

- •Что такое Data Mining?
- •Понятие Статистики
- •Понятие Машинного обучения
- •Понятие Искусственного интеллекта
- •Сравнение статистики, машинного обучения и Data Mining
- •Развитие технологии баз данных
- •Понятие Data Mining
- •Data Mining как часть рынка информационных технологий
- •Классификация аналитических систем
- •Мнение экспертов о Data Mining
- •Отличия Data Mining от других методов анализа данных
- •Перспективы технологии Data Mining
- •Существующие подходы к анализу
- •Данные
- •Что такое данные?
- •Набор данных и их атрибутов
- •Измерения
- •Шкалы
- •Типы наборов данных
- •Данные, состоящие из записей
- •Графические данные
- •Химические данные
- •Форматы хранения данных
- •Базы данных. Основные положения
- •Системы управления базами данных, СУБД
- •Классификация видов данных
- •Метаданные
- •Методы и стадии Data Mining
- •Классификация стадий Data Mining
- •Сравнение свободного поиска и прогностического моделирования с точки зрения логики
- •Классификация методов Data Mining
- •Классификация технологических методов Data Mining
- •Свойства методов Data Mining
- •Задачи Data Mining. Информация и знания
- •Задачи Data Mining
- •Классификация задач Data Mining
- •Связь понятий
- •От данных к решениям
- •От задачи к приложению
- •Информация
- •Свойства информации
- •Требования, предъявляемые к информации
- •Знания
- •Сопоставление и сравнение понятий "информация", "данные", "знание"
- •Задачи Data Mining. Классификация и кластеризация
- •Задача классификации
- •Процесс классификации
- •Методы, применяемые для решения задач классификации
- •Точность классификации: оценка уровня ошибок
- •Оценивание классификационных методов
- •Задача кластеризации
- •Оценка качества кластеризации
- •Процесс кластеризации
- •Применение кластерного анализа
- •Кластерный анализ в маркетинговых исследованиях
- •Практика применения кластерного анализа в маркетинговых исследованиях
- •Выводы
- •Задачи Data Mining. Прогнозирование и визуализация
- •Задача прогнозирования
- •Сравнение задач прогнозирования и классификации
- •Прогнозирование и временные ряды
- •Тренд, сезонность и цикл
- •Точность прогноза
- •Виды прогнозов
- •Методы прогнозирования
- •Задача визуализации
- •Плохая визуализация
- •Сферы применения Data Mining
- •Применение Data Mining для решения бизнес-задач
- •Банковское дело
- •Страхование
- •Телекоммуникации
- •Электронная коммерция
- •Промышленное производство
- •Маркетинг
- •Розничная торговля
- •Фондовый рынок
- •Применение Data Mining в CRM
- •Исследования для правительства
- •Data Mining для научных исследований
- •Биоинформатика
- •Медицина
- •Фармацевтика
- •Молекулярная генетика и генная инженерия
- •Химия
- •Web Mining
- •Text Mining
- •Call Mining
- •Основы анализа данных
- •Анализ данных в Microsoft Excel
- •Описательная статистика
- •Центральная тенденция
- •Свойства среднего
- •Некоторые свойства медианы
- •Характеристики вариации данных
- •Корреляционный анализ
- •Коэффициент корреляции Пирсона
- •Регрессионный анализ
- •Последовательность этапов регрессионного анализа
- •Задачи регрессионного анализа
- •Выводы
- •Методы классификации и прогнозирования. Деревья решений
- •Преимущества деревьев решений
- •Процесс конструирования дерева решений
- •Критерий расщепления
- •Большое дерево не означает, что оно "подходящее"
- •Остановка построения дерева
- •Сокращение дерева или отсечение ветвей
- •Алгоритмы
- •Алгоритм CART
- •Алгоритм C4.5
- •Разработка новых масштабируемых алгоритмов
- •Выводы
- •Методы классификации и прогнозирования. Метод опорных векторов. Метод "ближайшего соседа". Байесовская классификация
- •Метод опорных векторов
- •Линейный SVM
- •Метод "ближайшего соседа" или системы рассуждений на основе аналогичных случаев
- •Преимущества метода
- •Недостатки метода "ближайшего соседа"
- •Решение задачи классификации новых объектов
- •Решение задачи прогнозирования
- •Оценка параметра k методом кросс-проверки
- •Байесовская классификация
- •Байесовская фильтрация по словам
- •Методы классификации и прогнозирования. Нейронные сети
- •Элементы нейронных сетей
- •Архитектура нейронных сетей
- •Обучение нейронных сетей
- •Модели нейронных сетей
- •Персептрон
- •Программное обеспечение для работы с нейронными сетями
- •Пример решения задачи
- •Пакет Matlab
- •Нейронные сети. Самоорганизующиеся карты Кохонена.
