface layer |
|
2 & 3 |
|
|
|
|
|
|
Cache SPL |
|
|
|
Database |
|
|
|
|
5 |
Database |
|
Backend SPL |
|
|
|
Database |
|
|
|
4 |
|
Figure 4-7 Database interface layer with a cached database
Certain changes are required in the interface between application and cached database as compared to an application with similar logic accessing only a single database.
4.3.1 Awareness of separate database connections
A regular single-database application sees only one database and can handle everything with one database connection. All transactions that have been successfully committed to the single database automatically have the ACID (atomicity, consistency, isolation, durability) properties.
A cached database system has two physical databases, a front end and a back end. Certain performance-critical data has been moved to front-end database; volume data remains in the back-end database. These databases are synchronized by Universal Cache’s Changed Data Capture (CDC) replication but they still act as individual databases.
Chapter 4. Deploying solidDB and Universal Cache 85
The application can access these two databases by two strategies:
Opening and controlling separate connections to the two databases
Using SQL pass-through to route all queries to the back-end database using the front end
Opening separate connections
The application can open two database connections to the two databases and retain and monitor these connections constantly. This strategy provides the application full control on which queries to route to the front end and which to the back end. This is rather laborious but provides flexibility for distribution strategies.
SQL pass-through functionality
SQL pass-through functionality provided by the solidDB Universal Cache product can be used. SQL pass-through assumes that all statements are first run at the front-end database. If any error takes place, the statement is run at the back end. Errors are assumed to be caused by tables not being in place at the front end.
The application sees only one connection but the front-end and back-end databases are still separate and individual databases. The key challenges with SQL pass-through are as follows:
The set of two databases is not transactional. For example, writing something that is routed to the front end is not synchronously written to the back end. If a transaction writes something to a front-end table and in the next statement executes a join that combines data from the same table and another table that only resides in back end, the statement will be routed to back end. The recently written data will not be visible until the asynchronous replication is completed.
Cross-database queries are not supported, so joining data from a front-end table and back-end table is not possible. These queries are always automatically fully executed at the back-end database.
For large result sets, SQL pass-through can present a performance bottleneck. All rows must be first transferred from the back-end database to the front-end database, and then from front end to the application. The front-end database ends up processing all the rows and potentially performing type conversions for all columns. The impact of this challenge is directly proportional to size of result set. For smallish result sets it is not measurable.
SQL pass-through is built to route queries between the front-end and back-end databases on assumption that the routing can be done based on table name. SQL pass-through does not provide a mechanism for situations where a fraction of a table is stored on the front end and the whole table at back end.
86 IBM solidDB: Delivering Data with Extreme Speed
4.3.2 Combining data from separate databases in a transaction
Although both front-end and back-end databases are individually transactional databases, the two transactions taking place in two different databases do not constitute a transaction that would meet the ACID requirements.
Using the default asynchronous replication mechanism does not enable building a transactional combined database, because some compromises are always implicitly included in this architecture.
Creating a transactional combination of two or more databases, using Distributed Transactions, is possible. A Distributed Transaction is a set of database operations where two or more database servers are involved. The database servers provide transactional resources. Additionally, a Transaction Manager is required to create and manage the global transaction that runs on all databases.
4.3.3 Combining data from different databases in a query
Joining data from two or more tables by one query is one of the benefits of relational database and SQL. This is easily possible in the Universal Cache architecture as long as all tables participating the join reside in the same (either front-end or back-end) database. If this is not the case, several ways are available to work around the limitation:
Generally, the easiest way is to run all the joins of this kind in the back end. Typically, all tables would be stored at the back end, but the most recent changes to the tables that reside at the front end also might not have been replicated to the back end yet. If there is no timeliness requirement and if there is no performance benefit visible based on running the query at the front end, this approach is a good one.
Because there is no statement-level joins available between two separate databases, the only way to execute the join between two databases is to define a stored procedure that runs in the front end and executes an application-level join by running queries in the front-end and back-end databases as needed. All join logic will be controlled by the procedure. From the application perspective, the procedure is still called by executing a single SQL statement.
Application-level joins can also be executed outside the database by the application, but they cannot be made to appear as the execution of single statement in any way.
Chapter 4. Deploying solidDB and Universal Cache 87