

ЗКИ 4 ПрПр(2) / Потменский пособие по ПРПР
.pdfтаблицу INVOICE поместить столбец CustomerName, то она не будет соответствовать критерию третьей нормальной формы, т.к. эти два столбца могут зависеть друг от друга. При изменении значения поля CustomerNo может возникнуть необходимость в изменении значения поля CustomerName и наоборот. Таким образом, столбец CustomerName нужно вынести в отдельную таблицу и при необходимости обращаться к нему с помощью объединения.
Нормальная форма Бойса-Кодда (НФБК)
Усовершенствованная третья нормальная форма называется нормальной формой Бойса-Кодда (НФБК). Она требует, чтобы каждый столбец, от которого зависит другой, сам являлся уникальным ключом. Наборы столбцов, которые могут однозначно идентифицировать строки, называются потенциальными ключами (candidate key). Первичный ключ таблицы выбирается из таких потенциальных ключей. НФБК требует, чтобы любой зависимый столбец зависел только от потенциальных ключей. Таким образом, НФБК улучшает третью нормальную форму путем разрешения зависимости между неключевыми столбцами и потенциальными ключами. Однако здесь нет никакого нарушения третьей нормальной формы, как может показаться на первый взгляд, поскольку неключевые атрибуты зависят от потенциальных ключей, которые также могут однозначно идентифицировать строки как первичный ключ.
Пусть имеется отношение ПРОЕКТ (Д#, ПР#, П#), отражающее использование в проектах деталей, поставляемых поставщиком. В проекте используется несколько деталей, но каждая деталь проекта поставляется только одним поставщиком. Каждый поставщик обслуживает только один проект, но проекты могут обеспечиваться разными поставщиками (разных деталей). Детали, проекты, поставщики идентифицируются соответствующими номерами Д#, ПР#, П#. В отношении присутствуют следующие функциональные зависимости:
Д#, ПР# П# (по определению ключа), П# ПР#.
Рассматриваемое отношение находится в 3НФ, т.к. в нем отсутствуют неполные функциональные зависимости и транзитивные зависимости непервичных атрибутов от ключей, при этом, однако, наблюдается ряд аномалий.
Аномалии. Факт поставки поставщиком деталей для проекта не может быть занесен в базу данных до тех пор, пока в проекте действительно не будут использоваться эти детали (аномалия включения). Если последний из типов деталей, поставляемых поставщиком для проекта, использован, данные о поставщике также будут удалены из базы данных (аномалия удаления). Если меняется поставщик некоторого типа деталей для проекта, необходим пересмотр отношений для изменения всех кортежей, содержащих эти детали (аномалия обновления). Разложение исходного отношения в НФБК устраняет перечисленные аномалии. Отношение находится в НФБК, если находится в
121
3НФ и в нем отсутствуют зависимости первичных атрибутов от непервичных. Эквивалентное определение требует, чтобы все домены функциональных зависимостей были возможными ключами. Для этого необходимо устранить в данном отношении зависимость:
П# ПР#.
Следующее разложение приводит к отношениям в НФБК: Проект — деталь (Д# ПР#), поставки (П# ПР#).
