

Мат. лінгвістика 3
.pdf2.4 Імовірнісний підхід до визначення кількості інформації
При описі комбінаторного методу для обчислення кількості інформації та ентропії ми використовували спрощення, за яким всі закінчення досліду вважались рівноймовірними. При реальних дослідженнях така ситуація практично ніколи не зустрічається. Норма мови приписує кожному лінгвістичному елементу певну ймовірність. Якщо лінгвістичне випробування передбачає нерівноймовірні результати, то, очевидно, ентропія такого досліду і отримана від нього кількість інформації будуть відрізнятись від аналогічних величин для досліду з рівноймовірними результатами.
Перехід від оцінки невизначеності і інформації досліду з рівноймовірними закінченнями до обчислення ентропії та інформації випробування з нерівноймовірними закінченнями здійснюється на основі таких міркувань.
Використовуючи відомі правила логарифмування, перепишемо (6) вигляді
I0 log2 1 S . |
(8) |
Тут величина 1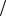 S – це ймовірність p кожного закінчення досліду. Припустимо тепер, що закінчення досліду нерівноймовірні і кожне закінчення має свою ймовірність pi . Тоді індивідуальна кількість інформації,
S – це ймовірність p кожного закінчення досліду. Припустимо тепер, що закінчення досліду нерівноймовірні і кожне закінчення має свою ймовірність pi . Тоді індивідуальна кількість інформації,
яка дається закінченням i при його окремій появі, дорівнює
Ii log2 pi .
При багатократному виконанні досліду закінчення i буде відбуватись з імовірністю pi . Тому середня кількість інформації, яка подається закінченням i при багатократному здійсненні випробування, складе
~
Ii pi log2 pi .
Величина I~i визначає той вклад, котрий вносить результат i у загальну кількість інформації, яка отримується при багатократному проведенні досліду A. Що стосується загальної інформації, то вона є сумою вкладів усіх S можливих результатів і визначається наступною рівністю, яка дає оцінку інформації незалежно від її змісту.
I pi log2 pi |
(9) |
Ii. |
Проте, інформаційні вимірювання, які ґрунтуються на обробці розподілів безумовних ймовірностей, мають у мовознавстві обмежене застосування. Справа полягає в тому, що мовні одиниці виступають у тексті як залежні лінгвістичні події, що обумовлені контекстом, а їхні ймовірності є умовними. Розподіл таких ймовірностей визначається тим положенням, яке займає дана
11
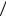
лінгвістична одиниця в тексті. Так, наприклад, розподіл ймовірностей букв на початку слова сильно відрізняється від спектру їхніх безумовних ймовірностей.
Щодо інформації, яка одержується з даної ділянки тексту, то вона дорівнює ентропії, яка характеризує цю ділянку.
Розглянемо тепер методику обчислення інформації, яка одержується від
деякого лінгвістичного досліду L, який має S |
результатів і здійснюється на |
n-й ділянці тексту за умови, що відомий |
ланцюжок bn 1 лінгвістичних |
елементів, який розташований перед цією ділянкою. Ланцюжок bn 1 розглядається як випадкова подія, яка набуває частковий вигляд i. Поява того чи іншого елементу в позиції n також розглядається як випадкова величина,
яка набуває значення |
jk (1 k S ). Для кожного значення i, яке може набути |
||||||||
bn 1 відома умовна ймовірність |
p j |
k |
/bn 1 |
того, що L |
одержить значення j |
k |
. |
||
|
|
|
|
i |
n |
|
|
||
Середня умовна |
ентропія |
Hn , |
яка |
кількісно |
дорівнює інформації In , |
||||
одержується в результаті усереднення ентропії, підрахованої по всіх
значеннях bn 1 |
з вагами, які відповідають імовірностям ланцюжка bn 1 . |
|
||||||||||||||||||
i |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Таким чином, маємо |
|
|
|
|
|
|
|
|
|
|
|
|
|
(10) |
||||||
|
|
|
|
|
|
|
|
|
S |
|
|
|
|
|
|
|
|
|||
|
H |
|
I |
|
|
|
|
p bn 1 |
|
p j |
|
/bn 1 |
log |
|
p j |
|
/bn 1 |
. |
|
|
|
n |
n |
|
|
|
k |
2 |
k |
|
|||||||||||
|
|
|
|
i |
|
|
i |
|
|
i |
|
|
||||||||
|
|
|
|
|
|
bn 1 |
|
|
|
k 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
i |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рівність (10) показує, якою є в середньому міра невизначеності і кількість інформації від вибору лінгвістичного елементу в позиції n, коли відомий ланцюжок bn 1 .
