

Этот подход можно представить и такой аналогией: данные стерилизуются, прежде
чем войти в операционную. Все, что находится в ней, считается безопасным. Ключевой вопрос проектирования — решить, что должно быть в операционной, что — остаться снаружи и где быть дверям. Иначе говоря, какие методы поместить внутри безопасной зоны, какие — снаружи, а какие будут проверять данные. Простейший способ — проверка внешних данных по мере их поступления. Но информацию часто необходимо проверять неоднократно, на нескольких уровнях, поэтому иногда требуется многоуровневая стерилизация.
Целесообразно преобразовать входные данные к нужному типу в момент ввода Данные на входе обычно представлены в форме строки или числа. Иногда значение соответствует булевому типу, например, «да» или «нет». Иногда - перечислимому, скажем, ColorRed, ColorGreen, и ColorBlue. Сохранение данных неопределенного типа в течение неизвестного периода времени усложняет программу и увеличивает шансы, что кто-нибудь может вывести программу из строя, указав «Да» в качестве цвета.
Применение баррикад делает отчетливым различие между утверждениями и обработкой ошибок. Методы с внешней стороны баррикады должны использовать обработчики ошибок, поскольку небезопасно де-
лать любые предположения о данных. Методы внутри баррикад должны использовать утверждения, так
как данные, переданные им, считаются проверенными при прохождении баррикады. Если один из методов внутри баррикады обнаруживает некорректные данные, это следует считать ошибкой в программе, а не в данных.
51. Стратегии безопасности. Три уровня реакции ПО на обнаруженную ошибку. Отказоустойчивые системы
Что происходит с системой, если её безотказность нарушена - отказ произошел? Этот вопрос практический и ответ на него оценивается свойством «безопасность», которое формулируется, как ограниченность ущерба системе, окружающей среде и персоналу, нанесенного вследствие нарушения безотказности функционирования системы.
Стратегия безопасности ПО – стратегия «аварийной защиты» предусматривает априорное при проектировании ПО определение опасности возникшей ошибки в системе ПО и применения соответствующих мер, препятствующих развитию ошибочной ситуации, что входит в понятие «аварийной защиты».
При этом оценки величины ущерба, нанесенного отказом, должны быть сопоставлены с величиной затрат на средства его предотвращения либо ограничения последствий. Ситуация, когда стоимость защитных мероприятий превышают величину ущерба не должны иметь место.
Здесь диапазон подходов к решению этой проблемы очень велик, начиная от придания системе и ПО свойств отказоустойчивости до организованного прекращения функционирования системы путем «мягкого её останова» с организованным переводом её в запасное устойчивое состояние, если его можно найти, либо в исходное состояние «финального останова» с минимизацией ущерба для окружающей среды. если такого запасного устойчивого состояния найти не удается.
76
Где-то в промежутке между ними находятся подходы с продолжением функционирования системы и ПО с ухудшением его качества в той или иной мере (это и есть тот ущерб, который несет система вследствие проявившейся ошибки).
При этом отказоустойчивая система продолжает функционировать без ухудшения качества процессов управления т.е. отказ части системы или ПО как бы остается без последствий – не видим либо маскируется.
Обычно отказоустойчивость систем связывается с наличием либо аппаратной избыточности в ЦВМ, ПО, сетях передачи данных, либо с наличием временной избыточности.
Однако, наличие только резерва аппаратуры или временной избыточности не обеспечивает отказоустойчивости системы.
Отказоустойчивость сложных технических систем реализуется при наличии в системе следующих свойств:
1)избыточности аппаратуры и в определённой мере ПО,
2)наличие средств встроенного контроля и диагностики для обнаружения и диагностики отказов и сбоев, а точнее нарушения целостности информации.
3)наличия или сохранения «правильной» информации процессов управления для загрузки её в подключаемые резервные элементы при парировании отказов аппаратуры системы.
