

изучить ее базовые термины, другими словами, он должен провести анализ предметной области. На основании знаний методов и инструментов Data Mining специалист по добыче данных предлагает вариант решения проблемы.
Второй точкой соприкосновения указанных выше специалистов является интерпретация результатов, полученных в результате Data Mining.
Взаимодействие специалиста по добыче данных и администратора баз данных осуществляется на этапах анализа требований к данным и сбора данных. Непосредственно подготовка данных для Data Mining может осуществляться специалистом по добыче данных самостоятельно либо во взаимодействии с администратором баз данных.
Взаимодействие трех специалистов осуществляется на завершающих этапах Data Mining при проверке работоспособности системы, например, при сравнении прогнозных результатов с реальными. При необходимости процесс Data Mining возвращается на один из предыдущих этапов.
От того, насколько консолидированы будут действия специалистов из разных областей, зависит длительность проекта и качество полученных результатов.
Если в проекте Data Mining присутствует роль руководителя, на него возлагается координация и контроль работ, проводимых описанными выше специалистами.
CRISP-DM методология
Мы рассмотрели процесс Data Mining с двух сторон: как последовательность этапов и как последовательность работ, выполняемых исполнителями ролей Data Mining.
Существует еще одна сторона - это стандарты, описывающие методологию Data Mining. Последние рассматривают организацию процесса Data Mining и разработку Data Miningсистем.
CRISP-DM [100] (The Cross Industrie Standard Process for Data Mining - Стандартный межотраслевой процесс Data Mining) является наиболее популярной и распространенной методологией. Членами консорциума CRISP-DM являются NCR, SPSS и DаimlerChrysler.
В соответствии со стандартом CRISP, Data Mining является непрерывным процессом со многими циклами и обратными связями.
Data Mining по стандарту CRISP-DM включает следующие фазы:
1.Осмысление бизнеса (Business understanding).
2.Осмысление данных (Data understanding).
3.Подготовка данных (Data preparation).
4.Моделирование (Modeling).
5.Оценка результатов (Evaluation).
6.Внедрение (Deployment).
Кэтому набору фаз иногда добавляют седьмой шаг - Контроль, он заканчивает круг. Фазы Data Mining по стандарту CRISP-DM изображены на рис. 21.2.
238
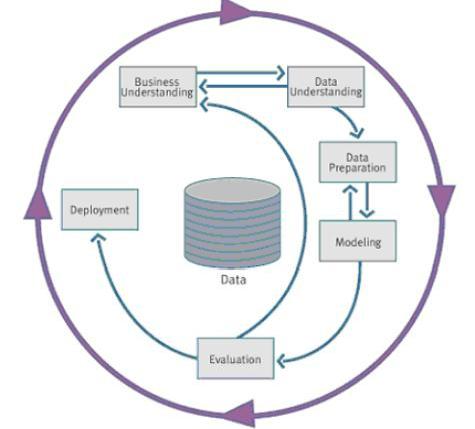
Рис. 21.2. Фазы, рекомендуемые моделью CRISP-DM
При помощи методологии CRISP-DM Data Mining превращается в бизнес-процесс, в ходе которого технология Data Mining фокусируется на решении конкретных проблем бизнеса. Методология CRISP-DM, которая разработана экспертами в индустрии Data Mining, представляет собой пошаговое руководство, где определены задачи и цели для каждого этапа процесса Data Mining.
Методология CRISP-DM описывается в терминах иерархического моделирования процесса [101], который состоит из набора задач, описанных четырьмя уровнями обобщения (от общих к специфическим): фазы, общие задачи, специализированные задачи и запросы.
На верхнем уровне процесс Data Mining организовывается в определенное количество фаз, на втором уровне каждая фаза разделяется на несколько общих задач. Задачи второго уровня называются общими, потому что они являются обозначением (планированием) достаточно широких задач, которые охватывают все возможные Data Mining-ситуации. Третий уровень является уровнем специализации задачи, т.е. тем местом, где действия общих задач переносятся на конкретные специфические ситуации. Четвертый уровень является отчетом по действиям, решениям и результатам фактического использования Data Mining.
