

2. Элементы теории кодирования
2.1. Линейные коды
Пусть
имеется канал связи, по которому
передаётся двоичная информация. Если
двоичная последовательность разбивается
на блоки длины
 ,
которые в соответствии с процедурой
кодирования преобразуются в блоки длины
,
которые в соответствии с процедурой
кодирования преобразуются в блоки длины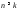 ,
то такое кодирование называется блочным.
,
то такое кодирование называется блочным.
Пример
1.
Одним из наиболее простых линейных
кодов является код проверки на чётность.
Двоичная последовательность
 длины
длины преобразуется в двоичную последовательность
преобразуется в двоичную последовательность длины
длины ,
где
,
где .
Код проверки на чётность позволяет
обнаруживать одиночную ошибку. Если в
полученном сообщении
.
Код проверки на чётность позволяет
обнаруживать одиночную ошибку. Если в
полученном сообщении ,
это свидетельствует о наличии, по крайней
мере, одной ошибки (или нечётного числа
ошибок).
,
это свидетельствует о наличии, по крайней
мере, одной ошибки (или нечётного числа
ошибок).
Определение
1.
Линейным
 -кодом
будем называть линейное подпространство
-кодом
будем называть линейное подпространство размерности
размерности в линейном пространстве
в линейном пространстве .
.
Определение
2.
Если
 ,
то весом Хэмминга
,
то весом Хэмминга вектора
вектора будем называть число его ненулевых
координат. Если
будем называть число его ненулевых
координат. Если ,
то число
,
то число будем называть расстоянием между
векторами
будем называть расстоянием между
векторами и
и .
.
Определение
3.
Число
 будем называть весом кода
будем называть весом кода и обозначать
и обозначать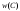 .
.
Определение
4.
Матрицу
 размера
размера ,
строки которой составлены из координат
векторов
,
строки которой составлены из координат
векторов некоторого базиса кода
некоторого базиса кода будем называть порождающей матрицей
кода
будем называть порождающей матрицей
кода .
.
Определение
5.
Пусть – элементы пространства
– элементы пространства .
Величину
.
Величину

назовём
их псевдоскалярным произведением. В
случае
 элементы
элементы и
и будем называть ортогональными. Если
будем называть ортогональными. Если – линейное подпространство в
– линейное подпространство в ,
то
,
то будем называть ортогональным дополнением
для
будем называть ортогональным дополнением
для .
.
Очевидно,
 – само является линейным подпространством.
Из курса линейной алгебры известно, что
сумма размерностей подпространств
– само является линейным подпространством.
Из курса линейной алгебры известно, что
сумма размерностей подпространств и
и равна
равна .
.
Заметим,
что
 возможно для
возможно для ,
т.е. не выполнена одна из аксиом скалярного
произведения. Поэтому произведение
,
т.е. не выполнена одна из аксиом скалярного
произведения. Поэтому произведение мы называем псевдоскалярным.
мы называем псевдоскалярным.
Определение
6.
Пусть
 – ортогональное дополнение кода
– ортогональное дополнение кода в пространстве
в пространстве .
Код
.
Код называется двойственным к
называется двойственным к ,
а его порождающая матрица
,
а его порождающая матрица размера
размера называется проверочной матрицей кода
называется проверочной матрицей кода .
Очевидно,
.
Очевидно, .
.
Пример
2.
Пусть процедура кодирования состоит в
том, что двоичной последовательности
 длины 3 сопоставляется двоичная
последовательность
длины 3 сопоставляется двоичная
последовательность длины 5 по формулам
длины 5 по формулам
 ,
,
 .
.
Тогда
код
 есть множество решений этой системы
линейных однородных уравнений ранга 2
с пятью неизвестными. Следовательно,
код
есть множество решений этой системы
линейных однородных уравнений ранга 2
с пятью неизвестными. Следовательно,
код имеет размерность 3. Фундаментальную
систему решений можно выбрать из векторов
имеет размерность 3. Фундаментальную
систему решений можно выбрать из векторов
 ,
,
 ,
,
 .