Многозначные зависимости
До сих пор шла речь лишь о функциональных зависимостях. В отношениях существуют и другие зависимости. Одними из них являются многозначные зависимости данного атрибута В от другого атрибута А в отношении R, содержащем и другие атрибуты. Говорят, что А многозначно определяет В в R (или что В многозначно зависит от А), обозначая указанную зависимость А В, если каждому значению А соответствует множество (возможно, пустое) значений В, никак не связанных с другими атрибутами R. Это можно проиллюстрировать на примере отношения:
ПРЕПОДАВАТЕЛЬ (ИД#, АСПИРАНТЫ, КУРСЫ, ДОЛЖНОСТЬ), содержащего данные об аспирантах преподавателя, читаемых им курсах и его должности. Между преподавателем и аспирантами имеется связь типа 1 : М, а между преподавателем и курсами связь М : N. Если предположить, что некоторые курсы могут читать несколько преподавателей, экстенсионал отношения будет иметь следующий вид:
ид# |
АСПИРАНТЫ |
КУРСЫ |
ДОЛЖНОСТЬ |
525-111 |
Иванов |
К410 |
Доцент |
525-111 |
Климов |
К412 |
Доцент |
525-111 |
Иванов |
К412 |
Доцент |
525-111 |
Климов |
К410 |
Доцент |
Если объявляется многозначная зависимость атрибутов АСПИРАНТЫ и КУРСЫ от атрибута ИД#, каждому значению атрибута ИД# должно соответствовать фиксированное множество значений атрибутов АСПИРАНТЫ и КУРСЫ соответственно. Другими словами, возможно изменение значения этих атрибутов в любой строке отношений. Замена значения атрибута КУРСЫ в кортеже < 525—111 Климов К412 Доцент > даст кортеж < 525—111 Климов К410 Доцент >. Замена значения атрибута АСПИРАНТЫ на Иванов даст кортеж < 525—111 Иванов К412 Доцент >. Оба полученных кортежа уже имеются в отношении. Таким образом, другие полученные кортежи никак не связаны со значениями многозначных атрибутов. Следовательно, имеет место ИД# АСПИРАНТЫ и ИД# КУРСЫ. Для наличия в отношении многозначной зависимости необходимо иметь минимум три атрибута — ключ и независимые атрибуты, которых не может быть меньше двух.
122
Четвертая нормальная форма (4НФ)
Отношение находится в 4НФ, если оно находится в НФБК, но в нем отсутствуют многозначные зависимости, которые не являются функциональными.
По другому определению 4НФ требуется, чтобы в отношении для любой нетривиальной многозначной зависимости, т.е. X Y(X 0 или Х U Х Y являются тривиальными), X обязательно содержал ключ отношения.
Следующие отношения находятся в 4НФ: R1 (ИД#, АСПИРАНТЫ),
R2 (ИД#, КУРСЫ), R3 (ИД#, должность).
Четвертая нормальная форма показывает, что отношение может находиться в НФБК. И тем не менее могут существовать некоторые аномалии, особенно при обновлениях. Например, если у преподавателя появится еще один аспирант, в отношении необходимо добавить не один кортеж, а столько, сколько преподаватель читает курсов (аналогичная ситуация возникает при появлении нового курса, читаемого преподавателем). Эти многократные модификации необходимы для сохранения независимости между всеми возможными значениями атрибутов.
Четвертая нормальная форма запрещает существование между столбцами многозначной зависимости. Если столбец не идентифицирует однозначно другой столбец, а лишь ограничивает его до определенных значений, то говорят, что между этими столбцами существует многозначная зависимость. Так, например, рассмотрим таблицу TENANT и RENTMAN. Предположим, что информация, которую вы хотите сохранить в этой таблице о работодателе и арендаторе, ограничивается лишь фамилией работодателя. Для хранения этой информации в сущности TENANT создает атрибут Employer. Однако если у арендатора более одного работодателя, вам понадобятся записи в таблице TENANT по одной строке для каждого работодателя. Все атрибуты таких строк будут идентичными, за исключением атрибута Employer.
Таким образом, связи между столбцами таблицы TENANT и столбцом Employer могут принять форму многозначной зависимости: у одного и того же значения столбца Tenant_No может быть несколько значений Employer. На практике операция приведения таблицы к четвертой нормальной форме выполняется достаточно трудно. Декомпозиция сущностей даже до третьей нормальной формы иногда дает столько новых сущностей, что разработчикам становится трудно с ними справиться.
Пятая нормальная форма 5НФ (проекция/соединение)
Согласно критерию пятой нормальной формы, если таблица имеет три или более потенциальных ключа и можно привести ее декомпозицию без потери данных, то такую таблицу расщепляют для каждого потенциального ключа. Приведение таблицы к пятой нормальной форме выполняется редко.
