586—Chapter 35. Pooled Time Series, Cross-Section Data
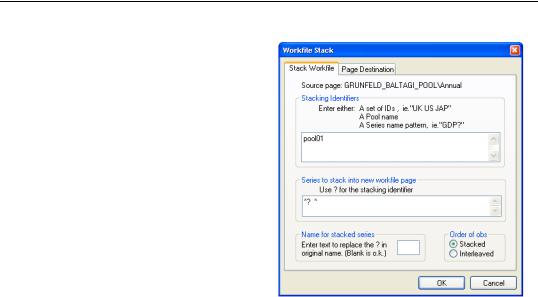
The Order of obs option allows you to order the data in Stacked form (stacking the data by series, which orders by crosssection), or in Interleaved format (stacked the data by interleaving series, which orders the data by period or date).
The default naming rule for series in the destination is to use the base name. For example, if you stack the pool series “SALES?” and the individual series GENDER, the corresponding stacked series will, by default, be named “SALES”, and “GENDER”. If use of the default naming convention will create problems in the destination workfile, you should use the
Name for stacked series field to specify
an alternative. If, for example, you enter “_NEW”, the target names will be formed by taking the base name, and appending the additional text, as in “SALES_NEW” and “GENDER_NEW”.
See “Stacking a Workfile” on page 257 of User’s Guide I for a more detailed discussion of the workfile stacking procedure.
Pooled Estimation
EViews pool objects allow you to estimate your model using least squares or instrumental variables (two-stage least squares), with correction for fixed or random effects in both the cross-section and period dimensions, AR errors, GLS weighting, and robust standard errors, all without rearranging or reordering your data.
We begin our discussion by walking you through the steps that you will take in estimating a pool equation. The wide range of models that EViews supports means that we cannot exhaustively describe all of the settings and specifications. A brief background discussion of the supported techniques is provided in “Estimation Background,” beginning on page 601.
Estimating a Pool Equation
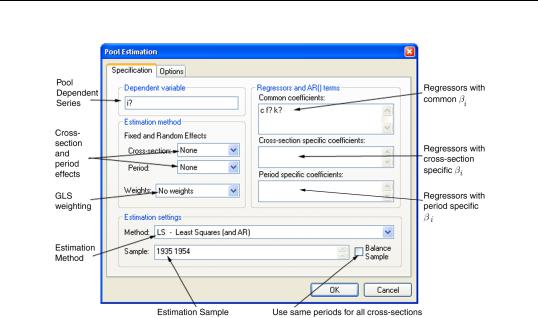
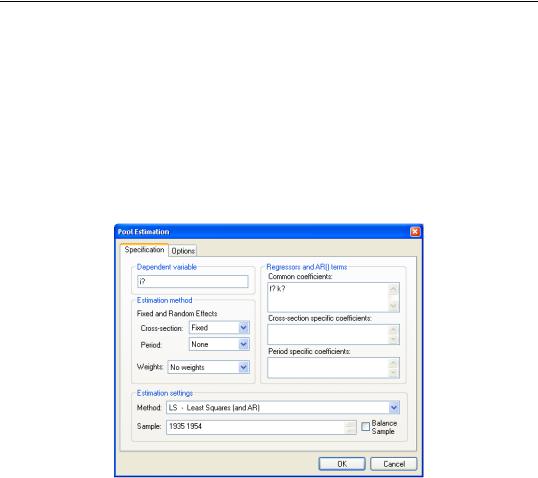
To estimate a pool equation specification, simply press the Estimate button on your pool object toolbar or select Proc/Estimate... from the pool menu, and the basic pool estimation dialog will open:
Pooled Estimation—587
First, you should specify the estimation settings in the lower portion of the dialog. Using the Method combo box, you may choose between LS - Least Squares (and AR), ordinary least squares regression, TSLS - Two-Stage Least Squares (and AR), two-stage least squares (instrumental variable) regression. If you select the latter, the dialog will differ slightly from this example, with the provision of an additional tab (page) for you to specify your instruments (see “Instruments” on page 592).
You should also provide an estimation sample in the Sample edit box. By default, EViews will use the specified sample string to form use the largest sample possible in each crosssection. An observation will be excluded if any of the explanatory or dependent variables for that cross-sectionare unavailable in that period.
The checkbox for Balanced Sample instructs EViews to perform listwise exclusion over all cross-sections. EViews will eliminate an observation if data are unavailable for any cross-sec- tion in that period. This exclusion ensures that estimates for each cross-section will be based on a common set of dates.
Note that if all of the observations for a cross-section unit are not available, that unit will temporarily be removed from the pool for purposes of estimation. The EViews output will inform you if any cross-section were dropped from the estimation sample.
You may now proceed to fill out the remainder of the dialog.
588—Chapter 35. Pooled Time Series, Cross-Section Data
Dependent Variable
List a pool variable, or an EViews expression containing ordinary and pool variables, in the
Dependent Variable edit box.
Regressors and AR terms
On the right-hand side of the dialog, you should list your regressors in the appropriate edit boxes:
•Common coefficients: — enter variables that have the same coefficient across all cross-section members of the pool. EViews will include a single coefficient for each variable, and will label the output using the original expression.
•Cross-section specific coefficients: — list variables with different coefficients for each member of the pool. EViews will include a different coefficient for each crosssectional unit, and will label the output using a combination of the cross-section identifier and the series name.
•Period specific coefficients: — list variables with different coefficients for each observed period. EViews will include a different coefficient for each period unit, and will label the output using a combination of the period identifier and the series name.
For example, if you include the ordinary variable TIME and POP? in the common coefficient list, the output will include estimates for TIME and POP?. If you include these variables in the cross-section specific list, the output will include coefficients labeled “_USA—TIME”, “_UK—TIME”, and “_USA—POP_USA”, “_UK—POP_UK”, etc.
Be aware that estimating your model with cross-section or period specific variables may generate large numbers of coefficients. If there are cross-section specific regressors, the number of these coefficients equals the product of the number of pool identifiers and the number of variables in the list; if there are period specific regressors, the number of corresponding coefficients is the number of periods times the number of variables in the list.
You may include AR terms in either the common or cross-section coefficients lists. If the terms are entered in the common coefficients list, EViews will estimate the model assuming a common AR error. If the AR terms are entered in the cross-section specific list, EViews will estimate separate AR terms for each pool member. See “Estimating AR Models” on page 89 for a description of AR specifications.