CRISP-DM - это не единственный стандарт, описывающий методологию Data Mining. Помимо него, можно применять такие известные методологии, являющиеся мировыми стандартами, как Two Crows, SEMMA, а также методологии организации или свои собственные.
239
SEMMA методология
SEMMA методология реализована в среде SAS Data Mining Solution (SAS) [102]. Ее аббревиатура образована от слов Sample ("Отбор данных", т.е. создание выборки), Explore ("Исследование отношений в данных"), Modify ("Модификация данных"), Model ("Моделирование взаимозависимостей"), Assess ("Оценка полученных моделей и результатов"). Методология разработки проекта Data Mining в соответствии с методологией SEMMA изображена на рис. 21.3.
Рис. 21.3. Методология разработки проекта Data Mining в соответствии с методологией SEMMA
Подход SEMMA подразумевает, что все процессы выполняются в рамках гибкой оболочки, поддерживающей выполнение всех необходимых работ по обработке и анализу данных. Подход SEMMA сочетает структурированность процесса и логическую организацию инструментальных средств, поддерживающих выполнение каждого из шагов. Благодаря диаграммам процессов обработки данных, подход SEMMA упрощает применение методов статистического исследования и визуализации, позволяет выбирать и преобразовывать наиболее значимые переменные, создавать модели с этими переменными, чтобы предсказать результаты, подтвердить точность модели и подготовить модель к развертыванию.
Эта методология не навязывает каких-либо жестких правил. В результате использования методологии SEMMA разработчик может располагать научными методами построения концепции проекта, его реализации, а также оценки результатов проектирования.
По результатам последних опросов KDnuggets (2004 г.), 42% опрошенных лиц использует методологию CRISP-DM, 10% - методологию SEMMA, 6% - собственную методологию организации, 28% - свою собственную методологию, другими методологиями пользуется 6% опрошенных. Не пользуются никакой методологией 7% опрошенных.
240
Другие стандарты Data Mining
Как уже отмечалось, описанные стандарты являются методологиями Data Mining, т.е. рассматривают организацию процесса и разработку систем Data Mining. Помимо этой группы, в последние годы появился ряд стандартов, цель которых - согласовать достижения в Data Mining, упростить управление моделированием процессов и дальнейшее использование созданных моделей. Эти стандарты условно можно поделить на две категории:
1.Стандарты, относящиеся к выработке единого соглашения по хранению и передаче моделей Data Mining.
2.Стандарты, относящиеся к унификации интерфейсов.
Стандарт PMML
В предыдущих лекциях мы уже упоминали о стандарте PMML (Predictive Modeling markup Language) - языке описания предикторных (или прогнозных) моделей или языке разметки для прогнозного моделирования.
PMML относится к группе стандартов по хранению и передаче моделей Data Mining.
Разработка и внедрение этого стандарта ведется IT-консорциумом DMG (Data Mining Group). DMG [103] - группа, в которую входят все лидирующие компании, разрабатывающие программное обеспечение в области анализа данных.
Основа этого стандарта - язык XML. Примером другого стандарта, также основанного на языке XML, является стандарт обмена статистическими данными и метаданными. Стандарт PMML используется для описания моделей Data Mining и статистических моделей.
Основная цель стандарта PMML - обеспечение возможности обмена моделями данных между программным обеспечением разных разработчиков.
При помощи стандарта PMML-совместимые приложения могут легко обмениваться моделями данных с другими PMML-инструментами. Таким образом, модель, созданная в одном программном продукте, может использоваться для прогнозного моделирования в другом.
По словам сторонников PMML, этот стандарт "делает Data Mining более демократичным", позволяет все большому количеству пользователей пользоваться продуктами Data Mining. Это достигается за счет возможности использования ранее созданных моделей данных.
PMML позволяет использовать модели данных сколь угодно часто и существенно помогает в практической работе с ними.
Стандарт PMML включает:
∙описание анализируемых данных (структура и типы данных);
∙описание схемы анализа (используемые поля данных);
∙описание трансформаций данных (например, преобразования типов данных);
∙описание статистик, прогнозируемых полей и самих прогнозных моделей.
241