«SEO: Поисковая Оптимизация от А до Я» - Средний уровень => Глава VI. Индексация сайта
Часть VI/9. Robots.txt – правильный robots для WordPress, dle, joomla, smf
Автор: Денис Тумилович (CLASSIK)
Что такое robots
Давайте вместе разберемся что такое robots.txt. Пусть это не будет для вас сюрпризом – это файл!. Да, это просто текстовый файлик, в котором что-то написано. Надо только разобраться ЧТО. Дело в том, что на наш сайт с той или иной периодичностью заходят различные роботы. В одном из блогов мне понравилось разделение этих роботов на культурных и некультурных.
Некультурные роботы – это такие роботы, которые «тибрят» у вас ваш контент, занимаются спамом или сбором почт из комментариев, в общем всякая «шушара» и мусор, которые мешает жить честным личностям типа нас с вами.
Культурные же роботы – это в основном роботы поисковых систем, которые заходят на ваш сайт с целью узнать, а что же у вас обновилось и это что-то выдать в поисковую выдачу, если оно конечно того заслуживает. Так вот эти – культурные роботы – прежде чем начать вообще лазить по вашему сайту – заходят сначала в «предбанник» или можно сказать «прихожую» , которой и является файл robots.
В файле robots прописаны все инструкции, которым обязан следовать культурный робот. Если в файле robots написано нельзя – значит нельзя! Кстати, находится этот файл robots в корневой папке вашего сайта.
Итак, файл Robots.txt – это набор инструкций, которым обязан следовать поисковой робот! С помощью файла robots можно запратить или разрешить индексировать файлы и каталоги, определить главное зеркало домена и даже можно указать интервал между скачиваниями файлов с сайта с целью уменьшения нагрузки
История Robots
История файла начинается в 90х годах, когда активно начинал развиваться сам интернет. Начало появляться большое количество сайтов и поисковые роботы индексировали все подряд, тем самым нагружая сайты и затрудняя пользователям работу или серфинг. Поэтому нужно было создать какое-то решение, которое бы явно указывало поисковому роботу на страницы, которые необходимо индексировать, а какие не стоит. И в 1994 году было подписано соглашение администраторами
Скачать последнее издание этого учебника - http://www.seobuilding.ru/seo-a-z.php |
стр. 405 из 578 |
21.03.2013 |
«SEO: Поисковая Оптимизация от А до Я» - Средний уровень => Глава VI. Индексация сайта
поисковиков, в результате которого появился файл robots.txt . Это конечно не отдельный сервис и не программа, на что все надеялись, но тоже неплохо выполняет поставленные задачи.
Как работает Robots.txt
Файл robots.txt должен находиться в корне вашего сайта и входя на сайт, робот любой поисковой системы в первую очередь обращается именно к этому файлу и получает набор инструкций, которые ему можно и нужно выполнить на этом сайте, а какие не стоит. Если у вас несколько поддоменов, то роботс должен находиться в корне каждого из поддоменов.
Вот как выглядит примерный Robots:
Примерный роботос выглядит так:
•User-agent: *
•Disallow: /tmp/
•Disallow: /cgi-bin/
Звездочка возле User-Agent говорит о том, что следующие инструкции предназначены для роботов любой поисковой системы. А дальше идет просто перечисление каталогов или файлов, которые не нужно индексировать. Все остальное индексироваться будет!
Собственно, вы уже наверное поняли, что параметр Disallow как раз и говорит о том чего «нельзя делать».
Можно запрещать индексировать не только каталоги, но и группы файлов или отдельные страницы вашего сайта.
Структура Robots.txt
Структура здесь небольшая. Сам файл состоит просто из списка инструкций. Каждая инструкция – это одна строка, в которой прописано одно правило.
Итак, каждый файлик роботс состоит из списка записей. Каждая запись – каждая строка – состоит из двух полей: директивы (приказа) и значение директивы. Между приказом и его значением всегда стоит символ
«:».
имя_поля:[необязательные пробелы]значение[необязательные пробелы]
Например User-Agent – это поле, которое обозначает идентификацию конкретного робота конкретного поисковика.
