

Сжатие графических данных
Для хранения графических изображений, представленных в растровой форме, обычно требуются очень большие объемы памяти. Для уменьшения физического объема блоков графических данных применяются специальные методы сжатия или кодирования данных. Кодирование данных – понятие более широкое, чем просто сжатие; т.е. сжатие – это один из типов кодирования, применяемый для уменьшения объема данных. Другие типы кодирования включают шифрование (криптографию) и различные специальные методы. Практически каждый формат графического файла применяет какой-нибудь метод сжатия.
Сжатие растровых, векторных и метафайловых данных осуществляется по-разному. В растровых файлах сжимаются только данные изображения. Заголовок и все остальные данные (например, таблица цветов), занимающие незначительную часть файла, остаются несжатыми. Векторные файлы сжимаются редко, так как в них хранятся только математические описания фрагментов изображения, а не сами данные изображения, поэтому сжатие даст очень незначительный эффект. Кроме того, векторные файлы читаются с небольшой скоростью, а при добавлении распаковки – этот процесс становится еще более медленным.
Существует множество методов сжатия. Они могут быть разделены на две категории: сжатие всего файла (иногда эту процедура называется упаковкой пикселей) и «внутренние» методы сжатия, работающие с самой структурой файла.
При сжатии всего файла без учета его внутренней структуры используется «упаковка» пикселей (форматы сжатия ZIP, ARC), что позволяет экономить память. Например, удобно хранить каждый пиксель в отдельном байте памяти, поскольку байт является наименьшим адресуемым элементом памяти в большинстве компьютерных систем. Если данные изображения требуют лишь 4 бита на пиксель, то при этом половина каждого байта не используется. Применяя
33
упаковку пикселей, т.е. записывая по два 4-битовых пикселя в один байт, можно сократить объем требуемой памяти наполовину. Однако полученный таким образом новый файл нельзя использовать до тех пор, пока он не будет восстановлен (распакован). При больших объемах графических файлов это приводит к потере времени. Поэтому сжатие всего файла применяется обычно для его длительного хранения или пересылки, но не для оперативной работы. Фактически, эта процедура не является методом сжатия графических данных.
Практически все графические системы поддерживают форматы, в которых используются структурные методы сжатия, учитывающие структуру файла. Наиболее распространенными алгоритмами сжатия являются:
-групповое кодирование (RLE - Run Length Encoding) – один из наиболее распространенных алгоритмов сжатия, поддерживаемый такими растровыми форматами как BMP, TIFF, PCX;
-алгоритм LZW (Lempel-Ziv-Welch) применяется в форматах GIF и TIFF,
включен в стандарт сжатия данных для модемов v.42bis и является частью
PostScript level 2;
-кодирование CCITT (кодирование по алгоритму Хаффмена). Это форма сжатия данных применяется при передаче изображений по телефонным каналам и сетям передачи данных;
-алгоритм JPEG (Joint Photographic Experts Group) разработан группой экспертов ISO и представляет набор методов сжатия, используемых, в основном, для обработки изображений с плавным переходом тона и для мультимедиа. Базовая реализация JPEG применяет схему кодирования по алгоритму дискретных косинус - преобразований (DCT);
-алгоритм JBIG (Joint Bi-level Image Experts Group - Объединенная груп-
па экспертов по двухуровневым изображениям) представляет собой метод сжатия данных двухуровневых (двухцветных) изображений, который должен заменить устаревшие и менее эффективные алгоритмы.
34
Фрактальное сжатие – это математический процесс, используемый для кодирования растров, содержащих реальное изображение, в совокупность математических данных, которые описывают фрактальные (т.е. похожие, повторяющиеся) свойства изображения.
Большинство распространенных алгоритмов сжатия, таких, например, как RLE, LZW, CCITT, являются методами сжатия без потерь, т.е. в процессе кодирования никакие данные не отбрасываются. Восстановленное изображение, сжатое с применением метода без потерь, полностью идентично оригинальному несжатому изображению. Такие алгоритмы очень эффективны для изображений, в которых есть большие области однотонной закраски или повторяющихся пиксельных узоров. Однако для растровых изображений фотографического качества, где каждый пиксель отличается от других, применение методов сжатия без потерь может дать обратный результат – полученный новый файл будет больше исходного (так называемое «отрицательное» сжатие).