Note that EViews only allows specification by list for pool equations. If you wish to estimate a nonlinear specification, you must first create a system object, and then edit the system specification (see “Making a System” on page 583).
Pooled Estimation—589
Fixed and Random Effects
You should account for individual and period effects using the Fixed and Random Effects combo boxes. By default, EViews assumes that there are no effects so that the combo boxes are both set to None. You may change the
default settings to allow for either Fixed or Random effects in either the cross-section or period dimension, or both.
There are some specifications that are not currently supported. You may not, for example, estimate random effects models with cross-section specific coefficients, AR terms, or weighting. Furthermore, while two-way random effects specifications are supported for balanced data, they may not be estimated in unbalanced designs.
Note that when you select a fixed or random effects specification, EViews will automatically add a constant to the common coefficients portion of the specification if necessary, to ensure that the observation weighted sum of the effects is equal to zero.
Weights
By default, all observations are given equal weight in estimation. You may instruct EViews to estimate your specification with estimated GLS weights using the combo box labeled
Weights.
If you select Cross section weights, EViews will estimate a feasible GLS specification assuming the presence of cross-section heteroskedasticity. If you select Cross-section SUR, EViews estimates a feasible GLS specification correcting for both cross-section heteroskedasticity and contem-
poraneous correlation. Similarly, Period weights allows for period heteroskedasticity, while Period SUR corrects for both period heteroskedasticity and general correlation of observations within a given cross-section. Note that the SUR specifications are each examples of what is sometimes referred to as the Parks estimator.
590—Chapter 35. Pooled Time Series, Cross-Section Data
Options
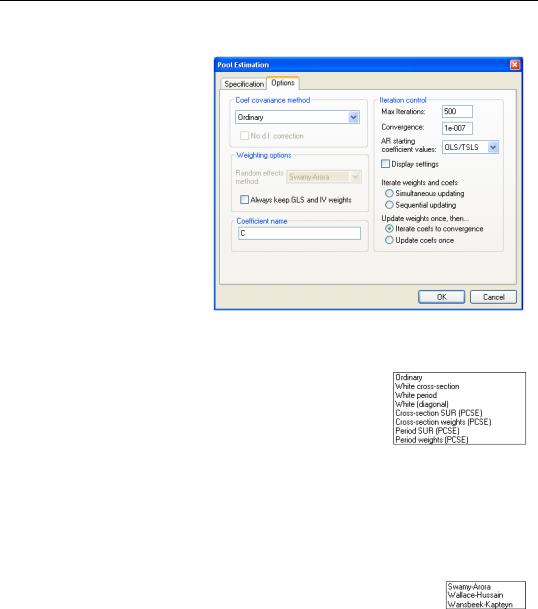
Clicking on the Options tab in the dialog brings up a page displaying a variety of estimation options for pool estimation. Settings that are not currently applicable will be grayed out.
Coef Covariance Method
By default, EViews reports conventional estimates of coefficient standard errors and covariances.
You may use the combo box at the top of the page to select from the various
robust methods available for computing the coefficient standard errors. Each of the methods is described in greater detail in “Robust Coefficient Covariances” on page 611.
Note that the checkbox No d.f. correction permits to you compute robust covariances without the leading degree of freedom correction term. This option may make it easier to match EViews results to those from other sources.
Weighting Options
If you are estimating a specification that includes a random effects specification, EViews will provide you with a Random effects method combo box so that you may specify one of the methods for calculating estimates of the component variances. You may choose between the default Swamy-Arora,Wallace-Hussain, or Wansbeek-Kapteynmethods. See “Random Effects” on page 605 for discussion of the differences between the methods. Note that the default Swamy-Arora method should be the most familiar from textbook discussions.
Details on these methods are provided in Baltagi (2005), Baltagi and
Chang (1994), Wansbeek and Kapteyn (1989).
The checkbox labeled Keep GLS weights may be selected to require EViews to save all estimated GLS weights with the equation, regardless of their size. By default, EViews will not save estimated weights in system (SUR) settings, since the size of the required matrix may be quite large. If the weights are not saved with the equation, there may be some pool views and procedures that are not available.
Pooled Estimation—591
Coefficient Name
By default, EViews uses the default coefficient vector C to hold the estimates of the coefficients and effects. If you wish to change the default, simply enter a name in the edit field. If the specified coefficient object exists, it will be used, after resizing if necessary. If the object does not exist, it will be created with the appropriate size. If the object exists but is an incompatible type, EViews will generate an error.
Iteration Control
The familiar Max Iterations and Convergence criterion edit boxes that allow you to set the convergence test for the coefficients and GLS weights.
If your specification contains AR terms, the AR starting coefficient values combo box allows you to specify starting values as a fraction of the OLS (with no AR) coefficients, zero, or user-specified values.
If Display Settings is checked, EViews will display additional information about convergence settings and initial coefficient values (where relevant) at the top of the regression output.
The last set of radio buttons is used to determine the iteration settings for coefficients and GLS weighting matrices.
The first two settings, Simultaneous updating and Sequential updating should be employed when you want to ensure that both coefficients and weighting matrices are iterated to convergence. If you select the first option, EViews will, at every iteration, update both the coefficient vector and the GLS weights; with the second option, the coefficient vector will be iterated to convergence, then the weights will be updated, then the coefficient vector will be iterated, and so forth. Note that the two settings are identical for GLS models without AR terms.
If you select one of the remaining two cases, Update coefs to convergence and Update coefs once, the GLS weights will only be updated once. In both settings, the coefficients are first iterated to convergence, if necessary, in a model with no weights, and then the weights are computed using these first-stage coefficient estimates. If the first option is selected, EViews will then iterate the coefficients to convergence in a model that uses the first-stage weight estimates. If the second option is selected, the first-stage coefficients will only be iterated once. Note again that the two settings are identical for GLS models without AR terms.
By default, EViews will update GLS weights once, and then will update the coefficients to convergence.
592—Chapter 35. Pooled Time Series, Cross-Section Data
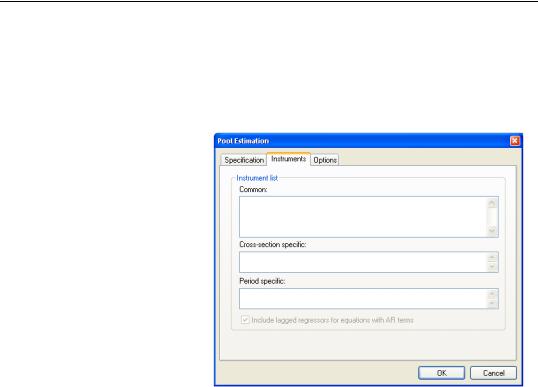
Instruments
To estimate a pool specification using instrumental variables techniques, you should select
TSLS - Two-Stage Least Squares (and AR) in the Method combo box at the bottom of the main (Specification) dialog page. EViews will respond by creating a three-tab dialog in which the middle tab (page) is used to specify your instruments.
