

Lab02_2010
.pdfво вспомогательную переменную distance расстояние от нее до середины отрезка. Далее, последовательно просматривая все остальные точки, вычисляем расстояние до середины отрезка до каждой из них и при необходимости обновляем значение вспомогательной переменной. По завершении просмотра массива выводим результат на печать. Будем полагать, что если таких точек несколько, при выводе ответа достаточно указать любую из них. Как и ранее, номер точки выводим со сдвигом 1.
Дополним метод main() вызовом метода theNearestToMidpoint() (рис. 19).
Рис. 19. Тестирование метода theNearestToMidpoint()
Сохраните и запустите на выполнение приложение. Выполните его проверку на всех ранее разработанных тестах. На рис. 20 приведен вывод приложения при входных данных с рис. 14.
Рис. 20. Работа метода theNearestToMidpoint() при N = 5
§ 7. Отыскание пары точек, ближайших друг к другу
Самое простое решение пункта в) задачи предполагает вычисление расстояния на координатной прямой от каждой точки до всех остальных и сравнение этих расстояний между собой. Именно его мы и реализуем в настоящем параграфе.
Примечание.
Выше было сказано, что еще одно решение состоит в упорядочении элементов массива, после которого достаточно выполнить сравнение расстояний между соседними элементами.

Однако само по себе упорядочение (сортировка) является нетривиальной задачей и будет рассматриваться позже.
Можно сказать, что «наивный» алгоритм отыскания пары ближайших точек является «расширением» алгоритма отыскания точки, ближайшей к середине отрезка, – но при этом в роли середины отрезка поочередно выступают все точки. Это значит, что цикл, подобный тому, с помощью которого определялась наиболее подходящая точка в пункте б), должен быть «заключен» в цикл, перебирающий тестируемые точки («аналоги» середины отрезка). Еще одно необходимое замечание состоит в том, что, вычислив расстояние между точками i и j и определив, является ли оно минимальным или нет, уже нет необходимости вычислять расстояние между точками j и i (результат не изменится). Поэтому достаточно проанализировать расстояния между точками в тех случаях, когда первая точка всегда имеет меньший номер в массиве, чем вторая (или наоборот). По прежнему будем полагать, что если существует несколько пар точек, отстоящих друг от друга на одинаковое (и притом минимальное) расстояние, то в качестве ответа можно вывести любую пару. Код метода приведен на рис. 21. Как и в предыдущих случаях, при выводе номеров точек выполняется сдвиг на 1.
Рис. 21. Метод отыскания ближайших друг к другу точек
Начальные значения переменных first и second повторно обрабатываются на первых итерациях вложенных циклов. Но в данном случае пересчитать расстояние между точками еще раз проще (и быстрее), чем ставить условия или же удлинять код. Вспомогательная переменная minDistance хранит расстояние между точками с индексами first и second (это позволяет не пересчитывать его каждый раз при выполнении сравнения во внутреннем цикле: иначе приходилось бы писать
if (Math.abs(array[i]–array[j]) < Math.abs.(array[first]–array[second])){...}

что и длиннее, и «накладнее»).
Цикл по i идет до предпоследнего элемента, так как предполагается сравнение первой точки в паре с теми, у которых больший номер в массиве. Это значит, что для последней точки пары не найдется. Цикл по j начинается от точки, следующей за i, и заканчивается последней точкой в массиве.
Вызов нового метода следует добавить в метод main() (рис. 22)
Рис. 22. Вызов метода theNearestPoints()
Сохраните приложение и запустите его на выполнение. Проверьте его работу на ранее заготовленном наборе тестов. На рис. 23 приведен результат работы приложения при N = 5 (для значений с рис. 14)
Рис. 23. Вывод результатов работы метода theNearestPoints()
Обратите внимание на расстояние между ближайшими друг к другу точками – это хорошая иллюстрация того, какова точность вещественной арифметики. Тип double гарантирует 15–16 значащих цифр в числе. Последняя единица является 17-ой значащей цифрой, и рассматриваться по соображениям точности не должна. Вообще при выводе вещественных значений правильным подходом будет оговаривать точность, с которой вычислен результат, и выводить соответствующее количество значащих цифр. Для этого можно использовать функцию printf() или формировать строку для вывода средствами класса Formatter. Оба способа будут обсуждаться в следующих лабораторных работах.
Выполните построение приложения (Clean and Build) и проверьте его работоспособность вне среды NetBeans (см. лабораторную работу № 1).