.
Порождающая
матрица кода
 ,
таким образом, имеет вид
,
таким образом, имеет вид
 .
.
Ортогональным
кодом
 будем множество решений систему уравнений
будем множество решений систему уравнений
 ,
,
 ,
,
 .
.
Фундаментальная система решений имеет вид
 ,
,
 .
.
Таким
образом, проверочная матрица кода
 есть
есть
 .
.
Код
 есть линейный (5, 3)-код.
есть линейный (5, 3)-код.
Путём
переименования переменных
 и линейных преобразований над строками
матрицы
и линейных преобразований над строками
матрицы всегда можно добиться, чтобы проверочная
матрица имела бы вид
всегда можно добиться, чтобы проверочная
матрица имела бы вид ,
где
,
где – единичная подматрица. В нашем примере
– единичная подматрица. В нашем примере .
Порождающая матрица может быть задана
в виде
.
Порождающая матрица может быть задана
в виде .
.
Связь между проверочной и порождающей матрицей даёт
Предложение
1.
Если
 – проверочная матрица
– проверочная матрица -кода
-кода ,
то
,
то – его порождающая матрица.
– его порождающая матрица.
Наоборот,
если
 – порождающая матрица кода, то
– порождающая матрица кода, то – его проверочная матрица.
– его проверочная матрица.
Доказательство.
Нужно лишь проверить, что
 .
.
Предложение
2.
Вес
линейного
 -кода
-кода равен
равен любые
любые столбцов проверочной матрицы линейно
независимы, но некоторые
столбцов проверочной матрицы линейно
независимы, но некоторые столбцов линейно зависимы.
столбцов линейно зависимы.
Доказательство.
 .
Допустим противное. Пусть столбцы с
номерами
.
Допустим противное. Пусть столбцы с
номерами линейно зависимы. Тогда, взяв вектор
линейно зависимы. Тогда, взяв вектор с единицами на указанных местах и нулями
на остальных, получим, что
с единицами на указанных местах и нулями
на остальных, получим, что .
Но тогда
.
Но тогда – кодовое слово с весом, меньшим
– кодовое слово с весом, меньшим .
Противоречие.
.
Противоречие.
 .
Любой вектор веса меньше
.
Любой вектор веса меньше
 не может быть кодовым словом, и существует
вектор
не может быть кодовым словом, и существует
вектор веса
веса ,
являющийся кодовым словом.
,
являющийся кодовым словом.
Предложение доказано.
Следствие.
 .
.
Доказательство.
Число линейно независимых столбцов не
превосходит числа строк матрицы
 .
Поэтому
.
Поэтому .
.
Предложение
3.
Линейный
код
 обнаруживает
обнаруживает ошибок
ошибок вес кода
вес кода .
.
Линейный
код
 исправляет
исправляет ошибок
ошибок вес кода
вес кода .
.
Доказательство.
Действительно, если вес кода равен
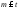 ,
то найдутся два кодовых слова
,
то найдутся два кодовых слова и
и ,
расстояние между которыми равно
,
расстояние между которыми равно .
Тогда, сделав
.
Тогда, сделав ошибок, возможно, мы вместо кодового
слова
ошибок, возможно, мы вместо кодового
слова на приёме получим слово
на приёме получим слово .
Но тогда, получив кодовое слово, у нас
не будет оснований утверждать наличие
ошибок. Если же вес кода не менее чем
.
Но тогда, получив кодовое слово, у нас
не будет оснований утверждать наличие
ошибок. Если же вес кода не менее чем ,
то при наличии не более
,
то при наличии не более ошибок на приёме мы не получим кодового
слова и, таким образом, сможем констатировать
наличие ошибок.
ошибок на приёме мы не получим кодового
слова и, таким образом, сможем констатировать
наличие ошибок.
Далее.
Пусть
 .
Если
.
Если ,
то множество
,
то множество
 назовём шаром радиуса
назовём шаром радиуса с центром в точке
с центром в точке .
