Шпаргалка ГОСы 2015 Информационно Управляющие системы
.doc|
БИЛЕТ 1 |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Язы́к программи́рования — формальная знаковая система, предназначенная для записи компьютерных программ. Язык программирования определяет набор лексических, синтаксических и семантических правил, определяющих внешний вид программы и действия, которые выполнит исполнитель под её управлением. Парадигма программирования Паради́гма программи́рования — это совокупность идей и понятий, определяющих стиль написания компьютерных программ (подход к программированию). Это способ концептуализации, определяющий организацию вычислений и структурирование работы, выполняемой компьютером. - Императивная, или процедурная парадигма программирования - развилась на базе низкоуровневых языков (машинные коды, ассемблер), основанных на архитектуре фон Неймана. Императивная программа состоит из последовательно выполняемых команд и вызовов процедур, которые обрабатывают данные и изменяют значения переменных программы. Переменные при этом рассматриваются как некоторые контейнеры для данных, подобно ячейкам памяти компьютера. - Функциональная парадигма программирования - получила развитие из вычислений по алгебраическим формулам. Функциональная программа состоит из набора взаимосвязанных и, как правило, рекурсивных функций. Каждая функция определяется выражением, которое задает правило вычисления её значения в зависимости от значений ее аргументов. Выполнение функциональной программы заключается в последовательном вычислении значений функциональных вызовов. - Логическая парадигма программа рассматривается как множество логических формул: аксиом (фактов и правил), описывающих свойства некоторых объектов, и теоремы, которую необходимо доказать. В свою очередь, выполнение программы – это доказательство теоремы, в ходе которого строится объект с описанными свойствами. - объектно-ориентированная парадигма - программа описывает структуру и поведение вычисляемых объектов и классов объектов. Объект обычно включает некоторые данные (состояние объекта) и операции с этими данными (методы), описывающие поведение объекта. Классы представляют множество объектов со схожей структурой и схожим поведением. Обычно описание классов имеет иерархическую структуру, включающую полиморфизм операций. Выполнение объектно-ориентированной программы представляет собой обмен сообщениями между объектами, в результате которого они меняют свои состояния. Языки программирования низкого уровня Языки низкого уровня, как правило, используют для написания небольших системных программ, драйверов устройств, модулей стыков с нестандартным оборудованием, программирование специализированных микропроцессоров, когда важнейшими требованиями являются компактность, быстродействие и возможность прямого доступа к аппаратным ресурсам. Языки программирования высокого уровня Особенности конкретных компьютерных архитектур в них не учитываются, поэтому созданные приложения легко переносятся с компьютера на компьютер. Разрабатывать программы на таких языках значительно проще и ошибок допускается меньше. Значительно сокращается время разработки программы, что особенно важно при работе над большими программными проектами .Недостатком некоторых языков высокого уровня является большой размер программ в сравнении с программами на языках низкого уровня. С другой стороны, для алгоритмически и структурно сложных программ при использовании суперкомпиляции преимущество может быть на стороне языков высокого уровня. Деление языков программирования на классы можно представить на схеме таким образом:
Процедурное программирование - есть отражение фон Неймановской архитектуры компьютера. Программа, написанная на процедурном языке, представляет собой последовательность команд, определяющих алгоритм решения задачи. Основная идея процедурного программирования - использование памяти для хранения данных. Основная команда- присвоение, с помощью которой определяется и меняется память компьютера. Программа производит преобразование содержимого памяти, изменяя его от исходного состояния к результирующему. а) Структурное программирование, которое основано на использовании подпрограмм и независимых структур данных; б) Программирование «сверху-вниз», когда задача делится на простые, самостоятельно решаемые задачи. Затем выстраивается решение исходной задачи полностью сверху вниз. Объектно-ориентированное программирование (ООП) — это метод программирования, при использовании которого главными элементами программ являются объекты. В языках программирования понятие объекта реализовано как совокупность свойств (структур данных, характерных для данного объекта), методов их обработки (подпрограмм изменения их свойств) и событий, на которые данный объект может реагировать и, которые приводят, как правило, к изменению свойств объекта - Декларативные языки программирования К ним относятся функциональные и логические языки программирования Функциональное программирование- это способ составления программ, в которых единственным действием является вызов функции. В функциональном программировании не используется память, как место для хранения данных, а, следовательно, не используются промежуточные переменные, операторы присваивания и циклы. Ключевым понятием в функциональных языках является выражение. Программа, написанная на функциональном языке, представляет собой последовательность описания функций и выражений. Выражение вычисляется сведением сложного к простому. Все выражения записываются в виде списков. Логическое программирование- это программирование в терминах логики. - Языки программирования баз данных отличаются от алгоритмических языков прежде всего своим функциональным назначением. При работе с базами данных выполняются следующие операции: создание, преобразование и удаление таблиц в БД; поиск, отбор, сортировка по запросам пользователя; добавление новых записей и модификация существующих, удаление записей и др. - Языки программирования для компьютерных сетей являются интерпретируемыми. Такие языки называются скрипт – языками. - Формальный язык является объединением нескольких множеств: множества исходных символов, называемых литерами (алфавит), множества правил, которые позволяют строить из букв алфавита новые слова (правила порождения слов или идентификаторов), множества предопределённых идентификаторов или словаря ключевых слов (прочие идентификаторы называются именами), множества правил, которые позволяют собирать из имён и ключевых слов выражения, на основе которых строятся простые и сложные предложения (правила порождения операторов или предложений).Множество правил порождения слов, выражений и предложений называют грамматикой формального языка или формальной грамматикой.
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Гипертекстовая структура получила исключительно широкое распространение, в основном, в информационно-справочных системах в различных областях знания. Такие программы обеспечивают электронный просмотр больших объемов иерархически организованной текстовой и графической информации. Гипертекстовая структура обеспечивает быстрый поиск информации по различным признакам. Гипертекст - это информационный массив, на котором заданы и автоматически поддерживаются связи между выделенными элементами. В виде гипертекста может быть представлена любая слабо формализованная совокупность текстов или изображений. Гипертекстовая форма представления информации является следствием эволюции средств общения людей между собой, и гипертекст соответствует природе мышления человека. Гипертекст в обобщенном смысле - это интерактивная информационная система, созданная на основе множества естественных и искусственных языков, гибких аппаратных и программных средств, позволяющих пользователю динамично и творчески взаимодействовать с изменяемым информационным массивом с целью получения нового для себя знания. Все большее распространение получают также системы гипермедиа. Под гипермедиа понимается способ организации мультимедиа. Мультимедиа предполагает объединение в компьютерной системе нескольких средств предоставления информации, а именно: текст, звук, графика, мультипликация, видео, пространственное моделирование. Гипермедиа состоит из узлов, которые являются основными единицами хранения информации и могут включать в себя страницы текста, графику, звуковую информацию, видеоклип или целый документ. Взаимное согласование голоса лектора, музыкального и шумового сопровождения с визуальным рядом способно обеспечить образное восприятие учебного материала, эмоциональное воздействие на ученика, что даёт не только более глубокие и "долгоживущие" знания, но сопряжено с гораздо меньшей нагрузкой на зрение учащихся. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Алгоритм - это заданное на некотором языке конечное предписание, задающее конечную последовательность выполнимых элементарных операций для решения задачи, общее для класса возможных исходных данных. Анализируя алгоритм, можно получить представление о том, сколько времени займет решение данной задачи при помощи данного алгоритма. Одну и ту же задачу можно решить с помощью различных алгоритмов. Анализ алгоритмов дает нам инструмент для выбора алгоритма. Результат анализа алгоритмов — не формула для точного количества секунд или компьютерных циклов, которые потребует конкретный алгоритм. Нужно понимать, что разница между алгоритмом, который делает N + 5 операций, и тем, который делает N + 250 операций, становится незаметной, как только N становится очень большим. Вместе с распространением информационных технологий увеличился риск программных сбоев. Одним из способов избежания ошибок в алгоритмах и их реализациях служат доказательства корректности систем математическими средствами. Сложность Хотя в определении алгоритма требуется лишь конечность числа шагов, требуемых для достижения результата, на практике выполнение даже хотя бы миллиарда шагов является слишком медленным. Также обычно есть другие ограничения (на размер программы, на допустимые действия). В связи с этим вводят такие понятия, как сложность алгоритма (временна́я, по размеру программы, вычислительная и др.). Традиционно принято оценивать степень сложности алгоритма по объему используемых им основных ресурсов компьютера: процессорного времени и оперативной памяти. В связи с этим вводятся такие понятия, как временная сложность алгоритма и объемная сложность алгоритма. Параметр временной сложности становится особенно важным для задач, предусматривающих интерактивный режим работы программы, или для задач управления в режиме реального времени. Часто программисту, составляющему программу управления каким-нибудь техническим устройством, приходится искать компромисс между точностью вычислений и временем работы программы. Как правило, повышение точности ведет к увеличению времени. Объемная сложность программы становится критической, когда объем обрабатываемых данных оказывается на пределе объема оперативной памяти ЭВМ. На современных компьютерах острота этой проблемы снижается благодаря как росту объема ОЗУ, так и эффективному использованию многоуровневой системы запоминающих устройств. Программе оказывается доступной очень большая, практически неограниченная область памяти (виртуальная память). Недостаток основной памяти приводит лишь к некоторому замедлению работы из-за обменов с диском. Используются приемы, позволяющие минимизировать потери времени при таком обмене. Это использование кэш-памяти и аппаратного просмотра команд программы на требуемое число ходов вперед, что позволяет заблаговременно переносить с диска в основную память нужные значения. Исходя из сказанного можно заключить, что минимизация емкостной сложности не является первоочередной задачей. Поэтому в дальнейшем мы будем интересоваться в основном временной сложностью алгоритмов. Время выполнения программы пропорционально числу исполняемых операций. Разумеется, в размерных единицах времени (секундах) оно зависит еще и от скорости работы процессора (тактовой частоты). Для того чтобы показатель временной сложности алгоритма был инвариантен относительно технических характеристик компьютера, его измеряют в относительных единицах. Обычно временная сложность оценивается числом выполняемых операций. Как правило, временная сложность алгоритма зависит от исходных данных. Это может быть зависимость как от величины исходных данных, так и от их объема. Если обозначить значение параметра временной сложности алгоритма Корректность По гипотезе Ричарда Мейса, «избежание ошибок лучше устранения ошибок»[16]. По гипотезе Хоара, «доказательство программ решает проблему корректности, документации и совместимости»[17]. Доказательство корректности программ позволяет выявлять их свойства по отношению ко всему диапазону входных данных. Для этого понятие корректности было разделено на два типа:
Во время доказательства корректности сравнивают текст программы со спецификацией желаемого соотношения входных-выходных данных. Для доказательств типа Хоара эта спецификация имеет вид утверждений, которые называют предусловиями и постусловиями. В совокупности с самой программой их еще называют тройкой Хоара. Эти утверждения записывают P{Q}R где P — это предусловие, что должно выполняться перед запуском программы Q, а R — постусловие, правильное после завершения работы программы. Формальные методы были успешно применены для широкого круга задач, в частности: разработке электронных схем, искусственного интеллекта, автоматических систем на железной дороге, верификации микропроцессоров, спецификации стандартов и спецификации и верификации программ[18]. Вычислимость
По мере развития теории вычислимости было сформулировано несколько определений, которые, как оказалось впоследствии, определяют одно и то же множество функций — множество вычислимых функций: -функции, реализуемые на машинах Тьюринга (Алан Тьюринг); -функции, реализуемые на нормальных алгорифмах Маркова А. А. -функции, реализуемые на машине Поста; -частично рекурсивные функции (Курт Гёдель, Стивен Клини); -функции, реализуемые на регистровой машине (англ.). Представимость Формы записи алгоритма:
Обычно сначала (на уровне идеи) алгоритм описывается словами, но по мере приближения к реализации он обретает всё более формальные очертания и формулировку на языке, понятном исполнителю (например, машинный код). Нелинейное время работы алгоритма (сложность алгоритма). Например, зависимость работы алгоритма от количества обрабатываемых объектов является экспоненциальной. И часто это приводит к невозможности получить решение за приемлемое время. Если стоит условие работы в режиме реального времени, то не все алгоритмы могут работать в таком режиме. Для практического применения алгоритмов может требоваться слишком качественные данные для работы. Например, выборка без помехи, большое количество элементов выборки, фотографии лиц людей только в одном ракурсе и так далее. Расходимость алгоритмов в компьютере в отличие от сходимости математического эквивалента. Например, это может наблюдаться из-за того, что в вещественные числа хранятся с определенной точностью. Наличие подчастей в алгоритме, сложно формализуемые с точки зрения программирования. Требование большого объема памяти для работы алгоритма и так далее. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
В процессе эволюции информационных систем наблюдается усложнение выполняемых функций и рост сферы охвата — от планирования производственных ресурсов к поддержке практически всех областей действия компании. Кроме того, возрастают и такие показатели, как время, необходимое на внедрение системы, и собственно затраты на информационные системы и осуществление процесса их внедрения Роль ИТ-стратегии варьируется от формирования общей стратегии плана развития ИТ до технической поддержки инфраструктуры. П |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Экспертная система (ЭС) - это компьютерная программа, которая моделирует рассуждения человека-эксперта в некоторой определенной области и использует для этого базу знаний, содержащую факты и правила об этой области, специальную процедуру логического вывода. Разработка систем, основанных на знаниях, является составной частью исследований по ИИ, и имеет целью создание компьютерных методов решения проблем, обычно требующих привлечения экспертов-специалистов. Взаимодействие эксперта, пользователя и структурных частей системы можно представить в виде следующей базовой структуры. Рассмотрим архитектуру экспертной системы. База знаний. Основу ЭС составляет база знаний (БЗ), хранящая множество фактов и набор правил, полученных от экспертов, из специальной литературы. БЗ отличается от базы данных тем, что в базе данных единицы информации представляют собой не связанные друг с другом сведения, формулы, теоремы, аксиомы. Машина логического вывода (МЛВ). Главным в ЭС является машина логического вывода, осуществляющая поиск в базе знаний для получения решения. Она манипулирует информацией из БЗ, определяя в каком порядке следует выявлять взаимосвязи и делать выводы. МЛВ используются для моделирования рассуждений, обработки вопросов и подготовки ответов
И Инженер по знаниям - специалист по искусственному интеллекту, выступающий в роли промежуточного буфера между экспертом и базой знаний. Помогает эксперту выявить и структурировать знания. Программисты разрабатывают программное обеспечение экспертной системы и осуществляют его сопряжение со средой, в которой оно будет использоваться Пользователь - специалист предметной области, для которого предназначена система, обычно его квалификация недостаточно высока, и поэтому он нуждается в помощи и поддержке своей деятельности со стороны экспертной системы. Многочисленные экспертные системы решают в настоящее время задачи в таких областях, как медицина, образование, бизнес, дизайн и научные исследования. Базовые функции экспертных систем Приобретение знаний Приобретение знаний - это передача потенциального опыта решения проблемы от некоторого источника знаний и преобразование его в вид, который позволяет использовать эти знания в программе". Представление знаний Представление знаний — еще одна функция экспертной системы. Теория представления знаний — это отдельная область исследований, тесно связанная с философией формализма и когнитивной психологией. Предмет исследования в этой области — методы ассоциативного хранения информации, подобные тем, которые существуют в мозгу человека. При этом основное внимание, естественно, уделяется логической, а не биологической стороне процесса, опуская подробности физических преобразований. Управление процессом поиска решения При проектировании экспертной системы серьезное внимание должно быть уделено и тому, как осуществляется доступ к знаниям и как они используются при поиске решения. Знание о том, какие знания нужны в той или иной конкретной ситуации, и умение ими распорядиться — важная часть процесса функционирования экспертной системы. Такие знания получили наименование метазнаний — т.е. знаний о знаниях. Решение нетривиальных проблем требует и определенного уровня планирования и управления при выборе, какой вопрос нужно задать, какой тест выполнить, и т.д. Разъяснение принятого решения Вопрос о том, как помочь пользователю понять структуру и функции некоторого сложного компонента программы, связан со сравнительно новой областью взаимодействия человека и машины, которая появилась на пересечении таких областей, как искусственный интеллект, промышленная технология, физиология и эргономика. На сегодня вклад в эту область исследователей, занимающихся экспертными системами, состоит в разработке методов представления информации о поведении программы в процессе формирования цепочки логических заключений при поиске решения. Отличительные особенности ЭС 1. Экспертиза может проводиться только в одной конкретной области. 2. Создание новой БЗ для ЭС должно обеспечивать выполнение требований машины логического вывода. 3. ЭС объясняет ход решения задачи (цепочку рассуждений) понятным пользователю способом (можно спросить как и почему получилось такое решение и получить понятный ответ). 4. Выходные результаты являются качественными (например, совет), а не количественными (цифровыми). 5. Системы строятся по модульному принципу, что позволяет наращивать их базы знаний. 6. Наиболее подходящая область применения - решение задач дедуктивным методом (лат. deductio - выведение), позволяющим по определенным правилам логики делать выводы из некоторых утверждений и комбинаций. Можно выделить четыре основных класса ЭС: классифицирующие, доопределяющие, трансформирующие и мультиагентные. 1) Классифицирующие ЭС решают задачи распознавания ситуаций. Основным методом формирования решений в таких системах является дедуктивный логический вывод. 2) Доопределяющие ЭС используются для решения задач с не полностью определенными данными и знаниями. В таких ЭС возникают задачи интерпретации нечетких знаний и выбора альтернативных направлений поиска в пространстве возможных решений. В качестве методов обработки неопределенных знаний могут использоваться байесовский вероятностный подход, коэффициенты уверенности, нечеткая логика. 3) Трансформирующие ЭС относятся к синтезирующим динамическим экспертным системам, в которых предполагается повторяющееся преобразование знаний в процессе решения задач 4) Мулътиагентные системы — это динамические ЭС, основанные на интеграции нескольких разнородных источников знаний. Эти источники обмениваются между собой получаемыми результатами в ходе решения задач. Системы данного класса имеют следующие возможности: - реализация альтернативных рассуждений на основе использования различных источников знаний и механизма устранения противоречий; - распределенное решение проблем, декомпозируемых на параллельно решаемые подзадачи с самостоятельными источниками знаний; - применение различных стратегий вывода заключений в зависимости от типа решаемой проблемы; - обработка больших массивов информации из баз данных; - использование математических моделей и внешних процедур для имитации развития ситуаций. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
БИЛЕТ 2 |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Во всех сферах своей деятельности, и частности в сфере обработки информации, человек сталкивается с различными способами, или методиками, решения задач. Они определяют порядок выполнения действий для получения желаемого результата – это можно трактовать как первоначальное или интуитивное определение алгоритма. Некоторые дополнительные требования приводят к неформальному определению алгоритма:
Отметим, что различные определения алгоритма, в явной или неявной форме, постулируют следующий ряд требований:
Алгоритмический объект (АО) - данные, для преобразования которых используется алгоритм. Для формального определения АО фиксируют конечный алфавит символов (цифр, букв и т.п.) и определяют правила построения АО (синтаксические правила). Процесс преобразования алгоритмических объектов в ходе выполнения алгоритма осуществляется дискретно, т.е. пошагово. Последовательность шагов детерминирована, т.е. после каждого шага указывается точно, что и как следует выполнять на следующем шаге. Процесс преобразования АО, включающий в себя заданную последовательность шагов, называют алгоритмическим процессом (АП). Механизм реализации АП прослеживается на алгоритмических моделях, использующих конечные наборы простейших АО и конечные наборы элементарных действий. Выделяют три основных типа алгоритмических моделей:
В теории вычислительных алгоритмов доказана сводимость одного типа модели к другой: всякий алгоритм, описанный средствами одной модели, может быть описан также средствами другой. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
WWW – это распределенная среда, состоящая из автономных систем, узлы которой все чаще формируются как реляционные базы данных. Точно так же пользование электронными публикациями предполагает наличие распределенной системы, в которой имеется довольно низкий уровень доверия между клиентом и сервером. Хотя исследовательское сообщество весьма интенсивно занималось вопросами распределенных баз данных, и плоды этих усилий находят отражение в коммерческих продуктах, новая среда, возникшая в рамках WWW, заставляет переосмыслить многие концепции существующей технологии распределенных баз данных. Информационные ресурсы могут использоваться для решения разнообразных научных и прикладных задач: от поиска необходимой информации до задач принятия управленческих решений. При этом, в зависимости от вида учреждений, пользователю сети этого учреждения должны предоставляться свои собственные виды информационных услуг. Так, например, в образовательных структурах важнейшей информационной услугой будет дистанционное образование, в банках и на биржах - проведение электронных сделок, на производствах - реклама своей продукции, на вокзалах, аэропортах - выдача информации о наличии билетов и заказ билетов и т.д. Развитие сети научного учреждения связано, прежде всего, с развитием информационных ресурсов, направленных на обеспечение среди ученых общего информационного пространства и доступа к различного рода электронным библиотекам, каталогам электронных публикации и т.д. При этом научное учреждение должно стремится к обеспечению в своей сети следующего набора информационных услуг:
Создание этих видов информационных услуг основывается на применении современных программных продуктов и технологий таких как: - базовые технологии Internet(WWW, E-mail и т.д.) - гипертекстовый язык HTML - архитектура клиент - сервер - использование инструментальных средств Java, CGI, JavaScript, и т.д. - SQL-ориентированные системы управления базами данных (СУБД) |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Программирование - сравнительно молодая и быстро развивающаяся отрасль науки и техники. Опыт ведения реальных разработок и совершенствования имеющихся программных и технических средств постоянно переосмысливается, в результате чего появляются новые методы, методологии и технологии, которые, в свою очередь, служат основой более современных средств разработки программного обеспечения. Исследовать процессы создания новых технологий и определять их основные тенденции целесообразно, сопоставляя эти технологии с уровнем развития программирования и особенностями имеющихся в распоряжении программистов программных и аппаратных средств. Технологией программирования называют совокупность методов и средств, используемых в процессе разработки программного обеспечения. Как любая другая технология, технология программирования представляет собой набор технологических инструкций, включающих:
Кроме набора операций и их последовательности, технология также определяет способ описания проектируемой системы, точнее модели, используемой на конкретном этапе разработки. Различают технологии, используемые на конкретных этапах разработки или для решения отдельных задач этих этапов, и технологии, охватывающие несколько этапов или весь процесс разработки. В основе первых, как правило, лежит ограниченно применимый метод, позволяющий решить конкретную задачу. В основе вторых обычно лежит базовый метод или подход (парадигма), определяющий совокупность методов, используемых на разных этапах разработки, или методологию. Исторически в развитии программирования можно выделить несколько принципиально отличающихся методологий. Изначально понятие технологии как таковой — это 60-е годы прошлого столетия — это период "стихийного" программирования. В этот период отсутствовало понятие структуры программы, типов данных и т.д. Вследствие этого код получался запутанным, противоречивым. Программирование тех лет считалось искусством. Конец 60-х — кризис в программирование. Выход из этого кризиса — переход к структурной парадигме программирования. Структурный подход к программированию представляет собой совокупность рекомендуемых технологических приемов, охватывающих выполнение всех этапов разработки программного обеспечения. В основе структурного подхода лежит декомпозиция (разбиение на части) сложных систем с целью последующей реализации в виде отдельных небольших подпрограмм. С появлением других принципов декомпозиции (объектного, логического и т.д.) данный способ получил название процедурной декомпозиции. Другим базовым принципом структурного программирования является использование при составлении программ только базовых алгоритмических структур (см. билет 4), запрет на использование оператора GOTO. Структурный подход требовал представления задачи в виде иерархии подзадач простейшей структуры. Проектирование осуществлялось "сверху-вниз" и подразумевало реализацию общей идеи, обеспечивая проработку интерфейсов подпрограмм. Одновременно вводились ограничения на конструкции алгоритмов, рекомендовались формальные модели их описания, а также специальный метод проектирования алгоритмов — метод пошаговой детализации. Поддержка принципов структурного программирования была заложена в основу так называемых процедурных языков программирования. Как правило, они включали основные "структурные" операторы передачи управления, поддерживали вложение подпрограмм, локализацию и ограничение области "видимости" данных. Среди наиболее известных языков этой группы стоит назвать PL/1, ALGOL-68, Pascal, С. Дальнейший рост сложности и размеров разрабатываемого программного обеспечения потребовал развития структурирования данных. Как следствие этого в языках появляется возможность определения пользовательских типов данных. Одновременно усилилось стремление разграничить доступ к глобальным данным программы, чтобы уменьшить количество ошибок, возникающих при работе с глобальными данными. В результате появилась и стала развиваться технология модульного программирования. Модульное программирование предполагает выделение групп подпрограмм, использующих одни и те же глобальные данные, в отдельно компилируемые модули (библиотеки подпрограмм), например, модуль графических ресурсов. Связи между модулями при использовании данной технологии осуществляются через специальный интерфейс, в то время как доступ к реализации модуля (телам подпрограмм и некоторым "внутренним" переменным) запрещен. Эту технологию поддерживают современные версии языков Pascal и С (C++), языки Ада и Modula. Объектно-ориентированное программирование (ООП) определяется как технология создания сложного программного обеспечения, основанная на представлении программы в виде совокупности объектов, каждый из которых является экземпляром определенного типа (класса), а классы образуют иерархию с наследованием свойств. Взаимодействие программных объектов в такой системе осуществляется путем передачи сообщений. Основным достоинством объектно-ориентированного программирования по сравнению с модульным программированием является "более естественная" декомпозиция программного обеспечения, которая существенно облегчает его разработку. Это приводит к более полной локализации данных и интегрированию их с подпрограммами обработки, что позволяет вести практически независимую разработку отдельных частей (объектов) программы. Кроме этого, объектный подход предлагает новые способы организации программ, основанные на механизмах наследования, полиморфизма, композиции, наполнения. Эти механизмы позволяют конструировать сложные объекты из сравнительно простых. В результате существенно увеличивается показатель повторного использования кодов и появляется возможность создания библиотек классов для различных применений. Бурное развитие технологий программирования, основанных на объектном подходе, позволило решить многие проблемы. Так были созданы среды, поддерживающие визуальное программирование, например, Delphi, C++ Builder, Visual C++ и т. д. При использовании визуальной среды у программиста появляется возможность проектировать некоторую часть, например, интерфейсы будущего продукта, с применением визуальных средств добавления и настройки специальных библиотечных компонентов. Результатом визуального проектирования является заготовка будущей программы, в которую уже внесены соответствующие коды. Можно дать обобщающее определение: объект ООП — это совокупность переменных состояния и связанных с ними методов (операций). Упомянутые методы определяют, как объект взаимодействует с окружающим миром. Под методами объекта понимают процедуры и функции, объявление которых включено в описание объекта и которые выполняют действия. Возможность управлять состояниями объекта посредством вызова методов в итоге и определяет поведение объекта. Эту совокупность методов часто называют интерфейсом объекта. Инкапсуляция — это механизм, который объединяет данные и методы, манипулирующие этими данными, и защищает и то и другое от внешнего вмешательства или неправильного использования. Когда методы и данные объединяются таким способом, создается объект. Применяя инкапсуляцию, мы защищаем данные, принадлежащие объекту, от возможных ошибок, которые могут возникнуть при прямом доступе к этим данным. Кроме того, применение этого принципа очень часто помогает локализовать возможные ошибки в коде программы. А это намного упрощает процесс поиска и исправления этих ошибок. Можно сказать, что инкапсуляция подразумевает под собой скрытие данных, что позволяет защитить эти данные. Однако применение инкапсуляции ведет к снижению эффективности доступа к элементам объекта. Это обусловлено необходимостью вызова методов для изменения внутренних элементов (переменных) объекта. Но при современном уровне развития вычислительной техники эти потери в эффективности не играют существенной роли. Наследование — это процесс, посредством которого один объект может наследовать свойства другого объекта и добавлять к ним черты, характерные только для него. В итоге создаётся иерархия объектных типов, где поля данных и методов "предков" автоматически являются и полями данных и методов "потомков". Смысл и универсальность наследования заключается в том, что не надо каждый раз заново ("с нуля") описывать новый объект, а можно указать "родителя" (базовый класс) и описать отличительные особенности нового класса. В результате новый объект будет обладать всеми свойствами родительского класса плюс своими собственными отличительными особенностями. Полиморфизм — это свойство, которое позволяет одно и тоже имя использовать для решения нескольких технически разных задач. Полиморфизм подразумевает такое определение методов в иерархии типов, при котором метод с одним именем может применяться к различным родственным объектам. В общем смысле концепцией полиморфизма является идея "один интерфейс — множество методов". Преимуществом полиморфизма является то, что он помогает снижать сложность программ, разрешая использование одного интерфейса для единого класса действий. Выбор конкретного действия, в зависимости от ситуации, возлагается на компилятор. Современная технология программирования — компонентный подход, который предполагает построение программного обеспечения из отдельных компонентов — физически отдельно существующих частей программного обеспечения, которые взаимодействуют между собой через стандартизованные двоичные интерфейсы. В отличие от обычных объектов объекты-компоненты можно собрать в динамически вызываемые библиотеки или исполняемые файлы, распространять в двоичном виде (без исходных текстов) и использовать в любом языке программирования, поддерживающем соответствующую технологию. На сегодня рынок объектов стал реальностью. Это позволяет программистам создавать продукты, хотя бы частично состоящие из повторно использованных частей, т.е. использовать технологию, хорошо зарекомендовавшую себя в области проектирования аппаратуры. Компонентный подход лежит в основе технологий, разработанных на базе COM (Component Object Model — компонентная модель объектов), и технологии создания распределенных приложенийCORBA (Common Object Request Broker Architecture — общая архитектура с посредником обработки запросов объектов). Эти технологии используют сходные принципы и различаются лишь особенностями их реализации. Технология СОМ фирмы Microsoft является развитием технологии OLE (Object Linking and Embedding — связывание и внедрение объектов), которая использовалась в ранних версиях Windows для создания составных документов. Технология СОМ определяет общую парадигму взаимодействия программ любых типов: библиотек, приложений, операционной системы, т. е. позволяет одной части программного обеспечения использовать функции (службы), предоставляемые другой, независимо от того, функционируют ли эти части в пределах одного процесса, в разных процессах на одном компьютере или на разных компьютерах. Модификация СОМ, обеспечивающая передачу вызовов между компьютерами, называется DCOM (Distributed COM — распределенная СОМ). |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Архитектура приложений (архитектура инфраструктуры) Архитектура приложений покрывает достаточно широкую область, которая начинается с идентификации того, какие прикладные системы нужны предприятию для выполнения бизнес-процессов, и включает такие аспекты, как проектирование, разработка (или приобретение) и интеграция прикладных систем. В архитектуре приложений, как правило, выделяют для основные области: - формирование и управление портфелем прикладных систем предприятия; - разработку прикладных систем. Портфель прикладных систем предприятия является общим планом того, как потребности бизнес-процессов предприятия обеспечиваются набором прикладных систем. Он определяет область ответственности и приоритетность каждого приложения, а так же то, как будет достигаться необходимая функциональность. Портфель прикладных систем описывает приложения, предназначенные для выполнения функций организации, а также обмена информацией между клиентами, поставщиками и партнерами предприятия. При этом описываются также каналы возможного взаимодействия пользователей с приложениями: веб-браузеры, графический интерфейс «толстого» клиента, мобильные устройства и т.д. Портфель прикладных систем обеспечивает целостных взгляд на функциональные компоненты информационных систем, которые обеспечивают потребности бизнес-архитектуры и архитектуры информации и поддерживаются технологической архитектурой. Область разработки прикладных систем описывает те технологии, которые используются для построения систем, разделения их на функциональные составляющие, создания интерфейсов, настройки, а также используемые для этого шаблоны, руководства и т.д. Основу архитектуры приложений составляет портфель прикладных систем – интегрированный набор информационных систем предприятия, который обеспечивает потребности бизнеса и включает в себя следующие аспекты: - имеющийся портфель прикладных систем. Это каталог имеющихся приложений и компонент, который отражает их связи с поддерживаемыми ими бизнес-процессами, интерфейсы с другими системами, используемую и требуемую информацию, используемые инфраструктурные шаблоны; - планируемый портфель прикладных систем. Представляет функциональность, которая требуется для обеспечения желаемого состояния бизнес-архитектуры и архитектуры информации предприятия; - план развития. Процесс перехода от текущего к будущему портфелю прикладных систем в рамках ИТ-проектов. Техническое состояние прикладной системы оценивается по ряду характеристики, включая точность и корректность данных, архитектуру, структуру программного кода, быстроту отклика, время простоя, уровень технического сопровождения, возможность получения отчетов и т.д. Ценность прикладной системы с точки зрения бизнеса означает способность системы обеспечивать выполнение основных функций предприятия, подразделения или процесса, поэтому портфель прикладных систем должен быть актуальным для бизнеса. В рамках реализации программы развития могут быть осуществлены следующие действия с прикладными системами: - вывод из эксплуатации (замена, то есть низкая ценность для бизнеса и плохое техническое состояние); - проведение переоценки (низкая ценность для бизнеса и отличное техническое состояние); - развитие инфраструктуры прикладной системы (высокая ценность для бизнеса и плохое техническое состояние); - обеспечение сопровождения и развития (высокая ценность для бизнеса и отличное техническое состояние). Технологическая архитектура (архитектура инфраструктуры) Эта область рассматривает «традиционные» аспекты построения информационных систем, которые необходимы для поддержки прикладных систем и информационных ресурсов организации. Для технологической архитектур иногда используются такие термины, как «платформы», «инфраструктура», «системная архитектура» или «ИТ-архитектура». Основное назначение технологической архитектуры – это обеспечение надежных ИТ-сервисов, предоставляемых в рамках всего предприятия в целом и координируемых департаментами информационных технологий. В технологической архитектуре можно выделить шесть архитектурных компонентов (сервисов), в каждом из которых выделяется определенное количество технологических «строительных блоков»: - сервисы данных – СУБД, хранилища данных, системы поддержки принятия решений; - прикладные сервисы – языки программирования, средства разработки приложений, системы коллективной работы (средства групповой работы и электронной почты, средства управления документами), архитектура приложений (модель компонентов, серверы приложений, серверы поддержки тонких клиентов), геоинформационные системы и средства; - программное обеспечение промежуточного слоя; - вычислительная архитектура – операционные системы и аппаратное обеспечение (приложения для настольных систем, операционные системы для настольных систем, мобильные устройства – ноутбуки, беспроводные устройства, персональные цифровые помощники, серверы приложений/данных, сетевые операционные системы, принтеры), среда для веб-инфраструктуры (браузеры, веб-порталы, веб-серверы, средства управления и создания контента, серверы каталогов, форматы публикаций информации), системы хранения (Storage Area Network – сети хранения данных, накопители на магнитных лентах, накопители на оптических носителях, системы хранения высокой надежности RAID), средства системного управления (средства сетевого управления, администрирование IP), топологии (топология распределенных приложений); - сетевые сервисы – локальные сети (протоколы, кабельные системы, топология), глобальные сети (транспорт, протоколы), технологии доступа (пользователи с удаленным доступом, эмуляция терминалов и шлюзы, беспроводные технологии для локальных и глобальных сетей, интегрированные средства передачи данных и голоса, обеспечение доступности, средства видеоконференций), голосовые технологии (голос/данные поверх IP-протокола, голосовая почта), сетевое аппаратное обеспечение (концентраторы, маршрутизаторы и пр.); - сервисы безопасности – авторизация, аутентификация (внутренняя и внешняя аутентификация), сетевая безопасность, физическая безопасность центров обработки данных, прочие сервисы безопасности (обнаружение вторжений, защита от вирусов). Технологическая архитектура является архитектурой инфраструктуры аппаратного и программного обеспечения, которая обеспечивает работу прикладных систем и выполнение операционных (нефункциональных) требований, предъявляемых к архитектуре прикладных систем и информации. Она описывает структуру и взаимосвязи между используемыми технологиями и то, как эти технологии обеспечивают выполнение операционных требований организации. Хорошая технологическая архитектура должна быть построена с учетом поддержки прикладных систем, играющих важную роль в работе организации. Хорошая архитектура приложений должна эффективно использовать технологическую архитектуру, чтобы обеспечить должный уровень соответствия всем операционным требованиям. Достаточно легко определить тенденции в современном ИТ-мире: аутсорсинг, глобализация, увеличение степени правовой регламентации, постоянное усложнение и требования руководства повышать прибыльность. Однако значительно сложнее предугадать, как эти тенденции повлияют на масштаб, состав и стратегию ИТ-отдела в ближайшие годы. Модель ИТ-отдела Модель ИТ-отдела как сервисного приложения компании уходит в прошлое. Зарождается новая философия инноваций и эффективности. Этот гипотетический ИТ-отдел недалекого будущего представляется небольшим по составу, более рассредоточенным и зависимым от поставщиков услуг. По-прежнему сохранится потребность в многопрофильных специалистах, не только обладающих глубокими познаниями в области ИТ, но и способных создавать на их основе новые продукты и решения. ИТ-руководители видятся не просто управляющими инфраструктуры, а лидерами инновационных процессов, умеющими перестроить соответствующим образом свой отдел. ИТ должны стать если не флагманом, то полноправным партнером в проведении экономических инновационных процессов. Рассмотрим детально отличительные черты и принципы работы постмодернистского ИТ—отдела. ИТ-отдел будет отвечать за проведение инновационных процессов всей компании. Добрая половина сорокалетней истории использования ИТ в коммерческой деятельности была в основном потрачена на автоматизацию работы предприятия. Данный процесс может продолжаться и далее, однако ограничиться этим в условиях современного бизнеса уже невозможно. Вопрос о том, как использовать ИТ, чтобы отстоять и расширить свое место на рынке, стоит как никогда остро. Соединив систему широкополосной связи, интернет-технологии, соответствующее программное обеспечение, мобильные телефоны и РВА, ИТ-специалист создает новые возможности и решения, которые крайне востребованы компаниями и их клиентами. ИТ-отделы не могут больше заниматься исключительно удовлетворением потребностей внутренних клиентов. Их основной задачей должна стать разработка инноваций, которые принесут прибыль компании и привлекут новых внешних клиентов. Переход к сервисно-ориентированной архитектуре (Srvice-Oriented Architecture, SOA) усилит потенциальные возможности ИТ-отдела активно участвовать в инновационной деятельности, так как предполагает понимание ИТ-персоналом основ функционирования компании. Основным принципом руководства ИТ-отделом станет внедрение сервисной модели предоставления услуг. ИТ-руководители располагают множеством механизмов для управления инфраструктурой и отдельной продукцией. Существуют широко распространенные системы, позволяющие контролировать практически любой аспект деятельности ИТ-отдела, начиная с библиотеки ITIL и заканчивая различными комплексными программами. ИТ-функции будут более разобщены, их придется организовывать в единое целое. Можно сказать, что процесс расформирования ИТ-отделов уже обозначился особенно в крупных компаниях, где многие ИТ-функции, такие как компьютерная служба помощи и текущее обслуживание программного обеспечения, исполняются аутсорсерами. Судя по всему, многие ИТ-должности станут звеньями в цепи предоставления расширенных услуг, сформированных на современных производственных цепях поставки. Именно поэтому для сотрудников ИТ-отдела сейчас важны такие навыки, как управление взаимоотношениями и руководство проектами. Исчезнут младшие ИТ-должности. ИТ-отделу потребуются квалифицированные кадры, однако, ИТ-руководителям будет достаточно сложно найти нужных им работников. Навыки, которые могут исчезнуть из ИТ- отделов. в процессе автоматизации или в связи с применением аутсорсинга: программирование, оперативное управление, помощь сотрудникам. А ведь на младшие ИТ-должности‚ как правило, нанимаются сотрудники именно с такими навыками. ИТ руководитель должен сделать шаг вперед. ИТ-руководители, которые по инерции продолжают обслуживание своих компаний по традиционной форме — построение инфраструктуры, разработка пакета программного обеспечения и его поддержка, либо будут вынуждены выполнять все возрастающий объем работы, либо обречены на увольнение. Но для того чтобы выжить в дальнейшем необходимо стать ИТ-руководителем-реформатором: 1) новатор — бизнесу нужна новая генерация руководителей‚ которые смогут не просто управлять ИТ‚ но с их помощью изменить компанию к лучшему; 2) Лидер – ИТ-директорам скоро придется сделать выбор: взять на себя новые функции, либо уступить лидерство другому топ-менеджеру; 3) экономист — ИТ-директора должны исполнять сразу две роли - борца за снижение затрат и новатора, и возникает соблазн отказаться от одной; 4) профессионал — ИТ—директор должен одинаково хорошо разбираться и в бизнесе, и в информационных технологиях, отличая технологии повышающие эффективность, от новомодных игрушек; 5) дипломат — дальновидные ИТ-директора знают, как учесть разные требования и представить удовлетворяющую всех информацию в понятных всем финансовых терминах. Первое правило управления бизнес-процессами гласит: важно определить как роль управления информационными технологиями, так и то, как структурные подразделения могут взаимодействовать друг с другом. Второе правило — сближение ИТ и бизнеса: руководители сферы ИТ должны быть вовлечены в координацию этапов процесса между разными департаментами, которым необходима поддержка со стороны ИТ. Вывод: на место директора информационной службы CIO (Chief Integration Officer) должен прийти директор по процессам, или его иногда называют директор проектного офиса СРО (Chief Project Officer). Но недостаточно просто сменить название должности с CIO на СРО. Руководство компании и начальники бизнес-подразделений ожидают от человека, занимающего этот новый пост, знания потенциала инноваций, который предоставляют новые ИТ-приложения и технологии, и умения перенести их в бизнес-процессы. Компетентность СРО заключается в том, чтобы сочетать управление процессами со знанием ИТ. Структуру и организацию управления бизнес-процессами, а также то, в какую категорию надлежит отнести бывшего CIO, а ныне директора по процессам (СРО), можно представить в виде трехуровневой модели: — на первом уровне, директорском (так называемый С-1еvе1 managment, включающий генерального директора — СЕО, директора по оперативному управлению — СОО, CIO, финансового директора — СFО и др.), принимаются решения о стратегически важной деятельности. В центре внимания здесь находятся ключевые компетенции, используемые компанией для производства продукции. Одна из главных обязанностей СРО — определять основной курс управления бизнес-процессами, создавать и внедрять необходимые методы, инструменты и платформы; — на втором уровне протекают бизнес-процессы, связанные с ИТ, причем критическое значение здесь имеет децентрализация. СРО должен обеспечить доступность знаний о децентрализованном процессе для всех сотрудников, задействованных в нем и ответственных за этот процесс, а также возможность централизованно его улучшать, делая управление процессом обязанностью каждого сотрудника; — третий уровень вновь выводит на первоначальный этап: результаты исполнения бизнес-процессов собираются, оцениваются и подготавливаются для того, чтобы руководство могло принимать решения и вносить коррективы. Выявленные при этом потребности ведут к формированию новых принципов построения организации и новой технологической архитектуре. Внутри процесса такие хорошо известные технологии, как системы управления потоками работ (workflow) и системы интеграции приложений предприятия (ЕAI-системы), объединяются и комбинируются с интеграционными платформами платформами приложений. Очевидно, что ориентация на процессы требует от ИТ-менеджеров иных подходов к своей работе. Изменения на рынке, требования по конкурентоспособности и развитие технологий ведут к постоянной реструктуризации бизнес-процессов, которая, в свою очередь, требует более широких навыков и знаний, нежели только умения нести ответственность за ИТ-системы. Директор по процессам должен иметь новые должностные обязанности: 1. Определять и описывать значимые бизнес-процессы и анализировать их на основе аспектов деятельности предприятия. 2. Выявлять и устранять «узкие» места (простои, ненужные задержки и т. п.), постоянно оптимизировать процессы. 3. Создавать интегрированные, общекорпоративные бизнес: процессы, которые пересекают границы структурных подразделений и сливаются в полную цепочку создания добавленной стоимости включающую и внешних партнеров. 4. Организовывать управление бизнес-процессами таким образом, чтобы ответственные за процессы сотрудники отчитывались за отдельные процессы и подпроцессы. 5. Обеспечивать интеграцию внутренних и внешних программных приложений. 6. Разрабатывать и внедрять высокопроизводительные, ориентированные на работу в реальном времени ИТ-платформы, включая аппаратное и программное обеспечение. 7. Устанавливать систему непрерывного мониторинга производственных процессов, в том числе системы отчетности. 8. Развивать системы технологически и организационно- Таким образом, новый директор информационной службы становится агентом изменений в компании, обеспечивая гибкие, динамичные и построенные на сотрудничестве процессы и системы. Для лиц, выполняющих эту роль, особенно важны четыре управленческих навыка: - коммуникационные навыки. Организационные изменения могут происходить только при поддержке со стороны внутренних и внешних партнеров. Следовательно, партнеров необходимо держать в курсе событий, ведь основополагающим фактором успешного внедрения изменений является взаимодействие; — процедурное мышление. Потенциальный СРО должен уметь анализировать цепочку создания добавленной стоимости, используя свою компетентность в области технологий, бизнеса и организационного управления, и понимать всю эту цепочку в терминах динамичных процессов; — социальные умения. Долгосрочный успех в управлении бизнес-процессами возможен только в том случае, когда сотрудники ощущают себя членами одной команды, особенно если CIO намерен ввергнуть их в процесс перемен. При формировании команд и назначении ответственных за процессы (владельцев процессов) в ходе управления изменениями необходимо принимать во внимание личностные аспекты; — мотивация и настрой на инновации. В будущем ключевым навыком для CIO станет умение создавать во всей организации, начиная от производственного подразделения и заканчивая отделом маркетинга и высшим звеном руководства, настрой на инновации и оптимизацию. Новый уровень ответственности CIO диктуется сегодняшними требованиями бизнеса: CGO (Chief Governance Officer) — директор по корпоративному управлению. Он отвечает за организацию эффективного взаимодействия всех отделов друг с другом и развитие системы коммуникаций в организации. Поле деятельности для CGO не ИТ, а БТ — технологии для бизнеса. Внедрять нужно только те новые технологии, которые позволяют решать задачи, стоящие перед бизнесом. Для этого современный CIO (Chief Integration Officer) должен хорошо ориентироваться в бизнес-процессах и предлагать способы их оптимизации, повышающие отдачу от инвестиций в ИТ: — переход от традиционных бизнес-процессов к автоматизированным, электронным процессам; — передача ответственности сотрудникам; — предоставление свободного доступа к информации для внутреннего и внешнего пользования; — создание системы поощрений сотрудников, основанной на эффективности их работы; — концентрация на стратегических целях компании. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Жизненный цикл программного обеспечения (ПО) — период времени, который начинается с момента принятия решения о необходимости создания программного продукта и заканчивается в момент его полного изъятия из эксплуатации. Этот цикл — процесс построения и развития ПО. Модель жизненного цикла ПО — структура, определяющая последовательность выполнения и взаимосвязи процессов, действий и задач на протяжении жизненного цикла. Модель жизненного цикла зависит от специфики, масштаба и сложности проекта и специфики условий, в которых система создается и функционирует. Стадия — часть процесса создания ПО, ограниченная определенными временными рамками и заканчивающаяся выпуском конкретного продукта (моделей, программных компонентов, документации), определяемого заданными для данной стадии требованиями. - Каскадная стратегия Каскадная стратегия (однократный проход, водопадная или классическая модель) подразумевает линейную последовательность прохождения стадий создания информационной системы. Другими словами, переход с одной стадии на следующую происходит только после того, как будет полностью завершена работа на текущей. Данная модель применяется при разработке информационных систем, для которых в самом начале разработки можно достаточно точно и полно сформулировать все требования. Достоинства модели: · на каждой стадии формируется законченный набор проектной документации, отвечающий критериям полноты и согласованности; · выполняемые в четкой последовательности стадии позволяют уверенно планировать сроки выполнения работ и соответствующие ресурсы (денежные, материальные и людские).
Н · реальный процесс разработки информационной системы редко полностью укладывается в такую жесткую схему. Особенно это относится к разработке нетиповых и новаторских систем; · жизненный цикл основан на точной формулировке исходных требований к информационной системе. Реально в начале проекта требования заказчика определены лишь частично; · основной недостаток – результаты разработки доступны заказчику только в конце проекта. В случае неточного изложения требований или их изменения в течение длительного периода создания ИС заказчик получает систему, не удовлетворяющую его потребностям. - Инкрементная стратегия (поэтапная с промежуточным контролем) Инкрементная стратегия (англ. increment – увеличение, приращение) подразумевает разработку информационной системы с линейной последовательностью стадий, но в несколько инкрементов (версий), т. е. с запланированным улучшением продукта.
В Данная модель жизненного цикла характерна при разработке сложных и комплексных систем, для которых имеется четкое видение (как со стороны заказчика, так и со стороны разработчика) того, что собой должен представлять конечный результат (информационная система). Разработка версиями ведется в силу разного рода причин: · отсутствия у заказчика возможности сразу профинансировать весь дорогостоящий проект; · отсутствия у разработчика необходимых ресурсов для реализации сложного проекта в сжатые сроки; · требований поэтапного внедрения и освоения продукта конечными пользователями. Внедрение всей системы сразу может вызвать у ее пользователей неприятие и только «затормозить» процесс перехода на новые технологии. Образно говоря, они могут просто «не переварить большой кусок, поэтому его надо измельчить и давать по частям». Достоинства и недостатки этой стратегии такие же, как и у классической. Но в отличие от классической стратегии заказчик может раньше увидеть результаты. Уже по результатам разработки и внедрения первой версии он может незначительно изменить требования к разработке, отказаться от нее или предложить разработку более совершенного продукта с заключением нового договора. - Спиральная стратегия Спиральная стратегия (эволюционная или итерационная модель, автор Барри Боэм, 1988 г.) подразумевает разработку в виде последовательности версий, но в начале проекта определены не все требования. Требования уточняются в результате разработки версий.
Д Достоинства модели: · позволяет быстрее показать пользователям системы работоспособный продукт, тем самым, активизируя процесс уточнения и дополнения требований; · допускает изменение требований при разработке информационной системы, что характерно для большинства разработок, в том числе и типовых; · обеспечивает большую гибкость в управлении проектом; · позволяет получить более надежную и устойчивую систему. По мере развития системы ошибки и слабые места обнаруживаются и исправляются на каждой итерации; · позволяет совершенствовать процесс разработки – анализ, проводимый в каждой итерации, позволяет проводить оценку того, что должно быть изменено в организации разработки, и улучшить ее на следующей итерации; · уменьшаются риски заказчика. Заказчик может с минимальными для себя финансовыми потерями завершить развитие неперспективного проекта. Недостатки модели: · увеличивается неопределенность у разработчика в перспективах развития проекта. Этот недостаток вытекает из предыдущего достоинства модели; · затруднены операции временного и ресурсного планирования всего проекта в целом. Для решения этой проблемы необходимо ввести временные ограничения на каждую из стадий жизненного цикла. Переход осуществляется в соответствии с планом, даже если не вся запланированная работа выполнена. План составляется на основе статистических данных, полученных в предыдущих проектах и личного опыта разработчиков. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
БИЛЕТ 3 |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Термин «компьютерная алгебра» возник как синоним терминов «символьные вычисления», «аналитические вычисления», «аналитические преобразования» и т. д. Даже в настоящее время этот термин на французском языке дословно означает «формальные вычисления». В чём основные отличия символьных вычислений от численных и почему возник термин «компьютерная алгебра»? Когда мы говорим о вычислительных методах, то считаем, что все вычисления выполняются в поле вещественных или комплексных чисел. В действительности же всякая программа для ЭВМ имеет дело только с конечным набором рациональных чисел, поскольку только такие числа представляются в компьютере. Для записи целого числа отводится обычно 16 или 32 двоичных символа (бита), для вещественного – 32 или 64 бита. Это множество не замкнуто относительно арифметических операций, что может выражаться в различных переполнениях (например, при умножении достаточно больших чисел или при делении на маленькое число). Ещё более существенной особенностью вычислительной математики является то, что арифметические операции над этими числами, выполняемые компьютером, отличаются от арифметических операций в поле рациональных чисел. Особенностью компьютерных вычислений является неизбежное наличие погрешности или конечная точность вычислений. Каждую задачу требуется решить с использованием имеющихся ресурсов ЭВМ за обозримое время с заданной точностью, поэтому оценка погрешности — важная задача вычислительной математики. Решение проблемы точности вычислений и конечности получаемых численных результатов в определённой степени даётся развитием систем компьютерной алгебры. Системы компьютерной алгебры, осуществляющие аналитические вычисления, широко используют множество рациональных чисел. Компьютерные операции над рациональными числами совпадают с соответствующими операциями в поле рациональных чисел. Кроме того, ограничения на допустимые размеры числа (количество знаков в его записи) позволяет пользоваться практически любыми рациональными числами, операции над которыми выполняются за приемлемое время. В компьютерной алгебре вещественные и комплексные числа практически не применяются, зато широко используется алгебраические числа. Алгебраическое число задаётся своим минимальным многочленом, а иногда для его задания требуется указать интервал на прямой или область в комплексной плоскости, где содержится единственный корень данного многочлена. Многочлены играют в символьных вычислениях исключительно важную роль. На использовании полиномиальной арифметики основаны теоретические методы аналитической механики, они применяются во многих областях математики, физики и других наук. Кроме того, в компьютерной алгебре рассматриваются такие объекты, как дифференциальные поля (функциональные поля), допускающие показательные, логарифмические, тригонометрические функции, матричные кольца (элементы матрицы принадлежат кольцам достаточно общего вида) и другие. Даже при арифметических операциях над такими объектами происходит 12 Глава 1. Возникновение и развитие СКМ разбухание информации, и для записи промежуточных результатов вычислений требуется значительный объём памяти ЭВМ. В научных исследованиях и технических расчётах специалистам приходится гораздо больше заниматься преобразованиями формул, чем собственно численным счётом. Тем не менее, с появлением ЭВМ основное внимание уделялось автоматизации численных вычислений, хотя ЭВМ начали применяться для решения таких задач символьных преобразований, как, например, символьное дифференцирование, ещё в 50-х годах прошлого века. Активная разработка систем компьютер- ной алгебры началась в конце 60-х годов. С тех пор создано значительное количество различных систем, получивших различную степень распространения; некоторые системы продолжают развиваться, другие отмирают, и постоянно появляются новые. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Типовая структура автоматизированных систем научных исследований, содержащая три уровня: объектный, инструментальный и сервисный (базовый). Объектный уровень характеризуется связью с объектом исследований. Его назначение состоит в организации процесса экспериментирования, т.е. реализации управления экспериментальной установкой, регистрации данных, их оперативной обработки, накопления и представления первичных результатов исследователю, в том числе и оказание ему помощи в интерпретации результатов эксперимента и принятии решения о дальнейшем проведении исследований. На объектный уровень также возлагают операции, связанные с проверкой и тестированием экспериментального оборудования, текущей регистрацией и документированием данных. Инструментальный уровень предназначен для проведения достаточно сложных видов обработки экспериментальных данных, научных расчетов и моделирования, если они не требуют слишком больших мощностей вычислительного оборудования. Здесь осуществляется накопление и длительное хранение информации, полученной в результате исследований, формируются архивы и банки данных по отдельным проблемам исследований. На инструментальном уровне осуществляется отработка различных алгоритмов и программ, составленных пользователем, в том числе и программ, используемых на объектном уровне. Базовый (или сервисный) уровень используется для осуществления наиболее сложных и громоздких научных расчетов, моделирования, обработки и представления информации, формирования крупных банков и баз данных, создания информационно-поисковой системы. Трехуровневая организация современных АСНИ позволяет, с одной стороны, предоставить исследователю необходимые средства вычислительной техники и автоматизации на всех этапах исследования, а с другой - сократить затраты на создание системы, уменьшить количество ЭВМ, периферийного оборудования и т.д. Необходимо подчеркнуть, что для АСНИ наиболее важным является объектный уровень, так как именно на этом уровне фигурирует исследователь, роль которого является ключевой. Именно на объектном уровне в первую очередь регистрируется новая информация об изучаемом явлении или объекте. Поэтому АСНИ, являясь многоуровневыми системами, не относятся к категории иерархических систем. Можно считать, что верхние этажи этой организации - инструментальный и базовый уровни - являются вспомогательными, оказывающими дополнительные услуги при извлечении полезной информации, разработке и проверке теоретических положений на основе экспериментальных данных. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Надежность программного обеспечения есть вероятность его работы без отказов в течение определенного периода времени, рассчитанная с учетом стоимости для пользователя каждого отказа. Надежность также не является внутренним свойством программы. Она во многом связана с тем, как программа используется. Надежность программного обеспечения существенно отличается от надежности аппаратуры. Программы не изнашиваются, поломка программы невозможна. Таким образом, надежность программного обеспечения — есть следствие исключения ошибок проектирования, т.е. ошибок, внесенных в процессе разработки программного обеспечения. Надежность является составной частью более общего понятия — качества. Качественная программа, например, не только надежна, но и компактна, совместима с другими программами, эффективна, удобна в сопровождении, вполне понятна. Можно добавить: программа должна быть разработана в срок и в пределах бюджетной стоимости. Среди прочих характеристик качества программ надежность стоит на первом месте, и поэтому дальнейшие вопросы разработки программного обеспечения рассматриваются через призму надежности. Кроссплатформенное (межплатформенное) программное обеспечение — программное обеспечение, работающее более чем на одной аппаратной платформе и/или операционной системе. Типичным примером является программное обеспечение, предназначенное для работы в операционных системах Linux и Windows одновременно. Большое количество прикладных программ также являются кроссплатформенными. Особенно это качество выражено у программ, изначально разработанных для UNIX-подобных операционных систем. Важным условием их переносимости на другие платформы является совместимость платформ с рекомендациями POSIX, а также существование компилятора GCC для платформы, на которую осуществляется перенос. Оценка стоимости программного продукта Рассматривается проблема оценки затрат и времени, необходимых для выполнения определенных этапов проекта. Менеджерам необходимо получить ответы на следующие вопросы. - Какие затраты необходимы для выполнения этапа? - Сколько это займет времени? - Какова стоимость выполнения данного этапа? Этапы расчета оценки стоимости: - Предварительные расчеты должны быть выполнены на ранней стадии для утверждения бюджета. - Во время выполнения проекта все расчеты должны регулярно обновляться. Это помогает планировать работу и содействует эффективному использованию средств. Цена продукта включает: - издержки производства; - предлагаемую прибыль Параметры, используемые для оценки проекта: - Стоимость аппаратных средств и программного обеспечения, включая их обслуживание. - Расходы на командировки и обучение. - Расходы на персонал (в основном на привлечение со стороны специалистов по программному обеспечению), включающие:
- расходы на содержание, отопление и освещение офисов; - на содержание вспомогательного персонала- бухгалтеров, секретарей, уборщиц и технического персонала; - на содержание компьютерной сети и средств связи; - на централизованные услуги - библиотеки, места отдыха и развлечения и т.д.; - на социальное обеспечение и выплаты служащим (например, пенсии и медицинская страховка).
