

Сети ЭВМ и телекоммуникации / Лекции / 14_Вычислительные сети
.docЛекция
14
Специализированные технологии вычислительных сетей.
Суперкомпьютинг
Хотя развитие компьютерной индустрии в значительной степени основано на прогрессе технологий и чисто маркетинговых факторах, оно не имело бы смысла и не было бы столь стремительным в отсутствии реальной востребованности. Ключевым параметров вычислительной системы является её производительность. Собственно, наличие вычислительных задач, принципиально не решаемых без использования ЭВМ, и было причиной их появления.
Соотнести ту или иную прикладную или научную задачу с производительностью вычислительной системы, необходимой для её решения, достаточно сложно. Однако очевидно что любой прогресс в производительности доступных для использования вычислительных систем расширяет горизонт решаемых задач. Поэтому вычислительные системы с максимальными параметрами всегда были и остаются предметом особого интереса.
В середине 80-х годов основными для этой области были суперкомпьютерные технологии, успешность которых во многом определялась стремительным прогрессом микропроцессорной техники. В 1985 году в США была принята – и в последующее десятилетие реализована – общенациональная программа по созданию суперкомпьютерных центров, финансируемая государством . Полученный опыт оказался не только положительным: появилось понимание, что при высокой цене разработки и производства суперкомпьютеров, построенные архитектуры имеют ограниченную масштабируемость и не успевают за развитием элементной базы. В то же время, проведенные прикладные исследования показали, что для решения ряда насущных и наиболее приоритетных задач методами математического моделирования (прогнозирование природных явлений, обработка данных высокоэнергетических ядерных реакций, эволюция звезд) необходимы вычислительные мощности принципиально нового уровня производительности и быстродействия.
Почему суперкомпьютеры считают быстро? Основных вариантов ответа всего два: развитие элементной базы и использование новых решений в архитектуре компьютеров.
На одном из первых компьютеров мира - EDSAC, появившемся в 1949 году в Кембридже время такта составляло 2 микросекунды, в современных процессорах время такта приблизительно 0,5 наносекунды. Следовательно выигрыш в быстродействии, связанный с уменьшением времени такта составляет всего около 4000 раз. При этом производительность EDSAC составляла всего 100 операций в секунду. Сегодня производительность более-менее серьезных систем измеряется триллионами операций в секунду. За счет чего достигнут такой прогресс? Рост производительности обеспечивает использование новых решений в архитектуре компьютеров. Важнейшим среди них занимает принцип параллельной обработки данных, воплощающий идею одновременного (параллельного) выполнения нескольких действий.
Рассмотрим базовые принципы использования параллелизма при построении вычислительных систем. Параллельная обработка данных, воплощая идею одновременного выполнения нескольких действий, имеет две разновидности: конвейерность и собственно параллельность. Смысл конвейерной обработки заключается в выделении отдельных этапов выполнения общей операции, причем каждый этап, выполнив свою работу, передавал бы результат следующему, одновременно принимая новую порцию входных данных. Если такие элементарные операции выполнять не последовательно а одновременно, получаем очевидный выигрыш в скорости. Конвеерность организуется на уровне архитектуры процессора. Собственно параллельность организуется на более высоких уровнях архитектуры системы.
1. Векторно-конвейерные компьютеры. Конвейерные функциональные устройства и набор векторных команд - это две особенности таких машин. В отличие от традиционного подхода, векторные команды оперируют целыми массивами независимых данных, что позволяет эффективно загружать доступные конвейеры, т.е. команда вида A=B+C может означать сложение двух массивов, а не двух чисел. Характерным представителем данного направления являлось семейство векторно-конвейерных компьютеров.
2. Параллельные компьютеры с общей памятью. Вся оперативная память таких компьютеров разделяется несколькими одинаковыми процессорами. Основная проблема таких систем заключается в том, что число процессоров, имеющих доступ к общей памяти, по чисто техническим причинам нельзя сделать очень большим. Сегодня это весьма распространенное решение даже для серверов начального уровня. По этой схеме строятся и современные серийные серверы верхнего ценового сегмента. Массовый переход производителей на многоядерные процессоры также лежит в этом русле.