Методы сжатия с потерями (например, JPEG) отбрасывают в процессе кодирования малополезные данные, что позволяет достичь намного большей степени сжатия. При этом в растровом рисунке, который содержит множество слегка отличающихся друг от друга пикселей, большие области заменяются пикселями одного цвета или пиксельным узором, имитирующим вид исходной области. Такие методы основаны на определенных особенностях восприятия человеком изображений. Глаз человека более чувствителен к изменению яркости, чем к незначительным изменениям цвета. В связи с этим система цветов RGB, наиболее часто используемая в графических форматах, преобразуется в систему, в которой информация о яркости и цвете пикселей записывается отдельно (системы HSB или HSL). Качество изображения, которое получается при использовании такого подхода, напрямую связано с особенностями исходного изображения и степени его сжатия.
Групповое кодирование (RLE). Алгоритмы RLE позволяют сжимать данные любых типов, невзирая на содержащуюся в них информацию. Однако,
35
сама информация влияет на полноту сжатия. Большинство этих алгоритмов не позволяют достигать высокой степени сжатия, характерной для более совершенных алгоритмов, однако групповое кодирование выполняется достаточно легко и быстро. RLE уменьшает физический размер повторяющихся строк символов (пикселей). Такие повторяющиеся строки, называемые группами, обычно кодируются в двух байтах. Первый байт определяет количество повторяющихся пикселей в группе и называется счетчиком группы. На практике закодированная группа может содержать до 256 символов. Второй байт содержит значение символа в группе, которое находится в диапазоне от 0 до 255 и называется значением группы. Например, несжатая символьная группа из 15 символов «А» обычно занимает 15 байтов. После RLE-сжатия та же строка займет всего два байта –15А.
Код, сгенерированный для представления символьной строки, называется RLE-пакетом. Новый пакет генерируется каждый раз, когда изменяется группа или когда количество символов в группе превышает максимальное значение счетчика. Пусть, например, 15-символьная строка содержит четыре различных символьных группы – «AAAAAAbbbXXXXXt». Применив групповое кодирование, можно сжать ее в четыре 2-байтовых пакета - 6A3b5Xlt, т.е. исходная 15байтовая строка станет занимать теперь только 8 байтов, а степень сжатия составит примерно 2:1. Однако, если эта строка будет состоять из 15 различных символов, то после кодирования ее длина удвоится («отрицательное» сжатие).
Групповое кодирование само по себе не является форматом файла, это лишь метод сжатия в некоторых графических форматах. Одни форматы применяют алгоритмы RLE по умолчанию во всех файлах, другие предоставляют возможность выбора. Существует множество вариантов RLE, все они достаточно просто реализуются, но эффективность сжатия зависит от типа изображения, подлежащего кодированию. Лучше всего сжимаются изображения, которые содержат ограниченное количество цветов и большие области однотонной закраски; хуже или совсем не сжимаются фотореалистические изображения, содержа-
36
щие большое количество различных цветов, так как в них нет длинных строк одинаковых пикселей, которые можно сжать.
LZW-сжатие. Алгоритмы сжатия, построенные по схеме Лемпела – Зива
–Велча являются одними из самых распространенных в компьютерной графике. Они относятся к так называемым алгоритмам подстановок или базирующимся на словарях. Этот алгоритм из данных входного потока строит словарь данных (часто его называют также переводной таблицей, таблицей строк, или таблицей кодов). Образцы данных (подстроки) идентифицируются в потоке данных и сопоставляются с записями в словаре. Если строка не представлена в словаре, то на базе содержащихся в ней данных создается и записывается в словарь кодовая фраза, записывается в выходной поток сжатых данных. Если эта подстрока встречается во входном потоке повторно, соответствующая ей фраза читается из словаря и записывается в выходной поток. Поскольку такая фраза имеет меньший физический размер, чем строка, которую она представляет, происходит сжатие данных.