Очевидно, что если
.
Очевидно, что если ,
то шары
,
то шары и
и не могут пересекаться. Поэтому, если в
слове
не могут пересекаться. Поэтому, если в
слове сделано не более чем
сделано не более чем ошибок, то полученное слово
ошибок, то полученное слово останется в шаре
останется в шаре и мы его декодируем как
и мы его декодируем как ,
т.е. ошибки будут исправлены. Если же
,
т.е. ошибки будут исправлены. Если же ,
то некоторые шары
,
то некоторые шары и
и могут пересекаться и тогда слово
могут пересекаться и тогда слово после того, как в нём сделано
после того, как в нём сделано ошибок, может попасть в шар
ошибок, может попасть в шар ,
и в этом случае мы не сможем его правильно
декодировать.
,
и в этом случае мы не сможем его правильно
декодировать.
Предложение доказано.
Общая
процедура декодирования линейного кода
 состоит в следующем. Если имеется
линейный
состоит в следующем. Если имеется
линейный -код,
то абелеву группу
-код,
то абелеву группу мы раскладываем в смежные классы по
подгруппе
мы раскладываем в смежные классы по
подгруппе .
В каждом смежном классе выбираем слово
наименьшего веса
.
В каждом смежном классе выбираем слово
наименьшего веса .
Если в данном смежном классе несколько
слов наименьшего веса, выбираем любое
из них. Выбранное слово называется
лидером. Если на приём поступило слово
.
Если в данном смежном классе несколько
слов наименьшего веса, выбираем любое
из них. Выбранное слово называется
лидером. Если на приём поступило слово ,
и это слово содержится в
,
и это слово содержится в -м
смежном классе, то мы декодируем его
как
-м
смежном классе, то мы декодируем его
как .
Таким образом, данный код будет исправлять
в точности те ошибки, которые совпадают
с лидерами смежных классов.
.
Таким образом, данный код будет исправлять
в точности те ошибки, которые совпадают
с лидерами смежных классов.
Пример
2 (продолжение).
Разложение абелевой группы
 по подгруппе
по подгруппе имеет следующий вид
имеет следующий вид

Лидеры
смежных классов расположены в первой
строчке. Допустим, что на вход поступает
слово
 .
Сначала оно кодируется как
.
Сначала оно кодируется как .
Предположим, что при передаче по каналу
связи во втором разряде была допущена
ошибка, и на приёме получено слово
.
Предположим, что при передаче по каналу
связи во втором разряде была допущена
ошибка, и на приёме получено слово .
Это слово содержится в четвёртом смежном
классе, поэтому при декодировании к
нему прибавляется лидер этого смежного
класса:
.
Это слово содержится в четвёртом смежном
классе, поэтому при декодировании к
нему прибавляется лидер этого смежного
класса: .
В результате мы получаем слово
.
В результате мы получаем слово ,
которое после отсечения последних двух
разрядов будет равно
,
которое после отсечения последних двух
разрядов будет равно .
Таким образом, ошибка исправлена.
.
Таким образом, ошибка исправлена.
Для
того чтобы исправить одну ошибку, можно
действовать и по-другому. Если умножить
проверочную матрицу
 на вектор
на вектор ,
то получится слово
,
то получится слово .
Оно называется синдромом и равно тому
столбцу проверочной матрицы, в котором
допущена ошибка. В данном случае слово
.
Оно называется синдромом и равно тому
столбцу проверочной матрицы, в котором
допущена ошибка. В данном случае слово совпадает со вторым столбцом матрицы
совпадает со вторым столбцом матрицы ,
поэтому в слове
,
поэтому в слове нужно исправить второй разряд.
нужно исправить второй разряд.
Заметим, что если бы ошибка произошла на первом или третьем разрядах, то слово было бы декодировано неправильно. Это свидетельствует о том, что данный код ещё очень мало эффективен в плане исправления ошибок. Далее мы познакомимся с более эффективными кодами.