2.5Приріст інформації
Припустімо, що до початку процесу дослід може закінчуватись p1 рівноімовірними результатами, жоден з яких не має переваги над іншим, а після закінчення процесу – p2 результатами. Зміна інформації при цьому визначатиметься так:
|
I kln p1 p2 k ln p1 ln p2 . |
(11) |
Якщо I 0 |
отримуємо приріст інформації, |
тобто відомості про дослід |
стали більш визначеними, при I 0 менш визначеними. Притому важливо, що не використовувалась явно структура досліду (механізм протікання процесу). Величина I може бути інтерпретована як кількість інформації, що необхідна для переходу від одного рівня організації системи до іншого ( I 0вищий рівень, I 0 нижчий рівень).
12
2.6 Інформаційні виміри кодування інформації
Представимо описані вище характеристики інформації у термінах кодування інформації.
Комбінаторний підхід до визначення кількості інформації. Загальна кількість повідомлень, що не повторюються, яка може бути складена з алфавіту з m символів шляхом комбінування по n символів в повідомленні, визначається за формулою
N mn . |
(12) |
Невизначеність, яка припадає на символ первинного (того, що кодується) алфавіту, складеного з рівноймовірних й взаємонезалежних символів
H=log m.H logm
13)
Введемо наступні означення.
Первинний алфавіт складається з m1 символів (якісні ознаки), за допомогою яких записується повідомлення, що передається.
Вторинний алфавіт складається з m2 символів, за допомогою яких повідомлення трансформується в код.
Оскільки інформація є невизначеністю, яка знімається при отриманні повідомлення, то кількість інформації може бути представлена, як добуток загальної кількості повідомлень k на середню ентропію H, яка припадає на одне повідомлення:
I k H біт.
Для випадків рівноймовірних та взаємонезалежних символів первинного алфавіту кількість інформації в k повідомленнях алфавіту з m символів дорівнює
I k log2 m біт.
Імовірнісний підхід до визначення кількості інформації. При описі комбінаторного методу для обчислення кількості інформації та ентропії ми використовували спрощення, за яким всі закінчення досліду вважались рівноймовірними. При реальних дослідженнях така ситуація практично ніколи не зустрічається. (Норма мови приписує кожному лінгвістичному елементу певну ймовірність). Якщо випробування передбачає нерівноймовірні результати, то, очевидно, ентропія такого досліду і отримана від нього кількість інформації будуть відрізнятись від аналогічних величин для досліду з рівноймовірними результатами.
Для нерівноймовірних результатів ентропія на символ алфавіту
m |
|
1 |
m |
(14) |
H pi |
log2 |
|
pi log2 pi біт/символ, |
|
pi |
|
|||
i 1 |
|
i 1 |
|
13
а кількість інформації в повідомленні, що скадається з k нерівноймовірних символів,
m |
(15) |
I k pi log2 pi біт. |
|
i 1 |
|
При розв’язуванні задач, в яких ентропія визначається як сума добутків ймовірностей на їх логарифми, ймовірності завжди представляють групу повних подій, незалежно від того, є ті події безумовними p(ai), умовними p(ai/bi) чи ймовірностями сумісних подій p(ai,bi).
Кількість інформації визначається виключно характеристиками первинного алфавіту, об’єм – характеристиками вторинного алфавіту. Об’єм
інформації |
(к-сть елементарних символів в прийнятому повідомленні) |
Q klсер , де lсер |
– середня довжина кодових слів вторинного алфавіту. |
Для рівномірних кодів (всі комбінації коду мають однакову кількість розрядів): Q=kn, де n – довжина кода (к-сть елементарних посилок в коді).
Згідно (11), об’єм дорівнює кількості інформації , якщо lсер H , тобто у випадку максимального інформаційного навантаження на символ повідомлення. У всіх інших випадках I<Q .
3КОНТРОЛЬНІ ПИТАННЯ
1.Які міри інформації Ви знаєте?
2.Назвіть одиниці виміру ентропії?
3.У чому полягає комбінаторний підхід до визначення кількості інформації?
4.Що таке структурне контекстне обмеження? Наведіть приклади.
5.Поясніть імовірнісний підхід до виміру кількості інформації.
4 ЗАВДАННЯ
Розв’язати завдання відповідно до свого порядкового номеру у списку групи. Завдання отримати у викладача. При оформленні лабораторної роботи дотримуватись вимог, які наведені в методичних вказівках. Оцінювання виконаної лабораторної роботи проводиться згідно кількості правильно розв’язаних завдань з відповідного варіанту. Завдання лабораторної роботи мають три рівня складності. Оцінювання виконання завдань першого рівня в п’ятибальній системі відповідає оцінці “задовільно”, другий рівень – “добре”, третій – “відмінно”. Реалізувати всі завдання за допомогою комп’ютера на мові Сі або С++. Тексти програм роздрукувати та прикріпити до звіту.