As with the regression specification, the instrument list specification is divided into a set of Common, Cross-sec- tion specific, and Period specific instruments. The interpretation of these lists is the same as for the regressors; if there are cross-sec- tion specific instruments, the number of these instruments equals the product of the number of pool identifiers and the number of variables in the list; if there are period specific instruments, the number of corresponding
instruments is the number of periods times the number of variables in the list.
Note that you need not specify constant terms explicitly since EViews will internally add constants to the lists corresponding to the specification in the main page.
Lastly, there is a checkbox labeled Include lagged regressors for equations with AR terms that will be displayed if your specification includes AR terms. Recall that when estimating an AR specification, EViews performs nonlinear least squares on an AR differenced specification. By default, EViews will add lagged values of the dependent and independent regressors to the corresponding lists of instrumental variables to account for the modified differenced specification. If, however, you desire greater control over the set of instruments, you may uncheck this setting.
Pool Equation Examples
For illustrative purposes, we employ the balanced firm-level data from Grunfeld (1958) that have been used extensively as an example dataset (e.g., Baltagi, 2005). The workfile (“Grunfeld_Baltagi_pool.WF1”) contains annual observations on investement (I?), firm value (F?), and capital stock (K?) for 10 large U.S. manufacturing firms for the 20 years from 1935-54.
Pooled Estimation—593
The pool identifiers for our data are “AR”, “CH”, “DM”, “GE”, “GM”, “GY”, “IB”, “UO”, “US”, “WH”.
We obviously cannot demonstrate all of the specifications that may be estimated using these data, but we provide a few illustrative examples.
Fixed Effects
First, we estimate a model regressing I? on the common regressors F? and K?, with a crosssection fixed effect. All regression coefficients are restricted to be the same across all crosssections, so this is equivalent to estimating a model on the stacked data, using the cross-sec- tional identifiers only for the fixed effect.
The top portion of the output from this regression, which shows the dependent variable, method, estimation and sample information is given by:
594—Chapter 35. Pooled Time Series, Cross-Section Data
Dependent Variable: I?
Method: Pooled Least Squares
Date: 12/03/03
Time: 12:21
Sample: 1935 1954
Included observations: 20
Number of cross-sections used: 10
Total pool (balanced) observations: 200
Variable
Coefficient
Std. Error
t-Statistic
Prob.
C
-58.74394
12.45369
-4.716990
0.0000
F?
0.110124
0.011857
9.287901
0.0000
K?
0.310065
0.017355
17.86656
0.0000
Fixed Effects (Cross)
AR--C
-55.87287
CH--C
30.93464
DM--C
52.17610
GE--C
-176.8279
GM--C
-11.55278
GY--C
-28.47833
IB--C
35.58264
UO--C
-7.809534
US--C
160.6498
WH--C
1.198282
EViews displays both the estimates of the coefficients and the fixed effects. Note that EViews automatically includes a constant term so that the fixed effects estimates sum to zero and should be interpreted as deviations from an overall mean.
Note also that the estimates of the fixed effects do not have reported standard errors since EViews treats them as nuisance parameters for the purposes of estimation. If you wish to compute standard errors for the cross-section effects, you may estimate a model without a constant and explicitly enter the C in the Cross-section specific coefficients edit field.
The bottom portion of the output displays the effects specification and summary statistics for the estimated model.
Pooled Estimation—595
Effects Specification
Cross-section fixed (dummy variables)
R-squared
0.944073
Mean dependent var
145.9583
Adjusted R-squared
0.940800
S.D. dependent var
216.8753
S.E. of regression
52.76797
Akaike info criterion
10.82781
Sum squared resid
523478.1
Schwarz criterion
11.02571
Log likelihood
-1070.781
Hannan-Quinn criter.
10.90790
F-statistic
288.4996
Durbin-Watson stat
0.716733
Prob(F-statistic)
0.000000
A few of these summary statistics require discussion. First, the reported R-squared and F- statistics are based on the difference between the residuals sums of squares from the estimated model, and the sums of squares from a single constant-only specification, not from a fixed-effect-only specification. As a result, the interpretation of these statistics is that they describe the explanatory power of the entire specification, including the estimated fixed effects. Second, the reported information criteria use, as the number of parameters, the number of estimated coefficients, including fixed effects. Lastly, the reported Durbin-Wat- son stat is formed simply by computing the first-order residual correlation on the stacked set of residuals.
Robust Standard Errors
We may reestimate this specification using White cross-section standard errors to allow for general contemporaneous correlation between the firm residuals. The “cross-section” designation is used to indicate that non-zero covariances are allowed across cross-sections (clustering by period). Simply click on the Options tab and select White cross-sectionas the coefficient covariance matrix, then reestimate the model. The relevant portion of the output is given by:
White cross-section standard errors & covariance (d.f. corrected)
Variable
Coefficient
Std. Error
t-Statistic
Prob.
C
-58.74394
19.61460
-2.994909
0.0031
F?
0.110124
0.016932
6.504061
0.0000
K?
0.310065
0.031541
9.830701
0.0000
The new output shows the method used for computing the standard errors, and the new standard error estimates, t-statistic values, and probabilities reflecting the robust calculation of the coefficient covariances.
Alternatively, we may adopt the Arellano (1987) approach of computing White coefficient covariance estimates that are robust to arbitrary within cross-section residual correlation
596—Chapter 35. Pooled Time Series, Cross-Section Data
(clustering by cross-section). Select the Options page and choose White period as the coefficient covariance method. The coefficient results are given by.
White period standard errors & covariance (d.f. corrected)
WARNING: estimated coefficient covariance matrix is of reduced rank
Variable
Coefficient
Std. Error
t-Statistic
Prob.
C
-58.74394
26.87312
-2.185974
0.0301
F?
0.110124
0.014793
7.444423
0.0000
K?