Декодирование LZW-данных происходит в порядке, обратном кодированию. Программа-дешифратор читает код из потока закодированных данных и, если этого кода еще нет в словаре данных, добавляет его туда. Затем этот код переводится в строку, которую он представляет, и записывается в выходной поток несжатых данных.
Практически процедура кодирования в простейшем случае сводится к поиску в растровом изображении повторяющихся комбинаций пикселей (пиксельных узоров, шаблонов), кодировании их и записи в таблицу кодов, где сохраняются найденные повторяющиеся пиксельные узоры.
Например, пусть во входном потоке данных имеется последовательность символов «ABABAAACAAAAD». Предположим для простоты, что каждый символ кодируется двумя битами. Тогда начальная кодовая таблица выглядит так: A:00, B:01, C:10, D:11.
37
Алгоритм LZW ищет самую длинную последовательность, которую он способен распознать, а в случае обнаружения неизвестной последовательности закодировать ее и вставить в таблицу. В данном случае идентифицируется первый символ «А», затем проверяется последовательность «АВ». В случае невозможности идентифицировать ее, формируется новый код для той величины, которая опознана (А:000), и добавляется новый элемент таблицы для нераспознанной последовательности АВ. Кодовая таблица теперь становится следую-
щей: А:000, В:001, С:010, D:011, АВ:100.
Теперь и шифратор, и дешифратор могут распознать любые следующие экземпляры последовательности АВ. Таким образом, трехбитный код заменяет два двухбитных. В данном случае полученный выигрыш невелик, но естественно, рассмотренную процедуру можно продолжить.
Обычно методом LZW сжимаются файлы до 1/3 или 1/4 их первоначального размера. Насыщенные изображения, содержащие большие блоки однотонной окраски или повторяющиеся цветные узоры, могут сжиматься еще больше
– до 1/10 их первоначального размера. Вместе с тем отсканированные фотографии или аналогичные изображения сжатию методом LZW подаются плохо. Отсутствие повторяющихся значений пикселей или их комбинаций делает процесс сжатия для таких файлов трудным и редко успешным (как и в методе
RLE).
Сжатие методом JPEG. В отличие от других методов сжатия JPEG не является одним алгоритмом, а представляет набор методов, пригодных для удовлетворения различных нужд пользователя. Схема JPEG была специально разработана для сжатия цветных и полутоновых многоградационных изображений (фотографий, телевизионных заставок, другой сложной графики), в которых различия между соседними пикселями незначительны . При этом анимация, черно-белые иллюстрации и документы, а также типичная векторная графика сжимаются плохо. Это объясняется тем, что JPEG сжимает с потерями, т.е. отбрасывается информация, отсутствие которой трудно заметить визуально.
38
Как уже отмечалось, небольшие изменения цвета плохо распознаются глазом человека, а небольшие изменения интенсивности (светлее или темнее) – лучше. Исходя из этого, алгоритмы JPEG стремятся к бережному обращению с полутоновой частью изображения, но более свободно обращаются с цветом. Таким образом, допустимая степень сжатия зависит от содержимого исходного изображения и от требований к качеству его воспроизведения. Например, степень сжатия изображения с фотографическим качеством может составить 25:1 без заметной его потери.
Пользователь может регулировать качество кодировщика JPEG, используя параметр, называемый установкой качества или Q-фактором. Различные реализации данного метода имеют разные диапазоны Q-фактора, но типичным считается диапазон 1 – 100. При значении фактора, равном 1, создается сжатое изображение самого маленького размера, но плохого качества; при значении фактора, равном 100, можно получить сжатое изображение большего размера, но и лучшего качества.
Алгоритмы JPEG основаны на схеме кодирования, базирующейся на дискретном косинус-преобразовании (DCT). Процесс сжатия по схеме JPEG делится на несколько этапов, которые приведены на рисунке 1.4. Такие преобразования графической информации осуществляются системой при каждом обращении к соответствующему файлу.