Перший рівень
1.Скільки слів з 5 букв, які починаються з тих же трьох букв, що і прізвище студента, можна утворити в українському алфавіті? Використовуючи словник вияснити, скільки з них допущені нормами української мови. Використати результати розв’язування задачі для
14
оцінки величини структурних обмежень (у бітах), які накладаються нормами української мови на ланцюжки з 5 букв, що починаються з послідовності про.
2. На основі словника обчислити відносні частоти появи букв a, e, i, o, u, y
після ланцюжка pr в англійській мові. Обчислити величини інформації Ia , Ie , Ii , Io , Iu , Iy , I~a , I~e , I~i , I~o , I~u , I~y , I .
3.Обчислити величину інформації, яка одержується від досліду з шістьма рівноймовірними результатами. Порівняти отримане значення I0 із значенням I , обчисленим у попередній задачі. Зробити висновок.
4.Символи алфавіту володіють стількома якісними ознаками, скільки букв міститься в прізвищі студента.
а. Яку кількість повідомлень можна отримати, комбінуючи по 3, 4, 5 та 6 елементів в повідомлені?
б. Яка кількість інформації приходиться на один елемент таких повідомлень?
5. В алфавіті три букви A,B,C .
в. Скласти максимальну кількість повідомлень, комбінуючи по три букви в повідомлені.
г. Яку кількість інформації несе одне таке повідомлення?
д. Чому рівна кількість інформації на символ первинного алфавіту?
Другий рівень
1.Скількома способами можна передати положення фігур на шаховій дошці? Чому дорівнює кількість інформації в кожному випадку?
2.Алфавіт складається із букв A,B,C,D . Ймовірності появи букв рівні,
відповідно, |
pA pB 0,25; pC 0,34; pD 0,16. Визначити кількість |
інформації на символ повідомлення, що складений із такого алфавіту.
3.Чому рівна кількість інформації при отриманні 8 повідомлень рівномірного чотиризначного трійкового коду?
4.На ПК постійна інформація зберігається в 32768 стандартних комірках пам’яті. Скількома способами можна передати відомості про те, із якої комірки можна отримати данні постійної інформації? Чому рівна кількість інформації в кожному випадку? Яка геометрична побудова сховища дозволить передавати цю інформацію мінімальною кількістю якісних ознак?
5.Визначити об’єм та кількість інформації в тексті “Ще не вмерла Україна!...” при lсeр 7.
15
6.Чому рівна ентропія системи, яка складається із k взаємонезалежних
підсистем:
е. кожна підсистема складається із n елементів, кожнен із яких з рівною ймовірністю може знаходитися в m станах;
ж. підсистема S1 складається із n1 елементів, підсистема S2
складається із n2 елементів і т. д., підсистема Sk складається із nk елементів,
кожний із яких може з рівною ймовірністю знаходитися в m станах;
з. кожна підсистема складається із різної кількості елементів, які з різною ймовірністю можуть знаходитися в одному зі станів?
7.Визначити ентропію повної багаторівневої ієрархічної системи,
кількість елементів якої на кожному рівні пов’язане залежністю ln Kn ,
де K основа системи, а n номер ієрархічного рівня. При цьому рахується, що корінь графу, що представляє ієрархічне дерево системи, розташований на нульовому рівні. Кожний елемент системи може знаходитися з рівною ймовірністю в m станах.
8.Генератор виробляє чотири частоти f1, f2, f3, f4 . В шифраторі частоти
комбінуються по три частоти в кодовій комбінації.
а. Чому рівна максимальна кількість комбінацій, складених із цих частот?
б. Чому рівна кількість інформації на одне кодове посилання цих кодів?
9.Яку кількість інформації приходиться на букву алфавіту, який складається із 16; 25; 32 букви?
10.Відомо, що одне із рівномірно можливих повідомлень несе 3 біта інформації. Із скількох якісних ознак складається алфавіт, якщо N 8?
11.Кількість символів алфавіту m 5. Визначити кількість інформації на
символ повідомлення, яке складене із цього алфавіту:
а. якщо символи алфавіту зустрічаються із рівними ймовірностями; б. якщо символи алфавіту зустрічаються в повідомленні з ймовірностями p1 0,8; p2 0,15; p3 0,03; p4 0,015; p5 0,005. Наскільки не
завантажені символи в другому випадку?