- •Классификация нейронных сетей
- •Подготовка данных для обучения
- •Выбор структуры нейронной сети
- •Карты Кохонена
- •Самоорганизующиеся карты (Self-Organizing Maps, SOM)
- •Задачи, решаемые при помощи карт Кохонена
- •Обучение сети Кохонена
- •Пример решения задачи
- •Карты входов
- •Выводы
- •Методы кластерного анализа. Иерархические методы
- •Методы кластерного анализа
- •Иерархические методы кластерного анализа
- •Меры сходства
- •Методы объединения или связи
- •Иерархический кластерный анализ в SPSS
- •Пример иерархического кластерного анализа
- •Определение количества кластеров
- •Методы кластерного анализа. Итеративные методы.
- •Алгоритм k-средних (k-means)
- •Описание алгоритма
- •Проверка качества кластеризации
- •Алгоритм PAM ( partitioning around Medoids)
- •Предварительное сокращение размерности
- •Факторный анализ
- •Итеративная кластеризация в SPSS
- •Процесс кластерного анализа. Рекомендуемые этапы
- •Сложности и проблемы, которые могут возникнуть при применении кластерного анализа
- •Сравнительный анализ иерархических и неиерархических методов кластеризации
- •Новые алгоритмы и некоторые модификации алгоритмов кластерного анализа
- •Алгоритм BIRCH (Balanced Iterative Reducing and Clustering using Hierarchies)
- •Алгоритм WaveCluster
- •Алгоритм CLARA (Clustering LARge Applications)
- •Алгоритмы Clarans, CURE, DBScan
- •Методы поиска ассоциативных правил
- •Часто встречающиеся приложения с применением ассоциативных правил:
- •Введение в ассоциативные правила
- •Часто встречающиеся шаблоны или образцы
- •Поддержка
- •Характеристики ассоциативных правил
- •Границы поддержки и достоверности ассоциативного правила
- •Методы поиска ассоциативных правил
- •Разновидности алгоритма Apriori
- •AprioriTid
- •AprioriHybrid
- •Пример решения задачи поиска ассоциативных правил
- •Визуализатор "Правила"
- •Способы визуального представления данных. Методы визуализации
- •Визуализация инструментов Data Mining
- •Визуализация Data Mining моделей
- •Методы визуализации
- •Представление данных в одном, двух и трех измерениях
- •Представление данных в 4 + измерениях
- •Параллельные координаты
- •"Лица Чернова"
- •Качество визуализации
- •Представление пространственных характеристик
- •Основные тенденции в области визуализации
- •Выводы
- •Комплексный подход к внедрению Data Mining, OLAP и хранилищ данных в СППР
- •Классификация СППР
- •OLAP-системы
- •OLAP-продукты
- •Интеграция OLAP и Data Mining
- •Хранилища данных
- •Преимущества использования хранилищ данных
- •Процесс Data Mining. Начальные этапы
- •Этап 1. Анализ предметной области
- •Этап 2. Постановка задачи
- •Этап 3. Подготовка данных
- •1. Определение и анализ требований к данным
- •2. Сбор данных
- •Определение необходимого количества данных
- •3. Предварительная обработка данных
- •Очистка данных
- •Этапы очистки данных
- •Выводы
- •Процесс Data Mining. Очистка данных
- •Инструменты очистки данных
- •Выводы по подготовке данных
- •Процесс Data Mining. Построение и использование модели
- •Моделирование
- •Виды моделей
- •Математическая модель
- •Этап 4. Построение модели
- •Этап 5. Проверка и оценка моделей
- •Этап 6. Выбор модели
- •Этап 7. Применение модели
- •Этап 8. Коррекция и обновление модели
- •Погрешности в процессе Data Mining