0.310065
0.051357
6.037432
0.0000
We caution that the White period results assume that the number of cross-sections is large, which is not the case in this example. In fact, the resulting coefficient covariance matrix is of reduced rank, a fact that EViews notes in the output.
AR Estimation
We may add an AR(1) term to the specification, and compute estimates using Cross-section SUR PCSE methods to compute standard errors that are robust to more contemporaneous correlation. EViews will estimate the transformed model using nonlinear least squares, will form an estimate of the residual covariance matrix, and will use the estimate in forming standard errors. The top portion of the results is given by:
Dependent Variable: I? Method: Pooled Least Squares Date: 08/17/09 Time: 14:45 Sample (adjusted): 1936 1954
Included observations: 19 after adjustments Cross-sections included: 10
Total pool (balanced) observations: 190
Cross-section SUR (PCSE) standard errors & covariance (d.f. corrected)
Convergence achieved after 14 iterations
Variable
Coefficient
Std. Error
t-Statistic
Prob.
C
-63.45169
28.79868
-2.203285
0.0289
F?
0.094744
0.015577
6.082374
0.0000
K?
0.350205
0.050155
6.982469
0.0000
AR(1)
0.686108
0.105119
6.526979
0.0000
Note in particular the description of the sample adjustment where we show that the estimation drops one observation for each cross-section when performing the AR differencing, as well as the description of the method used to compute coefficient covariances.
Pooled Estimation—597
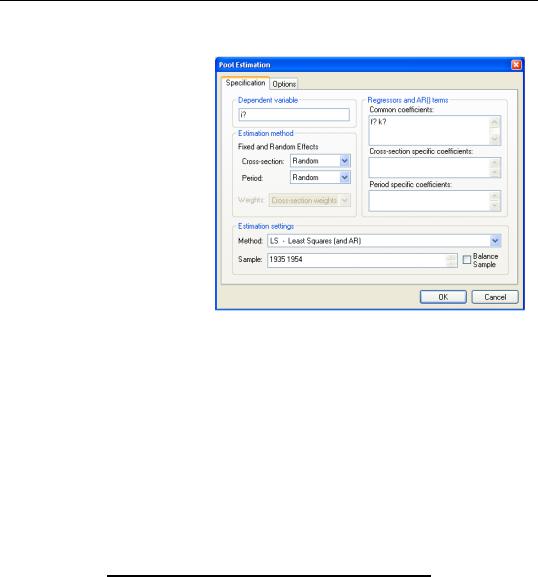
Random Effects
Alternatively, we may produce estimates for the two way random effects specification. First, in the Specification page, we set both the cross-section and period effects combo boxes to Random. Note that the dialog changes to show that weighted estimation is not available with random effects (nor is AR estimation).
Next, in the Options page we estimate the coefficient covariance using the Ordinary
method and we change the Random effects method to use the Wansbeek-Kapteynmethod of computing the estimates of the random component variances.
Lastly, we click on OK to estimate the model.
The top portion of the dialog displays basic information about the specification, including the method used to compute the component variances, as well as the coefficient estimates and associated statistics:
Dependent Variable: I?
Method: Pooled EGLS (Two-way random effects)
Date: 12/03/03 Time: 14:28
Sample: 1935 1954
Included observations: 20
Number of cross-sections used: 10
Total pool (balanced) observations: 200
Wansbeek and Kapteyn estimator of component variances
Variable
Coefficient
Std. Error
t-Statistic
Prob.
C
-63.89217
30.53284
-2.092573
0.0377
F?
0.111447
0.010963
10.16577
0.0000
K?
0.323533
0.018767
17.23947
0.0000
The middle portion of the output (not depicted) displays the best-linear unbiased predictor estimates of the random effects themselves.
598—Chapter 35. Pooled Time Series, Cross-Section Data
The next portion of the output describes the estimates of the component variances:
Effects Specification
S.D.
Rho
Cross-section random
89.26257
0.7315
Period random
15.77783
0.0229
Idiosyncratic random
51.72452
0.2456
Here, we see that the estimated cross-section, period, and idiosyncratic error component standard deviations are 89.26, 15.78, and 51.72, respectively. As seen from the values of Rho, these components comprise 0.73, 0.02 and 0.25 of the total variance. Taking the crosssection component, for example, Rho is computed as:
In addition, EViews reports summary statistics for the random effects GLS weighted data used in estimation, and a subset of statistics computed for the unweighted data.
Cross-section Specific Regressors
Suppose instead that we elect to estimate a specification with I? as the dependent variable, C and F? as the common regressors, and K? as the cross-section specific regressor, using crosssection weighted least squares. The top portion of the output is given by:
Pooled Estimation—599
Dependent Variable: I?
Method: Pooled EGLS (Cross-section weights)
Date: 12/18/03 Time: 14:40
Sample: 1935 1954
Included observations: 20
Number of cross-sections used: 10
Total pool (balanced) observations: 200
Linear estimation after one-step weighting matrix
Variable
Coefficient
Std. Error
t-Statistic
Prob.
C
-4.696363
1.103187
-4.257089
0.0000
F?
0.074084
0.004077
18.17140
0.0000
AR--KAR
0.092557
0.007019
13.18710
0.0000
CH--KCH
0.321921
0.020352
15.81789
0.0000
DM--KDM
0.434331
0.151100
2.874468
0.0045
GE--KGE
-0.028400
0.034018
-0.834854
0.4049
GM--KGM
0.426017
0.026380
16.14902
0.0000
GY--KGY
0.074208
0.007050
10.52623
0.0000
IB--KIB
0.273784
0.019948
13.72498
0.0000
UO--KUO
0.129877
0.006307
20.59268
0.0000
US--KUS
0.807432
0.074870
10.78444
0.0000
WH--KWH
-0.004321
0.031420
-0.137511
0.8908
Note that EViews displays results for each of the cross-section specific K? series, labeled using the equation identifier followed by the series name. For example, the coefficient labeled “AR--KAR” is the coefficient of KAR in the cross-section equation for firm AR.
Group Dummy Variables
In our last example, we consider the use of the @INGRP pool function to estimate an specification containing group dummy variables (see “Pool Series” on page 570). Suppose we modify our pool definition so that we have defined a group named “MYGROUP” containing the identifiers “GE”, “GM”, and “GY”. We may then estimate a pool specification using the common regressor list:
c f? k? @ingrp(mygrp)
where the latter pool series expression refers to a set of 10 implicit series containing dummy variables for group membership. The implicit series associated with the identifiers “GE”, “GM”, and “GY” will contain the value 1, and the remaining seven series will contain the value 0.