3. Массивно-параллельные компьютеры с распределенной памятью. Идея построения компьютеров этого класса тривиальна: возьмем серийные микропроцессоры, снабдим каждый своей локальной памятью, соединим посредством некоторой коммуникационной среды - вот и все. Достоинств у такой архитектуры масса: если нужна высокая производительность, то можно добавить еще процессоров, если ограничены финансы или заранее известна требуемая вычислительная мощность, то легко подобрать оптимальную конфигурацию и т.п. Однако есть и "минус", сводящий многие "плюсы" на нет. Дело в том, что межпроцессорное взаимодействие в компьютерах этого класса идет намного медленнее, чем происходит локальная обработка данных самими процессорами. Именно поэтому написать эффективную программу для таких компьютеров очень сложно, а для некоторых алгоритмов иногда просто невозможно.
4. Кластерные компьютеры. Данное направление не является самостоятельным, а скорее представляет собой комбинации предыдущих трех. Из нескольких процессоров (традиционных или векторно-конвейерных) и общей для них памяти формируется вычислительный узел. Если полученной вычислительной мощности не достаточно, то объединяются несколько узлов высокоскоростными каналами.
Метакомпьютинг и грид
В начале 90-х годов столь же бурно, как и микропроцессоры, стали развиваться телекоммуникационная аппаратура и линии передачи. Идея объединения процессорных технологий с телекоммуникационными дала толчок Метакомпьютингу, как способу соединения суперкомпьютерных центров. Метакомпьютинг определяется как “использование мощных вычислительных ресурсов, доступных прозрачно посредством телекоммуникационной среды”. В дополнении к условию прозрачности применимы также такие характеристики как бесшовность, масштабируемость и глобальность. Таким образом, в новой парадигме Метакомпьютинга предлагалось полностью скрыть наличие телекоммуникаций и использовать подключенные к сети компьютеры как единый объединенный вычислительный ресурс. Основной акцент в Метакомпьютинге делался на то, что потенциальный пользователь может получить практически неограниченные ресурсы для вычислений и хранения данных
Начатые в этом направлении работы – в первую очередь по системам Globus (совместный проект Арагоннской национальной лаборатории ANL при университете Чикаго и института информатики университета Южной Каролины ISI USC) и Legion (университет Вирджинии), а также ряд других - привели к существенному обобщению идеи Метакомпьютинга. Уже на начальном периоде развития было показано, что для программной поддержки распределенной среды необходимо решить широкий круг проблем: связь, безопасность, управление заданиями, доступ к данным, информационное обеспечение. Все эти вопросы имеют прямые аналоги в операционных системах, но должны быть пересмотрены для ненадежной, открытой и распределенной глобальной среды. Более того, архитектура среды должна быть расширяемой и способствующей наращиванию функциональности при сохранении работоспособности. В процессе практической работы идея метакомпьютинга претерпела существенные изменения, что привело к появлению нового термина – грид (От английского grid – решетка, сеть, electric grid – электрическая сеть. Вариант появления термина подразумевает смысловую аналогию: использование вычислительной грид среды для пользователя просто как использование обычного электричества).
Одно из классических определений:
«Грид является согласованной, открытой и стандартизованной средой, которая обеспечивает гибкое, безопасное, скоординированное разделение ресурсов в рамках виртуальной организации – то есть динамически формирующейся совокупности независимых пользователей, учреждений и ресурсов».
Обратим внимание что речь больше не идет о “мощных вычислительных ресурсах” Метакомпьютинга. В качестве процессорных ресурсов в грид рассматриваются рабочие станции и обычные ПК. В любой, как научной, так и коммерческой организации, основные вычислительные мощности сосредоточены вовсе не в суперкомпьютерном парке. Если организация располагает тремя тысячами рабочих мест на базе рабочих станций, то за время их регулярного простоя потерянные циклы составят существенную долю даже терафлопной производительности. Мощные ресурсы - суперкомпьютеры, кластеры, SMP-системы - остаются только важным частным случаем. Новая грид трактовка применима к самым разнообразным типам ресурсов: телекоммуникациям, системам массовой памяти, хранилищам данных, а также измерительным и научным инструментам.