Если User-agent = “ * ” – это значит что следующие инструкции предназначены для всех поисковых роботов. Очень часто мы видим строки user-agent: yandex или user-agent: googlebot – эти строки означают что инструкции, которые перечисляются чуть ниже относятся именно к ботам яндекса или гугла соответственно.
Чуть ниже строки с идентификацией поискового робота идут директивы – приказы для робота, которые говорят индексировать или не индексировать конкретные страницы или папки. Например, поле Disallow говорит о том, что поисковой робот не должен индексировать те файлы или папки, которые стоят в значении этого поля, например
Disallow: /cgi-bin/
Или
Скачать последнее издание этого учебника - http://www.seobuilding.ru/seo-a-z.php |
стр. 406 из 578 |
21.03.2013 |
«SEO: Поисковая Оптимизация от А до Я» - Средний уровень => Глава VI. Индексация сайта
Disallow: /about.html
Директива Disallow работает методом подстановки, т.е. в нашем примере про папку cgi-bin запрещена к индексации именно папка, а также все её содержимое. Но если бы строка строилась так:
Disallow: /cgi-bin/
То в этом случае поисковой робот получил бы приказ к запрету индексации всех документов и папок, в пути которых встречается последовательность символов «cgi-bin», например /cgi-bin.html или /cgibin/index.html – все это было бы под запретом.
Что такое метод подстановки в Robots.txt
Метод подстановки в Robots – это когда в инструкции указано что-то вроде:
Disallow: file
Есть URL вида http://site.ru/catalog/file/file.html и Robots при выполнении этой инструкции начинает подставляет значение поля Disallow (т.е. «file») в этот URL, и там где есть совпадения – считает необходимым выполнить указание, т.е. в данном примере НЕ БУДУТ индексироваться
каталог - http://site.ru/catalog/file/
файл - http://site.ru/catalog/file/file.html
Комментарии в Robots
Да, в роботсе также можно держать комментарии, чтобы поставить комментарий, нужно использовать перед ним символ решетки «#».
Disallow: /cgi-bin/ #comment
Такой стиль , так скажем, не запрещен. Однако это считается плохим стилем, правильней было бы писать каждую директиву на отдельной строке, а комментарий к ней на отдельной.
ВАЖНО!
Под каждым user-agent должен быть хотя бы один Disallow
Как создать robots txt
Чтобы создать файл Robots.txt – нужно воспользоваться любым текстовым редактором (например, тем же Блокнотом), создайте файлик с именем «robots.txt» и заполните его в соответствии с правилами, о которых мы тут рассуждаем. Конечно, не стоит забывать, что после создания файла Robots.txt нужно его «залить» в корневую директорию вашего сайта.
Анализируем Robots.txt
Самое интересное – что есть автоматические анализаторы подобных файлов.
Вот например, Анализатор Яндекса.
Скачать последнее издание этого учебника - http://www.seobuilding.ru/seo-a-z.php |
стр. 407 из 578 |
21.03.2013 |
«SEO: Поисковая Оптимизация от А до Я» - Средний уровень => Глава VI. Индексация сайта
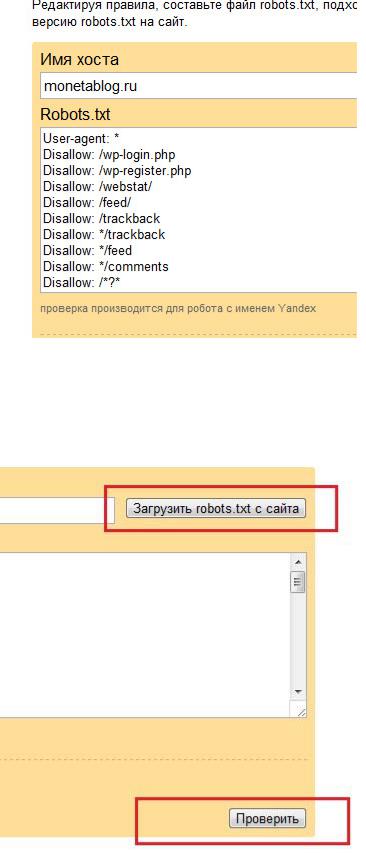
Здесь мы видим два поля: «Имя хоста» и «Robots.txt», мы можем заполнить любое, потому что и так и так, мы сможем выполнить наш анализ. Дело в том что в поле «Имя хоста» мы можем ввести URL нашего сайта и справа этой строчки мы видим кнопку «Загрузить Robots с сайта». Нажимая её, файл Robots.txt автоматически переноситься к поле «Robots.txt». И дальше уже можно будет анализировать.
