

262—Chapter 9. Page After Page After Page
Contracted Data
What we’ve done is called a contraction, because we’ve mapped many data points into one. We can see that the unionization rate in Arkansas—home of the world’s largest private employer—is about a half percent and the average education level is three-quarters of a year of college. In Washington—where the state bird is the geo- duck—the unionization rate is over three percent and average education is about a year and a half of college.
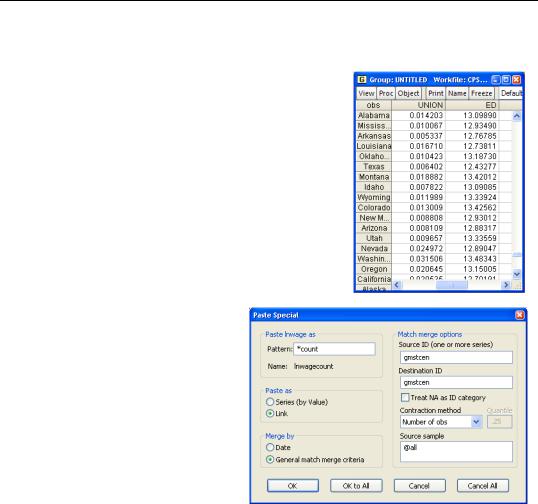
Something’s wrong. Unionization rates aren’t that low. To help investigate, let’s copy the data in using a count merge instead of a mean merge. We click on the tab to return to the Cps page, re-copy the four series, and paste into the ByState page as before, except with two differences. In the Pattern field in the Paste Special dialog we add the suffix “count” to the variable names, so that we don’t write over the state means that we computed previously. In the Contraction
method field, switch to Number of obs to get a count of how many observations are being used for each series.
Contracted Data—263
We can see that education and unionization always have the same underlying counts within a state. But the count for LNWAGE is different—and lower—than the count for ED and UNION.
Here’s what happened in the mean merge. The contraction computed the mean for each series separately. The Current Population Survey isn’t limited to workers, so the state-by- state means have been computed as a fraction of the population. We probably wanted only those who are working. What’s more, the variable LNWAGE is coded as NA for anyone who doesn’t report a positive salary, including all non-workers. As a result, the state-by-state
means for LNWAGE were computed using roughly 25 percent fewer observations than the other variables.
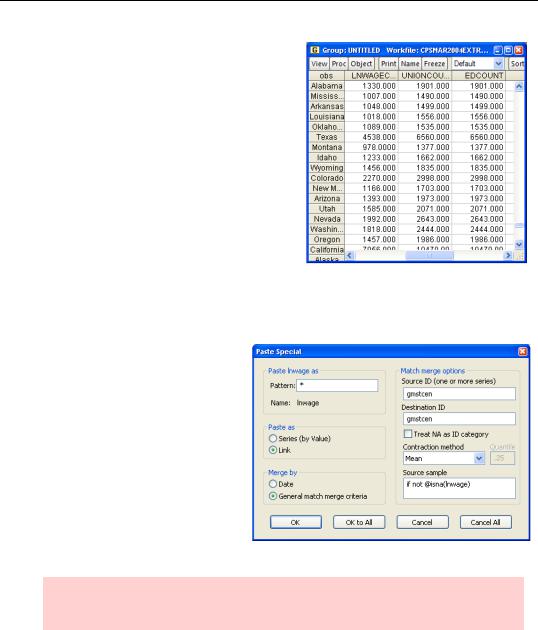
We want a common sample to be used for computing the series means for each state. This can be accomplished by specifying an appropriate sample in the Source Sample field in the Paste Special dialog. It happens that in this data set the only difference in the sample for the different series is that LNWAGE has a lot of NAs. Toss out the ByState page we made and make a new one, this time entering “if not @isna(lnwage)” in the
Source Sample field.
Hint: We could have edited the link specifications, but since we had several series, it was faster to just toss the links and start over.
264—Chapter 9. Page After Page After Page
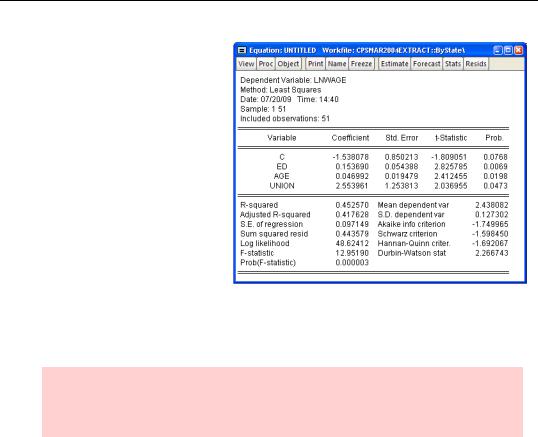
We now have a valid state-by- state dataset. Let’s repeat our earlier regression using statelevel data. The results are basically the same. The estimated effects of both education and age are a little larger than for the individual data. While the coefficients are highly significant, the standard errors are larger than before. That’s what we would expect from the much smaller— 99,991 versus 51 observations— sample.
In the state-by-state regression, the interpretation of the union
coefficient has changed. Because UNION is measured as a fraction, the regression now tells us that for each one percentage point increase in the unionization rate, the average wage rises two and a half percent.
Econometric caution: We’re assuming that unionization drives wage rates. Maybe. Or maybe it’s been easier for unions to survive in high income states. The latter interpretation would mean that our regression results aren’t causal.
Expanded Data
In order to separate out the effect of the average unionization rate from the effect of individual union membership, we need to include both variables in our individual level regression. To accomplish this, we need to expand the 51 state-by-state observations on unionization back into the individual page, linking each individual to the average unionization rate in her state of residence.
Expanded Data—265
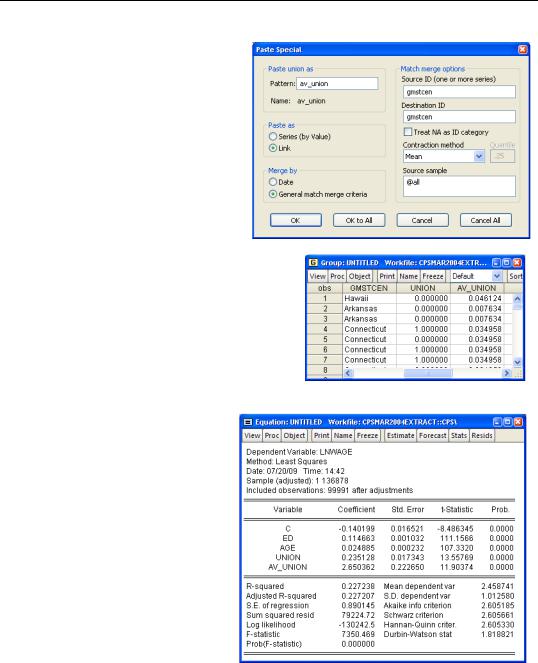
To expand the data, we make a link going in the other direction. Copy UNION from the ByState page and
Paste Special into the Cps page. We’ll change the name of the pasted variable to AV_UNION in order to avoid any confusion with the individual union variable.
The first few observations in the
Cps page are shown to the right. Notice that the fourth and fifth person are both from Connecticut. Even though the fourth person is a union member and the fifth person isn’t, they have the same value of AV_UNION. We’ve succeeded in attaching the state-wide average unionization rate to each individual observation.
And the answer is? Our regression results show that being a union member raises an individual’s wages 23.5 percent. Every additional percentage point of unionization in a state raises everyone’s wages 2.65 percent.