Общие задания по доработке проекта.
Все современные компиляторы способны оптимизировать код программы при переводе его на машинный язык (в случае Java – язык виртуальной машины JVM). Конечно, преобразования оптимизации не превратят алгоритм, выполняющий ~N2/2 шагов при вычислении расстояний между каждой парой из N точек, в алгоритм, делающий ту же самую работу за ~N шагов (просто потому, что если точек N, и каждую надо сопоставить со всеми остальными). Однако в ряде случаев в процессе оптимизации происходит упрощение арифметических выражений, «удаление» неиспользуемых переменных и т.п. Разумеется, следует стремиться писать программы, которые будут работать быстрее.
Наряду с улучшением алгоритмов есть и некоторые простые шаги, которые полезно делать, чтобы избежать «лишних» вычислений.
§ 8. Простая оптимизация кода
Рассмотрим, например, метод getMax() (рис. 11). На каждой итерации цикла for выполняется сравнение очередного элемента массива array[i] с элементом массива array[result], который является максимальным из уже просмотренных (т.е. среди элементов с номерами от 0 до (i–1)). Конечно, если массив упорядочен по возрастанию, то на каждом шаге значение result будет обновляться. Если же массив содержит случайные неупорядоченные значения, то индекс максимального элемента будет меняться далеко не каждый раз. А вот обращение к значению array[result] приводит к его вычислению на каждой итерации цикла. Конечно, если в Вашем массиве будет не более десятка элементов, то на такой «перерасход» можно закрыть глаза. Если же элементов будет несколько десятков тысяч, то затраты времени могут стать вполне заметными.
Поэтому введем вспомогательную вещественную переменную maxEl, в которой будет храниться значение максимального из просмотренных элементов массива. Изменение значения этой переменной будет происходить одновременно с изменением значения переменной result. Это позволит заменить в условном операторе обращение к элементу массива по индексу значением maxEl. В результате код метода приобретет следующий вид (рис. 24):
Рис. 24. Метод getMax() с использованием вспомогательной переменной