12.Чому рівна ентропія системи, стан якої описується дискретною величиною з наступними розподілами ймовірностей:
xi |
x1 |
x2 |
x3 |
x4 |
pi |
0,1 |
0,2 |
0,3 |
0,4 |
|
|
|
|
|
16
13.Ймовірність появи події при даній кількості дослідів рівна p ,
ймовірність не появи події q 1 p. При якому значенні q результат досліду буде володіти максимальною невизначеністю?
14.Для приладу Z деталі із комори відділу комплектації доставляє конвеєрна лінія 1, для прибору Y - лінія 2. В комплектуючі вироби приладу Z входять 10 конденсаторів, 5 резисторів та 5 транзисторів; в комплектуючі виробу приладу Y входять 8 конденсаторів, 8 резисторів та 4 транзистора. Визначити невизначеність появи однієї із деталей на лінії. Визначити ентропію в бітах та дітах.
15.Чому рівна кількість інформації в повідомленні, яке передане в двійковому коді п’ятизначної комбінації та двома п’ятизначними комбінаціями, якщо символи алфавіту, який кодуємо, рівноймовірні?
16.Чому рівна кількість інформації при отриманні повідомлення про вихід з ладу одного із восьми станків, отриманих в один і той же час з одного і того ж заводу?
17.Скількома способами можна скласти повідомлення про зміст кількісної частини показників, якщо таблиця має 256 комірок? Кількісні частини показників представлені двозначними числами, а із технічних засобів передачі інформації є тільки стандартний телеграфний апарат, що працює вд війковому коді? Чому рівний середній об’єм та кількість інформації в кожному випадку?
18.Визначити, в якому текстів а-г кількість інформації більша. Чому в тому
чи іншому з приведених текстів інформації більша чи менша?
а. |
“Ра, ра, ра, ра, ра, ра, ра”. |
б. |
“Виконуй правила техніки безпеки! Не стій під краном! Не |
смітити!” |
|
в. |
“Захід... Схід... Південь... Сходить та заходить сонце...” |
19.Чому рівна ймовірність появи комбінації 10110 при передачі п’ятизначних двійкових кодів? Чому рівна середня кількість інформації, яка припадає на одну комбінацію?
20.Повідомлення складені із рівноймовірного алфавіту, що має m 128 якісних ознак. Чому рівна кількість символів в прийнятому повідомлені, якщо відомо, що воно має 42 біти інформації? Чому рівна ентропія цього повідомлення?
Третій рівень
21.Визначити максимум ентропії системи, яка складається із 6 елементів, кожен із яких може бути в одному із чотирьох станів рівноймовірно.
17

22.Фізична система може знаходитися в одному із чотирьох станів. Стани системи задані через ймовірності наступним чином:
A a1 |
a2 |
a3 a4 |
0,25 0,25 0,3 0,2
Визначити ентропію такої системи.
23.Визначити ентропію джерела повідомлень, якщо статистика розподілу ймовірностей появи символів на виході джерела повідомлень представлена наступною схемою:
A |
a1 |
a2 |
a3 |
a4 |
a5 |
a6 |
a7 |
a8 |
a9 |
a10 |
|
0,35 |
0,035 |
0,07 |
0,15 |
0,07 |
0,07 |
0,14 |
0,035 |
0,01 |
0,07 |
24. В повідомлені, складеному із 5 якісних ознак, які використовуються з
різною |
частотою, |
ймовірності |
їх |
появи рівні |
відповідно: |
|
p1 0,7; |
p2 0,2; p3 |
0,08; |
p4 0,015; |
p5 |
0,005. Всього в |
повідомлені |
прийнято 20 знаків. Визначити кількість інформації в усьому повідомлені. Якою буде кількість інформації в даному повідомлені, якщо всі ознаки будуть мати рівну ймовірність?
25.Визначити об’єм інформації при передачі слова “АБАБАГАЛАМАГА” в 5 (7) повідомленнях. Чому рівна кількість інформації в прийнятому повідомлені, якщо завади в каналі зв’язку були відсутні?
26.Визначити кількість інформації у випадковому тексті:
а. якщо символи алфавіту рівноймовірні та взаємонезалежні; б. якщо символи алфавіту не рівноймовірні.
Вякому випадку кількість інформації може співпасти з об’ємом?
27.Визначити таблицю розподілу ймовірностей появи букв у випадковому українському тексті. Визначити ентропію української мови.
28.Визначити об’єм інформації при передачі документа, який має 20 рядків текстової та цифрової інформації, якщо передача ведеться при lсeр 7, а
кожний рядок має 30 знаків (враховуючи пробіл).
