

morozov_lektsiyi
.pdfПроектування машин баз даних та знань |
21 |
3.3. Стандарти архітектури клієнт-сервер в управлінні інформацією
3.3.1. SQL Access Group і стандарт DRDA
Процес стандартизації доступу до баз даних клієнт-сервер набув найбільшої активності в кінці 80-х - початку 90-х років. В 1989 році утворилася група SQL Access Group (SAG). Вона є консорціумом з 42 компаній, до числа яких входять найбільші постачальники СУБД і різних інструментальних засобів систем баз даних. Однією із задач SAG було визначення специфікацій форматів і протоколів (Formats And Protocols, FAP) для комунікацій в системах баз даних клієнт-сервер на основі специфікацій Віддаленого доступу до баз даних (Remote Database Access, RDA), розроблених Міжнародною організацією по стандартизації
(International Standards Organization, ISO). Стандарт RDA був описаний в документі ISO/IEC 9579, Інформаційні технології - Мови баз даних - Видалений доступ до баз даних (ISO/IEC
9579, Information Technology Database Languages - Remote Database Access), який складається з двох частин: Загальна модель, сервіс і протокол (Generic Model, Service and Protocol) і Спеціалізація SQL (SQL Specialization). Друга частина цього документа і стала основою специфікацій FAP, запропонованих групою SAG.
Приблизно в той же час компанія IBM, єдиний крупний постачальник засобів для баз даних, що не увійшов до групи SAG, ввела стандарт „Архітектура розподілених реляційних баз даних” (Distributed Relational Database Architecture, DRDA), що ніяк не узгоджується з ISO RDA.
Початковою метою DRDA була інтеграція баз даних в рамках системної архітектури додатків (System Application Architecture, SAA), запропонованої IBM. Спочатку SAA розглядалася як головний засіб інтеграції для чотирьох платформ IBM (MVS, VM, OS/400 і OS/2). Використовуючи DRDA і SAA, можна об’єднати менеджери баз даних для цих платформ (DB2, SQL/DS, OS/400 Data Manager і OS/2 Extended Edition Database Manager
відповідно) в єдину модель клієнт-сервер.
Між специфікаціями SAG і DRDA існує ряд технічних відмінностей. Оскільки специфікації FAP, запропоновані SAG, були засновані на ISO RDA, то компоненти ISO, у тому числі абстрактний синтаксис ASN.1 (Abstract Syntax Notation, ASN) і базові правила кодування (Basic Encoding Rules, BER) для ASN.l, використовуються як синтаксис передачі повідомлень (Transfer Syntax), хоча синтаксис фактичних повідомлень встановлюється індивідуально для кожного з’єднання шляхом узгодження. На відміну від цього DRDA спирається на архітектуру управління розподіленими даними IBM (Distributed Data Management, DDM), а саме на її третій рівень, який визначає абстрактний синтаксис і правила кодування команд і відповідно повідомлень. Для представлення даних і метаданих у DRDA використовується архітектура IBM FD OCA, що вживається також для представлення складних документів.
3.3.2.Стандарти, засновані на інтерфейсі рівня викликів SAG
У1992 році виникли відразу два конкуруючі стандарти - ODBC і IDAPI, і обидва вони були засновані на інтерфейсі рівня викликів (Call-Level Interface, CLI), запропонованому SAG. Перший з них - Відкритий інтерфейс доступу до баз даних (Open Data Base Connectivity, ODBC) був введений і активно просувався компанією Microsoft. Метою Microsoft було надання додаткам Microsoft Windows доступу до баз даних, заснованих на SQL, за допомогою стандартизованого інтерфейсу клієнт-сервер (мал. 3.6). Головне призначення ODBC - перетворити SAG CLI з абстрактного узагальненого стандарту в живе середовище, в якому він може безпосередньо використовуватися в додатках для ПК.
Тепер до їх числа слід додати корпоративний стандарт JDBC, розроблений Sun Microsystems і також заснований на Х/Ореп SQL CLI. Цей стандарт специфікує Java API для
Проектування машин баз даних та знань |
22 |
систем баз даних, заснованих на мові SQL. Він був оформлений у вигляді спеціального пакету Java, що містить відповідний набір специфікацій класів і інтерфейсів. У кінці 1997 році компанія Sun Microsystems випустила новий продукт Java Blend для вирішення тієї ж задачі, який є надбудовою над JDBC. При цьому розробник звільняється від необхідності знання SQL і всі специфікації формулює засобами Java.