123
Тот факт, что отношение может быть восстановлено без потерь соединения некоторых его проекций, известна как зависимость по соединению. Говорят, что отношение находится в пятой нормальной форме тогда и только тогда, когда любая зависимость по соединению в R определяется возможными ключами R. Другими словами, каждая проекция R содержит не менее одного возможного ключа и по крайней мере один непервичный атрибут.
Различия 5НФ и 4НФ можно показать на примере. Пусть имеются отношения:
R1 (П#,Д#, ОТД) |
|
R2 (П#, Д#) |
|
R3 (Д#, ОТД) |
|
R4 (П#, ОТД) |
|
|
|
|
|
|
|
П1 Д1 А |
|
П1 Д1 |
|
Д1 А |
|
П1 А |
|
|
|
|
|
|
|
П1 Д1 В |
|
П2 Д1 |
|
Д1 В |
|
П1 В |
|
|
|
|
|
|
|
П2 Д1 А |
|
П2 Д2 |
|
Д2 А |
|
П2 А |
|
|
|
|
|
|
|
П2 Д2 В |
|
П3 Д1 |
|
Д2 В |
|
П2 В |
|
|
|
|
|
|
|
П3 Д1 В |
|
П3 Д2 |
|
|
|
П3 А |
|
|
|
|
|
|
|
П3 Д2 А |
|
|
|
|
|
П3 В |
|
|
|
|
|
|
|
В отношении R1 отсутствуют независимые многозначные зависимости и оно состоит только из первичных атрибутов, следовательно оно находится в 4НФ. Отношения R2, R3 и RA находятся в 5НФ, т. к. R1 удовлетворяет зависимости по соединению R2, R3 и R4. Преимущество схемы с R2, R3 и R4 над R1 состоит в том, что она устраняет избыточность, а вместе с ней аномалии атрибутов.
8.6. Распределенные базы данных
Общение компьютеров в ЛВС
Когда происходит общение компьютеров, они вынуждены принимать некоторые решения относительно процесса обмена данными.
Алгоритм обработки адресного сообщения (рис. 8.8):
1)по мере того как компьютер прослушивает канал, чтобы обнаружить сообщение, адресованное ему, ему необходим механизм, благодаря которому он может определить, следует ли обнаруженный сигнал рассматривать как несущий информацию или рассматривать его как шум;
2)предположим, что получен не шумовой сигнал, далее компьютер должен решить, адресован ли сигнал ему или другому компьютеру;
3)каким образом во время принятия сигнала из канала компьютер может решать, что сообщение окончено? После того как компьютер определит, что сообщение окончено, он должен отбрасывать все последующие сигналы, пока не начнется передача нового сообщения;
124
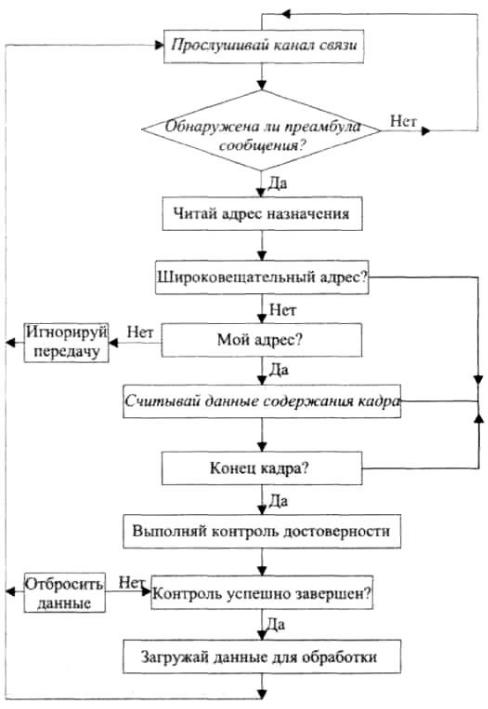
4)когда прием данных завершен, как очистить данные от шума или исправить испорченные данные?
