

3.1 Architecture
The architecture of solidDB Universal Cache is based on three main components: the solidDB in-memory database (the cache database), the relational database server (the back end), and the data synchronization software that copies data to and from the cache and the back end. The replication method is asynchronous, ensuring fast response times.
3.1.1 Architecture and key components
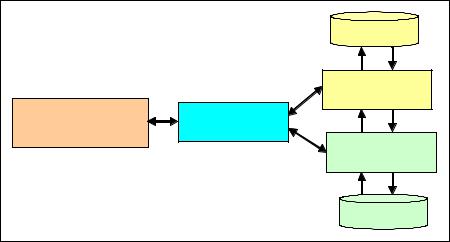
The architecture and key components of a typical configuration of the solidDB Universal Cache is shown in Figure 3-1.
|
solidDB Server |
|
solidDB Replication |
solidDB Universal |
Engine |
Access Server |
|
Cache tooling |
Daemon |
(Management Console) |
RDBMS |
|
|
|
Replication Engine |
|
RDBMS |
Figure 3-1 Sample IBM solidDB deployment
IBM solidDB: cache database
The solidDB server implements the cache database (or front end) in the IBM solidDB Universal Cache solution. The cache database benefits from various solidDB features, such as HotStandby that provides high availability and failover, or shared memory access (SMA) that enables collocating of data with the application.
Relational database server (RDBMS): back end
The RDBMS is a relational, disk-based data server that contain the data to be cached.
40 IBM solidDB: Delivering Data with Extreme Speed
Replication engines
The InfoSphere Change Data Capture (CDC) replication software ensures that as changes are made to the cache database, the back-end database is updated, and vice versa. The replication engines run typically on the same hosts as the data servers.
The replication engines are configured using a graphical user interface (GUI) or command-line based Configuration Tool (dmconfigurets). A set of commands (dm-commands) is available and can be used to control the replication engine instances.
Access Server
InfoSphere CDC Access Server is a process that manages a solidDB Universal Cache deployment. It is typically executed as a daemon.
Configuration tools such as Management Console communicate with the Access Server to allow deployments to be configured.
Access Server controls access to the replication environment; only users who have been granted the relevant rights can modify configurations. However, after the replication environment has been configured, Access Server is not needed for the replication to be operational: only the InfoSphere CDC replication engines need to be running.
Configuration tools
InfoSphere CDC Management Console is a graphical application that allows authorized users to access, configure and monitor their InfoSphere CDC deployments. It does so by communicating with the Access Server.
Similar functionality is available for command-line users. This functionality is realized through the dminstancemanager and dmsubscriptionmanager utilities, which are included the InfoSphere CDC for solidDB package.
3.1.2 Principles of operation
To use solidDB Universal Cache, you must first identify the data you want to cache and configure the environment accordingly. The data can then be loaded from the back-end database to the cache, so that when applications run against the cache database, they can take advantage of high performance and low latency of solidDB. (With the SQL pass-through functionality, some statements can also be passed to the back-end database.) As changes are made to the data, the InfoSphere CDC replication technology synchronizes data between the cache database and the back-end database.
Chapter 3. IBM solidDB Universal Cache details 41
Log-scraping
InfoSphere CDC uses log-scraping technologies, triggers, or both to capture databases changes. The front-end replication engine accesses the solidDB transaction log to capture data changes and transmits these changes to the back-end replication engine, which copies the changes to the back-end database.
Similarly, the back-end replication engine accesses the log (or uses triggers) to capture data changes in the back end and transmits these changes to the front-end replication engine, which copies the changes to the back-end database.
Asynchronous replication
The InfoSphere CDC replication method is asynchronous in nature. This means that as applications write, for example, to the cache database, control is returned to the application as soon as the write completes; the application does not block, waiting for these updates to be successfully applied to the back end.
Updates to the back end are not performed until the following tasks are completed:
1.The transaction has been committed.
2.The entries for the transaction are scraped from the log.
In a solidDB Universal Cache environment, asynchronous replication benefits applications by reducing the round-trip time required to access data. Instead of potentially incurring an expensive network hop and writing to the back-end database, applications can write directly to the solidDB in-memory database.
Asynchronous replication means also that applications cannot assume that the back-end database has been written to at the same time as the front-end, which can have ramifications for error recovery.
Mirroring and refresh
The two manners in which data can be copied between the cache database and the back end are mirroring and refresh.
Mirroring involves actively scanning a source database to see if any changes have been made, then applying these changes to a target database. This step is
accomplished by using the asynchronous replication mechanism. The mirroring process may be thought of as active caching.
Refresh involves taking a snapshot of the source database and writing it directly to the target. Refresh can thus be utilized to initialize or rebuild a database.
42 IBM solidDB: Delivering Data with Extreme Speed
Communication between components
The InfoSphere CDC replication components communicate with each other using TCP/IP. To collocate the data in the cache database with the application, the solidDB server can be configured as a shared memory access (SMA) server, so that both the application and the InfoSphere CDC for solidDB replication engine connect to solidDB using SMA. TCP/IP protocol can be used with solidDB too.
The inter-component communication in the solidDB Universal Cache environment is shown in Figure 3-2.
|
|
|
|
solidDB Server |
|
|
|
|
TCP/IP or SMA |
|
|
|
|
solidDB Replication |
solidDB Universal |
|
Access Server |
|
Engine |
TCP/IP |
TCP/IP |
TCP/IP |
||
Cache tooling |
|
Daemon |
|
|
(Management Console) |
|
|
RDBMS |
|
|
|
|
||
|
|
|
|
|
|
|
|
|
Replication Engine |
|
|
|
|
TCP/IP |
|
|
|
|
RDBMS |
Figure 3-2 solidDB Universal Cache inter-component communication
The Access Server is configured as a TCP/IP server and it listens on one or more ports. On UNIX systems, it may be deployed as a daemon service (inetd). All communication between the Access Server and tooling also uses TCP/IP.
Each replication engine instance must use a unique port number to connect to the Access Server; the port number is defined when creating the InfoSphere CDC instances. Figure 3-3 on page 44 shows the configuration dialog for the InfoSphere CDC for solidDB replication engine.
Chapter 3. IBM solidDB Universal Cache details 43
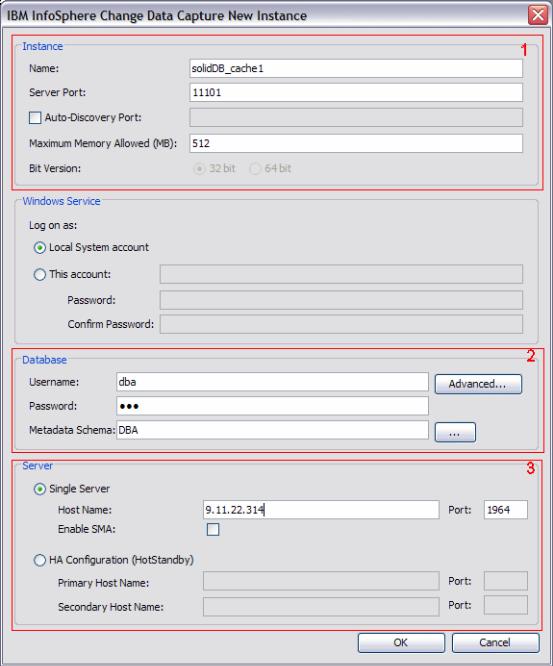
Figure 3-3 InfoSphere CDC for solidDB configuration
44 IBM solidDB: Delivering Data with Extreme Speed