Наиболее распространёнными проблемами, возникающими в процессе разработки ПО, считают:
Данная проблема возникает при недостаточном планировании структуры (или архитектуры) будущего программного продукта, что чаще всего является следствием отсутствия достаточного финансирования проекта: программа нужна, сколько времени займёт разработка, каковы этапы, можно ли какие-то этапы исключить или сэкономить — следствием этого процесса является то, что этап проектирования сокращается.
При этом жесткая привязка программного комплекса к конкретной программно-технической среде может стать серьезным ограничением применения этих комплексов. Возникает задача обеспечения кроссплатформенности предлагаемых программных решений. Машинонезависимость. Программный продукт обладает свойством машино-независимости, если входящие в него программы могут выполняться на вычислительной машине иной конфигурации, чем та, для которой они непосредственно предназначены. Надежность. Программный продукт обладает свойством надежности, если можно ожидать, что он будет удовлетворительно выполнять необходимые функции в течение определенного времени. Обеспечение надежности предполагает получение ответов на следующие две группы вопросов: 1) Способен ли программный продукт удовлетворить выдвинутым требованиям к нему? Если программный продукт — программа, то достигается ли необходимая точность процедур трансляции, загрузки и выполнения? 2) При функционировании в реальных условиях продолжает ли программа работать правильно в случае исходных данных, существенно отличающихся от тестовых? Как много будет выявлено скрытых ошибок после аттестации программы как работоспособной? Какова вероятность того, что результаты будут содержать необнаруженные ошибки? Структурированность. Программный продукт обладает свойством структурированности, если его взаимосвязанные части организованы в единое целое определенным образом. Структурированность программы может иметь в своей основе самые различные причины. Например, она может быть разработана в соответствии со специальными стандартами, определенными руководящими принципами и требованиями к интерфейсам, или она может быть написана с использованием языка структурного программирования, или может отражать в своей структуре процесс постепенного эволюционного развития на основе целенаправленных и систематизированных изменений. Эффективность. Программный продукт обладает свойством эффективности, если он выполняет требуемые функции без лишних затрат ресурсов и времени. Термин «ресурсы» здесь понимается в широком смысле: эта может быть оперативная память, общее количество выполняемых команд на одну итерацию решаемой задачи или на один прогон, внешняя память, пропускная способность канала и т.п. Часто эффективность приобретается ценой ухудшения других характеристик, так как нередко является машинозависимой характеристикой и определяется свойствами конкретного используемого языка программирования. Необходимость обеспечения эффективности за счет ухудшения других характеристик программного обеспечения должна особо отмечаться в задании на проектирование ПО. Точность. Программный продукт обладает свойством точности, если выдаваемые им результаты имеют точность, достаточную с точки зрения основного их назначения. Доступность. Программный продукт обладает свойством доступности, если он допускает селективное использование отдельных его компонент. Модифицируемость. Программный продукт обладает свойством модифицируемости, если он имеет структуру, позволяющую легко вносить требуемые изменения. Открытость. Программный продукт обладает свойством открытости, если его функции и назначения соответствующих операторов легко понимаются в результате чтения текста программы. Коммуникативность. Программный продукт обладает свойством коммуникативности, если он дает возможность легко описывать входные данные и выдает информацию, форма и содержание которой просты для понимания и несут полезные сведения. Отрицательным примером может служить выдаваемое программой число или набор чисел без комментариев. Информативность. Программный продукт обладает свойством информативности, если он содержит информацию, необходимую и достаточную для понимания читающим лицом назначения программных средств, принятых допущений, существующих ограничений, исходных данных, результатов, отдельных компонентов и текущего состояния программ при их функционировании. Расширяемость. Программный продукт обладает свойством расширяемости, если он позволяет увеличивать при необходимости объем памяти для хранения данных или расширять его функции. Учет человеческого фактора. Программный продукт учитывает человеческий фактор, если он способен выполнять свои функции, не требуя излишних затрат времени со стороны пользователя, неоправданных усилий пользователя по поддержанию процесса функционирования программ и без ущерба для морального состояния пользователя. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Интерне́т (англ. Internet, МФА: [ˈɪn.tə.net]) — всемирная система объединённых компьютерных сетей для хранения и передачи информации. Построена на базе стека протоколов TCP/IP. На основе интернета работает Всемирная паутина (World Wide Web, WWW) и множество других систем передачи данных. История Интернета началась в конце 50-х годов ХХ века, а именно, когда в 1957 году в СССР запустили первый искусственный спутник. В разгар холодной войны «захват» Советским Союзом космического пространства представлял серьезную угрозу для США. Необходимо было ускорить темпы разработок новейших систем защиты. С этой целью в 1957 году было создано Агентство перспективных исследований Министерства обороны США – ARPA. Эту организацию интересовал вопрос, можно ли соединять расположенные в разных местах компьютеры с помощью телефонных линий. Их целью являлась организация сети передачи данных, способной функционировать в условиях ядерного конфликта. В январе 1969 года впервые была запущена система, связавшая между собой 4 компьютера в разных концах США. А через год новая информационная сеть, названная ARPAnet, уже приступила к работе. С каждым годом ARPAnet росла и развивалась и из военной и засекреченной сети становилась все более доступной для различных организаций. В 1973 году сеть стала международной. В 1983 году был введен в строй новый механизм доступа к ARPAnet, названный «протоколом TCP/IP». Этот протокол позволял с легкостью подключаться к Интернету при помощи телефонной линии. В конце 80-х годов терпению военных пришел конец, так как сеть превратилась из секретной в общедоступную. Поэтому они отделили от сети часть для своих нужд, получившую название MILNet. В конце 90-х годов стало возможным передавать по сети не только текстовую, но и графическую информацию и мультимедиа. Одной из первых российских сетей, подключенных к Интернету, стала сеть Relcom (Релком), созданная в 1990 году на базе Российского центра «Курчатовский институт». В создании сети принимали участие специалисты кооператива «Демос» (сейчас это компания «Демос-Интернет»). Уже к концу года к Интернету было подключено 30 организаций. В 1991 году в компьютерной сети Relcom появился первый сервер новостей (электронных конференций). И очень скоро она объединила многие крупные города России (Екатеринбург, Барнаул и др.), а также некоторых других стран СНГ и стран Балтии. Сегодня Интернет состоит из миллионов компьютеров, подключенных друг к другу при помощи самых разных каналов, от сверхбыстродействующих спутниковых магистралей передачи данных до медленных коммутируемых телефонных линий. Структура Интернета включает национальные, межрегиональные и межконтинентальный уровни. Самый низший уровень состоит из отдельных поставщиков сетевого сервиса — Провайдеров. Он так и называется — уровень ISP (Internet Service Providers). Сети этого уровня включают в себя межрегиональную и региональную транспортную среду, программно-аппаратные средства и персонал для ее поддержания и прочее. Следущий уровень, так называемый, уровень пиринга (peering), использует несколько ISP и состоит из специальных узлов межсетевого обмена IP-трафиком — Internet eXchange (IX). Более высокий уровень — опорные высокоскоростные инфраструктуры национального и межнационального масштаба. Рабочее предложение (англ. Request for Comments, RFC) — документ из серии пронумерованных информационных документов Интернета, содержащих технические спецификации и стандарты, широко применяемые во всемирной сети. Название «Request for Comments» ещё можно перевести как «заявка (запрос) на отзывы» или «тема для обсуждения». В настоящее время первичной публикацией документов RFC занимается IETF под эгидой открытой организации Общество Интернета(англ. Internet Society, ISOC). Правами на RFC обладает именно Общество Интернета. Содержимое RFC Несмотря на название, запросы на отзывы RFC сейчас рассматриваются как стандарты Интернета (а рабочие версии стандартов обычно называют драфтами). Согласно RFC 2026, жизненный цикл стандарта выглядит следующим образом:
Многие старые RFC замещены более новыми версиями под новыми номерами или вышли из употребления. Такие документы получают статус исторических (Historic) Практически все стандарты Глобальной сети существуют в виде опубликованных заявок RFC. Но в виде документов RFC выходят не только стандарты, но также концепции, введения в новые направления в исследованиях, исторические справки, результаты экспериментов, руководства по внедрению технологий, предложения и рекомендации по развитию существующих Стандартов и другие новые идеи в информационных технологиях:
Почти все стандарты разрабатываются под эгидой каких-либо научных или интернет-организаций (например W3C, IETF, консорциум Юникода, Интернет2). Запросы на отзывы официально существуют только на английском языке. Строгих требований к оформлению нет. Встречаются RFC, написанные в строгом академическом стиле, иные — в дружеской неформальной манере. Существует традиция выпуска первоапрельских шуточных RFC, например, RFC 1149 рассказывает о передаче пакетов IP с помощью почтовых голубей. Появлению сети Internet и стека протоколов TCP/IP предшествовала в середине 1960-х годов разработка под эгидой агентства DARPA (Defence Advanced Research Projects Agency - Управление перспективных исследований Министерства обороны США) сети, получившей название ARPANET (Advanced Research Projects Agency NETwork). Разработка сети была поручена Стэндфордскому исследовательскому институту и трём американским университетам: Калифорнийскому в Лос-Анжелесе и Университетам штата Юта и штата Калифорния в Санта-Барбаре. Экспериментальная сеть из четырёх узлов была запущена в конце 1969 года, а к концу 1972 года в сети насчитывалось более 30 узлов. В 1974 году были разработаны модели и протоколы TCP/IP для управления обменом данными в интерсетях, а 1 января 1983 года сеть ARPANET полностью перешла на протокол TCP/IP. В конце 1970-х годов Национальный научный фонд США (National Science Foundation, NSF) начал разработку межуниверситетской сети, получившей название NSFNet, которая имела гораздо большую пропускную способность, чем ARPANET. В середине 1980-х годов произошло объединение сетей NSFNet и ARPANET, за которым закрепилось название INTRNET (Интернет). В 1984 году была разработана система доменных имён (Domain Name System, DNS), а в 1989 году появилась концепция Всемирной паутины (World Wide Web,WWW) и были разработаны протокол передачи гипертекста HTTP (HyperText Transfer Protocol) и язык разметки гипертекста HTML (HyperText Markup Language). Благодаря отсутствию единого руководства и открытости технических стандартов Интернет объединил большинство существующих сетей и к началу 21 века стал популярным средством для обмена данными. В настоящее время подключиться к Интернету можно через спутники связи, радио-каналы, кабельное телевидение, телефон, сотовую связь, специальные оптико-волоконные линии или электропровода. Координация разработок и поддержка Интернета осуществляется следующими организационными структурами (рис.):
- Internet Activities Board (IAB) - центральный орган, включающий два подкомитета: ■ исследовательский - IRTF (Internet Research Task Force); ■ законодательный - IETF (Internet Engineering Task Force), выполняющий функцию анализа, разработки и принятия стандартов сети Internet, получивших название RFC (Request For Comments); - Network Information Center (NIC) - орган, ответственный за распространение технической информации, работу по регистрации и подключению пользователей к Internet и за решение ряда административных задач, таких как распределение адресов в сети. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Современные программные приложения и информационные системы достигли такого уровня развития, что термин «архитектура» в применении к ним уже давно не удивляет. Грамотно построить информационную структуру, эффективно и надежно функционирующую, не проще, чем сконструировать и возвести современное многофункциональное здание. Приведем несколько определений, ориентированных на использование в области информационных систем, с разных сторон и с различной степенью детальности поясняющих рассматриваемые понятия. Архитектура – это организационная структура системы. Архитектура – это концептуальное описание структуры системы, включающее описание элементов системы, их взаимодействия и внешних свойств. Информационная (ИТ) архитектура - это интегрированная структура для развертывания или поддержки существующих ИТ-средств и для приобретения новых, служащая для реализации стратегии предприятия и достижению целей бизнеса. ИТ-архитектура – это набор организационных методов, технических средств, программных продуктов, структуры их размещения и способов взаимодействия, предназначенных для реализации функций информационных технологий. Бизнес—архитектура достаточно самостоятельна и чаще всего первична по отношению к ИТ-архитектуре. В жизни она может существовать и быть реализована и без ИТ-архитектуры (правда сейчас очень редко), она является самостоятельным предметом для анализа и разработки, именно она определяет требования к ИТ-архитектуре, является побудительной причиной для планирования последней и основой для оценки ее эффективности. С другой стороны, новые возможности информационных технологий могут стимулировать развитие бизнес-архитектуры, предоставляя бизнесу новые возможности. Поэтому во многих моделях и нормативных документах бизнес-и ИТ-архитектура определяются как отдельные «слои» целостной архитектуры современного предприятия. Бизнес-стратегия предприятия определяет направление развития бизнеса и причины движения в данном направлении. Архитектура ИТ должна идентифицировать те информационные системы, которые требуются для поддержки бизнес-стратегии. ИТ-стратегия должна показывать, как эти системы могут быть реализованы в организации и какие технологии нужны для этого. Архитектура предприятия является одним из инструментов организационных изменений. Существуют два основных подхода к организационным изменениям. Первый связан с реорганизацией, реинжинирингом процессов, а второй. — с управлением знаниями. Архитектура предприятия — это прежде всего управление знаниями, т. е. процесс сбора и распространения информации о том, как организация использует и должна использовать ИТ в‘ своей деятельности. Архитектура информационных технологий является основным механизмом реализации целей предприятия через адекватные ИТ-инфраструктуру и системы. Это достигается через создание определенного количества взаимосвязанных архитектурных представлений, которые делят архитектуру компании на различное количество моделей и определений, относящихся к таким областям, как бизнес, информация, прикладные системы, технологическая инфраструктура. Бизнес-модели описывают стратегию предприятия, структуры управления, требования, ограничения и правила, а также основные бизнес-процессы, включая взаимосвязи и зависимости между ними. То есть бизнес-архитектура описывает на уровне предприятия в целом то, как реализуются его основные функции, включая организационные и функциональные структуры, роли и ответственности. Архитектура информации определяет ключевые активы, связанные со структурированной и неструктурированной информацией, требующейся для бизнеса, включая расположение, время, типы файлов и баз данных и других информационных хранилищ. Архитектура прикладных систем описывает те системы, которые и обеспечивают необходимый функционал для реализации логики бизнес-процессов организации. С точки зрения технологической архитектуры, важные модели включают описание ИТ-сервисов, которые требуются для реализации перечисленных выше трех других областей архитектуры. Но в конце концов архитектура предприятия завершается физическими моделями, которые определяются технологиями, аппаратными и программными платформами, выбранными для реализации ИТ-сервисов. Существуют различные уровни архитектуры, поэтому требуется детализация высокоуровневых определений и классификация архитектуры бизнеса и информационных технологий на различных уровнях. Архитектура предприятия определяет общую структуру и функции систем (бизнеса и ИТ) в целом и обеспечивает общую модель, стандарты и руководство для архитектуры уровня отдельных проектов. Архитектура уровня отдельных проектов определяет структуру и функции систем (бизнеса и ИТ) на уровне проектов и программ, но в контексте всей организации в целом, т. е. не в золированном рассмотрении индивидуальных систем. Архитектура прикладных систем определяет структуру и функции приложений, которые разрабатываются с целью обеспечения требуемой функциональности. Подмножеством архитектуры прикладных систем является программная архитектура, которая предполагает следующие уровни описания: — Концептуальная архитектура определяет компоненты системы и их назначения, обычно в неформальном виде. Это представление часто используется для обсуждения с нетехническими специалистами, такими как руководство, бизнес-менеджеры и конечные пользователи функциональных характеристик системы (что система должна уметь делать, в основном с точки зрения конечного пользователя); — логическая архитектура выделяет прежде всего вопросы взаимодействия компонент системы, интерфейсы и используемые протоколы. Это представление позволяет эффективно организовать параллельную разработку; - физическая реализация, которая описывает привязку к конкретным узлам размещения, типам оборудования, характеристикам окружения (операционные системы и т.п.). Корпоративная архитектура информации включает в себя следующие компоненты: архитектура информации, архитектура приложений, технологическая архитектура (архитектура инфраструктуры) Современным предприятиям необходимо искать эффективные способы работы с информацией, которая поступает из самых разнообразных источников и должна быть доступна там, где это нужно, и тогда, когда это необходимо. Ситуация осложняется тем, что различные формы информации зачастую требуют специфических технологий и методов работы с ней: — структурированная информация — (реляционные и объектные модели); — развивающиеся, основанные на XML стандарты для полуструктурированной информации; —неструктурированная информация в форме текстов, графиков, образов, сопровождаемая определенными описательными данными (метаданными и каталогами). Архитектура информации включает в себя видение, принципы, модели и стандарты, которые обеспечивают процессы создания, использования и поддержания информации, относящиеся к деятельности предприятия. Она описывает, как информационные технологии обеспечивают на предприятии возможности для быстрого принятия решений, распространения информации внутри пред- приятия, а также за ее пределы, например, партнерам по бизнесу. Архитектура информации является как бы «зеркальным отражением» бизнес архитектуры. Последняя отвечает на вопрос: «С учетом нашего общего видения, целей и стратегий кто и что будет делать?» Архитектура информации отвечает на вопрос: «Какая информация должна быть предоставлена для того, чтобы эти процессы могли выполняться теми, кто их должен выполнять?» Архитектура информации включает в себя модели, которые описывают процессы обработки информации (Information value chain), основные информационные объекты, связанные с бизнес-событиями, информационные потоки, принципы управления информацией. Архитектура должна описывать как те данные, которые требуются для выполнения процессов (операционные), так и аналитические данные и «контент», публикуемый на веб. Модели архитектуры информации являются более абстрактными, они используют язык бизнеса и обеспечивают контекст, который требуется для моделирования данных. Модели данных уже предполагают четкие описания структуры объектов, атрибутов, отношений между сущностями. Поэтому понятие «архитектура информации» является расширением понятия «архитектура данных». В общем, под архитектурой информации понимается процесс организации и представления значимой информации для пользователей в интуитивно-понятной форме с использованием соответствующих средств каталогизации, навигации, пользовательского интерфейса. В ходе разработки архитектуры информации решаются следующие задачи: — идентификация и инвентаризация существующих данных, включая определение их источников, процедур изменения и использования, ответственность, оценка качества; — сокращение избыточности и фрагментарности данных с целью уменьшения затрат на устройства хранения, стоимость их обслуживания, а также повышение качества данных за счет исключения неоднозначности и противоречивости различных экземпляров; — исключение ненужных перемещений или копирования данных, особенно связанных с наличием большого количества унаследованных или устаревших приложений; — формирование интегрированных представлений данных, таких как витрины и хранилища; обеспечение доступности данных в режиме, приближением к режиму реального времени, за счет использования средств обмена сообщениями, интеграционных брокеров и шлюзов; — интеграция метаданных, что позволит обеспечить целостное представление данных из различных источников; — сокращение числа используемых технологий и продуктов, что позволяет снизить расходы на обслуживание, а также получить дополнительные, объемные скидки от поставщиков применяемых продуктов; - улучшение качества данных прежде всего за счет привлечения бизнес—пользователей к управлению и определению данных; — улучшение защиты данных на основе использования последовательных и согласованных мер, обеспечивающих, с одной стороны, защиту от несанкционированного доступа, а с другой - доступность данных для их использования на практике. На концептуальном уровне архитектура информации должна описывать аспекты, связанные с получением, хранением, трансформацией, презентацией, анализом и обработкой информации. Это включает в себя следующие процессы управления информацией: — получение данных из внутренних и внешних источников; — классификация данных по типам; - хранение и извлечение данных; — редактирование (или обновление) данных; — контроль качества (удаление или исправление некорректных данных); — презентация (трансформирование данных для определенной аудитории потребителей); — распространение информации для различных групп потребителей; — оценка (полезности, а также соотношения цены/качества данных); — обеспечение безопасности информации (например, аутентификация данных от различных источников, назначение адекватного уровня доступа; определение требований по аудиту; обеспечение механизмов резервного хранения и восстановления). |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
БИЛЕТ 4 |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Искусственный интеллект (ИИ) – это некая система программных средств, имитирующая на компьютере процесс мышления человека. Термин искусственный интеллект был предложен в 1956 г. в Станфордском университете (США). Интеллект представляет собой совокупность фактов и способов их применения для достижения определенной цели. А достижение цели – это применение необходимых правил использования соответствующих фактов. Алгоритм – это формальная процедура, которая гарантирует получение оптимального решения База знаний – это часть ЭС, содержащая предметные знания. Диспетчер – это часть механизма вывода, которая решает когда и в каком порядке применить правила из предметных знаний. Знание – это интеллектуальная информация, используемая в программе. Интерпретатор – это часть механизма вывода, которая решает каким образом применять предметные знания. Механизм вывода – это часть ЭС, содержащая в себе общие сведения о схеме управления процессом решения задачи. Коэффициент уверенности – это число, означающее вероятность или степень уверенности, с которой можно считать данные факты и правила достоверными. Правила – это формальный способ задания знаний в виде:ЕСЛИ <условие>, ТО <действие> Экспертная система – это программа, основанная на знаниях, в которых предметные знания предусмотрены в явном виде и отделены от прочих знаний. Эвристики – это правила, упрощают или ограничивают поиск решения в предметной области. Семантическая сеть – это метод представления знаний в виде графа, где вершинами являются объекты, а дугами – их свойства. Пример.Факт1. Зажженная плита – горячая. Правило1. ЕСЛИ положить руку на зажженную плиту, ТО можно обжечься. Рассмотрим этапы развития систем искусственного интеллект а:
В начале 90-х годов 20 века была принята совершенно новая концепция. Суть ее заключается в том, чтобы сделать программу интеллектуальной, ее нужно снабдить множеством высококачественных специальных знаний некоторой предметной области. Т.о., разрабатываемые системы ИИ должны иметь хорошо развитую базу знаний. В настоящее время наиболее полное развитие этой концепции получило проектирование экспертных систем (ЭС). Система искусственного интеллекта, созданная для решения задач в конкретной предметной области, называется экспертной. ЭС – это сложные программные комплексы, аккумулирующие знания специалистов в конкретных предметных областях и тиражирующие этот эмпирический опыт для консультации менее квалифицированных пользователей. Источником знаний для ЭС служат эксперты в соответствующей предметной области. Основные их свойства:
В процессе проектирования и функционирования ЭС можно выделить следующих участников: 1. Разработчик инструментальных средств проектирования ЭС; 2. Инструментальные средства (ИС) построения ЭС; 3. Сама ЭС; 4. Эксперт; 5. Инженер знаний или администратор БЗ; 6. Пользователь. Инженер знаний – это человек, имеющий навыки в разработке систем ИИ и знающий как надо строить ЭС. Он опрашивает эксперта и организует знания в БЗ. К инструментальным средствам (ИС) проектирования относят язык программирования ЭС и поддерживающие средства, через которые пользователь взаимодействует с ЭС. Взаимодействие участников ЭС. Р
Анализируя преимущества и недостатки этих систем, можно сделать основной вывод о необходимости человека-эксперта, т.к. во многих областях он превосходит ИИ, например, по творчеству, изобретательности, способности передавать информацию и вообще по здравому смыслу. Рассмотрим область применения СИИ: Доказательство теорем. Изучение приемов доказательства теорем сыграло важную роль в развитии искусственного интеллекта. Много неформальных задач, например, медицинская диагностика, применяют при решении методические подходы, которые использовались при автоматизации доказательства теорем. Поиск доказательства математической теоремы требует не только провести дедукцию, исходя из гипотез, но также создать интуитивные предположения о том, какие промежуточные утверждение следует доказать для общего доказательства основной теоремы. Распознавание изображений. Применение искусственного интеллекта для распознавании образов позволила создавать практически работающие системы идентификации графических объектов на основе аналогичных признаков. В качестве признаков могут рассматриваться любые характеристики объектов, подлежащих распознаванию. Признаки должны быть инвариантны к ориентации, размера и формы объектов. Алфавит признаков формируется разработчиком системы. Качество распознавания во многом зависит от того, насколько удачно сложившийся алфавит признаков. Распознавания состоит в априорном получении вектора признаков для выделенного на изображении отдельного объекта и, затем, в определении которой из эталонов алфавита признаков этот вектор отвечает. Машинный перевод и понимание человеческой речи. Задача анализа предложений человеческой речи с применением словаря является типичной задачей систем искусственного интеллекта. Для ее решения был создан язык-посредник, облегчающий сопоставление фраз из разных языков. В дальнейшем этот язык-посредник превратилась в семантическую модель представления значений текстов, подлежащих переводу. Эволюция семантической модели привела к созданию языка для внутреннего представления знаний. В результате, современные системы осуществляют анализ текстов и фраз в четыре основных этапа: морфологический анализ, синтаксический, семантический и прагматический анализ. Игровые программы. В основу большинства игровых программ положены несколько базовых идей искусственного интеллекта, таких как перебор вариантов и самообучения. Одна из наиболее интересных задач в сфере игровых программ, использующих методы искусственного интеллекта, заключается в обучении компьютера игры в шахматы. Она была основана еще на заре вычислительной техники, в конце 50-х годов. В шахматах существуют определенные уровни мастерства, степени качества игры, которые могут дать четкие критерии оценки интеллектуального роста системы. Поэтому компьютерными шахматами активно занимался ученые со всего мира, а результаты их достижений применяются в других интеллектуальных разработках, имеющих реальное практическое значение. В 1974 году впервые прошел чемпионат мира среди шахматных программ в рамках очередного конгресса IFIP (International Federation of Information Processing) в Стокгольме. Победителем этого соревнования стала шахматная программа «Каисса». Она была создана в Москве, в Институте проблем управления Академии наук СССР. Машинная творчество. К одной из областей применений искусственного интеллекта можно отнести программные системы, способные самостоятельно создавать музыку, стихи, рассказы, статьи, дипломы и даже диссертации. Сегодня существует целый класс музыкальных языков программирования (например, язык C-Sound). Для различных музыкальных задач было создано специальное программное обеспечение: системы обработки звука, синтеза звука, системы интерактивного композиции, программы алгоритмической композиции. Экспертные системы. Методы искусственного интеллекта нашли применение в создании автоматизированных консультирующих систем или экспертных систем. Первые экспертные системы были разработаны, как научно-исследовательские инструментальные средства в 1960-х годах прошлого столетия. Они были системами искусственного интеллекта, специально предназначенными для решения сложных задач в узкой предметной области, такой, например, как медицинская диагностика заболеваний. Классической целью этого направления изначально было создание системы искусственного интеллекта общего назначения, которая была бы способна решить любую проблему без конкретных знаний в предметной области. Ввиду ограниченности возможностей вычислительных ресурсов, эта задача оказалась слишком сложной для решения с приемлемым результатом. Коммерческое внедрение экспертных систем произошло в начале 1980-х годов, и с тех пор экспертные системы получили значительное распространение. Они используются в бизнесе, науке, технике, на производстве, а также во многих других сферах, где существует вполне определенная предметная область. Основное значение выражения «вполне определенное», заключается в том, что эксперт-человек способен определить этапы рассуждений, с помощью которых может быть решена любая задача по данной предметной области. Это означает, что аналогичные действия могут быть выполнены компьютерной программой. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Одним из наиболее важных этапов проектирования сложных изделий (в том числе и аэрокосмической продукции) является этап конструирования. В настоящее время все существующее программное обеспечение автоматизированного конструирования входит в состав САПР. Как и любая сложная система, САПР состоит из подсистем. Различают подсистемы проектирующие и обслуживающие. Проектирующие подсистемы непосредственно выполняют проектные процедуры. Примерами проектирующих подсистем могут служить подсистемы геометрического трехмерного моделирования механических объектов, изготовления конструкторской документации, схемотехнического анализа, трассировки соединений в печатных платах. Обслуживающие подсистемы обеспечивают функционирование проектирующих подсистем, их совокупность часто называют системной средой (или оболочкой) САПР. Типичными обслуживающими подсистемами являются подсистемы управления проектными данными, подсистемы разработки и сопровождения программного обеспечения CASE (Computer Aided Software Engineering), обучающие подсистемы для освоения пользователями технологий, реализованных в САПР. Структурирование САПР по различным аспектам обуславливает появление видов обеспечения САПР: техническое, математическое, программное, информационное, лингвистическое, методическое, организационное. Классификацию САПР осуществляют по ряду признаков, например по приложению, целевому назначению, масштабокомплектности решаемых задач), характеру базовой подсистемы – ядра САПР. По приложениям наиболее представительными и широко используемыми являются следующие группы САПР: 1 САПР для применения в отраслях машиностроения. Их часто называют машиностроительными САПР или системами MCAD (Machanical CAD); 2 САПР для радиоэлектроники: системы ECAD (Electronic CAD) или EDA (Electronic Design Automation); 3 САПР в области архитектуры и строительства Кроме того, известно большое число специализированных САПР, или выделяемых в указанных группах, или представляющих самостоятельную САПР электрических машин и т.п. По целевому назначению различают САПР или подсистемы САП, обеспечивающие разные аспекты (страты) проектирования. Так, в составе MCAD появляются рассмотренные выше CAE/CAD/CAM-системы. По масштабам различают отдельные программно-методические комплексы (ПМК) САПР, например комплекс анализа прочности механических изделий в соответствии с методом конечных элементов (МКЭ) или комплекс анализа электронных схем; систем ПМК; системы с уникальными архитектурами не только программного (software), но и технического (hardware) обеспечения. По характеру базовой подсистемы различают следующие разновидности САПР: 1 САПР на базе подсистемы машинной графики и геометрического моделирования. Эти САПР ориентированы на приложения, где основной процедурой проектирования является конструирование, то есть определение пространственных форм и взаимного расположения объектов. К этой группе систем относится большинство САПР в области машиностроения, построенных на базе графических ядер. В настоящее время широко используют унифицированные графические ядра, применяемые более чем в одной САПР; 2 САПР на базе СУБД. Они ориентированы на приложения, в которых при сравнительно несложных математических расчетах перерабатывается большой объем данных. Такие САПР преимущественно встречаются в технико-экономических приложениях, например при проектировании бизнес-планов, но они имеются так же при проектировании объектов, подобных щитам управления в системах автоматики; 3 САПР на базе конкретного прикладного пакета. Фактически это автономно используемые ПМК, например, имитационного моделирования производственных процессов, расчета прочности по МКЭ, синтеза и анализа систем автоматического управления и т.п. Часто такие САПР относят к системам САЕ. Примерами могут служить программы логического проектирования на базе языка VHDL, математические пакеты типа MathCAD 4 комплексные (интегрированные) САПР, состоящие из совокупности подсистем предыдущих видов. Характерными примерами комплексных САПР являются CAE/CAD/CAM-системы в машиностроении или САПР СБИС. Так, САПР СБИС включает в себя СУБД и подсистемы проектирования компонентов, принципиальных, логических и функциональных схем, топология кристаллов, тестов для проверки годности изделий. Для управления столь сложными системами применяют специализированные системные среды. Приведенных перечень информационных структур современного предприятия показывает, что используется очень широкий спектр, решающий различные задачи. Необходимо их объединить для решения общей задачи и дальнейшего развития. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
Таким образом распределенные вычисления не могут производится на одной вычислительной машине, а параллельные вычисления могут производиться как на одной (многопоточность), так и на нескольких машинах.
Открытые (добровольные) вычислительные системы (англ. volunteer computing) - вычислительные системы (сети) чаще всего строятся на базе, так называемых GRID систем (сетей), в русском языке иногда называются как системы метакомпьютинга (матавычисления). Вследствие повсеместного использования вычислительной техники бурно развивается направление численного моделирования (англ. numerical simulation). Численное моделирование, является промежуточным элементом между аналитическими методами изучения и физическими экспериментами. Рост количества задач, для решения которых необходимо использовать параллельные вычисления, обусловлен:
При этом, использование численных моделей и кластерных систем, позволяет значительно уменьшить стоимость процесса научного и технологического поиска. Кластерные системы в последние годы широко используются во всем мире как дешевая альтернатива суперкомпьютерам. Система требуемой производительности собирается из готовых, серийно выпускаемых компьютеров, объединенных, опять же, с помощью серийно выпускаемого коммуникационного оборудования. Это, с одной стороны, увеличивает доступность суперкомпьютерных технологий, а с другой, повышает актуальность их освоения, поскольку для всех типов многопроцессорных систем требуется использование специальных технологий программирования для того, чтобы программы могли в полной мере использовать ресурсы высокопроизводительной вычислительной системы. Создать программу для выполнения которой будут задействованы все ресурсы суперкомпьютера не всегда возможно. В самом деле, при разработке параллельной программы для распределенной системы мало разбить программу на параллельные потоки. Для эффективного использования ресурсов необходимо обеспечить равномерную загрузку каждого из узлов кластера, что в свою очередь означает, что все потоки программы должны выполнить примерно одинаковый объем вычислений. Рассмотрим частный случай, когда при решении некоторой параметрической задачи для разных значений параметров время поиска решения может значительно различаться. Тогда мы получим значительный перекос загрузки узлов кластера. В действительности практически любая вычислительная задача выполняется в кластере не равномерно. Несмотря на это, использование кластерных систем всегда более эффективно для обслуживания вычислительных потребностей большого количества пользователей, чем использование эквивалентного количества однопроцессорных рабочих станций, так как в этом случае с помощью системы управления заданиями легче обеспечить равномерную и более эффективную загрузку вычислительных ресурсов. Получение высокой эффективности выполнения программ усложняет использование параллельных систем. Доминирующее положение при разработке параллельных программ для параллельных систем занимает стандарт MPI (англ. Message Passing Interface). Программа, разработанная в модели передачи сообщений, может быть представлена информационным графом, вершинам которого соответствуют параллельные ветви программы, а ребрам коммуникационные связи между ними. Это можно использовать для диспетчеризации заданий и их вычислительных потоков. Учитывая гетерогенность вычислительных ресурсов и сред передачи данных в кластере, можно осуществить распределение вычислительных потоков (ветвей) по вычислительным узлам так, чтобы минимизировать накладные расходы на обмен данными между потоками и выровнять вычислительную нагрузку между узлами. Для этого необходимо обладать информацией о мощности и загруженности узлов и структуре параллельных программ, которые ожидают выполнения. “Параллельное и распределенное программирование — это два базовых подхода к достижению параллельного выполнения составляющих программного обеспечения (ПО). Они представляют собой две различные парадигмы программирования, которые иногда пересекаются. Методы параллельного программирования позволяют распределить работу программы между двумя (или больше) процессорами в рамках одного физического или одного виртуального компьютера. Методы распределенного программирования позволяют распределить работу программы между двумя (или больше) процессами, причем процессы могут существовать на одном и том же компьютере или на разных. Другими словами, части распределенной программы зачастую выполняются на разных компьютерах, связываемых по сети, или по крайней мере в различных процессах. Программа, содержащая параллелизм, выполняется на одном и том же физическом или виртуальном компьютере. Такую программу можно разбить на процессы (process) или потоки (thread). Многопоточность ограничивается параллелизмом. Формально параллельные программы иногда бывают распределенными, например, при PVM-программировании (Parallel Virtual Machine - параллельная виртуальная машина). Распределенное программирование иногда используется для реализации параллелизма, как в случае с MPI-программированием (Message Passing Interface- интерфейс для передачи сообщений). Однако не все распределенные программы включают параллелизм. Части распределенной программы могут выполняться по различным запросам и в различные периоды времени. Например, программу календаря можно разделить на две составляющие. Одна часть должна обеспечивать пользователя информацией, присущей календарю, и способом записи данных о важных для него встречах, а другая часть должна предоставлять пользователю набор сигналов для разных типов встреч. Пользователь составляет расписание встреч, используя одну часть ПО, в то время как другая его часть выполняется независимо от первой. Набор сигналов и компонентов расписания вместе образуют единое приложение, которое разделено на две части, выполняемые по отдельности. При чистом параллелизме одновременно выполняемые части являются компонентами одной и той же программы. Части распределенных приложений обычно реализуются как отдельные программы. Типичная архитектура построения параллельной и распределенной программ показана на рис. 1.1 и 1.2. Параллельное приложение, показанное на рис. 1.1, состоит из одной программы, разделенной на четыре задачи. Каждая задача выполняется на отдельном процессоре, следовательно, все они могут выполняться одновременно. Эти задачи можно реализовать в виде распределенной программы (см. рис. 1.2). Она состоит из трех отдельных программ, каждая из которых выполняется на отдельном компьютере. При этом программа 3 состоит из двух отдельных частей (задачи А и задачи D), выполняющихся на одном компьютере. Несмотря на это, задачи А и D являются распределенными, поскольку они реализованы как два отдельных процесса. Задачи параллельной программы более тесно связаны, чем задачи распределенного приложения. В общем случае процессоры, связанные с распределенными программами, находятся на различных компьютерах, в то время как процессоры, связанные с программами, реализующими параллелизм, находятся на одном и том же компьютере. Конечно же, существуют гибридные приложения, которые являются и параллельными, и распределенными одновременно. Именно такие гибридные объединения становятся нормой.”[15] С таким объединенным типом приложений и работают вычислительные системы кластерного типа.
Рис. 1.1. Архитектура построения параллельной программы
Рис. 1.2. Архитектура построения распределенной программы
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
При разработке ИТ-стратегии необходимо ответить на два главных вопроса: Каковы главные компоненты, составляющие основу стратегии ИТ? На какие аспекты явно или неявно сформулированных бизнес-стратегий необходимо обратить внимание, поскольку они важны для стратегии ИТ? На самом деле, в соответствии с Gartner Group, количество элементов, определяющих ИТ-стратегию, может быть уменьшено до пяти областей: ИТ-инфраструктура. Какие компоненты ИТ (аппаратное и программное обеспечение и комплектующие, сети) необходимы для обеспечения среды выполнения бизнес-процессов предприятия? ИТ-сервисы. Как департамент ИТ обеспечит доступность ИТ-среды, какие услуги бизнес-подразделения получают от департамента ИТ на ежедневной основе? Наиболее общим определением ИТ-услуг для бизнес-подразделений является Соглашение об уровне обслуживания (SLA – Service-Level Agreement). Портфель приложений. Как будет меняться имеющийся набор прикладных систем? Интеграции бизнес-процессов. Как будут обеспечены интеграция и взаимодействие различных систем между собой? Это особенно важно в связи с ростом объемов электронного взаимодействия с поставщиками, партнерами и клиентами и распространением практики использования внешних ресурсов. Сорсинг. Как обеспечивается выполнение стратегии внутренними и внешними для департамента ИТ-ресурсами? Независимо от того, насколько явно и полно сформулирована бизнес-стратегия, есть несколько моментов, знание которых обеспечивает ИТ-службу информацией, необходимой для формулировки ИТ-стратегии: География бизнеса. Распределение производственных объектов, клиентов и партнеров. Это имеет непосредственное влияние на развертывание инфраструктуры и предоставление ИТ-сервисов. Вопросы, связанные с изменением портфеля приложений и их интеграцией, приобретают иной уровень сложности в географически распределенной среде. Организация принятия решений в компании. Важно знать, каков механизм принятия решений – исключительно централизованный, или, наоборот, бизнес-подразделения самостоятельны в принятии решений, либо в компании существует какая-то промежуточная модель. При планировании стратегии ИТ необходимо адаптироваться к распределению центров власти и принятию решений. Горизонт планирования. Временная шкала, которую охватывает бизнес-стратегия и которую должна будет охватить ИТ-стратегия. Чем более широким является временной горизонт, тем в большей степени стратегические аспекты должны найти отражение в архитектуре ИТ. Если горизонт очень узок, то трудно вырабатывать долгосрочную стратегию ИТ. Существующие (унаследованные) бизнес-процессы и системы. Здесь определяется, насколько организация планирует жестко придерживаться принятых методов работы или, наоборот, насколько она готова изменять модели ведения бизнеса, а значит, соответствующие бизнес-процессы и те приложения, которые исторически их поддерживают. Виртуализация бизнеса. Интеграция с системами клиентов, партнеров, поставщиков и т.п. Этот аспект определяет, мыслит ли предприятие исключительно в терминах внутренних процессов организации бизнеса или существует тенденция в существенной степени интегрироваться с клиентами и поставщиками. Желание рассматривать внешние организации как активных участников своих бизнес-процессов обычно значительно повышает требования в области интеграции. Это также влияет на принятие решений о том, какие прикладные системы останутся внутренними для организации, а какие будут переданы на аутсорсинг. Клиенты и заказчики (здесь рассматриваются потребности, как внешних клиентов, так и внутренних пользователей информационных систем). Обслуживание клиентов может принимать различные формы, но степень взаимодействия с заказчиками во время процесса предоставления им услуг и соответствующие формы бизнес-процессов накладывают соответствующие требования на необходимую инфраструктуру ИТ. Финансирование ИТ. Это та область, которая явно показывает, насколько предприятие готово идти по пути изменений. Другим необходимым элементом является наличие достоверного и актуального описания ИТ-систем. Это позволит провести анализ соответствия текущего состояния информационных технологий на предприятии и предъявляемых требований. После этого формируется матрица корреляции между приведенными семью бизнес-категориями и выделенными пятью областями ИТ-стратегии. Эта матрица служит рабочим инструментом для анализа степени определенности и взаимосвязей между компонентами ИТ-стратегии Матрица соответствия потребности бизнеса и ИТ-стратегии
Независимо от того, есть ли в организации явно сформулированная бизнес-стратегия или нет, для понимания сути влияния бизнес-стратегии на стратегию ИТ важно дать ответ на два вопроса:
На самом деле, количество элементов, определяющих ИТ-стратегию, может быть уменьшено до пяти областей:
Эти выделенные пять областей могут быть "спроектированы" в две компоненты ИТ-стратегии: Прикладные системы и Сервисные операции. Первая из этих компонент, связанная с разработкой и функционированием приложений, включает такие области, как портфель приложений, интеграцию бизнес-процессов и сорсинг. Вторая компонента связана с выполнением операций и включает такие области, как инфраструктура, сервис (эксплуатация) и опять-таки сорсинг. При этом область сорсинга является, вполне естественно, общей для обеих компонент, так как она определяет доступность внутреннего и внешнего персонала, участвующего в выполнении обеих компонент. Главный вывод заключается в том, что IT-стратегия является частью бизнес-стратегии компании, хотя и более инерционной. Степень детализации IT-стратегии зависит от сроков, на которые она составляется, и от рисков, которые при этом несет компания: чем меньше срок и чем выше риск, тем более подробно должны быть описаны действия компании, направленные на поддержку бизнеса с помощью информационных технологий. Если же речь идет о создании нового бизнес-направления или предприятия, то IT-стратегия должна быть максимально подробной и предусматривать несколько вариантов развития событий, как и сам бизнес-план. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Логический вывод на основе субъективной вероятности. Простейший логический вывод. Рассмотрим случай, когда все правила в ЭС отражаются в форме: Если < Н является истинной > То < Е будет наблюдаться с вероятностью р >. Очевидно, если Н произошло, то это правило говорит о том, что событие Е происходит с вероятностью р. Но что будет, если состояние Н неизвестно, а Е произошло? Использование теоремы Байеса позволяет вычислить вероятность того, что Н истинно. Замена «А» и «В» на «Н» и «Е» не существенна для формулы Байеса, но с её помощью мы можем покинуть общую теорию вероятности и перейти к анализу вероятностных вычислений в ЭС. В этом контексте: Н – событие, заключающееся в том, что данная гипотеза верна; Е – событие, заключающееся в том, что наступило определённое доказательство (свидетельство), которое может подтвердить правильность указанной гипотезы. Переписывая формулу Байеса в терминах гипотез и свидетельств, получим:
Это равенство устанавливает связь гипотезы со свидетельством и, в то же время, наблюдаемого свидетельства с пока ещё не подтверждённой гипотезой. Эта интерпретация предполагает также определение априорной вероятности гипотезы р(Н), назначаемой Н до наблюдения или получения некоторого факта. В ЭС вероятности, требуемые для решения некоторой проблемы, обеспечивается экспертами и запоминается в БЗ. Эти вероятности включают: априорные вероятности всех возможных гипотез р(Н); условные вероятности возникновения свидетельств при условии существования каждой из гипотез р(Е /Н). Так, например, в медицинской диагностике эксперт должен задать априорные вероятности всех возможных болезней в некоторой медицинской области. Кроме того, должны быть определены условные вероятности проявления тех или иных симптомов при каждой из болезней. Условные вероятности должны быть получены для всех симптомов и болезней, предполагая, что все симптомы независимы в рамках одной болезни. Два события Е1 и Е2 являются условно независимыми, если их совместная вероятность при условии некоторой гипотезы Н равна произведению условных вероятностей этих событий при условии Н: р (Е1 Е2|Н) =р (Е1|Н)⋅р (Е2|Н) . Вероятность р (Нi |Еj ... Еk) является апостериорной вероятностью гипотез Нi по наблюдениям (Еj ... Еk), т.е. дает сравнительное ранжирование всех возможных гипотез. Результатом вывода ЭС является выбор гипотезы с наибольшей вероятностью. Однако, приведённая выше формула Байеса ограничена в том, что каждое свидетельство влияет только на одну гипотезу. Можно обобщить это выражение на случай множественных гипотез (Н1 ... Нm) и множественных свидетельств (Е1 ... Еn). Вероятности каждой из гипотез при условии возникновения некоторого конкретного свидетельства Е можно определить из выражения:
К сожалению данное выражение имеет ряд недостатков. Так, знаменатель требует от нас знания условных вероятностей всех возможных комбинаций свидетельств и гипотез, что делает правило Байеса малопригодным для ряда приложений. Однако в тех случаях, когда возможно предположить условную независимость свидетельств, правило Байеса можно привести к более простому виду
Вместе с тем предположения о независимости событий в ряде случаев подавляют точность суждений и свидетельств в ЭС. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
БИЛЕТ 5 |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Вычислительная машина – это комплекс технических и программных средств, предназначенных для автоматизации подготовки и решения задач пользователя. Вычислительная система – это совокупность взаимосвязанных и взаимосоединенных процессоров или вычислительных машин, периферийного оборудования и программного обеспечения для решения задач пользователя. Основной отличительной чертой вычислительных систем является наличие в них средств, реализующих параллельную обработку за счет построения параллельных ветвей вычисления, что как правило не предусматривается в вычислительных машинах. Очевидно, что различия между вычислительными машинами и вычислительными системами не могут быть точно определены (вычислительные машины даже с одним процессором обладает разными средствами распараллеливания, а вычислительные системы могут состоять из традиционных вычислительных машин или процессоров). Архитектура ВС – совокупность характеристик и параметров, определяющих функционально-логичную и структурно-организованную систему и затрагивающих в основном уровень параллельно работающих вычислителей. Понятие архитектуры охватывает общие принципы построения и функционирования, наиболее существенные для пользователя Архитектура фон Неймана - модель реализации ВС с одним устройством обработки (процессором) и одним устройством хранения (памятью)(см. рис. 2). Память используется для хранения как программ, так и данных. Архитектура предложена конструкторами ВС ENIAC Мокли и Экертом и популяризирована математиком Джоном фон Нейманом [6]. На момент появления данной архитектуры программы в ВС были либо жестко зашиты в логику работы процессора ВС, либо задавались с помощью перекоммутации связей у процессора. Вынесение программ в память сильно упростило их модификацию. Выполнение команд происходит в циклах, каждый из которых содержит следующие стадии: 1) выборка очередной команды для исполнения (по адресу регистра-указателя команд), 2) декодирование кода команды, выработка управляющих сигналов для арифметического-логического устройства (АЛУ), 3) чтение требуемых операндов из памяти и их размещение в регистрах процессора, 4) исполнение команды в АЛУ и запись результатов в память или регистры процессора.
Архитектура фон Неймана Размещение данных и программ в одной памяти позволяет строить самомодифицирующиеся программы. Это позволяет реализовывать необычайно гибкие решения. Однако, с другой стороны, ошибки в программах могут приводить к порче как данных, так и самих программ. С момента своего появления и по настоящий день архитектура фон Неймана является эталоном для последовательных ВС. Хотя в чистом виде она сейчас не применяется даже в самых простых ВС. Узкое место данной архитектуры ― пропускная способность шины между процессором и памятью. При доступе к памяти процессор простаивает. На момент появления архитектуры скорости работы процессора и памяти были приблизительно одинаковы. Сейчас скорость работы процессора существенно выше, чем у памяти. Для преодоления узкого места был предложен ряд усовершенствований этой базовой архитектуры. Два основных из них ― это использование конвейера команд (см. главу 3) и использование кэш памяти. Кэш память ― память более малого размера, чем оперативная. Но она более быстрая и расположена в процессоре. Часто используемые данные хранятся в кэш памяти, что исключает необходимость их чтения из оперативной памяти через шину. Гарвардская архитектура - архитектура последовательных ВС, в которой память физически и логически разделена на две части: память программ и память данных Впервые архитектура была реализована на машине Mark I, построенной в Гарвардском университете. Блок управления может считывать команды из памяти программ. АЛУ может считывать и записывать данные из памяти данных. Так как для доступа к памяти программ и памяти данных используются разные каналы, то возможен одновременный доступ к ним. Кроме этого, они могут иметь разные физические характеристики и логическую организацию (размер и разрядность слова) В модифицированной Гарвардской архитектуре добавлена связь между памятью программ и АЛУ, что позволяет хранить в памяти команд константы, например, строки.
В При этом разрядность памяти программ и памяти данных, а также шины доступа к ним, различны. В частности, все микроконтроллеры PIC12, PIC16 фирмы Microchip имеют 8-битную память данных, а разрядность памяти программ у них различна: PIC12 имеют 12 битную память программ, а РЮШ - 14 битную. По системе команд различаются: • CISC-архитектура (Complicated Instruction Set Computer) - архитектура с развитой системой команд. Система команд процессорного ядра имеет инструкции разного формата: однобайтовые, двухбайтовые, трехбайтовые. Различные инструкции при этом имеют и существенно разное время исполнения. • RISC-архитектура (Reduced Instruction Set Computer) - архитектура с сокращенным набором команд. Одна инструкция, как правило, занимает только одну ячейку памяти, и все инструкции имеют равное время исполнения. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Метод экспертных оценок — метод анализа и обобщения суждений и предположений с помощьюэкспертов. Данный метод используют, когда рациональные математические методы малоэффективны при решении проблем. Производится интуитивно-логический анализ проблемы с последующей количественной оценкой суждений и формальной обработкой результатов. Процесс организации экспертизы может быть разделен на следующие этапы: • составление руководящего документа. В нем указываются основные положения проведения экспертизы: • цели; • задачи по ее выполнению; . состав и обязанности рабочей группы и группы экспертов; • ресурсы, необходимые для обеспечения работ, и сроки выполнения работ; • подбор рабочей и экспертной групп. Две группы принимают участие в проведении экспертизы: • рабочая группа, которая состоит из организатора, специалиста -системотехника и технического работника; . экспертная группа, т. е. группа, мнения экспертов которой станут основой принятия будущих решений; • разработка методики проведения опроса (при необходимости). На данном этапе определяются: место и время проведения опроса; задачи; форма проведения; порядок фиксации и сбора результатов; состав необходимых документов. В зависимости от имеющегося времени на проведение экспертизы, сложности рассматриваемой проблемы, участвующих специалистов можно выделить следующие формы проведения опроса: индивидуальный — максимально используются способности и знания каждого специалиста; . групповой (коллективный)— позволяет экспертам обмениваться мнениями и на их основе скорректировать свою оценку. Но при данном методе опроса может проявиться сильное влияние авторитетов на специалистов; . личный (очный) — опрос осуществляется при непосредственном контакте, например интервьюера и эксперта; . заочный — одним из распространенных примеров данного метода опроса является пересылка анкет. Здесь нет прямого взаимодействия между интервьюером и экспертом; . устный — например, интервью; • письменный — например, заполнение анкеты; • открытый — процесс опроса и его результаты могут быть изучены другими экспертами; • скрытый — высказанные идеи и решения экспертов являются тайными; • разработка методики обработки данных опроса. Обработка данных опроса экспертов может быть осуществлена 2 способами: • проверкой согласованности мнений экспертов (или классификацией экспертов, если нет согласованности); .усреднением мнений экспертов внутри согласованной группы; • оформление результатов работы. Осуществляется анализ результатов, полученных в результате проведения экспертизы, на основе которого составляется отчет. После обсуждения и утверждения полученных результатов итоги проделанной работы предоставляются заказчикам экспертизы. При формировании экспертной и рабочих групп необходимо предъявлять следующие требования к экспертам: • выдвигаемые экспертами оценки должны быть стабильными во времени; • при введении дополнительной информации экспертная оценка должна улучшаться, но она не должна принципиально изменяться от первоначально сформулированной оценки; • эксперт должен быть признанным специалистом в изучаемой области знания; • у эксперта должен быть опыт участия в подобных экспертизах; • мнения экспертов должны быть устойчивыми. Устойчивость определяется характером ошибок, которые могут допустить эксперты во время проведения экспертизы. В связи с этим выделяют 2 вида ошибок: • систематические, которые характеризуются устойчивым положительным или отрицательным отклонением от истинного значения; . случайные, когда выдаваемые значения экспертов характеризуются большой дисперсией. Экспертное оценивание — процедура получения оценки проблемы на основе мнения специалистов (экспертов) с целью последующего принятия решения (выбора). Экспе́рт (от лат. expertus — опытный) — специалист, приглашаемый или нанимаемый за вознаграждение для выдачи квалифицированного заключения или суждения по вопросу, рассматриваемому или решаемому другими людьми, менее компетентными в этой области. Эксперты привлекаются для оценок, установления состояния объектов в целях определения их состояния для принятия ответственных решений (суды, управление предприятиями и проектами, оценка исторических объектов и артефактов, перепроверка заявляемых открытий и изобретений, и др.) Существует две группы экспертных оценок:
Совместное мнение обладает большей точностью, чем индивидуальное мнение каждого из специалистов. Данный метод применяют для получения количественных оценок качественных характеристик и свойств. Например, оценка нескольких технических проектов по их степени соответствия заданному критерию, во время соревнования оценка судьями выступления фигуриста. Известны следующие методы экспертных оценок:
Этапы экспертного оценивания
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Параллельные вычислительные системы— это физические компьютерные, а также программные системы, реализующие тем или иным способом параллельную обработку данных на многих вычислительных узлах. Идея распараллеливания вычислений основана на том, что большинство задач может быть разделено на набор меньших задач, которые могут быть решены одновременно. Обычно параллельные вычисления требуют координации действий. Параллельные вычисления существуют в нескольких формах: параллелизм на уровне битов, параллелизм на уровне инструкций, параллелизм данных, параллелизм задач. Параллельные вычисления использовались много лет в основном в высокопроизводительных вычислениях, но в последнее время к ним возрос интерес вследствие существования физических ограничений на рост тактовой частоты процессоров. Параллельные вычисления стали доминирующей парадигмой в архитектуре компьютеров, в основном в форме многоядерных процессоров. Параллелизм на уровне битов: Эта форма параллелизма основана на увеличении размера машинного слова. Увеличение размера машинного слова уменьшает количество операций, необходимых процессору для выполнения действий над переменными, чей размер превышает размер машинного слова. Параллелизм на уровне инструкций: Компьютерная программа — это, по существу, поток инструкций, выполняемых процессором. Но можно изменить порядок этих инструкций, распределить их по группам, которые будут выполняться параллельно, без изменения результата работы всей программы. Параллелизм данных: Основная идея подхода, основанного на параллелизме данных, заключается в том, что одна операция выполняется сразу над всеми элементами массива данных. Различные фрагменты такого массива обрабатываются на векторном процессоре или на разных процессорах параллельной машины. Распределением данных между процессорами занимается программа. Векторизация или распараллеливание в этом случае чаще всего выполняется уже на этапе компиляции — перевода исходного текста программы в машинные команды. Роль программиста в этом случае обычно сводится к заданию настроек векторной или параллельной оптимизации компилятору, директив параллельной компиляции, использованию специализированных языков для параллельных вычислений. Параллелизм задач (многопоточность): Стиль программирования, основанный на параллелизме задач, подразумевает, что вычислительная задача разбивается на несколько относительно самостоятельных подзадач и каждый процессор загружается своей собственной подзадачей. Если считать, что тактовая частота работы процессоров приблизительно соответствует их производительности, то в настоящее время около 103 млн. операций в секунду (МОПС) - это максимально возможная производительность, которая достижима на одном процессоре. Поскольку ежегодно тактовая частота выпускаемых процессоров возрастает, можно надеяться на увеличение максимальной производительности примерно до 106-108 МОПС. Однако эти процессы не имеют линейной экстраполяции во времени в силу молекулярных ограничений. Процессоры с производительностью более 108 МОПС либо будут иметь принципиально иную архитектуру по сравнению с современными процессорами, либо вообще невозможны. Из этого следует, что единственной стратегией развития вычислительной техники является создание многопроцессорных вычислителей. Получается, что параллельные алгоритмы - единственный перспективный способ повышения производительности при решении будущих задач. Применение параллельных вычислительных систем (ПВС) является стратегическим направлением развития вычислительной техники. Это обстоятельство вызвано не только принципиальным ограничением максимально возможного быстродействия обычных последовательных ЭВМ, но и практически постоянным наличием вычислительных задач, для решения которых возможностей существующих средств вычислительной техники всегда оказывается недостаточно. Так, проблемы "большого вызова" возможностям современной науки и техники - моделирование климата, генная инженерия, проектирование интегральных схем, анализ загрязнения окружающей среды, создание лекарственных препаратов и др. - требуют для своего анализа ЭВМ с производительностью более 1000 миллиардов операций с плавающей запятой в секунду (1 TFlops). Параллельные вычислительные системы применяются при решении следующих классов задач:
Проблема создания высокопроизводительных вычислительных систем относится к числу наиболее сложных научно-технических задач современности. Ее разрешение возможно только при всемерной концентрации усилий многих талантливых ученых и конструкторов, предполагает использование всех последних достижений науки и техники и требует значительных финансовых инвестиций. Тем не менее, достигнутые в последнее время успехи в этой области впечатляют. Список наиболее быстродействующих вычислительных систем Top 500 в данный момент возглавляет вычислительный комплекс Jaguar (США), содержащий 224162 процессора с общей суммарной пиковой производительностью 1759 TFlops. Россия в этом списке занимает 13 место с ее вычислительной системой Lomonosov на базе 35360 процессоров и максимальной производительностью 350 TFlops. Организация параллельности вычислений, когда в один и тот же момент выполняется одновременно несколько операций обработки данных, осуществляется в основном за счет введения избыточности функциональных устройств (многопроцессорности). В этом случае можно достичь ускорения процесса решения вычислительной задачи, если осуществить разделение применяемого алгоритма на информационно независимые части и организовать выполнение каждой части вычислений на разных процессорах. Подобный подход позволяет выполнять необходимые вычисления с меньшими затратами времени, и возможность получения максимально возможного ускорения ограничивается только числом имеющихся процессоров и количеством "независимых" частей в выполняемых вычислениях. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Прототипная система является усеченной версией экспертной системы, спроектированной для проверки правильности кодирования фактов, связей и стратегий рассуждения эксперта. Она также дает возможность инженеру по знаниям привлечь эксперта к активному участию в разработке экспертной системы и, следовательно, к принятию им обязательства приложить все усилия для создания системы в полном объеме. Объем прототипа - несколько десятков правил, фреймов или примеров. На рисизображены шесть стадий разработки прототипа и минимальный коллектив разработчиков, занятых на каждой из стадий. Приведем краткую характеристику каждой из стадий, хотя эта схема представляет грубое приближение к сложному итеративному процессу.