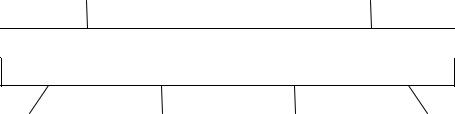
В листопаді 1992 році, група компаній під керівництвом Borland (що включала також IBM, Novell і WordPerfect) оголосила аналогічний стандарт інтерфейсу для систем баз даних клієнт-сервер, також заснований на SAG CLI і що отримав назву Інтерфейсу прикладного програмування для інтегрованих систем баз даних (Integrated Database Application Programming Interface, IDAPI). Архітектура IDAPI показана на мал. 3.2. Стандарт IDAPI концептуально аналогічний ODBC. Обидва стандарти специфікують інтерфейси клієнтсервер, засновані на SAG CLI, але IDAPI спочатку був орієнтований, крім Microsoft Windows, також і на інші платформи і надавав на додачу до SQL-доступу також і навігаційний доступ до серверів баз даних. Стандарт IDAPI прийшов на зміну іншому корпоративному стандарту компанії Borland - Інтерфейсу прикладного програмування об’єктних баз даних (Object Database API, ODAPI), який був частиною Компонентної об’єктної архітектури Borland (Borland Object Component Architecture, BOCA).
Додатки |
|
Додатки |
користувачів |
|
користувачів |
|
|
|
IDAPI API (SQL/CLI і NAV/CLI)
Технологія IDAPI
Драйвер |
|
Драйвер |
|
Драйвер |
|
Драйвер |
dBase |
|
Oracle |
|
DB2 |
|
Sybase |
|
|
|
|
|
|
|
Мал. 3.2. Технічна архітектура IDAPI
На мал. 3.3 показано співвідношення між стандартами ODBC і IDAPI сьогодні і, можливо, в майбутньому. Коли був оголошений стандарт IDAPI, голова групи SAG заявив, що SAG вивчить ті розширення базового стандарту SAG CLI, що містяться в IDAPI, і це означає, що навігаційні засоби, можливо, будуть введені також і в SAG CLI.
3.4. Програмне забезпечення проміжного шару
Стандартизовані інтерфейси клієнт-сервер останніми роками прийнято відносити до категорії програмного забезпечення проміжного шару, яке визначається як „деякий набір процедур або функцій, що забезпечують взаємодію двох різнорідних програм”. Програмні засоби цієї категорії застосовні до комп’ютерних сервісів практично будь-якого вигляду, включаючи управління базами даних і інформацією. Комерційні або самостійно розроблені програмні продукти, засновані на IDAPI, ODBC, DRDA або інших стандартах і, що надають інтерфейсі можливості для клієнта і серверу, відносяться до категорії програмного забезпечення проміжного шару.
Проектування машин баз даних та знань |
23 |
IDAPI |
Стандарт |
ODBC |
|
|
SQL/CLI |
|
|
SQL/CLI |
|
|
|
NAV/CLI |
|
|
|
|
розвивається |
розвивається |
|
Інші |
у напрямку |
у напрямку |
|
можливості
Мал. 3.3. Стандарти ODBC і IDAPI сьогодні і завтра
Тема 4. Управління розподіленою інформацією
4.1. Принципи побудови сховищ даних
Сховище даних - це логічно інтегроване джерело даних для додатку систем підтримки ухвалення рішень (DSS) і інформаційних систем керівника (EIS). Кажучи про логічну інтегрованість, тому що деякі прості середовища сховищ даних, можуть бути централізованими (незалежно від того, розподіленими або централізованими є самі джерела даних для них). Проте найвідповіднішим, у міру зростання популярності сховищ даних стануть, мабуть, розподілені архітектури. Можливо навіть, що розподіленість стане необхідною властивістю через такі чинники, як ємність запам’ятовуючих пристроїв.