Рис. 8.8. Алгоритм обработки компьютером адресного сообщения Чтобы обеспечить выполнение этой задачи, данные пересылаются с
помощью кадров данных, которые содержат, кроме собственного сообщения, еще и вспомогательную информацию (рис. 8.9).
На рисунке показан формат IEEЕ 802.3 Ethernet Data Link Technology.
Когда такой пакет передается, вначале передается поле преамбулы. Оно состоит из чередующейся последовательности 0 и 1, причем последний бит обязательно равен 0. Так как маловероятно, что такая последовательность может быть следствием шума, поле преамбулы служит в качестве сигнала,
125
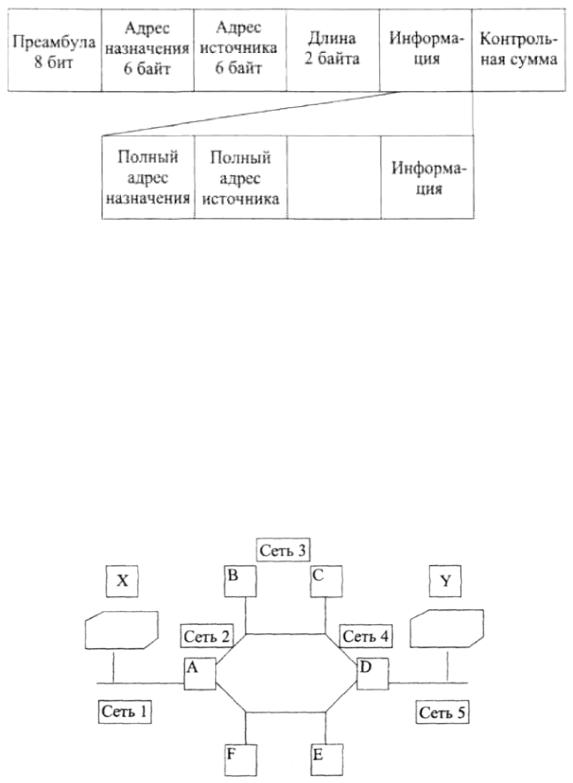
привлекающего внимание компьютеров в сети к предстоящей передаче сообщения.
Рис. 8.9. Структура данных кадра сообщения Следующее поле содержит адрес передачи данных. Это поле позволяет
компьютеру определить, адресованы ли данные ему. Это производится путем сравнения адресов, записанных в сообщении, и адреса, записанного в сетевой плате компьютера. В процессе приема различаются адреса компьютера и широковещательный адрес, обычно у последнего все биты устанавливаются равными 1. Адрес источника говорит о том, кто является отправителем сообщения.
Четвертое поле описывает длину информационного и говорит об окончании информационной части сообщения.
Последнее поле FCS frame check sequence — последовательность контроля кода представляет собой 32-битовое циклическое число, которое проверяет правильность всех полей, за исключением преамбулы.
Рис. 8.10. Глобальная информационно-вычислительная сеть
Проблема маршрутизации
Одна из проблем сетевой технологии заключается в обработке трафика в сети из сетей.
Предположим, что рабочая станция X в сети 1 хочет послать сообщение
126
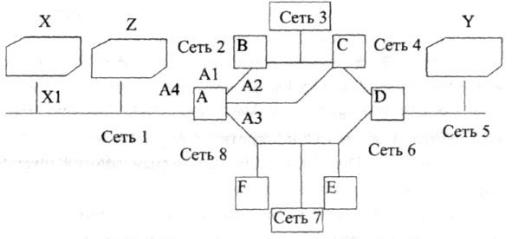
станции Y в сети 5 (рис. 8.10). Возникает вопрос: каким образом данные будут переданы через промежуточные устройства?
Для этого используются два механизма: мосты и маршрутизаторы. Помимо адреса сетевой карты (Data link address), который гарантированно
является однозначным для каждой рабочей станции, все рабочие станции должны иметь более общий сетевой адрес. Этот сетевой адрес подобен по функции и цели названию улицы. Когда вашей конторе адресуется сообщение, служба доставки в первую очередь обеспокоена поиском улицы, а затем уже конкретного адреса дома.