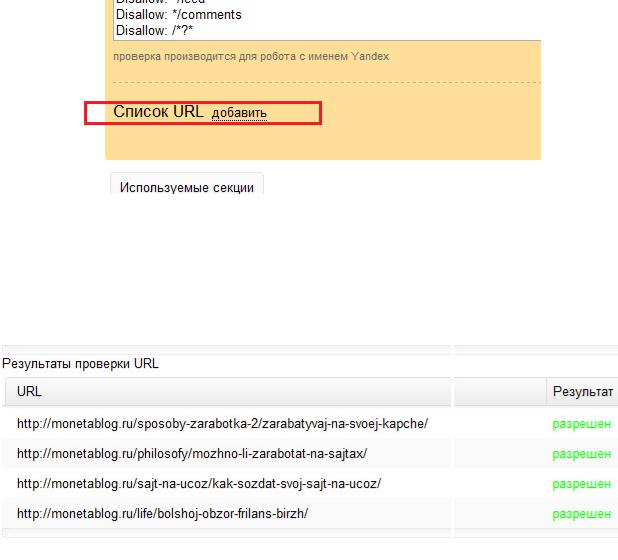
В окне, где появился файл Robots.txt , который находится у вас на сайте – вы можете редактировать этот файлик и проверять, правильно ли индексируется фаш сайт. Внизу окна анализа можно увидеть кнопку «Список URL». Давайте её нажмем. Откроется окно, куда можно вставить список ваших страниц, про индексацию которых вы беспокоитесь и нужно проверить, а Robots вообще позволяет поисковикам из индексировать?
Скачать последнее издание этого учебника - http://www.seobuilding.ru/seo-a-z.php |
стр. 408 из 578 |
21.03.2013 |
«SEO: Поисковая Оптимизация от А до Я» - Средний уровень => Глава VI. Индексация сайта
Я взял первые попавшиеся, наугад, страницы, которые были выделены на главной странице, и решил проверить их индексируемость, чтобы показать вам наглядно, как это может происходить. Итак, открыли мы это окошко и вбили туда списки наших урлов. Нажали уже показанную ранее кнопку «Проверить». И в самом низу нам показывается список страниц, которые проверены и их статус.
Статус может быть двух видов «Разрешен» или «Запрещен», в смысле к индексации.
Следует заметить, что файл robots.txt не является панацеей, так как его правила исключения используют только «культурные» роботы, а наряду с ними существует целый список роботов, сервисов и программ, которые не следуют правилам исключения, либо игнорируют существование файла robots.txt на сайте.
Кроме этого в файл исключений не стоит добавлять пути к файлам, о существовании которых не следует знать посторонним людям. Файл robots.txt доступен всем, поэтому присутствие там строк, вроде Disallow: /admin, только подзадорит некоторых посетителей к совершению вредоносных деяний.
1.В некоторых случаях используется динамическое формирование файла robots.txt, для сайтов с зеркалами.
2.Некоторые системы поддерживают дополнительные поля. Яндекс, например, использует поле Host для определения основного зеркала сайта.
