

3.3. Задача 3. Кластерный анализ
3.3.1. Постановка задачи кластерного анализа
Кластерный анализ - это совокупность методов классификации многомерных наблюдений или объектов, основанных на определении понятия расстояния между объектами с последующим выделением из них групп наблюдений (кластеров, таксонов).
Выбор конкретного метода кластерного анализа зависит от цели классификации.
Обычной формой представления исходных данных в задачах кластерного анализа служит матрица:

каждая строка которой , представляет результат измерений k, рассматриваемых признаков на одном из обследованных объектов.
Наиболее трудным считается определение однородности объектов, которые задаются введением расстояния между объектами хi и хj (p(xi, xj)).
Объекты будут однородными в случае p(xi, xj) pпор,
где pпор- заданное пороговое значение.
Выбор расстояния (р) является основным моментом исследования, от которого зависят окончательные варианты разбиения. Наиболее распространенными считаются принципы “ближайшего соседа” или “дальнего соседа”. В первом случае за расстояние между кластерами принимают расстояние между ближайшими элементами этих кластеров, а во втором - между наиболее удаленными друг от друга.
В задачах кластерного анализа часто используют Евклидово и Хемингово расстояния.
Евклидово расстояние определяется по формуле:
![]() ;
;
сравнивается близость двух объектов по большому числу признаков.
Хемингово расстояние:
![]() ;
;
используется как мера различия объектов, задаваемых атрибутивными признаками.
3.3.2. Решение задач кластерного анализа в интегрированных системах
Пример решения.
Провести
классификацию шести объектов, каждый
из которых характеризуется двумя
признаками (табл.9). В качестве расстояния
между объектами принять ![]() ,
расстояние между кластерами исчислить
по принципам: 1) “ближайшего соседа” и
2) “дальнего соседа”.
,
расстояние между кластерами исчислить
по принципам: 1) “ближайшего соседа” и
2) “дальнего соседа”.
Таблица 9
Исходные данные
|
№ п/п |
1 |
2 |
3 |
4 |
5 |
6 |
|
х1 |
2 |
4 |
5 |
12 |
14 |
15 |
|
х2 |
8 |
10 |
7 |
6 |
6 |
4 |
где х1 - объем выпускаемой продукции;
х2 - среднегодовая стоимость основных промышленно-производственных фондов. Зависимость между признаками приведена на рис. 12.
Так как в задаче не обуславливаются единицы измерения признаков, подразумевают, что они совпадают. Следовательно, нет необходимости в нормировании исходных данных, поэтому сразу рассчитываем матрицу расстояний.
Принцип “ближайшего соседа”.
Решение задачи:
В Excel 7.0 создаем таблицу с исходными данными и таблицы (матрицы) с расчетами (табл.10).
Х2

Воспользуемся агломеративным иерархическим алгоритмом классификации. В качестве расстояния между объектами примем обычное евклидовое расстояние. Тогда согласно формуле:
![]() ,
,
где l - признаки; k - количество признаков, расстояние между объектами 1 и 2 равно:
р11=0;
![]() .
.
Расчеты последующих
расстояний ![]() аналогичны.
аналогичны.
1. Формулу: =КОРЕНЬ((B5-B5)^2+(B6-B6)^2) помещаем в ячейку В14 и рассчитываем расстояние р11, затем в ячейке В15 - расстояние р12 по формуле: =КОРЕНЬ((B5-C5)^2+(B6-C6)^2) и т.д., пока не будет произведен расчет расстояний между всеми шестью объектами (ячейки В14:В29):
p11=0; p12=2.83; p13=3.16; p14=10.20; p15=12.17;
p16=13.6; p23=3.16; p24=8.94; p25=10.77; p26=12.53;
p34=7.07; p35=9.06; p36=10.44; p45=2; p46=3.61; p56=2.24.
Полученные данные помещаем в таблицу (матрицу) -ячейки D15:J21. Из матрицы расстояний следует, что объекты 4 и 5 наиболее близки P45=2.00 и поэтому объединяются в один кластер. Для расчета наименьшего расстояния используется формула: =МИН(F16:J16;G17:J17;H18:J18;I19:J19;J20) - ячейка E22.
После объединения имеем пять кластеров.
|
Номер кластера |
1 |
2 |
3 |
4 |
5 |
|
Состав кластера |
(1) |
(2) |
(3) |
(4,5) |
(6) |
Матрицу расстояний помещаем в ячейки D25 - I30, воспользуемся этой матрицей расстояний, чтобы рассчитать расстояние объединяемых объектов 4,5 и 6, которые имеют наименьшее расстояние PMIN=P4,5,6=2.24 (формула =МИН(F26:I26;G27:I27;H28:I28;I29 в ячейке E32). После объединения имеем четыре кластера: S(1), S(2), S(3), S(4,5,6).
Таблица 10
Исходные данные

Вновь находим матрицу расстояний (табл.11), помещаем рассчитанные значения в ячейки D35 - H39 и объединяем объекты 1 и 2, имеющие наименьшее расстояние PMIN=P1,2=2.83 (формула =МИН(F36:H36;G37:H37;H38) в ячейке E41). Расстояние между остальными кластерами остается без изменения. В результате имеем три кластера: S(1,2), S(3), S(4,5,6).
Объединим теперь объекты 1,2 и 3, расстояние между которыми равно: PMIN=P1,2,3=3.16 (формула =МИН(F45:G45;G46) в ячейке E49.
Таким образом, при проведении кластерного анализа по принципу “ближайшего соседа” получили два кластера: S(1,2,3), S(4,5,6), расстояние между которыми равно:
P(1,2,3); (4,5,6) = 7,07.
Таблица 11
Расчетные значения

Результаты иерархической классификации объектов представлены на рис.13 в виде
дерева объединения кластеров - дендрограммы, где по оси ординат приводятся расстояния между объединяемыми на данном этапе кластерами.
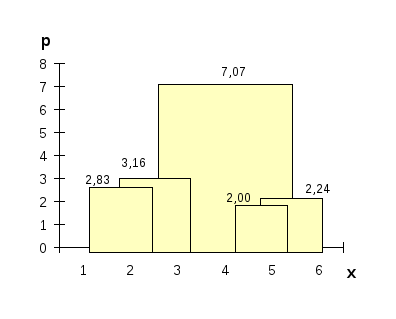
Рис.13. Дендрограмма