

1.2 Клас FreqDist для простих статистичних досліджень
Для автоматичного визначення слів, які є найбільш інформативними для текстів певного жанру або певної тематики спочатку інтуітивно виникає думка побудувати частотний список або частотний розподіл. Частотний розподіл вказує на частоту з якою в тексті зустрічається кожне зі слів. Такий частотний список називають розподілом тому, що він вказує яким чином загальна кількість слів розподіляється між словниковими статями (оригінальні слова) в тексті. Враховуючи що побудова частотних розподілів часто необхідна при обробці природної мови в NLTK реалізовано окремий клас FreqDist в модулі nltk.probability . Застосуємо цей клас для знаходження 50 найчастотніших слів в тексті Moby Dick.
>>> fdist1 = FreqDist(text1) #1
>>> fdist1 #2
<FreqDist with 260819 outcomes>
>>> vocabulary1 = fdist1.keys() #3
>>> vocabulary1[:50] #4
[',', 'the', '.', 'of', 'and', 'a', 'to', ';', 'in', 'that', "'", '-',
'his', 'it', 'I', 's', 'is', 'he', 'with', 'was', 'as', '"', 'all', 'for',
'this', '!', 'at', 'by', 'but', 'not', '--', 'him', 'from', 'be', 'on',
'so', 'whale', 'one', 'you', 'had', 'have', 'there', 'But', 'or', 'were',
'now', 'which', '?', 'me', 'like']
>>> fdist1['whale']
906
>>>
При першому виклику FreqDist назва текста вказується як аргумент класа #1. Можна дізнатися загальну кількість слів, які були підраховані #2. Вираз keys() дозволяє встановити список оригінальних слів текста #3 і можна переглянути перші 50 з них #4. Серед цих 50 слів тільки одне дає певну інформацію про текст (whale) і це слово зустрічається в тексті 906 раз. Всі інші слова є не інформативними, або службовими. Для визначення, яку частину тексту займають ці службові слова знайдемо їх сумарну частоту побудувавши графік (Рис.1.) за допомогою fdist1.plot(50, cumulative=True)