29.На ПК з периферійного пристрою необхідно передати визначену економічну інформацію, яка оформлена в таблицях з різними показниками. Визначити максимально можливий об’єм інформації, яким може бути завантажений канал зв’язку, якщо таблиць 100, вони мають 64 клітинки, цифри, які знаходяться в таблицях, не більше трьохзначних, а код, в якому передаються повідомлення, п’ятизначний двійковий.
30.Визначити ентропію системи, яка складається із двох підсистем. Перша підсистема складається із трьох елементів, кожна із яких може
знаходитися в двох станах з ймовірностями p1 0,6; |
p2 0,4. Друга |
18
підсистема складається із двох елементів, кожний із яких може
знаходитися в трьох станах із імовірностями p1 0,1; |
p2 0,4; |
p3 0,5. |
31.Визначити ентропію ієрархічної системи, заданої графом (рис. 2), якщо кожний елемент системи (вузол графу) може з рівною ймовірністю знаходитися в трьох станах.
Рис.2
32.Визначити ентропію ієрархічної системи, заданої графом (рис. 3), якщо кожний елемент системи (вузол графу) може з рівною ймовірністю знаходитися в чотирьох станах.
Рис.3
33.Скласти рівномірний двійковий код для передачі слів деякої умовної мови, алфавіт якої складається із 20 букв. Чому рівний об’єм інформації при передачі семибуквеного слова в цьому алфавіті?
34.Чому дорівнює кількість інформації про пошкодження n транзисторів після температурних дослідженнях партії транзисторів із N штук, які випущені в один і той же день, одним і тим же заводом?
35.Чому дорівнює ентропія українського алфавіту при дослідженні ймовірності появи букв в українських текстах на конкретному прикладі?
36.Визначити ентропію фізичної системи B , яка може знаходитися в одному із 10 станів. Ймовірності станів системи B :
B b1 |
b2 |
b3 |
b4 |
b5 |
b6 |
b7 |
b8 |
b9 |
b10 |
0,01 0,07 0,035 0,035 0,35 0,07 0,14 0,07 0,15 0,07
19
37.Визначити об’єм та кількість інформації в прийнятому тексті: “При описі комбінаторного методу для обчислення кількості інформації та ентропії ми використовували спрощення, за яким всі закінчення досліду вважались рівноймовірними.”.
38.Визначити об’єм та кількість інформації при наступних умовах:
аалфавіт A1, A2,...,A8 рівноймовірний, символи вторинного алфавіту
комбінуються в рівномірні коди, кількість якісних ознак, із яких
комбінуються вторинні повідомлення, m2 2; |
|
|
|
|||
б первинний алфавіт має 8 букв, |
m1 8, |
ймовірності |
появи |
букв |
||
первинного алфавіту |
на |
виході джерела |
повідомлень відповідно |
рівні: |
||
p1 0,1; p2 0,15; p3 p4 |
p5 |
p6 0,05; p7 0,25; p8 0.3; |
коди |
вторинного |
||
алфавіту рівномірні, m2 2; |
|
|
|
|
||
в первинний алфавіт складається із 5 |
букв, m1 5, які зустрічаються в |
|||||
текстах з рівними ймовірностями, вторинні повідомлення складені із рівномірних кодів з кількістю якісних ознак m2 2;
г первинний алфавіт рівноймовірний, m1 8, а вторинний алфавіт побудований із кодів, які можуть знайти одну помилку, коди вторинного алфавіту – рівної довжини.
39.Довжина коду у вторинному алфавіті рівна 10 символам. Кількість інформації на символ первинного алфавіту рівна 2,5 біт/символ. Яку
кількість інформації ми отримаємо, якщо приймемо: а 7 символів вторинного алфавіту?
б17 символів вторинного алфавіту?
40.Визначити ентропію трьохрівневої симетричної ієрархічної системи, основа якої рівна 2, якщо:
д на першому рівні один елемент системи з рівною ймовірністю може знаходитися в двох станах, другий – з рівною ймовірністю може знаходитися
втрьох станах;
ена другому рівні кожний елемент системи може знаходитися в двох станах з ймовірностями відповідно: I – 0,2 та 0,8; II – 0,3 та 0,7; III – 0,4 та 0,6; IV – 0,38 та 0,62;
ж на третьому ієрархічному рівні системи чотири елемента системи з рівною ймовірністю можуть знаходитися в трьох станах, два елементи – в двох станах і два елементи – в чотирьох станах відповідно. Чи залежить загальна ентропія системи від того, які саме (перші чи останні) елементи третього рівня можуть з рівною ймовірністю знаходитися в чотирьох станах?
20