

Управл_данными / 01-Введение
.pdfРазвитие технологий обработки данных
11

Этап 1. Файлы последовательного доступа.
Обработка данных осуществлялась в основном при помощи операций ввода – вывода.
•Порция данных, поступающая за одну такую операцию называется записью.
Файлы организованны последовательным способом.
При этом физическая структура данных и логическая структура файла совпадали.
•Пользователям файл в этой ситуации представляется как линейная последовательность записей, где структура записей файла известна только программе, которая с ним работает, поскольку эта структура содержится только в ней.
Если структура файла изменяется, требуется вносить изменения и в саму программу - зависимость программ от данных.
Другая проблема – значительная избыточность данных в файлах.
•- при рассматриваемом способе организации данных часто возникает необходимость хранения нескольких копий одного и того же файла, отсортированных по различным полям записи.
12
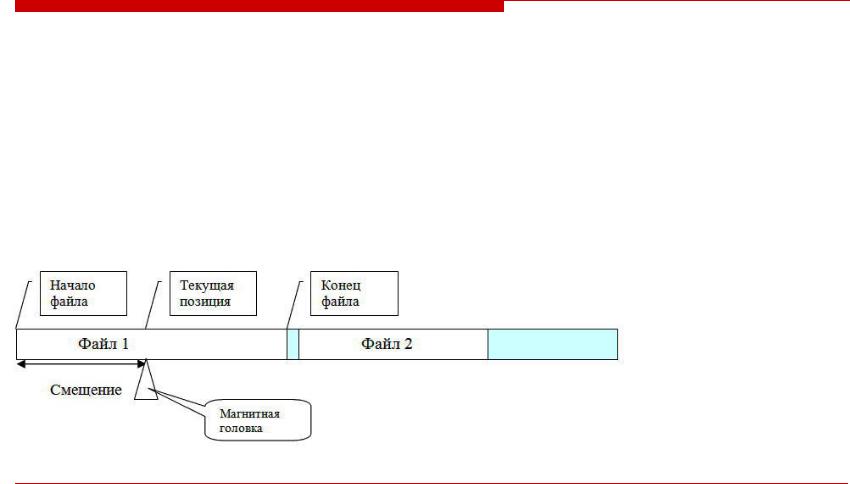
Последовательный доступ – файлы на лентах
Сначала файлы хранились на магнитных лентах (и перфолентах). Это определило способ доступа.
Для того, чтобы найти нужный (N-й) файл, необходимо перемотать ленту в начало, затем пропустить N-1 файлов. Установить магнитную головку в начало файла (смещение от начала = 0 байт).
Далее, для того, чтобы найти нужную запись, нужно установить заданное смещение
После этого можно считывать искомую порцию информации в оперативную память.
Запись данных можно производить только в конец последнего файла.
13

Последовательный доступ - файлы на дисках
С появлением дисковых накопителей стало возможным находить нужный файл сразу, не проматывая диск от начала.
Однако операции по поиску информации внутри файла остались прежними.
Для того, чтобы найти нужное слово в файле последовательного доступа нужно читать все слова от начала, до тех пор пока не попадется искомое.
Скорость доступа при больших размерах файлов оставалась низкой.
Организовать настоящую БД, используя такие файлы – невозможно.
Однако такие файлы широко используются и до сих пор, при небольших объема данных. Пример - текстовые файлы.
14

Этап 2. Файлы прямого доступа
Возможны только на дисковых накопителях.
Принцип файлов прямого доступа состоит в том, что есть способ вычислить смещение для N-й записи, а затем прочитать её за одну операцию.
Увеличилась производительность – новые устройства памяти.
В результате:
появилось некоторое различие логической и физической структуры данных;
некоторая независимость программ от данных;
15

