

Раздельное кэширование и динамическое исполнение. Трехмодульный потоковый конвейер современного процессора
Кроме конвейеризации в современных процессорах реализовано ряд технических и архитектурных элементов, которые обеспечивают реализацию базовых принципов функционирования фон-неймановской машины и в тоже время позволяют устранить ряд принципиальных архитектурных ограничений.
Одним из важнейших элементов архитектуры современных процессоров стала идея раздельного кэширования кода и данных. Кэширование – это способ увеличения быстродействия системы за счет хранения, копий блоков данных и кодов, вероятность выборки которых в ближайшее время максимальна, в так называемой кэш-памяти, находящейся внутри микропроцессора. Мотивация использования кэширования, как одного из способов увеличения производительности ВМ вытекает из так называемого принципа локальности. Сущность принципа основан на том, что в процессе исполнения большинства программ с высокой вероятностью адрес очередной команды программы следует непосредственно за адресом, по которому была считана текущая команда. Таким образом можно говорить о пространственной локальности программы. В свою очередь, обрабатываемые данные, также структурированы и хранятся в последовательных ячейках памяти, что подразумевает пространственную локальность данных. Кроме того, типичная программа содержит большое число циклов и подпрограмм, в которых небольшие наборы инструкций многократно повторяются в течение некоторого интервала времени. Такой ход вычислительного процесса подразумевает временную локальность. Таким образом, из свойств локальности следует, что небольшие фрагменты программы разумно предварительно размещать в быстрой памяти небольшого объема (кэш), существенно снижая издержки на последующее извлечение кодов и данных в течении некоторого времени. По мере исполнения программы содержимое кэша должно обновляться актуальными фрагментами программы для обеспечения непрерывности процесса исполнения. Для увеличения скорости доступа к кэшу в процессорах последних поколений единый кэш разделен на кэш команд и кэш данных, доступ к которым осуществляется по раздельным шинам. Такое деление позволяет совместить во времени процессы выборки команд и извлечения операндов.
Еще одним ценным свойством архитектуры процессоров последних поколений, впервые реализованной в процессорах семейства Intel P6 (Pentium II, Pentium III, Pentium Pro), механизм интеллектуальной обработки потока команд, называемого динамическим выполнением (dynamic execution). Этот механизм основывается на следующих свойствах, некоторые из них уже существовали сами по себе в прежних моделях МП, таких как предсказание переходов, в том числе вложенных и динамический анализ потока данных.
Под динамическим анализом потока данных понимается, анализ который проводится с целью определения зависимостей команд от данных и регистров процессора с целью последующей оптимизации их выполнения. Главный критерий здесь – максимально полная загрузка конвейера. Требования соблюдения данного критерия позволяет нарушать исходный порядок следования команд при поступлении на конвейер. Внешне логика программы при этом будет сохранена. Подобная «неупорядоченность» позволяет поддержать конвейер загруженным даже в то время, когда необходимые данные и код отсутствуют в кэш-памяти. При этом, свойство характеризующее способность процессора реализовывать неупорядоченное исполнение команд, восстановив впоследствии исходный порядок команд и организовав передачу результатов работы команд в порядке, предусмотренным алгоритмом называется также интеллектуальным исполнением.
Данная возможность обеспечивается разделением устройства выборки, устройства исполнения команд и устройства формирования результата. Все промежуточные результаты работы команд во время их исполнения размещаются во временной памяти, называемой пулом инструкций (instruction pool) или буфером переупорядочивания (reorder buffer). Устройство формирования результата, называемое также блоком удаления и восстановления постоянно просматривает пул инструкций и ищет те из них, которые уже исполнены и не имеют связи по данным с другими командами. Когда такие команды найдены, устройство формирования результата помещает готовые данные в память или регистры процессора в порядке, заданном исходным алгоритмом.
Микроархитектура процессоров семейства Р6 основана на идеи трехмодульного конвейера, модули которого работает независимо от остальных. Каждый модуль внутри себя реализует конвейерную обработку, так что совокупное число стадий составляет 14.
Подход используемый в микроархитектуре МП Р6 снимает ограничения линейного принципа прохождения инструкций на стадиях выборки и декодирования, за счет введения пула инструкций. Наличие пула инструкций позволяет процессору в фазе выполнения просматривать поток программных инструкций для улучшения планирования их выполнения. Данный подход требует отдельной фазы выборки/декодирования (fetch/decode) для более эффективного и длительного анализа и предсказания переходов в потоке инструкций. Оптимизация планирования выполнения потребовала также того, чтобы единая фундаментальная фаза выполнения, свойственная процессорам младших поколений, была разделена на фазы диспетчеризации/выполнения (dispatch/execute) и возвращения результатов (retire) выполнения. Это позволяет инструкциям начинать свое выполнение на конвейере в произвольном порядке, а завершать его только в порядке оригинальной программы. Процессоры данного семейства могут быть представлены в виде трех независимых исполняемых машин связанных между собой пулом инструкций, как показано на рис. 5.

Рис. 5. Структура вычислительного ядра процессоров семейства P6
Наличие трех независимых модулей ядра процессора определяют его высокую вычислительную эффективность. Рассмотрим пример фрагмента псевдокода, который позволяет наглядно показать особенности процесса исполнения команд на таком конвейере:
r1 <- mem [r0] (1)
r2 = r1 + r2 (2)
r5 = r5 + 1 (3)
r6 = r6 – r3 (4)
Первая инструкция в этом примере осуществляет загрузку в регистр r1 данных из ячейки памяти адрес, которой извлекается из регистра r0, в предположении того, что имеет место быть кэш-промах (cache miss) – ситуация при которой запрашиваемая строка кэша не содержит актуальных данных и требуется время для ее обновления, а также обращение к оперативной памяти для извлечения требуемого данного. Ядро традиционного процессора должно приостановить выполнение данной инструкции для чтения данных из памяти устройством шинного интерфейса, и только затем возвратиться к выполнению следующей инструкции. Такой процессор останавливается на время ожидания этих данных, снижая при этом свою среднюю производительность.
Для устранения проблемы латентности внешней памяти процессор Р6 использует технологию упреждающего просмотра (look-ahead) пула инструкций для выполнения действий над следующими последовательностями команд, не допуская остановок работы конвейера. Инструкция (2) не выполняется, ввиду ее зависимости от результатов инструкции (1). Однако две следующие инструкции (3) и (4) не имеют первичной зависимости от предыдущих инструкций, поэтому могут быть выполнены. Процессор выполняет эти инструкции, как правило, вне зависимости от порядка их следования в оригинальной программе. Результат этого неупорядоченного выполнения не может быть зафиксирован в состоянии первичной машины, т.е в состоянии программно доступных регистров общего назначения. Результат вместо этого сохраняется обратно в пул инструкций для его упорядочения и возвращения. Ядро исполняет инструкции в зависимости от их готовности к исполнению, а не в порядке оригинальной программы и поэтому представляет собой истинно потоковую исполнительную машину.
Кэш-промах первой инструкции, приводит к большому количеству внутренних тактов, во время которых исполнительное ядро продолжает упреждающее выполнение других инструкций, которые могут быть спекулятивно выполнены (speculative evaluation) и, как правило, просматривает от 20 до 30 инструкций от актуального содержимого счетчика команд. Внутри этого «окна» из инструкций имеется в среднем до 5 переходов (ветвлений, передач управления), которые должны быть корректно предсказаны устройством выборки/декодирования и совершать полезную работу в устройстве диспетчеризации/исполнения. Немногочисленный регистровый набор процессоров Intel архитектуры приводит к появлению большого числа ложных взаимозависимостей по регистрам (структурный риск), так что устройство диспетчеризации/исполнения переименовывает регистровые ссылки на регистры расширенного набора (программно недоступные) для дальнейшего продвижения процесса исполнения. Устройство возвращения результатов имеет доступ только к регистрами стандартного набора и фиксирует результаты выполнения только в эти регистры, когда выполненные инструкции удаляются из пула в порядке оригинальной программы.
Таким образом, технологию динамического исполнения можно охарактеризовать, как корректирующую оптимизацию выполнения инструкций посредством предсказания переходов, способности спекулятивного выполнения инструкций в произвольном порядке, потока данных для выбора лучшего порядка исполнения инструкций.
На рис. 6 представлена упрощенная блок-схема включающая интерфейсы к основной и кэш памяти. Модуль выборки/декодирования (Fetch/Decode Unit) является упорядоченным модулем, т.е. осуществляющий обработку инструкций в порядке оригинальной программы. Этот модуль принимает входной поток программных инструкций из кэша инструкций и декодирует их в последовательность микроопераций, которые представляют собой поток кода готовый к исполнению. Микрооперации размещаются в пуле инструкций.
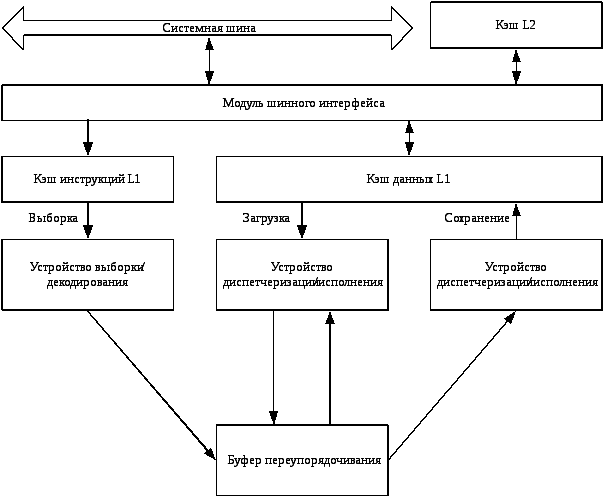
Рис. 6. Процессорное ядро семейства P6
Модуль диспетчеризации-исполнения (Dispatch/Execute Unit) является неупорядоченным модулем, который принимает этот поток, планирует выполнение микроопераций для зависимых данных и доступных ресурсов, временно сохраняя результаты их спекулятивного выполнения обратно в пул инструкций.
Модуль возвращения результатов (Retire Unit) является упорядоченным модулем, который определяет, как и когда подтвердить спекулятивные результаты для нормального архитектурного состояния МП.
Модуль шинного интерфейса (Bus Interface Unit) частично упорядоченный модуль ответственный за соединение трех внутренних модулей с «внешним миром» (память и периферийные устройства). Данный модуль непосредственно соединяется с кэшем второго уровня поддерживая до четырех параллельных операций с ним. Данный модуль также управляет транзакционной системной шиной, с использование протокола специального протокола обмена.