

1.Типы данных. Переменные целого типа. Формат вывода целых значений. Разделы1.1,1.4,1.8.
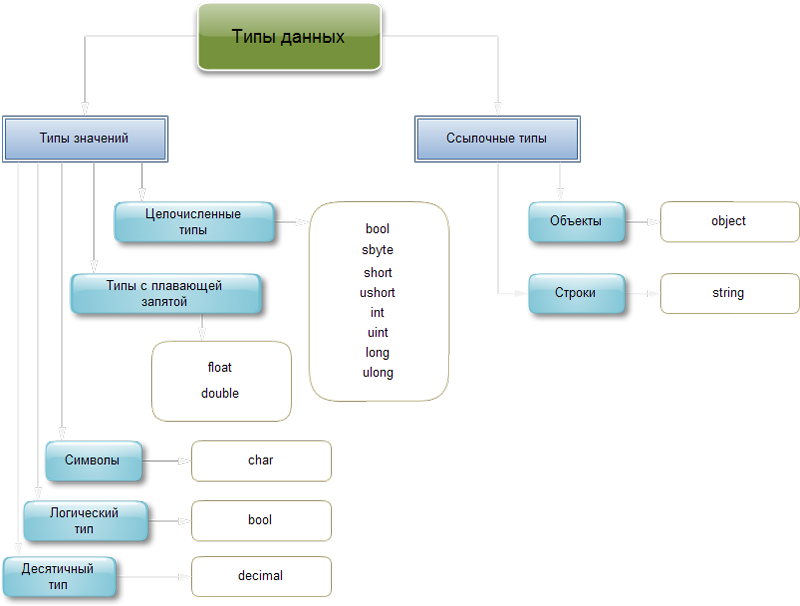
Переменные целого типа
bool- логический тип. Может принимать либо true, либо fasle. Переменная, объявленная этим типом будет иметь по-умолчанию true
byte –(0-255) .1 байт= 8 битам. 2^8=256. Есть 0, поэтому предельное число будет 255. Этот тип применяется тогда, когда нужно хранить небольшое значение, например, возраст. Больше 255 знаков нельзя.Тип byte –положительный(беззнаковый)
sbyte – это тот же byte, но только переменная этого типа может иметь отрицательное значение. (от -128 до 127)
int – (целые числа)
short – короткое целое число.
ushort – тоже самое, только без знака.
long –длинное целое, предназначенное для хранения больших чисел.(.> decimal) Запомните важную вещь – компилятору нужно указывать принадлежность переменной к данному типу суффиксом L или l. Например, long a=78485994L . Иначе компилятор посчитает переменную типом int.
ulong –положительные числа long
uint – положительные числа int
Вывод данных осуществляется с использованием метода Write-Line(или Write)(класса следующего выполнения WriteLine производится перевод строки и последующий вывод происходит в новую строку. После выполнения Write перевода строки не происходит. Вывод будет продолжен в текущую строку.
Вывод может быть организован с использованием формата.В этом случае оператор вывода имеет следующий вид:
Квадратные скобки означают необязательный параметр, т.е. строка формата может отсутсвовать , но только в том случае ,если в списке вывода один элемент. При выводе нескольких элементов использование формата обязательно.
В списке вывода перечисляются через запятую элементы списка. В качестве элементов списка вывода в общем случае могут фигурировать имена переменных , константы или выражения ,которые перед выводом вычисляются.
В строке формата для каждого выводимого значения в фигурных скобках указывается:
-номер выводимого элемента n(нумерация начинается с 0);порядок вывода может не совпадать с порядком следования элементов в списке вывода;
-количество позиций m, в которые должно быть выведено значение элемента списка вывода(необязательный параметр)
-код форматирования k (необязательный параметр)
Для данных типа int используется код d(или D).
Например,{0:d} или {0, 6:d}.В первом случае нулевой элемент списка, имеющий значение типа int,выводится в поле, размер которого не указан. Количество позиций , в которые осуществляется вывод, соответствует количеству знаков в числе.
Во втором случае значение выводится в поле размером 6 позиций .Выводимое число прижимается к правой границе. Если размер поля недостаточен для размещения числа, то указание размера игнорируется.
2.Типы данных. Переменные вещественного типа. Формат вывода вещественных значений. Разделы 1.1-1.4, 1.8.
double – вещественные числа с двойной точностью после знака запятой. По-умолчанию, это основной тип для всех дробных чисел.
Для данных типа double может использоваться код f(F) или код e(E).Первый используется для вывода в форме целой и дробной честей, разделенных запятой(форма с фиксированной запятой).Второй – для вывода вещественного числа в форме с порядком (можно указать также количество цифр после запятой, в целой части выводится всегда одна цифра).
Например, необходимо вывести значение 13,653 и пусть это будет 1-й элемент списка вывода .При выводе в форме с фиксированной запятой можно использовать формат {1, 8:f2} или {1, f} (возможны и другие варианты).
В первом случае значение выводится в поле размером 8 позиций с двумя знаками после запятой в правые позиции поля, т.е. будет выведено 13,65.
Во втором случае размер поля и количество знаков после запятой не указаны и выводятся все знаки, представляющие число, т.е. будет выведено 13,653.
При выводе вещественного числа в форме с порядком(например, 1-го элемента списка) можно в строке формата указать {1, e2} или {1^10:E3}(возможны и другие варианты).
В первом случае число будет выведено в виде 1,37e+001(при выводе значение округляется в большую сторону), во втором – в поле размером 10 позиций в виде 1,365e+001.
Таким образом, для каждого элемента списка имеем {n[,m] [:k]}.Кроме того , в строке формата могут содержаться и другие символы, которые обозначают сами себя и выводятся без изменений; наличие в строке символа /t соответствует нажатию клавиши Tab (табулирование), символа / n – переводу строки. Другие возможности здесь не рассматриваются.