В отличие от Data Link Address, который зашит в сетевой карте, сетевой адрес конфигурируют как часть инсталляции сети. Полный адрес должен включать достаточно информации, чтобы определить как сетевой адрес, так и
Data Link Address.
Таблицы маршрутизации (Routing Table)
Процесс маршрутизации обеспечивается процессом определения пути, который ответственен за поддержание карты маршрутов сети. Такие карты называются таблицами маршрутизации (табл. 1).
Таблица 8.6.1
Маршрутизация для рабочей станции X
Destination network |
Distance |
Next router |
Output port |
|
|
|
|
5 |
3 |
A |
XI |
|
|
|
|
Дополнительная колонка «выходной порт» в этих таблицах представляет метки, идентифицирующие коммуникационные интерфейсы, которые соединяют рабочую станцию или роутер с сетями.
Например, А1 и А2 представляют коммуникационные интерфейсы, которые соединяют роутеры с сетями 2 и 3 соответственно (рис. 8.8.4).
Рис. 8.11. Использование выходных потоков станции А для подключения к нескольким сетям
Первую строку в таблице 8.8.2 можно интерпретировать следующим образом: роутер А находится на расстоянии двух роутеров от сети 5 (С и D).
127
Следовательно, если роутер А должен отправить данные сети 5, он должен обратиться за помощью к роутеру С, направляя данные непосредственно ему через порт А2, который соединяет А с сетью 4.
Таблица 8.6.2
Маршрутизация роутера А
Destination network |
Distance |
Next router |
Output port |
|
|
|
|
5 |
2 |
С |
A2 |
|
|
|
|
2 |
0 |
A |
Al |
|
|
|
|
7 |
1 |
F |
A3 |
|
|
|
|
… |
… |
… |
… |
|
|
|
|
Роутер должен быть в состоянии выбрать кратчайший путь между двумя сетями.
Интеллигентный выбор пути означает, что роутер должен быть в состоянии направлять данные, используя кратчайший путь, связывающий две сети.
После того как данные поступили в компьютер, возникает вопрос, какому процессу их передать. Этот процесс связан с мультиплексированием, демультиплексированием данных.
Протокол — это множество взаимноприемлемых правил на обоих концах коммуникации для упорядоченного обмена данными.
8.7. Архитектура протокола ТСР/IР
В таблице 1 приведено сопоставление протоколов.
Таблица 8.7.1
Сопоставление протоколов OSI и TCP/IP
OSI |
TCP/IP |
Application |
Application layer |
Presentation |
|
Session |
|
Transport |
Host-to-Host |
Network |
Internet |
Data Link |
Network access |
Physical |
|
Инкапсуляция данных протоколом TCP/IP DATA
На транспортном уровне заголовок сообщения содержит номера портов пункта назначения и источника (рис. 8.9.1).
128
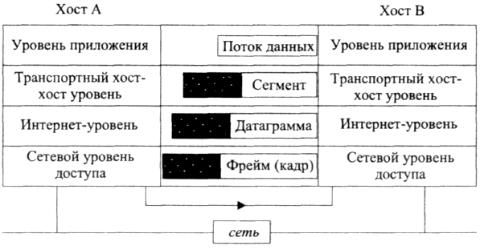
Рис. 8.12. Структура сообщения на различных уровнях протокола
TCP/IP
Они рассматриваются как номера, идентифицирующие процесс, которые помогают обмену инкапсулированными данными между процессами, обеспечивая однозначную идентификацию процессов, исполняемых на хостах на фоне или наряду с другими процессами. Данные и заголовок вместе образуют на этом уровне сегмент данных.
На уровне Интернета заголовок также содержит IP-адрес (т.е. полный адрес) целевой системы. Данные и заголовок на этом уровне образуют элемент, называемый IР-датаграммой.