3.Некоторые системы разрешают использование регулярных выражений. Так Гугл, который имеет поиск по изображениям, файлам PDF и другим, поддерживает в поле Disallow символы «*» (любая последовательность символов) и «$» (окончание строки ссылки). Это позволяет запретить индексирование определенного типа файлов:
User-agent: Googlebot Disallow: *.pdf$
#Запрет индексации файлов PDF
По мнению автора это избыточное расширение, так как с тем же успехом можно вынести все документы PDF в отдельный каталог и запретить его индексирование:
User-agent: * Disallow: /pdf/
Скачать последнее издание этого учебника - http://www.seobuilding.ru/seo-a-z.php |
стр. 409 из 578 |
21.03.2013 |
«SEO: Поисковая Оптимизация от А до Я» - Средний уровень => Глава VI. Индексация сайта
Директива Crawl-delay
Задает таймаут в секундах, с которым поисковый робот закачивает страницы с вашего сервера (Crawldelay).
Если сервер сильно нагружен и не успевает отрабатывать запросы на закачку, воспользуйтесь директивой «Crawl-delay». Она позволяет задать поисковому роботу минимальный период времени (в секундах) между концом закачки одной страницы и началом закачки следующей. В целях совместимости с роботами, которые не полностью следуют стандарту при обработке robots.txt, директиву «Crawl-delay» необходимо добавлять в группе, начинающейся с записи «User-Agent», непосредственно после директив
«Disallow» («Allow»).
Поисковый робот Яндекса поддерживает дробные значения Crawl-Delay, например, 0.5. Это не гарантирует, что поисковый робот будет заходить на ваш сайт каждые полсекунды, но дает роботу больше свободы и позволяет ускорить обход сайта.
Пример: User-agent: Yandex
Crawl-delay: 2 # задает таймаут в 2 секунды
User-agent: *
Disallow: /search
Crawl-delay: 4.5 # задает таймаут в 4.5 секунды
Директива Host для Яндекса
Внимание!
Эта директива используется только Яндексом
Если ваш сайт имеет зеркала, специальный робот, который специализируется на зеркалах определит их и сформирует группу зеркал вашего сайта. В поиске будет участвовать только главное зеркало. Вы можете указать его при помощи robots.txt, используя директиву ‘Host’, определив в качестве ее параметра имя главного зеркала. Директива ‘Host’ не гарантирует выбор указанного главного зеркала, тем не менее, алгоритм при принятии решения учитывает ее с высоким приоритетом.
Пример:
#Если www.glavnoye-zerkalo.ru главное зеркало сайта, то robots.txt для #www.neglavnoye-zerkalo.ru выглядит так
User-Agent: * Disallow: /forum Disallow: /cgi-bin
Host: www.glavnoye-zerkalo.ru
В целях совместимости с роботами, которые не полностью следуют стандарту при обработке robots.txt, директиву ‘Host’ необходимо добавлять в группе, начинающейся с записи ‘User-Agent’, непосредственно после директив ‘Disallow’(‘Allow’). Аргументом директивы ‘Host’ является доменное имя с номером порта (80 по умолчанию), отделенным двоеточием. Параметр директивы Host обязан состоять из одного корректного имени хоста (т.е. соответствующего RFC 952 и не являющегося IP-адресом) и допустимого номера порта. Некорректно составленные строчки ‘Host:’ игнорируются.
Недостатки файла robots.txt
Многие хакеры могут проникнуть на ваш сайт, изучив файл robots.txt, и просмотреть данные ограниченного доступа. При эффективном контроле безопасности содержащейся на вашем сайте информации какие-либо хакеры, конечно, не представляют для вас серьезной опасности.
Скачать последнее издание этого учебника - http://www.seobuilding.ru/seo-a-z.php |
стр. 410 из 578 |
21.03.2013 |
«SEO: Поисковая Оптимизация от А до Я» - Средний уровень => Глава VI. Индексация сайта
Например, если вы хотите запретить доступ к страницу с адресомwww.domain.com/stats/index.php, необходимо прописать в файле robots.txt следующую команду:
User-agent: *
Disallow: /stats/
Однако хакерам не трудно догадаться, как зайти на эту страницу – нужно просто ввести в адресной строке браузера URL www.domain.com/stats. От вас же в этом случае потребуется принятие следующих мер:
• Смените имя файла:
Поменяйте имя файла stats index.php на другое, например, stats-new.php. Тогда полный адрес страницы будет выглядеть следующим образом www.domain.com/stats/stats-new.php
Разместите по старому адресу страницы index.php простой текстовый файл, например, содержащий следующую информацию: «извините, но у вас нет прав для доступа к этой странице».