Хотя любое теоретическое разделение бывает часто условным, осознание коллективом разработчиков четких задач каждой стадии представляется целесообразным. Роли разработчиков (эксперт, программист, пользователь и аналитик) являются постоянными на протяжении всей разработки. Совмещение ролей нежелательно. Сроки приведены условно, так как зависят от квалификации специалистов и особенностей задачи. Идентификация проблемы Уточняется задача, планируется ход разработки прототипа экспертной системы, определяются: необходимые ресурсы (время, люди, ЭВМ и т.д.); источники знаний (книги, дополнительные эксперты, методики); имеющиеся аналогичные экспертные системы; цели (распространение опыта, автоматизация рутинных действий и др.); классы решаемых задач и т.д. Идентификация проблемы - знакомство и обучение коллектива разработчиков, а также создание неформальной формулировки проблемы. Средняя продолжительность 1 - 2 недели. Извлечение знаний Происходит перенос компетентности экспертов на инженеров по знаниям с использованием различных методов: анализ текстов; диалоги; экспертные игры; лекции; дискуссии; интервью; наблюдение и другие. Извлечение знаний - получение инженером по знаниям наиболее полного представления о предметной области и способах принятия решения в ней. Средняя продолжительность 1 -3 месяца. Структурирование или концептуализация знаний Выявляется структура полученных знаний о предметной области, т.е. определяются: терминология; список основных понятий и их атрибутов; отношения между понятиями; структура входной и выходной информации; стратегия принятия решений; ограничения стратегий и т.д. Концептуализация знаний - разработка неформального описания знаний о предметной области в виде графа, таблицы, диаграммы или текста, которое отражает основные концепции и взаимосвязи между понятиями предметной области. Такое описание называется полем знаний. Средняя продолжительность этапа 2 - 4 недели. Формализация. Строится формализованное представление концепций предметной области на основе выбранного языка представления знаний (ЯПЗ). Традиционно на этом этапе используются: логические методы (исчисления предикатов I порядка и др.); продукционные модели (с прямым и обратным выводом); семантические сети; фреймы; объектно-ориентированные языки, основанные на иерархии классов, объектов и др. Формализация знаний - разработка базы знаний на языке, который, с одной стороны, соответствует структуре поля знаний, а с другой - позволяет реализовать прототип системы на следующей стадии программной реализации. Все чаще на этой стадии используется симбиоз языков представления знаний, например, в системе ОМЕГА [7] - фреймы + семантические сети + полный набор возможностей языка исчисленияпредикатов. Средняя продолжительность 1 - 2 месяца. Реализация Создается прототип экспертной системы, включающий базу знаний и остальные блоки, при помощи одного из следующих способов: программирование на традиционных языках типа Паскаль, Си и др.; программирование на специализированных языках, применяемых в задачах искусственного интеллекта: LISP [14], FRL [I], SmallTalk [7] и др.; использование инструментальных средств разработки ЭС типа СПЭИС [З], ПИЭС [11]; использование "пустых" ЭС или "оболочек" типа ЭКСПЕРТ [2], ФИАКР [7] и др. Реализация - разработка программного комплекса, демонстрирующего жизнеспособность подхода в целом. Чаще всего первый прототип отбрасывается на этапе реализации действующей ЭС. Средняя продолжительность 1 - 2 месяца. Тестирование Оценивается и проверяется работа программ прототипа с целью приведения в соответствие с реальными запросами пользователей. Прототип проверяется на: удобство и адекватность интерфейсов ввода-вывода (характер вопросов в диалоге, связность выводимого текста результата и др.)
Тестирование - выявление ошибок в подходе и реализации прототипа и выработка рекомендаций по доводке системы до промышленного варианта. Средняя продолжительность 1 - 2 недели. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
ITSM (IT Service Management, управление ИТ-услугами) — подход к управлению и организации ИТ-услуг, направленный на удовлетворение потребностей бизнеса. Управление ИТ-услугами реализуется поставщиками ИТ-услуг путём использования оптимального сочетания людей, процессов и информационных технологий[1]. Для содействия реализации подхода к управлению ИТ-услугами используется серия документов ITIL. В отличие от более традиционного технологического подхода, ITSM рекомендует сосредоточиться на клиенте и его потребностях, на услугах, предоставляемых пользователю информационными технологиями, а не на самих технологиях. При этом процессная организация предоставления услуг и наличие заранее оговоренных в соглашениях об уровне услуг параметров эффективности (KPI) позволяет ИТ-отделам предоставлять качественные услуги, измерять и улучшать их качество. Важным моментом при изложении принципов ITSM является системность. При изложении каждого составного элемента ITSM (управление инцидентами, управление конфигурациями, управление безопасностью и т. д.) в обязательном порядке прослеживается его взаимосвязь и координация с остальными элементами (службами, процессами) и при этом даются необходимые практические рекомендации. ITIL не является конкретным алгоритмом или руководством к действию, но она описывает передовой опыт (best practices) и предлагает рекомендации по организации процессного подхода и управления качеством предоставления услуг. Это позволяет оторваться от особенностей данного конкретного предприятия в данной конкретной отрасли. Вместе с тем, несмотря на определённую абстрактность, ITIL всячески нацелено на практическое использование. В каждом разделе библиотеки приводятся ключевые факторы успеха внедрения того или иного процесса, практические рекомендации при этом превалируют над чисто теоретическими рассуждениями. Концепция управления качеством информационных услуг (Information Technology Service Management - ITSM) возникла в результате принципиального изменения сегодняшней роли ИТ-подразделений. Бизнес-процессы настолько тесно увязаны с приложениями, техническими ресурсами и деятельностью персонала отделов автоматизации, что эффективность последних оказывается одним из решающих факторов эффективности компании в целом. Сами информационные технологии, на которые опирается компания в повседневной работе, постоянно усложняются, корпоративная инфраструктура растет и требует значительных усилий для своего поддержания в работоспособном состоянии. А бизнес-подразделения хотят, чтобы ИТ-механизмы работали как часы, обслуживая их с надлежащим качеством и при оптимальных затратах. Основная идея внедрения ITSM состоит в том, чтобы ИТ-отдел перестал быть вспомогательным элементом для основного бизнеса компании, ответственным только за работу отдельных серверов, сетей и приложений, «где-то и как-то» применяющихся в компании. Отдел автоматизации становится полноправным участником бизнеса, выступая в роли поставщика определенных услуг для бизнес-подразделений, а отношения между ними формализуются как отношения «поставщик услуг - потребитель услуг«. Бизнес-подразделение формулирует свои требования к необходимому спектру услуг и их качеству, руководство компании определяет объем финансирования для выполнения этих требований, а подразделения автоматизации поддерживают и развивают информационную инфраструктуру компании таким образом, чтобы она была в состоянии обеспечить запрошенную услугу с заданным качеством. Для того чтобы сделать явью эту идеальную картинку, необходимо научить ИТ-отделы работать по-новому, перейти от управления отдельными информационными ресурсами компании к управлению услугами, которые на этих ресурсах базируются. Перестать воспринимать персонал других отделов только как своих пользователей, наладить отношениями с ними как с заказчиками. Скажем, бухгалтерия хочет иметь автоматизированный процесс выставления счетов, что, с точки зрения ИТ-отдела услуга, которая будет реализована при помощи некоторой совокупности ПК, сервера, приложений и сети, будет обладать определенными характеристиками надежности, производительности, времени отклика, а предоставление этой услуги будет контролироваться, по результатам контроля будут сформированы отчеты в понятных заказчику бухгалтерских терминах. Эта услуга будет обладать, наконец, определенной себестоимостью, зависящей от надежности, производительности и, возможно, других характеристик. Значит, заказчик будет иметь представление о том, какие расходы повлечет за собой нужное ему качество услуги, и, можно надеяться, выдвинет ИТ-отделу реальные требования, а тот, в свою очередь, сможет организовать свою работу, исходя из реальных приоритетов. Итак, ITSM подразумевает коренную реорганизацию службы эксплуатации информационных технологий. Опираясь на мировой опыт, компания Нewlett-Рackard разработала типовую модель управления качеством информационных услуг, так называемую ITSM Reference Model. Модель детально описывает процессы и взаимосвязи между ними, которые должен поддерживать ИТ-отдел, чтобы предоставлять информационные услуги с гарантированным качеством. Ключевые элементы ITSM - процессы, персонал, технологии Идеология ITSM держится на трех китах:
Решающим для успеха внедрения ITSM является первый элемент - разработка производственных процессов ИТ-отдела, определяющих последовательность действий персонала в определенных ситуациях, координирующих работу всех сотрудников, служб и подразделений автоматизации. ИТ-отделы постоянно внедряют новые технологии, еще более усложняющие информационную инфраструктуру компании. Однако более эффективные системы сами по себе не обеспечат бизнес необходимыми услугами с требуемым качеством, если не определены процессы использования таких систем. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
БИЛЕТ 6 |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Существует множество определений информатики, что связано с многогранностью ее функций, возможностей, средств и методов. Обобщая опубликованные в литературе по информатике определения этого термина, предлагаем такую трактовку. Информатика — это область человеческой деятельности, связанная с процессами преобразования информации с помощью компьютеров и их взаимодействием со средой применения. Часто возникает путаница в понятиях "информатика" и "кибернетика". Попытаемся разъяснить их сходство и различие. Основная концепция, заложенная Н. Винером в кибернетику, связана с разработкой теории управления сложными динамическими системами в разных областях человеческой деятельности. Кибернетика существует независимо от наличия или отсутствия компьютеров. Кибернетика — это наука об общих принципах управления в различных системах: технических, биологических, социальных и др. Информатика занимается изучением процессов преобразования и создания новой информации более широко, практически не решая задачи управления различными объектами, как кибернетика. Поэтому может сложиться впечатление об информатике как о более емкой дисциплине, чем кибернетика. Однако, с другой стороны, информатика не занимается решением проблем, не связанных с использованием компьютерной техники, что, несомненно, сужает ее, казалось бы, обобщающий характер. Между этими двумя дисциплинами провести четкую границу не представляется возможным в связи с ее размытостью и неопределенностью, хотя существует довольно распространенное мнение, что информатика является одним из направлений кибернетики. Информатика появилась благодаря развитию компьютерной техники, базируется на ней и совершенно немыслима без нее. Кибернетика же развивается сама по себе, строя различные модели управления объектами, хотя и очень активно использует все достижения компьютерной техники. Кибернетика и информатика, внешне очень похожие дисциплины, различаются, скорее всего, в расстановке акцентов:
Термин информатика возник в 60-х гг. во Франции для названия области, занимающейся автоматизированной обработкой информации с помощью электронных вычислительных машин. Французский термин informatique (информатика) образован путем слияния слов information (информация) и automatique (автоматика) и означает "информационная автоматика или автоматизированная переработка информации". В англоязычных странах этому термину соответствует синоним computer science (наука о компьютерной технике). Выделение информатики как самостоятельной области человеческой деятельности в первую очередь связано с развитием компьютерной техники. Причем основная заслуга в этом принадлежит микропроцессорной технике, появление которой в середине 70-х гг. послужило началом второй электронной революции. С этого времени элементной базой вычислительной машины становятся интегральные схемы и микропроцессоры, а область, связанная с созданием и использованием компьютеров, получила мощный импульс в своем развитии. Термин "информатика" приобретает новое дыхание и используется не только для отображения достижений компьютерной техники, но и связывается с процессами передачи и обработки информации. В нашей стране подобная трактовка термина "информатика" утвердилась с момента принятия решения в 1983 г. на сессии годичного собрания Академии наук СССР об организации нового отделения информатики, вычислительной техники и автоматизации. Информатика трактовалась как "комплексная научная и инженерная дисциплина, изучающая все аспекты разработки, проектирования, создания, оценки, функционирования основанных на ЭВМ систем переработки информации, их применения и воздействия на различные области социальной практики". Информатика в таком понимании нацелена на разработку общих методологических принципов построения информационных моделей. Поэтому методы информатики применимы всюду, где существует возможность описания объекта, явления, процесса и т.п. с помощью информационных моделей. Информатика как фундаментальная наука занимается разработкой методологии создания информационного обеспечения процессов управления любыми объектами на базе компьютерных информационных систем. Существует мнение, что одна из главных задач этой науки — выяснение, что такое информационные системы, какое место они занимают, какую должны иметь структуру, как функционируют, какие общие закономерности им свойственны. В Европе можно выделить следующие основные научные направления в области информатики: разработка сетевой структуры, компьютерно-интегрированные производства, экономическая и медицинская информатика, информатика социального страхования и окружающей среды, профессиональные информационные системы. Цель фундаментальных исследований в информатике — получение обобщенных знаний о любых информационных системах, выявление общих закономерностей их построения и функционирования. Новый этап теоретического расширения понятия “информация” связан с кибернетикой (греч. kiber – над, nautus – моряк, кормчий, управляющий рулем, отсюда – искусство управления) – наукой об управлении и связи в живых организмах, обществе и машинах, технических системах. Впервые термин “кибернетика” встречается в работах древнегреческого философа Платона (ок. 427-347 гг. до н. э.), в которых он обозначил правила управления обществом. Через две с лишним тысячи лет французский физик А. И. Ампер (1775 –1836) в своей работе “Опыт философских наук” (1834) термин “кибернетика” также применил к науке об управлении обществом. Понадобилось еще 200 лет развития естественных и гуманитарных наук для того, чтобы в 1940-х годах термин “кибернетика” наполнился современным содержанием. Н. Винер (рис. 1.1) применил этот термин в своей книге “Кибернетика или управление и связь в животном и машине” (1948). Основное внимание Н. Винер обратил на информационную сущность управления, наличие движения информации в контуре управления, прямую и обратную связь в управлении живыми организмами и техническими системами. Появление в 1948 г. работы Н. Винера было представлено на Западе некоторыми журналистами как сенсация. О кибернетике, вопреки мнению самого Винера, писали как о новой универсальной науке, якобы способной заменить философию, объясняющую процессы развития в природе и обществе. Все это наряду с недостаточной осведомленностью отечественных философов с первоисточниками из области теории кибернетики привело к необоснованному отрицанию кибернетики в нашей стране как самостоятельной науки. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Эксперимент считают перспективным, если: - Объектом исследования служат новые исследования, явления, материалы, процессы и конструкции; - Проверяются теории или гипотезы, а также устанавливаются границы их применимости; - Получаются точные количественные или новые качественные данные об известных свойствах процессов, явлений, материалов и конструкций. Цель эксперимента определяет выбор метода. Для того чтобы эксперимент был действительно перспективным необходимо выбрать соответствующий метод исследования. Неправильный выбор приводит к получению избыточной или недостаточной информации, удорожанию и усложнению эксперимента, а иногда и к ошибочным результатам. Математические методы планирования эксперимента – это новый кибернетический подход к инженерным исследованиям, имеющим экспериментальный характер. Внедрение математических методов планирования эксперимента позволяет в значительной степен исключить слепой хаотический поиск, заменить его научно обоснованной программой проведения экспериментального исследования, включающей объективную оценку результатов эксперимента на всех последовательных этапах исследования. Отметим список задач, которыми занимается планирование эксперимента:
Даже при не полном знании о механизме процесса путём направленного эксперимента можно получить его математическую модель. Можно сказать, что там, где есть эксперимент, имеет место и наука о его проведении – планирование эксперимента. На какие вопросы даёт ответ планирование эксперимента:
Следовательно, задача, которой занимается планирование эксперимента, может быть сформулирована так: "Сколько и каких опытов следует провести и как обработать их результаты, чтобы ответить на заранее заданный вопрос с заранее заданной точностью при минимальном возможном числе опытов". Эта вечная для экспериментатора задача, которая решалась обычно интуитивными методами, теперь поставлена на научную основу]. Известно, что новая наука может возникнуть, если существует объективная необходимость ее появления и имеется предмет новой науки, представляющий общенаучный интерес. Сказанное в полной мере относится и к теории планирования эксперимента. Предмет исследования этого научного направления – эксперимент. Однако особенности планирования, постановки эксперимента рассматриваются и в физике, и в химии, и в прикладных науках. Для того чтобы эксперимент стал предметом исследования отдельного научного направления, необходимо, чтобы он характеризовался некоторыми чертами, общими для любого эксперимента независимо от того, в какой конкретной области знаний эксперимент проводится. Такими общими чертами эксперимента является необходимость: 1) контролировать любой эксперимент, т.е. исключать влияние внешних переменных, не принятых исследователем по тем или иным причинам к рассмотрению; 2) определять точность измерительных приборов и получаемых данных; 3) уменьшать до разумных пределов число переменных в эксперименте; 4) составлять план проведения эксперимента, наилучший с той или иной точки зрения; 5) проверять правильность полученных результатов и их точность; 6) выбирать способ обработки экспериментальных данных и форму представления результатов; 7) анализировать полученные результаты и давать их интерпретацию в терминах той области, где эксперимент проводится. Планирование экспериментов имеет следующие цели:
Таким образом, целью любого эксперимента является получение информации об исследуемом объекте. План эксперимента на компьютере представляет собой метод получения с помощью эксперимента необходимой информации. Таким образом, проблема проведения эксперимента с минимальными затратами и высокоэффективным использованием средств вычислительной техники весьма актуальна. Изучение сложных объектов, являющихся по своей природе стохастическими, возможна лишь с помощью методов планирования и обработки результатов эксперимента. Планирование эксперимента – это процедура выбора числа и условий проведения опытов, необходимых и достаточных для решения поставленной задачи с требуемой точностью Под экспериментом будем понимать совокупность операций совершаемых над объектом исследования с целью получения информации об его свойствах. Эта совокупность может быть весьма сложной, но её всегда можно разложить на отдельные элементы, каждый из которых мы называем опытом. Эксперимент, в котором исследователь по своему усмотрению может изменять условия его проведения, называется активным экспериментом. Если исследователь не может самостоятельно изменять условия его проведения, а лишь регистрирует их, то это пассивный эксперимент. Важнейшей задачей методов обработки полученной в ходе эксперимента информации является задача построения математической модели изучаемого явления, процесса, объекта. Ее можно использовать и при анализе процессов и при проектировании объектов. Можно получить хорошо аппроксимирующую математическую модель, если целенаправленно применяется активный эксперимент. Другой задачей обработки полученной в ходе эксперимента информации является задача оптимизации, т.е. нахождения такой комбинации влияющих независимых переменных, при которой выбранный показатель оптимальности принимает экстремальное значение План эксперимента – совокупность данных определяющих число, условия и порядок проведения опытов. Цель планирования эксперимента – нахождение таких условий и правил проведения опытов при которых удается получить надежную и достоверную информацию об объекте с наименьшей затратой труда, а также представить эту информацию в компактной и удобной форме с количественной оценкой точности. Пусть интересующее нас свойство (Y) объекта зависит от нескольких (n) независимых переменных (Х1, Х2, …, Хn) и мы хотим выяснить характер этой зависимости – Y=F(Х1, Х2, …, Хn), о которой мы имеем лишь общее представление. Величина Y – называется «отклик», а сама зависимость Y=F(Х1, Х2, …, Хn) – "функция отклика". Отклик должен быть определен количественно. Однако могут встречаться и качественные признаки Y. В этом случае возможно применение рангового подхода. Пример рангового подхода – оценка на экзамене, когда одним числом оценивается сложный комплекс полученных сведений о знаниях студента. Независимые переменные Х1, Х2, …, Хn – иначе факторы, также должны иметь количественную оценку. Если используются качественные факторы, то каждому их уровню должно быть присвоено какое-либо число. Важно выбирать в качестве факторов лишь независимые переменные, т.е. только те которые можно изменять, не затрагивая другие факторы. Факторы должны быть однозначными. Для построения эффективной математической модели целесообразно провести предварительный анализ значимости факторов (степени влияния на функцию), их ранжирование и исключить малозначащие факторы. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Область распределенных вычислений представляет собой раздел теории вычислительных систем. Изучающий теоретические вопросы организации распределенных систем Также распределенные вычисления иногда определяют в более узком смысле. как применение распределенных систем для решения трудоемких вычислительных задач. В таком контексте распределенные вычисления являются частным случаем параллельных вычислений. т.е. одновременного решения различных частей одной вычислительной задачи несколькими вычислительньши устройствами. Отметим. что при изучении параллельных вычислений основной акцент обычно делается на методах разделеъшя решаемой задачи на подзадачи. которые могут рассчитываться одновременно для максимального ускорения вычислений. Основная же особенность в организации параллельных вычислений с использованием распределенных систем будет заключаться в необходимости учитывать разштчне характеристикдоступньгх вычислительных устройств и наличие существеннои временной задержки при оомене даиньши между’ ними. Существует множество определений распределенной системы, причем ни одно из них не является строгим или общепринятым. Распределенная система - это набор независимых компьютеров, представляющийся их пользователям еджтой объединенной системой. Здесь необходимо обратить внимание на то. что сами по себе независимые компьютеры не могут представляться пользоватешпо единой системой. Приведем еще несколько других определений, встречающихся в литературе. Распределенная система — это такая система, в которой взаимодействие и синхронизация программных компонентов, выполняемых на независимых сетевых компьютерах осуществляется посредством передачи сообщений. Распределенная система — набор независимых компьютеров. Не имеющих общей совместно используемой памяти и общего единого времени (таймера) и взаимодействующих через коммуникационную сеть посредством передачи сообщений‚ где каждый компьютер использует свою собственную оперативную память и на котором выполняется отдельный экземпляр своей операционной системы. Однако эти операционные системы функционируют совместно предоставляя свои службы друг другу для решения общей задачи. Термин "распределенная система" описывает широкий спектр систем от слабо связанных многомашинных комплексов. представляемых, например, набором персональных компьютеров. объединенных в сеть, до сильно связанных многопроцессорных систем. Рассматрим распределенную систему с аппаратной точки зрения в виде совокупности взаимосвязанных автономных компьютеров или процессоров. с программной точки зрения — в виде совокупности независимых процессов (исполняемых программных компонентов распределенной системы), взаимодействующих посредством передачи сообщений для обмена данными и координации своих действий. Компьютеры процессоры или процессы будем называть узлами распределенной системы. Чтобы процессоры могли считаться автономными. они должны, по меньшей мере, обладать собствеъшьтм независимым управлением. По этой причине параллельный компьютер, архитектура которого устроена по схеме "одна команда для многих данных не может считаться распределенной системой. Под независимостью процессов подразумевается тот факт, что каждый процесс имеет свое собственное состояние, представляемое набором данных. вшпочахощнм текущие значения счетчика команд. регистров и переменных к которым процесс может обращаться и которые может изменять, Состояние каждого процесса является полностью закрьгтътм для других процессов: другие процессы не имеют в: нему прямого доступа н не могут изменять его. Скорости выполнения операций разных процессов в распределенной системе различны и заранее неизвестны, а доставка отправленных сообщений может занимать непредсказуемое время. Поскольку в качестве узлов системы могут выступатъ процессы, под приведенное нами определение подпадают также и программные системы, представляющие собой совокупность взаимодействующих процессов, вьшодтняемъпх на одном и том же вычислителъиом устройстве. В этой ситуации каналы взаимодействии осуществляющие передачу сообщений между процессами, реализуются с помощью разделяемой памяти вместо сети связи. Однако в большинстве случаев в распределенной системе все же содержится несколько процессоров, взаимосвязаииъш друг с другом при помощи средств коммуникации. Типичная распределенная система представлена на рис‚ 1.1; ЦП — центральный процессор, ОП — оперативная (основная) памятъ. Признаки распределенных систем: - Отсутствие единого времени для компонентов распределенной системы. Подразумевает отсутствие синхронности в компонентах системы, а именно процессоров, входящий в состав системы, а так же их территориальное распределение. - отсутствие общей памяти – подразуемает необходимость обмена сообщениями между программными компонентами распределенной системы для их взаимодействия и синхронизации. Отсутсиве единого для всех процессоров физического времени. - географическое распределение – сюда входят как процессы распределения в глобальной сети, так и в локальных вычислительных сетях при распределенности процессов вычислительной системы - независимость и гетерогенность – компьютеры, входящие в состав распределенной системы слабо связаны в том смысле, что они могут иметь различный состав и различную производительность и следовательно обеспечивать различное время выполнения идентичных задач. Обычно они не являются частями одной специализированной системы, но функционируют совместно, предоставляя свои службы друг другу для выполнения общей задачи. Цели построения распределительных систем: - Географически распределенная вычислительная среда (например, банковская сеть, Интернет) - требование увеличения производительности вычислений – принцип реализуется в виде больших многопроцессорных систем и машинных комплексов - совместное использование ресурсов - отказоустойчивость – достигается за счет избыточности, когда в систему добавляется дополнительное оборудование (аппаратная избыточность), процессы (программная избыточность), которое делают возможным правильное функционирование системы при неработоспособности или некорректной работе некоторых ее компонентов. Требования к распределенным системам: - прозрачность – способность скрывать свою распределенную природу, а именно, распределение процессов и ресурсов по множеству компьютеров и предоставляться для пользователей и разрабочиков в виде единой централизованной компьютерной системы -Открытость – реализация открытых спецификаций (стандартов) на нтерфейсы, службы и поддерживаемые форматы данных, достаточные для того, чтобы обеспечить возможность переноса разработанного ПП обеспечения на широкий диапазон систем, совместную работу с другими прикладными приложениями на локальных и удаленных платформах, взаимодействие с пользователями в стиле, облегчающим последним переход от системы к системе. -масштабируемость – способность вычислительной системы эффективно справляться с увеличением числа пользователей и без увеличения административной нагрузки на ее управление.
Сложности разработки распределенных систем Реализация перечисленных выше свойств распределенных систем на практике представляют непростую задачу. Основные сложности вытекают именно из того факта, что компоненты распределенной системы территориально удалены друг от друга и выполняются на независимых компьютерах в сети. Игнорирование этого обстоятельства на этапе проектирования и разработки соответствующего программного обеспечения часто приводит к существенным проблемам в функционировании распределенной системы. При создании распределенных приложений часто возникают ошибки, которые возникают на следующих заблуждениях: - сеть является надежной - задержки передачи передачи сообщений равны нулю - полоса пропускания не ограничена - сеть является безопасной - сетевая топология неизменна - систему обслуживает только один администратор - издержки на транспортную инфраструктуру равны нулю - сеть является однородной Важно отметить, что перечисленные предположения как раз и отличают разработку традиционных локальных приложений и систем от распределенных в том смысле, что для нераспределенных приложений большинство из этих допущени остается верным, а проблемы, возникающие при нарушении любого из них, скорее всего, не будут проявляться. Большая же часть принципов, лежащих в основе распределенных систем имеет непосредственное отношение к перечисленным предположениям. Поэтому в области распределенных вычислений рассматриваются методы и алгоритмы, позволяющие реализовывать распределенные системы, при условии того, что хотя бы одно из представленных допущений является ложным. Например, понятно, что надежных сетей не существует, что, в свою очередь, приводит к невозможности достижения абсолютной прозрачности отказов. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Любой экономический объект (предприятие, организация, фирма) является сложной, динамичной и управляемой системой. Система - это упорядоченная совокупность разнородных элементов или частей, взаимодействующих между собой и с внешней средой, объединенных в единое целое и функционирующих в интересах достижения единых целей. Целенаправленное воздействие на систему, ведущее к изменению, либо сохранению ее состояния обеспечивается управлением. Экономический объект, как управляемая система, включает объект и субъект управления. Объектом управления экономического объекта является производственный коллектив, выполняющий комплекс работ, направленных на достижение определенных целей и располагающий для этого материальными, финансовыми и иными видами ресурсов. Субъект или система управления экономического объекта формирует цели его функционирования и осуществляет контроль их выполнения. Основными функциями управления экономическим объектом являются планирование, учет, анализ, контроль и регулирование. Выполнение функций управления возлагается на аппарат управления, включающий службы и отделы, выполняющие отдельные функции: плановый отдел, финансовый отдел, бухгалтерия, отдел сбыта, снабжения и т.д. Совокупность взаимосвязанных органов, выполняющих частные функции управления, определяет организационную структуру системы управления. В системе управления экономическим объектом выделяются стратегический, тактический (функциональный) и оперативный уровни. На стратегическом уровне вырабатываются решения, направленные на достижение целей долгосрочного характера. Здесь определяются цели и осуществляется долгосрочное (прогнозное) планирование. На тактическом (функциональном) уровне разрабатываются среднесрочные, текущие и оперативно-календарные планы и контролируется ход их выполнения. На оперативном уровне осуществляется сбор первичной информации обо всех изменениях, происходящих в объекте управления, ее анализ и выработка решений, направленных на достижение установленных планами целей и задач. Управление базируется на информации. В процессе управления возникают информационные потоки между объектом и субъектом управления экономического объекта, а также между ним и внешней средой. Направленность внутренних информационных потоков характеризует прямую и обратную связь в системе управления. Система управления, на основе информации о состоянии экономического объекта и информации, поступающей из внешней среды, определяет цели функционирования экономического объекта и вырабатывает директивы, воздействующие на объект управления (прямая связь). В процессе функционирования экономического объекта происходят изменения в объекте управления. Информация об этих изменениях в совокупности с внешними воздействиями (директивной информацией, информацией от контрагентов и др.) воспринимается системой управления, которая на ее основе вырабатывает новые управляющие решения и вновь воздействует на объект управления (обратная связь). В процессе управления необходимая информация регистрируется, передается, хранится, накапливается и обрабатывается. Комплекс этих процедур составляет информационный процесс управления. Информационный процесс - это процесс регистрации, передачи, хранения, накопления и обработки информации. Информация в этом процессе рассматривается и как предмет (исходная информация) и как продукт труда (результатная информация) системы управления. Исходная, первичная информация преобразуется в результатную, пригодную для формирования управленческих решений. Поэтому информационный процесс является частью управленческой деятельности. Информационный процесс управления реализуется путем выполнения строго регламентированной совокупности процедур, направленных на преобразование исходной информации в результатную. Установленная последовательность процедур преобразования информации и совокупность методов и способов их реализации определяют информационную технологию. Информационная технология (ИТ) - это совокупность взаимосвязанных процедур преобразования данных с использованием системы методов их выполнения в определенной технической среде. Автоматизированная информационная технология является процессом, состоящим из четко регламентированных правил выполнения операций разной степени сложности над данными, хранящимися в компьютерах. Для организации и реализации информационного процесса необходим персонал, способный выполнять его процедуры, а также соответствующие средства и методы обработки информации. Все это в совокупности составляет информационную систему (ИС). Информационная система - это взаимосвязанная совокупность информации, средств и методов ее обработки, а также персонала, реализующего информационный процесс. Экономическая информационная система (ЭИС) имеет дело, прежде всего, с экономической информацией. Основным назначением ЭИС является преобразование исходной информации в результатную, пригодную для принятия управленческих решений. Любому экономическому объекту присуща экономическая информационная система. В дальнейшем под термином "информационная система" будет пониматься "экономическая информационная система". Процедуры информационного процесса могут выполняться в ИС вручную и с использованием различных технических средств: разнообразной офисной техники, компьютеров и средств телекоммуникаций. Компьютеры и соответствующее программное обеспечение радикально изменяют методы и технологию обработки информации. Поэтому различают неавтоматизированные и автоматизированные информационные системы. В неавтоматизированных ИС все операции по обработке информации выполняются самими управленческими работниками без использования или с минимальным использованием технических средств обработки информации. В автоматизированных ИС (АИС) значительная часть рутинных операций информационного процесса осуществляются специальными методами с помощью технических средств, без или при минимальном вмешательстве человека. Автоматизированная информационная система - это система, в которой информационный процесс управления автоматизирован за счет применения специальных методов обработки данных, использующих комплекс вычислительных, коммуникационных и других технических средств в целях получения и доставки результатной информации пользователю-специалисту для выполнения возложенных на него функций управления. В современном понимании термин "информационные системы" подразумевает автоматизацию информационных процессов. Поэтому термины "информационная система" и "автоматизированная информационная система" часто используются как равноправные. Но следует помнить о том, что информационные системы могут использовать и неавтоматизированную технологию обработки информации. На любом экономическом объекте существует информационная система, даже если при реализации информационного процесса никакие технические средства не используются. При этом в рамках ИС экономического объекта для решения части задач информационного процесса управления могут использоваться средства автоматизации, а часть задач может решаться без применения средств вычислительной техники, реализующих принцип программного управления, то есть неавтоматизированно. Таким образом, ИС экономического объекта может включать АИС как свою составную часть. В дальнейшем мы будем говорить только об автоматизированных информационных системах, применямых при управлении производственными, торговыми и сервисными предприятиями, то есть об АИС управления предприятиями (ИСУП). Поэтому в последующем нами будет использоваться именно этот термин. В последнее время во множестве публикаций, посвященных применению информационных технологий при управлении экономическими объектами, часто используются термины "корпоративные информационные системы" и "информационные системы управления предприятиями", под которыми в них понимаются как собственно автоматизированные информационные системы экономических объектов, так и пакеты прикладных программ, которые могут быть составляющими специализированного прикладного программного обеспечения ИСУП. Подробнее соотношение этих понятий с введенными выше определениями раскрывается далее, при рассмотрении обеспечивающих подсистем АИС. Решения в системе управления предприятием принимаются людьми на основе информации, являющейся продуктом ИС. На ее входе находится исходная, первичная информация обо всех изменениях, происходящих в объекте управления. Она фиксируется в результате выполнения функций оперативного учета. В ИС первичная информация преобразуется в результатную, пригодную для принятия решений. В ИСУП часть процедур формального преобразования первичной информации в результатную автоматически выполняется техническими средствами по заранее заданным алгоритмам, без непосредственного вмешательства человека. Это не означает, что ИСУП может полностью функционировать в автоматическом режиме. Персонал системы управления определяет состав и структуру первичной и результатной информации, порядок сбора и регистрации первичной информации, контролирует ее полноту и достоверность, определяет порядок выполнения преобразований первичной информации в результатную, контролирует ход выполнения процесса преобразований. К тому же процедура сбора первичной информации до сих пор слабо автоматизирована. Поэтому ее ввод в технические средства также осуществляется персоналом ИСУП. В современных ИСУП автоматизированные процедуры информационного процесса интегрированы с функциями управления. Наряду со своими основными функциями, их непосредственно выполняет управленческий персонал. Более того, некоторые современные перспективные методы управления жестко ориентированы на использование компьютеров и без их применения практически нереализуемы. Организационно ИСУП реализуется через создание автоматизированных рабочих мест (АРМ) работников системы управления. Номенклатура АРМ зависит от организационной структуры системы управления экономическим объектом и разделяется по различным функциям управления (планирование, учет, анализ, контроль). Каждая функция управления имеет свой набор решаемых задач. Отдельные задачи распределяются по комплексам задач. Например, в подсистеме бухгалтерского учета выделяются комплексы задач учета: основных средств, материальных ценностей, труда и заработной платы, готовой продукции и ее реализации, финансово-расчетных операций, затрат на производство, сводного учета и составления отчетности. В соответствии с этим отдельные АРМ обычно ориентированы на решение отдельных комплексов задач системы управления. Распределение комплексов задач между отдельными АРМ зависит от разделения функций между разными подразделениями системы управления предприятием, между сотрудниками внутри этих подразделений и ряда других факторов. Для ИСУП характерны развитые внутренние и внешние информационные связи. Внутренние информационные связи существуют между задачами внутри отдельных комплексов, а также между самими комплексами. Так, например, задачи учета затрат и сводного учета базируются на информации, которая является результатом решения задач комплексов учета основных средств, материальных ценностей, труда и заработной платы и др. А задачи этих комплексов, в свою очередь, используют первичную информацию оперативного учета. Внешние информационные связи АИС проявляются в использовании данных, поступающих от внешних организаций. Комплексы и состав входящих в них задач, внешние и внутренние информационные связи задач составляют функциональную модель ИСУП. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Самообучающаяся система – это интеллектуальная информационная система, которая на основе примеров реальной практики автоматически формирует единицы знаний. В основе самообучающихся систем лежат методы автоматической классификации примеров реальной практики, то есть обучения на примерах. Примеры реальных ситуаций накапливаются за некоторый период и составляют обучающую выборку. В результате обучения системы автоматически строятся обобщенные правила или функции, определяющие принадлежность ситуаций классам, которыми обученная система пользуется при интерпретации незнакомых ситуаций. Из обобщающих правил автоматически формируется база знаний, которая периодически корректируется по мере накопления информации об анализируемых ситуациях. Различают следующие виды самообучающихся систем: 1) Индуктивные системы. Система с индуктивным выводом – это самообучающаяся интеллектуальная информационная система, работающая на принципе индукции с помощью классификации примеров по значимым признакам. Индуктивный вывод (от частного к общему) – вывод (обобщение) общих утверждений на основе множества частных утверждений. Обобщение примеров на основе этого принципа сводится к выбору классификационного признака из множества заданных; выявлению множества примеров по значению выбранного признака; определению принадлежности данных примеров одному из классов Процесс классификации может быть представлен в виде дерева решений, в котором в промежуточных узлах находятся значения признаков последовательной классификации, а в конечных узлах – значения признака принадлежности определенному классу. 2) Нейронные сети – это самообучающиеся интеллектуальные информационные системы, которые на основе обучения по реальным примерам строят ассоциативную сеть понятий (нейронов) для параллельного поиска на ней решений. В результате обучения на примерах строятся математические решающие функции (передаточные функции или функции активации), которые определяют зависимости между входными (Xi) и выходными (Yj) признаками (сигналами).
З
Каждая
такая функция, называемая по аналогии
с элементарной единицей человеческого
мозга – нейроном, отображает зависимость
значения выходного признака (Y) от
взвешенной суммы (U) значений входных
признаков (Xi), в которой вес входного
признака (Wi) показывает степень влияния
входного признака на выходной:
Решающие функции используются в задачах классификации на основе сопоставления их значений при различных комбинациях значений входных признаков с некоторым пороговым значением. В случае превышения заданного порога считается, что нейрон сработал и, таким образом, распознал некоторый класс ситуаций. Нейроны используются и в задачах прогнозирования, когда по значениям входных признаков после их подстановки в выражение решающей функции получается прогнозное значение выходного признака. Нейроны могут быть связаны между собой, когда выход одного нейрона является входом другого. Таким образом, строится нейронная сеть, в которой нейроны, находящиеся на одном уровне, образуют слои.