Принципиально алгоритм JPEG способен кодировать изображения, основанные на любом типе цветового пространства, так как кодирует каждый компонент цветовой модели отдельно, что обеспечивает его независимость от любой цветовой системы. Практически обычно применяется система цветов YUV, где Y- компонента яркости, U и V – характеристики цвета. Преобразование обычно применяемой системы RGB в YUV позволяет программе уделять больше внимания данным о яркости (Y), чем о цвете (U,V). Для этого компоненты Y, U, V выбираются с разной частотой, причем количество пикселей для каналов цветности относительно уменьшается. Этот процесс называют иногда под-
39
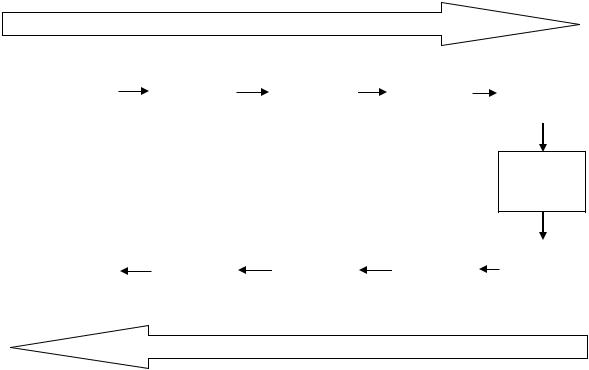
выборкой. Например, метод выборки YUV411 на каждую подвыборку цвета делает четыре выборки данных о яркости, а метод YUV422 четыре выборки данных о яркости осуществляет для каждых двух выборок данных о цвете.
Сжатие методом JPEG
Преобразование |
|
Субдискре- |
|
Прямые |
|
Квантова- |
|
|
|
|
|
|
Кодирова- |
||||
в иное цветовое |
|
|
DCT |
|
|
|||
пространство |
|
тизация |
|
|
|
ние |
|
ние |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Изображение, сжатое
JPEG
Восстановление |
|
Обратная |
|
Обратные |
|
Декванто- |
|
Декодиро- |
|
субдискре- |
|
|
|
||||
цветов |
|
|
DCT |
|
вание |
|
вание |
|
|
тизация |
|
|
|
||||
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Распаковка сжатого изображения
Рисунок 1.4 – Сжатие графических данных методом JPEG
Выборка данных сразу уменьшает размер исходного файла изображения. Например, при использовании метода YUV411 для прямоугольника 2x2 пикселя получается четыре выборки Y и по одной – на U и V, т.е. всего 6 значений (вместо 12 в случае, если каждый компонент был бы представлен с полным разрешением). Это уже позволяет уменьшить в два раза размер получаемого файла практически без ощутимых для восприятия потерь качества.
JPEG вычисляет изменение значений пикселей (т.е. как быстро меняются их яркость и цвет) в форме изменения частот с помощью дискретного косинусного преобразования (Discrete Cosine Transform – DCT), рассмотрение которого выходит за рамки данного пособия. DCT применяется к каждому блоку размером 8x8 пикселей, преобразовывая пространственное представление изображе-
40
ния в специальную частотную карту. После вычисления значений изменения эти величины усредняются в соответствии со шкалой относительной важности. Изменения частоты, которые меньше влияют на общий вид изображения, усредняются больше других значений. На этом этапе большинством JPEG-коди- ровщиков можно управлять с помощью установки качества. Окончательные усредненные данные сжимаются с целью увеличения степени сжатия одним из алгоритмов, рекомендованным стандартом JPEG.
Рассмотренный алгоритм применяется для компрессии неподвижных изображений; в настоящее время он адаптирован и для видео. Алгоритм MJPEG (Motion JPEG) каждый кадр видеопоследовательности сжимает по методу
JPEG. Алгоритм MPEG (Motion Picture Expert Group) сжимает цифровое видео до 150 раз. В цифровой поток также добавляется синхронизированный стереозвук. Как и в MJPEG, в MPEG-сжатии используется алгоритм JPEG, но при формировании потока данных предполагается, что два соседних кадра в видеопоследовательности мало различаются. В потоке данных, сжатых по технологии MPEG, имеются три типа изображений:
-Intra (I-frame, опорные) – это изображения, сжатые методом JPEG, используемые для восстановления остальных изображений. В типичном случае задаются два раза в секунду со сжатием 12:1;
-Predicted (P-frame, предсказываемые) – изображения, содержащие только отличия текущего изображения от предыдущего (Intra или Predicted) и предполагают высокий уровень сжатия;
-Bidirectional (B-frame, двунаправленные) – содержат отличие текущего изображения от предыдущего и последующего и предполагают максимальный уровень компрессии. При восстановлении результат усредняется.