- •Выводы
- •Организационные и человеческие факторы в Data Mining. Стандарты Data Mining
- •Организационные Факторы
- •Человеческие факторы. Роли в Data Mining
- •CRISP-DM методология
- •SEMMA методология
- •Другие стандарты Data Mining
- •Стандарт PMML
- •Стандарты, относящиеся к унификации интерфейсов
- •Рынок инструментов Data Mining
- •Поставщики Data Mining
- •Классификация инструментов Data Mining
- •Программное обеспечение Data Mining для поиска ассоциативных правил
- •Программное обеспечение для решения задач кластеризации и сегментации
- •Программное обеспечение для решения задач классификации
- •Программное обеспечение Data Mining для решения задач оценивания и прогнозирования
- •Выводы
- •Инструменты Data Mining. SAS Enterprise Miner
- •Обзор программного продукта
- •Графический интерфейс (GUI) для анализа данных
- •Инструментарий для углубленного интеллектуального анализа данных
- •Набор инструментов для подготовки, агрегации и исследования данных
- •Интегрированный комплекс разнообразных методов моделирования
- •Интегрированные средства сравнения моделей и пакеты результатов
- •Скоринг по модели и простота развертывания модели
- •Гибкость благодаря открытости и расширяемости
- •Встроенная стратегия обнаружения данных
- •Распределенная система интеллектуального анализа данных, ориентированная на крупные предприятия
- •Основные характеристики пакета SAS Enterprise Miner 5.1
- •Специализированное хранилище данных
- •Подход SAS к созданию информационно-аналитических систем
- •Технические требования пакета SASR Enterprise Miner
- •Инструменты Data Mining. Система PolyAnalyst
- •Архитектура системы
- •PolyAnalyst Workplace - лаборатория аналитика
- •Аналитический инструментарий PolyAnalyst
- •Модули для построения числовых моделей и прогноза числовых переменных
- •Алгоритмы кластеризации
- •Алгоритмы классификации
- •Алгоритмы ассоциации
- •Модули текстового анализа
- •Визуализация
- •Эволюционное программирование
- •Общесистемные характеристики PolyAnalyst
- •WebAnalyst
- •Инструменты Data Mining. Программные продукты Cognos и система STATISTICA Data Miner
- •Особенности методологии моделирования с применением Cognos 4Thought
- •Система STATISTICA Data Miner
- •Средства анализа STATISTICA Data Miner
- •Инструменты Oracle Data Mining и Deductor
- •Oracle Data Mining
- •Oracle Data Mining - функциональные возможности
- •Прогнозирующие модели
- •Краткая характеристика алгоритмов классификации
- •Регрессия
- •Поиск существенных атрибутов
- •Дескрипторные модели
- •Алгоритмы кластеризации
- •Аналитическая платформа Deductor
- •Поддержка процесса от разведочного анализа до отображения данных
- •Архитектура Deductor Studio
- •Архитектура Deductor Warehouse
- •Описание аналитических алгоритмов
- •Инструмент KXEN
- •Реинжиниринг аналитического процесса
- •Технические характеристики продукта
- •Предпосылки создания KXEN
- •Структура KXEN Analytic Framework Version 3.0
- •Технология IOLAP
- •Data Mining консалтинг
- •Data Mining-услуги
- •Работа с клиентом
- •Примеры решения
- •Техническое описание решения
- •Выводы
Если уровень достоверности слишком мал, то ценность правила вызывает серьезные сомнения. Например, правило с достоверностью в 3% только условно можно назвать правилом.