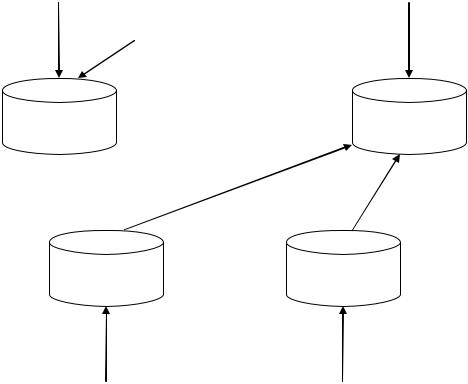
Розвинута архітектура, де як джерелами для сховища даних виступають декілька баз даних, показана на мал. 4.1.
Важливо, проте, розуміти, що сховище даних - не є розподіленою або нерозподіленою базою даних.
Оскільки призначення сховища даних - це інформаційна підтримка ухвалення рішень, а не операційної обробки або обробки трансакцій, то багато принципів, що лежать в основі технології баз даних, втрачають для них своє значення. Зокрема, в сховищах даних не підтримуються операції оновлення даних, традиційні для систем баз даних. Нижче перераховано чотири основоположні принципи організації сховищ даних.
1.Наочна орієнтація. В операційних інформаційних системах звичайно підтримується декілька наочних областей, кожна з яких може послужити кандидатом для представлення в сховищі даних. Наприклад, для магазина роздрібної торгівлі видео- і музичною продукцією можуть представляти інтерес наступні наочні області:
- клієнти; - відеокасети;
- компакт-диски і аудіокасети; - співробітники; - постачальники.
Неважко провести аналогію між наочними областями сховища даних і класами об’єктів
воб’єктно-орієнтованих базах даних. Дійсно, методи проектування і моделювання, що вживаються в об’єктно-орієнтованих базах даних, можуть виявитися корисними і при формуванні наочних областей сховищ даних.
2.Можливості інтеграції. Вище вже обговорювалися проблеми інтеграції даних, що виникають при побудові глобальних схем для розподілених середовищ федеральних або мультибаз даних. Мовилося про те, що одна і та ж сутність у різних існуючих базах даних і
Проектування машин баз даних та знань |
24 |
додатках може бути представлено абсолютно по-різному, і що всі ці уявлення повинні бути відображені в деяке загальне уявлення. Точно такий же принцип повинен застосовуватися і до середовища сховищ даних, що одержують інформацію від низки додатків і операційних баз даних, як показано на мал. 4.1.
|
|
|
|
|
Інформаційна |
|
|
|
|
|
система |
|
|
|
|
||
|
Додаток 1 |
|
|
|
керівника |
|
|
|
|
|
|
Операції |
|
Додаток 2 |
Інформаційні |
||
читання/запису |
|
||||
|
|
|
запити |
||
над базою |
|
|
|
||
|
Операції |
||||
|
|
|
|||
|
даних |
|
|
|
|
|
|
читання/запису |
|
|
|
|
|
|
|
|
|
|
|
|
над базою |
|
|
|
|
|
даних |
|
|
Операційна  Сховище
Сховище
база даних Періодичне поповнення вмісту даних сховища даних
|
Операційна |
|
Операційна |
|
база даних |
|
база даних |
Операції |
Операції |
||
читання/запису |
читання/запису |
||
над базою |
над базою |
||
|
даних |
|
даних |
|
|
|
|
|
Додаток 3 |
|
Додаток 4 |
|
|
|
|
Мал. 4.1. Множина баз даних як джерело для сховища даних
3.Немінливість даних. У сховищах даних не підтримуються традиційні для систем баз даних операції оновлення даних. Для різних середовищ баз даних характерні різні рівні мінливості даних. Так, в реляційних базах даних допускаються вставки рядків, зміни значень стовпців, видалення рядків, виконувані регулярно в процесі звичайної діяльності. В сховищах даних підтримується модель „масового завантаження” даних (виконується в задані моменти часу) згідно зі встановленими правилами витягання їх з джерел. Масове завантаження може виконуватися з централізованої бази даних, що знаходиться в тій же обчислювальній системі, що і сховище даних, а може здійснюватися і шляхом одночасних витягань даних з розподілених баз даних (або навіть з розрізнених баз даних або інформаційних систем, які не знаходяться під контролем якого-небудь типу глобальної схеми). Коротше кажучи, модель оновлення індивідуальних об’єктів, що використовується в традиційних базах даних, не застосовується до сховищ даних.
