


210—Chapter 7. Look At Your Data
Boxplots By Categories
Boxplots give quick visual comparisons of different subpopulations. In this plot we’re again classifying GPA by Washington residence using the categorical graph tools. We also clicked the notched and proportional to observations radio buttons in the dialog. The distribution of grades is higher for non-
Washington residents, but the ranges for residents and non-residents mostly overlap.
Statistics don’t lie, but they can mislead. In this plot, the upper staple for non-residents is higher than the staple for residents. A little investigation shows that, while GPA is measured on a four point scale, one observation for a non-residents was recorded 4.1. Because some schools use something other than a four point scale, we don’t know if this GPA is an error or not. But we probably shouldn’t conclude anything about the difference between inand out-of-state applicants based on this one data point.
Tests On Series
Up to this point, we’ve been looking at ways to summarize the data in a series. Now we move on to formal hypothesis tests. The tests corresponding to the descriptive statistics we’ve looked at are found under the Descriptive Statistics & Tests menu. As an example, having found the mean LSAT in our applicant pool, we might want to test whether it differs from the national average.
Tests On Series—211
Simple Hypothesis Tests
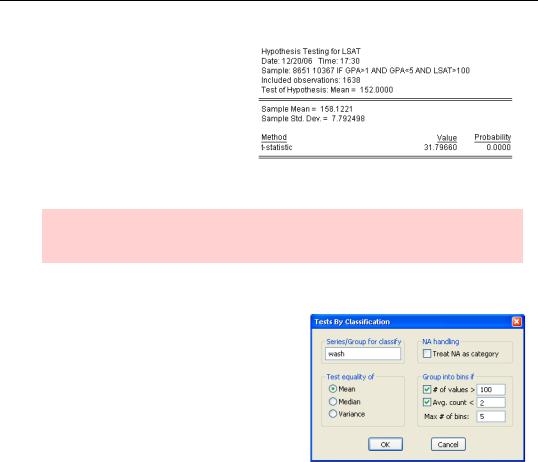
Nationally, the average LSAT score is about 152. Looking at the data for University of Washington applicants, we see their average was higher, just over 158. It would be interesting to know whether the difference is meaningful, or whether it’s a random statistical fluke.
Formally, we want to test the hypothesis that the mean University of Washington score equals 152 and ask whether there is sufficient evidence to reject this hypothesis. We will perform this test after setting the sample to include observations where the GPA is within normal bounds and the LSAT score exceeds 100. Choose Descriptive Statistics & Tests and Simple Hypothesis Tests and then enter the hypothesized mean in the Series Distribution Tests dialog.
Hint: If you’re only testing a mean, you don’t need to fill out any other fields. The Variance and Median fields are for hypothesis tests on the variance or median. In particular, don’t enter a previously estimated standard deviation in the Enter s.d. if known field. That’s only for the (unusual) case in which a standard deviation is known, rather than having been estimated.
212—Chapter 7. Look At Your Data
EViews conducts a standard t-test for this hypothesis, providing both the t- statistic and its associated p-value. In this case, the p-value tells us that if the true average LSAT in the applicant pool was 152, the probability of observing the mean LSAT found in our data, 158, is zero to four decimal places. Clearly, applicants to the Uni-
versity of Washington’s (very good) law school are better than the average LSAT taker.
Buzzword hint: We’d say that the average UW applicant LSAT is statistically significantly different from the average of all test takers.
Tests By Classification
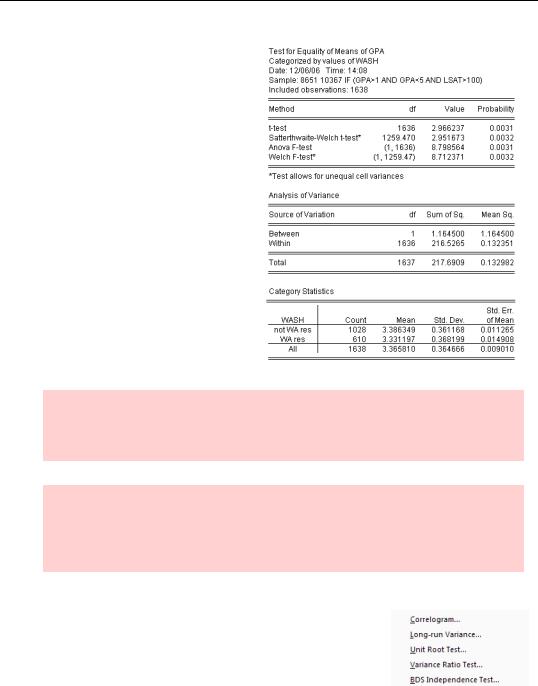
We know from our work earlier in the chapter that out-of-state applicants have a slightly higher average GPA than do in-state applicants. Is the difference statistically significant? Open the GPA series and use the menu Equality Tests by Classification… to get to the Tests By Classification dialog. We’ve filled out the
Series/Group for classify field with the series WASH, since that’s the classifying variable of interest.
Tests On Series—213
Since there are only two categories in this problem, in-state and out-, we need only look at the reported t-statis- tic and its associated p-value. If there were more than two categories, we would have to rely on the F-statistic; with exactly two categories, the F- is redundant with the t-.
While the difference between in-state and out-of-state GPAs is very small, statistically it’s highly significant.
Hint: Finding a difference that is statistically significant but very small demonstrates the maxim that with enough data you can accurately identify differences too small for anyone to care about.
Statistical hint: The basic Anova F-test for differences of means assumes that the subpopulations have equal variances. Most introductory statistics classes also teach the Satterthwaite and Welch tests that allow for different variances for different subpopulations.
Time series tests
Five tests of the time-series properties of a series appear in the View menu. Exploring these tests would take us too far afield for now, but Correlograms and Unit Root Tests will be discussed in Chapter 13, “Serial Correlation—Friend or Foe?”