The results from this estimation are given by:
600—Chapter 35. Pooled Time Series, Cross-Section Data
Dependent Variable: I?
Method: Pooled Least Squares
Date: 08/22/06 Time: 10:47
Sample: 1935 1954
Included observations: 20
Cross-sections included: 10
Total pool (balanced) observations: 200
Variable
Coefficient
Std. Error
t-Statistic
Prob.
C
-34.97580
8.002410
-4.370659
0.0000
F?
0.139257
0.005515
25.25029
0.0000
K?
0.259056
0.021536
12.02908
0.0000
@INGRP(MYGRP)
-137.3389
14.86175
-9.241093
0.0000
R-squared
0.869338
Mean dependent var
145.9583
Adjusted R-squared
0.867338
S.D. dependent var
216.8753
S.E. of regression
78.99205
Akaike info criterion
11.59637
Sum squared resid
1222990.
Schwarz criterion
11.66234
Log likelihood
-1155.637
Hannan-Quinn criter.
11.62306
F-statistic
434.6841
Durbin-Watson stat
0.356290
Prob(F-statistic)
0.000000
We see that the mean value of I? for the three groups is substantially lower than for the remaining groups, and that the difference is statistically significant at conventional levels.
Pool Equation Views and Procedures
Once you have estimated your pool equation, you may examine your output in the usual ways:
Representation
Select View/Representations to examine your specification. EViews estimates your pool as a system of equations, one for each cross-section unit.
Estimation Output
View/Estimation Output will change the display to show the results from the pooled estimation.
As with other estimation objects, you can examine the estimates of the coefficient covariance matrix by selecting View/Coef Covariance Matrix.
Testing
EViews allows you to perform coefficient tests on the estimated parameters of your pool equation. Select View/Wald Coefficient Tests… and enter the restriction to be tested. Additional tests are described in the panel discussion “Panel Equation Testing” on page 668
Pooled Estimation—601
Residuals
You can view your residuals in spreadsheet or graphical format by selecting View/Residuals/Table or View/Residuals/Graph. EViews will display the residuals for each cross-sec- tional equation. Each residual will be named using the base name RES, followed by the cross-section identifier.
If you wish to save the residuals in series for later use, select Proc/Make Resids. This procedure is particularly useful if you wish to form specification or hypothesis tests using the residuals.
Residual Covariance/Correlation
You can examine the estimated residual contemporaneous covariance and correlation matrices. Select View/Residual and then either Covariance Matrix or Correlation Matrix to examine the appropriate matrix.
Forecasting
To perform forecasts using a pool equation you will first make a model. Select Proc/Make Model to create an untitled model object that incorporates all of the estimated coefficients. If desired, this model can be edited. Solving the model will generate forecasts for the dependent variable for each of the cross-section units. For further details, see Chapter 34. “Models,” on page 511.
Estimation Background
The basic class of models that can be estimated using a pool object may be written as:
Yit = a + Xit¢bit + di + gt + eit ,
(35.2)
where Yit
is the dependent variable, and Xit is a k -vector of regressors, and eit
are the
error terms for i = 1, 2, º, M cross-sectional units observed for dated periods
t
= 1, 2, º, T . The a parameter represents the overall constant in the model, while the
di
and gt
represent cross-section or period specific effects (random or fixed). Identification
obviously requires that the b coefficients have restrictions placed upon them. They may be divided into sets of common (across cross-section and periods), cross-section specific, and period specific regressor parameters.
While most of our discussion will be in terms of a balanced sample, EViews does not require that your data be balanced; missing values may be used to represent observations that are not available for analysis in a given period. We will detail the unbalanced case only where deemed necessary.
We may view these data as a set of cross-section specific regressions so that we have M cross-sectional equations each with T observations stacked on top of one another:
602—Chapter 35. Pooled Time Series, Cross-Section Data
Yi = alT + Xi¢bit + dilT + ITg + ei
(35.3)
for i = 1, º, M , where lT is a T -element unit vector, IT is the T -element identity matrix, and g is a vector containing all of the period effects, g¢ = (g1, g2, º, gT).
Analogously, we may write the specification as a set of T period specific equations, each with M observations stacked on top of one another.
Yt = alM + Xt¢bit + IMd + gtlM + et
(35.4)
for t = 1, º, T , where lM is a M -element unit vector, IM is the M -element identity matrix, and d is a vector containing all of the cross-section effects, d¢ = (d1, d2, º, dM).
For purposes of discussion we will employ the stacked representation of these equations. First, for the specification organized as a set of cross-section equations, we have:
Y = alMT + Xb + (IM ƒ lT)d + (lM ƒ IT)g + e
(35.5)
where the matrices b and X are set up to impose any restrictions on the data and parameters between cross-sectional units and periods, and where the general form of the unconditional error covariance matrix is given by:
e1e1¢ e2e1
¢ º eMe1¢
Q = E(ee¢) =
e
e
¢
e
e
¢
M
E
2
1
2
2
O
eMeM¢
eMe1¢ º
(35.6)
If instead we treat the specification as a set of period specific equations, the stacked (by period) representation is given by,
Y = alMT + Xb + (lM ƒ IT)d + (IM ƒ lT)g + e
(35.7)
with error covariance,
e1e1
¢ e2e1¢ º
eTe1¢
Q = E(ee¢)
=
e
2
e
1
¢ e
2
e
2
¢
M
(35.8)
E
O
¢ º
eTe1
eTeT¢
The remainder of this section describes briefly the various components that you may employ in an EViews pool specification.
Cross-section and Period Specific Regressors
The basic EViews pool specification in Equation (35.2) allows for b slope coefficients that are common to all individuals and periods, as well as coefficients that are either cross-sec-
Pooled Estimation—603
tion or period specific. Before turning to the general specification, we consider three extreme cases.
First, if all of the bit are common across cross-sections and periods, we may simplify the expression for Equation (35.2) to:
Yit = a + Xit¢b + di + gt + eit
(35.9)
There are a total of k coefficients in b , each corresponding to an element of x .
Alternately, if all of the bit coefficients are cross-section specific, we have:
Yit =
a + Xit¢bi + di + gt + eit
(35.10)
Note that there are k in each bi
for a total of Mk slope coefficients.
Lastly, if all of the bit coefficients are period specific, the specification may be written as:
Yit = a + Xit¢bt + di + gt + eit
(35.11)
for a total of Tk slope coefficients.