О Наиболее распространенным алгоритмом обучения нейронной сети является алгоритм обратного распространения ошибки. Целевая функция по этому алгоритму должна обеспечить минимизацию квадрата ошибки в обучении по всем примерам: f(u) = min å(Ti - Yi)2, здесь Ti – заданное значение выходного признака по i-му примеру; Yi – вычисленное значение выходного признака по i-му примеру. Достоинство нейронных сетей перед индуктивным выводом заключается в решении не только классифицирующих, но и прогнозирующих задач. Возможность нелинейного характера функциональной зависимости выходных и входных признаков позволяет строить более точные классификации. Сам процесс решения задач в силу проведения матричных преобразований проводится очень быстро. Фактически имитируется параллельный процесс прохода по нейронной сети в отличие от последовательного в индуктивных системах. Нейронные сети могут быть реализованы и аппаратно в виде нейрокомпьютеров с ассоциативной памятью. Последнее время нейронные сети получили стремительное развитие и очень активно используются в финансовой области. В качестве примеров внедрения нейронных сетей можно назвать: • Система прогнозирования динамики биржевых курсов для Chemical Bank (фирма Logica); • Система прогнозирования для Лондонской фондовой биржи (фирма SearchSpace); • Управление инвестициями для Mellon Bank (фирма NeuralWare) и др. В качестве инструментальных средств разработки нейронных сетей следует выделить инструментальные средства NeurOn-line (фирма GENSYM), NeuralWorks Professional II/Plus (фирма NeuralWare), отечественную разработку FOREX-94 (Уралвнешторгбанк) и др. 3) Системы, основанные на прецедентах (Case-based reasoning) – это самообучающиеся интеллектуальные информационные системы, которые в качестве единиц знаний хранят прецеденты решений (примеры) и позволяют по запросу подбирать и адаптировать наиболее похожие прецеденты. В этих системах база знаний содержит описания не обобщенных ситуаций, а собственно сами ситуации или прецеденты. Тогда поиск решения проблемы сводится к поиску по аналогии (абдуктивному выводу). Абдуктивный вывод (от частного к частному) – вывод частных утверждений на основе поиска других аналогичных утверждений (прецедентов). Он включает следующие этапы: 1. Получение подробной информации о текущей проблеме; 2. Сопоставление полученной информации со значениями признаков прецедентов из базы знаний; 3. Выбор прецедента из базы знаний, наиболее близкого к рассматриваемой проблеме; 4. В случае необходимости выполняется адаптация выбранного прецедента к текущей проблеме; 5. Проверка корректности каждого полученного решения; 6. Занесение детальной информации о полученном решении в базу знаний. Также как и для индуктивных систем, прецеденты описываются множеством признаков, по которым строятся индексы быстрого поиска. Но в отличие от индуктивных систем допускается нечеткий поиск с получением множества допустимых альтернатив, каждая из которых оценивается некоторым коэффициентом уверенности. Далее наиболее подходящие решения адаптируются по специальным алгоритмам к реальным ситуациям. Обучение системы сводится к запоминанию каждой новой обработанной ситуации с принятыми решениями в базе прецедентов. 4) Информационные хранилища (Data Warehouse) – это самообучающиеся ИИС, которые позволяют извлекать знания из баз данных и создавать специально-организованные базы знаний. Информационные хранилища представляют собой хранилища значимой информации, регулярно извлекаемой из оперативных баз данных и предназначенной для оперативного анализа данных (реализации OLAP-технологии). Типичными задачами оперативного ситуационного анализа являются: • Определение профиля потребителей конкретного товара; • Предсказание изменений ситуации на рынке; • Анализ зависимостей признаков ситуаций (корреляционный анализ) и др. Для извлечения значимой информации из баз данных используются специальные методы (Data Mining или Knowledge Discovery), основанные или на применении методов математической статистики, индуктивных методов построения деревьев решений или нейронных сетей. Формулирование запроса осуществляется в результате применения интеллектуального интерфейса, позволяющего в диалоге гибко определять значимые признаки анализа. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
БИЛЕТ 7 |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Мультимедиа (multimedia) - это современная компьютерная информационная технология, позволяющая объединить в компьютерной системе текст, звук, видеоизображение, графическое изображение и анимацию (мультипликацию). Мультимедиа-это сумма технологий, позволяющих компьютеру вводить, обрабатывать, хранить, передавать и отображать (выводить) такие типы данных, как текст, графика, анимация, оцифрованные неподвижные изображения, видео, звук, речь. 20 лет назад мультимедиа ограничивалась пишущей машинкой " Консул ", которая не только печатала, но и могла привлечь внимание заснувшего оператора мелодичным треском. Чуть позже компьютеры уменьшились до бытовой аппаратуры, что позволило собирать их в гаражах и комнатах. Нашествие любителей дало новый толчок развития мультимедиа (компьютерный гороскоп 1980 года который при помощи динамика и программируемого таймера синтезировал расплывчатые устные угрозы на каждый день да еще перемещал по экрану звезды (зачатки анимации)). Примерно в это время появился и сам термин мультимедиа. Скорее всего, он служил ширмой, отгораживавшей лаборатории от взглядов непосвященных ("А что это у тебя там звенит ? ". " Да, это мультимедиа "). Критическая масса технологий накапливается. Появляются бластеры, "сиди ромы" и другие плоды эволюции, появляется интернет, WWW, микроэлектроника. Человечество переживает информационную революцию. И вот мы становимся свидетелями того, как общественная потребность в средствах передачи и отображения информации вызывает к жизни новую технологию, за неимением более корректного термина называя ее мультимедиа. В наши дни это понятие может полностью заменить компьютер практически в любом контексте. Совсем другое развитие получило мультимедиа у нас в стране: В России мультимедиа появилась примерно в конце 80х годов, и она не использовалась на домашних компьютерах, а использовалась только специалистами. Поэтому в статьях газет и журналов тех лет она упоминалась редко. Слово мультимедиа не вызывало ничего кроме недоумения или шуточек "Какая еще вам, -говорили мультимедиа! Посмотрите, что в стране делается!" Только в 1993 году многие поняли или начали понимать важность направления, осознавать роль, которую технология мультимедиа предстоит сыграть в 90е годы. Слово мультимедиа стало вдруг таким модным и в нашей стране, и все новые команды и организации поднимают этот флаг. Образовались новые коллективы разработчиков систем и конечных продуктов мультимедиа; появились потребители таких систем и продуктов, при чем весьма нетерпеливые. Конференция, состоящая 25-26 февраля 1993 года, как бы открыла сезон мультимедиа в России. 1994 год можно смело назвать годом начала бума домашнего мультимедиа на российском компьютерном рынке. А в наши дни мультимедиа - есть почти у всех, у кого есть компьютер и программное обеспечение на мультимедиа продаются везде разных типов, то есть она вошла в обиход. В широком смысле термин "мультимедиа" означает спектр информационных технологий, использующих различные программные и технические средства с целью наиболее эффективного воздействия на пользователя (ставшего одновременно и читателем, и слушателем, и зрителем). Благодаря применению мультимедиа в средствах информатизации за счет одновременного воздействия графической, звуковой, фото и видео информации такие средства обладают большим эмоциональным зарядом и активно включаются в индустрию развлечений, практику работы различных учреждений, домашний досуг. Появление систем мультимедиа произвело революцию во многих областях деятельности человека. Одно из самых широких областей применения технология мультимедиа получила в сфере образования, поскольку средства информатизации, основанные на мультимедиа способны, в ряде случаев, существенно повысить эффективность обучения. Экспериментально установлено, что при устном изложении материала обучаемый за минуту воспринимает и способен переработать до одной тысячи условных единиц информации, а при "подключении" органов зрения до 100 тысяч таких единиц. В настоящее время количество созданных средств мультимедиа измеряется тысячами наименований. Мультимедиа-технологии и соответствующие средства ИКТ развиваются очень быстро. Если в первом издании российского справочника по CD-ROM и мультимедиа, изданного в 1995 году, перечислено всего 34 экземпляра мультимедиа-продуктов образовательного назначения, в издании 1996 года таких продуктов было перечислено уже более 112-ти, а в начале 1998 года это число перевалило за 300, то сейчас этот список содержит несколько тысяч наименований. Безусловно, эти показатели не отражают точной картины обеспеченности средствами мультимедиа, но однозначно свидетельствуют о неуклонном росте числа создаваемых и используемых средств мультимедиа. Средства и технологии мультимедиа обеспечивают возможность интенсификации обучения и повышение мотивации к учению за счет применения современных способов обработки аудиовизуальной информации, таких, как:
В последнее время наметилось создание интегрированных информационных технологии, лежащих в основе так называемых систем комплексной информации [24]. Примером подобной технологии может служить мультимедиа-технология, позволяющая одновременно работать с числовой, текстовой, графической и аудио-видео информацией в реальном масштабе времени. И все это под управлением одного компьютера. К ее предшественникам можно отнести, например, интерактивные графические технологии, применяемые уже в течение двух десятков лет в САПР электронных компонентов и систем. Определяющими для развития мультимедиа-технологии являются достигнутые успехи в таких системах, как рабочие станции, широкополосные линии коммуникаций, запоминающие устройства большой емкости, цветные мониторы высокого разрешения. Передача больших объемов данных в мультимедиа системах требует высокой скорости и широкой полосы передачи. Развитие коммуникационных стандартов ISDN и FDD1 и оптиковолоконных линий связи в локальных сетях позволяют в значительной степени удовлетворить эти потребности. Вводу того, что информация в мультимедиа системах по своей природе представляет данные очень большого объема, проблема их хранения носит ключевой характер. Здесь прорывным решением является технология использования различных типов оптических дисков (CD - ROM - только читаемых, WORM - с однократной записью, CD-I с перезаписью). Графика и изображения требуют адекватных средств отображения. Имеющиеся сегодня мониторы разрешением 1000х1000 с 256 цветами уже можно считать таковыми. Мультимедиа-технологии опираются не только на достижения в аппаратных средствах, но и на технологические успехи в программном обеспечении, среди которых отметим два важных момента. Технология сжатия изображений является неотъемлемой частью при обработке образов и изображений. Достигнутые уровни сжатия изображений 120:1 позволяют на современных рабочих станциях выйти на работу в реальном времени, что необходимо в мультимедиа системах. Для манипуляции с данными мультимедиа систем важное значение имеют графические редакторы и человеко-машинные интерфейсы. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Классическими задачами системного анализа являются игровые задачи принятия решений в условиях риска и неопределенности. Неопределенными могут быть как цели операции, условия выполнения операции, так и сознательные действия противников или других лиц, от которых зависит успех операции. Разработаны специальные математические методы, предназначенные для обоснования решений в условиях риска и неопределенности. В некоторых, наиболее простых случаях эти методы дают возможность фактически найти и выбрать оптимальное решение. В более сложных случаях эти методы доставляют вспомогательный материал, позволяющий глубже разобраться в сложной ситуации и оценить каждое из возможных решений с различных точек зрения, и принять решений с учетом его возможных последствий. Одним из важных условий принятия решений в этом случае является минимизация риска. При решении ряда практических задач исследования операций (в области экологии, обеспечения безопасности жизнедеятельности и т. д.) приходится анализировать ситуации, в которых сталкиваются две (или более) враждующие стороны, преследующие различные цели, причем результат любого мероприятия каждой из сторон зависит от того, какой образ действий выберет противник. Такие ситуации мы можно отнести к конфликтным ситуациям. Теория игр является математической теорией конфликтных ситуаций, при помощи которой можно выработать рекомендации по рациональному образу действий участников конфликта. Чтобы сделать возможным математический анализ ситуации без учета второстепенных факторов, строят упрощенную, схематизированную модель ситуации, которая называется игрой. игра ведется по вполне определенным правилам, под которыми понимается система условий, регламентирующая возможные варианты действий игроков; объем информации каждой стороны о поведении другой; результат игры, к которому приводит каждая данная совокупность ходов. Результат игры (выигрыш или проигрыш) вообще не всегда имеет количественное выражение, но обычно можно, хотя бы условно, выразить его числовым значением. Ход — выбор одного из предусмотренных правилами игры действий и его осуществление. Ходы делятся на личные и случайные. Личным ходом называется сознательный выбор игроком одного из возможных вариантов действий и его осуществление. Случайным ходом называется выбор из ряда возможностей, осуществляемый не решением игрока, а каким-либомеханизмом случайного выбора (бросание монеты, выбор карты из перетасованной колоды и т. п.). Для каждого случайного хода правила игры определяют распределение вероятностей возможных исходов. Игра может состоять только их личных или только из случайных ходов, или из их комбинации. Следующим основным понятием теории игр является понятие стратегии. Стратегия — это априори принятая игроком система решений (вида «если — то»), которых он придерживается во время ведения игры, которая может быть представлена в виде алгоритма и выполняться автоматически. Целью теории игр является выработка рекомендаций для разумного поведения игроков в конфликтной ситуации, т. е. определение «оптимальной стратегии» для каждого из них. Стратегия, оптимальная по одному показателю, необязательно будет оптимальной по другим. Сознавая эти ограничения и поэтому не придерживаясь слепо рекомендаций, полученных игровыми методами, можно все же разумно использовать математический аппарат теории игр для выработки, если не в точности оптимальной, то, во всяком случае «приемлемой» стратегии. Игры можно классифицировать: по количеству игроков, количеству стратегий, характеру взаимодействия игроков, характеру выигрыша, количеству ходов, состоянию информации и т.д. [2, 7, 8]. В зависимости от количества игроков различают игры двух и n игроков. Первые из них наиболее изучены. Игры трех и более игроков менее исследованы из-за возникающих принципиальных трудностей и технических возможностей получения решения. В зависимости от числа возможных стратегий игры делятся на «конечные» и «бесконечные». Игра называется конечной, если у каждого игрока имеется только конечное число стратегий, и бесконечной, если хотя бы у одного из игроков имеется бесконечное число стратегий. По характеру взаимодействия игры делятся на бескоалиционные: игроки не имеют права вступать в соглашения, образовывать коалиции; коалиционные (кооперативные) — могут вступать в коалиции. В кооперативных играх коалиции заранее определены. По характеру выигрышей игры делятся на: игры с нулевой суммой (общий капитал всех игроков не меняется, а перераспределяется между игроками; сумма выигрышей всех игроков равна нулю) и игры с ненулевой суммой. По виду функций выигрыша игры делятся на: матричные, биматричные, непрерывные, выпуклые и др. Матричная игра — это конечная игра двух игроков с нулевой суммой, в которой задается выигрыш игрока 1 в виде матрицы (строка матрицы соответствует номеру применяемой стратегии игрока 1, столбец — номеру применяемой стратегии игрока на пересечении строки и столбца матрицы находится выигрыш игрока 1, соответствующий применяемым стратегиям). Для матричных игр доказано, что любая из них имеет решение и оно может быть легко найдено путем сведения игры к задаче линейного программирования. Биматричная игра — это конечная игра двух игроков с ненулевой суммой, в которой выигрыши каждого игрока задаются матрицами отдельно для соответствующего игрока (в каждой матрице строка соответствует стратегии игрока 1, столбец — стратегии игрока 2, на пересечении строки и столбца в первой матрице находится выигрыш игрока 1, во второй матрице — выигрыш игрока ) Непрерывной считается игра, в которой функция выигрышей каждого игрока является непрерывной. Доказано, что игры этого класса имеют решения, однако не разработано практически приемлемых методов их нахождения. Если функция выигрышей является выпуклой, то такая игра называется выпуклой. Для них разработаны приемлемые методы решения, состоящие в отыскании чистой оптимальной стратегии (определенного числа) для одного игрока и вероятностей применения чистых оптимальных стратегий другого игрока. Такая задача решается сравнительно легко. Запись матричной игры в виде платежной матрицы Рассмотрим конечную игру, в которой первый игрок А имеет m стратегий, а второй игрок B-n стратегий. Такая игра называется игрой m×n. Обозначим стратегии A1, А2, ..., Аm; и В1, В2, ..., Вn. Предположим, что каждая сторона выбрала определенную стратегию: Ai или Bj. Если игра состоит только из личных ходов, то выбор стратегий однозначно определяет исход игры — выигрыш одной из сторон aij. Если игра содержит кроме личных случайные ходы, то выигрыш при паре стратегий Ai и B является случайной величиной, зависящей от исходов всех случайных ходов. В этом случае естественной оценкой ожидаемого выигрыша является математическое ожидание случайного выигрыша, которое также обозначается за aij. Предположим, что нам известны значения aij при каждой паре стратегий. Эти значения можно записать в виде прямоугольной таблицы (матрицы), строки которой соответствуют стратегиям Ai, а столбцы — стратегиям Bj. Тогда, в общем виде матричная игра может быть записана следующей платежной матрицей:
Таблица — Общий вид платежной матрицы матричной игры где Ai — названия стратегий игрока 1, Bj — названия стратегий игрока 2, aij — значения выигрышей игрока 1 при выборе им i–й стратегии, а игроком 2 — j-й стратегии. Поскольку данная игра является игрой с нулевой суммой, значение выигрыша для игрока 2 является величиной, противоположенной по знаку значению выигрыша игрока 1. Критерии принятия решения ЛПР определяет наиболее выгодную стратегию в зависимости от целевой установки, которую он реализует в процессе решения задачи. Результат решения задачи ЛПР определяет по одному из критериев принятия решения. Для того, чтобы прийти к однозначному и по возможности наиболее выгодному варианту решению, необходимо ввести оценочную (целевую) функцию. При этом каждой стратегии ЛПР (Ai) приписывается некоторый результат Wi, характеризующий все последствия этого решения. Из массива результатов принятия решений ЛПР выбирает элемент W, который наилучшим образом отражает мотивацию его поведения. В зависимости от условий внешней среды и степени информативности ЛПР производится следующая классификация задач принятия решений:
Принятие решений в условиях неопределенности Будем предполагать, что лицу, принимающему решение не противостоит разумный противник. Данные, необходимо для принятия решения в условии неопределенности, обычно задаются в форме матрицы, строки которой соответствуют возможным действиям, а столбцы — возможным состояниям системы. Пусть, например, из некоторого материала требуется изготовить изделие, долговечность которого при допустимых затратах невозможно определить. Нагрузки считаются известными. Требуется решить, какие размеры должно иметь изделие из данного материала. Варианты решения таковы: Е1 — выбор размеров из соображений максимальной долговечности ; Еm — выбор размеров из соображений минимальной долговечности ; Ei — промежуточные решения. Условия требующие рассмотрения таковы: F1 — условия, обеспечивающие максимальной долговечность; Fn — условия, обеспечивающие min долговечность; Fi — промежуточные условия. Под результатом решения eij = е(Ei ; Fj) здесь можно понимать оценку, соответствующую варианту Ei и условиям Fj и характеризующие прибыль, полезность или надежность. Обычно мы будем называть такой результат полезностью решения. Тогда семейство (матрица) решений ||eij|| имеет вид:
Чтобы прийти к однозначному и по возможности наивыгоднейшему варианту решению необходимо ввести оценочную (целевую) функцию. При этом матрица решений ||eij|| сводится к одному столбцу. Каждому варианту Ei приписывается, т.о., некоторый результат eir, характеризующий, в целом, все последствия этого решения. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Важнейшей характеристикой вычислительных сетей является надежность. Повышение надежности основано на принципе предотвращения неисправностей путем снижения интенсивности отказов и сбоев за счет применения электронных схем и компонентов с высокой и сверхвысокой степенью интеграции, снижения уровня помех, облегченных режимов работы схем, обеспечение тепловых режимов их работы, а также за счет совершенствования методов сборки аппаратуры. Отказоустойчивость – это такое свойство вычислительной системы, которое обеспечивает ей как логической машине возможность продолжения действий, заданных программой, после возникновения неисправностей. Введение отказоустойчивости требует избыточного аппаратного и программного обеспечения. Направления, связанные с предотвращением неисправностей и отказоустойчивостью, основные в проблеме надежности. На параллельных вычислительных системах достигается как наиболее высокая производительность, так и, во многих случаях, очень высокая надежность. Имеющиеся ресурсы избыточности в параллельных системах могут гибко использоваться как для повышения производительности, так и для повышения надежности. Следует помнить, что понятие надежности включает не только аппаратные средства, но и программное обеспечение. Главной целью повышения надежности систем является целостность хранимых в них данных. Безопасность – одна из основных задач, решаемых любой нормальной компьютерной сетью. Проблему безопасности можно рассматривать с разных сторон – злонамеренная порча данных, конфиденциальность информации, несанкционированный доступ, хищения и т.п. Обеспечить защиту информации в условиях локальной сети всегда легче, чем при наличии на фирме десятка автономно работающих компьютеров. Практически в вашем распоряжении один инструмент – резервное копирование (backup). Для простоты давайте называть этот процесс резервированием. Суть его состоит в создании в безопасном месте полной копии данных, обновляемой регулярно и как можно чаще. Для персонального компьютера более или менее безопасным носителем служат дискеты. Возможно использование стримера, но это уже дополнительные затраты на аппаратуру. Важнейшей характеристикой вычислительных сетей является надежность. Повышение надежности основано на принципе предотвращения неисправностей путем снижения интенсивности отказов и сбоев за счет применения электронных схем и компонентов с высокой и сверхвысокой степенью интеграции, снижения уровня помех, облегченных режимов работы схем, обеспечение тепловых режимов их работы, а также за счет совершенствования методов сборки аппаратуры. Для сокращения стоимости линий связи в сетях обычно стремятся к сокращению количества проводов и из-за этого используют не параллельную передачу всех бит одного байта или даже нескольких байт, как это делается внутри компьютера, а последовательную, побитную передачу, требующую всего одной пары проводов. При использовании индивидуальных линий связи в полносвязных топологиях конечные узлы должны иметь по одному порту на каждую линию связи. В звездообразных топологиях конечные узлы могут подключаться индивидуальными линиями связи к специальному устройству - коммутатору. В глобальных сетях коммутаторы использовались уже на начальном этапе, а в локальных сетях - с начала 90-х годов. Коммутаторы приводят к существенному удорожанию локальной сети, поэтому пока их применение ограничено, но по мере снижения стоимости коммутации этот подход, возможно, вытеснит применение разделяемых линий связи. Необходимо подчеркнуть, что индивидуальными в таких сетях являются только линии связи между конечными узлами и коммутаторами сети, а связи между коммутаторами остаются разделяемыми, так как по ним передаются сообщения разных конечных узлов. Кабельные системы, повторители, мосты, коммутаторы, маршрутизаторы и модульные концентраторы из вспомогательных компонентов сети превратились в основные наряду с компьютерами и системным программным обеспечением как по влиянию на характеристики сети, так и по стоимости. Стремительный прогресс в области информационных технологий повлек за собой активное развитие сетевых структур. Глобальные и локальные компьютерные сети сегодня являются основой всех электронных коммуникаций. Они помогают государственным и коммерческим предприятиям автоматизировать свои бизнес-процессы, повышать эффективность работы сотрудников, сохранять конкурентоспособность и оптимизировать затраты. Чтобы развиваться и идти в ногу со временем, необходимо иметь современную и надежную информационную инфраструктуру — локальную вычислительную сеть (ЛВС), позволяющую создать единое информационное пространство организации. Грамотно спроектированная ЛВС предоставляет возможность сотрудникам оперативно обмениваться информацией и эффективно использовать программные и технические ресурсы компании — от принтеров, сканеров и других периферийных устройств до серверного оборудования, систем электронного документооборота и внутренних бизнес-приложений. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Экспертная система - это набор программ, выполняющий функции эксперта при решении задач из некоторой предметной области. Экспертные системы выдают советы, проводят анализ, дают консультации, ставят диагноз. Практическое применение экспертных систем на предприятиях способствует эффективности работы и повышению квалификации специалистов. Главным достоинством экспертных систем является возможность накопления знаний и сохранение их длительное время. В отличие от человека к любой информации экспертные системы подходят объективно, что улучшает качество проводимой экспертизы. Для принятия эффективных управленческих решений необходимо применение разнообразных инструментов анализа экономического состояния деятельности предприятий. С некоторой долей условности можно выделить три основных круга задач, требующих применения экономического анализа. Во-первых, это анализ финансового состояния. В нем заинтересованы, прежде всего, внешние по отношению к предприятию пользователи экономической информации – инвесторы, налоговые службы и т.д. Здесь основой анализа являются показатели, выводимые из данных стандартной бухгалтерской и статической отчетности, а также других открытых источников информации. Во-вторых, это задачи анализа, направленного на выработку стратегических управленческих решений по развитию бизнеса. Здесь информационная база шире, но все равно остается в рамках показателей регламентированной отчетности, характеризующих основные тенденции развития отдельного предприятия или корпорации. Третий круг задач анализа ориентирован на выработку тактических решений и является прерогативой служб оперативного управления. Его информационная база чрезвычайно широка и требует охвата большого количества частных, детализированных показателей, характеризующих различные стороны функционирования объекта управления. Вторая и третья группы аналитических задач требуют поиска путей создания информационных хранилищ, организованных по типу баз знаний. Знания – это высшая форма информации, определяющая зависимости, взаимосвязи и скрытые закономерности между различными явлениями, процессами и фактами. Базы знаний экономического анализа представляют собой основную компоненту экспертных систем и создаются путем структурирования и концептуализации знаний. В экспертных системах анализа для этого выявляется структура полученных знаний о предметной области, в нашем случае, экономическое состояние деятельности предприятий. При этом определяются:
Концептуализация знаний предполагает разработку неформального описания знаний о предметной области в виде графа, таблицы, диаграммы или текста, которые отражают основные концепции и взаимосвязи между понятиями предметной области. Такое описание называется полем знаний. Следующим шагом построения базы знаний является формализация. Строится формализованное представление концепций предметной области на основе выбранного языка представления знаний (ЯПЗ). Рейтинговый метод формирует интегральную оценку экономического состояния предприятия «снизу-вверх», реализуя дизъюнктивный подход к построению правил базы знаний. Метод последовательной декомпозиции обеспечивает диагностику экономического состояния предприятия «сверху-вниз», когда проблема последовательно разбивается на подпроблемы, пока не обнаружится требующая оперативного решения подпроблема. Выбор метода структурной организации базы знаний зависит от целей и глубины анализа. Рейтинговый метод и метод классификации ситуаций предназначены для внешнего анализа, дающего общую оценку экономического состояния предприятия. Результаты внешнего анализа предназначены для контролирующих органов, банков, контрагентов и других внешних организаций. Метод последовательной композиции направлен на поиск путей совершенствования деятельности предприятия за счет выявления узких мест и возможностей принятия эффективных управленческих решений. В определении основной цели финансового анализа большую роль играют экспертные оценки. Только опытные специалисты могут отобрать небольшое число ключевых (наиболее информативных) параметров, дающих объективную и точную картину финансового состояния предприятия, его прибылей и убытков, изменений в структуре активов и пассивов, в расчетах с дебиторами и кредиторами. При этом важно определить как текущее финансовое состояние предприятия, так и его проекцию на ближайшую или более отдаленную перспективу, то есть ожидаемые параметры финансового состояния. Эффективно организованная база знаний позволяет экспертным системам анализа экономического состояния предприятия успешно реализовать интеллектуальные функции, к которым относятся: интерпретация данных, диагностика, мониторинг, прогнозирование. Интерпретация данных. Это одна из традиционных задач для экспертных систем. Под интерпретацией понимается определение смысла данных, результаты которого должны быть согласованными и корректными. Диагностика. Под диагностикой понимается обнаружение отклонений от нормы. Мониторинг. Основная задача мониторинга – непрерывная интерпретация данных в реальном масштабе времени и сигнализация о выходе тех или иных параметров за допустимые пределы.. Прогнозирование. Прогнозирующие системы логически выводят вероятные следствия из заданных ситуаций. Архитектура экспертной системы экономического анализа (особенности формирования базы знаний, выбора методов логического вывода, пользовательского интерфейса) во многом зависит от целей и глубины анализа: внешнего (для сторонних организаций) или внутреннего (для самого предприятия). Целью внешнего анализа предприятия является определение общего состояния предприятия, т.е. интерпретация его экономического положения с точки зрения выявления возможностей эффективного взаимодействия с ним внешних организаций. Таким анализом занимаются банки при выдаче кредитов, инвесторы при размещении своего капитала, фирмы-партнеры при осуществлении закупочно-сбытовой или подрядной деятельности. Наиболее зарекомендовавшим себя методом внешнего анализа, интегрирующим множество различных экономических показателей предприятия, служит рейтинговый метод, который формирует «снизу-вверх» интегральную оценку финансового состояния предприятия. Примером экспертной системы внешнего анализа является система оценки кредитоспособности предприятия EvEnt (рис.3.1) [11], в которой общая оценка кредитоспособ-ности суммируется из оценок отдельных факторов с учетом их весовой значимости на общую оценку по формуле: Oi =∑(Wij∗Oij), j, где: Oij – оценка влияния j-го фактора на i-й вышестоящий фактор по некоторой число- вой шкале, Wij – вес (коэффициент) влияния j-го фактора на i-й фактор. В результате внедрения системы EvEnt для 80 % ситуаций решения формируются без экспертов. Если раньше на оценку предприятия экспертом банка требовалось в сред- нем 2-3 недели, то после внедрения экспертной системы основные затраты стали связы- ваться со сбором и вводом исходных данных в течение 2-3 дней, а собственно оценка предприятия занимает порядка 20 минут. При этом стоимость экспертизы в среднем со- кратилась с 10000 долларов до 1000 долларов. Примером применения декомпозиционного метода к построению экспертных систем служит система внутреннего финансового анализа FINEX
В случае применения экспертной системы внутреннего финансового анализа FINEX экспертиза осуществляется автоматически на основе введённых данных финансовой отчётности. При этом анализ финансовых показателей выполняется последовательно по принципу "сверху - вниз" и "слева - направо" в соответствии с деревом взаимосвязи показателей. В случае обнаружения некоторого "узкого места" (неудовлетворительного значения показателя) может быть включен диалоговый режим работы экспертной системы, в котором система последовательно опрашивает пользователя на предмет качественной оценки тех или иных процессов, причем вопросы задаются в порядке, зависящем от предыдущих ответов. Для проведения комплексного экономического анализа предприятия целесообразно комбинировать применение описанных выше методов к построению наборов правил. В МЭСИ разработан исследовательский прототип экспертной системы "Финансовый анализ предприятий" в среде интегрированного ППП Интерэксперт (GURU), реализующий и рейтинговый, и классификационный, и декомпозиционный методы анализа. Функциями экспертной системы финансового анализа предприятия являются:
В ходе ввода и проверки бухгалтерской отчетности осуществляется логический контроль зависимостей различных статей баланса предприятия, отчета о финансовых результатах и их использовании, справки к этому отчету и приложений к балансу. При этом правила логического контроля выполняются последовательно по декомпозиционному методу. Анализ финансового состояния предприятия предполагает комплексную рейтинговую и классификационную оценку платежеспособности и финансовой устойчивости предприятия. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Диаграммы переходов состояний (SDT) SDT демонстрирует поведение разрабатываемой программной системы при получении управляющих воздействий (извне). В диаграммах такого вида узлы соответствуют состояниям динамической системы, а дуги — переходу системы из одного состояния в другое. Узел, из которого выходит дуга, является начальным состоянием, узел, в который дуга входит, — следующим. Дуга помечается именем входного сигнала или события, вызывающего переход, а также сигналом или действием, сопровождающим переход.
На рис. 3.20 представлена диаграмма переходов состояний программы, активно не взаимодействующей с окружающей средой, которая имеет примитивный интерфейс, производит некоторые вычисления и выводит простой результат.
На рис. 3.21 представлена диаграмма переходов торгового автомата, активно взаимодействующего с покупателем.
Функциональные диаграммы Функциональными называют диаграммы, в первую очередь отражающие взаимосвязи функций разрабатываемого программного обеспечения. Они создаются на ранних этапах проектирования систем, для того чтобы помочь проектировщику выявить основные функции и составные части проектируемой системы и, по возможности, обнаружить и устранить существенные ошибки. Современные методы структурного анализа и проектирования предоставляют разработчику определенные синтаксические и графические средства проектирования функциональных диаграмм информационных систем. В качестве примера рассмотрим методологию SADT, предложенную Дугласом Россом. На ее основе разработана, в частности, известная методология IDEFO (Icam DEFinition). Методология SADT представляет собой набор методов, правил и процедур, предназначенных для построения функциональной модели объекта какой-либо предметной области. Функциональная модель SADT отображает функциональную структуру объекта, т. е. производимые им действия и связи между этими действиями. Основные элементы этой методологии основываются на следующих концепциях: • графическое представление блочного моделирования. На SADT-диаграмме функции представляются в виде блока, а интерфейсы входа-выхода — в виде дуг, соответственно входящих в блок и выходящих из него. Интерфейсные дуги отображают взаимодействие функций друг с другом; • строгость и точность отображения. Правила SADT включают: • уникальность меток и наименований; • ограничение количества блоков на каждом уровне декомпозиции; • синтаксические правила для графики; • связность диаграмм; • отделение организации от функции; • разделение входов и управлений. Методология SADT может использоваться для моделирования и разработки широкого круга систем, удовлетворяющих определенным "требованиям и реализующих требуемые функции. В уже разработанных системах методология SADT может быть использована для анализа выполняемых ими функций, а также для указания механизмов, посредством которых они осуществляются. Диаграммы — главные компоненты модели, все функции программной системы и интерфейсы на них представлены как блоки и дуги. Место соединения дуги с блоком определяет тип интерфейса. Дута, обозначающая управление, входит в блок сверху, в то время как информация, которая подвергается обработке, представляется дугой с левой стороны блока, а результаты обработки — дугами с правой стороны. Механизм (человек или автоматизированная система), который осуществляет операцию, представляется в виде дуги, входящей в блок снизу
Блоки на диаграмме размещают по «ступенчатой» схеме в соответствии с последовательностью их работы или доминированием, которое понимается как влияние, оказываемое одним блоком на другие. В функциональных диаграммах SADT различают пять типов влияний блоков друг на друга: • вход-выход блока подается на вход блока с меньшим доминированием, т. е. следующего • управление. Выход блока используется как управление для блока с меньшим доминированием • обратная связь по входу. Выход блока подается на вход блока с большим доминированием • обратная связь по управлению. Выход блока используется как управляющая информация для блока с большим доминированием • выход-исполнитель. Выход блока используется как механизм для другого блока Одной из наиболее важных особенностей методологии SADT является постепенное введение все больших уровней детализации по мере создания диаграмм, отображающих модель.
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
БИЛЕТ 8 |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Компью́терная гра́фика (также маши́нная графика) — область деятельности, в которой компьютеры используются в качестве инструмента, как для синтеза (создания) изображений, так и для обработки визуальной информации, полученной из реального мира. Двухмерная (2D — от англ. two dimensions — «два измерения») компьютерная графика классифицируется по типу представления графической информации, и следующими из него алгоритмами обработки изображений. Обычно компьютерную графику разделяют на векторную и растровую, хотя обособляют ещё и фрактальный тип представления изображений. Векторная графика Пример векторного рисунка Векторная графика представляет изображение как набор геометрических примитивов. Обычно в качестве них выбираются точки, прямые, окружности, прямоугольники, а также, как общий случай, кривые некоторого порядка. Объектам присваиваются некоторые атрибуты, например, толщина линий, цвет заполнения. Рисунок хранится как набор координат, векторов и других чисел, характеризующих набор примитивов. При воспроизведении перекрывающихся объектов имеет значение их порядок. Изображение в векторном формате даёт простор для редактирования. Изображение может без потерь масштабироваться, поворачиваться, деформироваться, также имитация трёхмерности в векторной графике проще, чем в растровой. Дело в том, что каждое такое преобразование фактически выполняется так: старое изображение (или фрагмент) стирается, и вместо него строится новое. Математическое описание векторного рисунка остаётся прежним, изменяются только значения некоторых переменных, например, коэффициентов. При преобразовании растровой картинки исходными данными является только описание набора пикселей, поэтому возникает проблема замены меньшего числа пикселей на большее (при увеличении, или большего на меньшее (при уменьшении). Простейшим способом является замена одного пикселя несколькими того же цвета (метод копирования ближайшего пикселя: Nearest Neighbour). Более совершенные методы используют алгоритмы интерполяции, при которых новые пиксели получают некоторый цвет, код которого вычисляется на основе кодов цветов соседних пикселей. Подобным образом выполняется масштабирование в программе Adobe Photoshop (билинейная и бикубическая интерполяция). Вместе с тем, не всякое изображение можно представить как набор из примитивов. Такой способ представления хорош для схем, используется для масштабируемых шрифтов, деловой графики, очень широко используется для создания мультфильмов и просто роликов разного содержания. Растровая графика Растровая графика всегда оперирует двумерным массивом (матрицей) пикселей. Каждому пикселю сопоставляется значение яркости, цвета, прозрачности — или комбинация этих значений. Растровый образ имеет некоторое число строк и столбцов. Без особых потерь растровые изображения можно только лишь уменьшать, хотя некоторые детали изображения тогда исчезнут навсегда, что иначе в векторном представлении. Увеличение же растровых изображений оборачивается «красивым» видом на увеличенные квадраты того или иного цвета, которые раньше были пикселями. В растровом виде представимо любое изображение, однако этот способ хранения имеет свои недостатки: больший объём памяти, необходимый для работы с изображениями, потери при редактировании. Фрактальная графика Фрактал — объект, отдельные элементы которого наследуют свойства родительских структур. Поскольку более детальное описание элементов меньшего масштаба происходит по простому алгоритму, описать такой объект можно всего лишь несколькими математическими уравнениями. Фракталы позволяют описывать целые классы изображений, для детального описания которых требуется относительно мало памяти. С другой стороны, фракталы слабо применимы к изображениям вне этих классов. Трёхмерная графика (3D — от англ. three dimensions — «три измерения») оперирует с объектами в трёхмерном пространстве. Обычно результаты представляют собой плоскую картинку, проекцию. Трёхмерная компьютерная графика широко используется в кино, компьютерных играх. Трехмерная графика бывает полигональной и воксельной. Воксельная графика, аналогична растровой. Объект состоит из набора трехмерных фигур, чаще всего кубов. А в полигональной компьютерной графике все объекты обычно представляются как набор поверхностей, минимальную поверхность называют полигоном. В качестве полигона обычно выбирают треугольники. Всеми визуальными преобразованиями в векторной (полигональной) 3D-графике управляют матрицы (см. также: аффинное преобразование в линейной алгебре). В компьютерной графике используется три вида матриц: - матрица поворота - матрица сдвига - матрица масштабирования Любой полигон можно представить в виде набора из координат его вершин. Так, у треугольника будет 3 вершины. Координаты каждой вершины представляют собой вектор (x, y, z). Умножив вектор на соответствующую матрицу, мы получим новый вектор. Сделав такое преобразование со всеми вершинами полигона, получим новый полигон, а преобразовав все полигоны, получим новый объект, повёрнутый/сдвинутый/масштабированный относительно исходного. Материальной основой любой САПР является программно-технический комплекс, включающий в себя технические и программно-методические средства. Технические средства САПР содержат следующие согласованные между собой элементы: устройства ввода информации в виде различного периферийного оборудования ЭВМ (дисплеи, cчитыватели графической информации, ввод с различных носителей информации); устройства хранения информации (внешние запоминающие устройства ЭВМ); устройства переработки информации (программное обеспечение и центральные процессоры ЭВМ); устройства отображения и вывода информации в удобной для проектировщика форме (чертежный автомат, дисплей, печатающие устройства); устройства управления процессами обработки информации при проектировании. Программно-методические средства включают в себя пакеты программ, базы данных и документацию по эксплуатации САПР. Функциональными составляющими САПР являются проектирующие и обслуживающие подсистемы. К первым из них относятся подсистемы, предназначенные для выполнения операций проектирования отдельных частей объекта или определенных стадий проектирования (например, подсистема выполнения расчетов). Обслуживающими называют подсистемы, обеспечивающие функционирование проектирующих подсистем. Это информационно-поисковая, подсистема графического отображения объектов, формирования документов и др. Проектирующие подсистемы САПР в большинстве случаев являются объектно-ориентированными, т. е. применимыми только для данного вида проектируемых объектов. Обслуживающие подсистемы чаще всего выполняют инвариантными, объектно-независимыми. Перечисленные подсистемы САПР обладают всеми свойствами систем, т. е. могут функционировать самостоятельно и подвергаться декомпозиции на составляющие элементы, которые принято называть компонентами САПР. В отечественной литературе обычно выделяют следующие обязательные компоненты САПР: методическое обеспечение, содержащее комплекс документов описания САПР, данные о составе, правила обслуживания и использования; лингвистическое обеспечение — совокупность специальных проблемно-ориентированных языков проектирования; математическое обеспечение — совокупность математических методов, моделей, алгоритмов, необходимых для выполнения проектных процедур; программное обеспечение — комплекс всех программ и эксплуатационной документации к ним; техническое обеспечение — совокупность всех технических средств, используемых при автоматизированном проектировании, диагностике и ремонте вычислительной техники; информационное обеспечение — совокупность информации, используемой проектировщиком непосредственно для получения проектных решений и содержащейся в машинных банках данных или в иных документах; организационное обеспечение — комплект документов, устанавливающих правила выполнения проектирования, в том числе: правила выпуска, корректирования и использования выходных документов, правила доступа к базам данных, приоритеты использования средств САПР, порядок взаимодействия всех проектирующих и обслуживающих подразделений. При разработке САПР, их подсистем и компонентов учитывают несколько основополагающих принципов: - принцип системного единства и совместимости, предполагающий взаимосвязь и взаимодействие подсистем в процессе функционирования САПР, стремление к достижению единой цели системы; - принцип развития, предусматривающий возможность пополнения и обновления подсистем и компонентов САПР; - принцип оптимального распределения процессов преобразования информации (задач проектирования) между человеком и ЭВМ с учетом возможностей их взаимодействия; - принцип унификации компонентов и инвариантности их по отношению к широкому кругу проектируемых объектов; - принцип смежности этапов проектирования, согласно которому выходная информация одного этапа проектирования является исходной для последующего (конвейерная обработка информации); - блочно-иерархический принцип построения подсистем САПР, естественно вытекающий из иерархического характера процесса проектирования. Перечисленные принципы позволили создать и успешно эксплуатировать системы автоматизированного проектирования, их подсистемы и элементы в различных областях проектной деятельности. Говоря о разработке и внедрении САПР, необходимо подчеркнуть динамичный, развивающийся характер автоматизации проектных работ. На ранних стадиях осуществляется привлечение машинных методов и средств к выполнению рутинных, повторяющихся операций. Далее разрабатываются модели и программы для решения с помощью ЭВМ частных проектных задач, создается некая взаимосвязанная система. Эта система расширяется и постепенно охватывает задачи все более высокого уровня формализации вплоть до задач, связанных с творческой стороной процесса проектирования. Наиболее сложным этапом создания САПР, определяющим при прочих равных условиях эффективность системы в целом, является разработка математического обеспечения. Несмотря на то что в явном виде этот компонент в автоматизированном проектировании не используется (используют производный компонент — программное обеспечение), его роль и значение трудно переоценить. В зависимости от назначения и способа реализации в математическом обеспечении выделяют две взаимосвязанные части. К первой относят математические методы и модели, описывающие объекты проектирования или их элементы и отражающие их специфику. Вторая часть включает в себя формализованное описание технологии автоматизированного проектирования и носит инвариантный или достаточно обобщенный характер по отношению к конкретному объекту. Разработка вопросов, относящихся ко второй части математического обеспечения, представляет собой сложную задачу в связи с необходимостью отражения в них всей логики технологии проектирования, включая творческие, слабо формализованные ее элементы. Развитие математического обеспечения САПР происходит по двум базовым направлениям: разработка и совершенствование методов получения оптимальных проектных решений в условиях автоматизированного проектирования; совершенствование и типизация процессов и элементов автоматизированного проектирования, инвариантных по отношению к объекту проектирования. Точные математические методы поиска оптимальных проектных решений малодоступны. Поэтому, как уже говорилось, эту задачу часто решают на основе использования банков (фондов) знаний и типовых эвристических методов. При оценке эффективности автоматизированного проектирования необходимо учитывать не только экономическую сторону вопроса, связанную с оценкой затрат, но и такие аспекты проблемы, как повышение качества проектного решения, большая глубина проработки проектной ситуации, более высокая вероятность получения принципиально новых решений, социальная сторона автоматизации умственной деятельности. К настоящему времени САПР и ее подсистемы широко используются при решении различных проектных задач. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Для решения задач обработки данных используются различные статистические методы: проверка гипотез, оценивание параметров и числовых характеристик случайных величин и процессов, корреляционный и дисперсионный анализ. Чтобы решение задачи было проведено качественно, необходимо провести предварительную обработку данных, для того чтобы не возвращаться повторно к решению той или иной задачи после получения результатов на последующем этапе обработки. Чтобы понять, с помощью, какой программы, или каким методом проводить обработку данных, необходимо помнить, что при наблюдении и проведении эксперимента встречаются ошибки грубые, систематические и случайные. В зависимости от точности и сложности эксперимента выбираются и методы обработки данных. Если эксперимент не предполагает особой точности и сложности можно выбрать простую программу и провести статистическую обработку, если же необходима высокая точность измерения, то и программу необходимо выбирать более сложную. Другими словами технология обработки экспериментальных данных зависит от того результата, к которому Вы стремитесь. Обработке экспериментальных данных с целью построения моделей «сложных систем» (эмпирических зависимостей) должна предшествовать предварительная обработка, содержание которой, в основном, состоит в отсеивании грубых погрешностей измерений и в проверке соответствия распределения результатов нормальному закону. Следует помнить, что только после выполнения предварительной обработки можно с наибольшей эффективностью, а главное корректно, использовать более сложные экспериментально-статистические методы, позволяющие получать математические модели даже таких процессов, строгое детерминированное описание которых вообще отсутствует. Все методы количественной обработки принято подразделять на первичные и вторичные. Первичная статистическая обработка нацелена на упорядочивание информации об объекте и предмете изучения. На этой стадии «сырые» сведения группируются по тем или иным критериям, заносятся в сводные таблицы. Первично обработанные данные, представленные в удобной форме, дают исследователю в первом приближении понятие о характере всей совокупности данных в целом: об их однородности – неоднородности, компактности – разбросанности, четкости – размытости и т. д. Эта информация хорошо считывается с наглядных форм представления данных и дает сведения об их распределении. В ходе применения первичных методов статистической обработки получаются показатели, непосредственно связанные с производимыми в исследовании измерениями. К основным методам первичной статистической обработки относятся: вычисление мер центральной тенденции и мер разброса (изменчивости) данных. Первичный статистический анализ всей совокупности полученных в исследовании данных дает возможность охарактеризовать ее в предельно сжатом виде и ответить на два главных вопроса: 1) какое значение наиболее характерно для выборки; 2) велик ли разброс данных относительно этого характерного значения, т. е. какова «размытость» данных. Для решения первого вопроса вычисляются меры центральной тенденции, для решения второго – меры изменчивости (или разброса). Эти статистические показатели используются в отношении количественных данных, представленных в порядковой, интервальной или пропорциональной шкале. Меры центральной тенденции – это величины, вокруг которых группируются остальные данные. Данные величины являются как бы обобщающими всю выборку показателями, что, во-первых, позволяет судить по ним обо всей выборке, а во-вторых, дает возможность сравнивать разные выборки, разные серии между собой. К мерам центральной тенденции в обработке результатов психологических исследований относятся: выборочное среднее, медиана, мода. Выборочное среднее (М) – это результат деления суммы всех значений (X) на их количество (N).
Медиана (Me) – это значение, выше и ниже которого количество отличающихся значений одинаково, т. е. это центральное значение в последовательном ряду данных. Медиана не обязательно должна совпадать с конкретным значением. Совпадение происходит в случае нечетного числа значений (ответов), несовпадение – при четном их числе. В последнем случае медиана вычисляется как среднее арифметическое двух центральных значений в упорядоченном ряду. Мода (Мо) – это значение, наиболее часто встречающееся в выборке, т. е. значение с наибольшей частотой. Если все значения в группе встречаются одинаково часто, то считается, что моды нет. Если два соседних значения имеют одинаковую частоту и больше частоты любого другого значения, мода есть среднее этих двух значений. Если то же самое относится к двум несмежным значениям, то существует две моды, а группа оценок является бимодальной. Обычно выборочное среднее применяется при стремлении к наибольшей точности в определении центральной тенденции. Медиана вычисляется в том случае, когда в серии есть «нетипичные» данные, резко влияющие на среднее. Мода используется в ситуациях, когда не нужна высокая точность, но важна быстрота определения меры центральной тенденции. Вычисление всех трех показателей производится также для оценки распределения данных. При нормальном распределении значения выборочного среднего, медианы и моды одинаковы или очень близки. Меры разброса (изменчивости) – это статистические показатели, характеризующие различия между отдельными значениями выборки. Они позволяют судить о степени однородности полученного множества, его компактности, а косвенно и о надежности полученных данных и вытекающих из них результатов. Наиболее используемые в психологических исследованиях показатели: среднее отклонение, дисперсия, стандартное отклонение. Размах (Р) – это интервал между максимальным и минимальным значениями признака. Определяется легко и быстро, но чувствителен к случайностям, особенно при малом числе данных. Среднее отклонение (МД) – это среднеарифметическое разницы (по абсолютной величине) между каждым значением в выборке и ее средним.
где d = |Х – М |, М – среднее выборки, X – конкретное значение, N – число значений. Множество всех конкретных отклонений от среднего характеризует изменчивость данных, но если не взять их по абсолютной величине, то их сумма будет равна нулю и мы не получим информации об их изменчивости. Среднее отклонение показывает степень скученности данных вокруг выборочного среднего. Кстати, иногда при определении этой характеристики выборки вместо среднего (М) берут иные меры центральной тенденции – моду или медиану. Дисперсия (D) характеризует отклонения от средней величины в данной выборке. Вычисление дисперсии позляет избежать нулевой суммы конкретных разниц (d = Х – М) не через их абсолютные величины, а через их возведение в квадрат:
где d = |Х – М|, М – среднее выборки, X – конкретное значение, N – число значений. Стандартное отклонение (б). Из-за возведения в квадрат отдельных отклонений d при вычислении дисперсии полученная величина оказывается далекой от первоначальных отклонений и потому не дает о них наглядного представления. Чтобы этого избежать и получить характеристику, сопоставимую со средним отклонением, проделывают обратную математическую операцию – из дисперсии извлекают квадратный корень. Его положительное значение и принимается за меру изменчивости, именуемую среднеквадратическим, или стандартным, отклонением:
где d = |Х– М|, М – среднее выборки, X– конкретное значение, N – число значений. МД, D и б применимы для интервальных и пропорционных данных. Для порядковых данных в качестве меры изменчивости обычно берут полуквартильное отклонение (Q), именуемое еще полуквартильным коэффициентом. Вычисляется этот показатель следующим образом. Вся область распределения данных делится на четыре равные части. Если отсчитывать наблюдения начиная от минимальной величины на измерительной шкале, то первая четверть шкалы называется первым квартилем, а точка, отделяющая его от остальной части шкалы, обозначается символом Q.1Вторые 25 % распределения – второй квартиль, а соответствующая точка на шкале – Q2. Между третьей и четвертой четвертями распределения расположена точка Q3. Полуквартильный коэффициент определяется как половина интервала между первым и третьим квартилями:
При симметричном распределении точка Q2 совпадет с медианой (а, следовательно, и со средним), и тогда можно вычислить коэффициент Q для характеристики разброса данных относительно середины распределения. При несимметричном распределении этого недостаточно. Тогда дополнительно вычисляют коэффициенты для левого и правого участков:
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Телекоммуникация - это связь при помощи электронного оборудования такого, как телефоны, компьютерные модемы, спутники и волоконно-оптические кабели. Телекоммуникационные системы включают в себя телекоммуникационные кабели от абонента до местных коммутаторов (местные линии), коммутационные средства, которые обеспечивают коммуникационное соединение с абонентом, с линиями или каналами, которые передают вызовы между коммутаторами и, естественно, абонентом. Глобальная компьютерная сеть, ГКС (англ. Wide Area Network, WAN) — компьютерная сеть, охватывающая большие территории и включающая в себя большое число компьютеров. ГКС служат для объединения разрозненных сетей так, чтобы пользователи и компьютеры, где бы они ни находились, могли взаимодействовать со всеми остальными участниками глобальной сети. Некоторые ГКС построены исключительно для частных организаций, другие являются средством коммуникации корпоративных ЛВС с сетью Интернет или посредством Интернет с удалёнными сетями, входящими в состав корпоративных. Чаще всего ГКС опирается на выделенные линии, на одном конце которых маршрутизатор подключается к ЛВС, а на другом коммутатор связывается с остальными частями ГКС. Основными используемыми протоколами являются TCP/IP, SONET/SDH, MPLS, ATM и Frame relay. Ранее был широко распространён протокол X.25, который может по праву считаться прародителем Frame relay. Спутниковое телевидение — система передачи телевизионного сигнала от передающего центра к потребителю, использующая в качестве ретранслятораискусственные спутники Земли, расположенные в космосе на геостационарной (ранее и на других видах орбит[1][2]) околоземной орбите над экватором, и оснащенные приемопередающим оборудованием. По сравнению с эфирным наземным телевидением, обеспечивает покрытие качественным телевизионным сигналом больших территорий, труднодоступных для ретрансляции обычным способом. Для приема сигнала спутникового телевидения требуется специальное оборудование. Стандартный комплект состоит из спутниковой антенны, кронштейна (крепление антенны к стене или крыше), конвертера, кабеля и спутникового ресивера (спутникового приемника), последний может быть встроен в телевизор или исполнен в виде компьютерной платы. Для просмотра спутниковых телеканалов с помощью ресивера используется телевизор или монитор компьютера (через специальную встроенную DVB-S-карту). Аналоговое спутниковое телевидение транслируется в системах цветного телевещания NTSC, PAL или SECAM. В настоящее время во всех странах мира аналоговое спутниковое телевидение практически полностью заменено цифровым. Цифровое спутниковое телевидение транслируется в стандартах DVB-S, DVB-S2. В цифровом спутниковом телевидении используются стандарты сжатия видео MPEG-2 и MPEG-4. Цифровой телевизионный сигнал или мультиплексированый сигнал обычно модулируется QPSK или 8SPK. По степени доступности спутниковое телевидение делится на свободное (FTA - аббревиатура англ. free to air) и кодированное.Система условного доступа включает в себя кодировки: BISS, Conax, DigiCipher, Irdeto, Irdeto 2, Nagravision, PowerVu, Viaccess и др. В настоящее время использование цифрового спутникового оборудования позволяет получать изображение высокого цифрового качества, вплоть до HDTV (1080i) и 3D-TV (DVB 3D-TV). Операторы спутникового телевидения (DTH), как правило, предоставляют своим клиентам несколько пакетов телеканалов в зависимости от их вкусов и финансовых возможностей. Сотовая связь, сеть подвижной связи — один из видов мобильной радиосвязи, в основе которого лежит сотовая сеть. Ключевая особенность заключается в том, что общая зона покрытия делится на ячейки (соты), определяющиеся зонами покрытия отдельных базовых станций (БС). Соты частично перекрываются и вместе образуют сеть. На идеальной (ровной и без застройки) поверхности зона покрытия одной БС представляет собой круг, поэтому составленная из них сеть имеет вид шестиугольных ячеек (сот). Сеть составляют разнесённые в пространстве приёмопередатчики, работающие в одном и том же частотном диапазоне, и коммутирующее оборудование, позволяющее определять текущее местоположение подвижных абонентов и обеспечивать непрерывность связи при перемещении абонента из зоны действия одного приёмопередатчика в зону действия другого. Основные составляющие сотовой сети — это сотовые телефоны и базовые станции, которые обычно располагают на крышах зданий и вышках. Будучи включённым, сотовый телефон прослушивает эфир, находя сигнал базовой станции. После этого телефон посылает станции свой уникальный идентификационный код. Телефон и станция поддерживают постоянный радиоконтакт, периодически обмениваясь пакетами. Связь телефона со станцией может идти по аналоговому протоколу (AMPS,NAMPS, NMT-450) или по цифровому (DAMPS, CDMA, GSM, UMTS). Если телефон выходит из поля действия базовой станции (или качество радиосигнала сервисной соты ухудшается), он налаживает связь с другой (англ. handover). Сотовые сети могут состоять из базовых станций разного стандарта, что позволяет оптимизировать работу сети и улучшить её покрытие. Сотовые сети разных операторов соединены друг с другом, а также со стационарной телефонной сетью. Это позволяет абонентам одного оператора делать звонки абонентам другого оператора, с мобильных телефонов на стационарные и со стационарных на мобильные. Операторы могут заключать между собой договоры роуминга. Благодаря таким договорам абонент, находясь вне зоны покрытия своей сети, может совершать и принимать звонки через сеть другого оператора. Как правило, это осуществляется по повышенным тарифам. Возможность роуминга появилась лишь в стандартах 2G и является одним из главных отличий от сетей 1G.[1] Операторы могут совместно использовать инфраструктуру сети, сокращая затраты на развертывание сети и текущие издержки. Глобальные вычислительные сети Wide Area Networks (WAN), которые относятся к территориальным компьютерными сетями, предназначены, как и ЛВС для предоставления услуг, но значительно большему количеству пользователей, находящихся на большой территории. Глобальные вычислительные сети - это компьютерные сети, объединяющие локальные сети и отдельные компьютеры, удаленные друг от друга на большие расстояния. Самая известная и популярная глобальная сеть - это Интернет. Кроме того, к глобальным вычислительным сетям относятся: всемирная некоммерческая сеть FidoNet, CREN, EARNet, EUNet и другие глобальные сети, в том числе и корпоративные. Из-за большой протяженности каналов связи построение требует очень больших затрат, поэтому глобальные сети чаще всего создаются крупными телекоммуникационными компаниями для оказания платных услуг абонентам. Такие сети называют общественными или публичными. Но в некоторых случаях WAN создаются как частные сети крупных корпораций. В глобальных сетях для передачи информации применяются следующие виды коммутации:
Большой интерес представляет глобальная информационная сеть Интернет. Интернет объединяет множество различных компьютерных сетей (локальных, корпоративных, глобальных) и отдельных компьютеров, которые обмениваются между собой информацией по каналам общественных телекоммуникаций. Наземные радиорелейные линии не могут в полной мере удовлетворить обмен радиовещательных и телевизионных программ, особенно если они сильно удалены друг от друга. Между ретрансляторами не может быть больших расстояний, поэтому размещение наземных ретрансляторов связано со значительными техническими и экономическими сложностями, а связь через океаны и труднодоступные территории просто невозможна. От этих недостатков свободны спутниковые системы связи (ССС). Они могут ретранслировать сигналы с высоты в десятки тысяч километров. ССС обладают высокой пропускной способностью и позволяют обеспечить экономичную круглосуточную связь между любыми оконечными пунктами, обмен радиовещательными и телевизионными программами, одновременную работу без взаимных помех большого числа линий. В основе построения спутниковой системы связи лежит идея размещения ретранслятора на космическом аппарате (КА). Движение КА длительное время происходит без затрат энергии, а энергоснабжение всех систем осуществляется от солнечных батарей. КА, находящийся на достаточно высокой орбите, способен охватить очень большую территорию около трети поверхности Земли. Через его бортовой ретранслятор могут связываться любые станции, находящиеся на этой территории. Принцип спутниковой связи заключается в ретрансляции аппаратурой спутника сигнала от передающих наземных станций к приёмникам. МОБИЛЬНАЯ СВЯЗЬ – вид телекоммуникаций, при котором голосовая, текстовая и графическая информация передается на абонентские беспроводные терминалы, не привязанные к определенному месту или территории. Различаются спутниковая, сотовая, транкинговая и др. виды мобильной связи. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Диаграммы потоков данных Основой данной методологии графического моделирования информационных систем является специальная технология построения диаграмм потоков данных DFD. В разработке методологии DFD приняли участие многие аналитики, среди которых следует отметить Э. Йордона (Е. Yourdon). Он является автором одной из первых графических нотаций DFD [10]. В настоящее время наиболее распространенной является так называемая нотация Гейна-Сарсона (Gene-Sarson), основные элементы которой будут рассмотрены в этом разделе. Модель системы в контексте DFD представляется в виде некоторой информационной модели, основными компонентами которой являются различные потоки данных, которые переносят информацию от одной подсистемы к другой. Каждая из подсистем выполняет определенные преобразования входного потока данных и передает результаты обработки информации в виде потоков данных для других подсистем. Основными компонентами диаграмм потоков данных являются: • внешние сущности • накопители данных или хранилища • процессы • потоки данных • системы/подсистемы Внешняя сущность представляет собой материальный объект или физическое лицо, которые могут выступать в качестве источника или приемника информации. Определение некоторого объекта или системы в качестве внешней сущности не является строго фиксированным. Хотя внешняя сущность находится за пределами границ рассматриваемой системы, в процессе дальнейшего анализа некоторые внешние сущности могут быть перенесены внутрь диаграммы модели системы. С другой стороны, отдельные процессы могут быть вынесены за пределы диаграммы и представлены как внешние сущности. Примерами внешних сущностей могут служить: клиенты организации, заказчики, персонал, поставщики. Внешняя сущность обозначается прямоугольником с тенью, внутри которого указывается ее имя. При этом в качестве имени рекомендуется использовать существительное в именительном падеже. Иногда внешнюю сущность называют также терминатором.
Процесс представляет собой совокупность операций по преобразованию входных потоков данных в выходные в соответствии с определенным алгоритмом или правилом. Хотя физически процесс может быть реализован различными способами, наиболее часто подразумевается программная реализация процесса. Процесс на диаграмме потоков данных изображается прямоугольником с закругленными вершинами (рис. 2.16), разделенным на три секции или поля горизонтальными линиями. Поле номера процесса служит для идентификации последнего. В среднем поле указывается имя процесса. В качестве имени рекомендовано использовать глагол в неопределенной форме с необходимыми дополнениями. Нижнее поле содержит указание на способ физической реализации процесса.
Рис. 2.16. Изображение процесса на диаграмме потоков данных
Рис. 2.17. Изображение подсистемы на диаграмме потоков данных Информационная модель системы строится как некоторая иерархическая схема в виде так называемой контекстной диаграммы, на которой исходная модель последовательно представляется в виде модели подсистем соответствующих процессов преобразования данных. При этом подсистема или система на контекстной диаграмме DFD изображается так же, как и процесс – прямоугольником с закругленными вершинами (рис. 2.17). Накопитель данных или хранилище представляет собой абстрактное устройство или способ хранения информации, перемещаемой между процессами. Предполагается, что данные можно в любой момент поместить в накопитель и через некоторое время извлечь, причем физические способы помещения и извлечения данных могут быть произвольными. Накопитель данных может быть физически реализован различными способами, но наиболее часто предполагается его реализация в электронном виде на магнитных носителях. Накопитель данных на диаграмме потоков данных изображается прямоугольником с двумя полями (рис. 2.18). Первое поле служит для указания номера или идентификатора накопителя, который начинается с буквы "D". Второе поле служит для указания имени. При этом в качестве имени накопителя рекомендуется использовать существительное, которое характеризует способ хранения соответствующей информации.
Рис. 2.18. Изображение накопителя на диаграмме потоков данных Наконец, поток данных определяет качественный характер информации, передаваемой через некоторое соединение от источника к приемнику. Реальный поток данных может передаваться по сети между двумя компьютерами или любым другим способом, допускающим извлечение данных и их восстановление в требуемом формате. Поток данных на диаграмме DFD изображается линией со стрелкой на одном из ее концов, при этом стрелка показывает направление потока данных. Каждый поток данных имеет свое собственное имя, отражающее его содержание. Таким образом, информационная модель системы в нотации DFD строится в виде диаграмм потоков данных, которые графически представляются с использованием соответствующей системы обозначений. В качестве примера рассмотрим упрощенную модель процесса получения некоторой суммы наличными по кредитной карточке клиентом банка. Внешними сущностями данного примера являются клиент банка и, возможно, служащий банка, который контролирует процесс обслуживания клиентов. Накопителем данных может быть база данных о состоянии счетов отдельных клиентов банка. Отдельные потоки данных отражают характер передаваемой информации, необходимой для обслуживания клиента банка. Соответствующая модель для данного примера может быть представлена в виде диаграммы потоков данных (рис. 2.19). В настоящее время диаграммы потоков данных используются в некоторых CASE-средствах для построения информационных моделей систем обработки данных. Основной недостаток этой методологии также связан с отсутствием явных средств для объектно-ориентированного представления моделей сложных систем, а также для представления сложных алгоритмов обработки данных. Поскольку на диаграммах DFD не указываются характеристики времени выполнения отдельных процессов и передачи данных между процессами, то модели систем, реализующих синхронную обработку данных, не могут быть адекватно представлены в нотации DFD. Все эти особенности методологии структурного системного анализа ограничили возможности ее широкого применения и послужили основой для включения соответствующих средств в унифицированный язык моделирования.