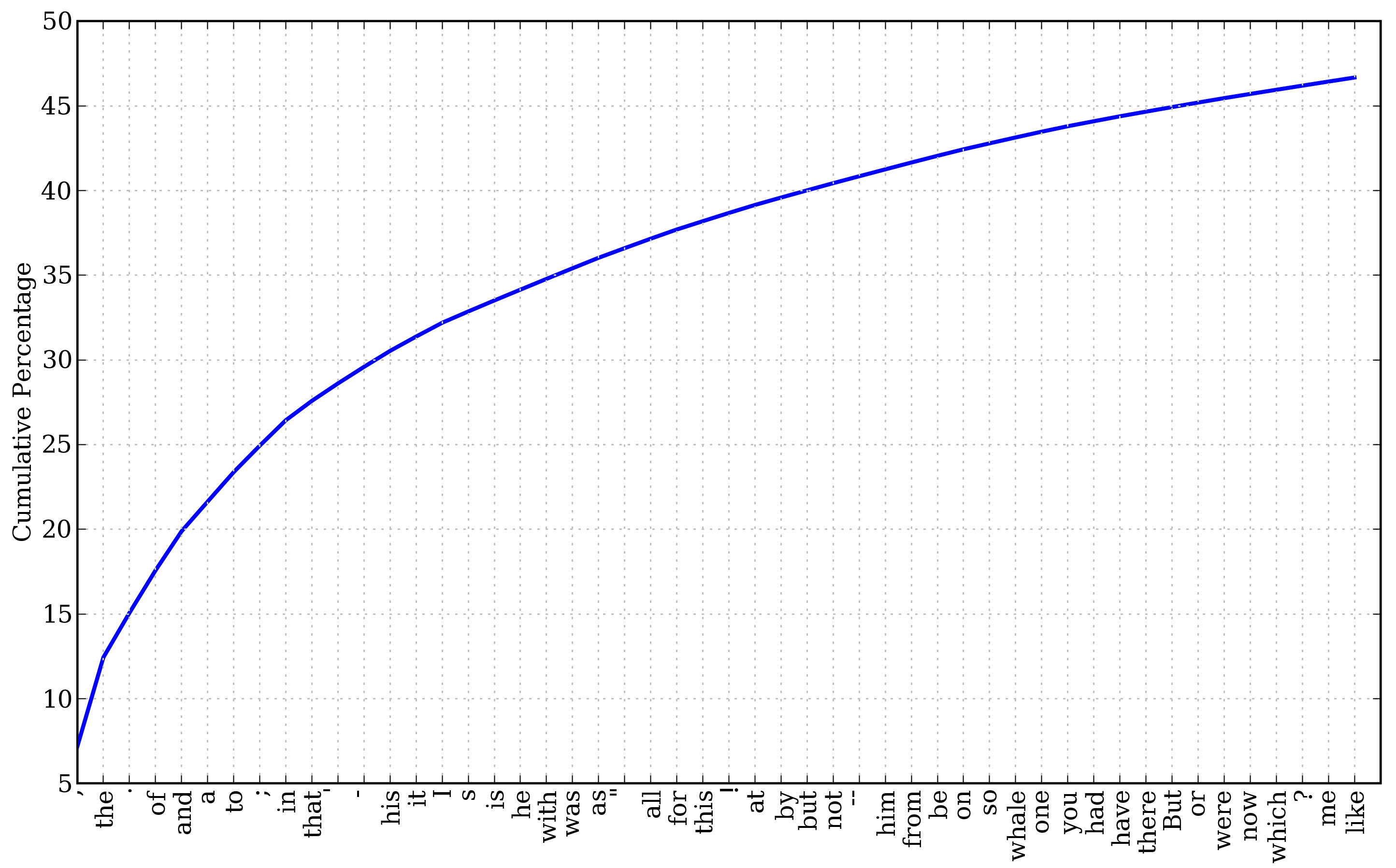
Рис.1. Частотний розподіл (з накопиченням ) 50 слів тексту Moby Dick.
Якщо найбільш частотні слова не дають уяви про текст то спробуємо за допомогою fdist1.hapaxes() побудувати список слів які зустрічаються тільки один раз. В даному тексті таких 9002 слова і серед них є такі слова як: exicographer, cetological, contraband, expostulations . Деякі слова без контексту тяжко зрозуміти і вони також не дають уяву про текст.
1.2.1.Вибір слів з текста.
Спробуємо знайти найдовші слова сподіваючись що вони є більш інформативними:
>>> V = set(text1)
>>> long_words = [w for w in V if len(w) > 15]
>>> sorted(long_words)
['CIRCUMNAVIGATION', 'Physiognomically', 'apprehensiveness', 'cannibalistically',
'characteristically', 'circumnavigating', 'circumnavigation', 'circumnavigations',
'comprehensiveness', 'hermaphroditical', 'indiscriminately', 'indispensableness',
'irresistibleness', 'physiognomically', 'preternaturalness', 'responsibilities',
'simultaneousness', 'subterraneousness', 'supernaturalness', 'superstitiousness',
'uncomfortableness', 'uncompromisedness', 'undiscriminating', 'uninterpenetratingly']
>>>
Для кожного слова зі списку V здійснюється перевірка чи його довжина є більша ніж 15 символів, всі інні слова ігноруються.
Виконати самостійно: Виконати попередній приклад для інших текстів зміннючи довжину слів. Результати порівняти і пояснити.