More generally, splitting Xit into the three groups (common regressors X0it , cross-section specific regressors X21it , and period specific regressors X2it ), we have:
Yit = a + X0it¢b0 + X1it¢b1i + X2it¢b2t + di + gt + eit
(35.12)
If there are k1 common regressors, k2
cross-section specific regressors, and k3
period spe-
cific regressors, there are a total of k0
= k1 + k2M + k3T regressors in b .
EViews estimates these models by internally creating interaction variables, M for each regressor in the cross-section regressor list and T for each regressor in the period-specific list, and using them in the regression. Note that estimating models with cross-section or period specific coefficients may lead to the generation of a large number of implicit interaction variables, and may be computationally intensive, or lead to singularities in estimation.
AR Specifications
EViews provides convenient tools for estimating pool specifications that include AR terms. Consider a restricted version of Equation (35.2) on page 601 that does not admit period specific regressors or effects,
Yit = a + Xit¢bi + di + gt + eit
(35.13)
where the cross-section effect di is either not present, or is specified as a fixed effect. We then allow the residuals to follow a general AR process:
p
eit = Â rrieit – r + hit
(35.14)
r =
1
604—Chapter 35. Pooled Time Series, Cross-Section Data
for all i , where the innovations hit are independent and identically distributed, assuming further that there is no unit root. Note that we allow the autocorrelation coefficients r to be cross-section, but not period specific.
If, for example, we assume that eit follows an AR(1) process with cross-section specific AR coefficients, EViews will estimate the transformed equation:
using iterative techniques to estimate (a, bi, ri ) for all i . See “Estimating AR Models” on page 89 for additional discussion.
We emphasize that EViews does place are restrictions on the specifications that admit AR errors. AR terms may not be estimated in specifications with period specific regressors or effects. Lastly, AR terms are not allowed in selected GLS specifications (random effects, period specific heteroskedasticity and period SUR). In those GLS specifications where AR terms are allowed, the error covariance assumption is for the innovations not the autoregressive error.
Fixed and Random Effects
The presence of cross-section and period specific effects terms d and g may be handled using fixed or random effects methods.
You may, with some restrictions, specify models containing effects in one or both dimension, for example, a fixed effect in the cross-section dimension, a random effect in the period dimension, or a fixed effect in the cross-section and a random effect in the period dimension. Note, in particular, however, that two-way random effects may only be estimated if the data are balanced so that every cross-section has the same set of observations.
Fixed Effects
The fixed effects portions of specifications are handled using orthogonal projections. In the simple one-way fixed effect specifications and the balanced two-way fixed specification, these projections involve the familiar approach of removing cross-section or period specific means from the dependent variable and exogenous regressors, and then performing the specified regression using the demeaned data (see, for example Baltagi, 2005). More generally, we apply the results from Davis (2002) for estimating multi-way error components models with unbalanced data.
Note that if instrumental variables estimation is specified with fixed effects, EViews will automatically add to the instrument list, the constants implied by the fixed effects so that the orthogonal projection is also applied to the instrument list.
Pooled Estimation—605
Random Effects
The random effects specifications assumes that the corresponding effects di and gt are realizations of independent random variables with mean zero and finite variance. Most importantly, the random effects specification assumes that the effect is uncorrelated with the idiosyncratic residual eit .
EViews handles the random effects models using feasible GLS techniques. The first step, estimation of the covariance matrix for the composite error formed by the effects and the residual (e.g., nit = di + gt + eit in the two-way random effects specification), uses one of the quadratic unbiased estimators (QUE) from Swamy-Arora, Wallace-Hussain, or Wans- beek-Kapteyn. Briefly, the three QUE methods use the expected values from quadratic forms in one or more sets of first-stage estimated residuals to compute moment estimates of the component variances (j2d, j2g, j2e ). The methods differ only in the specifications estimated in evaluating the residuals, and the resulting forms of the moment equations and estimators.
The Swamy-Arora estimator of the component variances, cited most often in textbooks, uses residuals from the within (fixed effect) and between (means) regressions. In contrast, the Wansbeek and Kapteyn estimator uses only residuals from the fixed effect (within) estimator, while the Wallace-Hussain estimator uses only OLS residuals. In general, the three should provide similar answers, especially in large samples. The Swamy-Arora estimator requires the calculation of an additional model, but has slightly simpler expressions for the component variance estimates. The remaining two may prove easier to estimate in some settings.
Additional details on random effects models are provided in Baltagi (2005), Baltagi and Chang (1994), Wansbeek and Kapteyn (1989). Note that your component estimates may differ slightly from those obtained from other sources since EViews always uses the more complicated unbiased estimators involving traces of matrices that depend on the data (see Baltagi (2005) for discussion, especially “Note 3” on p. 28).
Once the component variances have been estimated, we form an estimator of the composite residual covariance, and then GLS transform the dependent and regressor data.
If instrumental variables estimation is specified with random effects, EViews will GLS transform both the data and the instruments prior to estimation. This approach to random effects estimation has been termed generalized two-stage least squares (G2SLS). See Baltagi (2005, p. 113-116) and “Random Effects and GLS” on page 609 for additional discussion.
Generalized Least Squares
You may estimate GLS specifications that account for various patterns of correlation between the residuals. There are four basic variance structures that you may specify: crosssection specific heteroskedasticity, period specific heteroskedasticity, contemporaneous covariances, and between period covariances.
606—Chapter 35. Pooled Time Series, Cross-Section Data
Note that all of the GLS specifications described below may be estimated in one-step form, where we estimate coefficients, compute a GLS weighting transformation, and then reestimate on the weighted data, or in iterative form, where to repeat this process until the coefficients and weights converge.
Cross-section Heteroskedasticity
Cross-section heteroskedasticity allows for a different residual variance for each cross section. Residuals between different cross-sections and different periods are assumed to be 0. Thus, we assume that:
E(eiteit Xi ) = j2i
(35.16)
E(eisejt Xi ) = 0
for all i , j , s and t with i π j and s π t , where Xi contains Xi and, if estimated by fixed effects, the relevant cross-section or period effects (di, g ).
Using the cross-section specific residual vectors, we may rewrite the main assumption as:
E(eiei¢
Xi ) = ji2IT
(35.17)
GLS for this specification is straightforward. First, we perform preliminary estimation to obtain cross-section specific residual vectors, then we use these residuals to form estimates of the cross-specific variances. The estimates of the variances are then used in a weighted least squares procedure to form the feasible GLS estimates.