Диаграмма компонентов (component diagram) Полный проект программной системы представляет собой совокупность моделей логического и физического уровней, которые должны быть согласованы между собой. В языке UML для физического представления моделей систем используются диаграммы реализации (implementation diagrams), которые включают в себя диаграмму компонентов и диаграмму развертывания. Диаграмма компонентов, в отличие от ранее рассмотренных диаграмм, описывает особенности физического представления системы. Она позволяет определить архитектуру разрабатываемой системы, установив зависимости между программными компонентами, в роли которых может выступать исходный и исполняемый код. Основными графическими элементами диаграммы компонентов являются компоненты, интерфейсы и зависимости между ними. Диаграмма компонентов разрабатывается для следующих целей:
В разработке диаграмм компонентов участвуют как системные аналитики и архитекторы, так и программисты. Диаграмма компонентов обеспечивает согласованный переход от логического представления к конкретной реализации проекта в форме программного кода. Одни компоненты могут существовать только на этапе компиляции программного кода, другие на этапе его исполнения. Диаграмма компонентов отражает общие зависимости между компонентами, рассматривая последние в качестве классификаторов. Компоненты Для представления физических сущностей в языке UML применяется специальный термин - компонент (component). Компонент реализует некоторый набор интерфейсов и служит для общего обозначения элементов физического представления модели. Для графического представления компонента используется специальный символ - прямоугольник со вставленными слева двумя более мелкими прямоугольниками. Внутри большого прямоугольника записывается имя компонента и, при необходимости, некоторая дополнительная информация. Изображение этого символа может незначительно варьироваться в зависимости от характера ассоциируемой с компонентом информации. Имя компонента подчиняется общим правилам именования элементов модели в языке UML и может состоять из любого числа букв, цифр и некоторых знаков препинания. Отдельный компонент может быть представлен на уровне типа или на уровне экземпляра. Графическое изображение в обоих случаях одинаковое, но правила записи имени компонента отличаются. Если компонент представляется на уровне типа, то в качестве его имени записывается только имя типа с заглавной буквы. Если же компонент представляется на уровне экземпляра, то в качестве его имени записывается <имя компонента>':'<имя типаХ>. При этом вся строка имени подчеркивается. В качестве простых имен принято использовать имена исполняемых файлов (с указанием расширения ехе после точки-разделителя), динамических библиотек (расширение dll), Web-страниц (расширение html), текстовых файлов (расширения txt или doc) или файлов справки (hip), файлов баз данных (DB) или файлов с исходными текстами программ (расширения h, cpp для языка C++, расширение java для языка Java), скрипты (pi, asp) и другие. Поскольку конкретная реализация логического представления модели системы зависит от используемого программного инструментария, то и имена компонентов определяются особенностями синтаксиса соответствующего языка программирования. В отдельных случаях к простому имени компонента может быть добавлена информация об имени объемлющего пакета и о конкретной версии реализации данного компонента. В этом случае номер версии записывается как помеченное значение в фигурных скобках. В других случаях символ компонента может быть разделен на секции, чтобы явно указать имена реализованных в нем интерфейсов. Поскольку компонент как элемент физической реализации модели представляет отдельный модуль кода, иногда его комментируют с указанием дополнительных графических символов, иллюстрирующих конкретные особенности его реализации. Эти дополнительные обозначения для примечаний не специфицированы в языке UML, однако их применение упрощает понимание диаграммы компонентов, повышая наглядность физического представления. В языке UML выделяют три вида компонентов:
Эти элементы иногда называют артефактами, подчеркивая при этом их законченное информационное содержание, зависящее от конкретной технологии реализации соответствующих компонентов. Другим способом спецификации различных видов компонентов является явное указание его стереотипа компонента перед именем. В языке UML для компонентов определены следующие стереотипы:
Интерфейсы Следующим элементом диаграммы компонентов являются интерфейсы. В общем случае, интерфейс графически изображается окружностью, которая соединяется с компонентом отрезком линии без стрелок. Имя интерфейса должно начинаться с заглавной буквы "I" и записываться рядом с окружностью. Семантически линия означает реализацию интерфейса, а наличие интерфейсов у компонента означает, что данный компонент реализует соответствующий набор интерфейсов. Другим способом представления интерфейса на диаграмме компонентов является его изображение в виде прямоугольника класса со стереотипом «интерфейс» и возможными секциями атрибутов и операций. Как правило, этот вариант обозначения используется для представления внутренней структуры интерфейса, которая может быть важна для реализации. При разработке программных систем интерфейсы обеспечивают не только совместимость различных версий, но и возможность вносить существенные изменения в одни части программы, не изменяя другие ее части. Таким образом, назначение интерфейсов существенно шире, чем спецификация взаимодействия с пользователями системы (актерами). Зависимости В общем случае отношение зависимости также было рассмотрено ранее. Напомним, что зависимость не является ассоциацией, а служит для представления только факта наличия такой связи, когда изменение одного элемента модели оказывает влияние или приводит к изменению другого элемента модели. Отношение зависимости на диаграмме компонентов изображается пунктирной линией со стрелкой, направленной от клиента (зависимого элемента) к источнику (независимому элементу). Зависимости могут отражать связи модулей программы на этапе компиляции и генерации объектного кода. В другом случае зависимость может отражать наличие в независимом компоненте описаний классов, которые используются в зависимом компоненте для создания соответствующих объектов. Применительно к диаграмме компонентов зависимости могут связывать компоненты и импортируемые этим компонентом интерфейсы, а также различные виды компонентов между собой. В первом случае рисуют стрелку от компонента-клиента к импортируемому интерфейсу. Наличие стрелки означает, что компонент не реализует соответствующий интерфейс, а использует его в процессе своего выполнения. Причем на этой же диаграмме может присутствовать и другой компонент, который реализует этот интерфейс. Другим случаем отношения зависимости на диаграмме компонентов является отношение между различными видами компонентов. Наличие подобной зависимости означает, что внесение изменений в исходные тексты программ или динамические библиотеки приводит к изменениям самого компонента. При этом характер изменений может быть отмечен дополнительно. На диаграмме компонентов могут быть также представлены отношения зависимости между компонентами и реализованными в них классами. Эта информация имеет значение для обеспечения согласования логического и физического представлений модели системы. Если требуется подчеркнуть, что некоторый компонент реализует отдельные классы, то для обозначения компонента используется расширенный символ прямоугольника. При этом прямоугольник компонента делится на две секции горизонтальной линией. Верхняя секция служит для записи имени компонента, а нижняя секция — для указания дополнительной информации. Внутри символа компонента могут изображаться другие элементы графической нотации, такие как классы (компонент уровня типа) или объекты (компонент уровня экземпляра). В этом случае символ компонента изображается таким образом, чтобы вместить эти дополнительные символы. Объекты, которые находятся в отдельном компоненте-экземпляре, изображаются вложенными в символ данного компонента. Подобная вложенность означает, что выполнение компонента влечет выполнение соответствующих объектов. Рекомендации по построению диаграммы компонентов Разработка диаграммы компонентов предполагает использование информации как о логическом представлении модели системы, так и об особенностях ее физической реализации. До начала разработки необходимо принять решения о выборе вычислительных платформ и операционных систем, на которых предполагается реализовывать систему, а также о выборе конкретных баз данных и языков программирования. После этого можно приступать к общей структуризации диаграммы компонентов. В первую очередь, необходимо решить, из каких физических частей (файлов) будет состоять программная система. На этом этапе следует обратить внимание на такую реализацию системы, которая обеспечивала бы не только возможность повторного использования кода за счет рациональной декомпозиции компонентов, но и создание объектов только при их необходимости. Речь идет о том, что общая производительность программной системы существенно зависит от рационального использования вычислительных ресурсов. Для этой цели необходимо большую часть описаний классов, их операций и методов вынести в динамические библиотеки, оставив в исполняемых компонентах только самые необходимые для инициализации программы фрагменты программного кода. После общей структуризации физического представления системы необходимо дополнить модель интерфейсами и схемами базы данных. При разработке интерфейсов следует обращать внимание на согласование (стыковку) различных частей программной системы. Включение в модель схемы базы данных предполагает спецификацию отдельных таблиц и установление информационных связей между таблицами. Завершающий этап построения диаграммы компонентов связан с установлением и нанесением на диаграмму взаимных связей между компонентами, а также отношений реализации. Эти отношения должны иллюстрировать все важнейшие аспекты физической реализации системы, начиная с особенностей компиляции исходных текстов программ и заканчивая исполнением отдельных частей программы на этапе ее выполнения. Для этой цели можно использовать различные виды графического изображения компонентов. При разработке диаграммы компонентов следует придерживаться общих принципов создания моделей на языке UML. В частности, необходимо использовать уже имеющиеся в языке UML компоненты и стереотипы. Для большинства типовых проектов этого набора элементов может оказаться достаточно для представления компонентов и зависимостей между ними. Если проект содержит некоторые физические элементы, описание которых отсутствует в языке UML, то следует воспользоваться механизмом расширения и использовать дополнительные стереотипы для отдельных нетиповых компонентов или помеченные значения для уточнения их отдельных характеристик. Следует обратить внимание, что диаграмма компонентов, как правило, разрабатывается совместно с диаграммой развертывания, на которой представляется информация о физическом размещении компонентов программной системы по ее отдельным узлам. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
В процессе эволюции информационных систем наблюдается усложнение выполняемых функций и рост сферы охвата — от планирования производственных ресурсов к поддержке практически всех областей действия компании. Кроме того, возрастают и такие показатели, как время, необходимое на внедрение системы, и собственно затраты на информационные системы и осуществление процесса их внедрения Роль ИТ-стратегии варьируется от формирования общей стратегии плана развития ИТ до технической поддержки инфраструктуры. Принятие решения о внедрении информационной системы имеет статус стратегической инвестиции, поэтому некоторые компании разрабатывают ИТ-стратегию только для реализации этой программы. В таком контексте используется термин SISP (Strategic Information Systems Planning — планирование стратегических информационных систем). В случае SISP область действия сужается до внедрения информационной системы, поэтому существует обособленный ряд методологий SISP, таких как BSP (Business Systems Planning — планирование бизнес- систем), SSP (Strategic Systems Planning — планирование стратегических систем), IE (Information Engineering — информационный инжиниринг). ИТ-стратегию характеризуют возможности ИТ как на рынке технологий, так и на предприятии, а также роль, отведенная ИТ в организации. Область действия ИТ-стратегии можно подразделить на две составляющие: ИТ-архитектуру и организационную часть. В круг задач стратегии входят: • выравнивание ИТ-стратегии с бизнес-стратегией; • определение целевых бизнес-единиц для использования различных информационных компонент; • определение приложений для использования в работе с этими бизнес-единицами; • установление архитектурных вариантов для системы; • определение бизнес-процессов и их увязка с архитектурой; • установление стратегий работы с данными; • описание технологической инфраструктуры; • объяснение организационных изменений. Исходя из перечня задач, дадим определение ИТ-стратегии: это функциональная стратегия, формирование которой характеризуется ролью ИТ в организации и степенью зрелости возможностей ИТ, в зависимости от которых находятся цели и задачи стратегии. Для разработки стратегии процессов управления ИТ-ресурсами необходимо знать планы предприятия, которые потребуют развития инфраструктуры, обеспечения необходимого уровня ИТ-сервисов и возможных вариантов обеспечения ресурсами. С точки зрения стратегии изменения портфеля прикладных систем, необходимо опреде- лить планы, связанные с новыми бизнес-процессами, интеграцией приложений и поддерживанием этих аспектов людскими ресурсами и программным обеспечением. Основная деятельность ИТ-служб направлена на создание и управление приложениями (прикладными системами), т.е. предоставление ИТ-услуг, и эксплуатацию инфраструктуры, т.е. поддержку ИТ-услуг. Разделение обязанностей связано с различием в деятельности по со- зданию систем и их сопровождению. Каждая из групп имеет свои цели: • приложения определяют то, как выполняется работа, поэтому разработка приложений тесно связана с основным бизнесом компании или деятельностью государственной организации, а знание приложений — это прежде всего понимание бизнес- процессов; • эксплуатация инфраструктуры — деятельность, относительно слабо связанная с ключевыми функциями организации, сфокусированная в основном на технологиях. Таким образом, необходимо различать две разные стратегии в области ИТ: прикладные системы и эксплуатация ИТ-инфраструктуры: • приложения как элемент стратегии ИТ — это зона ответственности бизнеса. Основой функционирования организации явля- ются бизнес-процессы, которые поддерживаются прикладными системами. Руководство компании должно оценивать стратегию в области прикладных систем с точки зрения качества и результативности поддержки ключевых функций; • эксплуатация инфраструктуры сфокусирована на сегодняшних, ежедневных проблемах. Бизнес-руководство оценивает стратегию в области ИТ-инфраструктуры с точки зрения эффективности (максимальная отдача при минимальных затратах). Gartner Group предлагает следующий подход к составным элементам ИТ-стратегии и определяет 9 этапов реализации: 1. Согласование понимания требований бизнеса к ИТ (понимание направлений развития бизнеса). 2. Определение процессов управления и контроля, выбор финансовых критериев для принятия решений и сравнительного анализа вариантов стратегии. 3. Определение будущего состояния архитектуры предприятия (высокоуровневое описание). 4. Анализ текущего состояния ИТ и оценка вариантов реализаций с учетом существующих ограничений, накладываемых имеющейся инфраструктурой ИТ. 5. Разработка стратегии развития/изменения приложений. Применение знаний, полученных на предыдущих этапах. 6. Формирование стратегии развития процессов и операций управления ИТ-ресурсами. Стратегическим направлением здесь может являться переход к сервисной модели предоставления ИТ-услуг. 7. Определение стратегии и задач по развитию необходимых кадровых ИТ-ресурсов и позиционированию аутсорсинга. 8. Подготовка документа с описанием стратегии ИТ и представление результатов для формального обсуждения. 9. Организация управленческого процесса поддержания стратегии в актуальном состоянии. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
БИЛЕТ 9 |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Человеко-компьютерное взаимодействие (HCI) — это изучение, планирование и разработка взаимодействия между людьми (пользователями) и компьютерами. Взаимодействие между пользователями и компьютерами происходит на уровне пользовательского интерфейса (или просто интерфейса), который включает в себя программное и аппаратное обеспечение. Основной задачей человеко-компьютерного взаимодействия является улучшение взаимодействия между человеком и компьютером, делая компьютеры более удобными (usability) и восприимчивыми к потребностям пользователей. В частности, человеко-компьютерное взаимодействие занимается: методологией и развитием проектирования интерфейсов (т. е., исходя из требований и класса пользователей, проектирование наилучшего интерфейса в заданных рамках, оптимизация под требуемые свойства, такие как обучаемость и эффективность использования);
Долгосрочной задачей человеко-компьютерного взаимодействия является разработка системы, которая снизит барьер между человеческой когнитивной моделью того, чего они хотят достичь, и пониманием компьютером поставленных перед ним задач. При оценке текущего пользовательского интерфейса или разработке нового интерфейса следует иметь в виду следующие принципы разработки: С самого начала необходимо акцентировать своё внимание на пользователях и задачах: установить количество пользователей, требуемых для выполнения задачи и определить подходящих пользователей; кто-либо никогда не использовавший интерфейс, либо тот, кто никогда не будет его использовать в будущем является неподходящим пользователем. Кроме того, необходимо определить какие задачи и как часто будут выполнять пользователи. Эмпирические измерения : на ранней стадии провести тест интерфейса с реальными пользователями, которые используют интерфейс каждый день. Имейте в виду, что результаты могут измениться, если уровень производительности пользователя не является точным отображением реального человеко-компьютерного взаимодействия. Установить количественные особенности практичности, такие как: количество пользователей, выполняющих задачи, время выполнения задачи, и количество ошибок, сделанных в ходе выполнения задачи. Итеративное проектирование : после определения количества пользователей, поставленных задач, эмпирических измерений, выполните следующие шаги итеративной разработки:
Повторяйте итеративную разработку до тех пор, пока не создадите практичный, удобный для пользователя интерфейс. Разнообразные методики, излагающие техники проектирования человеко-компьютерного взаимодействия, начали появляться во времена развития данной области в 1980-х годах. Большинство методик разработки произошли от модели взаимодействия пользователей, разработчиков и технических систем. Ранние методики, например, трактовали когнитивные процессы пользователей как предсказуемые и поддающиеся количественному определению, и предлагали разработчикам при проектировании пользовательских интерфейсов рассматривать результаты когнитивных исследований в таких областях как память и внимание. Современные модели имеют тенденцию акцентировать внимание на постоянной обратной связи и диалоге между пользователями, разработчиками и инженерами, и прилагать усилия к тому, что технические системы крутятся вокруг желаний пользователей, нежели желания пользователей вокруг уже готовой системы. Ориентированное на пользователя проектирование: разработка, ориентированная на пользователя в данный момент является современной, широко практикующейся философией, суть которой заключается в том, что пользователи должны занимать центральное место в разработке любой компьютерной системы. Пользователи, разработчики и технические специалисты работают вместе чтобы чётко выразить желания, потребности и границы, и создать систему, отвечающую этим требованиям. Ориентированные на пользователя проекты часто пользуются исследованиями этнографической среды, в которой пользователи будут работать с системой. Эта практика является аналогичной, но не является совместной разработкой, которая подчёркивает возможность для пользователей активно сотрудничать посредством сессий и семинаров. Принципы разработки пользовательского интерфейса (англ. Principles of user interface design): эти семь принципов могут рассматриваться в любое время, в любом порядке в течение всего времени разработки, это: привычность, простота, очевидность, допустимость, последовательность, структура и обратная связь. Интерфейс, по определению - это правила взаимодействия операционной системы с пользователями, с другими ЭВМ и др. От интерфейса обычно зависит технология общения человека с компьютером. Человеко-машинный интерфейс обеспечивает связь между пользователем и компьютером - он позволяет достигать поставленных целей, успешно находить решение поставленной задачи. Взаимодействие - обмен действиями и реакциями на эти действия между компьютером и пользователем. Лет десять назад основным видом взаимодействия был текст (так называемые терминальные или командные системы). В настоящее время, взаимодействие может также включать графику и иконки (знаки) вместо текста. Имеется ряд стилей взаимодействий, которые делятся на два основных вида. Первый – это использование интерфейса языка команд - ввод команд текстовыми средствами; и второй – это непосредственное манипулирование. Таким образом, имеется ряд способов, которыми пользователь мог бы связываться с компьютером:
Основными принципами создания интерфейса являются:
Разнообразные методики, излагающие техники проектирования человеко-компьютерного взаимодействия, начали появляться во времена развития данной области в 1980-х годах. Большинство методик разработки произошли от модели взаимодействия пользователей, разработчиков и технических систем. Ранние методики, например, трактовали когнитивные процессы пользователей как предсказуемые и поддающиеся количественному определению, и предлагали разработчикам при проектировании пользовательских интерфейсов рассматривать результаты когнитивных исследований в таких областях как память и внимание. Современные модели имеют тенденцию акцентировать внимание на постоянной обратной связи и диалоге между пользователями, разработчиками и инженерами, и прилагать усилия к тому, что технические системы крутятся вокруг желаний пользователей, нежели желания пользователей вокруг уже готовой системы. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Гипертекстовая структура получила исключительно широкое распространение, в основном, в информационно-справочных системах в различных областях знания. Такие программы обеспечивают электронный просмотр больших объемов иерархически организованной текстовой и графической информации. Гипертекстовая структура обеспечивает быстрый поиск информации по различным признакам. Гипертекст - это информационный массив, на котором заданы и автоматически поддерживаются связи между выделенными элементами. В виде гипертекста может быть представлена любая слабо формализованная совокупность текстов или изображений. Гипертекстовая форма представления информации является следствием эволюции средств общения людей между собой, и гипертекст соответствует природе мышления человека. Гипертекст в обобщенном смысле - это интерактивная информационная система, созданная на основе множества естественных и искусственных языков, гибких аппаратных и программных средств, позволяющих пользователю динамично и творчески взаимодействовать с изменяемым информационным массивом с целью получения нового для себя знания. Все большее распространение получают также системы гипермедиа. Под гипермедиа понимается способ организации мультимедиа. Мультимедиа предполагает объединение в компьютерной системе нескольких средств предоставления информации, а именно: текст, звук, графика, мультипликация, видео, пространственное моделирование. Гипермедиа состоит из узлов, которые являются основными единицами хранения информации и могут включать в себя страницы текста, графику, звуковую информацию, видеоклип или целый документ. Взаимное согласование голоса лектора, музыкального и шумового сопровождения с визуальным рядом способно обеспечить образное восприятие учебного материала, эмоциональное воздействие на ученика, что даёт не только более глубокие и "долгоживущие" знания, но сопряжено с гораздо меньшей нагрузкой на зрение учащихся. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Феномен Big Data, или проблема Больших Данных. Стоит отметить, что проблема хранения и обработки большого объема данных существовала всегда, но с развитием ИТ она стала беспокоить не только ряд крупнейших корпораций, но и гораздо более широкий круг компаний. В первую очередь, возросло число генераторов данных, причем весьма большого объема – это Web 2.0 системы, а именно социальные сети разных видов, данные электронной почты, Twitter, Wiki-проекты. Кроме того, огромные объемы данных могут генерироваться датчиками различных типов – Сall Data Records (CDR) сотовых операторов, телеметрические данные, информация с камер видеонаблюдения и т.п. Во-вторых, значительное уменьшение стоимости хранения привело к тому, что многие компании могут позволить себе следовать парадигме «данные слишком ценны, чтобы их уничтожать». Но главная проблема заключается в том, что кроме количества данных изменился и их характер. Основной объем этих данных – неструктурированная информация, поэтому ее хранение и обработка в привычных системах на основе реляционных БД, как правило, малоэффективна. И постепенно пришло осознание того, что реляционные СУБД не являются оптимальным решением для ряда ситуаций, а это, в свою очередь, привело к появлению целого семейства решений, которые можно классифицировать одним словом – NoSQL- системы. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Риск это проблема, которая еще не возникла, а проблема — это риск, который материализовался. Риск характеризуется следующими характеристиками:
Планирование управления риска Управление рисками это определенная деятельность, которая выполняется в проекте от его начала до завершения. Как и любая другая работа в проекте управление рисками требует времени и затрат ресурсов. Поэтому эта работа обязательно должна планироваться. Планирование управления рисками — это процесс определения подходов и планирования операций по управлению рисками проекта. Тщательное и подробное планирование управления рисками позволяет:
Планирование управления рисками должен быть завершено на ранней стадии планирования проекта, поскольку оно крайне важно для успешного выполнения других процессов. В соответствии с исходными данными для планирования управления рисками служат:
План управления рисками обычно включает в себя следующие элементы:
Шкала оценки воздействия отражает значимость риска в случае его возникновения. Шкала оценки воздействия может различаться в зависимости от потенциально затронутой риском цели, типа и размера проекта, принятыми в организации стратегиями и его финансовым состоянием, а также от чувствительности организации к конкретному виду воздействий.
менее $10KХотя риск может воздействовать и на сроки проекта, и на качество получаемого продукта, но все эти отклонения могут быть оценены в денежном эквиваленте. Например, последствия задержка по срокам для заказной разработки может быть выражена в сумме денежных санкций, определенных в контракте. Похожая шкала может быть применена для оценки вероятности наступления риска
ноЕще одной важной характеристикой риска является близость его наступления. Естественно, что при прочих равных условиях рискам, которые могут осуществиться уже завтра, следует сегодня уделять больше внимания, чем тем, которые могут произойти не ранее, чем через полгода. Для шкалы оценки близости риска может быть применена, например, следующая градация: очень скоро, не очень скоро, очень нескоро. Идентификация рисков Идентификация рисков — это выявление рисков, способных повлиять на проект, и документальное оформление их характеристик. Это итеративный процесс, который периодически повторяется на всем протяжении проекта, поскольку в рамках его жизненного цикла могут обнаруживаться новые риски. Исходные данные для выявления и описания характеристик рисков могут браться из разных источников. В первую очередь это база знаний организации. Информация о выполнении прежних проектов может быть доступна в архивах предыдущих проектов. Следует помнить, что проблемы завершенных и выполняемых проектов, это, как правило, риски в новых проектах. Другим источником данных о рисках проекта может служить разнообразная информация из открытых источников, научных работ, маркетинговая аналитика и другие исследовательские работы в данной области. Наконец, многие форумы по программированию могут дать бесценную информацию о возникших ранее проблемах в похожих проектах. Каждый проект задумывается и разрабатывается на основании ряда гипотез, сценариев и допущений. Как правило, в описании содержания проекта перечисляются принятые допущения — факторы, которые для целей планирования считаются верными, реальными или определенными без привлечения доказательств. Неопределенность в допущениях проекта следует также обязательно рассматривать в качестве потенциального источника возникновения рисков проекта. Анализ допущения позволяет идентифицировать риски проекта, происходящие от неточности, несовместимости или неполноты допущений. Для сбора информации о рисках могут применяться различные подходы. Среди этих подходов наиболее распространены:
Цель опроса экспертов — идентифицировать и оценить риски путем интервью подходящих квалифицированных специалистов. Специалисты высказывают своё мнение о рисках и дают им оценку, исходя из своих знаний, опыта и имеющейся информации. Этот метод может помочь избежать повторного наступления на одни и те же грабли. Перед опросом эксперт должен получить всю необходимую вводную информацию. Деятельность экспертов необходимо направлять, задавая вопросы. Во время опроса вся информация, выдаваемая экспертом, должна записываться и сохраняться. При работе с несколькими экспертами выходная информация обобщается и доводится до сведения всех задействованных экспертов. К участию в мозговом штурме привлекаются квалифицированные специалисты, которым дают «домашнее задание» — подготовить свои суждения по определенной категории рисков. Затем проводится общее собрание, на котором специалисты по очереди высказывают свои мнения о рисках. Важно: споры и замечания не допускаются. Все риски записываются, группируются по типам и характеристикам, каждому риску дается определение. Цель — составить первичный перечень возможных рисков для последующего отбора и анализа. Метод Дельфи во многом похож на метод мозгового штурма. Однако есть важные отличия. Во-первых, при применении этого метода эксперты участвуют в опросе анонимно. Поэтому результат характеризуется меньшей субъективностью, меньшей предвзятостью и меньшим влиянием отдельных экспертов. Во-вторых, опрос экспертов проводится в несколько этапов. На каждом этапе модератор рассылает анкеты, собирает и обрабатывает ответы. Результаты опроса рассылаются экспертам снова для уточнения их мнений и оценок. Такой подход позволяет достичь некоего общего мнения специалистов о рисках. Для быстрого выявления рисков можно воспользоваться еще одной из методик социометрии является известной как "Карточки Кроуфорда" . Суть этой методики в следующем. Собирается группа экспертов 7-10 человек. Каждому участнику мини-исследования раздается по десять карточек (для этого вполне подойдет обычная бумага для записок). Ведущий задает вопрос: "Какой риск является наиболее важным в этом проекте?" Все респонденты должны записать наиболее, по их мнению, важный риск в данном проекте. При этом никакого обмена мнениями не должно быть. Ведущий делает небольшую паузу, после чего вопрос повторяется. Участник не может повторять в ответе один и тот же риск. После того как вопрос прозвучит десять раз, в распоряжении ведущего появятся от 70 до 100 карточек с ответами. Если группа подобрана хорошо (в том смысле, что в нее входят люди с различными точками зрения), вероятность того, что участники эксперимента укажут большинство значимых для проекта рисков, весьма высока. Остается составить список названных рисков и раздать его участникам для внесения изменений и дополнений. В качестве источника информации при выявлении рисков могут служить различные доступные контрольные списки рисков проектов разработки ПО, которые следует проанализировать на применимость к данному конкретному проекту. 10 наиболее распространенных рисков программного проекта:
Не существует исчерпывающих контрольных списков рисков программного проекта, поэтому необходимо внимательно анализировать особенности каждого конкретного проекта. Результатом идентификации рисков должен стать список рисков с описанием их основных характеристик: причины, условия, последствий и ущерба.
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Экспертная система (ЭС) - это компьютерная программа, которая моделирует рассуждения человека-эксперта в некоторой определенной области и использует для этого базу знаний, содержащую факты и правила об этой области, специальную процедуру логического вывода. Разработка систем, основанных на знаниях, является составной частью исследований по ИИ, и имеет целью создание компьютерных методов решения проблем, обычно требующих привлечения экспертов-специалистов. Общепринятая классификация экспертных систем отсутствует, однако наиболее часто экспертные системы различают по назначению, предметной области, методам представления знаний, динамичности и сложности:
По назначению классификацию экспертных систем можно провести следующим образом:
По предметной области наибольшее количество экспертных систем используется в военном деле, геологии, инженерном деле, информатике, космической технике, математике, медицине, метеорологии, промышленности, сельском хозяйстве, управлении процессами, физике, филологии, химии, электронике, юриспруденции. Классификация экспертных систем по методам представления знаний делит их на традиционные и гибридные. Традиционные экспертные системы используют, в основном, эмпирические модели представления знаний и исчисление предикатов первого порядка. Гибридные экспертные системы используют все доступные методы, в том числе оптимизационные алгоритмы и концепции баз данных. По степени сложности экспертные системы делят на поверхностные и глубинные. Поверхностные экспертные системы представляют знания в виде правил «ЕСЛИ-ТО». Условием выводимости решения является безобрывность цепочки правил. Глубинные экспертные системы обладают способностью при обрыве цепочки правил определять (на основе метазнаний) какие действия следует предпринять для продолжения решения задачи. Кроме того, к сложным относятся предметные области в которых текст записи одного правила на естественном языке занимает более 1/3 страницы. Классификация экспертных систем по динамичности делит экспертные системы на статические и динамические. Предметная область называется статической, если описывающие ее исходные данные не изменяются во времени. Статичность области означает неизменность описывающих ее исходных данных. При этом производные данные (выводимые из исходных) могут и появляться заново, и изменяться (не изменяя, однако, исходных данных). Если исходные данные, описывающие предметную область, изменяются за время решения задачи, то предметную область называют динамической. В архитектуру динамической экспертной системы, по сравнению со статической, вводятся два компонента:
Последняя осуществляет связи с внешним миром через систему датчиков и контроллеров. Кроме того, традиционные компоненты статической экспертной системы (база знаний и механизм логического вывода) претерпевают существенные изменения, чтобы отразить временную логику происходящих в реальном мире событий. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
БИЛЕТ 10 |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Язы́к программи́рования — формальная знаковая система, предназначенная для записи компьютерных программ. Язык программирования определяет набор лексических, синтаксических и семантических правил, определяющих внешний вид программы и действия, которые выполнит исполнитель под её управлением. Парадигма программирования Паради́гма программи́рования — это совокупность идей и понятий, определяющих стиль написания компьютерных программ (подход к программированию). Это способ концептуализации, определяющий организацию вычислений и структурирование работы, выполняемой компьютером. - Императивная, или процедурная парадигма программирования - развилась на базе низкоуровневых языков (машинные коды, ассемблер), основанных на архитектуре фон Неймана. Императивная программа состоит из последовательно выполняемых команд и вызовов процедур, которые обрабатывают данные и изменяют значения переменных программы. Переменные при этом рассматриваются как некоторые контейнеры для данных, подобно ячейкам памяти компьютера. - Функциональная парадигма программирования - получила развитие из вычислений по алгебраическим формулам. Функциональная программа состоит из набора взаимосвязанных и, как правило, рекурсивных функций. Каждая функция определяется выражением, которое задает правило вычисления её значения в зависимости от значений ее аргументов. Выполнение функциональной программы заключается в последовательном вычислении значений функциональных вызовов. - Логическая парадигма программа рассматривается как множество логических формул: аксиом (фактов и правил), описывающих свойства некоторых объектов, и теоремы, которую необходимо доказать. В свою очередь, выполнение программы – это доказательство теоремы, в ходе которого строится объект с описанными свойствами. - объектно-ориентированная парадигма - программа описывает структуру и поведение вычисляемых объектов и классов объектов. Объект обычно включает некоторые данные (состояние объекта) и операции с этими данными (методы), описывающие поведение объекта. Классы представляют множество объектов со схожей структурой и схожим поведением. Обычно описание классов имеет иерархическую структуру, включающую полиморфизм операций. Выполнение объектно-ориентированной программы представляет собой обмен сообщениями между объектами, в результате которого они меняют свои состояния. Языки программирования низкого уровня Языки низкого уровня, как правило, используют для написания небольших системных программ, драйверов устройств, модулей стыков с нестандартным оборудованием, программирование специализированных микропроцессоров, когда важнейшими требованиями являются компактность, быстродействие и возможность прямого доступа к аппаратным ресурсам. Языки программирования высокого уровня Особенности конкретных компьютерных архитектур в них не учитываются, поэтому созданные приложения легко переносятся с компьютера на компьютер. Разрабатывать программы на таких языках значительно проще и ошибок допускается меньше. Значительно сокращается время разработки программы, что особенно важно при работе над большими программными проектами .Недостатком некоторых языков высокого уровня является большой размер программ в сравнении с программами на языках низкого уровня. С другой стороны, для алгоритмически и структурно сложных программ при использовании суперкомпиляции преимущество может быть на стороне языков высокого уровня. Деление языков программирования на классы можно представить на схеме таким образом:
Процедурное программирование - есть отражение фон Неймановской архитектуры компьютера. Программа, написанная на процедурном языке, представляет собой последовательность команд, определяющих алгоритм решения задачи. Основная идея процедурного программирования - использование памяти для хранения данных. Основная команда- присвоение, с помощью которой определяется и меняется память компьютера. Программа производит преобразование содержимого памяти, изменяя его от исходного состояния к результирующему. а) Структурное программирование, которое основано на использовании подпрограмм и независимых структур данных; б) Программирование «сверху-вниз», когда задача делится на простые, самостоятельно решаемые задачи. Затем выстраивается решение исходной задачи полностью сверху вниз. Объектно-ориентированное программирование (ООП) — это метод программирования, при использовании которого главными элементами программ являются объекты. В языках программирования понятие объекта реализовано как совокупность свойств (структур данных, характерных для данного объекта), методов их обработки (подпрограмм изменения их свойств) и событий, на которые данный объект может реагировать и, которые приводят, как правило, к изменению свойств объекта - Декларативные языки программирования К ним относятся функциональные и логические языки программирования Функциональное программирование- это способ составления программ, в которых единственным действием является вызов функции. В функциональном программировании не используется память, как место для хранения данных, а, следовательно, не используются промежуточные переменные, операторы присваивания и циклы. Ключевым понятием в функциональных языках является выражение. Программа, написанная на функциональном языке, представляет собой последовательность описания функций и выражений. Выражение вычисляется сведением сложного к простому. Все выражения записываются в виде списков. Логическое программирование- это программирование в терминах логики. - Языки программирования баз данных отличаются от алгоритмических языков прежде всего своим функциональным назначением. При работе с базами данных выполняются следующие операции: создание, преобразование и удаление таблиц в БД; поиск, отбор, сортировка по запросам пользователя; добавление новых записей и модификация существующих, удаление записей и др. - Языки программирования для компьютерных сетей являются интерпретируемыми. Такие языки называются скрипт – языками. - Формальный язык является объединением нескольких множеств: множества исходных символов, называемых литерами (алфавит), множества правил, которые позволяют строить из букв алфавита новые слова (правила порождения слов или идентификаторов), множества предопределённых идентификаторов или словаря ключевых слов (прочие идентификаторы называются именами), множества правил, которые позволяют собирать из имён и ключевых слов выражения, на основе которых строятся простые и сложные предложения (правила порождения операторов или предложений).Множество правил порождения слов, выражений и предложений называют грамматикой формального языка или формальной грамматикой. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
WWW – это распределенная среда, состоящая из автономных систем, узлы которой все чаще формируются как реляционные базы данных. Точно так же пользование электронными публикациями предполагает наличие распределенной системы, в которой имеется довольно низкий уровень доверия между клиентом и сервером. Хотя исследовательское сообщество весьма интенсивно занималось вопросами распределенных баз данных, и плоды этих усилий находят отражение в коммерческих продуктах, новая среда, возникшая в рамках WWW, заставляет переосмыслить многие концепции существующей технологии распределенных баз данных. Информационные ресурсы могут использоваться для решения разнообразных научных и прикладных задач: от поиска необходимой информации до задач принятия управленческих решений. При этом, в зависимости от вида учреждений, пользователю сети этого учреждения должны предоставляться свои собственные виды информационных услуг. Так, например, в образовательных структурах важнейшей информационной услугой будет дистанционное образование, в банках и на биржах - проведение электронных сделок, на производствах - реклама своей продукции, на вокзалах, аэропортах - выдача информации о наличии билетов и заказ билетов и т.д. Развитие сети научного учреждения связано, прежде всего, с развитием информационных ресурсов, направленных на обеспечение среди ученых общего информационного пространства и доступа к различного рода электронным библиотекам, каталогам электронных публикации и т.д. При этом научное учреждение должно стремится к обеспечению в своей сети следующего набора информационных услуг:
Создание этих видов информационных услуг основывается на применении современных программных продуктов и технологий таких как: - базовые технологии Internet(WWW, E-mail и т.д.) - гипертекстовый язык HTML - архитектура клиент - сервер - использование инструментальных средств Java, CGI, JavaScript, и т.д. - SQL-ориентированные системы управления базами данных (СУБД) |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Data Mining (DM) — направление в области интеллектуальных систем, связанное с поиском в больших объемах данных скрытых закономерностей. Data Mining можно интерпретировать как обнаружение знаний в базах данных или как интеллектуальный анализ данных. Дословно DM переводится как добыча данных. Другими словами, это добыча знаний, необходимых для принятия решений в различных сферах человеческой деятельности. При этом под знаниями понимается совокупность сведений, которая образует целостное описание, соответствующее некоторому уровню осведомленности об описываемом вопросе, предмете, проблеме и т.д. Искомые закономерности часто выражаются в виде шаблонов (паттернов — patterns), которые представляют собой некоторые выборки данных. Построение моделей прогнозирования также является целью поиска закономерностей. «Сырой» поиск» иногда пользователь не знает точно, какую именно информацию ему хотелось бы получить, имея лишь общее представление о границах своих интересов. Так, например, пытаясь расширить свою познания в области компьютерной лингвистики, на поисковом сервере AltaVista или др. вы просто получите список из сотен тысяч документов, содержащих слова “computer“ и “linguistic". А ведь хотелось бы расклассифицировать найденный материал по тематическим группам, отражающим, к примеру, основные событиям и разработки в этой области! И хотя наиболее интересен тот материал, о присутствии которого вы вообще не догадываетесь, большинство поисковых машин предлагает найти информацию “под фонарем", а не там, где она зарыта! Классификация знаний составляется на основе таксоно́мии (от древне-греческого Τάξις - строй, порядок и νόμος – закон). Это учение о принципах и практике классификации и систематизации. Классификация знаний представляет собой довольно сложную систему, где все знания изначально классифицируются по признакам «ясность», «доступность», «пропозициональность» и «уровень абстракции». Далее ясные знания подразделяются на явные (сформулированные и обобщенные) и неявные, которые отражаются в действиях, опыте, применительно к конкретной ситуации. По признаку доступности выделяются знания индивидуальные (созданные и используемые конкретным человеком) и коллективные (групповые, организационные, межорганизационные), которые создаются и используются в коллективной деятельности определенной группы людей. Наличие категории «уровень абстракции» позволяет выделять знания конкретные, специализированные, которые дают представление о конкретном предмете или явлении, способе действия в ситуации, и общее, которые объясняют роль, место и взаимосвязь объекта с другими объектами. Для практической деятельности наибольшую ценность представляют знания, которые классифицируются как пропозициональные. Они включают в себя такие типы знаний, как декларативные (знания о чем-то), процедурные (знание осуществления процесса), каузальные, причинно-следственные (знание причин явлений), знания условий и времени выполнения действия, знания отношений объекта действий с другими объектами. К пропозициональным относятся также такие типы знаний как активное и пассивное. Активные знания способствуют осуществлению конкретных действий, используются для понимания причин ситуации, принятия решений и их реализации. Пассивные знания хранится в системах, книгах, документах, базах данных и могут быть востребованы в случае необходимости. Различные виды работы требуют знаний различных по своему уровню, поэтому выделяется такое понятие как «интенсивности знаний», где учитываются, например, такие факторы как: - уровень и сложность знаний и понимания, требуемые для выполнения работы; - уровень экспертизы, требуемый для того чтобы справиться с изменениями рабочей ситуации (условий выполнения задачи); - тяжесть последствий возможных ошибок; - скорость выполнения задачи. Поисковая система — веб-сайт, предоставляющий возможность поиска информации в Интернете. Большинство поисковых систем ищут информацию на сайтах Всемирной паутины, но существуют также системы, способные искать файлы на ftp-серверах, товары в интернет-магазинах, а также информацию в группах новостей Usenet. По принципу действия поисковые системы делятся на два типа: поисковые каталоги и поисковые индексы. Поисковые каталоги служат для тематического поиска. Информация на этих серверах структурирована по темам и подтемам. Имея намерение осветить какую-то узкую тему, нетрудно найти список web-страниц, ей посвященных. Катало́г ресурсов в Интернете или каталог интернет-ресурсов или просто интернет-каталог — структурированный набор ссылок на сайты с кратким их описанием. Каталог, в котором ссылки на сайты внутри категорий сортируются по популярности сайтов называется рейтинг (или топ). Поисковые индексы работают как алфавитные указатели. Клиент задает слово или группу слов, характеризующих его область поиска, — и получает список ссылок на web-страницы, содержащие указанные термины. Первой поисковой системой для Всемирной паутины был «Wandex», уже не существующий индекс, разработанный Мэтью Грэйем из Массачусетского технологического института в 1993. Как работает поисковой индекс? Поисковые индексы автоматически, при помощи специальных программ (веб-пауков), сканируют страницы Интернета и индексируют их, то есть заносят в свою огромную базу данных. Поисковый робот («веб-паук») — программа, являющаяся составной частью поисковой системы и предназначенная для обхода страниц Интернета с целью занесения информации о них (ключевые слова) в базу поисковика. По своей сути паук больше всего напоминает обычный браузер. Он сканирует содержимое страницы, забрасывает его на сервер поисковой машины, которой принадлежит и отправляется по ссылкам на следующие страницы. В ответ на запрос, где найти нужную информацию, поисковый сервер возвращает список гиперссылок, ведущих web-страницам, на которых нужная информация имеется или упоминается. Обширность списка может быть любой, в зависимости от содержания запроса. Яндекс — российская система поиска в Сети. Сайт компании, Yandex.ru, был открыт 23 сентября 1997 года. Головной офис компании находится в Москве. Поиск Яндекса позволяет искать по Рунету документы на русском, украинском, белорусском, румынском, английском, немецком и французском языках с учётом морфологии русского и английского языков и близости слов в предложении. Отличительная особенность Яндекса — возможность точной настройки поискового запроса. Это реализовано за счёт гибкого языка запросов. По умолчанию Яндекс выводит по 10 ссылок на каждой странице выдачи результатов, в настройках результатов поиска можно увеличить размер страницы до 20, 30 или 50 найденных документов. Время от времени алгоритмы Яндекса, отвечающие за релевантность выдачи, меняются, что приводит к изменениям в результатах поисковых запросов. В частности, эти изменения направлены против поискового спама, приводящего к нерелевантным результатам по некоторым запросам. Лидер поисковых машин Интернета, Google занимает более 70 % мирового рынка. Cейчас регистрирует ежедневно около 50 млн поисковых запросов и индексирует более 8 млрд веб-страниц. Google может находить информацию на 115 языках. По одной из версий, Google — искажённое написание английского слова googol. «Googol (гугол)» – это математический термин, обозначающий единицу со 100 нулями. Этот термин был придуман Милтоном Сироттой, племянником американского математика Эдварда Каснера, и впервые описан в книге Каснера и Джеймса Ньюмена «Математика и воображение» (Mathematics and the Imagination). Использование этого термина компанией Google отражает задачу организовать огромные объемы информации в Интернете. Интерфейс Google содержит довольно сложный язык запросов, позволяющий ограничить область поиска отдельными доменами, языками, типами файлов и т. д. Rambler Media Group — интернет-холдинг, включающий в качестве сервисов поисковую систему, рейтинг-классификатор ресурсов российского Интернета, информационный портал. Rambler создан в 1996 году. Поисковая система Рамблер понимает и различает слова русского, английского и украинского языков. По умолчанию поиск ведётся по всем формам слова. Поиск@Mail.Ru — поисковая система от компании Mail.Ru. По данным на декабрь 2013 года, на рынке Рунета он занимает долю около 10 %[1][2]. Таким образом, он занимает третью строчку в рейтинге поисковых систем на российском рынке. С 1 марта 2010 года руководителем Поиска@Mail.Ru является Андрей Калинин[3].В течение многих лет в поисковой строке на главной странице Мейл.ру использовался сторонний движок: в 2004—2006 и 2010—2013 годы использовался поиск Google, 2007—2009 годах — решение от Яндекса. С 1 июля 2013 года сервис использует собственные поисковые технологии, которые разрабатывались командой инженеров Mail.Ru. Проблема поиска, отбора и первичной интерпретации информации в сети Интернет базируются на существовании множества мошеннических сайтов, требующих неправомерную платную регистрацию, или сайтов, полагающих навредить программному обеспечению компьютера. Проблему поиска также затрудняет существование массы web-страниц, которые имеют своей целью распространение рекламы, в качестве «наживки» используя научную литературу или ложно представляя себя научным источником. Классификация знаний. По природе Знания могут быть:
Декларативные знания содержат в себе лишь представление о структуре определенных понятий. Эти знания приближены к данным, фактов. Например вуз является совокупностью факультетов, а каждый факультет в свою очередь является совокупностью кафедр. Процедурные знания имеют активную природу. Они определяют представления о средствах и путях получения новых знаний, проверки знаний. Это алгоритмы разного рода.Например метод мозгового штурма для поиска новых идей. По степени научности Знания могут быть научными и ненаучными. Научные знания могут быть:
Теоретические знания - абстракции, аналогии, схемы, отражающие структуру и природу процессов, протекающих в предметной области. Эти знания объясняют явления и могут использоваться для прогнозирования поведения объектов. Ненаучные знания могут быть: паранаучные - знание несовместимы с имеющимся гносеологическим стандартом. Широкий класс паранаукового (пара от греч. - Возле, при) знания включает учения или размышления о феноменах, объяснение которых не является убедительным с точки зрения критериев научности; псевдонаучными - сознательно эксплуатирующие домыслы и предрассудки. Лженаучных знание часто представляет науку как дело аутсайдеров. Как симптомы лженауки выделяют малограмотный пафос, принципиальную нетерпимость к опровергающих доводов, а также претенциозность. Псевдонаучное знание очень чувствительно к злобе дня, сенсации. Его особенностью является то, что оно не может быть объединено парадигмой, не может обладать систематичностью, универсальностью. Лженаукой знания сосуществуют с научными знаниями. Считается, что псевдонаучное знание обнаруживает себя и развивается через квазинаучная; квазинаучными - они ищут себе сторонников, опираясь на методы насилия и принуждения. Квазинаучные знания, как правило, расцветает в условиях строгой иерархированной науки, где невозможна критика власть имущих, где жестко проявлен идеологический режим; антинаучными - как утопические и сознательно искажающие представления о действительности. Приставка «анти» обращает внимание на то, что предмет и способы исследования противоположны науке. С ним связывают извечную потребность в выявлении общего легко доступных "лекарств от всех болезней». Особый интерес и тяга к антинауки возникает в периоды социальной нестабильности. Но хотя данный феномен достаточно опасен, принципиального избавления от антинауки произойти не может; псевдонаучными - является интеллектуальной активностью, спекулирует на совокупности популярных теорий, например, истории о древних астронавтов; повседневно-практическими - доставлявшие элементарные сведения о природе и окружающей действительности. Люди, как правило, располагают большой объем обыденного знания, которое проводится повседневно и является исходным пластом всякого познания. Иногда аксиомы здравомыслия противоречат научным положениям, препятствуют развитию науки. Иногда, наоборот, наука длинным и трудным путем доказательств и опровержений приходит к формулировке тех положений, которые давно утвердили себя в среде обыденного знания. Обыденное знание включает и здравый смысл, и приметы, и поучения, и рецепты, и личный опыт, и традиции. Оно хоть и фиксирует истину, но делает это не систематично и бездоказательно. Его особенностью является то, что оно используется человеком практически неосознанно и в своем применении не требует предварительных систем доказательст. Другая его особенность - принципиально неграмотный характер. собственные - зависящие от способностей того или иного субъекта и от особенностей его интеллектуальной познавательной деятельности. «Народной наукой» - особой формой вненаучного и иррационального знания, которая в настоящее время стала делом отдельных групп или отдельных субъектов: знахарей, целителей, экстрасенсов, а ранее шаманов, жрецов, старейшин рода. При своем возникновении народная наука обнаруживала себя как феномен коллективного сознания и выступала как этнонаука. В эпоху доминирования классической науки она потеряла статус интерсубъективности расположилась на периферии, вдали от центра официальных экспериментальных и теоретических исследований. Как правило, народная наука существует и транслируется в бесписьменная форме от наставника к ученику. Она также иногда проявляется в виде заветов, наставлений, ритуалов и др.. По месту нахождения Выделяют: личностные (неявные, скрытые) знания и формализованные (явные) знания; Неявные знания:
Формализованные (явные) знания:
Большинство поисковых систем ищут информацию на сайтах Всемирной паутины, но существуют также системы, способные искать файлына FTP-серверах, товары в интернет-магазинах, а также информацию в группах новостей Usenet. Для поиска информации с помощью поисковой системы пользователь формулирует поисковый запрос[1]. По запросу пользователя поисковая система генерирует страницу результатов поиска. Такая поисковая выдача может сочетать различные типы файлов, например: веб-страницы, изображения, аудиофайлы. Некоторые поисковые системы также извлекают данные из баз данных и каталогов ресурсов в Интернете. По методам поиска и обслуживания разделяют четыре типа поисковых систем: системы, использующие поисковых роботов, системы, управляемые человеком, гибридные системы и мета-системы[⇨]. В архитектуру поисковой системы включены: поисковый робот, сканирующий сайты сети Интернет, индексатор, обеспечивающий быстрый поиск, и поисковик — графический интерфейс для работы пользователя. Цель поисковой системы заключается в том, чтобы находить документы, содержащие либо ключевые слова, либо слова как-либо связанные с ключевыми словами[2]. Поисковая система тем лучше, чем больше документов, релевантных запросу пользователя, она будет возвращать. Результаты поиска могут становиться хуже из-за особенностей алгоритмов и вследствие человеческого фактора. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Неопределенности в ЭС и проблемы порождаемые ими В жизни часто приходится оценивать гипотезы, для которых имеется неполная или недостаточная информация. Иногда трудно сделать точные оценки, но, не смотря на неопределенность, мы принимаем разумные решения. Чтобы ЭС были полезными, они тоже должны уметь это делать. Неопределенность в ЭС она может быть двух типов: неопределенность в истинности самой посылки; неопределенность самого правила. Существуют четыре важные проблемы, которые возникают при создании ЭС с неопределенными знаниями. Как количественно выразить степень определенности при установлении истинности (ложности) некоторой части данных? Как выразить степень поддержки заключения конкретной посылкой? Как использовать совместно две (или более) посылки, независимо влияющие на заключение? Как быть в ситуации, когда нужно обсудить цепочку вывода для подтверждения заключения в условиях неопределенности? Прежде всего, рассмотрим возможности использования теории вероятности при вводе в условиях неопределенности. Теория субъективных вероятностей Основное понятие вероятности настолько естественно, что оно играет значительную роль в повседневной жизни. Разговоры, касающиеся вероятности дождя или хорошего урожая в огороде, часто встречаются в нашей жизни. Понятие вероятности было разработано несколько столетий назад. Но уже тысячи лет человек использует такие слова, как «может быть», «шанс», «удача» или иные их эквиваленты в разговорном языке. Однако математическая теория вероятностей была сформулирована относительно недавно (около 1660 года). Вероятность события классически определяется как отношение случаев, в которых данное событие происходит, к общему числу наблюдений. Однако возможны и другие определения. В настоящее время существует несколько интерпретаций теории вероятностей. Рассмотрим три наиболее доминирующих взгляда. Объективистский взгляд. Заключается в том, что рассматривает вероятность отношения исходов ко всем наблюдениям в течении длительного времени. Другими словами этот подход основан на законе больших чисел, гарантирующим то, что при наличии достаточно большого количества наблюдений частота исходов, интересующего события будет стремиться к объективной вероятности. Персонифицированный, субъективистский или основанный на суждениях взгляд. Заключается в том, что вероятностная мера рассматривается как степень доверия того, как отдельная личность судит об истинности некоторого высказывания. Этот взгляд постулирует, что данная личность имеет в некотором смысле отношение к этому событию. Но это не отрицает возможности того, что две приемлемые личности могут иметь различные степени доверия для одного и того же суждения. Термин «байесовский» часто используется как синоним субъективной вероятности. Необходимый или логический. Характеризуется тем, что вероятностная мера расширяется на множество утверждений, имеющих логическую связь такую, что истинность одного из них может выводиться из другого. Другими словами, вероятность измеряет степень доказуемости логически выверенного заключения. Такой взгляд можно рассматривать как расширение обычной логики. Эти вероятностные интерпретации используют и различные схемы вывода. Однако существует всего две школы вероятностных расчетов: школа Паскаля (или общепринятая), школа Бэкона (или индуктивная). Расчеты по Паскалю используют байесовские правила для проверки и обработки мер доверия. Вычисления по Бэкону используют правила логики для доказательства или опровержения гипотез. Таким образом, общепринятые вероятности (по Паскалю) не могут быть получены из индуктивных вероятностей (по Бэкону) и, наоборот. Объективистский и субъективистский взгляды используют расчеты по Паскалю. Те, кто поддерживают логические выводы, используют расчеты по Бэкону. Существуют ЭС, построенные на обоих из этих направлений. Однако в ЭС БЗ накапливают человеческие знания, поэтому для представления знаний экспертов с учетом вероятностей наиболее подходящим является интерпретация на основе субъективных мер доверия. В результате чего и большинство современных ЭС, использующих теорию вероятностей, являются "байесовскими". Теорема Байеса как основа управления неопределенностью Если А и В являются непересекающимися множествами, то объединение множеств соответствует сумме вероятностей, а пересечение – произведению вероятностей: р (А∪В) = р (А) + р ( B ) и р (А∩В) = р (А) * р ( B ). Без предположения независимости эта связь является неточной и формулы должны содержать дополнительные члены включения и исключения (так, например, р (А∪В) = р (А) + р ( B ) - р (А∩В)). Продолжая теоретико-множественное обозначение, В можно записать как: В= ( B∩A )∪ ( B ∩ ¬ A). Т.к. это объединение явно непересекающееся, то: p (В) = p ( ( B∩A )∪ ( B ∩ ¬ A) ) = p ( B∩A ) + p ( B ∩ ¬ A) = p ( B | A )× p ( A ) + p ( B | ¬ A) × p ( ¬ A). Если вернуться к обозначению событий, а не множеств, то последнее равенство может быть подставлено в правило Байеса:
Это равенство является основой для использования теории вероятности в управлении неопределенностью. Оно обеспечивает путь для получения условной вероятности события В при условии А. Это соотношение позволяет ЭС управлять неопределенностью и «делать вывод вперед и назад». Логический вывод на основе субъективной вероятности. Простейший логический вывод. Рассмотрим случай, когда все правила в ЭС отражаются в форме: Если < Н является истинной > То < Е будет наблюдаться с вероятностью р >. Очевидно, если Н произошло, то это правило говорит о том, что событие Е происходит с вероятностью р. Но что будет, если состояние Н неизвестно, а Е произошло? Использование теоремы Байеса позволяет вычислить вероятность того, что Н истинно. Замена «А» и «В» на «Н» и «Е» не существенна для формулы Байеса, но с её помощью мы можем покинуть общую теорию вероятности и перейти к анализу вероятностных вычислений в ЭС. В этом контексте: Н – событие, заключающееся в том, что данная гипотеза верна; Е – событие, заключающееся в том, что наступило определённое доказательство (свидетельство), которое может подтвердить правильность указанной гипотезы. Переписывая формулу Байеса в терминах гипотез и свидетельств, получим:
Это равенство устанавливает связь гипотезы со свидетельством и, в то же время, наблюдаемого свидетельства с пока ещё не подтверждённой гипотезой. Эта интерпретация предполагает также определение априорной вероятности гипотезы р(Н), назначаемой Н до наблюдения или получения некоторого факта. В ЭС вероятности, требуемые для решения некоторой проблемы, обеспечивается экспертами и запоминается в БЗ. Эти вероятности включают: априорные вероятности всех возможных гипотез р(Н); условные вероятности возникновения свидетельств при условии существования каждой из гипотез р(Е /Н). Так, например, в медицинской диагностике эксперт должен задать априорные вероятности всех возможных болезней в некоторой медицинской области. Кроме того, должны быть определены условные вероятности проявления тех или иных симптомов при каждой из болезней. Условные вероятности должны быть получены для всех симптомов и болезней, предполагая, что все симптомы независимы в рамках одной болезни. Два события Е1 и Е2 являются условно независимыми, если их совместная вероятность при условии некоторой гипотезы Н равна произведению условных вероятностей этих событий при условии Н: р (Е1 Е2|Н) =р (Е1|Н)⋅р (Е2|Н) . Вероятность р (Нi |Еj ... Еk) является апостериорной вероятностью гипотез Нi по наблюдениям (Еj ... Еk), т.е. дает сравнительное ранжирование всех возможных гипотез. Результатом вывода ЭС является выбор гипотезы с наибольшей вероятностью. Однако, приведённая выше формула Байеса ограничена в том, что каждое свидетельство влияет только на одну гипотезу. Можно обобщить это выражение на случай множественных гипотез (Н1 ... Нm) и множественных свидетельств (Е1 ... Еn). Вероятности каждой из гипотез при условии возникновения некоторого конкретного свидетельства Е можно определить из выражения:
а в случае множественных свидетельств:
К сожалению данное выражение имеет ряд недостатков. Так, знаменатель требует от нас знания условных вероятностей всех возможных комбинаций свидетельств и гипотез, что делает правило Байеса малопригодным для ряда приложений. Однако в тех случаях, когда возможно предположить условную независимость свидетельств, правило Байеса можно привести к более простому виду
Вместе с тем предположения о независимости событий в ряде случаев подавляют точность суждений и свидетельств в ЭС. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Структурное программирование - метод программирования, использование которого снижает вероятность ошибок в процессе составления программ, повышает их надежность, эффективность, упрощает понимание, обеспечивает создание программ, структура которых ясна и неразрывно связана со структурой решаемых задач. Целью структурного программирования является попытка упростить процесс написания правильных программ и обеспечить возможность чтения программы от начала до конца, следуя логике. Программы, написанные с использованием традиционных методов, обычно имеют хаотичную структуру, поэтому и чтение, и понимание их затруднено. Структурированные программы можно читать как обычный текст сверху вниз без перерыва, так как они имеют последовательную организацию, т.е. применение метода структурного программирования улучшает ясность и читабельность программ. Иначе его еще называют методом пошаговой детализации. Нисходящее проектирование программы, когда первоначально программа рассматривается, как совокупность действий, каждое из которых затем детализируется и представляется как последовательность более простых и конкретных действий и т.д. Вплоть до отдельных операторов языка; такой подход позволяет реализовать наличие двух видов подпрограмм в языке – процедур и функций. Первоначально продумывается общая структура алгоритма без детальной проработки отдельных его частей. Блоки требующие дальнейшей детализации, обозначаются пунктирной линией. Далее прорабатываются отдельные блоки, не детализированные на предыдущем шаге. Таким образом, на каждом шаге разработки уточняется реализация фрагмента алгоритма (или программы), т.е. решается более простая задача.Полностью закончив детализацию всех блоков, получаем решение задачи в целом. Если на каждом шаге детализации использовать принципы структурного программирования, то получается хорошая структурированная программа в целом. Технология нисходящего проектирования с пошаговой детализацией является неотъемлемой частью создания хорошо структурированных программ. Разработка алгоритма методом пошаговой детализации заключается в следующем: Любой алгоритм можно представить в виде одного предписания - в виде постановки задачи. Но если исполнитель не обучен исполнять заданное предписание, то возникает необходимость представить данное предписание в виде некоторой совокупности более простых предписаний.Если исполнитель не может выполнить и некоторые из них, то такие предписания вновь представляются в виде совокупности еще более простых предписаний. Объединяя так полученные предписания в единую совокупность выполняемых в определенном порядке предписаний получают выполнение исходного задания в целом. Достоинства метода пошаговой детализации: 1. Сохраняется концептуальная целостность программы: от сложного к простому. 2. Проектирование программы, кодирование, проверку и документирование можно делать параллельно. 3. В каждый момент времени (даже в начале разработки) имеется работающий вариант программы. 4. Фразы естественного языка, будучи закомментированными, служат хорошим путеводителем по программе. В процессе создания программы особое внимание нужно уделять разработке алгоритмов. Такой подход поможет избежать ошибок, допущенных при проектировании программного продукта. Наличие подобных ошибок потребует массу времени на исправление, возврат на предыдущие этапы разработки с целью их доработки. При разработке алгоритмов обычно используют метод пошаговой детализации (поэтапно): 1. На первом этапе описываются решения поставленной перед программой задачи, выделяются подзадачи. 2. В последующих этапах описывается решение каждой подзадачи, выделяя при этом новые подзадачи. Так происходит до тех пор, пока решение подзадач не будет очевидным. Рекомендовано решение каждой задачи описывать при помощи 1 - 2 конструкций не более, чтобы более четко представлять структуру программы.