На уровне сетевого доступа (Network Access) заголовок включает контроль среды (Media Access Control — MAC), адреса приборов источника и назначения, общающихся в той же самой физической сети. Элемент данных, формируемый на этом уровне, называется кадр данных. На рис. 2 показана структура данных IР-датаграммы.
Version |
|
IHL |
|
|
SERVICE TYPE |
TOTAL Length |
|
|
Identification |
flags |
JFragment offset |
||||
Time to live |
|
|
Protocol |
Header checksum |
|||
|
|
|
|
Source IP address |
|
|
|
|
|
|
Destination IP address |
|
|
||
|
IP Options |
|
|
|
|
Padding |
|
|
|
|
|
|
Data |
|
|
|
|
|
|
……………… |
|
|
|
Рис. 8.13. Структура данных IР-датаграммы
Основное свойство IP бесконтактный протокол, т.е. он не предполагает:
—установления связи со станцией до передачи ее данных;
—не обеспечивает обнаружения и исправления ошибок. Функции IP:
—инкапсуляция данных и приписывание заголовков,
—маршрутизация данных в интерсети,
—передача данных другим протоколам,
129
—фрагментирование и реассемблирование данных.
Хотя IP является ненадежным протоколом т.к. не обнаруживает и не исправляет ошибки, он заботится о контроле информации заголовков. С помощью поля Header Checksum IP проверяет целостность данных в полях Header, если проверка не проходит — датаграмма отбрасывается.
8.8. IP-маршрутизация (IP routing)
IP-маршрутиризация является простейшей, но наиболее эффективной. IP различает хост и шлюз. Шлюз в TCP/IP в действительности роутер, который соединяет две или более сети.
По умолчанию маршрутизация на хостах ограничена отправкой датаграммы на удаленную систему, если оба хоста прикреплены к одной и той же сети. Если нет — IP отправляет датаграмму шлюзу умолчания (т.е. роутеру). Шлюз умолчания, определенный на хосте во время конфигурирования TCP/ IP,
— это роутер, прикрепленный к той же самой сети, что и хост. Хост X конфигурируется таким образом, что А есть его шлюз умолчания. Соответственно, когда X хочет послать данные Y, он направляет датаграмму шлюзу А (шлюз умолчания), а не В. По изучению IP-адреса пункта назначения шлюз А понимает, что адрес посылки принадлежит хосту Y, который находится в сети, с которой связан шлюз В. Следовательно, шлюз А отправляет датаграмму шлюзу В с последующей передачей хосту Y.
Внастоящее время обычно проводят различия между роу-тером и шлюзом. Говорят, что роутер обеспечивает услуги маршрутизации между одинаковыми (в смысле протокола) сетями. Шлюзы, с другой стороны, связывают сети с различной архитектурой, например TCP/IP и Apple Talk.
Интернет-уровень IP-протокола и маршрутизация
Для создания интерсети, соединяющей физически различные типы, чтобы они могли выглядеть как одна логическая сеть, необходима информация маршрутизации. В соответствии с этой целью создается уникальное множество адресов, которое идентифицирует каждую сеть в интерсети. Этот адрес называется сетевым адресом, становится частью адреса, идентифицируя каждый хост в этой сети.
ВTCP/IP каждый прибор в сети получает уникальный полный сетевой адрес в процессе конфигурирования. Приписываемый прибору адрес известен как символический IP-адрес и составлен из двух частей: (1) адрес сети, который является общим для всех хостов и приборов в одной и той же физической сети,
и(2) адрес узла, который является уникальным для хоста в этой сети. Они не связаны непосредственно с теми адресами, которые записаны в сетевой карте, и поэтому называются символическими.
IP-адрес содержит 32 бита (4 байта), включая адрес сети и хоста. Он занимает в IP-заголовке поле адреса источника и пункта назначения. Соотношение между количеством бит, отводимых для адреса сети и для адреса хоста, определяется классом адреса.
IP определяет три главных класса сетей: А, В, С (рис. 3). Имеется также
130