Period Heteroskedasticity
Exactly analogous to the cross-section case, period specific heteroskedasticity allows for a different residual variance for each period. Residuals between different cross-sections and different periods are still assumed to be 0 so that:
E(eitejt Xt ) = j2t
(35.18)
E(eisejt Xt ) = 0
for all i , j , s and t with s π t , where Xt contains Xt and, if estimated by fixed effects, the relevant cross-section or period effects (d, gt ).
Using the period specific residual vectors, we may rewrite the first assumption as:
E(etet¢ Xt ) = jt2IM
(35.19)
We perform preliminary estimation to obtain period specific residual vectors, then we use these residuals to form estimates of the period variances, reweight the data, and then form the feasible GLS estimates.
Pooled Estimation—607
Contemporaneous Covariances (Cross-section SUR)
This class of covariance structures allows for conditional correlation between the contemporaneous residuals for cross-section i and j , but restricts residuals in different periods to be uncorrelated. Specifically, we assume that:
E(eitejt
Xt )
= jij
E(eisejt
Xt )
=
(35.20)
0
for all i , j , s and t with s π t . The errors may be thought of as cross-sectionally correlated. Alternately, this error structure is sometimes referred to as clustered by period since observations for a given period are correlated (form a cluster). Note that in this specification the contemporaneous covariances do not vary over t .
Using the period specific residual vectors, we may rewrite this assumption as,
for all t , where,
E(etet¢
Xt )
= QM
(35.21)
j11
j12
º j1M
QM
=
j
12
j
22
M
(35.22)
O
jM1
º
jMM
We term this a Cross-section SUR specification since it involves covariances across cross-sec- tions as in a seemingly unrelated regressions type framework (where each equation corresponds to a cross-section).
Cross-section SUR generalized least squares on this specification (sometimes referred to as the Parks estimator) is simply the feasible GLS estimator for systems where the residuals are both cross-sectionally heteroskedastic and contemporaneously correlated. We employ residuals from first stage estimates to form an estimate of QM . In the second stage, we perform feasible GLS.
Bear in mind that there are potential pitfalls associated with the SUR/Parks estimation (see Beck and Katz (1995)). For one, EViews may be unable to compute estimates for this model when you the dimension of the relevant covariance matrix is large and there are a small number of observations available from which to obtain covariance estimates. For example, if we have a cross-section SUR specification with large numbers of cross-sections and a small number of time periods, it is quite likely that the estimated residual correlation matrix will be nonsingular so that feasible GLS is not possible.
608—Chapter 35. Pooled Time Series, Cross-Section Data
It is worth noting that an attractive alternative to the SUR methodology estimates the model without a GLS correction, then corrects the coefficient estimate covariances to account for the contemporaneous correlation. See “Robust Coefficient Covariances” on page 611.
Note also that if cross-section SUR is combined with instrumental variables estimation, EViews will employ a Generalized Instrumental Variables estimator in which both the data and the instruments are transformed using the estimated covariances. See Wooldridge (2002) for discussion and comparison with the three-stage least squares approach.
Serial Correlation (Period SUR)
This class of covariance structures allows for arbitrary heteroskedasticity and serial correlation between the residuals for a given cross-section, but restricts residuals in different crosssections to be uncorrelated. This error structure is sometimes referred to as clustered by cross-section since observations in a given cross-section are correlated (form a cluster).
Accordingly, we assume that:
E(eiseit
Xi )
= jst
E(eisejt
Xi )
=
(35.23)
0
for all i , j , s and t with i π j . Note that in this specification the heteroskedasticity and serial correlation does not vary across cross-sections i .
Using the cross-section specific residual vectors, we may rewrite this assumption as,
for all i , where,
E(eiei¢
Xi )
= QT
(35.24)
j11
j12
º j1T
QT
=
j
12
j
22
M
(35.25)
O
jT1
º
jTT
We term this a Period SUR specification since it involves covariances across periods within a given cross-section, as in a seemingly unrelated regressions framework with period specific equations. In estimating a specification with Period SUR, we employ residuals obtained from first stage estimates to form an estimate of QT . In the second stage, we perform feasible GLS.
See “Contemporaneous Covariances (Cross-section SUR)” on page 607 for related discussion of errors clustered-by-period.
Pooled Estimation—609
Instrumental Variables
All of the pool specifications may be estimated using instrumental variables techniques. In general, the computation of the instrumental variables estimator is a straightforward extension of the standard OLS estimator. For example, in the simplest model, the OLS estimator may be written as:
ˆ
=
–1
(35.26)
bOLS
ÂXi¢Xi
ÂXi¢Yi
i
i
while the corresponding IV estimator is given by:
ˆ
=
–1
(35.27)
bIV
ÂXi¢PZi Xi
ÂXi¢PZi Yi
i
i
where PZi = (Zi(Zi¢Zi)–1Zi¢)
is the orthogonal projection matrix onto the Zi .
There are, however, additional complexities introduced by instruments that require some discussion.
Cross-section and Period Specific Instruments
As with the regressors, we may divide the instruments into three groups (common instruments Z0it , cross-section specific instruments Z1it , and period specific instruments Z2it ).
You should make certain that any exogenous variables in the regressor groups are included in the corresponding instrument groups, and be aware that each entry in the latter two groups generates multiple instruments.
Fixed Effects
If instrumental variables estimation is specified with fixed effects, EViews will automatically add to the instrument list any constants implied by the fixed effects so that the orthogonal projection is also applied to the instrument list. Thus, if Q is the fixed effects transformation operator, we have:
ˆ
=
ÂXi
–1
bOLS
¢QXi
ÂXi¢QYi
i
i
(35.28)
–1
ˆ
=
Â
X
QP ˜ QX
Â
X
¢QP ˜
QY
b
IV
i
i
i
Zi
i
Zi
i
i
˜
= QZi .
where Zi
Random Effects and GLS
Similarly, for random effects and other GLS estimators, EViews applies the weighting to the instruments as well as the dependent variable and regressors in the model. For example, with data estimated using cross-sectional GLS, we have:
610—Chapter 35. Pooled Time Series, Cross-Section Data
ˆ
bGLS
ˆ
bGIV
where Zi
=
ˆ
Q
=ÂX ¢ ˆ –1X –1ÂX ¢ˆ –1Y
i i QM i i i QM i
–1
(35.29)
=
ˆ –1 § 2
ˆ –1 § 2
ˆ –1 § 2
ˆ –1 § 2
ÂXiQM
PZi QM
Xi
ÂXi¢QM
PZi QM
Yi
i
i
–1 § 2
Zi .
M
In the context of random effects specifications, this approach to IV estimation is termed generalized two-stage least squares (G2SLS) method (see Baltagi (2005, p. 113-116) for references and discussion). Note that in implementing the various random effects methods (Swamy-Arora, Wallace-Hussain, Wansbeek-Kapteyn), we have extended the existing results to derive the unbiased variance components estimators in the case of instrumental variables estimation.
More generally, the approach may simply be viewed as a special case of the Generalized Instrumental Variables (GIV) approach in which data and the instruments are both transformed using the estimated covariances. You should be aware that this has approach has the effect of altering the implied orthogonality conditions. See Wooldridge (2002) for discussion and comparison with a three-stage least squares approach in which the instruments are not transformed. See “GMM Details” on page 677 for an alternative approach.
AR Specifications
EViews estimates AR specifications by transforming the data to a nonlinear least squares specification, and jointly estimating the original and the AR coefficients.
This transformation approach raises questions as to what instruments to use in estimation. By default, EViews adds instruments corresponding to the lagged endogenous and lagged exogenous variables introduced into the specification by the transformation.
For example, in an AR(1) specification, we have the original specification,
and Xit – 1 are introduced by the transformation. EViews will, by default, add
these to the previously specified list of instruments Zit .
You may, however, instruct EViews not to add these additional instruments. Note, however, that the order condition for the transformed model is different than the order condition for the untransformed specification since we have introduced additional coefficients corresponding to the AR coefficients. If you elect not to add the additional instruments automati-
Pooled Estimation—611
cally, you should make certain that you have enough instruments to account for the additional terms.
Robust Coefficient Covariances
In this section, we describe the basic features of the various robust estimators, for clarity focusing on the simple cases where we compute robust covariances for models estimated by standard OLS without cross-section or period effects. The extensions to models estimated using instrumental variables, fixed or random effects, and GLS weighted least squares are straightforward.
White Robust Covariances
The White cross-sectionmethod assumes that the errors are contemporaneously (cross-sec- tionally) correlated (period clustered). The method treats the pool regression as a multivariate regression (with an equation for each cross-section), and computes robust standard errors for the system of equations. We may write the coefficient covariance estimator as:
N
–1
–1
ÂXt¢Xt
ÂXt¢etet¢Xt
ÂXt¢Xt
(35.32)
---------------------
ˆ ˆ
N
– K
t
t
t
where the leading term is a degrees of freedom adjustment depending on the total number of observations in the stacked data, N is the total number of stacked observations, and and K , the total number of estimated parameters.
This estimator is robust to cross-equation (contemporaneous) correlation and heteroskedasticity. Specifically, the unconditional contemporaneous variance matrix E(etet¢) = QMt is unrestricted, may now vary with t , with conditional variance matrix E(etet¢ Xt ) that may depend on Xt in arbitrary, unknown fashion. See Wooldridge (2002, p. 148-153) and Arellano (1987).
Alternatively, the White period method assumes that the errors for a cross-section are heteroskedastic and serially correlated (cross-section clustered). The coefficient covariances are calculated using a White cross-section clustered estimator:
N
Âi
–1
Âi
Âi
–1
N – K
Xi¢Xi
Xi¢eiei¢Xi
Xi¢Xi
(35.33)
---------------------
ˆ ˆ
where, in contrast to Equation (35.32), the summations are taken over individuals and individual stacked data instead of periods.
The estimator is designed to accommodate arbitrary heteroskedasticity and within cross-sec- tion serial correlation. The corresponding multivariate regression (with an equation for each period) allows the unconditional variance matrix E(eiei¢) = QTi to be unrestricted and varying with i , with conditional variance matrix E(eiei¢ Xi ) depending on Xi in general fashion.
612—Chapter 35. Pooled Time Series, Cross-Section Data
In contrast, the White (diagonal) method is robust to observation specific heteroskedasticity in the disturbances, but not to correlation between residuals for different observations. The coefficient asymptotic variance is estimated as:
N
–1
2
–1
ÂXit¢Xit
ÂeitXit
¢Xit
ÂXit¢Xit
(35.34)
---------------------
ˆ
N
– K
i, t
i, t
i, t
This method allows the unconditional variance matrix E(ee¢) = L to be an unrestricted diagonal matrix, with the conditional variances E(e2it Xit ) depending on Xit in general fashion.
EViews allows you to compute non degree-of-freedom corrected versions of all of the robust coefficient covariance estimators. In these cases, the leading ratio term in the expressions above is dropped from the calculation. While this has no effect on the asymptotic validity of the estimates, it has the practical effect of lowering all of your standard error estimates.
PCSE Robust Covariances
The remaining methods are variants of the first two White statistics in which residuals are replaced by moment estimators for the unconditional variances. These methods, which are variants of the so-called Panel Corrected Standard Error (PCSE) methodology (Beck and Katz, 1995), are robust to unrestricted unconditional variance matrices QM and QT , but place additional restrictions on the conditional variance matrices.
A sufficient (though not necessary) condition for use of PCSE is that the conditional and unconditional variances are the same. (Note also that as with the SUR estimators above, we require that QM and QT not vary with t and i , respectively.)
For example, the Cross-section SUR (PCSE) method handles cross-section correlation (period clustering) by replacing the outer product of the cross-section residuals in Equation (35.32) with an estimate of the (contemporaneous) cross-section residual covariance matrix QM :
N
–1
ˆ
–1
ÂXt¢Xt
ÂXt¢QMXt
ÂXt¢Xt
(35.35)
---------------------
N
– K
t
t
t
Analogously, the Period SUR (PCSE) handles between period correlation (cross-section clustering) by replacing the outer product of the period residuals in Equation (35.33) with an estimate of the period covariance QT :
N
–1
ˆ
–1
(35.36)
ÂXi¢Xi
ÂXi¢QTXi
ÂXi¢Xi
---------------------
N
– K
i
i
i
The two diagonal forms of these estimators, Cross-section weights (PCSE), and Period
ˆ
and
ˆ
weights (PCSE), use only the diagonal elements of the relevant QM
QT . These covari-
ance estimators are robust to heteroskedasticity across cross-sections or periods, respectively, but not to general correlation of residuals.