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
БИЛЕТ 11 |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Во всех сферах своей деятельности, и частности в сфере обработки информации, человек сталкивается с различными способами, или методиками, решения задач. Они определяют порядок выполнения действий для получения желаемого результата – это можно трактовать как первоначальное или интуитивное определение алгоритма. Некоторые дополнительные требования приводят к неформальному определению алгоритма:
Отметим, что различные определения алгоритма, в явной или неявной форме, постулируют следующий ряд требований:
Алгоритмический объект (АО) - данные, для преобразования которых используется алгоритм. Для формального определения АО фиксируют конечный алфавит символов (цифр, букв и т.п.) и определяют правила построения АО (синтаксические правила). Процесс преобразования алгоритмических объектов в ходе выполнения алгоритма осуществляется дискретно, т.е. пошагово. Последовательность шагов детерминирована, т.е. после каждого шага указывается точно, что и как следует выполнять на следующем шаге. Процесс преобразования АО, включающий в себя заданную последовательность шагов, называют алгоритмическим процессом (АП). Механизм реализации АП прослеживается на алгоритмических моделях, использующих конечные наборы простейших АО и конечные наборы элементарных действий. Выделяют три основных типа алгоритмических моделей:
В теории вычислительных алгоритмов доказана сводимость одного типа модели к другой: всякий алгоритм, описанный средствами одной модели, может быть описан также средствами другой. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Типовая структура автоматизированных систем научных исследований, содержащая три уровня: объектный, инструментальный и сервисный (базовый). Объектный уровень характеризуется связью с объектом исследований. Его назначение состоит в организации процесса экспериментирования, т.е. реализации управления экспериментальной установкой, регистрации данных, их оперативной обработки, накопления и представления первичных результатов исследователю, в том числе и оказание ему помощи в интерпретации результатов эксперимента и принятии решения о дальнейшем проведении исследований. На объектный уровень также возлагают операции, связанные с проверкой и тестированием экспериментального оборудования, текущей регистрацией и документированием данных. Инструментальный уровень предназначен для проведения достаточно сложных видов обработки экспериментальных данных, научных расчетов и моделирования, если они не требуют слишком больших мощностей вычислительного оборудования. Здесь осуществляется накопление и длительное хранение информации, полученной в результате исследований, формируются архивы и банки данных по отдельным проблемам исследований. На инструментальном уровне осуществляется отработка различных алгоритмов и программ, составленных пользователем, в том числе и программ, используемых на объектном уровне. Базовый (или сервисный) уровень используется для осуществления наиболее сложных и громоздких научных расчетов, моделирования, обработки и представления информации, формирования крупных банков и баз данных, создания информационно-поисковой системы. Трехуровневая организация современных АСНИ позволяет, с одной стороны, предоставить исследователю необходимые средства вычислительной техники и автоматизации на всех этапах исследования, а с другой - сократить затраты на создание системы, уменьшить количество ЭВМ, периферийного оборудования и т.д. Необходимо подчеркнуть, что для АСНИ наиболее важным является объектный уровень, так как именно на этом уровне фигурирует исследователь, роль которого является ключевой. Именно на объектном уровне в первую очередь регистрируется новая информация об изучаемом явлении или объекте. Поэтому АСНИ, являясь многоуровневыми системами, не относятся к категории иерархических систем. Можно считать, что верхние этажи этой организации - инструментальный и базовый уровни - являются вспомогательными, оказывающими дополнительные услуги при извлечении полезной информации, разработке и проверке теоретических положений на основе экспериментальных данных. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Искусственный интеллект (ИИ) – это некая система программных средств, имитирующая на компьютере процесс мышления человека. Термин искусственный интеллект был предложен в 1956 г. в Станфордском университете (США). Интеллект представляет собой совокупность фактов и способов их применения для достижения определенной цели. А достижение цели – это применение необходимых правил использования соответствующих фактов. Алгоритм – это формальная процедура, которая гарантирует получение оптимального решения База знаний – это часть ЭС, содержащая предметные знания. Диспетчер – это часть механизма вывода, которая решает когда и в каком порядке применить правила из предметных знаний. Знание – это интеллектуальная информация, используемая в программе. Интерпретатор – это часть механизма вывода, которая решает каким образом применять предметные знания. Механизм вывода – это часть ЭС, содержащая в себе общие сведения о схеме управления процессом решения задачи. Коэффициент уверенности – это число, означающее вероятность или степень уверенности, с которой можно считать данные факты и правила достоверными. Правила – это формальный способ задания знаний в виде:ЕСЛИ <условие>, ТО <действие> Экспертная система – это программа, основанная на знаниях, в которых предметные знания предусмотрены в явном виде и отделены от прочих знаний. Эвристики – это правила, упрощают или ограничивают поиск решения в предметной области. Семантическая сеть – это метод представления знаний в виде графа, где вершинами являются объекты, а дугами – их свойства. Пример.Факт1. Зажженная плита – горячая. Правило1. ЕСЛИ положить руку на зажженную плиту, ТО можно обжечься. Рассмотрим этапы развития систем искусственного интеллект а:
В начале 90-х годов 20 века была принята совершенно новая концепция. Суть ее заключается в том, чтобы сделать программу интеллектуальной, ее нужно снабдить множеством высококачественных специальных знаний некоторой предметной области. Т.о., разрабатываемые системы ИИ должны иметь хорошо развитую базу знаний. В настоящее время наиболее полное развитие этой концепции получило проектирование экспертных систем (ЭС). Система искусственного интеллекта, созданная для решения задач в конкретной предметной области, называется экспертной. ЭС – это сложные программные комплексы, аккумулирующие знания специалистов в конкретных предметных областях и тиражирующие этот эмпирический опыт для консультации менее квалифицированных пользователей. Источником знаний для ЭС служат эксперты в соответствующей предметной области. Основные их свойства:
В процессе проектирования и функционирования ЭС можно выделить следующих участников: 1. Разработчик инструментальных средств проектирования ЭС; 2. Инструментальные средства (ИС) построения ЭС; 3. Сама ЭС; 4. Эксперт; 5. Инженер знаний или администратор БЗ; 6. Пользователь. Инженер знаний – это человек, имеющий навыки в разработке систем ИИ и знающий как надо строить ЭС. Он опрашивает эксперта и организует знания в БЗ. К инструментальным средствам (ИС) проектирования относят язык программирования ЭС и поддерживающие средства, через которые пользователь взаимодействует с ЭС. Взаимодействие участников ЭС.
Рассмотрим компетентность ЭС, сравнивая систему человеческого интеллекта и систему ИИ.
Анализируя преимущества и недостатки этих систем, можно сделать основной вывод о необходимости человека-эксперта, т.к. во многих областях он превосходит ИИ, например, по творчеству, изобретательности, способности передавать информацию и вообще по здравому смыслу. Рассмотрим область применения СИИ: Доказательство теорем. Изучение приемов доказательства теорем сыграло важную роль в развитии искусственного интеллекта. Много неформальных задач, например, медицинская диагностика, применяют при решении методические подходы, которые использовались при автоматизации доказательства теорем. Поиск доказательства математической теоремы требует не только провести дедукцию, исходя из гипотез, но также создать интуитивные предположения о том, какие промежуточные утверждение следует доказать для общего доказательства основной теоремы. Распознавание изображений. Применение искусственного интеллекта для распознавании образов позволила создавать практически работающие системы идентификации графических объектов на основе аналогичных признаков. В качестве признаков могут рассматриваться любые характеристики объектов, подлежащих распознаванию. Признаки должны быть инвариантны к ориентации, размера и формы объектов. Алфавит признаков формируется разработчиком системы. Качество распознавания во многом зависит от того, насколько удачно сложившийся алфавит признаков. Распознавания состоит в априорном получении вектора признаков для выделенного на изображении отдельного объекта и, затем, в определении которой из эталонов алфавита признаков этот вектор отвечает. Машинный перевод и понимание человеческой речи. Задача анализа предложений человеческой речи с применением словаря является типичной задачей систем искусственного интеллекта. Для ее решения был создан язык-посредник, облегчающий сопоставление фраз из разных языков. В дальнейшем этот язык-посредник превратилась в семантическую модель представления значений текстов, подлежащих переводу. Эволюция семантической модели привела к созданию языка для внутреннего представления знаний. В результате, современные системы осуществляют анализ текстов и фраз в четыре основных этапа: морфологический анализ, синтаксический, семантический и прагматический анализ. Игровые программы. В основу большинства игровых программ положены несколько базовых идей искусственного интеллекта, таких как перебор вариантов и самообучения. Одна из наиболее интересных задач в сфере игровых программ, использующих методы искусственного интеллекта, заключается в обучении компьютера игры в шахматы. Она была основана еще на заре вычислительной техники, в конце 50-х годов. В шахматах существуют определенные уровни мастерства, степени качества игры, которые могут дать четкие критерии оценки интеллектуального роста системы. Поэтому компьютерными шахматами активно занимался ученые со всего мира, а результаты их достижений применяются в других интеллектуальных разработках, имеющих реальное практическое значение. В 1974 году впервые прошел чемпионат мира среди шахматных программ в рамках очередного конгресса IFIP (International Federation of Information Processing) в Стокгольме. Победителем этого соревнования стала шахматная программа «Каисса». Она была создана в Москве, в Институте проблем управления Академии наук СССР. Машинная творчество. К одной из областей применений искусственного интеллекта можно отнести программные системы, способные самостоятельно создавать музыку, стихи, рассказы, статьи, дипломы и даже диссертации. Сегодня существует целый класс музыкальных языков программирования (например, язык C-Sound). Для различных музыкальных задач было создано специальное программное обеспечение: системы обработки звука, синтеза звука, системы интерактивного композиции, программы алгоритмической композиции. Экспертные системы. Методы искусственного интеллекта нашли применение в создании автоматизированных консультирующих систем или экспертных систем. Первые экспертные системы были разработаны, как научно-исследовательские инструментальные средства в 1960-х годах прошлого столетия. Они были системами искусственного интеллекта, специально предназначенными для решения сложных задач в узкой предметной области, такой, например, как медицинская диагностика заболеваний. Классической целью этого направления изначально было создание системы искусственного интеллекта общего назначения, которая была бы способна решить любую проблему без конкретных знаний в предметной области. Ввиду ограниченности возможностей вычислительных ресурсов, эта задача оказалась слишком сложной для решения с приемлемым результатом. Коммерческое внедрение экспертных систем произошло в начале 1980-х годов, и с тех пор экспертные системы получили значительное распространение. Они используются в бизнесе, науке, технике, на производстве, а также во многих других сферах, где существует вполне определенная предметная область. Основное значение выражения «вполне определенное», заключается в том, что эксперт-человек способен определить этапы рассуждений, с помощью которых может быть решена любая задача по данной предметной области. Это означает, что аналогичные действия могут быть выполнены компьютерной программой. Многие споры вокруг проблемы "кибернетика и мышление" имеют эмоциональную подоплеку. Признание возможности искусственного разума представляется чем-то унижающим человеческое достоинство. Однако нельзя смешивать вопросы возможности искусственного разума с вопросом о развитии и совершенствовании человеческого разума. Разумеется, искусственный разум может быть использован в негодных целях, однако это проблема не научная, а скорее морально-этическая. Однако развитие кибернетики выдвигает ряд проблем, которые все же требуют пристального внимания. Эти проблемы связаны с опасностями, возникающими в ходе работ по искусственному интеллекту. Первая проблема связана с возможной потерей стимулов к творческому труду в результате массовой компьютеризации или использования машин в сфере искусств. Однако в последнее время стало ясно, что человек добровольно не отдаст самый квалифицированный творческий труд, т.к. он для самого человека является привлекательным. Вторая проблема носит более серьезный характер и на нее неоднократно указывали такие специалисты, как Н. Винер, Н. М. Амосов, И. А. Полетаев и др. Состоит она в следующем. Уже сейчас существуют машины и программы, способные в процессе работы самообучаться, т.е. повышать эффективность приспособления к внешним факторам. В будущем, возможно, появятся машины, обладающие таким уровнем приспособляемости и надежности, что необходимость человеку вмешиваться в процесс отпадет. В этом случае возможна потеря самим человеком своих качеств, ответственных за поиск решений. Налицо возможная деградация способностей человека к реакции на изменение внешних условий и, возможно, неспособность принятия управления на себя в случае аварийной ситуации. Встает вопрос о целесообразности введения некоторого предельного уровня в автоматизации процессов, связанных с тяжелыми аварийными ситуациями. В этом случае у человека, "надзирающим" за управляющей машиной, всегда хватит умения и реакции таким образом воздействовать на ситуацию, чтобы погасить разгорающуюся аварийную ситуацию. Таковые ситуации возможны на транспорте, в ядерной энергетике. Особо стоит отметить такую опасность в ракетных войсках стратегического назначения, где последствия ошибки могут иметь фатальный характер. Несколько лет назад в США начали внедрять полностью компьютеризированную систему запуска ракет по командам суперкомпьютера, обрабатывающего огромные массивы данных, собранных со всего света. Однако оказалось, что даже при условии многократного дублирования и перепроверки, вероятность ошибки оказалась бы столь велика, что отсутствие контролирующего оператора привело бы к непоправимой ошибке. От системы отказались. Люди будут постоянно решать проблему искусственного интеллекта, постоянно сталкиваясь со все новыми проблемами. И, видимо, процесс этот бесконечен. (упомянуть тест Тьюринга |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
В Интернет используется много различных типов пакетов, но один из основных - IP-пакет (RFC-791), именно он вкладывается в кадр Ethernet и именно в него вкладываются пакеты UDP, TCP. IP-протокол предлагает ненадежную транспортную среду. Ненадежную в том смысле, что не существует гарантии благополучной доставки IP-дейтограммы. Алгоритм доставки в рамках данного протокола предельно прост: при ошибке дейтограмма выбрасывается, а отправителю посылается соответствующее ICMP-сообщение (или не посылается ничего). Обеспечение же надежности возлагается на более высокий уровень (UDP или TCP).
Формат дейтограммы Интернет Поле версия характеризует версию IP-протокола (например, 4 или 6). Формат пакета определяется программой и, вообще говоря, может быть разным для разных значений поля версия. Только размер и положение этого поля незыблемы. Поэтому в случае изменений длины IP-адреса слишком тяжелых последствий это не вызовет. Понятно также, что значение поля версия во избежании непредсказуемых последствий должно контролироваться программой. HLEN - длина заголовка, измеряемая в 32-разрядных словах, обычно заголовок содержит 20 октетов (HLEN=5, без опций и заполнителя). Заголовок для IPv6 имеет размер в два раза больше, чем для IPv4. Поле полная длина определяет полную длину IP-дейтограммы (до 65535 октетов), включая заголовок и данные. Заголовок IPv4 может расширяться от 20 до максимум 60 байт, но эта опция редко используется, так как влечет ухудшение рабочих характеристик и часто административно запрещена из соображений безопасности. Одно-октетное поле тип сервиса (TOS - type of service) характеризует то, как должна обрабатываться дейтограмма. Это поле делится на 6 субполей:
Субполе Приоритет предоставляет возможность присвоить код приоритета каждой дейтограмме. Значения приоритетов приведены в таблице (в настоящее время это поле не используется). 0 Обычный уровень 1 Приоритетный 2 Немедленный 3 Срочный 4 Экстренный 5 ceitic/ecp 6 Межсетевое управление 7 Сетевое управление Формат поля TOS определен в документе RFC-1349. Биты C, D, T и R характеризуют пожелание относительно способа доставки дейтограммы. Так D=1 требует минимальной задержки, T=1 - высокую пропускную способность, R=1 - высокую надежность, а C=1 - низкую стоимость. TOS играет важную роль в маршрутизации пакетов. Интернет не гарантирует запрашиваемый TOS, но многие маршрутизаторы учитывают эти запросы при выборе маршрута (протоколы OSPF и IGRP). Протокол передачи команд и сообщений об ошибках (ICMP - internet control message protocol, RFC-792, - 1256) выполняет многие и не только диагностические функции, хотя у рядового пользователя именно этот протокол вызывает раздражение, сообщая об его ошибках или сбоях в сети. Именно этот протокол используется программным обеспечением ЭВМ при взаимодействии друг с другом в рамках идеологии TCP/IP. Осуществление повторной передачи пакета, если предшествующая попытка была неудачной, лежит на TCP или прикладной программе. При пересылке пакетов промежуточные узлы не информируются о возникших проблемах, поэтому ошибка в маршрутной таблице будет восприниматься как неисправность в узле адресата и достоверно диагностироваться не будет. ICMP-протокол сообщает об ошибках в IP-дейтограммах, но не дает информации об ошибках в самих ICMP-сообщениях. icmp использует IP, а IP-протокол должен использовать ICMP. В случае ICMP-фрагментации сообщение об ошибке будет выдано только один раз на дейтограмму, даже если ошибки были в нескольких фрагментах. Задачи, решаемые ICMP Подводя итоги, можно сказать, что ICMP-протокол осуществляет:
Следует только иметь в виду, что получив отклик на посланный запрос, мы узнаем состояние объекта не в данный момент, а RTT/2 тому назад. ICMP-сообщения об ошибках никогда не выдаются в ответ на:
Эти правила призваны блокировать потоки дейтограмм, посылаемым в отклик на мультикастинг или широковещательные ICMP-сообщения. ICMP-сообщения имеют свой формат, а схема их вложения аналогична UDP или TCP Схема вложения ICMP-пакетов в Ethernet-кадр
Схема вложения ICMP-пакетов в Ethernet-кадр Все ICMP пакеты начинаются с 8-битного поля типа ICMP и его кода (15 значений). Форматы пакетов ICMP
Формат эхо-запроса и отклика ICMP
Поля идентификатор (обычно это идентификатор процесса) и номер по порядку (увеличивается на 1 при посылке каждого пакета) служат для того, чтобы отправитель мог связать в пары запросы и отклики. Поле тип определяет, является ли этот пакет запросом (8) или откликом (0). Поле контрольная сумма представляет собой 16-разрядное дополнение по модулю 1 контрольной суммы всего ICMP-сообщения, начиная с поля тип. Поле данные служит для записи информации, возвращаемой отправителю. При выполнении процедуры ping эхо-запрос с временной меткой в поле данные посылается адресату. Если адресат активен, он принимает IP-пакет, меняет адрес отправителя и получателя местами и посылает его обратно. ЭВМ-отправитель, восприняв этот отклик, может сравнить временную метку, записанную им в пакет, с текущим показанием внутренних часов и определить время распространения пакета (RTT - round trip time). Размер поля данные не регламентирован и определяется предельным размером IP-пакета. Поле идентификатор бывает важно, когда ЭВМ используется как программируемый генератор трафика. В этом случае очередной ICMP-пакет посылается, не дожидаясь прихода отклика. Более того, такие пакеты могут генерироваться несколькими процессами одновременно. В этом случае поле идентификатор становится необходимым, чтобы определить, какому процессу ОС передать очередной отклик. Время распространения ICMP-запроса, вообще говоря, не равно времени распространения отклика. Это связано не только с возможными изменениями в канале. В общем случае маршруты их движения могут быть различными. Когда маршрутизатор не может доставить дейтограмму по месту назначения, он посылает отправителю сообщение "адресат не достижим" (destination unreachable). Формат такого сообщения показан ниже
Формат ICMP-сообщения "адресат не достижим" Поле код содержит целое число, проясняющее положение дел. Поле MTU на следующем этапе характеризует максимальную длину пакетов на очередном шаге пересылки. Так как в сообщении содержится Интернет-заголовок и первые 64-бита дейтограммы, легко понять, какой адрес оказался недостижим. Этот тип ICMP-сообщения посылается и в случае, когда дейтограмма имеет флаг DF=1 ("не фрагментировать"), а фрагментация необходима. В поле код в этом случае будет записано число 4. Если буфер приема сообщения переполнен, ЭВМ посылает сообщение типа 4 для каждого из не записанных в буфер сообщений. Так как собственные часы различных ЭВМ имеют свое представление о времени, протокол ICMP, среди прочего, служит для синхронизации работы различных узлов, если это требуется (запросы временных меток). Протокол синхронизации NTP (network time protocol) описан в RFC-1119. Когда дейтограммы поступают слишком часто и принимающая сторона не справляется с этим потоком, отправителю может быть послано сообщение с требованием резко сократить информационный поток (quench-запрос), снижение потока должно продолжаться до тех пор, пока не прекратятся quench-запросы. Такое сообщение имеет формат:
Формат icmp-запроса снижения загрузки В Internet таблицы маршрутизации остаются без изменений достаточно долгое время, но иногда таблицы все же меняются. Если маршрутизатор обнаружит, что ЭВМ использует неоптимальный маршрут, он может послать ей ICMP-запрос переадресации.
Формат ICMP-запроса переадресации Поле Internet-адрес маршрутизатора содержит адрес маршрутизатора, который ЭВМ должна использовать, чтобы посланная дейтограмма достигла места назначения, указанного в ее заголовке. В поле internet-заголовок кроме самого заголовка лежит 64 первых бита дейтограммы, вызвавшей это сообщение. Поле код специфицирует то, как нужно интерпретировать адрес места назначения Команды переадресации маршрутизатор посылает только ЭВМ и никогда другим маршрутизаторам. Рассмотрим конкретный пример. Пусть некоторая ЭВМ на основе своей маршрутной таблицы посылает пакет маршрутизатору M1. Он, просмотрев свою маршрутную таблицу, находит, что пакет следует переслать маршрутизатору M2. Причем выясняется, что пакет из M1 в M2 следует послать через тот же интерфейс, через который он попал в M1. Это означает, что M2 доступен и непосредственно для ЭВМ-отправителя. В такой ситуации M1 посылает ICMP-запрос переадресации ЭВМ-отправителю указанного пакета с тем, чтобы она внесла соответствующие коррективы в свою маршрутную таблицу. Маршрутная таблица может загружаться из файла, формироваться менеджером сети, но может создаваться и в результате запросов и объявлений, посылаемых маршрутизаторами. После загрузки системы маршрутизатор посылает широковещательный запрос. Один или более маршрутизаторов посылают в ответ сообщения об имеющейся маршрутной информации. Кроме того, маршрутизаторы периодически (раз в 450-600 сек.) широковещательно объявляют о своих маршрутах, что позволяет другим маршрутизаторам скорректировать свои маршрутные таблицы. В RFC-1256 описаны форматы ICMP-сообщений такого рода
Формат ICMP-сообщений об имеющихся маршрутах Поле число адресов характеризует количество адресных записей в сообщении. Поле длина адреса содержит число 32-битных слов, необходимых для описания адреса маршрутизатора. Поле время жизни предназначено для записи продолжительности жизни объявленных маршрутов (адресов) в секундах. По умолчанию время жизни равно 30 мин. Поля уровень приоритета представляют собой меру приоритетности маршрута по отношению к другим маршрутам данной подсети. Чем больше этот код тем выше приоритет. Маршрут по умолчанию имеет уровень приоритета 0. Формат запроса маршрутной информации (8 октетов)
Формат запроса маршрутной информации Так как следующий прогон (hop) дейтограммы определяется на основании локальной маршрутной таблицы, ошибки в последней могут привести к зацикливанию пакетов. Для подавления таких циркуляций используется контроль по времени жизни пакета (TTL). При ликвидации пакета по истечении TTL маршрутизатор посылает отправителю сообщение "время истекло", которое имеет формат
Формат сообщения "время (ttl) истекло" Значение поля код определяет природу тайм-аута Когда маршрутизатор или ЭВМ выявили какую-либо ошибку, не из числа описанных выше (например, нелегальный заголовок дейтограммы), посылается сообщение "конфликт параметров". Это может произойти при неверных параметрах опций. При этом посылается сообщение вида
Формат сообщения типа "конфликт параметров" Поле указатель отмечает октет дейтограммы, который создал проблему. Код=1 используется для сообщения о том, что отсутствует требуемая опция (например, опция безопасности при конфиденциальных обменах), поле указатель при значении поля код=1 не используется. В процессе трассировки маршрутов возникает проблема синхронизации работы часов в различных ЭВМ. К счастью синхронизация внутренних часов ЭВМ требуется не так часто (например, при выполнении синхронных измерений), негативную роль здесь могут играть задержки в каналах связи. Для запроса временной метки другой ЭВМ используется сообщение запрос временной метки, которое вызывает отклик с форматом
Формат ICMP-запроса временной метки Протокол UDP (User Datagram Protocol, RFC-768) является одним из основных протоколов, расположенных непосредственно над IP. Он предоставляет прикладным процессам транспортные услуги, немногим отличающиеся от услуг протокола IP. Протокол UDP обеспечивает доставку дейтограмм, но не требует подтверждения их получения. Протокол UDP не требует соединения с удаленным модулем UDP ("бессвязный" протокол). К заголовку IP-пакета UDP добавляет поля порт отправителя и порт получателя, которые обеспечивают мультиплексирование информации между различными прикладными процессами, а также поля длина UDP-дейтограммы и контрольная сумма, позволяющие поддерживать целостность данных. Таким образом, если на уровне IP для определения места доставки пакета используется адрес, на уровне UDP - номер порта. Область использования UDP Примерами сетевых приложений, использующих UDP, являются NFS (Network File System), TFTP (Trivial File Transfer protocol, RFC-1350), RPC (Remote Procedure Call, RFC-1057) иSNMP (Simple Network Management Protocol, RFC-1157). Малые накладные расходы, связанные с форматом UDP, а также отсутствие необходимости подтверждения получения пакета, делают этот протокол наиболее популярным при реализации приложений мультимедиа, но главное его место работы - локальные сети и мультимедиа. Прикладные процессы и модули UDP взаимодействуют через UDP-порты. Эти порты нумеруются, начиная с нуля. Прикладной процесс, предоставляющий некоторые услуги (сервер), ожидает сообщений, направленных в порт, специально выделенный для этих услуг. Программа-сервер ждет, когда какая-нибудь программа-клиент запросит услугу. Например, сервер SNMP всегда ожидает сообщения, адресованного в порт 161. Если клиент snmp желает получить услугу, он посылает запрос в UDP-порт 161 на машину, где работает сервер. На каждой машине может быть только один агент SNMP, т.к. существует только один порт 161. Данный номер порта является общеизвестным, т.е. фиксированным номером, официально выделенным в сети Internet для услуг SNMP. Общеизвестные номера портов определяются стандартами Internet Данные, отправляемые прикладным процессом через модуль UDP, достигают места назначения как единое целое. Например, если процесс-отправитель производит 5 записей в порт, то процесс-получатель должен будет сделать 5 чтений. Размер каждого записанного сообщения будет совпадать с размером каждого прочитанного. Протокол UDP сохраняет границы сообщений, определяемые прикладным процессом. Он никогда не объединяет несколько сообщений в одно и не делит одно сообщение на части. Формат UDP-дейтограмм
Формат UDP-дейтограмм Длина сообщения равна числу байт в UDP-дейтограмме, включая заголовок. Поле UDP контрольная сумма содержит код, полученный в результате контрольного суммирования UDP-заголовка и поля данные. Не трудно видеть, что этот протокол использует заголовок минимального размера (8 байт). Таблица номеров UDP-портов приведена ниже (4.4.2.1). Номера портов от 0 до 255 стандартизованы и использовать их в прикладных задачах не рекомендуется. Но и в интервале 255-1023 многие номера портов заняты, поэтому прежде чем использовать какой-то порт в своей программе, следует заглянуть в RFC-1700. Во второй колонке содержится стандартное имя, принятое в Internet, а в третей - записаны имена, принятые в UNIX. Схема вычисления контрольных сумм Модуль IP передает поступающий IP-пакет модулю UDP, если в заголовке этого пакета указан код протокола UDP. Когда модуль UDP получает дейтограмму от модуля IP, он проверяет контрольную сумму, содержащуюся в ее заголовке. Если контрольная сумма равна нулю, это означает, что отправитель ее не подсчитал. ICMP, IGMP, UDP и TCP протоколы имеют один и тот же алгоритм вычисления контрольной суммы (RFC-1071). Но вычисление контрольной суммы для UDP имеет некоторые особенности. Во-первых, длина UDP-дейтограммы может содержать нечетное число байт, в этом случае к ней добавляется нулевой байт, который служит лишь для унификации алгоритма и никуда не пересылается. Во-вторых, при расчете контрольной суммы для UDP и TCP добавляются 12-байтные псевдо-заголовки, содержащие IP-адреса отправителя и получателя, код протокола и длину дейтограммы Как и в случае IP-дейтограммы, если вычисленная контрольная сумма равна нулю, в соответствующее поле будет записан код 65535.
Псевдозаголовок, используемый при расчете контрольной суммы Если контрольная сумма правильная (или равна 0), то проверяется порт назначения, указанный в заголовке дейтограммы. Если прикладной процесс подключен к этому порту, то прикладное сообщение, содержащиеся в дейтограмме, становится в очередь к прикладному процессу для прочтения. В остальных случаях дейтограмма отбрасывается. Если дейтограммы поступают быстрее, чем их успевает обрабатывать прикладной процесс, то при переполнении очереди сообщений поступающие дейтограммы отбрасываются модулем UDP. Следует учитывать, что во многих посылках контрольное суммирование не охватывает адреса отправителя и места назначения. При некоторых схемах маршрутизации это приводит к зацикливанию пакетов в случае повреждения его адресной части (адресат не признает его "своим"). Так как максимальная длина IP-дейтограммы равна 65535 байтам, максимальная протяженность информационного поля UDP-дейтограммы составляет 65507 байт. На практике большинство систем работает с UDP-дейтограммами с длиной 8192 байта или менее (Ethernet допускает 1508 байт). Детальное описание форматов, полей пакетов и пр. читатель может найти в RFC-768. Смотри также RFC-2147 (IPv6 Jumbo), RFC-2508 (компрессия заголовков) и RFC-3828 (Lightweight UDP). |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Жизненный цикл проекта – это набор, как правило, последовательных и иногда перекрывающихся фаз проекта, названия и количество которых определяются потребностями в управлении и контроле организации или организаций, вовлеченных в проект, характером самого проекта и его прикладной областью Каждый программный продукт имеет свой жизненный цикл, в который проект разработки очередного релиза входит как одна из фаз. Аналогично, каждый проект разработки ПО имеет свой собственный жизненный цикл, который состоит из четырех фаз
На фазе инициации проекта необходимо понять, что и зачем мы будем делать — разработать концепцию проекта. Фаза планирования определяет, как мы будем это делать. На фазе реализации происходит материализация наших идей в виде документированного и протестированного программного продукта. И, наконец, на фазе завершения мы должны подтвердить, что мы разработали именно тот продукт, который задумали в концепции проекта, а также провести приемо-сдаточные испытания (ПСИ) продукта на предмет соответствия его свойств, определенным ранее требованиям. Как правило, редкий проект выполняется в соответствие с первоначальными планами, поэтому важным элементом фазы завершения является «обратная связь»: анализ причин расхождения и усвоение уроков на будущее. Помним, что управляющая система без обратной связи не может быть устойчивой. Если в операционной деятельности ресурсы расходуются более-менее равномерно по времени, то в проектном управлении расходование ресурсов в единицу времени имеет явно выраженное колоколообразное распределение
Проект часто начинается с идеи, которая появляется у одного человека. Постепенно, по мере формулирования, анализа и оценки этой идеи, привлекаются дополнительные специалисты. Еще больше участников требуется на фазе планирования проекта. Пик потребления ресурсов приходится на фазу реализации. В современных моделях разработки ПО реализация осуществляется на основе сочетания итеративного и инкрементального подходов. Итеративность предполагает, что требования к системе и ее архитектура прорабатываются не один раз, а постепенно уточняются от итерации к итерации. Это означает, что на каждой итерации происходит полный цикл процессов разработки: уточнение требований, проектирование, кодирование, тестирование и документирование. Инкрементальность состоит в том, что результатом каждой итерации является версия ПО, которая реализует часть функциональности будущего программного продукта и может быть введена в тестовую или опытную эксплуатацию, а также оценена заказчиком и будущими пользователями. Это означает, что после каждой итерации происходит прирост требуемого функционала, а нереализованных функций будущего продукта остается все меньше. Сочетание итеративности и инкрементальности обеспечивает эффективность разработки и существенное снижение рисков по ходу проекта. На последней фазе происходит постепенное высвобождение участников проектной команды. Следует помнить, что проект должен иметь четкое окончание во времени, после которого все работы по проекту закрываются, и на проект перестают тратиться ресурсы. Не должно оставаться «зависших» работ. Жизненный цикл продукта обычно состоит из последовательных, неперекрывающихся фаз продукта, определяемых потребностью производства и контроля организации. Последней фазой жизненного цикла продукта, как правило, является прекращение сервисного обслуживания и поддержки. Обычно жизненный цикл проекта заключен в рамках жизненных циклов одного или нескольких продуктов. Но, тем не менее, следует отличать жизненный цикл проекта от жизненного цикла продукта Например, разработка нового продукта сама по себе может являться проектом. С другой стороны, существующий продукт может получить преимущества от проекта в виде добавления новых функций или возможностей, либо проект может быть предпринят для разработки новой модели. Многие составляющие жизненного цикла продукта могут сами по себе выступать в качестве проектов, например проведение исследования применимости, проведение маркетингового исследования, проведение рекламной кампании, установка продукта, удержание целевой группы, проведение испытаний продукта на тестовом рынке и т. д. В каждом из данных примеров жизненный цикл проекта отличается от жизненного цикла продукта Поскольку с одним продуктом может быть связано множество проектов, дополнительной эффективности можно достичь, управляя всеми сопутствующими проектами в совокупности Таким образом, различия состоят в следующем: - ЖЦ разработки нового продукта зависит от того, о какой отрасли идет речь (о дополнительных влияниях со стороны предприятия) - ЖЦ проекта не зависит от того, о какой именно отрасли идет речь, поскольку теория управления проектами не привязана к конкретной отрасли. - ЖЦ разработки нового продукта относится к работе, которую необходимо выполнить для создания продукта. ЖЦ проекта ориентирован на управление работой - ЖЦ разработки нового продукта может содержать в себе множество проектов, каждый из которых должен пройти полный ЖЦ. Система управления проектами Система управления проектами (СУП) - набор инструментов, методов, методологий, ресурсов и процедур, используемых для управления проектом. Она может быть как формальной, так и неформальной и помогает менеджеру проекта эффективно завершить проект. Система управления проектами - это ряд процессов и связанных с ними функций контроля, объединенных в единую целенаправленную структуру. Система управления проектами строится на основе плана управления проектом, который описывает то, как будет использоваться система. Содержание системы управления проектом изменяется в зависимости от области приложения, особенностей организации, сложности проекта и доступности необходимых ресурсов. Система строится так, чтобы максимально соответствовать стратегическим целям и производственным ресурсам клиентской организации. Применение системы управления проектами позволяет:
Офис управления проектами (ОУП) или проектный офис — структурное подразделение организации, контрольно-координационный орган который определяет и развивает в организации стандарты бизнес-процессов, связанные с управлением проектами. На Западе, в отличие от проектного офиса (англ. project office), офис управления проектами (англ. project management office) является структурой, которая отвечает за управление проектами, а не отдельным проектом. Проектный офис управляет портфелем проектов, при этом учитывается:
Проектный офис структурирует, декомпозирует и выделяет повторяемые бизнес-процессы, имея целью в будущем повысить эффективностьпланирования и качество выполнения проектов. Проектный офис также документирует, консультирует и пропагандирует лучшие практики проектного менеджмента в организации. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
БИЛЕТ 12 |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Термин «компьютерная алгебра» возник как синоним терминов «символьные вычисления», «аналитические вычисления», «аналитические преобразования» и т. д. Даже в настоящее время этот термин на французском языке дословно означает «формальные вычисления». В чём основные отличия символьных вычислений от численных и почему возник термин «компьютерная алгебра»? Когда мы говорим о вычислительных методах, то считаем, что все вычисления выполняются в поле вещественных или комплексных чисел. В действительности же всякая программа для ЭВМ имеет дело только с конечным набором рациональных чисел, поскольку только такие числа представляются в компьютере. Для записи целого числа отводится обычно 16 или 32 двоичных символа (бита), для вещественного – 32 или 64 бита. Это множество не замкнуто относительно арифметических операций, что может выражаться в различных переполнениях (например, при умножении достаточно больших чисел или при делении на маленькое число). Ещё более существенной особенностью вычислительной математики является то, что арифметические операции над этими числами, выполняемые компьютером, отличаются от арифметических операций в поле рациональных чисел. Особенностью компьютерных вычислений является неизбежное наличие погрешности или конечная точность вычислений. Каждую задачу требуется решить с использованием имеющихся ресурсов ЭВМ за обозримое время с заданной точностью, поэтому оценка погрешности — важная задача вычислительной математики. Решение проблемы точности вычислений и конечности получаемых численных результатов в определённой степени даётся развитием систем компьютерной алгебры. Системы компьютерной алгебры, осуществляющие аналитические вычисления, широко используют множество рациональных чисел. Компьютерные операции над рациональными числами совпадают с соответствующими операциями в поле рациональных чисел. Кроме того, ограничения на допустимые размеры числа (количество знаков в его записи) позволяет пользоваться практически любыми рациональными числами, операции над которыми выполняются за приемлемое время. В компьютерной алгебре вещественные и комплексные числа практически не применяются, зато широко используется алгебраические числа. Алгебраическое число задаётся своим минимальным многочленом, а иногда для его задания требуется указать интервал на прямой или область в комплексной плоскости, где содержится единственный корень данного многочлена. Многочлены играют в символьных вычислениях исключительно важную роль. На использовании полиномиальной арифметики основаны теоретические методы аналитической механики, они применяются во многих областях математики, физики и других наук. Кроме того, в компьютерной алгебре рассматриваются такие объекты, как дифференциальные поля (функциональные поля), допускающие показательные, логарифмические, тригонометрические функции, матричные кольца (элементы матрицы принадлежат кольцам достаточно общего вида) и другие. Даже при арифметических операциях над такими объектами происходит 12 Глава 1. Возникновение и развитие СКМ разбухание информации, и для записи промежуточных результатов вычислений требуется значительный объём памяти ЭВМ. В научных исследованиях и технических расчётах специалистам приходится гораздо больше заниматься преобразованиями формул, чем собственно численным счётом. Тем не менее, с появлением ЭВМ основное внимание уделялось автоматизации численных вычислений, хотя ЭВМ начали применяться для решения таких задач символьных преобразований, как, например, символьное дифференцирование, ещё в 50-х годах прошлого века. Активная разработка систем компьютер- ной алгебры началась в конце 60-х годов. С тех пор создано значительное количество различных систем, получивших различную степень распространения; некоторые системы продолжают развиваться, другие отмирают, и постоянно появляются новые. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Одним из наиболее важных этапов проектирования сложных изделий (в том числе и аэрокосмической продукции) является этап конструирования. В настоящее время все существующее программное обеспечение автоматизированного конструирования входит в состав САПР. Как и любая сложная система, САПР состоит из подсистем. Различают подсистемы проектирующие и обслуживающие. Проектирующие подсистемы непосредственно выполняют проектные процедуры. Примерами проектирующих подсистем могут служить подсистемы геометрического трехмерного моделирования механических объектов, изготовления конструкторской документации, схемотехнического анализа, трассировки соединений в печатных платах. Обслуживающие подсистемы обеспечивают функционирование проектирующих подсистем, их совокупность часто называют системной средой (или оболочкой) САПР. Типичными обслуживающими подсистемами являются подсистемы управления проектными данными, подсистемы разработки и сопровождения программного обеспечения CASE (Computer Aided Software Engineering), обучающие подсистемы для освоения пользователями технологий, реализованных в САПР. Структурирование САПР по различным аспектам обуславливает появление видов обеспечения САПР: техническое, математическое, программное, информационное, лингвистическое, методическое, организационное. Классификацию САПР осуществляют по ряду признаков, например по приложению, целевому назначению, масштабокомплектности решаемых задач), характеру базовой подсистемы – ядра САПР. По приложениям наиболее представительными и широко используемыми являются следующие группы САПР: 1 САПР для применения в отраслях машиностроения. Их часто называют машиностроительными САПР или системами MCAD (Machanical CAD); 2 САПР для радиоэлектроники: системы ECAD (Electronic CAD) или EDA (Electronic Design Automation); 3 САПР в области архитектуры и строительства Кроме того, известно большое число специализированных САПР, или выделяемых в указанных группах, или представляющих самостоятельную САПР электрических машин и т.п. По целевому назначению различают САПР или подсистемы САП, обеспечивающие разные аспекты (страты) проектирования. Так, в составе MCAD появляются рассмотренные выше CAE/CAD/CAM-системы. По масштабам различают отдельные программно-методические комплексы (ПМК) САПР, например комплекс анализа прочности механических изделий в соответствии с методом конечных элементов (МКЭ) или комплекс анализа электронных схем; систем ПМК; системы с уникальными архитектурами не только программного (software), но и технического (hardware) обеспечения. По характеру базовой подсистемы различают следующие разновидности САПР: 1 САПР на базе подсистемы машинной графики и геометрического моделирования. Эти САПР ориентированы на приложения, где основной процедурой проектирования является конструирование, то есть определение пространственных форм и взаимного расположения объектов. К этой группе систем относится большинство САПР в области машиностроения, построенных на базе графических ядер. В настоящее время широко используют унифицированные графические ядра, применяемые более чем в одной САПР; 2 САПР на базе СУБД. Они ориентированы на приложения, в которых при сравнительно несложных математических расчетах перерабатывается большой объем данных. Такие САПР преимущественно встречаются в технико-экономических приложениях, например при проектировании бизнес-планов, но они имеются так же при проектировании объектов, подобных щитам управления в системах автоматики; 3 САПР на базе конкретного прикладного пакета. Фактически это автономно используемые ПМК, например, имитационного моделирования производственных процессов, расчета прочности по МКЭ, синтеза и анализа систем автоматического управления и т.п. Часто такие САПР относят к системам САЕ. Примерами могут служить программы логического проектирования на базе языка VHDL, математические пакеты типа MathCAD 4 комплексные (интегрированные) САПР, состоящие из совокупности подсистем предыдущих видов. Характерными примерами комплексных САПР являются CAE/CAD/CAM-системы в машиностроении или САПР СБИС. Так, САПР СБИС включает в себя СУБД и подсистемы проектирования компонентов, принципиальных, логических и функциональных схем, топология кристаллов, тестов для проверки годности изделий. Для управления столь сложными системами применяют специализированные системные среды. Приведенных перечень информационных структур современного предприятия показывает, что используется очень широкий спектр, решающий различные задачи. Необходимо их объединить для решения общей задачи и дальнейшего развития. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Мягкие вычисления - это сложная компьютерная методология, основанная на нечеткой логике, генетических вычислениях, нейрокомпьютинге и вероятностных вычислениях . Составные части не конкурируют, но создают эффект синергизма (суммирующий эффект взаимодействия двух или более факторов, характеризующийся тем, что их действие существенно превосходит эффект каждого отдельного компонента в виде их простой суммы). Ведущий принцип МВ - это учет неточности, неопределенности, частичной истины и аппроксимации для достижения робастности, низкой цены решения, большего соответствия с реальностью. Четыре составные части мягких вычислений (Рис.2.1) включают в себя: - нечеткую логику; - нейрокомпьютинг; - генетические алгоритмы; -вероятностные вычисления. - Нечеткая логика Очевидной областью внедрения алгоритмов нечеткой логики являются всевозможные экспертные системы, в том числе:
Мощь и интуитивная простота нечеткой логики как методологии разрешения проблем гарантирует ее успешное использование во встроенных системах контроля и анализа информации. При этом происходит подключение человеческой интуиции и опыта оператора. Недостатками нечетких систем являются:
- Нейрокомпьютинг. Нейрокомпьютинг - это технология создания систем обработки информации (например, нейронных сетей), которые способны автономно генерировать методы, правила и алгоритмы обработки в виде адаптивного ответа в условиях функционирования в конкретной информационной среде. Данная технология охватывает параллельные, распределенные, адаптивные системы обработки информации, способные «учиться» обрабатывать информацию, действуя в информационной среде. Таким образом, нейрокомпьютинг можно рассматривать как перспективную альтернативу программируемым вычислениям, по крайней мере, в тех областях, где его удается применять. Новый подход не требует готовых алгоритмов и правил обработки - система должна «уметь» вырабатывать правила и модифицировать их в процессе решения конкретных задач обработки информации. Нейрокомпьютинг дает эффективные, легко и быстро реализуемые параллельные методы решения. Представляет интерес также и обратная задача: анализируя обученную систему, определить разработанный ею алгоритм решения задачи. Недостатки нейрокомпьютинга в том, что каждый алгоритм создается специально для решения конкретных задач, связанных с нелинейной логикой и теорией самоорганизации. Также ввиду уникальности устройств для нейрокомпьютинга к недостаткам можно отнести дороговизну нейрокомпьютеров. - Генетические алгоритмы Генетический алгоритм — это эвристический алгоритм поиска, используемый для решения задач оптимизации и моделирования путём случайного подбора, комбинирования и вариации искомых параметров с использованием механизмов, напоминающих биологическую эволюцию. Является разновидностью эволюционных вычислений, с помощью которых решаются оптимизационные задачи с использованием методов естественной эволюции, таких как наследование, мутации, отбор и кроссинговер. Отличительной особенностью генетического алгоритма является акцент на использование оператора «скрещивания», который производит операцию рекомбинации решений-кандидатов, роль которой аналогична роли скрещивания в живой природе. Задача генетических алгоритмов формализуется таким образом, чтобы её решение могло быть закодировано в виде вектора («генотипа») генов, где каждый ген может быть битом, числом или неким другим объектом. В классических реализациях ГА предполагается, что генотип имеет фиксированную длину. Однако существуют вариации ГА, свободные от этого ограничения. Некоторым, обычно случайным, образом создаётся множество генотипов начальной популяции. Они оцениваются с использованием «функции приспособленности», в результате чего с каждым генотипом ассоциируется определённое значение («приспособленность»), которое определяет насколько хорошо фенотип, им описываемый, решает поставленную задачу. Из полученного множества решений («поколения») с учётом значения «приспособленности» выбираются решения (обычно лучшие особи имеют большую вероятность быть выбранными), к которым применяются «генетические операторы» (в большинстве случаев «скрещивание» — crossover и «мутация» — mutation), результатом чего является получение новых решений. Для них также вычисляется значение приспособленности, и затем производится отбор («селекция») лучших решений в следующее поколение. Этот набор действий повторяется итеративно, так моделируется «эволюционный процесс», продолжающийся несколько жизненных циклов (поколений), пока не будет выполнен критерий остановки алгоритма. Таким критерием может быть:
Генетические алгоритмы служат, главным образом, для поиска решений в многомерных пространствах поиска. Недостатки генетических алгоритмов проявляются :
- Вероятностные вычисления. Вероятностная машина Тьюринга Вероятностные вычисления — один из подходов в теории вычислительной сложности, в котором программы получают доступ, говоря неформально, к генератору случайных чисел. Вероятностная машина Тьюринга (ВМТ) — детерминированная машина Тьюринга, имеющая вероятностную ленту. Переходы в ВМТ могут осуществляться с учетом информации, считанной с вероятностной ленты.
Вероятностная
лента —
бесконечная в одну сторону
последовательность битов, распределение
которых подчиняется некоторому
вероятностному закону (обычно считают,
что биты в различных позициях независимы
и вероятность нахождения
Введем вероятностное
пространство Недостатком вероятностных вычислений является то, что эффективными будут только полиномиальные алгоритмы. Главной особенностью мягких вычислений является то, что в отличие от традиционных (жестких) вычислений, они приспособлены к неточности реального мира. Основным принципом мягких вычислений является: «терпимость к неточности, неопределенности и частичной истинности для достижения удобства манипулирования, робастности (малое изменение выхода замкнутой системы управления при малом изменении параметров объекта управления), низкой стоимости решения и лучшего согласия с реальностью». Исходной моделью для мягких вычислений служит человеческое мышление. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Иерархическая структура работ (далее ИСР) — это разбиение проекта на более мелкие и измеримые части. ИСР описывает все результаты/работы, которые должны быть получены/выполнены для завершения проекта. Все, что не вошло в ИСРв рамки проекта не входит. Часто ИСР представляют в виде диаграммы, где нижние уровни являются декомпозицией верхних. ИСР также может быть представлена в виде:
Все элементы ИСР имеют специальную кодировку, смысл которой — присвоить каждому элементу уникальный номер. Самый верхний уровень имеет код 0 (ноль) и его часто именуют просто: «проект». Элементы первого уровня нумеруются последовательно от 1 до количества элементов на уровне (обычно не более 7). Второй и последующие уровни нумеруется таким образом, чтобы элемент сохранил ссылку на вышестоящий В некоторых случаях иерархическая структура работ содержит специальное дополнение, т.н. «словарь ИСР«. Это чаще таблица, которая помогает правильно прочитать диаграмму:
Структуры декомпозиции проекта (принципы декомпозиции)
Например, проект выполняется по таким фазам: Продажа, Аналитика, Проектирование, Дизайн, Продакшн, Верстка и т.д По ключевым результатам проекта (deliverables) Например, проект по внедрению системы управления транспортом может иметь такой набор результатов: Информационная система, Карты для маршрутизации транспорта, Векторные графы дорог и маршрутов, Механизм поддержки, Обученный персонал, Оборудование. Эти результаты удобно отразить на первом уровне, чтобы заказчик ясно и точно видел, что будет сдано ему по завершению проекта.
Например, в проекте есть 4 структуры, которые вовлечены в реализацию проекта:
Очень удобно показать структуру результатов проекта, распределенную по всем участникам проекта, до подписания контракта.
Например, проект выполняется с использованием своих и заемных средств. Наверняка спонсоры захотят увидеть, какой именно результат будет получен и за чьи инвестиции.
Иногда можно использовать смешанный подход: на первом уровне фазы проекта, на втором организационные структуры, на третьем — результаты. Управление изменениями Управление изменениями - это совокупность заранее оговоренных процедур и правил, в соответствии с которыми изменения вносятся в проект. Важно отметить, что любое изменение, прежде чем оно будет внесено в план проекта, вначале рассматривается лицами, имеющими соответствующие полномочия, которые ответственны за внесение изменений. После рассмотрения изменение либо принимается, либо отвергается (или откладывается до выяснения обстоятельств). Все изменения, влияющие на продукт проекта, должны быть обязательно одобрены заказчиком. Для этого в правоустанавливающие документы проекта вносится статья, описывающая процедуру рассмотрения и утверждение изменений, а также сроки выполнения этой процедуры каждой из сторон. Изменений не нужно бояться, ими нужно управлять с помощью системы управления изменениями. Для того чтобы внедрить эффективную систему управления изменениями, необходимо выполнить следующее:
Процедура управления изменениями должна выглядеть примерно следующим образом: 1. Подача запроса на изменение. Запрос на изменение должен быть документирован и внесен в базу данных для дальнейшего контроля его статуса. 2. Оценка последствий. Производится оценка степени воздействия предлагаемого изменения на проект. 3. Принятие решения об изменении. Принимается решение о необходимости предложенного изменения или отказе от его реализации. 4. Реализация изменения. Если принято решение об утверждении изменения, необходимо обеспечить выполнение изменения. 5. Контроль. Если изменение выполнено, вопрос может быть снят с контроля, следовательно, статус запроса на изменение должен быть изменен в базе данных. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Экспертная система (ЭС) - это компьютерная программа, которая моделирует рассуждения человека-эксперта в некоторой определенной области и использует для этого базу знаний, содержащую факты и правила об этой области, специальную процедуру логического вывода. Разработка систем, основанных на знаниях, является составной частью исследований по ИИ, и имеет целью создание компьютерных методов решения проблем, обычно требующих привлечения экспертов-специалистов. Экспе́ртная систе́ма (ЭС, англ. expert system) — компьютерная система, способная частично заменить специалиста-эксперта в разрешении проблемной ситуации. При разработке ЭС, как правило, используется концепция "быстрого прототипа". Суть этой концепции состоит в том, что разработчики не пытаются сразу построить конечный продукт. На начальном этапе они создают прототип (прототипы) ЭС. Прототипы должны удовлетворять двум противоречивым требованиям: с одной стороны, они должны решать типичные задачи конкретного приложения, а с другой - время и трудоемкость их разработки должны быть весьма незначительны, чтобы можно было максимально запараллелить процесс накопления и отладки знаний (осуществляемый экспертом) с процессом выбора программных средств. Для удовлетворения указанным требованиям, как правило, при создании прототипа используются разнообразные средства, ускоряющие процесс проектирования. Прототип должен продемонстрировать пригодность методов инженерии знаний для данного приложения. В случае успеха эксперт с помощью инженера по знаниям расширяет знания прототипа о проблемной области. При неудаче может потребоваться разработка нового прототипа или разработчики могут прийти к выводу о непригодности методов ЭС для данного приложения. По мере увеличения знаний прототип может достигнуть такого состояния, когда он успешно решает все задачи данного приложения. Преобразование прототипа ЭС в конечный продукт обычно приводит к перепрограммированию ЭС на языках низкого уровня, обеспечивающих как увеличение быстродействия экспертных систем, так и уменьшение требуемой памяти. В ходе работ по созданию экспертных систем сложилась определенная технология их разработки, включающая шесть следующих этапов: идентификацию, концептуализацию, формализацию, выполнение, тестирование, опытную эксплуатацию. На этапе идентификации определяются задачи, которые подлежат решению, выявляются цели разработки, определяются эксперты и типы пользователей. На этапе концептуализации проводится содержательный анализ проблемной области, выявляются используемые понятия и их взаимосвязи, определяются методы решения задач. На этапе формализации выбираются инструментальные средства и определяются способы представления всех видов знаний, формализуются основные понятия, определяются способы интерпретации знаний, моделируется работа системы, оценивается адекватность целям системы зафиксированных понятий, методов решений, средств представления и манипулирования знаниями. На этапе выполнения осуществляется наполнение базы знаний, создание прототипа ЭС. Главное в создании прототипа заключается в том, чтобы этот прототип обеспечил проверку адекватности идей, методов и способов представления знаний решаемым задачам. Создание первого прототипа должно подтвердить, что выбранные методы решений и способы представления пригодны для успешного решения, по крайней мере, ряда задач из актуальной предметной области, а также продемонстрировать тенденцию к получению высококачественных и эффективных решений для всех задач предметной области по мере увеличения объема знаний. В ходе этапа тестирования производится оценка выбранного способа представления знаний в ЭС в целом. Для этого инженер по знаниям подбирает примеры, обеспечивающие проверку всех возможностей новой ЭС.
На этапе опытной эксплуатации проверяется пригодность экспертных систем для конечного пользователя. Пригодность экспертных систем для пользователя определяется в основном удобством работы с ней и ее полезностью. Под полезностью ЭС понимается ее способность в ходе диалога определять потребности пользователя, выявлять и устранять причины неудач в работе, а также удовлетворять указанные потребности пользователя (решать поставленные задачи). В свою очередь, удобство работы с ЭС подразумевает естественность взаимодействия с ней (общение в привычном, не утомляющем пользователя виде), гибкость ЭС (способность системы настраиваться на различных пользователей, а также учитывать изменения в квалификации одного и того же пользователя) и устойчивость системы к ошибкам (способность не выходить из строя при ошибочных действиях неопытного пользователях). В ходе разработки экспертных систем почти всегда осуществляется ее модификация. Выделяют следующие виды модификации системы: переформулирование понятий и требований, переконструирование представления знаний в системе и усовершенствование прототипа |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
БИЛЕТ 13 |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Искусственный интеллект (ИИ) – это некая система программных средств, имитирующая на компьютере процесс мышления человека. Термин искусственный интеллект был предложен в 1956 г. в Станфордском университете (США). Интеллект представляет собой совокупность фактов и способов их применения для достижения определенной цели. А достижение цели – это применение необходимых правил использования соответствующих фактов. Алгоритм – это формальная процедура, которая гарантирует получение оптимального решения База знаний – это часть ЭС, содержащая предметные знания. Диспетчер – это часть механизма вывода, которая решает когда и в каком порядке применить правила из предметных знаний. Знание – это интеллектуальная информация, используемая в программе. Интерпретатор – это часть механизма вывода, которая решает каким образом применять предметные знания. Механизм вывода – это часть ЭС, содержащая в себе общие сведения о схеме управления процессом решения задачи. Коэффициент уверенности – это число, означающее вероятность или степень уверенности, с которой можно считать данные факты и правила достоверными. Правила – это формальный способ задания знаний в виде:ЕСЛИ <условие>, ТО <действие> Экспертная система – это программа, основанная на знаниях, в которых предметные знания предусмотрены в явном виде и отделены от прочих знаний. Эвристики – это правила, упрощают или ограничивают поиск решения в предметной области. Семантическая сеть – это метод представления знаний в виде графа, где вершинами являются объекты, а дугами – их свойства. Пример.Факт1. Зажженная плита – горячая. Правило1. ЕСЛИ положить руку на зажженную плиту, ТО можно обжечься. Рассмотрим этапы развития систем искусственного интеллект а:
В начале 90-х годов 20 века была принята совершенно новая концепция. Суть ее заключается в том, чтобы сделать программу интеллектуальной, ее нужно снабдить множеством высококачественных специальных знаний некоторой предметной области. Т.о., разрабатываемые системы ИИ должны иметь хорошо развитую базу знаний. В настоящее время наиболее полное развитие этой концепции получило проектирование экспертных систем (ЭС). Система искусственного интеллекта, созданная для решения задач в конкретной предметной области, называется экспертной. ЭС – это сложные программные комплексы, аккумулирующие знания специалистов в конкретных предметных областях и тиражирующие этот эмпирический опыт для консультации менее квалифицированных пользователей. Источником знаний для ЭС служат эксперты в соответствующей предметной области. Основные их свойства:
В процессе проектирования и функционирования ЭС можно выделить следующих участников: 1. Разработчик инструментальных средств проектирования ЭС; 2. Инструментальные средства (ИС) построения ЭС; 3. Сама ЭС; 4. Эксперт; 5. Инженер знаний или администратор БЗ; 6. Пользователь. Инженер знаний – это человек, имеющий навыки в разработке систем ИИ и знающий как надо строить ЭС. Он опрашивает эксперта и организует знания в БЗ. К инструментальным средствам (ИС) проектирования относят язык программирования ЭС и поддерживающие средства, через которые пользователь взаимодействует с ЭС. Взаимодействие участников ЭС.
Рассмотрим компетентность ЭС, сравнивая систему человеческого интеллекта и систему ИИ.
Анализируя преимущества и недостатки этих систем, можно сделать основной вывод о необходимости человека-эксперта, т.к. во многих областях он превосходит ИИ, например, по творчеству, изобретательности, способности передавать информацию и вообще по здравому смыслу. Рассмотрим область применения СИИ: Доказательство теорем. Изучение приемов доказательства теорем сыграло важную роль в развитии искусственного интеллекта. Много неформальных задач, например, медицинская диагностика, применяют при решении методические подходы, которые использовались при автоматизации доказательства теорем. Поиск доказательства математической теоремы требует не только провести дедукцию, исходя из гипотез, но также создать интуитивные предположения о том, какие промежуточные утверждение следует доказать для общего доказательства основной теоремы. Распознавание изображений. Применение искусственного интеллекта для распознавании образов позволила создавать практически работающие системы идентификации графических объектов на основе аналогичных признаков. В качестве признаков могут рассматриваться любые характеристики объектов, подлежащих распознаванию. Признаки должны быть инвариантны к ориентации, размера и формы объектов. Алфавит признаков формируется разработчиком системы. Качество распознавания во многом зависит от того, насколько удачно сложившийся алфавит признаков. Распознавания состоит в априорном получении вектора признаков для выделенного на изображении отдельного объекта и, затем, в определении которой из эталонов алфавита признаков этот вектор отвечает. Машинный перевод и понимание человеческой речи. Задача анализа предложений человеческой речи с применением словаря является типичной задачей систем искусственного интеллекта. Для ее решения был создан язык-посредник, облегчающий сопоставление фраз из разных языков. В дальнейшем этот язык-посредник превратилась в семантическую модель представления значений текстов, подлежащих переводу. Эволюция семантической модели привела к созданию языка для внутреннего представления знаний. В результате, современные системы осуществляют анализ текстов и фраз в четыре основных этапа: морфологический анализ, синтаксический, семантический и прагматический анализ. Игровые программы. В основу большинства игровых программ положены несколько базовых идей искусственного интеллекта, таких как перебор вариантов и самообучения. Одна из наиболее интересных задач в сфере игровых программ, использующих методы искусственного интеллекта, заключается в обучении компьютера игры в шахматы. Она была основана еще на заре вычислительной техники, в конце 50-х годов. В шахматах существуют определенные уровни мастерства, степени качества игры, которые могут дать четкие критерии оценки интеллектуального роста системы. Поэтому компьютерными шахматами активно занимался ученые со всего мира, а результаты их достижений применяются в других интеллектуальных разработках, имеющих реальное практическое значение. В 1974 году впервые прошел чемпионат мира среди шахматных программ в рамках очередного конгресса IFIP (International Federation of Information Processing) в Стокгольме. Победителем этого соревнования стала шахматная программа «Каисса». Она была создана в Москве, в Институте проблем управления Академии наук СССР. Машинная творчество. К одной из областей применений искусственного интеллекта можно отнести программные системы, способные самостоятельно создавать музыку, стихи, рассказы, статьи, дипломы и даже диссертации. Сегодня существует целый класс музыкальных языков программирования (например, язык C-Sound). Для различных музыкальных задач было создано специальное программное обеспечение: системы обработки звука, синтеза звука, системы интерактивного композиции, программы алгоритмической композиции. Экспертные системы. Методы искусственного интеллекта нашли применение в создании автоматизированных консультирующих систем или экспертных систем. Первые экспертные системы были разработаны, как научно-исследовательские инструментальные средства в 1960-х годах прошлого столетия. Они были системами искусственного интеллекта, специально предназначенными для решения сложных задач в узкой предметной области, такой, например, как медицинская диагностика заболеваний. Классической целью этого направления изначально было создание системы искусственного интеллекта общего назначения, которая была бы способна решить любую проблему без конкретных знаний в предметной области. Ввиду ограниченности возможностей вычислительных ресурсов, эта задача оказалась слишком сложной для решения с приемлемым результатом. Коммерческое внедрение экспертных систем произошло в начале 1980-х годов, и с тех пор экспертные системы получили значительное распространение. Они используются в бизнесе, науке, технике, на производстве, а также во многих других сферах, где существует вполне определенная предметная область. Основное значение выражения «вполне определенное», заключается в том, что эксперт-человек способен определить этапы рассуждений, с помощью которых может быть решена любая задача по данной предметной области. Это означает, что аналогичные действия могут быть выполнены компьютерной программой. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Метод экспертных оценок Возрастающая сложность управления организациями требует тщательного анализа целей и задач деятельности, путей и средств их достижения, оценки влияния различных факторов на повышение эффективности и качества работы. Это приводит к необходимости широкого применения экспертных оценок в процессе формирования и выбора решений. Экспертиза как способ получения информации всегда использовалась при выработке решений. Однако научные исследования по ее рациональному проведению были начаты всего три десятилетия назад. Результаты этих исследований позволяют сделать вывод о том, что в настоящее время экспертные оценки являются в основном сформировавшимся научным методом анализа сложных неформализуемых проблем. Сущность метода экспертных оценок заключается в рациональной организации проведения экспертами анализа проблемы с количественной оценкой суждений и обработкой их результатов. Обобщенное мнение группы экспертов принимается как решение проблемы. В процессе принятия решений эксперты выполняют информационную и аналитическую работу по формированию и оценке решений. Все многообразие решаемых ими задач сводится к трем типам: формирование объектов, оценка характеристик, формирование и оценка характеристик объектов. Формирование объектов включает определение возможных событий и явлений, построение гипотез, формулировку целей, ограничений, вари- антов решений, определение признаков и показателей для описания свойств объектов и их взаимосвязей и т.п. В задаче оценки характеристик эксперты производят измерения достоверности событий и гипотез, важно- сти целей, значений признаков и показателей, предпочтений решений. В задаче формирования и оценки характеристик объектов осуществляется комплексное решение первых двух типов задач. Таким образом, эксперт выполняет роль генератора объектов (идей, событий, решений и т.п.) и измерителя их характеристик. При решении рассмотренных задач все множество проблем можно разделить на два класса: с достаточным и недостаточным информационным потенциалом. Для проблем первого класса имеется необходимый объем знаний и опыта по их решению. Поэтому по отношению к этим проблемам эксперты являются качественными источниками и достаточно точными измерителями информации. Для таких проблем обобщенное мнение группы экспертов определяется осреднением их индивидуальных суждений и является близким к истинному. В отношении проблем второго класса эксперты уже не могут рассматриваться как достаточно точные измерители. Мнение одного эксперта может оказаться правильным, хотя оно сильно отличается от мнения всех остальных экспертов. Обработка результатов экспертизы при решении проблем второго класса не может основываться на методах осреднения. Метод экспертных оценок применяется для решения проблем прогнозирования, планирования и разработки программ деятельности, нормирования труда, выбора перспективной техники, оценки качества продукции и др. Для применения метода экспертных оценок в процессе принятия решений необходимо рассмотреть вопросы подбора экспертов, проведения опроса и обработки его результатов Подбор экспертов Подбор количественного и качественного состава экспертов производится на основе анализа широты проблемы, требуемой достоверности оценок, характеристик экспертов и затрат ресурсов. Широта решаемой проблемы определяет необходимость привлечения к экспертизе специалистов различного профиля. Следовательно, минимальное число экспертов определяется количеством различных аспектов, направлений, которые необходимо учесть при решении проблемы. Достоверность оценок группы экспертов зависит от уровня знаний отдельных экспертов и количества членов. Если предположить, что экс- перты являются достаточно точными измерителями, то с увеличением числа экспертов достоверность экспертизы всей группы возрастает. Затраты ресурсов на проведение экспертизы пропорциональны количеству экспертов. С увеличением числа экспертов увеличиваются временные и финансовые затраты, связанные с формированием группы, проведением опроса и обработкой его результатов. Таким образом, повышение достоверности экспертизы связано с увеличением затрат. Располагаемые финансовые ресурсы ограничивают максимальное число экспертов в группе. Оценка числа экспертов снизу и сверху позволяет определить границы общего количества экспертов в группе. Характеристики группы экспертов определяются на основе индивидуальных характеристик экспертов: компетентности (коэффициент компетентности – до экспертизы как самомнение и мнение остальных экспертов или после экспертизы по ее результатам), креативности , отношения к экспертизе, конформизма (подверженность влиянию авторитетов), конструктивности мышления, коллективизма, самокритичности Опрос экспертов Опрос экспертов представляет собой заслушивание и фиксацию в содержательной и количественной форме суждений экспертов по решаемой проблеме. Проведение опроса является основным этапом совместной работы групп управления и экспертов. На этом этапе выполняются следующие процедуры: организационно-методическое обеспечение опроса; постановка задачи и предъявление вопросов экспертам; информационное обеспечение работы экспертов. Вид опроса по существу определяет разновидность метода эксперт- ной оценки. Основными видами опроса являются: анкетирование, интервьюирование, метод Дельфы, мозговой штурм, дискуссия. Обработка экспертных оценок После проведения опроса группы экспертов осуществляется обработка результатов. Исходной информацией для нее являются числовые данные, выражающие предпочтения экспертов, и содержательное обоснование этих предпочтений. Целью обработки является получение обобщенных данных и новой информации, содержащейся в скрытой форме в экс- пертных оценках. На основе результатов обработки формируется решение проблемы. Наличие как числовых данных, так и содержательных высказываний экспертов приводит к необходимости применения качественных и количе- ственных методов обработки результатов группового экспертного оцени- вания. Удельный вес этих методов существенно зависит от класса про- блем, решаемых экспертным оцениванием. В зависимости от целей экспертного оценивания при обработке ре- зультатов опроса решают следующие основные задачи: определение согласованности мнений экспертов; построение обобщенной оценки объектов; определение зависимости между суждениями экспертов; определение относительных весов объектов; оценка надежности результатов экспертизы. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Проблемами, связанными с автоматическим управлением интеллектуальными системами, являются: 1. Разнородные классы объектов управления: информационные ресурсы, решатели задач, пользовательские интерфейсы. Данная проблема является общей для всех задач управления, метод ее решения рассмотрен выше. 2. Разнородность состояний объекта управления (автоматическое управление в периоды функционирования объекта и между этими периодами). Данная проблема состоит в том, что наряду с задачами ручного и автоматического управления интеллектуальной системой в периоды, когда она не функционирует, возникают задачи автоматического управления ею во время ее функционирования. 3. Достижение согласованности механизмов ручного управления с механизмами автоматического управления. Механизмы автоматического управления должны быть согласованы с механизмами ручного управления, чтобы управляющие могли контролировать процессы автоматического управления. 4. Различная степень неопределенности в задачах автоматического управления. Разнородность классов объектов управления пока не позволила найти общих, проблемно-независимых решений для задач автоматического управления, поэтому в настоящее время предлагается использовать и проблемно-зависимые решения. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Экспертная система (ЭС) - это компьютерная программа, которая моделирует рассуждения человека-эксперта в некоторой определенной области и использует для этого базу знаний, содержащую факты и правила об этой области, специальную процедуру логического вывода. Разработка систем, основанных на знаниях, является составной частью исследований по ИИ, и имеет целью создание компьютерных методов решения проблем, обычно требующих привлечения экспертов-специалистов. Экспе́ртная систе́ма (ЭС, англ. expert system) — компьютерная система, способная частично заменить специалиста-эксперта в разрешении проблемной ситуации. Масштабы разработки ЭС предопределили создание специальных инструментальных (аппаратных и программных) средств, систематизированное представление которых составляет содержание рис. 16.4. Следует отметить, что первоначально разработка ЭС осуществлялась на традиционных алгоритмических языках программирования с реализацией на универсальных ЭВМ. В дальнейшем были созданы как специализированные аппаратные и программные средства, так и средства автоматизации программирования. Появились и оболочки ЭС, которые по задумке авторов должны были существенно упростить (и удешевить) разработку систем. Однако в полной мере эти надежды не оправдались (как показало дальнейшее развитие прикладных программных средств не только в области искусственного интеллекта, и не могли оправдаться). Это связано с принципиальной сложностью использования конкретной ЭС (даже весьма эффективной в своей предметной области) для решения совершенно других задач, а именно таким путем создавались первые оболочки ЭС. Еще более проблематичными представляются попытки создания так называемых универсальных оболочек, пригодных для применения “во всех” предметных областях.
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Понятие протокола маршрутизации Сеть Интернет, являющаяся сетью сетей и объединяющая громадное количество различных локальных, региональных и корпоративных сетей, функционирует и развивается благодаря использованию единого протокола передачи данных TCP/IP. Термин TCP/IP включает название двух протоколов:
Основная задача сетей - транспортировка информации от ЭВМ-отправителя к ЭВМ-получателю. В большинстве случаев для этого нужно совершить несколько пересылок. Проблему выбора пути решают алгоритмы маршрутизации. Если транспортировка данных осуществляется дейтограммами, для каждой из них эта задача решается независимо. При использовании виртуальных каналов выбор пути выполняется на этапе формирования этого канала. В Интернет с его IP-дейтограммами реализуется первый вариант (если не рассматривать виртуальные сети), а в ISDN и ATM - второй. Для решения проблемы маршрутизации используются специальные устройства, называемые маршрутизаторами. Маршрутизация подразумевает два параллельных процесса: подготовку маршрутной таблицы и переадресацию дейтограмм с помощью этой таблицы. Формирование маршрутной таблицы производится посредством протоколов маршрутизации или под воздействием инструкций сетевого администратора. Протокол IP обеспечивает передачу информации между компьютерами сети. Рассмотрим работу данного протокола по аналогии с передачей информации с помощью обычной почты. Для того чтобы письмо дошло по назначению, на конверте указывается адрес получателя (кому письмо) и адрес отправителя (от кого письмо). Аналогично передаваемая по сети информация "упаковывается в конверт", на котором "пишутся" IP-адреса компьютеров получателя и отправителя, например "Кому: 198.78.213.185", "От кого: 193.124.5.33". Содержимое конверта на компьютерном языке называется IP-пакетом и представляет собой набор байтов. В процессе пересылки обыкновенных писем они сначала доставляются на ближайшее к отправителю почтовое отделение, а затем передаются по цепочке почтовых отделений на ближайшее к получателю почтовое отделение. На промежуточных почтовых отделениях письма сортируются, то есть определяется, на какое следующее почтовое отделение необходимо отправить то или иное письмо. IP-пакеты на пути к компьютеру-получателю также проходят через многочисленные промежуточные серверы Интернета, на которых производится операция маршрутизации. В результате маршрутизации IP-пакеты направляются от одного сервера Интернета к другому, постепенно приближаясь к компьютеру-получателю. Internet Protocol (IP) обеспечивает маршрутизацию IP-пакетов, то есть доставку информации от компьютера-отправителя к компьютеру-получателю. Понятие автономной системы В технологии маршрутизации существует два понятия автономная система и домен маршрутизации Автономная система (autonomous system, AS) - это набор сетей, которые находятся под единым административным управлением и в которых используются единая стратегия и правила маршрутизации. Автономная система для внешних сетей представляется как некий единый объект. Домен маршрутизации - это совокупность сетей и маршрутизаторов, использующих один и тот же протокол маршрутизации. В сети Интернет термин автономная система используется для описания крупных логически объединенных сетей, например сетей Internet провайдеров. Каждая такая AS имеет в качестве своего идентификатора шестнадцати-битовое число. Для публичных сетей Internet провайдеров номер AS выдает и регистрирует Американский реестр Internet номеров (American Registry of Internet Numbers - ARIN), согласно RFC 2270 для частных AS выделен диапазон номеров 64512 - 65534, автономная система 65535 зарезервирована под служебные задачи. Протоколы маршрутизации делятся на две категории: внутренние (Interior) и внешние (Exterior). Внешние и внутренние протоколы маршрутизации Внутренние протоколы имеют общее название IGP (Interior Gateway Protocol, протоколы внутреннего шлюза). К ним относятся любой протокол маршрутизации, используемый исключительно внутри автономной системы, к таким протоколам относятся, например RIP, EIGRP и OSPF. Каждый IGP протокол представляет один домен маршрутизации внутри AS. В пределах автономной системы может существовать множество IGP доменов
Маршрутизаторы, поддерживающие один и тот же протокол IGP обмениваются информацией друг с другом в пределах домена маршрутизации. Маршрутизаторы, работающие более чем с одним протоколом IGP, например, использующие протоколы RIP и OSPF, являются участниками двух отдельным доменов маршрутизации. Такие маршрутизаторы называются граничными. Внешние протоколы - EGP (Exterior Gateway Protocol протоколы внешнего шлюза) - это протоколы маршрутизации, обеспечивающие маршрутизацию между различными автономными системами. Протокол BGP (Border Gateway Protocol, протокол пограничного шлюза) является одним из наиболее известных межсистемных протоколов маршрутизации. Протоколы EGP обеспечивают соединение отдельных AS и транзит передаваемых данных между этими AS и через AS
П Обзор протоколов маршрутизации Дистанционно-векторные протоколы RIP — Routing Information Protocol; IGRP — Interior Gateway Routing Protocol (лицензированный протокол Cisco Systems); BGP — Border GateWay Protocol; EIGRP — Enhanced Interior Gateway Routing Protocol (на самом деле он гибридный — объединяет свойства дистанционно-векторных протоколов и протоколов по состоянию канала; лицензированный протокол Cisco Systems); AODV Протоколы состояния каналов связи IS-IS — Intermediate System to Intermediate System (стек OSI); OSPF — Open Shortest Path First; NLSP — NetWare Link-Services Protocol (стек Novell); HSRP и CARP — протоколы резервирования шлюза в Ethernet-сетях. OLSR TBRPF Протоколы междоменной маршрутизации EGP; BGP; IDRP; IS-IS level 3; Протоколы внутридоменной маршрутизации RIP; IS-IS level 1-2; OSPF; IGRP; EIGRP. RIP Протокол маршрутной информации (англ. RoutingInformation Protocol) — один из самых простых протоколовмаршрутизации. Применяется в небольших компьютерных сетях, позволяетмаршрутизаторам динамически обновлять маршрутную информацию (направление и дальность в хопах), получая ее от соседних маршрутизаторов. RIP — так называемый протокол дистанционно-векторной маршрутизации, который оперирует транзитными участками в качестве метрики маршрутизации. Максимальное количество хопов, разрешенное в RIP — 15 (метрика 16 означает «бесконечно большую метрику»). Каждый RIP-маршрутизатор по умолчанию вещает в сеть свою полную таблицу маршрутизации раз в 30 секунд, довольно сильно нагружая низкоскоростные линии связи. RIP работает на 7 уровне (уровень приложения) стека TCP/IP, используя UDP порт 520. В современных сетевых средах RIP — не самое лучшее решение для выбора в качестве протокола маршрутизации, так как его возможности уступают более современным протоколам, таким как EIGRP, OSPF. Ограничение на 15 хопов не дает применять его в больших сетях. Преимущество этого протокола — простота конфигурирования. EIGRP EIGRP (англ. Enhanced Interior Gateway Routing Protocol) — протоколмаршрутизации, разработанный фирмой Cisco на основе протокола IGRPтой же фирмы. Релиз протокола состоялся в 1994 году. EIGRP использует механизм DUAL для выбора наиболее короткого маршрута. Более ранний и практически не используемый ныне протокол IGRP был создан как альтернатива протоколу RIP (до того, как был разработанOSPF). После появления OSPF, Cisco представила EIGRP — переработанный и улучшенный вариант IGRP, свободный от основного недостатка дистанционно-векторных протоколов — особых ситуаций с зацикливанием маршрутов — благодаря специальному алгоритмураспространения информации об изменениях в топологии сети. EIGRP более прост в реализации и менее требователен к вычислительным ресурсам маршрутизатора чем OSPF. Также EIGRP имеет более продвинутый алгоритм вычисления метрики, основной особенностью которого служат два критерия: При вычислении метрики используется минимальная пропускная способность (bandwidth) для данного маршрута (а не сумму цен (cost)как в случае с OSPF), что позволяет более точно определять более выгодный путь (маршрут). В формуле вычисления метрики есть возможность учитывать загрузку и надежность интерфейсов на пути. Стоит заметить, что усложнение формулы вычисления метрик приводит и к усложнению понимания метрики администратором. Хотя многие сторонники OSPF и считают, что ,при прочих равных, EIGRP отрабатывает изменение топологии медленнее чем OSPF, но это скорее заблуждение, поскольку при малом количестве маршрутизаторов EIGRP отрабатывает быстрее, а при усложнении схемы дизайн и архитектура протокола OSPF требует более тщательного внедрения (создание зон и межзонных отношений), что также замедляет обмен маршрутами и усложняет количество вычислений требуемых для выбора лучшего маршрута. В итоге EIGRP работает сравнительно одинаково, а в некоторых простейших или наоборот более сложных топологиях даже быстрее чем другие, существующие на данный момент, протоколы маршрутизации. Еще одно преимущество протокола EIGRP в том, что он способен производить суммаризацию на любом маршрутизаторе на пути, поскольку является протоколом класса "вектор расстояния" (Distance Vector), информация передается от соседа к соседу, где каждый следующий выбирает только лучший маршрут, отдаваемый соседу. Единственным недостатком протокола EIGRP на данный момент является его ограниченность в использовании оборудования только компании Cisco. Хотя в феврале 2013 года Cisco открыла EIGRP, его внедрение в маршрутизаторы других производителей официально не объявлено. OSPF Протокол OSPF (Open Shortest Pass First, RFC-1245-48, RFC-1583-1587, std-54, алгоритмы предложены Дикстрой) является альтернативой RIP в качестве внутреннего протокола маршрутизации. OSPF представляет собой протокол состояния маршрута (в качестве метрики используется - коэффициент качества обслуживания). Каждый маршрутизатор обладает полной информацией о состоянии всех интерфейсов всех маршрутизаторов (переключателей) автономной системы. Протокол OSPF реализован в демоне маршрутизации gated, который поддерживает также RIP и внешний протокол маршрутизации BGP. Автономная система может быть разделена на несколько областей, куда могут входить как отдельные ЭВМ, так и целые сети. В этом случае внутренние маршрутизаторы области могут и не иметь информации о топологии остальной части AS. Сеть обычно имеет выделенный (designated) маршрутизатор, который является источником маршрутной информации для остальных маршрутизаторов AS. Каждый маршрутизатор самостоятельно решает задачу оптимизации маршрутов. Если к месту назначения ведут два или более эквивалентных маршрута, информационный поток будет поделен между ними поровну. Переходные процессы в OSPF завершаются быстрее, чем в RIP. В процессе выбора оптимального маршрута анализируется ориентированный граф сети. На иллюстративном рис. приведена схема узлов (A-J) со значениями метрики для каждого из отрезков пути. Анализ графа начинается с узла A (Старт). Пути с наименьшим суммарным значением метрики считаются наилучшими. Именно они оказываются выбранными в результате рассмотрения графа (“кратчайшие пути“).
EGP EGP (сокр. от англ. Exterior Gateway Protocol, протокол внешнего шлюза) — устаревший протокол обмена информации между маршрутизаторами нескольких автономных систем. Разработан в 82-84 годах. Впоследствии был заменён на BGP. EGP не является протоколом маршрутизации пакетов данных. Он предназначен для обеспечения взаимодействия между шлюзами различных AS, для обмена информацией согласования алгоритмов маршрутизации между ними, а не для управления перемещением самой информации. Каждая из AS может работать со своим (RIP или OSPF) a EGP осуществляет управление маршрутизацией между AS. Все из менения обеспечивающие доступ AS к главной магистрали - backbone, должны быть также сделаны самой AS. Кроме того EGP не строит схем и алгоритмов маршрутизации данных. Любая часть EGP сети Internet должна представлять собой структуру дерева, у которого стержневой роутер является корнем, и в пределах которого отсутствуют петли между другими AS. Это ограничение является основным ограничением EGP. Оно стало причиной его постепенного вытеснения другими, более совершенными протоколами внешних роутеров. Несмотря на то, что EGP является динамическим протоколом маршрутизации, схема его работы очень проста. Он не может принимать интеллектуальных решений о маршрутизации. Корректировки маршрутизации EGP содержат информацию только о досягаемости сетей. Другими словами, они указывают, что в определенные сети информационные пакеты попадают через определенные роутеры. EGP выполняет три основные функции: Маршрутизаторы, работающие с EGP, организуют для себя определенный набор соседей. Соседи - это просто другие маршрутизаторы, с которыми какой-нибудь роутер хочет коллективно пользоваться информацией о досягаемости сетей (какие-либо указания о географическом соседстве не включаются). Маршрутизаторы EGP опрашивают своих соседей для того, чтобы убедиться в их работоспособности. Маршрутизаторы EGP отправляют сообщения о корректировках, содержащих информацию о досягаемости сетей в пределах своих AS. BGP BGP (англ. Border Gateway Protocol, протокол граничного шлюза) — основной протокол динамической маршрутизации в Интернете. Протокол BGP предназначен для обмена информацией о достижимости подсетей междуавтономными системами (АС), то есть группами маршрутизаторов под единым техническим управлением, использующимипротокол внутридоменной маршрутизации для определения маршрутов внутри себя и протокол междоменной маршрутизации для определения маршрутов доставки пакетов в другие АС. Передаваемая информация включает в себя список АС, к которым имеется доступ через данную систему. Выбор наилучших маршрутов осуществляет исходя из правил, принятых в сети. BGP поддерживает бесклассовую адресацию и использует суммирование маршрутов для уменьшения таблиц маршрутизации. С 1994 годадействует четвёртая версия протокола, все предыдущие версии являются устаревшими. BGP, наряду с DNS, является одним из главных механизмов, обеспечивающих функционирование Интернета. BGP является протоколом прикладного уровня и функционирует поверх протокола транспортного уровня TCP (порт 179). После установки соединения передаётся информация обо всех маршрутах, предназначенных для экспорта. В дальнейшем передаётся только информация об изменениях в таблицах маршрутизации. При закрытии соединения удаляются все маршруты, информация о которых передана противоположной стороной. Основным предназначением BGP является обеспечение обмена информацией с другими BGP-системами о досягаемости определенных сетей или хостов. Эта информация должна содержать набор маршрутов к данной сети, т е. должны быть указаны все промежуточные AS. Такой информации вполне достаточно для того, чтобы построить граф соединений между AS и контролировать возможность образования петель. Хосты работающие с ВОР, не принимают участие в процедуре маршрутизации информационных пакетов. Они предназначены только для обмена информацией с роутерами других AS. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
БИЛЕТ 14 |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Вычислительная машина – это комплекс технических и программных средств, предназначенных для автоматизации подготовки и решения задач пользователя. Вычислительная система – это совокупность взаимосвязанных и взаимосоединенных процессоров или вычислительных машин, периферийного оборудования и программного обеспечения для решения задач пользователя. Основной отличительной чертой вычислительных систем является наличие в них средств, реализующих параллельную обработку за счет построения параллельных ветвей вычисления, что как правило не предусматривается в вычислительных машинах. Очевидно, что различия между вычислительными машинами и вычислительными системами не могут быть точно определены (вычислительные машины даже с одним процессором обладает разными средствами распараллеливания, а вычислительные системы могут состоять из традиционных вычислительных машин или процессоров). Архитектура ВС – совокупность характеристик и параметров, определяющих функционально-логичную и структурно-организованную систему и затрагивающих в основном уровень параллельно работающих вычислителей. Понятие архитектуры охватывает общие принципы построения и функционирования, наиболее существенные для пользователя Архитектура фон Неймана - модель реализации ВС с одним устройством обработки (процессором) и одним устройством хранения (памятью)(см. рис. 2). Память используется для хранения как программ, так и данных. Архитектура предложена конструкторами ВС ENIAC Мокли и Экертом и популяризирована математиком Джоном фон Нейманом [6]. На момент появления данной архитектуры программы в ВС были либо жестко зашиты в логику работы процессора ВС, либо задавались с помощью перекоммутации связей у процессора. Вынесение программ в память сильно упростило их модификацию. Выполнение команд происходит в циклах, каждый из которых содержит следующие стадии: 1) выборка очередной команды для исполнения (по адресу регистра-указателя команд), 2) декодирование кода команды, выработка управляющих сигналов для арифметического-логического устройства (АЛУ), 3) чтение требуемых операндов из памяти и их размещение в регистрах процессора, 4) исполнение команды в АЛУ и запись результатов в память или регистры процессора.
Рис. 2. Архитектура фон Неймана Размещение данных и программ в одной памяти позволяет строить самомодифицирующиеся программы. Это позволяет реализовывать необычайно гибкие решения. Однако, с другой стороны, ошибки в программах могут приводить к порче как данных, так и самих программ. С момента своего появления и по настоящий день архитектура фон Неймана является эталоном для последовательных ВС. Хотя в чистом виде она сейчас не применяется даже в самых простых ВС. Узкое место данной архитектуры ― пропускная способность шины между процессором и памятью. При доступе к памяти процессор простаивает. На момент появления архитектуры скорости работы процессора и памяти были приблизительно одинаковы. Сейчас скорость работы процессора существенно выше, чем у памяти. Для преодоления узкого места был предложен ряд усовершенствований этой базовой архитектуры. Два основных из них ― это использование конвейера команд (см. главу 3) и использование кэш памяти. Кэш память ― память более малого размера, чем оперативная. Но она более быстрая и расположена в процессоре. Часто используемые данные хранятся в кэш памяти, что исключает необходимость их чтения из оперативной памяти через шину. Гарвардская архитектура[7] - архитектура последовательных ВС, в которой память физически и логически разделена на две части: память программ и память данных (см. рис. 3). Впервые архитектура была реализована на машине Mark I, построенной в Гарвардском университете. Блок управления может считывать команды из памяти программ. АЛУ может считывать и записывать данные из памяти данных. Так как для доступа к памяти программ и памяти данных используются разные каналы, то возможен одновременный доступ к ним. Кроме этого, они могут иметь разные физические характеристики и логическую организацию (размер и разрядность слова)
В современных ВС Гарвардская архитектура используется в сигнальных (DSP) процессорах и в микроконтроллерах. Микроконтроллер - микропроцессор для встраиваемых и разнообразных специализированных ВС. Микроконтроллер отличается от обычного процессора пониженным энегропотреблением, часто малым размером и малым числом выводов на корпусе. Также он может иметь дополнительные возможности, таке как оцифровка аналогового сигнала, интегрированный интерфейс для связи. Типичный микроконтроллер (PIC, Atmel AVR8) имеет модифицированную Гарвардскую архитектуру. Для программного обеспечения микроконтроллеров надежность гораздо важнее возможности построения самомодифицирующихся программ. Размещение программ в отдельной памяти, которая может записываться только при программировании микроконтроллера, исключает возможность случайной порчи программ. При этом разрядность памяти программ и памяти данных, а также шины доступа к ним, различны. В частности, все микроконтроллеры PIC12, PIC16 фирмы Microchip имеют 8-битную память данных, а разрядность памяти программ у них различна: PIC12 имеют 12 битную память программ, а РЮШ - 14 битную. По системе команд различаются: • CISC-архитектура (Complicated Instruction Set Computer) - архитектура с развитой системой команд. Система команд процессорного ядра имеет инструкции разного формата: однобайтовые, двухбайтовые, трехбайтовые. Различные инструкции при этом имеют и существенно разное время исполнения. • RISC-архитектура (Reduced Instruction Set Computer) - архитектура с сокращенным набором команд. Одна инструкция, как правило, занимает только одну ячейку памяти, и все инструкции имеют равное время исполнения. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Эксперимент считают перспективным, если: - Объектом исследования служат новые исследования, явления, материалы, процессы и конструкции; - Проверяются теории или гипотезы, а также устанавливаются границы их применимости; - Получаются точные количественные или новые качественные данные об известных свойствах процессов, явлений, материалов и конструкций. Цель эксперимента определяет выбор метода. Для того чтобы эксперимент был действительно перспективным необходимо выбрать соответствующий метод исследования. Неправильный выбор приводит к получению избыточной или недостаточной информации, удорожанию и усложнению эксперимента, а иногда и к ошибочным результатам. Математические методы планирования эксперимента – это новый кибернетический подход к инженерным исследованиям, имеющим экспериментальный характер. Внедрение математических методов планирования эксперимента позволяет в значительной степен исключить слепой хаотический поиск, заменить его научно обоснованной программой проведения экспериментального исследования, включающей объективную оценку результатов эксперимента на всех последовательных этапах исследования. Отметим список задач, которыми занимается планирование эксперимента:
Даже при не полном знании о механизме процесса путём направленного эксперимента можно получить его математическую модель. Можно сказать, что там, где есть эксперимент, имеет место и наука о его проведении – планирование эксперимента. На какие вопросы даёт ответ планирование эксперимента:
Следовательно, задача, которой занимается планирование эксперимента, может быть сформулирована так: "Сколько и каких опытов следует провести и как обработать их результаты, чтобы ответить на заранее заданный вопрос с заранее заданной точностью при минимальном возможном числе опытов". Эта вечная для экспериментатора задача, которая решалась обычно интуитивными методами, теперь поставлена на научную основу]. Известно, что новая наука может возникнуть, если существует объективная необходимость ее появления и имеется предмет новой науки, представляющий общенаучный интерес. Сказанное в полной мере относится и к теории планирования эксперимента. Предмет исследования этого научного направления – эксперимент. Однако особенности планирования, постановки эксперимента рассматриваются и в физике, и в химии, и в прикладных науках. Для того чтобы эксперимент стал предметом исследования отдельного научного направления, необходимо, чтобы он характеризовался некоторыми чертами, общими для любого эксперимента независимо от того, в какой конкретной области знаний эксперимент проводится. Такими общими чертами эксперимента является необходимость: 1) контролировать любой эксперимент, т.е. исключать влияние внешних переменных, не принятых исследователем по тем или иным причинам к рассмотрению; 2) определять точность измерительных приборов и получаемых данных; 3) уменьшать до разумных пределов число переменных в эксперименте; 4) составлять план проведения эксперимента, наилучший с той или иной точки зрения; 5) проверять правильность полученных результатов и их точность; 6) выбирать способ обработки экспериментальных данных и форму представления результатов; 7) анализировать полученные результаты и давать их интерпретацию в терминах той области, где эксперимент проводится. Планирование экспериментов имеет следующие цели:
Таким образом, целью любого эксперимента является получение информации об исследуемом объекте. План эксперимента на компьютере представляет собой метод получения с помощью эксперимента необходимой информации. Таким образом, проблема проведения эксперимента с минимальными затратами и высокоэффективным использованием средств вычислительной техники весьма актуальна. Изучение сложных объектов, являющихся по своей природе стохастическими, возможна лишь с помощью методов планирования и обработки результатов эксперимента. Планирование эксперимента – это процедура выбора числа и условий проведения опытов, необходимых и достаточных для решения поставленной задачи с требуемой точностью Под экспериментом будем понимать совокупность операций совершаемых над объектом исследования с целью получения информации об его свойствах. Эта совокупность может быть весьма сложной, но её всегда можно разложить на отдельные элементы, каждый из которых мы называем опытом. Эксперимент, в котором исследователь по своему усмотрению может изменять условия его проведения, называется активным экспериментом. Если исследователь не может самостоятельно изменять условия его проведения, а лишь регистрирует их, то это пассивный эксперимент. Важнейшей задачей методов обработки полученной в ходе эксперимента информации является задача построения математической модели изучаемого явления, процесса, объекта. Ее можно использовать и при анализе процессов и при проектировании объектов. Можно получить хорошо аппроксимирующую математическую модель, если целенаправленно применяется активный эксперимент. Другой задачей обработки полученной в ходе эксперимента информации является задача оптимизации, т.е. нахождения такой комбинации влияющих независимых переменных, при которой выбранный показатель оптимальности принимает экстремальное значение План эксперимента – совокупность данных определяющих число, условия и порядок проведения опытов. Цель планирования эксперимента – нахождение таких условий и правил проведения опытов при которых удается получить надежную и достоверную информацию об объекте с наименьшей затратой труда, а также представить эту информацию в компактной и удобной форме с количественной оценкой точности. Пусть интересующее нас свойство (Y) объекта зависит от нескольких (n) независимых переменных (Х1, Х2, …, Хn) и мы хотим выяснить характер этой зависимости – Y=F(Х1, Х2, …, Хn), о которой мы имеем лишь общее представление. Величина Y – называется «отклик», а сама зависимость Y=F(Х1, Х2, …, Хn) – "функция отклика". Отклик должен быть определен количественно. Однако могут встречаться и качественные признаки Y. В этом случае возможно применение рангового подхода. Пример рангового подхода – оценка на экзамене, когда одним числом оценивается сложный комплекс полученных сведений о знаниях студента. Независимые переменные Х1, Х2, …, Хn – иначе факторы, также должны иметь количественную оценку. Если используются качественные факторы, то каждому их уровню должно быть присвоено какое-либо число. Важно выбирать в качестве факторов лишь независимые переменные, т.е. только те которые можно изменять, не затрагивая другие факторы. Факторы должны быть однозначными. Для построения эффективной математической модели целесообразно провести предварительный анализ значимости факторов (степени влияния на функцию), их ранжирование и исключить малозначащие факторы. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Системой распознавания образов будем называть класс систем искусственного интеллекта, обеспечивающих: – формирование конкретных образов объектов и обобщенных образов классов; – обучение, т.е. формирование обобщенных образов классов на основе ряда примеров объектов, классифицированных (т.е. отнесенных к тем или иным категориям – классам) учителем и составляющих обучающую выборку; – самообучение, т.е. формирование кластеров объектов на основе анализа неклассифицированной обучающей выборки; – распознавание, т.е. идентификацию (и прогнозирование) состояний объектов, описанных признаками, друг с другом и с обобщенными образами классов; – измерение степени адекватности модели; – решение обратной задачи идентификации и прогнозирования (обеспечивается не всеми моделями). Распознавание – это операция сравнения и определения степени сходства образа данного конкретного объекта с образами других конкретных объектов или с обобщенными образами классов, в результате которой формируется рейтинг объектов или классов по убыванию сходства с распознаваемым объектом. Ключевым моментом при реализации операции распознавания в математической модели является выбор вида интегрального критерия или меры сходства, который бы на основе знания о признаках конкретного объекта позволил бы количественно определить степень его сходства с другими объектами или обобщенными образами классов. В ортонормированном пространстве, осями которого являются шкалы отношений, вполне естественным является использовать в качестве такой меры сходства Евклидово расстояние. Однако, такие пространства на практике встречаются скорее как исключение из правила, а операция ортонормирования является довольно трудоемкой в вычислительном отношении и приводит к обеднению модели, а значит ее не всегда удобно и целесообразно осуществлять. Поэтому актуальной является задача выбора или конструирования интегрального критерия сходства, применение которого было бы корректно и в неортонормированных пространствах. Кроме того, этот интегральный критерий должен быть устойчив к наличиюшума, т.е. к неполноте и искажению как в исходных данных, так и самой численной модели. Требование устойчивости к наличию шума математически означает, что результат применения интегрального критерия к сигналу, состоящему только из белого шума, должен быть равным нулю. Это значит, что в качестве интегрального критерия может быть применена функция, используемая при определении самого понятия "белый шум", т.е. свертка, скалярное произведение, корреляция. Проблема распознавания образов сводится к двум задачам: обучения и распознавания. Поэтому, прежде чем сформулировать задачу обучения распознаванию образов уточним, в чем смысл их распознавания. Простейшим вариантом распознавания является строгий запрос на поиск объекта в базе данных по его признакам, который реализуется в информационно-поисковых системах. При этом каждому полю соответствует признак (описательная шкала), а значению поля – значение признака (градация описательной шкалы). Если в базе данных есть записи, все значения заданных полей которых точно совпадают со значениями, заданными в запросе на поиск, то эти записи извлекаются в отчет, иначе запись не извлекается. Более сложными вариантами распознавания является нечеткий запрос с неполнотой информации, когда не все признаки искомых объектов задаются в запросе на поиск, т.к. не все они известны, и нечеткий запрос с шумом, когда не все признаки объекта известны, а некоторые считаются известными ошибочно. В этих случаях из базы данных извлекаются все объекты, у которых совпадает хотя бы один признак и в отчете объекты сортируются (ранжируются) в порядке убывания количества совпавших признаков. При этом при определении ранга объекта в отсортированном списке все признаки считаются имеющими одинаковый "вес" и учитывается только их количество. Однако: – во-первых, на самом деле признаки имеют разный вес, т.е. один и тот же признак в разной степени характерен для различных объектов; – во-вторых, нас могут интересовать не столько сами объекты, извлекаемые из базы данных прецедентов по запросам, сколько классификация самого запроса, т.е. отнесение его к определенной категории, т.е. к тому или иному обобщенному образу класса. Если реализация строгих и даже нечетких запросов не вызывает особых сложностей, то распознавание как идентификация с обобщенными образами классов, причем с учетом различия весов признаков представляет собой определенную проблему. Обучение осуществляется путем предъявления системе отдельных объектов, описанных на языке признаков, с указанием их принадлежности тому или другому классу. При этом сама принадлежность к классам сообщается системе человеком – Учителем (экспертом). В результате обучения распознающая система должна приобрести способность: 1. Относить объекты к классам, к которым они принадлежат (идентифицировать объекты верно). 2. Не относить объекты к классам, к которым они не принадлежат (неидентифицировать объекты ошибочно). Эта и есть проблема обучения распознаванию образов, и состоит она в следующем: 1. В разработке математической модели, обеспечивающей: обобщение образов конкретных объектов и формирование обобщенных образов классов; расчет весов признаков; определение степени сходства конкретных объектов с классами и ранжирование классов по степени сходства с конкретным объектом, включая и положительное, и отрицательное сходство. 2. В наполнении этой модели конкретной информацией, характеризующей определенную предметную область. Распознаванием образов называются задачи установления отношений эквивалентности между конкретными и обобщенными образами-моделями объектов реального или идеального мира. Отношения эквивалентности выражают принадлежность оцениваемых объектов к каким–либо классам, рассматриваемым как самостоятельные семантические единицы. При построении алгоритмов распознавания классы эквивалентности могут задаваться исследователем, который пользуется собственными содержательными представлениями или использует внешнюю дополнительную информацию о сходстве и различии объектов в контексте решаемой задачи. Тогда говорят о "распознавании с учителем". В противном случае, т.е. когда автоматизированная система решает задачу классификации без привлечения внешней обучающей информации, говорят об автоматической классификации или "распознавании без учителя". Большинство алгоритмов распознавания образов требует привлечения весьма значительных вычислительных мощностей, которые могут быть обеспечены только высокопроизводительной компьютерной техникой. используется следующая типология методов распознавания образов: – методы, основанные на принципе разделения; – статистические методы; – методы, построенные на основе "потенциальных функций"; – методы вычисления оценок (голосования); – методы, основанные на исчислении высказываний, в частности на аппарате алгебры логики. В основе данной классификации лежит различие в формальных методах распознавания образов и поэтому опущено рассмотрение эвристического подхода к распознаванию, получившего полное и адекватное развитие в экспертных системах. Эвристический подход основан на трудно формализуемых знаниях и интуиции исследователя. При этом исследователь сам определяет, какую информацию и каким образом система должна использовать для достижения требуемого эффекта распознавания. Подобная типология методов распознавания с той или иной степенью детализации встречается во многих работах по распознаванию. В то же время известные типологии не учитывают одну очень существенную характеристику, которая отражает специфику способа представления знаний о предметной области с помощью какого–либо формального алгоритма распознавания образов. Выделяет два основных способа представления знаний: – интенсиональное, в виде схемы связей между атрибутами (признаками). – экстенсиональное, с помощью конкретных фактов (объекты, примеры). Интенсиональное представление фиксируют закономерности и связи, которыми объясняется структура данных. Применительно к диагностическим задачам такая фиксация заключается в определении операций над атрибутами (признаками) объектов, приводящих к требуемому диагностическому результату. Интенсиональныепредставления реализуются посредством операций над значениями атрибутов и не предполагают произведения операций над конкретными информационными фактами (объектами). В свою очередь, экстенсиональные представления знаний связаны с описанием и фиксацией конкретных объектов из предметной области и реализуются в операциях, элементами которых служат объекты как целостные системы. Описанные выше два фундаментальных способа представления знаний позволяют предложить следующую классификацию методов распознавания образов: – интенсиональные методы, основанные на операциях с признаками. – экстенсиональные методы, основанные на операциях с объектами. Необходимо особо подчеркнуть, что существование именно этих двух (и только двух) групп методов распознавания: оперирующих с признаками, и оперирующих с объектами, на наш взгляд, глубоко закономерно. С этой точки зрения ни один из этих методов, взятый отдельно от другого, не позволяет сформировать адекватное отражение предметной области. Между этими методами существует отношение дополнительности , поэтому перспективные системы распознавания должны обеспечивать реализацию обоих этих методов, а не только какого–либо одного из них. Таким образом, в основу классификации методов распознавания, положены фундаментальные закономерности, лежащие в основе человеческого способа познания вообще, что ставит ее в совершенно особое (привилегированное) положение по сравнению с другими классификациями, которые на этом фоне выглядят более легковесными и искусственными. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
хDSL (англ. digital subscriber line, цифровая абонентская линия) — семейство технологий, позволяющих значительно повысить пропускную способность абонентской линии телефонной сети общего пользования путём использования эффективных линейных кодов и адаптивных методов коррекции искажений линии на основе современных достижений микроэлектроники и методов цифровой обработки сигнала. Технологии хDSL появились в середине 90-х годов как альтернатива цифровому абонентскому окончанию ISDN. В аббревиатуре xDSL символ «х» используется для обозначения первого символа в названии конкретной технологии, а DSL обозначает цифровую абонентскую линию DSL (англ. Digital Subscriber Line — цифровая абонентская линия; также есть другой вариант названия — Digital Subscriber Loop — цифровой абонентский шлейф). Технологии хDSL позволяют передавать данные со скоростями, значительно превышающими те скорости, которые доступны даже лучшим аналоговым и цифровым модемам. Эти технологии поддерживают передачу голоса, высокоскоростную передачу данных и видеосигналов, создавая при этом значительные преимущества как для абонентов, так и для провайдеров. Многие технологии хDSL позволяют совмещать высокоскоростную передачу данных и передачу голоса по одной и той же медной паре. Существующие типы технологий хDSL различаются в основном по используемой форме модуляции и скорости передачи данных. Службы xDSL разрабатывались для достижения определенных целей: они должны работать на существующих телефонных линиях, они не должны мешать работе различной аппаратуры абонента, такой как телефонный аппарат, факс и т. д., скорость работы должна быть выше теоретического предела в 56Кбит/сек., и наконец, они должны обеспечивать постоянное подключение. Широкое распространение технологий хDSL должно сопровождаться некоторой перестройкой работы поставщиков услуг Интернета и поставщиков услуг телефонных сетей, так как их оборудование теперь должно работать совместно. Возможен также вариант, когда альтернативный оператор связи берёт оптом в аренду большое количество абонентских окончаний у традиционного местного оператора или же арендует некоторое количество модемов в DSLAM. К основным типам xDSL относятся ADSL, HDSL, IDSL, MSDSL, PDSL, RADSL, SDSL, SHDSL, UADSL, VDSL. Все эти технологии обеспечивают высокоскоростной цифровой доступ по абонентской телефонной линии. Некоторые технологии xDSL являются оригинальными разработками, другие представляют собой просто теоретические модели, в то время как третьи уже стали широко используемыми стандартами. Основным различием данных технологий являются методы модуляции, используемые для кодирования данных. WiMAX Wi-Fi EDGE Особенности GPRS GPRS CSD Достоинства и недостатки WAP WAP (Wireless Application Protocol) WAP (Wireless Application Protocol) — это протокол беспроводного доступа к информационным и сервисным ресурсам Интернета непосредственно с мобильных телефонов. WAP-сайты располагаются на веб-серверах и представлены в специальном формате Wireless Markup Language (WML). Используется, как правило, вместе с CSD. Достоинства: Данный сервис доступен на большинстве мобильных телефонов Удобства просмотра ресурсов, созданных специально для мобильных телефонов Траффик меньше, чем при скачивании обычных ресурсов Недостатки: ограниченность интернет-ресурсов, доступных к просмотру, из-за особенностей формата. Неудобство настройки WAP-браузера Circuit Switched Data (CSD) — технология передачи данных, разработанная для мобильных телефонов стандарта GSM. Скорость передачи данных: до 9,6 кбит/с. GPRS (англ. General Packet Radio Service — пакетная радиосвязь общего пользования) — надстройка над технологией мобильной связи GSM, осуществляющая пакетную передачу данных. GPRS позволяет пользователю сети сотовой связи производить обмен данными с другими устройствами в сети GSM и с внешними сетями, в том числе Интернет. Теоретический максимум скорости: 171,2 кбит/c Доступность в любой точке, над которой развернута GSM-сеть с поддержкой GPRS. Оплата объемов информации, а не времени нахождения на линии. Возможность постоянного нахождения в он-лайне. Возможность работы в роуминге. Асимметричность - скорость передачи данных в три-четыре раза ниже скорости приема. EDGE (англ. Enhanced Data rates for GSM Evolution)— цифровая технология для мобильной связи, которая функционирует как надстройка над 2G и 2.5G (GPRS)-сетями. EDGE обеспечивает передачу данных со скоростью до 474 кбит/с в режиме пакетной коммутации (8 тайм-слотов x 59,2 кбит/c на схеме кодирования MCS-9) соответствуя, таким образом, требованиям ITU к сетям 3G. Данная технология была принята ITU как часть семейства IMT-2000 стандартов 3G Wi-Fi - это современная беспроводная технология (wireless, wlan) передачи данных по радио каналу (wi-fi). Wi-Fi используется преимущественно владельцами ноутбуков и КПК для оперативного доступа в Интернет за пределами офиса или дома. Скорость до 300Мбит/с Теоретическая скорость до 600 Мбит/с Достоинства:мобильность, высокая скорость передачи данных, простота использования (просто введите пароль и логин), роуминг Недостатки: компьютер не может находиться от передающей антенны на расстоянии более 100-150 метров WiMAX (англ. Worldwide Interoperability for Microwave Access) — телекоммуникационная технология, разработанная с целью предоставления универсальной беспроводной связи на больших расстояниях для широкого спектра устройств (от рабочих станций и портативных компьютеров до мобильных телефонов). Основана на стандарте IEEE 802.16, который также называют Wireless MAN. Название «WiMAX» было создано WiMAX Forum — организацией, которая была основана в июне 2001 года с целью продвижения и развития технологии WiMAX. Форум описывает WiMAX как «основанную на стандарте технологию, предоставляющую высокоскоростной беспроводной доступ к сети, альтернативный выделенным линиям и DSL». Максимальная скорость — до 1 Гбит/сек. Максимальный радиус действия – 5-10 км Область использования WiMAX подходит для решения следующих задач: Соединения точек доступа Wi-Fi друг с другом и другими сегментами Интернета. Обеспечения беспроводного широкополосного доступа как альтернативы выделенным линиям и DSL. Предоставления высокоскоростных сервисов передачи данных и телекоммуникационных услуг. Создания точек доступа, не привязанных к географическому положению. Создания систем удалённого мониторинга (monitoring системы), как это имеет место в системе SCADA. WiMAX позволяет осуществлять доступ в Интернет на высоких скоростях, с гораздо большим покрытием, чем у Wi-Fi-сетей. Это позволяет использовать технологию в качестве «магистральных каналов», продолжением которых выступают традиционные DSL- и выделенные линии, а также локальные сети. В результате подобный подход позволяет создавать масштабируемые высокоскоростные сети в рамках городов. VPN (англ. Virtual Private Network — виртуальная частная сеть[1]) — обобщённое название технологий, позволяющих обеспечить одно или несколько сетевых соединений (логическую сеть) поверх другой сети (например, Интернет). Несмотря на то, что коммуникации осуществляются по сетям с меньшим или неизвестным уровнем доверия (например, по публичным сетям), уровень доверия к построенной логической сети не зависит от уровня доверия к базовым сетям благодаря использованию средств криптографии (шифрования, аутентификации, инфраструктуры открытых ключей, средств для защиты от повторов и изменений передаваемых по логической сети сообщений). Структура VPN VPN состоит из двух частей: «внутренняя» (подконтрольная) сеть, которых может быть несколько, и «внешняя» сеть, по которой проходит инкапсулированное соединение (обычно используется Интернет). Возможно также подключение к виртуальной сети отдельного компьютера. Подключение удалённого пользователя к VPN производится посредством сервера доступа, который подключён как к внутренней, так и к внешней (общедоступной) сети. При подключении удалённого пользователя (либо при установке соединения с другой защищённой сетью) сервер доступа требует прохождения процесса идентификации, а затем процесса аутентификации. После успешного прохождения обоих процессов, удалённый пользователь (удаленная сеть) наделяется полномочиями для работы в сети, то есть происходит процесс авторизации.