Фрактальное сжатие изображений.
Фрактальное кодирование – это математический процесс, применяемый для кодирования растров, которые содержат реальное изображение в совокупности математических данных, описывающих фрактальные свойства изображе-
41
ния. Фрактальное кодирование основано на том предположении, что все естественные и большинство искусственных объектов содержат избыточную информацию в виде почти одинаковых, повторяющихся рисунков, которые называются фракталами.
Фрактал – это структура, которая состоит из подобных форм и рисунков, которые: выглядят почти идентичными по форме при любом размере и встречаются в различных структурах. Термин фрактал впервые применил Б. Мандельброт, который также обнаружил, что фракталы можно описывать и впоследствии воссоздавать с помощью простых алгоритмов и незначительного количества данных. Алгоритмы воплощаются в систему математических уравнений, называемых фрактальными кодами, которые описывают данную поверхность через ее фрактальные свойства. Эти уравнения можно затем использовать для воссоздания изображения. Указанная процедура похожа на процедуры, применяемые в векторной графике, где также оперируют математическими описаниями объектов, а не их реальными изображениями. Существенное различие между векторной и фрактальной графикой состоит в том, что фрактальные описания выводятся из фактических рисунков, присутствующих в реальных объектах, тогда как векторные объекты – это чисто искусственные структуры, которые сами по себе фрактальных рисунков не содержат.
Фрактальное кодирование широко используется для преобразования растровых изображений во фрактальные коды. Фрактальное декодирование представляет собой обратный процесс, в котором система фрактальных кодов преобразуется в растр.
Процесс кодирования требует исключительно большого объема вычислений. Для поиска фрактальных рисунков в изображении необходимы миллионы (часто даже миллиарды) итераций. В зависимости от особенностей входных данных, качества изображения и других факторов процесс сжатия одного изображения может занять от нескольких секунд до нескольких часов. Декодирование фрактального изображения – процесс более простой, так как вся трудо-
42
емкая работа была выполнена при поиске фракталов во время кодирования. В процессе декодирования нужно лишь интерпретировать фрактальные коды, преобразовав их в растровое изображение.
Размер физических данных, используемых для записи фрактальных кодов, значительно меньше размера исходных растровых данных (иногда до 100 раз). Именно этот аспект фрактальной технологии, называемый фрактальным сжатием, вызвал наибольший интерес в сфере формирования и воспроизведения компьютерных изображений. Фрактальное сжатие сопровождается потерями, так как процесс поиска фракталов не предусматривает нахождения точного их соответствия. Вместо этого ищется «наилучшее» их соответствие на основании параметров сжатия (времени кодирования, качества изображения и др.). Процессом кодирования можно управлять, добиваясь такого качества изображения, когда потери данных, визуально, практически незаметны.
Фрактальное сжатие отличается от других методов сжатия с потерями, таких как JPEG. Метод JPEG обеспечивает сжатие, отбрасывая те данные изображения, которые практически не влияют на его качество при восприятии человеческим глазом. Полученные в результате данные далее обрабатываются с помощью метода сжатия без потерь. Для достижения высокой степени сжатия необходимо отбрасывать больше данных, что приводит к ухудшению качества изображения и другим дефектам.
Фрактальные изображения не строятся на базе растра, а кодирование не соизмеряется с физиологическими характеристиками человеческого глаза. Наоборот, растровые данные отбрасываются, если необходимо создать наилучший фрактальный рисунок. Высокая степень сжатия достигается путем выполнения большого объема преобразований, что может ухудшить качество изображения, однако благодаря фрактальным компонентам искажения не столь заметны. На степень фрактального сжатия заметное влияние оказывает также содержимое и разрешение исходного растра. Изображения с высоким содержанием фрактальных элементов (например, портреты, пейзажи и сложные текстуры) характери-
43