Chapter 36. Working with Panel Data
EViews provides you with specialized tools for working with stacked data that have a panel structure. You may have, for example, data for various individuals or countries that are stacked one on top of another.
The first step in working with stacked panel data is to describe the panel structure of your data: we term this step structuring the workfile. Once your workfile is structured as a panel workfile, you may take advantage of the EViews tools for working with panel data, and for estimating equation specifications using the panel structure.
The following discussion assumes that you have an understanding of the basics of panel data. “Panel Data,” beginning on page 216 of User’s Guide I provides background on the characteristics of panel structured data.
We first review briefly the process of applying a panel structure to a workfile. The remainder of the discussion in this chapter focuses on the basics working with data in a panel workfile. Chapter 37. “Panel Estimation,” on page 647 outlines the features of equation estimation in a panel workfile.
Structuring a Panel Workfile
The first step in panel data analysis is to define the panel structure of your data. By defining a panel structure for your data, you perform the dual tasks of identifying the cross-section associated with each observation in your stacked data, and of defining the way that lags and leads operate in your workfile.
While the procedures for structuring a panel workfile outlined below are described in greater detail elsewhere, an abbreviated review may prove useful (for additional detail, see “Describing a Balanced Panel Workfile” on page 38, “Dated Panels” on page 230, and “Undated Panels” on page 235 of User’s Guide I).
Structuring a Panel Workfile—617
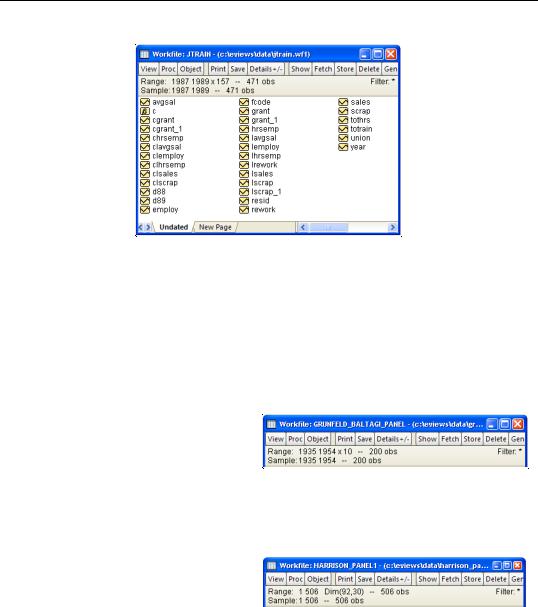
Suppose that we have data for the job training example considered by Wooldridge (2002), using data from Holzer, et al. (1993), which are provided in “Jtrain.WF1”.
These data form a balanced panel of 3 annual observations on 157 firms. The data are first read into a 471 observation, unstructured EViews workfile. The values of the series YEAR and FCODE may be used to identify the date and cross-section, respectively, for each observation.
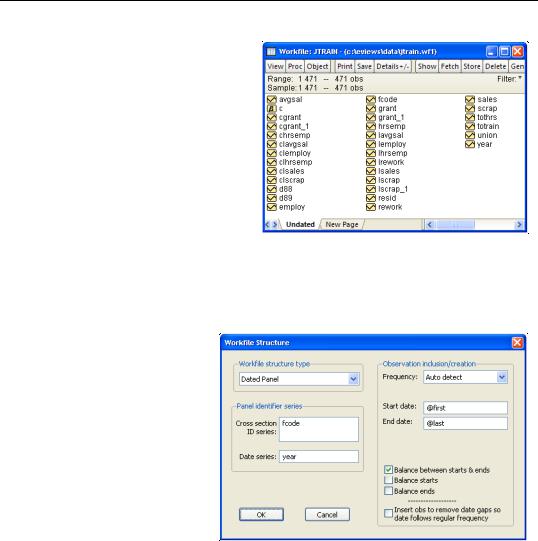
To apply a panel structure to this workfile, simply double click on the “Range:” line at the top of the workfile window, or select Proc/Structure/Resize Current Page... to open the
Workfile structure dialog. Select Dated Panel as our Workfile structure type.
Next, enter YEAR as the Date series and FCODE as the
Cross-section ID series. Since our data form a simple balanced dated panel, we need not concern ourselves with the remaining settings, so we may simply click on OK.
EViews will analyze the data in the specified Date series and Cross-section ID series to determine the appropriate structure for the workfile. The
data in the workfile will be sorted by cross-section ID series, and then by date, and the panel structure will be applied to the workfile.