Раскомментируйте в методе main() вызов метода getMax(), сохраните приложение, запустите его на выполнение и проверьте работу изменненого метода на имеющемся у Вас наборе тестов.
Конечно, можно еще обратить внимание на то, что при обновлении значения maxEl происходит повторное обращение к элементу array[i] (первое обращение всегда выполняется при вычислении логического выражения в условном операторе), и ввести еще одну вспомогательную переменную вещественного типа curEl, в которую в начале каждой итерации цикла будет помещаться очередного элемента массива. Код метода после этого изменения показан на рис. 25.
Рис. 25. Метод getMax() с двумя вспомогательными переменными
Сохраните приложение после внесения изменений и запустите его на выполнение. Удостоверьтесь, что максимальный элемент по-прежнему вычисляется правильно.
После добавления переменной maxEl «экономия» состояла в том, что вычисление array[result] происходило на каждой итерации цикла, а вычисление maxEl – только в случае успешного срабатывания условного оператора (т.е., как правило, не на каждой итерации цикла). А в случае добавления curEl произошло следующее: вместо вычисления array[i] на каждой итерации цикла единожды или дважды получили его однократное вычисление на каждой итерации.
Код стал еще на пару строк длиннее, но не утратил при этом своей «прозрачности». Впрочем, обращение к массиву – не слишком долгая операция. Если бы вместо элемента массива требовалось бы вычислять какую-либо сложную функцию, обращаться к элементу файла или какой-либо сложной динамической структуры, то такие изменения были бы просто «хорошим тоном». Мы же пока рассматриваем учебную ситуацию «как вносить изменения в существующий код» на простых и легко тестируемых примерах.
Примечание 1.
Вполне возможно, что какой-либо конкретный компилятор справляется с подобными «сложными» заменами. Однако от «лишних» переменных избавиться намного проще, и это реализовано практически во всех компиляторах. Поэтому «экономить» на вспомогательных
переменных не стоит (если, конечно, они не являются копиями какой-то большой структуры данных – тут в каждом случае необходим тщательный анализ).
Примечание 2.
Чтобы проверить, будут ли отличия в длительности работы программы, необходимо создавать большие массивы – например, с помощью генератора случайных чисел. Как это сделать, мы обсудим позже.
Задание 1. Модифицируйте метод getMin() аналогично методу getMax(). Можете использовать в качестве имен переменных minEl и curEl.
§ 9. Использование меню Refactor при простых оптимизациях
Метод theNearestToMidpoint(), решающий пункт б) задачи, также может быть подвергнут аналогичному преобразованию. Действительно, расстояние между текущим элементом массива и серединой отрезка вычисляется сначала в логическом выражении, а затем (в случае успешного срабатывания условия) – в теле условного оператора. Конечно, можно внести изменения вручную, но сейчас мы изучим, как можно выполнить их с помощью среды NetBeans.
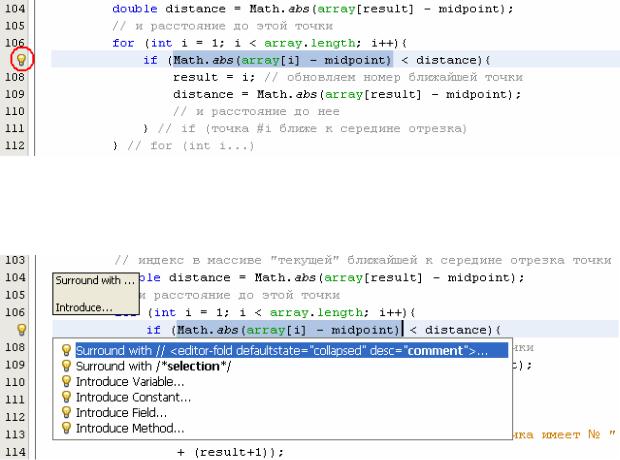
Выделите выражение, вычисляющее расстояние между точками. Среда разработки «просигнализирует» о том, что готова предложить варианты изменений, продемонстрировав значок лампочки (рис. 26).
Рис. 26. Реакция IDE NetBeans на выделение фрагмента кода
Нажатие на значок лампочки приводит к демонстрации возможных вариантов (рис. 27).
Рис. 27. Предлагаемые IDE варианты изменений

Первые два предложения касаются добавления комментариев, причем второе предложение позволяет заключить выделенный фрагмент в многострочный комментарий. Предложения Introduce (Ввести) фактически являются частью контекстного меню Refactor, полный вид которого для выделенного фрагмента приведен на рис. 28.
Рис. 28. Меню Refactor для выделенного фрагмента кода
Нет разницы, выберете ли Вы пункт Introduce Variable (Ввести переменную) из меню Refactor или из краткого меню, предлагаемого средой при нажатии на значок лампочки: результатом будет диалоговое окно (рис. 29).
В этом окне предлагается ввести имя переменной, которая заменит собой выделенное выражение. Среда предлагает свой вариант (чаще всего это name), но, конечно, нужно использовать осмысленные имена переменных.
Пункт Declare Final означает, что новая переменная будет объявлена с модификатором final, предписывающим однократную инициализацию данной переменной и неизменность ее значения в последующем. В нашем случае отмечать его не нужно (если «галочка» поставлена – снимите ее), поскольку переменная будет заново вычисляться на каждой итерации цикла.

Рис. 29. Диалоговое окно Introduce Variable
Пункт Replace All Occurences (заменить все вхождения) не активен: действительно, при обновлении переменной distance в условном операторе вместо array[i] использовалось array[result]. Нет ничего сложного в том, чтобы внести изменения в код для distance позже. Но сейчас мы хотим максимально «автоматизировать» процесс. Нажмите кнопку Cancel и измените строчку кода для distance (рис. 30).
Рис. 30. Изменение выражения для вычисления distance
Вновь выделите выражение для вычисления расстояния в условном операторе и выберите в контекстном меню пункт Introduce Variable. Теперь вид диалогового окна будет немного другим (рис. 31).
Рис. 31. В диалоговом окне стал активен пункт Заменить все вхождения

