

Variance Ratio Test—403
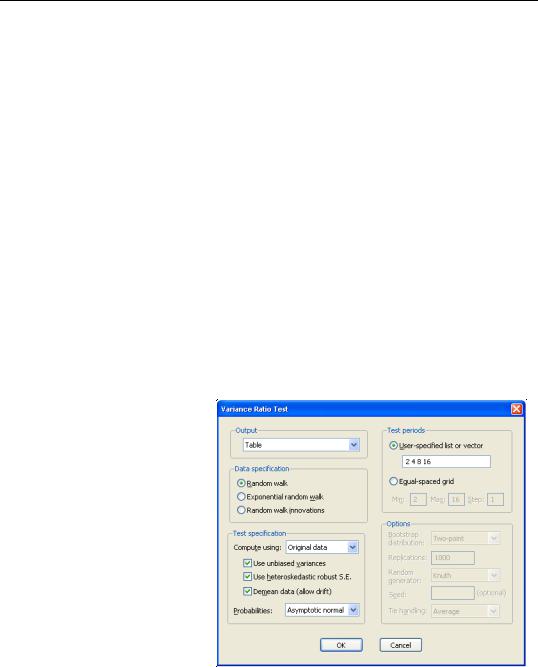
The Test specification section describes the method used to compute your test. By default, EViews computes the basic Lo and MacKinlay variance ratio statistic assuming heteroskedastic increments to the random walk. The default calculations also allow for a non-zero innovation mean and bias correct the variance estimates.
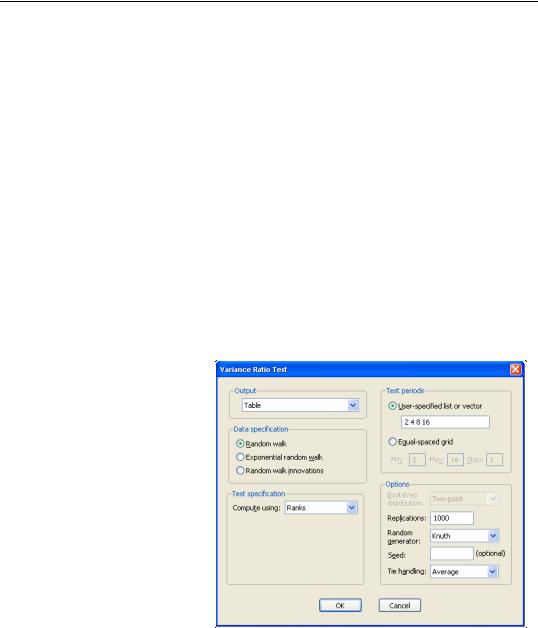
The Compute using combo, which defaults to Original data, instructs EViews to use the original Lo and MacKinlay test statistic based on the innovations obtained from the original data. You may instead use the Compute using combo to instruct EViews to perform the variance ratio test using Ranks, Rank scores (van der Waerden scores), or Signs of the data.
For the Lo and MacKinlay test statistic, the three checkboxes directly beneath the combo allow you to choose whether to bias-correct the variance estimates, to construct the test using the heteroskedasticity robust test standard error, and to allow for non-zero means in the innovations. The Probabilities combo may be used to select between computing the test probabilities using the default Asymptotic normal results (Lo and MacKinlay 1988), or using the Wild bootstrap (Kim 2006). If you choose to perform a wild bootstrap, the Options portion on the lower right of the dialog will prompt you to choose a bootstrap error distribution (Two-point, Rademacher, Normal), number of replications, random number generator, and to specify an optional random number generator seed.
For variance ratio test computed using Ranks, Rank scores (van der Waerden scores), or Signs of the data, the probabilities will be computed by permutation bootstrapping using the settings specified under Options. For the ranks and rank scores tests, there is an additional Tie handling option for the method of assigning ranks in the presence of tied data.
Lastly, the Test periods section identifies the intervals whose variances you wish to compare to the variance of
the one-period innovations. You may specify a single period or more than one period; if there is more than one period, EViews will perform one ore more joint tests of the variance ratio restrictions for the specified periods.

Variance Ratio Test—405
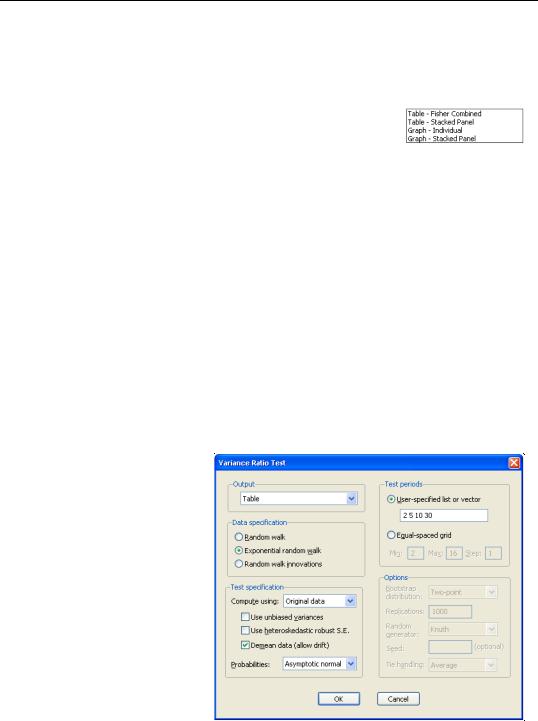
boxes to perform the i.i.d. version of the Lo-MacKinlay test with no bias correction. Lastly, change the user-specified test periods to “2 5 10 30” to match the test periods examined by Wright. Click on OK to compute and display the results.
The top portion of the output shows the test settings and basic test results.
Null Hypothesis: Log JP is a random walk
Date: 04/21/09 Time: 15:15
Sample: 8/07/1974 5/29/1996
Included observations: 1138 (after adjustments)
Standard error estimates assume no heteroskedasticity
Use biased variance estimates
User-specified lags: 2 5 10 30
Joint Tests |
Value |
df |
Probability |
|
Max |z| (at period 5)* |
4.295371 |
1138 |
0.0001 |
|
Wald (Chi-Square) |
22.63414 |
4 |
0.0001 |
|
Individual Tests |
|
|
|
|
Period |
Var. Ratio |
Std. Error |
z-Statistic |
Probability |
2 |
1.056126 |
0.029643 |
1.893376 |
0.0583 |
5 |
1.278965 |
0.064946 |
4.295371 |
0.0000 |
10 |
1.395415 |
0.100088 |
3.950676 |
0.0001 |
30 |
1.576815 |
0.182788 |
3.155651 |
0.0016 |
|
|
|
|
|
|
|
|
|
|
*Probability approximation using studentized maximum modulus with parameter value 4 and infinite degrees of freedom
Since we have specified more than one test period, there are two sets of test results. The “Joint Tests” are the tests of the joint null hypothesis for all periods, while the “Individual Tests” are the variance ratio tests applied to individual periods. Here, the Chow-Denning maximum z statistic of 4.295 is associated with the period 5 individual test. The approximate p-value of 0.0001 is obtained using the studentized maximum modulus with infinite degrees of freedom so that we strongly reject the null of a random walk. The results are quite similar for the Wald test statistic for the joint hypotheses. The individual statistics generally reject the null hypothesis, though the period 2 variance ratio statistic p-value is slightly greater than 0.05.
The bottom portion of the output shows the intermediate results for the variance ratio test calculations, including the estimated mean, individual variances, and number of observations used in each calculation.
Test Details (Mean = -0.000892835617901)
Period |
Variance |
Var. Ratio |
Obs. |
1 |
0.00021 |
-- |
1138 |
2 |
0.00022 |
1.05613 |
1137 |
5 |
0.00027 |
1.27897 |
1134 |
10 |
0.00029 |
1.39541 |
1129 |
30 |
0.00033 |
1.57682 |
1109 |
|
|
|
|
|
|
|
|

Variance Ratio Test—407
for the individual variance ratio tests, which are all generated using the wild bootstrap, are generally consistent with the previous results, albeit with probabilities that are slightly higher than before. The individual period 2 test, which was borderline (in)significant in the homoskedastic test, is no longer significant at conventional levels. The Chow-Denning joint test statistic of 3.647 has a bootstrap p-value of 0.0012 and strongly rejects the null hypothesis that the log of JP is a martingale.
Lastly, we perform Wright’s rank variance ratio test with ties replaced by the average of the tied ranks. The test probabilities for this test are computed using the permutation bootstrap, whose settings we select to match those for the previous bootstrap:
Null Hypothesis: Log JP is a random walk Date: 04/21/09 Time: 15:16
Sample: 8/07/1974 5/29/1996
Included observations: 1138 (after adjustments) Standard error estimates assume no heteroskedasticity User-specified lags: 2 5 10 30
Test probabilities computed using permutation bootstrap: reps=5000, rng=kn, seed=1000
Joint Tests |
Value |
df |
Probability |
|
Max |z| (at period 5) |
5.415582 |
1138 |
0.0000 |
|
Wald (Chi-Square) |
37.92402 |
4 |
0.0000 |
|
Individual Tests |
|
|
|
|
Period |
Var. Ratio |
Std. Error |
z-Statistic |
Probability |
2 |
1.081907 |
0.029643 |
2.763085 |
0.0050 |
5 |
1.351718 |
0.064946 |
5.415582 |
0.0000 |
10 |
1.466929 |
0.100088 |
4.665193 |
0.0000 |
30 |
1.790412 |
0.182788 |
4.324203 |
0.0000 |
|
|
|
|
|
|
|
|
|
|
The standard errors employed in forming the individual z-statistics (and those displayed in the corresponding graph view) are obtained from the asymptotic normal results. The probabilities for the individual z-statistics and the joint max z and Wald statistics, which all strongly reject the null hypothesis, are obtained from the permutation bootstrap.
The preceding analysis may be extended to tests that jointly consider all five exchange rates in a panel setting. The second page (WRIGHT_STK) of the “Wright.WF1” workfile contains the panel dataset of the relative-to-U.S. exchange rates described above (Canada, Germany, France, Japan, U.K.). Click on the WRIGHT_STK tab to make the second page active, double click on the EXCHANGE series to open the stacked exchange rates series, then select View/
Variance Ratio Test...
We will redo the heterogeneous Lo and MacKinlay test example from above using the panel data series. Select Table - Fisher Combined in the Output combo then fill out the remainder of the dialog as before, then click on OK. The output, which takes a moment to generate since we are performing 5000 bootstrap replications for each cross-section, consists of two distinct parts. The top portion of the output:

Variance Ratio Test—409
First, Lo and MacKinlay make the strong assumption that the et are i.i.d. Gaussian with variance j2 (though the normality assumption is not strictly necessary). Lo and MacKinlay term this the homoskedastic random walk hypothesis, though others refer to this as the i.i.d. null.
Alternately, Lo and MacKinlay outline a heteroskedastic random walk hypothesis where they weaken the i.i.d. assumption and allow for fairly general forms of conditional heteroskedasticity and dependence. This hypothesis is sometimes termed the martingale null, since it offers a set of sufficient (but not necessary), conditions for et to be a martingale difference sequence (m.d.s.).
We may define estimators for the mean of first difference and the scaled variance of the q -th difference:
|
|
|
|
1 |
|
T |
|
|
|
|
|
|
|
|
|
m |
= |
T |
 |
(Yt – Yt – 1 ) |
|
|
|
||||
|
|
ˆ |
|
--- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
t |
= 1 |
|
|
|
|
|
|
(30.54) |
|
|
|
|
1 |
|
T |
|
|
|
|
|
||
|
2 |
|
|
|
|
|
|
|
|
2 |
|||
j |
(q) = |
|
 |
(Yt – |
Yt – q – qm) |
||||||||
|
Tq |
|
|||||||||||
ˆ |
|
|
|
------ |
|
|
|
|
ˆ |
|
|
||
|
|
|
|
|
|
t = 1 |
|
|
|
|
|
|
|
and the corresponding variance ratio VR(q) = |
ˆ 2 |
ˆ |
2 |
(1). The variance estimators |
|||||||||
j |
(q) § j |
|
|||||||||||
may be adjusted for bias, as suggested by Lo and MacKinlay, by replacing T in |
|||||||||||||
Equation (30.54) with (T – q + 1) |
in the no-drift case, or with (T – q + 1)(1 – q § T) in |
||||||||||||
the drift case.
Lo and MacKinlay show that the variance ratio z-statistic:
|
|
|
z(q) |
|
|
|
|
|
|
ˆ2 |
(q)] |
–1 § 2 |
|
|
|
(30.55) |
|||
|
|
|
= (VR(q) – 1) [s |
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ˆ |
2 |
(q). |
|
|
is asymptotically N(0, 1) for appropriate choice of estimator s |
|
|
|||||||||||||||||
Under the i.i.d. hypothesis we have the estimator, |
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
ˆ |
2 |
(q) = |
|
2(2q – 1)(q – 1) |
|
|
|
|
|
(30.56) |
|||||
|
|
|
|
s |
|
|
----------------------------------------- |
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
3qT |
|
|
|
|
|
|
|
|
|
while under the m.d.s. assumption we may use the kernel estimator, |
|
|
|||||||||||||||||
|
|
|
|
2 |
|
|
q – 1 |
|
2(q – j) |
2 |
|
|
|
|
|
|
|||
|
|
|
ˆ |
|
(q) = |
|
 |
|
|
|
ˆ |
|
|
|
|
|
|
||
|
|
|
|
|
|
------------------- |
dj |
|
|
|
|
(30.57) |
|||||||
|
|
|
s |
|
|
|
q |
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
j = 1 |
|
|
|
|
|
|
|
|
|
|
|
|
where |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ˆ |
|
T |
|
|
|
|
2 |
|
|
|
2 |
T |
|
|
|
ˆ 2 2 |
|
||
dj |
|
 |
(yt |
– j – mˆ ) |
|
(yt |
– mˆ ) |
|
|
 |
(yt – j |
– m) |
|
(30.58) |
|||||
= |
|
|
§ |
|
|
|
|
||||||||||||
|
|
t = j + 1 |
|
|
|
|
|
|
|
|
|
t = j + 1 |
|
|
|
|
|
||