В этом случае хакерам будет трудно угадать имя файла и проникнуть на страницу ограниченного доступа.
• Установите пароль:
Защитите паролем информацию, прописанную в robots.txt файле.
Правильный Robots.txt для WordPress
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Host: monetablog.ru
Sitemap: http://monetablog.ru/sitemap.xml.gz
Sitemap: http://monetablog.ru/sitemap.xml
Правильный Robots.txt для DLE
User-agent: Yandex
Disallow: /autobackup.php
Disallow: /user/
Disallow: /cache/
Disallow: /favorites/
Disallow: /cgi-bin/
Disallow: /engine/
Disallow: /language/
Скачать последнее издание этого учебника - http://www.seobuilding.ru/seo-a-z.php |
стр. 411 из 578 |
21.03.2013 |
«SEO: Поисковая Оптимизация от А до Я» - Средний уровень => Глава VI. Индексация сайта
Disallow: /backup/
Disallow: /rek/
Disallow: /languages/
Disallow: /index.php?do=pm
Disallow: /index.php?do=search
Disallow: /index.php?do=register
Disallow: /index.php?do=feedback
Disallow: /index.php?do=lostpassword
Disallow: /index.php?do=stats
Disallow: /index.php?do=addnews
Disallow: /index.php?subaction=newposts
Disallow: /?do=lastcomments
Disallow: /statistics.html
Sitemap: http://сайт.ru/sitemap.xml
Host: сайт.ru
Этот Robots справедлив когда вы ориентируетесь только на поисковую систему Яндекс. Если же вам интересны многие поисковые системы, то вам будет проще написать User-Agent: *
Правильный Robots.txt для Joomla
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /xmlrpc/
User-agent: Yandex
Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/
Host: vash_sait.ru
Sitemap: http://vash_sait.ru/index.php?option=com_xmap&sitemap=1&view=xml&no_html=1
Правильный Robots.txt для SMF форума
User-agent: *
Allow: /forum/*sitemap
Allow: /forum/*arcade # если не стоит мод игр, удалить без пропуска строки
Allow: /forum/*rss Allow: /forum/*type=rss
Disallow: /forum/attachments/ Disallow: /forum/avatars/ Disallow: /forum/Packages/ Disallow: /forum/Smileys/ Disallow: /forum/Sources/ Disallow: /forum/Themes/ Disallow: /forum/Games/
Скачать последнее издание этого учебника - http://www.seobuilding.ru/seo-a-z.php |
стр. 412 из 578 |
21.03.2013 |
«SEO: Поисковая Оптимизация от А до Я» - Средний уровень => Глава VI. Индексация сайта
Disallow: /forum/*.msg
Disallow: /forum/*.new
Disallow: /forum/*sort
Disallow: /forum/*topicseen
Disallow: /forum/*wap
Disallow: /forum/*imode
Disallow: /forum/*action
Disallow: /forum/*prev_next
Disallow: /forum/*all
Disallow: /forum/*go.php # либо тот редирект что стоит у вас
Host: www.мой сайт.ru # указать ваше главное зеркало
User-agent: Slurp
Crawl-delay: 100
Вэтом шаблоне, есть явное отличие от остальных – это наличие Slurp – это бот Yahoo , и он выполняет проверку в несколько потоков, что может негативно сказаться на производительности вашего форума. Чтобы этого не происходило – здесь включена директива задержки.
Впринципе, это все что нужно знать блоггеру или начинающему вебмастеру. Сложного вроде бы ничего нет, но пошевелить мозгами придется.
Скачать последнее издание этого учебника - http://www.seobuilding.ru/seo-a-z.php |
стр. 413 из 578 |
21.03.2013 |