Повертаючись до задачі пошуку характерних для текста слів зазначимо, що довгі слова в тексті№4 constitutionally, transcontinentalвказують на його державницький характер а довгі слова тексту№5 boooooooooooglyyyyyy and yuuuuuuuuuuuummmmmmmmmmmm вказують на його неформальний характер. Але довгі слова часто зустрічаються в тексті тільки один раз і тому потрібно знайти ті довгі слова які зустрічаються в тексті з певною частотою. Одночасно ми уникаємо врахування коротких не нформативних слів а також уникаємо врахування довгих але рідкісних слів. В наступному прикладі показано, як з текста №5 вибираються слова які мають довжину більше ніж 7 символів і зустрічаються в тесті більше ніж 7 разів.
>>> fdist5 = FreqDist(text5)
>>> sorted([w for w in set(text5) if len(w) > 7 and fdist5[w] > 7])
['#14-19teens', '#talkcity_adults', '((((((((((', '........', 'Question',
'actually', 'anything', 'computer', 'cute.-ass', 'everyone', 'football',
'innocent', 'listening', 'remember', 'seriously', 'something', 'together',
'tomorrow', 'watching']
>>>
1.2.2.Колокації та біграми.
Колокація це словосполучення яке зустрічається дуже часто. red wine–це колокація а the wine –ні . Характерною рисою колокацій є те що вони є стійкі до заміни одного зі слів на інше подібне за змістом (maroon wine). Для того щоб побудувати колокації спочатку потрібно побудувати на основі тексту пари слів, або біграми. Для цього можна використати функцію bigrams():
>>> bigrams(['more', 'is', 'said', 'than', 'done'])
[('more', 'is'), ('is', 'said'), ('said', 'than'), ('than', 'done')]
>>>
Так як колокації це частотні біграми з врахуванням випадків рідкісних слів, то нам потрібно знайти такі біграми частота яких вища ніж частоти слів з яких він складається. Функція collocations() реалізує такі дії.
>>> text4.collocations()
Building collocations list
United States; fellow citizens; years ago; Federal Government; General
Government; American people; Vice President; Almighty God; Fellow
citizens; Chief Magistrate; Chief Justice; God bless; Indian tribes;
public debt; foreign nations; political parties; State governments;
National Government; United Nations; public money
>>> text8.collocations()
Building collocations list
medium build; social drinker; quiet nights; long term; age open;
financially secure; fun times; similar interests; Age open; poss
rship; single mum; permanent relationship; slim build; seeks lady;
Late 30s; Photo pls; Vibrant personality; European background; ASIAN
LADY; country drives
>>>
Колокації є характерними для текстів різних тематик та жанрів.
Крім підрахунку окремих слів цікаво також здійснити підрахунок довжин слів в тексті використовуючи FreqDist.
>>> [len(w) for w in text1] #1
[1, 4, 4, 2, 6, 8, 4, 1, 9, 1, 1, 8, 2, 1, 4, 11, 5, 2, 1, 7, 6, 1, 3, 4, 5, 2, ...]
>>> fdist = FreqDist([len(w) for w in text1]) #2
>>> fdist #3
<FreqDist with 260819 outcomes>
>>> fdist.keys()
[3, 1, 4, 2, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 20]
>>>
Спочатку будуємо список довжин слів в тексті №1 #1. FreqDist здійснює підрахунок кількості вживань слів різної довжини #2. В результаті #3 отримуємо розподіл в якому довжині слова відповідає кількість таких слів в тексті. Бачимо, що в тексті зустрічаються слова різної довжини від 1 до 20 символів. Частоту різних довжин слів можна переглянути:
>>> fdist.items()
[(3, 50223), (1, 47933), (4, 42345), (2, 38513), (5, 26597), (6, 17111), (7, 14399),
(8, 9966), (9, 6428), (10, 3528), (11, 1873), (12, 1053), (13, 567), (14, 177),
(15, 70), (16, 22), (17, 12), (18, 1), (20, 1)]
>>> fdist.max()
3
>>> fdist[3]
50223
>>> fdist.freq(3)
0.19255882431878046
>>>
Найчастіше зустрічаються слова з довжиною 3 символа і такі слова становлять близько 20% всього тексту. Можна здійснити аналіз довжин слів для текстів різних жанрів, авторів та мов.