Недостатки
Сохраняется зависимость приложений от структуры данных.
Сохраняется значительная избыточность данных.
Отсутствует централизованный контроль на уровне элементов данных. Часто один и тот же элемент данных имеет несколько имен.
Требуются большие затраты труда программистов при определении новых данных.
Очень сложные процедуры манипулирования данными.
Не устранены сложности администрирования доступом к файлу, а следовательно и сложность реализации многопользовательского режима работы.
16

Этап 3. БД и СУБД
Необходимость решения этих проблем заставила разработчиков ИС предложить новые концепции:
1.Для хранения информации должны использоваться базы данных (БД).
2.Для управления информацией – Системы управления базами данных (СУБД)
Дальнейшая история развития систем обработки данных – это эпоха развития БД и СУБД.
17

Базы данных (БД)
Базы данных (БД) – это единое, вместительное хранилище разнообразных данных и описаний их структур, которое после своего определения, осуществляемого отдельно и независимо от приложений, используется одновременно многими приложениями.
Хранимые данные организованы в совместно используемые наборы и логически связаны между собой, в соответствии с предметной областью.
Поскольку структуры данных определяются отдельно от приложений и хранятся в БД, то изменение структуры не влияет на приложения, не использующие измененные данные.
Базы данных управляются с помощью СУБД.
 18
18

Системы управления базами данных (СУБД)
СУБД– это программное обеспечение, с помощью которого можно:
Определять БД, структуру ее данных, а также задавать ограничения для хранимых данных.
Манипулировать данными.
Предоставлять контролируемый доступ к информации БД.
Осуществлять поддержку обеспечения безопасности данных.
Обеспечивать целостность данных.
Управлять многопользовательским режимом работы, контролируя процессы совместного доступа к данным.
Восстанавливать информацию БД, потерянную в результате различных аппаратных или программных сбоев.
19
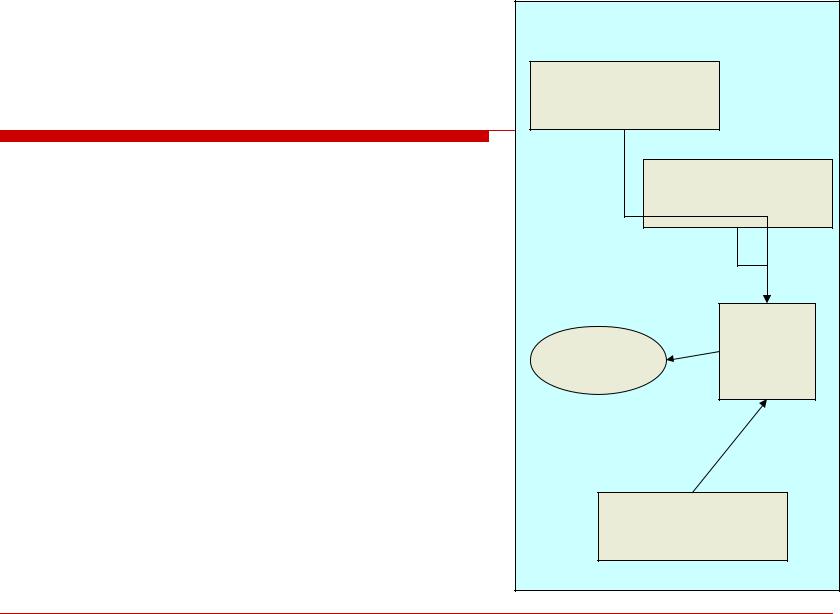
|
СУБД – это отдельные |
ИС |
|
|
программы, или библиотеки |
|
|
|
функций |
Приложение 1 |
|
|
Приложения работают с |
|
Приложение 2 |
|
данными не напрямую, а |
|
|
|
через СУБД |
|
|
|
Происходит выделение |
|
|
|
описания структуры данных |
|
|
|
Появилась независимость |
БД |
СУБД |
|
приложений от данных |
||
|
|
||
|
Поиск возможен по многим |
|
|
|
ключам |
|
|
|
уменьшения избыточности |
|
|
|
данных |
Приложение 3 |
|
|
|
||
|
|
|
20 |