Выход за рамки высокопроизводительных систем и приложений выявляет реальное содержание Грид: это инфраструктура для поддержки любой глобально распределенной вычислительной деятельности. От инфраструктуры Грид может извлечь пользу множество типов приложений – это электронный бизнес, кооперативное проектирование, исследование данных, системы обработки высокой пропускной и собственно распределенный суперкомпьютинг (то есть Метакомпьютинг). Для некоторых из этих приложений с “хорошими” свойствами, могут и не требоваться высокопроизводительные телекоммуникации как для Метакомпьютинга. Тогда в качестве телекоммуникационной составляющей инфраструктуры грид может выступать обычный Интернет - неограниченно масштабируемый, всеобъемлющий и повсеместный уже сейчас.
В качестве примера можно привести известный проект по проблеме SETI, в котором данные с радиотелескопов обрабатывались в фоновом режиме на миллионах частных персоналок по всему миру в поисках сигналов от внеземных цивилизаций.
Сети вычислительных кластеров
Рассмотрим основные технологии, используемые при построении массово параллельных и кластерных решений. Как уже отмечалось, критически важным в этом случае является скорость доступа процессорных модулей к данным, находящимся вне непосредственно доступной памяти. Проблема не сводиться к скорости передачи данных в используемых каналах связи. Очень важную роль играет латентность – задержки потока данных в каналообразующем оборудовании.
Gigabit Ethernet
Хотя на сегодня Gigabit Ethernet отнюдь не позиционируется как коммуникационная среда для массово-параллельных систем а является стандартной широкодоступной технологией, именно её доступность (в том числе в финансовом смысле) при достаточно высокой пропускной способности часто определяет выбор. Этому способствует и распространение идей гридкомпьютинга не нацеленного на высокоскоростную связность вычислительных подсистем.
Для этой технологии ключевые параметры составляют:
Пиковая пропускная способность - 1 Gbit/sec (125 MB/sec),
Латентность - 100 мкс
Хотя надо понимать что эти параметры очень существенно зависят от конкретной архитектуры и аппаратной реализации системы.
Тем не менее такие решения широко применяются в настоящее время.
Myrinet
Myrinet – это высокопроизводительная технология передачи и коммутации пакетов, широко используемая для объединения разнородных ЭВМ в кластеры.
Отличительными чертами Myrinet являются:
-
Контроль потока данных, контроль ошибок, непрерывный мониторинг каждого линка.
-
Сквозная коммутация с низкой латентностью и мониторингом для высокопроизводительных приложений.
-
Коммутируемые сети масштабируемые до десятков тысяч хостов и с возможностью организации альтернативных соединений между хостами.
-
NICs выполняющие собственные программы (firmware) для разгрузки основного процессора от обработки коммуникационного проттокола. Это специальное ПО может напрямую взаимодействовать с процессами на хосте минуя операционную систему для снижения латентности коммуникаций и напрямую взаимодействовать с сетью, отправляя, получая и буферизуя пакеты.
Myrinet является стандартом ANSI (American National Standards Institute) -- ANSI/VITA 26-1998. Спецификации этого стандарта открыты и опубликованы.
Компоненты
и ПО Myrinet

Фирма Myricom выпускает для Myrinet компоненты и ПО двух серий: Myrinet-2000 и Myri-10G.
Myrinet-2000 является альтернативой Gigabit Ethernet для кластеров. В полнодуплексном режиме скорость передачи данных 2+2 Gbit/sec (250+250 MB/sec) при латентности около 3 мкс. Соединение узлов сети выполняется оптическими кабелями длиной до 200 м. Для коммутации используются 16 или 32 портовые свичи,
Myri-10G превосходит по производительности 10-Gigabit Ethernet. При этом Myri-10G использует те же самые элементы физического уровня (кабели и коннекторы) что и 10-Gigabit Ethernet, и может взаимодействовать с сетью на этом протоколе. Фактически, Myri-10G NICs являются одновременно 10-Gigabit Myrinet NICs и 10-Gigabit Ethernet NICs.