Как видите, теперь пункт Replace All Occurences активен, при этом в скобках указано количество вхождений этого выражения. Назовите новую переменную curDistance. Снимите пометку с пункта Declare Final и поставьте пометку на пункт Replace All Occurences. После этого можно нажимать OK. Получившийся код показан на рис. 32.
Рис. 32. Изменения, внесенные средой
Обратите внимание: объявление (совмещенное с инициализацией) новой переменной появилось внутри цикла. Это логично – поскольку внутри блока кода, ограниченного телом цикла, переменная с таким именем будет гарантированно уникальной. Однако в нашем случае объявление переменной на каждой итерации цикла не требуется, поэтому именно «объявляющую» часть этого предложения поместим перед циклом for. Это придется сделать уже вручную. Выполнять инициализацию переменной curDistance до цикла нет необходимости (рис. 33).
Рис. 33. Объявление переменной curDistance помещено перед циклом for
Сохраните и запустите на выполнение приложение. Проверьте (с помощью имеющегося набора тестов), что после внесенных изменений все вычисления выполняются правильно.
Задание 2. Модифицируйте метод theNearestPoints() аналогично методу theNearestToMidpoint() (с помощью подсказок среды). Можете использовать в качестве имени вспомогательной переменной curDistance. Объявление этой переменной целесообразно поместить перед обоими циклами for. Убедитесь в правильной работе приложения после внесения изменений.
Внимание! Для выполнения индивидуальных заданий следует создать новый проект. Массив и методы работы с ним должны быть оформлены в виде отдельного класса. В проекте обязательно должны присутствовать комментарии. Также следует разработать комплект тестов (не менее 5, создайте для их записи отдельный текстовый файл), который нужно будет предъявить и использовать при сдаче задания.
Индивидуальные задания
С клавиатуры вводятся количество чисел N и сами эти числа. Разработайте приложение, которое помещает эти элементы в массив, а потом
1.вычисляет сумму элементов, расположенных между минимальным и максимальным элементами (числа – вещественные; считайте, что в массиве есть ровно один максимальный и ровно один минимальный элемент)
2.вычисляет количество элементов, которые отличаются по абсолютной величине от среднего арифметического всех элементов массива не более, чем на величину d (числа – вещественные, величина d также вещественная и вводится с клавиатуры)
3.вычисляет произведение элементов массива, которые принадлежат отрезку [X, Y] (числа X и Y вводятся с клавиатуры; элементы массива, а также X и Y – вещественные числа)
4.вычисляет максимальную из сумм отрезков из m подряд идущих чисел (числа –
вещественные, m – целое, вводится с клавиатуры, не превосходит N) (Должны быть рассмотрены отрезки 0, 1, 2, … m–1; 1,2, 3, …, m; 2, 3, 4, …, m+1; … N –m, N–m+1, N–m+2, …, N-1. Постарайтесь обойтись без вложенных циклов).
5.определяет номер элемента в массиве, суммы элементов слева и справа от которого различаются на минимально возможную величину (элементы – целые числа)
6.определяет количество элементов в массиве, разделяющих его на две части (слева и справа от такого элемента), отличающихся по сумме элементов не более чем на величину d (элементы массива – вещественные числа, d – вещественное число, вводится с клавиатуры)
7.определяет номер (и значение) элемента в массиве, который является медианой – количество чисел, которые превосходят его, совпадает с количеством чисел, которые меньше него (считайте, что элемент, а N – нечетное число)
8.определяет, сколько чисел в массиве встречается по одному разу (числа – целые)
9.определяет для каждого из чисел, встречающихся в массиве, – сколько раз оно в нем встречается (числа – целые) (Приветствуется отсутствие повторного рассмотрения чисел)
10.определяет, верно ли, что никакой из положительных элементов не превосходит по модулю любой из отрицательных элементов, расположенных в массиве правее него (числа – вещественные)
11.рассматривая элементы массива как коэффициенты многочлена степени (N–1), определяет производную этого многочлена в точке x (элементы массива – вещественные числа, точка x – тоже вещественное число, вводится с клавиатуры)
12. вычисляет сумму вида x1y1 + x2y2 + …+ |
xSyS, где x1, x2, … , xP – отрицательные |
элементы массива, перенумерованные в |
порядке следования; y1, y2, …, yQ – |