4.Зміни в часі. Завдяки всім можливостям інтеграції і підтримки інформації сховище даних - це дещо більше, ніж просто «складна послідовність миттєвих знімків». Воно завжди має певний часовий (темпоральний) аспект, властивий його вмісту. Далі будуть розглянуті тимчасові бази даних як ще одна область управління інформацією, що зароджується.
Проектування машин баз даних та знань |
25 |
Фундаментальний принцип часових баз даних, що полягає в тому, що час є ключовим компонентом бази даних і її вмісту, також можна віднести і до сховищ даних.
Централізоване сховище даних
Операційна Операційна  база даних база даних
база даних база даних
Операційна база даних
Розподілене сховище даних
Сховище
даних
Сховище
даних
Сховище
даних
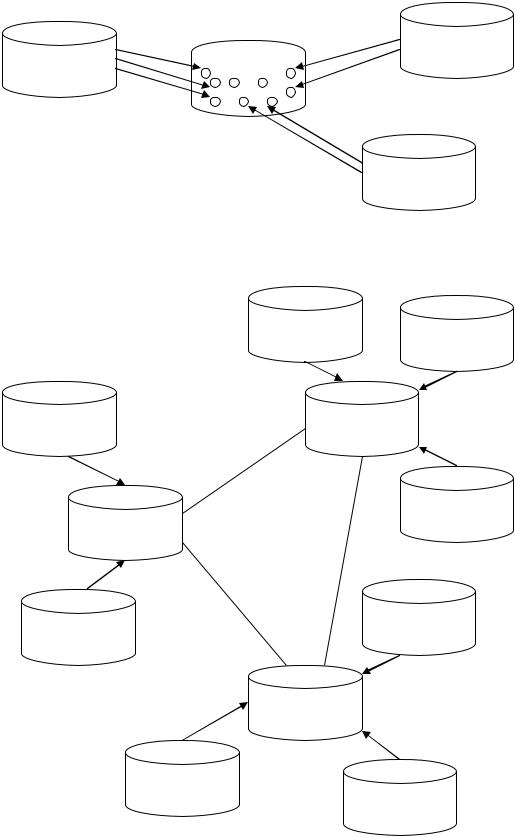
Мал. 4.2. Архітектура централізованого і розподіленого сховища даних
Проектування машин баз даних та знань |
26 |
Організації, що вже використовують сховища даних або планують робити це в майбутньому, неминуче зіткнуться з необхідністю мати в тому або іншому ступені можливість розподілення, подібно до своїх операційних баз даних. Тому архітектори, проектувальники і фахівці з реалізації сховищ даних повинні мати уявлення про принципи побудови розподілених сховищ даних, а також про існуючі комерційні і інші розробки такого роду.
Розглянемо архітектуру сховищ даних, зображену на мал. 4.2. Централізоване сховище даних може застосовуватися для таких середовищ, де осереддям даних компанії як і раніше є мейнфрейм. В той же час недоцільно зберігати централізовану архітектуру інформаційних додатків в ситуаціях, коли операційні додатки (і відповідні дані) базуються на розподілених обчислювальних системах.
4.2. Цифрові бібліотеки і інформаційні магістралі
Принципи організації сховищ даних можуть, ймовірно, зіграти важливу роль в розвитку таких перспективних напрямів управління інформацією, як цифрові бібліотеки і доступ до них за допомогою інформаційних магістралей. Концентруючи великі об’єми інформації з множини джерел в сховищах даних, до яких організований доступ через загальнонаціональну оптоволоконну мережу, можна було б надавати величезні масиви інформації користувачам безпосередньо за місцем їх проживання або роботи.
Цифрові бібліотеки (Digital Libraries), або „електронні бібліотеки”, — одна з нових технологій, що інтенсивно розвиваються в 90-х роках. Йдеться про створення крупних розподілених мультимедійних і гипермедійних інформаційних систем, що дозволяють ефективно використовувати різноманітні колекції електронних документів, що володіють вельми розвинутими призначеними для користувача інтерфейсами, що реалізовують елементи систем баз знань, що забезпечують доступ користувачів через глобальні комунікаційні мережі.
Теми 5. Паралельні системи баз даних
5.1. Сучасні підходи до фрагментація і тиражування
Згідно з означенням фрагментація означає розбиття об’єкту даних, наприклад реляційної таблиці, на підмножини рядків або стовпців і розподіл їх між різними ресурсами обчислювальної системи.
Тиражування - це створення дублюючих копій (реплікатів) об’єктів даних на різних вузлах з метою підвищення рівня доступу і/або скорочення часу доступу до критично важливих даних.
Зосередимо увагу на використанні моделей фрагментації при реалізації обробки з масовим паралелізмом (Massively Parallel Processing, МРР) і паралельних систем баз даних.
5.2. Концепції МРР і паралельних систем баз даних
На елементарному рівні ідеї систем обробки даних з масовим паралелізмом виключно прості: декомпозиція обчислювальних задач на велику кількість операцій, що паралельно виконуються. Архітектура МРР (Мал. 5.1) може масштабуватися аж до тисяч процесорів, оскільки в ній виключені вузькі місця, властиві симетричним багатопроцесорним системам (Symmetrical Multiple Processing, SMP), за рахунок досконаліших міжпроцесорних комунікацій і схем доступу до пам’яті.
Проектування машин баз даних та знань |
27 |
У середовищах управління інформацією МРР є будівельними блоками, з яких створюються системи баз даних з високим рівнем паралелізму, що є привабливими альтернативами централізованих база даних на мейнфреймах.
|
Процесор |
|
Процесор |
Пам’ять |
Процесор |
Пам’ять |
|
Пам’ять |
|
Міжпроцесорна мережа |
|
Процесор |
|
Процесор |
|
|
|
|
Процесор |
Пам’ять |
Пам’ять |
|
|
|
|
|
|
Пам’ять |
|
Мал. 5.1. Архітектура МРР
Відродження інтересу до таких систем пояснюється частково становленням і розвитком реляційних СУБД як домінуючого інструменту управління інформацією, оскільки реляційні запити є ідеальним об’єктом для розпаралелювання.
REPORT
SCAN
Мал. 5.2. Конвеєрний паралелізм
Розглянемо основну властивість реляційної моделі, що полягає в тому, що кожний оператор породжує нове відношення. Це означає, що низка операторів (можливо, дуже велика) може бути представлена у вигляді сильно розпаралелюючого графу потоків даних. Застосовуючи конвеєрний паралелізм, можна направити результат виконання оператора А на вхід оператору В, де В виконується услід за А. Якщо, скажімо, оператори SCAN (перегляд) і
Проектування машин баз даних та знань |
28 |
REPORT (звіт) виконуються в режимі конвеєрного паралелізму, то результати SCAN поступатимуть на вхід REPORT, але при цьому обидва оператори виконуватимуться паралельно (мал. 5.2).
Альтернативна модель паралелізму - паралелізм з фрагментацією - дозволяє розбивати один оператор на декількох незалежних, кожний з яких працює з окремим незалежним набором даних, і всі вони виконуються паралельно. Як показано на мал. 5.3, кожний потік моделі паралелізму з фрагментацією може також використовувати конвейєрний паралелізм, видаючи результат оператору рекомбінування даних, наприклад оператору MERGE (злиття).
Тут є, проте, одне тонке місце. Для того, щоб реалізувати паралелізм з фрагментацією, початкові дані також повинні бути фрагментовані. Слід відзначити лише, що фрагментація даних є необхідною передумовою для вживання паралельних систем баз даних, що ґрунтуються на паралелізмі з фрагментацією.
MERGE
REPORT |
|
REPORT |
|
REPORT |
|
REPORT |
|
REPORT |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
SCAN |
|
SCAN |
|
SCAN |
|
SCAN |
|
SCAN |
|
|
|
|
|
|
|
|
|
Мал. 5.3. Паралелізм з фрагментацією
(тут SCAN - перегляд, SORT - сортування, MERGE - злиття)
5.3. Моделі фрагментації для паралельних систем баз даних
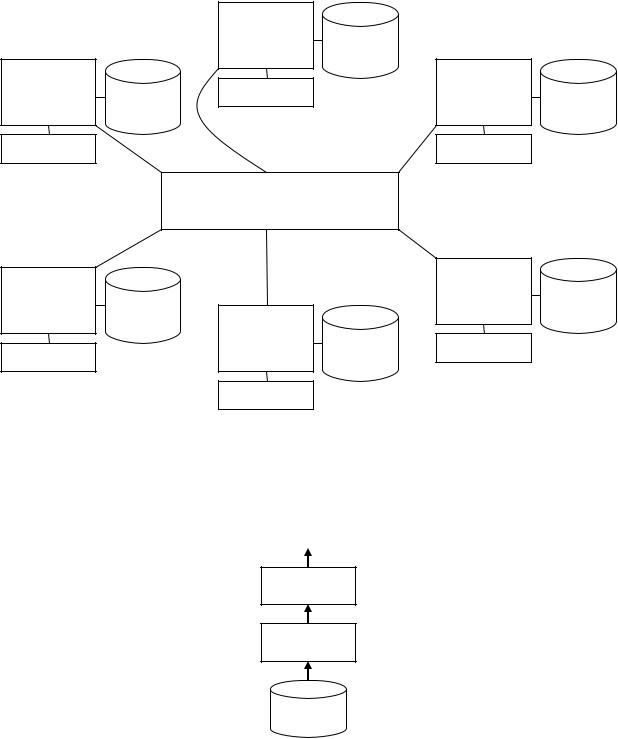
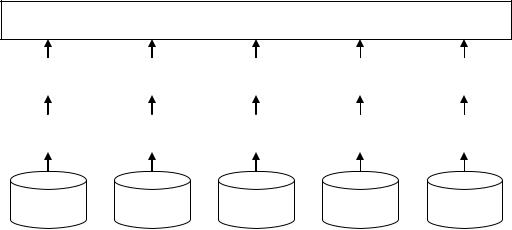
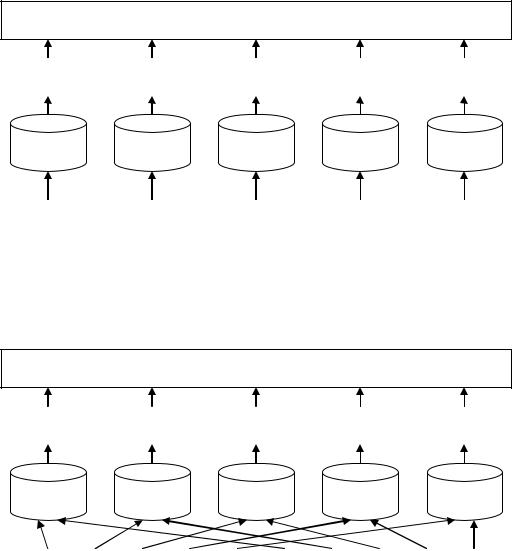
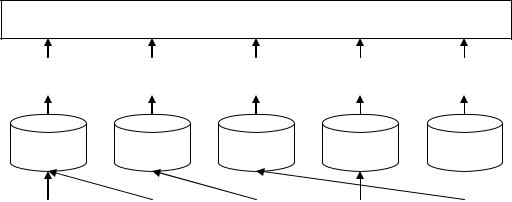
Як згадувалося вище, необхідною передумовою для досягнення паралелізму з фрагментацією є фрагментація даних. На мал. 5.4, 5.5 і 5.6 відповідно наведені приклади трьох схем фрагментації - фрагментації за діапазонами, карусельної фрагментації і фрагментації хешуванням.
Кожна з цих схем має свої відносні достоїнства і недоліки. Фрагментація по діапазонах приводить до створення кластерів кортежів, близьких за якою-небудь характеристикою, що зручне для послідовного доступу до відношення. Результати вибірки з кожного кластера можна зібрати разом і злити, а якщо необхідне впорядкування результату співпадає з базою фрагментації (скажімо, сортування за збільшенням деякого коду, що позначає місце роботи), то проміжне сортування в кожному потоці виконання може бути взагалі не потрібно. В той же час залежно від розподілу значень за діапазонами можна отримати нерівномірне заповнення фрагментів, що приводить до „перекосів” при виконанні запитів. Перекоси можна звести до мінімуму, використовуючи критерії розподілу, близького до рівномірного.
При карусельній фрагментації значення даних не грають якої-небудь ролі. Фрагменти розподіляються між різними дисками і процесорами, і кожний черговий кортеж прямує в наступний за порядком фрагмент. Карусельна фрагментація в меншій мірі схильна до „перекосів”, так само як фрагментація хешуванням, коли номер фрагменту для кожного кортежу визначається вживанням хеш-функції до якого-небудь його атрибуту.
Проектування машин баз даних та знань |
29 |
Міжпроцесорна мережа
Процесор 1 |
|
Процесор 2 |
|
Процесор 3 |
|
Процесор 4 |
|
Процесор 5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 - 100 |
|
101 - 200 |
|
201 - 300 |
|
301 - 400 |
|
401 - 500 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Фрагментація за діапазонами Мал. 5.4. Фрагментація за діапазонами в паралельних системах даних
Міжпроцесорна мережа
Процесор 1 |
|
|
Процесор 2 |
|
|
Процесор 3 |
|
Процесор 4 |
|
Процесор 5 |
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Карусельна фрагментація
Мал. 5.5. Карусельна фрагментація в паралельних системах даних
5.3.Перспективи розвитку паралельних систем баз даних
Вгалузі паралельних систем баз даних було досягнуто немало важливих результатів – „стандартизація” принципів реалізації (або навіть самих фактичних реалізацій) на архітектурі без розділення ресурсів, розробка добре розпаралелюючих алгоритмів для виконання реляційних операторів і ін. Проте в цій області залишається ще цілий ряд невирішених проблем:
- Поєднання пакетної обробки і оперативної обробки трансакцій (On-Line Transaction Processing, OLTP) на одному сервері. В середовищах, призначених для виконання пакетних завдань, і в середовищах для OLTP-обробки істотно розрізняються принципи управління блокуванням ресурсів і пріоритетного планування. Для максимально ефективної обробки паралельних реляційних операторів при співіснуванні вказаних типів середовищ (наприклад, виконання пакетних завдань, що ініціюються з центру обробки даних, і обробка випадкових
Проектування машин баз даних та знань |
30 |
запитів, що поступають від окремих користувачів) необхідно розробити моделі і алгоритми, придатні для цих обох типів середовищ.
Міжпроцесорна мережа
|
Процесор 1 |
|
Процесор 2 |
|
Процесор 3 |
|
Процесор 4 |
|
Процесор 5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Фрагментація з кешуванням
Мал. 5.6. Фрагментація з кешуванням в паралельних системах даних
-Оптимізація паралельних запитів. Оптимізатори запитів повинні бути забезпечені засобами для розгляду всіх можливих паралельних алгоритмів реалізації кожного оператора,
зтим щоб вибрати в кожному випадку оптимальне поєднання конвеєрного паралелізму і паралелізму з фрагментацією.
-Розпаралелювання прикладних програм. Є декілька мов, що в якійсь мірі передбачають засоби паралельного виконання (наприклад, модель багатозадачності в мові Ада, яка, втім, часто вимагає додаткової настройки навіть в сучасних багатопотокових середовищах). Проте в багатьох мовах, наприклад в Коболі, взагалі відсутні засоби розпаралелювання. Механізмом для реалізації паралелізму в прикладних програмах, мабуть, повинні стати бібліотечні процедури.
-Фізичне проектування баз даних. Оскільки є три альтернативи фрагментації для підтримки паралельних систем баз даних, необхідні інструментальні засоби проектування, здатні допомогти в аналізі організації бази даних і надати рекомендації з вибору оптимальних стратегій фрагментації.
-Утиліти і процедури реорганізації баз даних, виконувані в оперативному режимі.
Якщо врахувати, що паралельні системи баз даних, ймовірно, оперуватимуть терабайтовими об’ємами даних, то очевидно, що традиційні процедури завантаження, реорганізації, видачі дампів, створення індексів і виконань інших службових функцій виявляться абсолютно непридатними у зв’язку із значним збільшенням необхідних витрат часу. Фрагментація повинна також враховуватися при реалізації таких службових функцій, як створення вибіркових контрольних копій і відновлення даних.
5.4. Перспективи тиражування
Тиражування - цей розподіл даних не на основі моделі їх розбиття (наприклад, горизонтальної або вертикальної фрагментації), а за допомогою їх дублювання. Для управління існуючими в даному середовищі можливостями оновлення копій з боку додатків, а також стратегіями синхронізації копій застосовуються різноманітні моделі (втім, іноді ці можливості відсутні).
Основні принципи тиражування даних, перераховані нижче: 1) Повні або часткові копії Стратегії оновлення копій