10G-PCIE-8B-QP NIC
В полнодуплексном режиме скорость передачи данных 10+10 Gbit/sec (1200+1200 MB/sec) при латентности около 2 мкс. Соединение узлов сети выполняется оптическими кабелями. Для коммутации используются 16 портовые свичи,
InfiniBand
Пожалуй наиболее популярным на сегодня решением является Infiniband (дословно – неограниченная пропускная способность) высокоскоростная коммутируемая последовательная шина, применяющаяся как для внутренних (внутрисистемных), так и для межсистемных соединений. Именно с использованием этой технологии реализованы системы, занимающие три верхних призовых места в списке Топ50 России на сентябрь 2008 года.
Базовой является идея создания системной архитектуры, освобождающей центральный процессор от участия в обработке коммуникаций и сетевого трафика. Ресурсы основных процессоров освобождаются для сложных математических расчетов и иных вычислительных задач.
Архитектура InfiniBand определяет общий стандарт для обработки операций ввода-вывода коммуникационных и сетевых подсистем и систем хранения данных. Вокруг этого стандарта сформировалась торговая ассоциация InfiniBand Trade Association, в которую входят такие лидеры рынка, как Dell, Hewlett-Packard, Intel, IBM, Microsoft и Sun Microsystems.
Используя коммутируемую сетевую структуру (switched fabric), InfiniBand переносит трафик операций ввода-вывода с процессоров сервера на периферийные устройства и иные процессоры или серверы. В качестве физического канала используется специальный кабель, обеспечивающий скорость передачи данных 2,5 Гбит/с в обоих направлениях (InfiniBand 1х). Для повышения скорости могут использоваться 4-кратные и 12-кратные версии InfiniBand. Многоуровневая архитектура InfiniBand включает четыре аппаратных уровня и верхние уровни, реализуемые программно. В каждом физическом канале можно организовать множество виртуальных каналов, присвоив им разные приоритеты.

Host Channel Adapter (HCA) устанавливается внутри сервера или рабочей станции (хоста). Он образует интерфейс между контроллером памяти и внешним миром и служит для подключения хост-машин к сетевой инфраструктуре, построенной на основе InfiniBand. HCA реализует протокол обмена сообщениями и основной механизм прямого доступа к памяти.
HCA подключается к одному или нескольким коммутаторам InfiniBand и может обмениваться сообщениями с одним или несколькими адаптерами каналов целевой машины (Target Channel Adapter, TCA). TCA служит для подключения к сети InfiniBand различных устройств, таких, как накопители, дисковые массивы или сетевые контроллеры. Он выступает в качестве интерфейса между коммутатором InfiniBand и контроллерами ввода-вывода периферийных устройств. Эти контроллеры могут принадлежать к разным классам, что позволяет объединять в одну систему разнородные устройства. Таким образом, TCA действует в качестве промежуточного физического слоя между трафиком данных структуры InfiniBand и более традиционными контроллерами ввода-вывода для иных подсистем: Ethernet, SCSI или Fibre Channel.
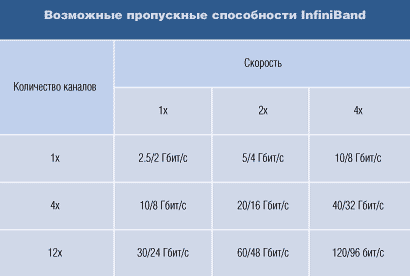
Один физический канал, используемый InfiniBand, изначально определен как последовательное экранированное соединение. В нем обеспечивается передача около 2,5 Гбит/с в каждом направлении. В зависимости от возможностей среды передачи InfiniBand может устанавливаться удвоенная и учетверенная скорость передачи, то есть 5 Гбит/с и 10 Гбит/с соответственно. Поскольку каждый байт сопровождается двумя контрольными битами, реальная пропускная способность составляет 80% от номинальной, то есть могут формироваться потоки в 2 Гбит/с, 4 Гбит/с или 8 Гбит/с полезного трафика, причем обмен потоками происходит в полнодуплексном режиме.
Спецификация предусматривает объединение четырех или двенадцати каналов в один логический. В случае объединения двенадцати четырех скоростных физических каналов достигается номинальная скорость 120 Гбит/с (или 96 Гбит/с полезного трафика). При этом обеспечивается латентность на уровне 4 мкс. При использовании оптоволоконных соединений максимальная длина межсоединений составляет 10 км.
Последняя версия «дорожной карты» стандарта, представленная на сайте ассоциации разработчиков и поставщиков оборудования выглядит следующим образом:
