336—Chapter 28. Quantile Regression
tation of the Ln(t) form of the QLR statistics (see “Standard Views and Procedures” on page 337 and “Quasi-Likelihood Ratio Tests” on page 350).
We may elect instead to perform bootstrapping to obtain the covariance matrix. Click on the Estimate button to bring up the dialog, then on Estimation Options to show the options tab. Select Bootstrap as the Coefficient Covariance, then choose MCMB-A as the bootstrap method. Next, we increase the number of replications to 500. Lastly, to see the effect of using a different estimator of the sparsity, we change the scalar sparsity estimation method to Siddiqui (mean fitted). Click on OK to estimate the specification.
Dependent Variable: Y
Method: Quantile Regression (Median)
Date: 08/12/09 Time: 11:49
Sample: 1 235
Included observations: 235
Bootstrap Standard Errors & Covariance
Bootstrap method: MCMB-A, reps=500, rng=kn, seed=47500547
Sparsity method: Siddiqui using fitted quantiles
Bandwidth method: Hall-Sheather, bw=0.15744
Estimation successfully identifies unique optimal solution
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|
|
|
|
|
|
|
|
|
|
C |
81.48225 |
22.01534 |
3.701158 |
0.0003 |
X |
0.560181 |
0.023804 |
23.53350 |
0.0000 |
|
|
|
|
Pseudo R-squared |
0.620556 |
Mean dependent var |
624.1501 |
Adjusted R-squared |
0.618927 |
S.D. dependent var |
276.4570 |
S.E. of regression |
120.8447 |
Objective |
|
8779.966 |
Quantile dependent var |
582.5413 |
Restr. objective |
|
23139.03 |
Sparsity |
267.8284 |
Quasi-LR statistic |
428.9034 |
Prob(Quasi-LR stat) |
0.000000 |
|
|
|
|
|
|
|
|
|
|
|
|
|
For the most part the results are quite similar. The header information shows the different method of computing coefficient covariances and sparsity estimates. The Huber Sandwich and bootstrap standard errors are reasonably close (24.03 versus 22.02, and 0.031 versus 0.024). There are moderate differences between the two sparsity estimates, with the Siddiqui estimator of the sparsity roughly 25% higher (267.83 versus 209.35), but this difference has no substantive impact on the probability of the QLR statistic.
Views and Procedures
We turn now to a brief description of the views and procedures that are available for equations estimated using quantile regression. Most of the available views and procedures for the quantile regression equation are identical to those for an ordinary least squares regression, but a few require additional discussion.
Views and Procedures—337
Standard Views and Procedures
With the exception of the views listed under Quantile Process, the quantile regression views and procedures should be familiar from the discussion in ordinary least squares regression (see “Working with Equations” on page 17).
A few of the familiar views and procedures do require a brief comment or two:
• Residuals are computed using the estimated parameters for the specified quantile:
ˆ |
(t) |
= |
ˆ |
ei |
Yi – Xi¢b(t). Standardized residuals are the ratios of the residuals to the |
the degree-of-freedom corrected sample standard deviation of the residuals.
Note that an alternative approach to standardizing residuals that is not employed here would follow Koenker and Machado (1999) in estimating the scale parameter using the average value of the minimized objective function jˆ (t) = n–1Vˆ (t). This latter estimator is used in forming quasi-likelihood ratio (QLR) tests (“Quasi-Likelihood Ratio Tests” on page 350).
•Wald tests and confidence ellipses are constructed in the usual fashion using the possibly robust estimator for the coefficient covariance matrix specified during estimation.
•The omitted and redundant variables tests and the Ramsey RESET test all perform QLR tests of the specified restrictions (Koenker and Machado, 1999). These tests require the i.i.d. assumption for the sparsity estimator to be valid.
•Forecasts and models will be for the estimated conditional quantile specification,
using the estimated ˆ (t). We remind you that by default, EViews forecasts will b
insert the actual values for out-of-forecast-sample observations, which may not be the desired approach. You may switch the insertion off by unselecting the Insert actuals for out-of-sample observations checkbox in the Forecast dialog.
Quantile Process Views
The Quantile Process view submenu lists three specialized views that rely on quantile process estimates. Before describing the three views, we note that since each requires estimation of quantile regression specifications for various t , they may be time-consuming, especially for specifications where the coefficient covariance is estimated via bootstrapping.
338—Chapter 28. Quantile Regression
Process Coefficients
You may select View/Quantile Process/Process Coefficients to examine the process coefficients estimated at various quantiles.
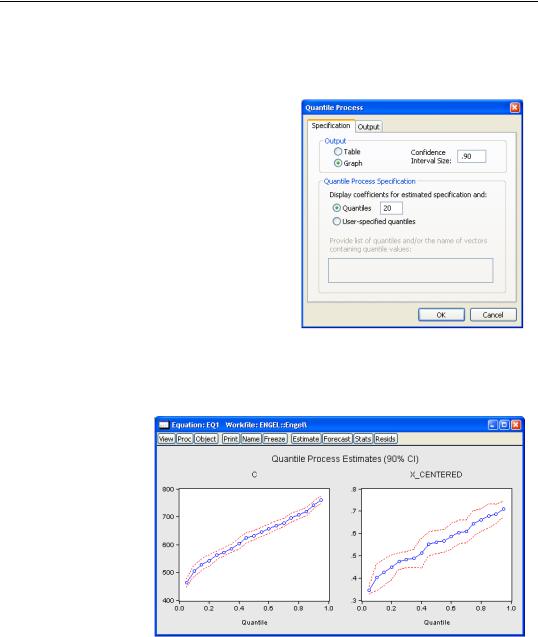
The Output section of the Specification page is used to control how the process results are displayed. By default, EViews displays the results as a table of coefficient estimates, standard errors, t-statistics, and p-values. You may instead click on the Graph radio button and enter the size of the confidence interval in the edit field that appears. The default is to display a 95% confidence interval.
The Quantile Process Specification section of the page determines the quantiles at which the process will be estimated. By default, EViews will estimate models for each of the
deciles (10 quantiles,
t = {0.1, 0.2, º, 0.9}). You may specify a different number of quantiles using the edit field, or you may select User-specified quantiles and then enter a list of quantiles or one or more vectors containing quantile values.
Here, we follow Koenker (2005), in displaying a process graph for a modified version of the earlier equation; a median regression using the Engel data, where we fit the Y data to the centered X series and a constant. We display the results for 20
quantiles, along with 90% confidence intervals.
In both cases, the coefficient estimates show a clear positive relationship between the quantile value and the estimated coefficients; the positive relationship between X_CENTERED is
Views and Procedures—339
clear evidence that the conditional quantiles are not i.i.d. We test the strength of this relationship formally below.
The Output page of the dialog allows you to save the results of the quantile process estimation. You may provide a name for the vector of quantiles, the matrix of process coefficients, and the covariance matrix of the coefficients. For the k sorted quantile estimates, each row of the k ¥ p coefficient matrix contains estimates for a given quantile. The covariance matrix is the covariance of the vec of the coefficient matrix.
Slope Equality Test
To perform the Koenker and Bassett (1982a) test for the equality of the slope coefficients across quantiles, select View/Quantile Pro-
cess/Slope Equality Test... and fill out the dialog.
The dialog has two pages. The Specification page is used to determine the quantiles at which the process will be compared. EViews will compare with slope (non-intercept) coefficients of the estimated tau, with the taus specified in the dialog. By default, the com-
parison taus will be the three quartile limits (t = {0.25, 0.5, 0.75}), but you may select
User-specified quantiles and provide your own values.
The Output page allows you to save the results from the supplementary process esti-
mation. As in “Process Coefficients” on page 338, you may provide a name for the vector of quantiles, the matrix of process coefficients, and the covariance matrix of the coefficients.
The results for the slope equality test for a median regression of our first equation relating food expenditure and household income in the Engel data set. We compare the slope coefficient for the median against those estimated at the upper and lower quartile.
340—Chapter 28. Quantile Regression
Quantile Slope Equality Test
Equation: UNTITLED
Specification: Y C X
|
|
Chi-Sq. |
|
|
Test Summary |
|
Statistic |
Chi-Sq. d.f. |
Prob. |
|
|
|
|
|
|
|
|
|
|
Wald Test |
|
25.22366 |
2 |
0.0000 |
|
|
|
|
|
|
Restriction Detail: b(tau_h) - b(tau_k) = 0 |
|
|
|
|
|
|
|
|
|
|
|
|
Quantiles |
Variable |
Restr. Value |
Std. Error |
Prob. |
|
|
|
|
|
|
|
|
|
|
0.25, 0.5 |
X |
-0.086077 |
0.025923 |
0.0009 |
0.5, 0.75 |
|
-0.083834 |
0.030529 |
0.0060 |
|
|
|
|
|
|
|
|
|
|
The top portion of the output shows the equation specification, and the Wald test summary. Not surprisingly (given the graph of the coefficients above), we see that the x2 -statistic value of 25.22 is statistically significant at conventional test levels. We conclude that coefficients differ across quantile values and that the conditional quantiles are not identical.
Symmetric Quantiles Test
The symmetric quantiles test performs the Newey and Powell (1987) of conditional symmetry. Conditional symmetry implies that the average value of two sets of coefficients for symmetric quantiles around the median will equal the value of the coefficients at the median:
b--------------------------------------(t) + b(1 – t) |
= b(1 § 2) |
(28.1) |
2 |
|
|
By default, EViews will test for symmetry using the estimated quantile and the quartile limits specified in the dialog. Thus, if the estimated model fits the median, there will
be a single set of restrictions:
(b(0.25) + b(0.75)) § 2 = b(0.5). If the
estimated model fits the 0.6 quantile, there will be an additional set of restrictions:
(b(0.4) + b(0.6)) § 2 = b(0.5).
As with the other process routines, you may select User-specified quantiles and provide your own values. EViews will estimate a model for both the specified quantile, t , and its complement 1 – t , and will compare the results to the median estimates.