Методы поиска ассоциативных правил
Алгоритм AIS. Первый алгоритм поиска ассоциативных правил, называвшийся AIS [62], (предложенный Agrawal, Imielinski and Swami) был разработан сотрудниками исследовательского центра IBM Almaden в 1993 году. С этой работы начался интерес к ассоциативным правилам; на середину 90-х годов прошлого века пришелся пик исследовательских работ в этой области, и с тех пор каждый год появляется несколько новых алгоритмов.
В алгоритме AIS кандидаты множества наборов генерируются и подсчитываются "на лету", во время сканирования базы данных.
Алгоритм SETM. Создание этого алгоритма было мотивировано желанием использовать язык SQL для вычисления часто встречающихся наборов товаров. Как и алгоритм AIS, SETM также формирует кандидатов "на лету", основываясь на преобразованиях базы данных. Чтобы использовать стандартную операцию объединения языка SQL для формирования кандидата, SETM отделяет формирование кандидата от их подсчета.
Неудобство алгоритмов AIS и SETM - излишнее генерирование и подсчет слишком многих кандидатов, которые в результате не оказываются часто встречающимися. Для улучшения их работы был предложен алгоритм Apriori [63].
Работа данного алгоритма состоит из нескольких этапов, каждый из этапов состоит из следующих шагов:
∙формирование кандидатов;
∙подсчет кандидатов.
Формирование кандидатов (candidate generation) - этап, на котором алгоритм, сканируя базу данных, создает множество i-элементных кандидатов (i - номер этапа). На этом этапе поддержка кандидатов не рассчитывается.
Подсчет кандидатов (candidate counting) - этап, на котором вычисляется поддержка каждого i-элементного кандидата. Здесь же осуществляется отсечение кандидатов, поддержка которых меньше минимума, установленного пользователем (min_sup). Оставшиеся i-элементные наборы называем часто встречающимися.
Рассмотрим работу алгоритма Apriori на примере базы данных D. Иллюстрация работы алгоритма приведена на рис. 15.1. Минимальный уровень поддержки равен 3.
174
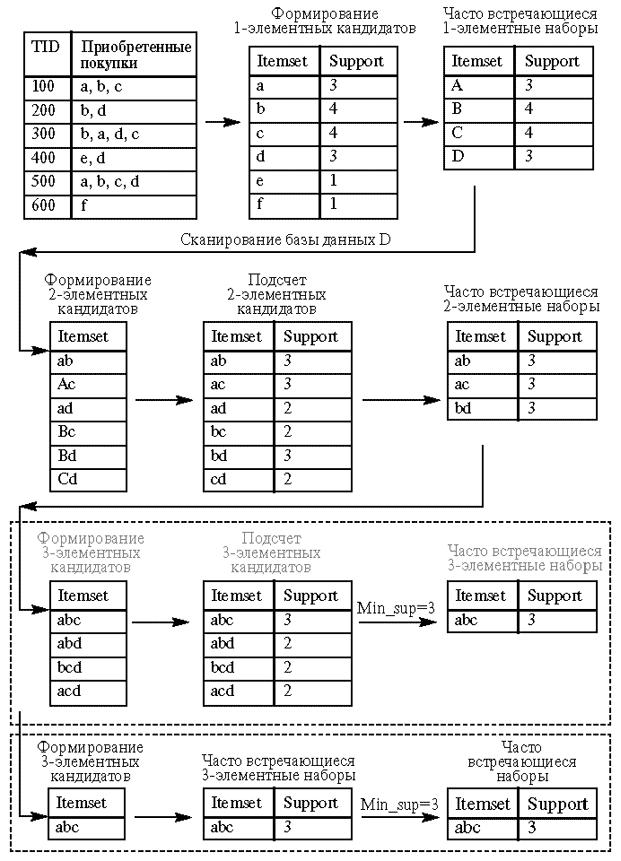
Рис. 15.1. Алгоритм Apriori
175