Вподходах с продолжением функционирования ПО с ухудшением его качества в зависимости от функции структурной единицы ПО (программы), в которой проявилась ошибка в ПО возможны варианты :
1.снятия с исполнения только той задачи, в которой проявилась ошибка, если это возможно, и проведенная диагностика причин отказа позволяет выделить программу с отказом,
2.сокращения объема выполняемых задач до определенного минимума задач, предназначенных для поддержания только самосохраняемого состояния системы без исполнения в полной мере целевых задач; этой реакции соответствуют более серьёзные нарушения работоспособности ПО и системы и алгоритм контроля должен быть способен различать такие ситуации
Пункты 1, 2 возможно реализовать, если изоляция ошибок в ПО высока.
Таким образом, глубина контроля работы ПО должна обеспечивать не просто обнаружения факта неправильной работы ПО и системы, но и возможность локализации и диагностики ошибки с целью определения адекватных мер по «аварийной защите» с выбором одного из трех вышеприведенных сценариев.
[Введите текст]
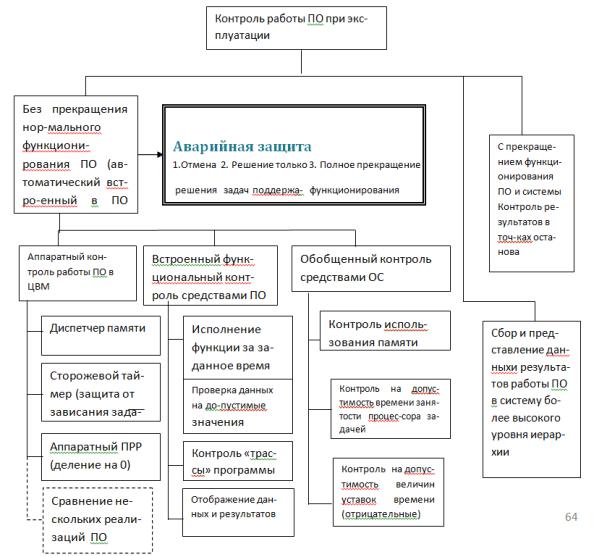
Рис.14 Контроль работы ПО в процессе эксплуатации и аварийная защита
52.Перечень нештатных ситуаций. Аварийная защита
При рассмотренном подходе при проектировании ПО определяется перечень возможных нештатных ситуаций в системе, которые могут быть обнаружены ПО путем обработки имеющейся в ЦВМ информации о функционировании системы.
После чего на каждую возможную нештатную ситуацию системы и ПО из перечня определяется метод её распознавания, а также сценарий реакции, направленной на минимизацию ущерба или восстановления работоспособности, реализуемые в самом ПО.
Реально в специально выделенном фрагменте ПО, предназначенном для управления в нештатных ситуациях СТС, программируется «таблица» с перечнем предусмотренных при проектировании и распознавае-
78
мых ПО нештатных ситуаций и управленческих реакций на каждую из них. Входы в эту таблицу инициируются при возникновении и обнаружении встроенным контролем нештатных ситуаций.
При возникновении непредусмотренных при проектировании или не распознаваемых нештатных ситуаций дело обстоит сложней и чаще всего в этом случае необходимо обеспечивать реакцию по сценарию полного прекращения функционирования ПО и системы с организованным переходом их в исходное состояние, как самую радикальную.
Таким образом, определить и реализовать меры защиты ПОот возникших ошибок это только половина вопроса. Вторая половина – найти методы автоматического обнаружения ошибок средствами ПО.
Классификация возможных методов приведена на схеме рис.14. Приведены общие методы , но в конкретных системах они могут быть гораздо разнообразнее с учетом специфики работы СТС.
Рассмотренный метод аварийной защиты ПО, базирующейся на обнаружении ошибок в ПО внутренними средствами и «мягком» сворачивании работ ПО (ограничения функций или организованного аварийного останова), позволяет корректно завершить работу ПО и дать сообщения об ошибке в систему более высокого уровня иерархии или эксплуатирующему персоналу.
Кроме того, в интерфейсах пользователя с ПО должны быть средства по возможности предотвращающие ошибки оператора(пользователя), а также позволяющие корректно восстановить информацию после ошибок. Эти средства должны быть двух видов: предупреждения о наличии деструктивных действий, если пользователь выбрал опасную для ПО операцию, возможность отмены ошибочных действий, переданных через интерфейс оператора, с возвращением ПО в состояние, в котором оно находилось до их исполнения. Эти возможности должны иметь место не только при наборе текста в графическом редакторе, где они очевидны и привычны, но и для управляющего ПО реального времени.
При этом надо решить а что будет с системой кто её вернет в исходное состояние вместе с ПО, если ко-
мандные воздействия на систему уже прошли да и время уже ушло?
Скорее всего в этих случаях отмену действий ПО надо сопровождать и возвращением системы в состояние на момент проведения неправильных действий ПО. Реально это возможно сделать только приведе-
нием системы в исходное состояние через вызов аварийной защиты, которая и должна привести си-
стему в исходное состояние.
53.Защитное конструирование ПО с возможностью отмены ошибочных команд, выданных из ПО.
54. Ошибки ПО, отладка и тестирование ПО.
Опыт разработки сложного ПО позволяет утверждать, что в любой написанной программе и тем более в любом написанном комплексе программ имеются ошибки. То, что человеку свойственно ошибаться это – объективная реальность. Но эксплуатация ПО с ошибками не допустима.
[Введите текст]

Поэтому для их выявления до сдачи программ в эксплуатацию необходима отладка, которая планируется,
как этап ЖЦПО. Определение: отладка – процесс поиска, локализации и устранения ошибок.
Имеются статистические данные по числу совершаемых ошибок при разработке ПО. По данным американского института программной инженерии ( SEJ ) профессиональные программисты со стажем 10 и более лет на 1000 строк кода допускают в среднем 131,3 ошибки. При этом на этапе компиляции сразу же обнаруживаются и устраняются 50% ошибок. На этапе отладки отдельных модулей обнаруживается ещё 25% ошибок. Остальные ошибки должны быть обнаружены на этапе комплексной отладки или остаются в ПО.
Перед тем как рассматривать технологию поиска и устранения ошибок – технологию отладки надо уточнить «что же такое ошибка».
Ошибка программы – невыполнение ею при правильных входных данных, находящихся в заданном диа-
пазоне, заданных функций с заданным качеством, оговоренных в НТД (спецификации), за заданное время, оговоренное в НТД (спецификации); неправильное взаимодействие со смежными программами, ОС, аппаратурой СТС; создание помех работе других программ ПК.
Поэтому юридическим основанием для предъявления разработчику ПО ошибки является наличие сформулированных требований к ПО, которые разработчик обязался выполнить, но не выполнил. Нет спецификации или другого документа с обещанными функциями – нет ошибки и разработчик будет оспаривать сам факт ее существования.
Это надо учитывать и заказчику, и пользователю при приобретении ПО.
Ошибки, проявляющиеся при любых сочетаниях исходных данных, обнаруживаются легко и не о них идёт речь. Наиболее опасны ошибки, проявляющиеся при определенных наборах исходных данных или при определенных временных соотношениях работы ПО. Они имеют скрытый характер и проявляются внешне случайным образом, как только появляется этот определенный набор данных или эти временные соотношения (прерывания в определенный момент времени).
Ошибки надо уметь воспроизводить для того, чтобы их можно было локализовать и определить их причину. Чаще всего дефект в работе программы видим, но причина его не ясна и требуется проведение определенной работы, связанной с повторными реализациями подозрительного на ошибку участка ПО. В многопоточной системе ПО при этих повторениях необходимо тщательно воспроизводить временные соотношения работы ПО для диагностики ошибок.
Здесь надо вставлять в систему ПО средства, облегчающие эту работу, либо должна использоваться модель внешней среды, позволяющая «передвигать потоки» относительно друг друга.
Кроме понятия отладки ПО существует понятие тестирования ПО. Тестирование ПО это процесс поиска для обнаружения ошибки. Таким образом, тестирование – составная часть процесса отладки. Однако, иногда эти процессы разделяются. Например, в процессе приемки ПО заказчик тестирует его с целью обнаруже-
80