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Процесс — устойчивая и целенаправленная совокупность взаимосвязанных действий, которые по определённой технологии преобразуют входы в выходы для получения заранее определённых продуктов, результатов или услуг, представляющих ценность для потребителя. Составляющими процессами являются: 1. Определение состава операций. 2. Определение последовательности и взаимосвязей операций. 3. Оценка длительности операций. 4. Составление расписания – базового плана по срокам. 5. Управление расписанием. Определение состава операций Этот процесс предполагает дальнейшую декомпозицию рабочих пакетов ИСР на меньшие, управляемые операции. Рабочий пакет может и не разбиваться без необходимости на операции. Разбиение выполняется членами команды проекта в случае большой продолжительности рабочего пакета и необходимости разделения ответственности при назначении ресурсов. Обычно рабочие пакеты определяются (именуются) в терминах результатов (например, "результат оценки", "согласованный документ", "опытный образец"), а операции определяются в терминах действий (например, "оценка", "написание" или "оценить", "написать" и т.д.). На входе процесса определения состава операций мы имеем: • ИСР; • документ Констатация содержания; • ограничения, допущения, экспертные оценки, историческую информацию. На выходе: • перечень операций; • уточнения ИСР (иерархическая структура работ) Определение взаимосвязей операций Этот процесс должен установить последовательность и логические взаимосвязи между операциями. Операции могут выполняться как параллельно, так одна за другой. Во втором случае операции могут быть связаны жесткой логикой, когда очередная операция может быть выполнена только по окончании другой операции, получая её результаты. Например, нельзя начать строительство дома, не заложив фундамент, нельзя начать продажи, не изготовив продукцию и пр. Существует также мягкая зависимость, которая исходит из разумного практического опыта команды проекта и определяет предпочтительную последовательность операций. Например, при ремонте квартиры предпочтительнее завершить работы с потолком, а затем приступать к работам с полом. Кроме того, могут существовать внешние обстоятельства, влияющие на последовательность операций – внешние взаимосвязи. Схематично взаимосвязь двух операций можно показать двумя способами:
С помощью работ по стрелке строят стрелочные диаграммы. Но они все реже используются в современной практике. Для построения расписания используют метод предшествования (PDM – Precedence Diagramming Method), который использует работу на узлах. Между узлами в способе работа на узлах может быть 4 типа взаимосвязей:
В современных программах составления расписания можно устанавливать все 4 вида зависимостей, но чаще всего используется взаимосвязь типа FS. Кроме этого, используются связь типа фиктивная работа. Фиктивная работа (операция) бывает необходима лишь для демонстрации логической связи операций. Она иметь нулевую длительность. На входе процесса определения взаимосвязей операций мы имеем: • перечень операций; • описание продукта; • жесткие, мягкие и внешние взаимосвязи; • контрольные события для включения в сетевую диаграмму. На выходе процесса – сетевая диаграмма, например:
Оценка длительности операций Этот процесс должен установить длительность операций для последующего составления расписания. Во многих случаях он предшествует процессу установления взаимосвязей операций. Под длительностью операции понимают точное время, необходимое для завершения операции. Обычно под этим понимается количество дней, в течение которых один или несколько человек способны выполнить операцию. Длительность не включает время простоя. Фактическое время в днях между стартом и финишем операции, включая простои, называют периодом времени выполнения операции. Длительность операции зависит от имеющихся ресурсов. Например, 2 человека могут выполнить работу быстрее, чем один. Кроме того, длительность также зависит от производительности ресурсов, в частности, от опыта человека. Длительность определяет временные параметры составления расписания. В то же время, длительность операций связана с оценкой стоимости проекта, поскольку в нее заключен некий объем работ, называемый трудоемкостью или трудозатратами операции. Стоимость проекта может быть оценена снизу вверх как сумма стоимостей отдельных операций. Трудоемкость (трудозатраты) – есть количество человеко-часов, необходимых для завершения операции. Так трудоемкость в 100 чел/час означает, что один человек выполнит операцию за 100 часов, или 100 человек выполнят операцию за 1 час. В соответствии с трудоемкостью, операциям назначаются единицы человеческих ресурсов, которые имеют некую стоимость. В программах календарного планирования возможен выбор метода планирования – на основе длительности или на основе трудозатрат. См. также раздел 14.1.4. К длительности операции может быть добавлен некоторый процент в качестве резервного времени, которое может быть удалено впоследствии при составлении расписания. Оценкой длительности операций занимаются члены команды проекта (а не менеджер проекта). Здесь важны их экспертные знания, информация по прошлым проектам, а также информация о выявленных рисках и угрозах, способных оказать отрицательное влияние на длительность операций. Поэтому расписание составляется после детальной оценки рисков проекта. Таким образом, на входе процесса оценки длительности операций мы имеем: • перечень операций; • потребности в ресурсах и производительность ресурсов; • историческую информацию, экспертные знания команды проекта, аналогичные проекты; • идентифицированные риски. На выходе процесса имеем оценку длительности операций. Она может быть оформлена в табличном виде, либо в виде сетевой диаграммы с узлами, содержащими информацию о длительности, резерве, датах:
Задержки и опережения используются как дополнение к видам взаимосвязей FS, SS, SF, FF. Например, взаимосвязь может потребовать установки связи вида FS+10, вместо FS, т.е. задержки последующей операции на 10 дней. Задержки и опережения соответственно добавляют или вычитают из старта (и финиша) последующей операции указанное количество дней (здесь показано 0). Заметим, что финиш операции F вычисляется по формуле F = S + D – 1, где D (Duration) длительность операции. Способы представления расписания Расписание можно представить как в табличном виде, так и в графическом виде. Графические форматы могут быть следующими: • сетевые диаграммы; • диаграммы Ганта; • поэтапные календарные планы. На сетевые диаграммы, как было показано выше, наносят информацию о датах. Даты рассчитываются по формуле F = S + D – 1:
Такие сетевые диаграммы наиболее эффективны на этапе планирования расписания по следующим причинам: • наглядно показывают логику проекта, т.е. взаимосвязи и последовательность операций; • позволяют быстро планировать и организовать проект. Диаграммы Ганта также наглядно показывают выполнение операций во времени и широко используются в программах управления проектами. Ниже показана диаграмма Ганта для предыдущей сетевой диаграммы:
Преимуществами диаграмм Ганта являются: • легкая читабельность и обозримость; • возможность показать прогресс во времени; • возможность дополнения другими параметрами, например, отобразить ресурсы; • легкость составления отчетов о ходе работ. Применение диаграмм Ганта наиболее эффективно в процессе управления проектом, и менее эффективно в процессах планирования. Причина в том, что они менее наглядно показывают взаимосвязи операций! В то же время, взаимосвязи между операциями на диаграммах Ганта показываются отображением связей FS, SS, SF, FF, как показано на рисунке выше. Поэтапные календарные планы применяются для укрупненного представления расписания основных этапов работ, вех, контрольных точек и событий, основных внешних взаимосвязей. На них отображают плановые и фактические даты. Например:
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
БИЛЕТ 15 |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Существует множество определений информатики, что связано с многогранностью ее функций, возможностей, средств и методов. Обобщая опубликованные в литературе по информатике определения этого термина, предлагаем такую трактовку. Информатика — это область человеческой деятельности, связанная с процессами преобразования информации с помощью компьютеров и их взаимодействием со средой применения. Часто возникает путаница в понятиях "информатика" и "кибернетика". Попытаемся разъяснить их сходство и различие. Основная концепция, заложенная Н. Винером в кибернетику, связана с разработкой теории управления сложными динамическими системами в разных областях человеческой деятельности. Кибернетика существует независимо от наличия или отсутствия компьютеров. Кибернетика — это наука об общих принципах управления в различных системах: технических, биологических, социальных и др. Информатика занимается изучением процессов преобразования и создания новой информации более широко, практически не решая задачи управления различными объектами, как кибернетика. Поэтому может сложиться впечатление об информатике как о более емкой дисциплине, чем кибернетика. Однако, с другой стороны, информатика не занимается решением проблем, не связанных с использованием компьютерной техники, что, несомненно, сужает ее, казалось бы, обобщающий характер. Между этими двумя дисциплинами провести четкую границу не представляется возможным в связи с ее размытостью и неопределенностью, хотя существует довольно распространенное мнение, что информатика является одним из направлений кибернетики. Информатика появилась благодаря развитию компьютерной техники, базируется на ней и совершенно немыслима без нее. Кибернетика же развивается сама по себе, строя различные модели управления объектами, хотя и очень активно использует все достижения компьютерной техники. Кибернетика и информатика, внешне очень похожие дисциплины, различаются, скорее всего, в расстановке акцентов:
Термин информатика возник в 60-х гг. во Франции для названия области, занимающейся автоматизированной обработкой информации с помощью электронных вычислительных машин. Французский термин informatique (информатика) образован путем слияния слов information (информация) и automatique (автоматика) и означает "информационная автоматика или автоматизированная переработка информации". В англоязычных странах этому термину соответствует синоним computer science (наука о компьютерной технике). Выделение информатики как самостоятельной области человеческой деятельности в первую очередь связано с развитием компьютерной техники. Причем основная заслуга в этом принадлежит микропроцессорной технике, появление которой в середине 70-х гг. послужило началом второй электронной революции. С этого времени элементной базой вычислительной машины становятся интегральные схемы и микропроцессоры, а область, связанная с созданием и использованием компьютеров, получила мощный импульс в своем развитии. Термин "информатика" приобретает новое дыхание и используется не только для отображения достижений компьютерной техники, но и связывается с процессами передачи и обработки информации. В нашей стране подобная трактовка термина "информатика" утвердилась с момента принятия решения в 1983 г. на сессии годичного собрания Академии наук СССР об организации нового отделения информатики, вычислительной техники и автоматизации. Информатика трактовалась как "комплексная научная и инженерная дисциплина, изучающая все аспекты разработки, проектирования, создания, оценки, функционирования основанных на ЭВМ систем переработки информации, их применения и воздействия на различные области социальной практики". Информатика в таком понимании нацелена на разработку общих методологических принципов построения информационных моделей. Поэтому методы информатики применимы всюду, где существует возможность описания объекта, явления, процесса и т.п. с помощью информационных моделей. Информатика как фундаментальная наука занимается разработкой методологии создания информационного обеспечения процессов управления любыми объектами на базе компьютерных информационных систем. Существует мнение, что одна из главных задач этой науки — выяснение, что такое информационные системы, какое место они занимают, какую должны иметь структуру, как функционируют, какие общие закономерности им свойственны. В Европе можно выделить следующие основные научные направления в области информатики: разработка сетевой структуры, компьютерно-интегрированные производства, экономическая и медицинская информатика, информатика социального страхования и окружающей среды, профессиональные информационные системы. Цель фундаментальных исследований в информатике — получение обобщенных знаний о любых информационных системах, выявление общих закономерностей их построения и функционирования. Новый этап теоретического расширения понятия “информация” связан с кибернетикой (греч. kiber – над, nautus – моряк, кормчий, управляющий рулем, отсюда – искусство управления) – наукой об управлении и связи в живых организмах, обществе и машинах, технических системах. Впервые термин “кибернетика” встречается в работах древнегреческого философа Платона (ок. 427-347 гг. до н. э.), в которых он обозначил правила управления обществом. Через две с лишним тысячи лет французский физик А. И. Ампер (1775 –1836) в своей работе “Опыт философских наук” (1834) термин “кибернетика” также применил к науке об управлении обществом. Понадобилось еще 200 лет развития естественных и гуманитарных наук для того, чтобы в 1940-х годах термин “кибернетика” наполнился современным содержанием. Н. Винер (рис. 1.1) применил этот термин в своей книге “Кибернетика или управление и связь в животном и машине” (1948). Основное внимание Н. Винер обратил на информационную сущность управления, наличие движения информации в контуре управления, прямую и обратную связь в управлении живыми организмами и техническими системами. Появление в 1948 г. работы Н. Винера было представлено на Западе некоторыми журналистами как сенсация. О кибернетике, вопреки мнению самого Винера, писали как о новой универсальной науке, якобы способной заменить философию, объясняющую процессы развития в природе и обществе. Все это наряду с недостаточной осведомленностью отечественных философов с первоисточниками из области теории кибернетики привело к необоснованному отрицанию кибернетики в нашей стране как самостоятельной науки. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Классическими задачами системного анализа являются игровые задачи принятия решений в условиях риска и неопределенности. Неопределенными могут быть как цели операции, условия выполнения операции, так и сознательные действия противников или других лиц, от которых зависит успех операции. Разработаны специальные математические методы, предназначенные для обоснования решений в условиях риска и неопределенности. В некоторых, наиболее простых случаях эти методы дают возможность фактически найти и выбрать оптимальное решение. В более сложных случаях эти методы доставляют вспомогательный материал, позволяющий глубже разобраться в сложной ситуации и оценить каждое из возможных решений с различных точек зрения, и принять решений с учетом его возможных последствий. Одним из важных условий принятия решений в этом случае является минимизация риска. При решении ряда практических задач исследования операций (в области экологии, обеспечения безопасности жизнедеятельности и т. д.) приходится анализировать ситуации, в которых сталкиваются две (или более) враждующие стороны, преследующие различные цели, причем результат любого мероприятия каждой из сторон зависит от того, какой образ действий выберет противник. Такие ситуации мы можно отнести к конфликтным ситуациям. Теория игр является математической теорией конфликтных ситуаций, при помощи которой можно выработать рекомендации по рациональному образу действий участников конфликта. Чтобы сделать возможным математический анализ ситуации без учета второстепенных факторов, строят упрощенную, схематизированную модель ситуации, которая называется игрой. игра ведется по вполне определенным правилам, под которыми понимается система условий, регламентирующая возможные варианты действий игроков; объем информации каждой стороны о поведении другой; результат игры, к которому приводит каждая данная совокупность ходов. Результат игры (выигрыш или проигрыш) вообще не всегда имеет количественное выражение, но обычно можно, хотя бы условно, выразить его числовым значением. Ход — выбор одного из предусмотренных правилами игры действий и его осуществление. Ходы делятся на личные и случайные. Личным ходом называется сознательный выбор игроком одного из возможных вариантов действий и его осуществление. Случайным ходом называется выбор из ряда возможностей, осуществляемый не решением игрока, а каким-либомеханизмом случайного выбора (бросание монеты, выбор карты из перетасованной колоды и т. п.). Для каждого случайного хода правила игры определяют распределение вероятностей возможных исходов. Игра может состоять только их личных или только из случайных ходов, или из их комбинации. Следующим основным понятием теории игр является понятие стратегии. Стратегия — это априори принятая игроком система решений (вида «если — то»), которых он придерживается во время ведения игры, которая может быть представлена в виде алгоритма и выполняться автоматически. Целью теории игр является выработка рекомендаций для разумного поведения игроков в конфликтной ситуации, т. е. определение «оптимальной стратегии» для каждого из них. Стратегия, оптимальная по одному показателю, необязательно будет оптимальной по другим. Сознавая эти ограничения и поэтому не придерживаясь слепо рекомендаций, полученных игровыми методами, можно все же разумно использовать математический аппарат теории игр для выработки, если не в точности оптимальной, то, во всяком случае «приемлемой» стратегии. Игры можно классифицировать: по количеству игроков, количеству стратегий, характеру взаимодействия игроков, характеру выигрыша, количеству ходов, состоянию информации и т.д. [2, 7, 8]. В зависимости от количества игроков различают игры двух и n игроков. Первые из них наиболее изучены. Игры трех и более игроков менее исследованы из-за возникающих принципиальных трудностей и технических возможностей получения решения. В зависимости от числа возможных стратегий игры делятся на «конечные» и «бесконечные». Игра называется конечной, если у каждого игрока имеется только конечное число стратегий, и бесконечной, если хотя бы у одного из игроков имеется бесконечное число стратегий. По характеру взаимодействия игры делятся на бескоалиционные: игроки не имеют права вступать в соглашения, образовывать коалиции; коалиционные (кооперативные) — могут вступать в коалиции. В кооперативных играх коалиции заранее определены. По характеру выигрышей игры делятся на: игры с нулевой суммой (общий капитал всех игроков не меняется, а перераспределяется между игроками; сумма выигрышей всех игроков равна нулю) и игры с ненулевой суммой. По виду функций выигрыша игры делятся на: матричные, биматричные, непрерывные, выпуклые и др. Матричная игра — это конечная игра двух игроков с нулевой суммой, в которой задается выигрыш игрока 1 в виде матрицы (строка матрицы соответствует номеру применяемой стратегии игрока 1, столбец — номеру применяемой стратегии игрока на пересечении строки и столбца матрицы находится выигрыш игрока 1, соответствующий применяемым стратегиям). Для матричных игр доказано, что любая из них имеет решение и оно может быть легко найдено путем сведения игры к задаче линейного программирования. Биматричная игра — это конечная игра двух игроков с ненулевой суммой, в которой выигрыши каждого игрока задаются матрицами отдельно для соответствующего игрока (в каждой матрице строка соответствует стратегии игрока 1, столбец — стратегии игрока 2, на пересечении строки и столбца в первой матрице находится выигрыш игрока 1, во второй матрице — выигрыш игрока ) Непрерывной считается игра, в которой функция выигрышей каждого игрока является непрерывной. Доказано, что игры этого класса имеют решения, однако не разработано практически приемлемых методов их нахождения. Если функция выигрышей является выпуклой, то такая игра называется выпуклой. Для них разработаны приемлемые методы решения, состоящие в отыскании чистой оптимальной стратегии (определенного числа) для одного игрока и вероятностей применения чистых оптимальных стратегий другого игрока. Такая задача решается сравнительно легко. Запись матричной игры в виде платежной матрицы Рассмотрим конечную игру, в которой первый игрок А имеет m стратегий, а второй игрок B-n стратегий. Такая игра называется игрой m×n. Обозначим стратегии A1, А2, ..., Аm; и В1, В2, ..., Вn. Предположим, что каждая сторона выбрала определенную стратегию: Ai или Bj. Если игра состоит только из личных ходов, то выбор стратегий однозначно определяет исход игры — выигрыш одной из сторон aij. Если игра содержит кроме личных случайные ходы, то выигрыш при паре стратегий Ai и B является случайной величиной, зависящей от исходов всех случайных ходов. В этом случае естественной оценкой ожидаемого выигрыша является математическое ожидание случайного выигрыша, которое также обозначается за aij. Предположим, что нам известны значения aij при каждой паре стратегий. Эти значения можно записать в виде прямоугольной таблицы (матрицы), строки которой соответствуют стратегиям Ai, а столбцы — стратегиям Bj. Тогда, в общем виде матричная игра может быть записана следующей платежной матрицей:
Таблица — Общий вид платежной матрицы матричной игры где Ai — названия стратегий игрока 1, Bj — названия стратегий игрока 2, aij — значения выигрышей игрока 1 при выборе им i–й стратегии, а игроком 2 — j-й стратегии. Поскольку данная игра является игрой с нулевой суммой, значение выигрыша для игрока 2 является величиной, противоположенной по знаку значению выигрыша игрока 1. Критерии принятия решения ЛПР определяет наиболее выгодную стратегию в зависимости от целевой установки, которую он реализует в процессе решения задачи. Результат решения задачи ЛПР определяет по одному из критериев принятия решения. Для того, чтобы прийти к однозначному и по возможности наиболее выгодному варианту решению, необходимо ввести оценочную (целевую) функцию. При этом каждой стратегии ЛПР (Ai) приписывается некоторый результат Wi, характеризующий все последствия этого решения. Из массива результатов принятия решений ЛПР выбирает элемент W, который наилучшим образом отражает мотивацию его поведения. В зависимости от условий внешней среды и степени информативности ЛПР производится следующая классификация задач принятия решений:
Принятие решений в условиях неопределенности Будем предполагать, что лицу, принимающему решение не противостоит разумный противник. Данные, необходимо для принятия решения в условии неопределенности, обычно задаются в форме матрицы, строки которой соответствуют возможным действиям, а столбцы — возможным состояниям системы. Пусть, например, из некоторого материала требуется изготовить изделие, долговечность которого при допустимых затратах невозможно определить. Нагрузки считаются известными. Требуется решить, какие размеры должно иметь изделие из данного материала. Варианты решения таковы: Е1 — выбор размеров из соображений максимальной долговечности ; Еm — выбор размеров из соображений минимальной долговечности ; Ei — промежуточные решения. Условия требующие рассмотрения таковы: F1 — условия, обеспечивающие максимальной долговечность; Fn — условия, обеспечивающие min долговечность; Fi — промежуточные условия. Под результатом решения eij = е(Ei ; Fj) здесь можно понимать оценку, соответствующую варианту Ei и условиям Fj и характеризующие прибыль, полезность или надежность. Обычно мы будем называть такой результат полезностью решения. Тогда семейство (матрица) решений ||eij|| имеет вид:
Чтобы прийти к однозначному и по возможности наивыгоднейшему варианту решению необходимо ввести оценочную (целевую) функцию. При этом матрица решений ||eij|| сводится к одному столбцу. Каждому варианту Ei приписывается, т.о., некоторый результат eir, характеризующий, в целом, все последствия этого решения. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Знания – это совокупность сведений о сущностях (объектах, предметах) реального мира, их свойствах и отношениях между ними в определенной предметной области. Иными словами, знания – это выявленные закономерности предметной области (принципы, связи, законы), позволяющие решать задачи в этой области. С точки зрения ИИ знания можно определить как формализованную информацию, на которую ссылаются в процессе логического вывода. Если данные обладают этими свойствами, можно говорить о перерастании данных в знания. Внутренняя интерпретируемость означает наличие в памяти ЭВМ сведений не только о значении, но и о наименовании информационной единицы. Следует отметить, что это свойство присуще некоторым моделям представления данных, например реляционной. Внутренняя (рекурсивная) структурированность отражает вложенность одних информационных единиц в другие или в самих себя. Она предусматривает установку отношений принадлежности элементов к классу, родовидовые отношения типа «часть-целое» и т.п. В целом внутренняя структурированность характеризует структуру знания. Внешняя взаимосвязь единиц определяет, с какой информационной единицей имеет связь данная информационная единица и какова эта связь. С помощью этого свойства устанавливается связь различных отношений, отражающих семантику и прагматику связей понятий, а также отношений, отражающих смысл системы в целом. Отдельные информационные единицы не могут описывать динамические ситуации, когда некоторые факты, содержащиеся в структуре одной единицы, вступают в ситуативную связь с фактами или явлениями, описанными в структуре другой единицы. Для описания таких связей используются специальные информационные элементы, в которых указываются имена взаимосвязанных информационных единиц и имена существующих отношений. Шкалирование означает использование шкал, предназначенных для фиксации соотношения различных величин. Прежде всего шкалирование необходимо для фиксации соотношений качественной информации. Погружение в пространство с семантической метрикой используется для задания меры близости информационных единиц. Это свойство можно проиллюстрировать на следующем примере. Пусть разработано несколько вариантов построения системы связи. Требуется определить, насколько структура существующей системы связи близка к одному из имеющихся вариантов. Для этого можно использовать метод матриц сходства - различия, в соответствии с которым матрицы заполняются оценками попарного сходства и различия элементов структур реальной системы связи и рассматриваемого варианта. В качестве оценок обычно выступают числа в диапазоне от -1 до +1 при условии, что -1 характеризует полное различие, а +1 - полное сходство. На основании матриц сходства - различия определяется степень сходства текущей ситуации с заранее заданной (планируемой). Активность знаний выражается в возможности вызова той или иной процедуры в зависимости от структуры, сложившейся между информационными единицами. Активность знаний обусловлена тем, что в отличие от обычных программ, в которых процедуры играют роль активаторов данных, в интеллектуальных системах определенная структура данных активизирует выполнение той или иной процедуры. Практически это осуществляется включением в состав информационной единицы элемента, содержащего имя процедуры, или представлением знаний в виде правил, причем правила записываются в следующем виде: "если произошли события А1 и А2 и ...и АN, то необходимо выполнить процедуру В". Использование правил значительно упрощает объяснение того, как и почему получено то или иное заключение (вывод). Перечисленные особенности информационных единиц определяют ту грань, за которой данные превращаются в знания, а базы данных перерастают в базы знаний (БЗ). Совокупность средств, обеспечивающих работу со знаниями, образует систему управления базой знаний (СУБЗ). В настоящее время не существует баз знаний, в которых в полной мере были бы реализованы все пять особенностей знаний. Базы данных фиксируют экстенсиональную семантику заданной проблемной области, состояние конкретных объектов, конкретные значения параметров для определенных моментов времени и временных интервалов. База знаний определяет интенсиональную семантику моделей и содержит описание абстрактных сущностей: объектов, отношений, процессов. Если рассматривать знания с точки зрения решения задач в некоторой предметной области, то их удобно разделить на две большие категории — факты и эвристику. Первая категория указывает обычно на хорошо известные в данной предметной области обстоятельства, поэтому знания этой категории иногда называют текстовыми, подчеркивая их достаточную освещенность в специальной литературе или учебниках. Вторая категория знаний основывается на собственном опыте специалиста (эксперта) в данной предметной области, накопленном в результате многолетней практики. Знания можно разделить на процедурные и декларативные. Декларативные знания – это совокупность сведений о качественных и количественных характеристиках конкретных объектов, явлений и их элементов, представленных в виде фактов и эвристик. Традиционно такие знания накапливались в виде разнообразных таблиц и справочников, а с появлением ЭВМ приобрели форму информационных массивов (файлов) и баз данных. Процедурные знания хранятся в памяти ИИС в виде описаний процедур, с помощью которых их можно получить. В виде процедурных знаний обычно описывается информация о предметной области, характеризующая способы решения задач в этой области, а также различные инструкции, методики и тому подобная информация. Другими словами, процедурные знания – это методы, алгоритмы, программы решения различных задач, последовательности действий (в выбранной проблемной области) – они составляют ядро баз знаний. Таким образом, при использовании знаний происходит переход к формуле знания + вывод = система. Работа со знаниями, иначе называемая обработкой знаний, лежит в основе всего современного периода развития ИИ. В свою очередь обработка знаний включает в себя: извлечение знаний из источников (под источниками понимаются материальные средства хранения знаний, а также события и явления, но при этом считается, что человек источником не является); приобретение знаний от профессионалов (экспертов); представление знаний, т.е. их формализация, позволяющая в дальнейшем использовать знания для проведения логического вывода на ЭВМ; манипулирование знаниями, включающее пополнение, классификацию, обобщение знаний и вывод на знаниях; объяснение на знаниях, позволяющее дать ответ, как и почему проведен тот или иной вывод. В памяти ЭВМ знания представляются в виде некоторой знаковой системы. С понятием "знак" связываются понятия "экстенсионал" и "интенсионал". Экстенсионал знака - это его конкретное значение или класс допустимых значений. Интенсионал знака - это его смысл, содержания. Интенсионал знака определяет содержание связанного с ним понятия. Соответственно различают два типа знаний: экстенсиональные и интенсиональные. Экстенсиональные знания - это набор количественных и качественных характеристик различных конкретных объектов. Они представляются перечислениями объектов предметной области, экземпляров объектов, свойств объектов. Иными словами, экстенсиональные знания - это данные, хранящиеся в базах данных. Иногда экстенсиональные знания называются предметными, или фактографическими знаниями. Интенсиональные знания - это совокупность основных терминов, применяемых в проблемной области, и правил над ними, позволяющих получать новые знания. Интенсиональные знания описывают абстрактные объекты, события, отношения. Интенсиональные знания подразделяются на декларативные, процедуральные и метазнания. Декларативные знания отражают понятия проблемной области и связи между ними. Они не содержат в явном виде описания каких-либо процедур. Иначе декларативные знания называются понятийными, или концептуальными. Процедуральные знания описывают процедуры, т.е. указывают операции над понятиями, позволяющие получать новые понятия. В отличие от декларативных знаний они содержат в явном виде описания процедур. Примером процедуральных знаний является программа, хранящаяся в памяти ЭВМ. Иногда процедуральные знания называются алгоритмическими. Метазнания - это знания об организации всех остальных типов знаний. Иначе они называются специальными. Метазнания содержат признаки декларативных и процедуральных знаний. Поверхностные — знания о видимых взаимосвязях между отдельными событиями и фактами в предметной области. Глубинные — абстракции, аналогии, схемы, отображающие структуру и природу процессов, протекающих в предметной области. Эти знания объясняют явления и могут использоваться для прогнозирования поведения объектов. Модели представления знаний. Неформальные (семантические) модели. Существуют два типа методов представления знаний (ПЗ):
Очевидно, все методы представления знаний, которые рассмотрены выше, включая продукции (это система правил, на которых основана продукционная модель представления знаний), относятся к неформальным моделям. В отличие от формальных моделей, в основе которых лежит строгая математическая теория, неформальные модели такой теории не придерживаются. Каждая неформальная модель годится только для конкретной предметной области и поэтому не обладает универсальностью, которая присуща моделям формальным. Логический вывод - основная операция в СИИ - в формальных системах строг и корректен, поскольку подчинен жестким аксиоматическим правилам. Вывод в неформальных системах во многом определяется самим исследователем, который и отвечает за его корректность. Каждому из методов ПЗ соответствует свой способ описания знаний.
Множество P есть множество синтаксических правил. С их помощью из элементов T образуют синтаксически правильные совокупности. Например, из слов ограниченного словаря строятся синтаксически правильные фразы, из деталей детского конструктора с помощью гаек и болтов собираются новые конструкции. Декларируется существование процедуры П(P), с помощью которой за конечное число шагов можно получить ответ на вопрос, является ли совокупность X синтаксически правильной. В множестве синтаксически правильных совокупностей выделяется некоторое подмножество A. Элементы A называются аксиомами. Как и для других составляющих формальной системы, должна существовать процедура П(A), с помощью которой для любой синтаксически правильной совокупности можно получить ответ на вопрос о принадлежности ее к множеству A. Множество B есть множество правил вывода. Применяя их к элементам A, можно получать новые синтаксически правильные совокупности, к которым снова можно применять правила из B. Так формируется множество выводимых в данной формальной системе совокупностей. Если имеется процедура П(B), с помощью которой можно определить для любой синтаксически правильной совокупности, является ли она выводимой, то соответствующая формальная система называется разрешимой. Это показывает, что именно правило вывода является наиболее сложной составляющей формальной системы. Для знаний, входящих в базу знаний, можно считать, что множество A образуют все информационные единицы, которые введены в базу знаний извне, а с помощью правил вывода из них выводятся новые производные знания. Другими словами формальная система представляет собой генератор порождения новых знаний, образующих множество выводимых в данной системе знаний. Это свойство логических моделей делает их притягательными для использования в базах знаний. Оно позволяет хранить в базе лишь те знания, которые образуют множество A, а все остальные знания получать из них по правилам вывода. 2. Сетевые модели. В основе моделей этого типа лежит конструкция, названная ранее семантической сетью. Сетевые модели формально можно задать в виде H = <I, C1, C2, ..., Cn,Г>. Здесь I есть множество информационных единиц; C1, C2, ..., Cn - множество типов связей между информационными единицами. Отображение Г задает между информационными единицами, входящими в I, связи из заданного набора типов связей. В зависимости от типов связей, используемых в модели, различают классифицирующие сети, функциональные сети и сценарии. В классифицирующих сетях используются отношения структуризации. Такие сети позволяют в базах знаний вводить разные иерархические отношения между информационными единицами. Функциональные сети характеризуются наличием функциональных отношений. Их часто называют вычислительными моделями, т.к. они позволяют описывать процедуры "вычислений" одних информационных единиц через другие. В сценариях используются каузальные отношения, а также отношения типов "средство - результат", "орудие - действие" и т.п. Если в сетевой модели допускаются связи различного типа, то ее обычно называют семантической сетью. 3. Продукционные модели. В моделях этого типа используются некоторые элементы логических и сетевых моделей. Из логических моделей заимствована идея правил вывода, которые здесь называются продукциями, а из сетевых моделей - описание знаний в виде семантической сети. В результате применения правил вывода к фрагментам сетевого описания происходит трансформация семантической сети за счет смены ее фрагментов, наращивания сети и исключения из нее ненужных фрагментов. Таким образом, в продукционных моделях процедурная информация явно выделена и описывается иными средствами, чем декларативная информация. Вместо логического вывода, характерного для логических моделей, в продукционных моделях появляется вывод на знаниях. 4. Фреймовые модели. В отличие от моделей других типов во фреймовых моделях фиксируется жесткая структура информационных единиц, которая называется протофреймом. В общем виде она выглядит следующим образом: (Имя фрейма: Имя слота 1(значение слота 1) Имя слота 2(значение слота 2) . . . . . . . . . . . . . . . . . . . . . . Имя слота К (значение слота К)). Значением слота может быть практически что угодно (числа или математические соотношения, тексты на естественном языке или программы, правила вывода или ссылки на другие слоты данного фрейма или других фреймов). В качестве значения слота может выступать набор слотов более низкого уровня, что позволяет во фреймовых представлениях реализовать "принцип матрешки". При конкретизации фрейма ему и слотам присваиваются конкретные имена и происходит заполнение слотов. Таким образом, из протофреймов получаются фреймы - экземпляры.Переход от исходного протофрейма к фрейму - экземпляру может быть многошаговым, за счет постепенного уточнения значений слотов. Связи между фреймами задаются значениями специального слота с именем "Связь". Часть специалистов по ИС считает, что нет необходимости специально выделять фреймовые модели в представлении знаний, т.к. в них объединены все основные особенности моделей остальных типов. Формальные модели представления знаний. Система ИИ в определенном смысле моделирует интеллектуальную деятельность человека и, в частности, - логику его рассуждений. В грубо упрощенной форме наши логические построения при этом сводятся к следующей схеме: из одной или нескольких посылок (которые считаются истинными) следует сделать "логически верное" заключение (вывод, следствие). Очевидно, для этого необходимо, чтобы и посылки, и заключение были представлены на понятном языке, адекватно отражающем предметную область, в которой проводится вывод. В обычной жизни это наш естественный язык общения, в математике, например, это язык определенных формул и т.п. Наличие же языка предполагает, во - первых, наличие алфавита (словаря), отображающего в символьной форме весь набор базовых понятий (элементов), с которыми придется иметь дело и, во - вторых, набор синтаксических правил, на основе которых, пользуясь алфавитом, можно построить определенные выражения. Логические выражения, построенные в данном языке, могут быть истинными или ложными. Некоторые из этих выражений, являющиеся всегда истинными. Объявляются аксиомами(или постулатами). Они составляют ту базовую систему посылок, исходя из которой и пользуясь определенными правилами вывода, можно получить заключения в виде новых выражений, также являющихся истинными. Если перечисленные условия выполняются, то говорят, что система удовлетворяет требованиям формальной теории. Ее так и называют формальной системой (ФС). Система, построенная на основе формальной теории, называется также аксиоматической системой. Формальная теория должна, таким образом, удовлетворять следующему определению: всякая формальная теория F = (A, V, W, R), определяющая некоторую аксиоматическую систему, характеризуется: наличием алфавита (словаря), A, множеством синтаксических правил, V, множеством аксиом, лежащих в основе теории, W, множеством правил вывода, R. Исчисление высказываний (ИВ) и исчисление предикатов (ИП) являются классическими примерами аксиоматических систем. Эти ФС хорошо исследованы и имеют прекрасно разработанные модели логического вывода - главной метапроцедуры в интеллектуальных системах. Поэтому все, что может и гарантирует каждая из этих систем, гарантируется и для прикладных ФС как моделей конкретных предметных областей. В частности, это гарантии непротиворечивости вывода, алгоритмической разрешимости (для исчисления высказываний) и полуразрешимости (для исчислений предикатов первого порядка). ФС имеют и недостатки, которые заставляют искать иные формы представления. Главный недостаток - это "закрытость" ФС, их негибкость. Модификация и расширение здесь всегда связаны с перестройкой всей ФС, что для практических систем сложно и трудоемко. В них очень сложно учитывать происходящие изменения. Поэтому ФС как модели представления знаний используются в тех предметных областях, которые хорошо локализуются и мало зависят от внешних факторов. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Управление проектами — это приложение знаний, навыков, инструментов и методов к работам проекта для удовлетворения требований, предъявляемых к проекту . Результат эффективного управления — реализация проекта в рамках необходимых сроков, бюджета и в соответствии с первоначальными требованиями. Ключевым фактором успеха проектного управления является наличие четкого заранее определенного расписания проекта. Разработка расписания — процесс анализа последовательностей операций, их длительности, требований к ресурсам и временных ограничений для создания расписания проекта. Ввод операций, длительностей и ресурсов в инструмент составления расписания генерирует расписание с запланированными датами завершения операций проекта. Разработка приемлемого расписания проекта зачастую является итеративным процессом, т. е. конкретные этапы формирования расписания происходят многократно. В результате определяются запланированные даты старта и финиша операций и контрольных событий проекта. Управление расписанием проекта, включает в себя все действия по планированию, контролю и корректирующие расписание действия. Именно расписание проекта позволяет использовать ресурсы наиболее эффективным способом, привлекать их в те даты, когда они необходимы и высвобождать, когда необходимость в ресурсах отпадает При разработке расписания выделяют следующие основные методы: 1. Метод PERT. 2. Метод критического пути. 3. Метод критической цепи. Метод PERT. Обычно при осуществлении научных исследований и разработок заранее неизвестно время, необходимое для выполнения различных работ. Поэтому при использовании PERT учитывается неопределенность в задании продолжительности работ. Метод позволяет определить вероятность завершения различных этапов проекта в заданный срок, а также вычислить ожидаемую продолжительность проекта. Важным и исключительно полезным результатом применения PERT является определение узких мест проекта. Иначе говоря, выявляются те работы, которые с большей вероятностью способны вызвать задержку сроков завершения проекта. Таким образом, еще до начала работ руководитель проекта знает, где могут ожидать задержки. Они имеет возможность заранее принять необходимые меры с целью устранить возможные задержки и обеспечить осуществление проекта в срок. Можно отметить ряд особенностей метода PERT. · PERT следует применять только для крупных проектов с большим количеством работ (более 300). Помимо достаточного числа работ критического пути это обеспечит независимость случайных величин их продолжительностей. · Для применения PERT необходимо подобрать экспертов и организовать их работу для получения оценок оптимистичной, пессимистичной и наиболее вероятной продолжительностей для каждой работы проекта. От качества этой работы будет зависеть качество применения PERT · PERT занижает оценку продолжительности проекта. Чем больше параллельно идущих работ, тем серьезней ошибка. Для ее утсранения следует воспользоваться методом Монте-Карло. ·Критическим путем проекта при его реализации может оказаться путь, отличный от того, который был получен с помощью метода PERT. Степень критичности той или иной работы проекта также зависит от конкретной реализации. Можно говорить лишь о вероятности, что работа будет критичной. PERT не учитывает существующие ограничения на ресурсы и действия проектного менеджера, который стремится выполнять проект в назначенные сроки. Для успешности PERT необходимо сделать одно допущение: все случайные величины продолжительностей работ критического пути — независимы. В противном случае это повлияет на дисперсию продолжительности проекта . Основное отличие PERT от CPM заключается в том, что продолжительности работ считаются случайными величинами. Другими словами, PERT позволяет учесть неопределенность реальных продолжительностей выполнения работ проекта для оценки и анализа сроков его выполнения. Метод PERT реализует вероятностный подход к определению продолжительности работ с использованием среднего значения β-распределения PERT широко используется в научно-исследовательских и опытно-конструкторских проектах, так как позволяет учитывать неопределенность сроков выполнения работ. Метод критического пути. Основное различие между ними состоит в том, что CPM не учитывает случайные колебания продолжительности работ. Вместо этого предполагается, что продолжительность работы пропорциональна количеству выделяемых ресурсов и что, изменяя количество ресурсов, можно изменять продолжительность работы и сроки завершения проекта. Таким образом, при использовании МКП на основе имеющегося опыта осуществления аналогичных проектов устанавливаются соотношения между имеющимися ресурсами и продолжительностями работ. Затем оцениваются компромиссные соотношения между затратами и продолжительность проекта. МКП предъявляет следующие требования к модели проекта : 1. Проект состоит из точно определенного множества работ. Все работы в процессе выполнения проекта должны быть закончены и никаких других работ возникнуть не может. 2. Для каждой работы известна продолжительность ее выполнения. 3. На множестве работ введено отношение предшествования. На начало каждой последующей работы влияет только окончание предыдущих работ и отношения предшествования. Метод критического пути позволяет рассчитать теоретические даты раннего старта и финиша, а также даты позднего старта и финиша для всех операций без учета ресурсных ограничений путем проведения анализа прохода вперед и назад по сети проекта: 1. Прохода вперед. Вычисляются самые ранние возможные сроки выполнения работ проекта. 2. Проход назад. Вычисляются самые поздние возможные сроки выполнения работы проекта. Полученные даты раннего старта и финиша не всегда являются расписанием проекта; они указывают периоды времени, в рамках которых могут быть запланированы операции с учетом длительностей операций, логических связей, опережений, задержек и других известных ограничений. На рассчитанные ранние и поздние даты старта и финиша может влиять общий временной резерв операции, который определяется как разность между поздними и ранними сроками выполнения работ. Это позволяет делать расписание гибким и может быть положительным, отрицательным или нулевым. Для любого пути в сети гибкость расписания, называемая «полным временным резервом», измеряется положительной разницей между ранними и поздними датами. У критических путей полный временной резерв либо нулевой, либо отрицательный, а запланированные операции на критическом пути называются «критическими операциями». Критический путь обычно характеризуется нулевым полным временным резервом, т. е. с самым длинным путем в сети. В сетях может существовать несколько путей, близких к критическому. Для создания путей в сети с нулевым или положительным полным временным резервом может потребоваться адаптация длительностей операций, логических связей, опережений, задержек и других временных ограничений. После подсчета полного временного резерва пути в сети также может быть определен свободный временной резерв — период времени, на который операция может быть отложена, не вызывая задержки раннего старта любой непосредственно последующей операции в данном сетевом пути . Для расчета критического пути необходимо проделать следующие шаги: · Перечислить все задания (операции) с указанием номера задания или номера в ИСР. · Перечислить зависимости по каждой операции. · Записать продолжительность каждой операции. · Рассчитать раннюю дату начала и раннюю дату окончания каждого задания. Соответственно при расчете дат раннего начала надо учитывать все зависимости, которые есть у данной операции. · Рассчитать дату позднего старта и позднего окончания для каждой операции, учитывая существующие зависимости между операциями. · Рассчитать резерв времени для каждой операции, как разницу между датами раннего и позднего начала (или окончания). Резерв времени — всегда положительная величина. · Определить критический путь проекта путем суммирования длительности каждой операции с нулевым запасом времени. Методика, предлагаемая СРМ, в настоящее время широко распространена, однако она имеет свои недостатки. Оптимизации методом СРМ поддаются только сравнительно легко понятные проекты, в которых не трудно спрогнозировать время выполнения действия. Поэтому при разработке или конструировании различных систем (когда одна из интеллектуальных задач может быть не решаема достаточно долгое время) СРМ применим лишь условно. В итоге, МКП не может учесть ограничения на ресурсы, не учитывает неопределенность выполнения работы, не учитывает возможные риски выполнения проекта, качества выполнения работ. Данный метод разработки расписания проекта используется на проектах, где заданы не жесткие временные рамки и проект может выполняться как для внутренних нужд, так и для внешних клиентов. Нарушение их повлечет, скорее всего, временной сдвиг в сдаче проекта и санкции по отношению к руководителю проекта и соответствующие штрафные взыскания. Метод критической цепи . В управлении проектами существует одна очень крупная проблема — значительная часть проектов выполняется с существенным превышением установленных сроков, что негативно сказывается на успешности этих проектов. Быстрое выполнение проектов чрезвычайно важно и напрямую связано с прибылью, поэтому компании, способные в сжатые сроки реализовать свои проекты, обладают серьезным конкурентным преимуществом по сравнению с теми, которые регулярно срывают сроки. Именно поэтому Голдратт выбрал основной целью выполнение проекта в минимально возможный срок. Действуя согласно ТОС, определим проблемные зоны управления проектами по CPM/PERT, которые напрямую влияют на скорость выполнения проекта. Результатом подобного анализа стал следующий список проблем: 1. Выигрыш по времени не передается. 2. Работа занимает все отведенное на неё время. 3. Исполнители не передают работу на следующий этап раньше при досрочном выполнении. 4. Невозможно точно оценить продолжительность каждой работы. 5. В случаи нарушения сроков выполнения работы, предпринимаются корректирующие действия, связанные с увеличением бюджета или уменьшением объемов работ. 6. Необходимые ресурсы заняты выполнением других проектов. 7. Необходимые для выполнения задачи работы некритического пути еще не закончены. После подробного анализа каждой из проблем, Голдратт предложил свой подход к решению проблем: 1. Использовать оценки времени с 50 % перекрытием неопределенности. 2. Исполнители защищены от давления руководства на сроки выполнения работы. Обеспечить напряженную работу исполнителей над своей задачей. 3. Сконцентрироваться на дате окончания проекта, а не на определении срока выполнения каждого задания. 4. Введение проектного буфера — общий для проекта запас времени для компенсации неопределённости. 5. Введение ресурсных буферов — оповещение ресурсов занятых на критической цепи, о том, что скоро необходимо будет переключиться на выполнение задания по данному проекту. 6. Введение питающих буферов — временной резерв на покрытие неопределенности при выполнении работ некритической цепи. Критическая цепь представляет собой метод анализа сети, который изменяет расписание проекта с учетом ограниченности ресурсов. Изначально сетевая диаграмма проекта строится на основе оценок длительности, заданных зависимостей и ограничений. Затем рассчитывается критический путь. После определения критического пути учитывается наличие ресурсов и в результате определяется расписание с учетом ресурсных ограничений. Полученное расписание часто имеет измененный критический путь. Критический путь с ресурсными ограничениями известен как «критическая цепь». Метод критической цепи добавляет буферы длительности в виде операций, не предусматривающих выполнения работ, для управления неопределенностью. Один из буферов, расположенный в конце критической цепи, известен как проектный буфер и защищает статусную дату завершения от задержек на критической цепи. Дополнительные буферы, известные как «питающие буферы», располагаются в каждой точке, в которой в критическую цепь входят цепи взаимосвязанных операций извне критической цепи. Питающие буферы, таким образом, защищают критическую цепь от отставания по входящим цепям. Размер каждого буфера должен учитывать неопределенность длительности цепи зависимых операций, ведущих к данному буферу. Как только буферные операции расписания определены, операции расписания планируются на максимально поздние плановые даты старта и финиша. Таким образом, вместо управления полным временным резервом сетевых путей метод критической цепи концентрируется на управлении оставшимися длительностями буферов, сопоставляя их с оставшейся длительностью цепей операций. Опишем основные особенности метода критической цепи: 1. Метод нацелен на скорейшее выполнение проекта. 2. Позволяет управлять расписанием проекта в условиях ограниченных возобновляемых ресурсов. 3. Учитывает неопределенность продолжительностей работ. 4. Позволяет мобилизировать команду проекта на достижение его целей, обладая организационными и психологическими механизмами стимулирования. 5. Существует проблема оценки питающих и проектных буферов. Метод критической цепи желательно применять на проектах, где задан крайний срок и проект выполняется для внешнего заказчика. Как правило, подобного рода проекты, завершаются вовремя, хотя и приходится подстраиваться под текущую ситуацию скорость и объем работ. В качестве примера можно привести строительство объектов к Олимпийским играм Метод имитационного моделирования Монте-Карло Методом формализованного описания неопределенности, используемым в наиболее сложных для прогнозирования проектах, является метод Монте-Карло. Он позволяет создать множество сценариев, согласованных с заданными ограничениями исходных переменных. Метод наиболее полно отражает всю гамму неопределенностей, с которой может столкнуться реальный проект, а через изначально заданные ограничения учитывает всю информацию, имеющуюся в распоряжении аналитика. Риск - величина случайная, поэтому описывается функцией распределения случайной величины [2]. Определение формы распределения случайной величины - одна из самых сложных задач, решаемых при моделировании. Основные типы распределения вероятности, используемые при анализе рисков
Для моделирования рисков природных и техногенных процессов также используют распределение Больцмана (экспоненциальное) и распределение Парето. Для каждой категории рисков подбирается свой вид функции распределения, характеризующий частоту появления каждого значения переменной из области определения. Выбор производится на основе статистических данных или оценок экспертов. После определения функции распределения применяется процедура моделирования Монте-Карло. Алгоритм метода Монте-Карло
Проведение расчетных итераций является полностью компьютеризированной частью метода. Метод Монте-Карло итерационный - чем больше количество прогонов, тем выше точность получаемых результатов. Метод Монте-Карло При имитационных прогонах переменная выбирается случайным образом в соответствии с типом распределения и в границах заданного диапазона. Каждый прогон происходит с вероятностью: Р= 100 \ N (размер выборки) Например для 10 000 прогонов, Р=0.01% Вероятность = Р*Х, Х - количество прогонов с получением анализируемого результата Р - вероятность одного прогона При анализе инвестиционных проектов наиболее часто рассчитывается вероятность получения отрицательного значения NPV. При выборе ключевых факторов, то есть переменных, которые в значительной степени влияют на проект, а следовательно подлежат анализу, можно использовать результаты анализа чувствительности. Второй сложнейшей задачей, решаемой при использовании метода Монте-Карло, является интерпретация полученных результатов. Основным критерием принятия решения с учетом статистического анализа риска является следующий: следует выбирать проект с таким распределением вероятности исследуемого параметра, которое наилучшим образом соответствует отношению к риску конкретного инвестора. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Неопределённость — отсутствие или недостаток определения или информации о чём-либо. При решении проблем часто приходиться встречаться с множеством источников неопределенности используемой информации, но в большинстве случаев их можно разделить на две категории: недостаточно полное знание предметной области и недостаточная информация о конкретной ситуации. Получение новой информации приводит к расширению знаний или, как иногда говорят, к уменьшению неопределенности знания. Если некоторое сообщение приводит к уменьшению неопределенности нашего знания, то можно говорить, что такое сообщение содержит информацию. Ясно, что чем более неопределенна первоначальная ситуация, тем больше мы получим новой информации при получении информационного сообщения. Теория предметной области (т.е. наши знания об этой области) может быть неясной или неполной: в ней могут использоваться недостаточно четко сформулированные концепции или недостаточно изученные явления. Например, в диагностике психических заболеваний существует несколько отличающихся теорий о происхождении и симптоматике шизофрении. Неопределенность знаний приводит к тому, что правила влияния даже в простых случаях не всегда дают корректные результаты. Располагая неполным знанием, мы не можем уверенно предсказать, какой эффект даст то или иное действие. Например, терапия, использующая новые препараты, довольно часто дает совершенно неожиданные результаты. И, наконец, даже когда мы располагаем достаточно полной теорией предметной области, эксперт может посчитать, что эффективнее использовать не точные, а эвристические методы. Так, методика устранения неисправности в электронном блоке путем замены подозрительных узлов оказывается значительно более эффективной, чем скрупулезный анализ цепей в поиске детали, вышедшей из строя. Но помимо неточных знаний, неопределенность может быть внесена и неточными или ненадежными данными о конкретной ситуации. Любой сенсор имеет ограниченную разрешающую способность и отнюдь не стопроцентную надежность. При составлении отчетов могут быть допущены ошибки или в них могут попасть недостоверные сведения. На практике далеко не всегда можно получить полные ответы на поставленные вопросы, и хотя можно воспользоваться различного рода дополнительной информацией о пациенте, например с помощью дорогостоящих процедур или хирургическим путем, такие методики используются крайне редко из-за высокой стоимости и рискованности. Помимо всего прочего, существует еще и фактор времени. Не всегда есть возможность быстро получить необходимые данные, когда ситуация требует принятия срочного решения. Если работа ядерного реактора вызывает подозрение, вряд ли кто-нибудь будет ждать окончания всего комплекса проверок, прежде чем принимать решение о его остановке. Неопределенность знаний в экспертных системах При решении проблем часто приходиться встречаться с множеством источников неопределенности используемой информации, но в большинстве случаев их можно разделить на две категории: недостаточно полное знание предметной области и недостаточная информация о конкретной ситуации. Теория предметной области (т.е. наши знания об этой области) может быть неясной или неполной: в ней могут использоваться недостаточно четко сформулированные концепции или недостаточно изученные явления. Например, в диагностике психических заболеваний существует несколько отличающихся теорий о происхождении и симптоматике шизофрении. Неопределенность знаний приводит к тому, что правила влияния даже в простых случаях не всегда дают корректные результаты. Располагая неполным знанием, мы не можем уверенно предсказать, какой эффект даст то или иное действие. Например, терапия, использующая новые препараты, довольно часто дает совершенно неожиданные результаты. И, наконец, даже когда мы располагаем достаточно полной теорией предметной области, эксперт может посчитать, что эффективнее использовать не точные, а эвристические методы. Так, методика устранения неисправности в электронном блоке путем замены подозрительных узлов оказывается значительно более эффективной, чем скрупулезный анализ цепей в поиске детали, вышедшей из строя. Но помимо неточных знаний, неопределенность может быть внесена и неточными или ненадежными данными о конкретной ситуации. Любой сенсор имеет ограниченную разрешающую способность и отнюдь не стопроцентную надежность. При составлении отчетов могут быть допущены ошибки или в них могут попасть недостоверные сведения. На практике далеко не всегда можно получить полные ответы на поставленные вопросы, и хотя можно воспользоваться различного рода дополнительной информацией о пациенте, например с помощью дорогостоящих процедур или хирургическим путем, такие методики используются крайне редко из-за высокой стоимости и рискованности. Помимо всего прочего, существует еще и фактор времени. Не всегда есть возможность быстро получить необходимые данные, когда ситуация требует принятия срочного решения. Если работа ядерного реактора вызывает подозрение, вряд ли кто-нибудь будет ждать окончания всего комплекса проверок, прежде чем принимать решение о его остановке. Суммируя все сказанное, отметим, что эксперты пользуются неточными методами по двум главным причинам: точных методов не существует; точные методы существуют, но не могут быть применены на практике из-за отсутствия необходимого объема данных или невозможности их накопления по соображениям стоимости, риска или из-за отсутствия времени на сбор необходимой информации. Большинство исследователей, занимающихся проблемами искусственного интеллекта, давно пришли к единому мнению, что неточные методы играют важную роль в разработке экспертных систем, но много споров вызывает вопрос, какие именно методы должны использоваться. До последнего времени многие соглашались с утверждениями Мак-Карти и Хейеса, что теория вероятности не является адекватным инструментом для решения задач представления неопределенности знаний и данных. Выдвигались следующие аргументы в пользу такого мнения: теория вероятности не дает ответа на вопрос, как комбинировать вероятности с количественными данными; назначение вероятности определенным событиям требует информации, которой мы просто не располагаем. Другие исследователи прибавляли к этим аргументам свои: непонятно, как количественно оценивать такие часто встречающиеся на практике понятия, как «в большинстве случаев», «в редких случаях», или такие приблизительные оценки, как «старый» или «высокий»; применение теории вероятности требует «слишком много чисел», что вынуждает инженеров давать точные оценки тем параметрам, которые они не могут оценить; обновление вероятностных оценок обходится очень дорого, поскольку требует большого объема вычислений. Все эти соображения породили новый формальный аппарат для работы с неопределенностями, который получил название нечеткая логика или теория функций доверия. Этот аппарат широко используется при решении задач искусственного интеллекта, и особенно при построении экспертных систем. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
БИЛЕТ 16 |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Мультимедиа (multimedia) - это современная компьютерная информационная технология, позволяющая объединить в компьютерной системе текст, звук, видеоизображение, графическое изображение и анимацию (мультипликацию). Мультимедиа-это сумма технологий, позволяющих компьютеру вводить, обрабатывать, хранить, передавать и отображать (выводить) такие типы данных, как текст, графика, анимация, оцифрованные неподвижные изображения, видео, звук, речь. 20 лет назад мультимедиа ограничивалась пишущей машинкой " Консул ", которая не только печатала, но и могла привлечь внимание заснувшего оператора мелодичным треском. Чуть позже компьютеры уменьшились до бытовой аппаратуры, что позволило собирать их в гаражах и комнатах. Нашествие любителей дало новый толчок развития мультимедиа (компьютерный гороскоп 1980 года который при помощи динамика и программируемого таймера синтезировал расплывчатые устные угрозы на каждый день да еще перемещал по экрану звезды (зачатки анимации)). Примерно в это время появился и сам термин мультимедиа. Скорее всего, он служил ширмой, отгораживавшей лаборатории от взглядов непосвященных ("А что это у тебя там звенит ? ". " Да, это мультимедиа "). Критическая масса технологий накапливается. Появляются бластеры, "сиди ромы" и другие плоды эволюции, появляется интернет, WWW, микроэлектроника. Человечество переживает информационную революцию. И вот мы становимся свидетелями того, как общественная потребность в средствах передачи и отображения информации вызывает к жизни новую технологию, за неимением более корректного термина называя ее мультимедиа. В наши дни это понятие может полностью заменить компьютер практически в любом контексте. Совсем другое развитие получило мультимедиа у нас в стране: В России мультимедиа появилась примерно в конце 80х годов, и она не использовалась на домашних компьютерах, а использовалась только специалистами. Поэтому в статьях газет и журналов тех лет она упоминалась редко. Слово мультимедиа не вызывало ничего кроме недоумения или шуточек "Какая еще вам, -говорили мультимедиа! Посмотрите, что в стране делается!" Только в 1993 году многие поняли или начали понимать важность направления, осознавать роль, которую технология мультимедиа предстоит сыграть в 90е годы. Слово мультимедиа стало вдруг таким модным и в нашей стране, и все новые команды и организации поднимают этот флаг. Образовались новые коллективы разработчиков систем и конечных продуктов мультимедиа; появились потребители таких систем и продуктов, при чем весьма нетерпеливые. Конференция, состоящая 25-26 февраля 1993 года, как бы открыла сезон мультимедиа в России. 1994 год можно смело назвать годом начала бума домашнего мультимедиа на российском компьютерном рынке. А в наши дни мультимедиа - есть почти у всех, у кого есть компьютер и программное обеспечение на мультимедиа продаются везде разных типов, то есть она вошла в обиход. В широком смысле термин "мультимедиа" означает спектр информационных технологий, использующих различные программные и технические средства с целью наиболее эффективного воздействия на пользователя (ставшего одновременно и читателем, и слушателем, и зрителем). Благодаря применению мультимедиа в средствах информатизации за счет одновременного воздействия графической, звуковой, фото и видео информации такие средства обладают большим эмоциональным зарядом и активно включаются в индустрию развлечений, практику работы различных учреждений, домашний досуг. Появление систем мультимедиа произвело революцию во многих областях деятельности человека. Одно из самых широких областей применения технология мультимедиа получила в сфере образования, поскольку средства информатизации, основанные на мультимедиа способны, в ряде случаев, существенно повысить эффективность обучения. Экспериментально установлено, что при устном изложении материала обучаемый за минуту воспринимает и способен переработать до одной тысячи условных единиц информации, а при "подключении" органов зрения до 100 тысяч таких единиц. В настоящее время количество созданных средств мультимедиа измеряется тысячами наименований. Мультимедиа-технологии и соответствующие средства ИКТ развиваются очень быстро. Если в первом издании российского справочника по CD-ROM и мультимедиа, изданного в 1995 году, перечислено всего 34 экземпляра мультимедиа-продуктов образовательного назначения, в издании 1996 года таких продуктов было перечислено уже более 112-ти, а в начале 1998 года это число перевалило за 300, то сейчас этот список содержит несколько тысяч наименований. Безусловно, эти показатели не отражают точной картины обеспеченности средствами мультимедиа, но однозначно свидетельствуют о неуклонном росте числа создаваемых и используемых средств мультимедиа. Средства и технологии мультимедиа обеспечивают возможность интенсификации обучения и повышение мотивации к учению за счет применения современных способов обработки аудиовизуальной информации, таких, как:
В последнее время наметилось создание интегрированных информационных технологии, лежащих в основе так называемых систем комплексной информации [24]. Примером подобной технологии может служить мультимедиа-технология, позволяющая одновременно работать с числовой, текстовой, графической и аудио-видео информацией в реальном масштабе времени. И все это под управлением одного компьютера. К ее предшественникам можно отнести, например, интерактивные графические технологии, применяемые уже в течение двух десятков лет в САПР электронных компонентов и систем. Определяющими для развития мультимедиа-технологии являются достигнутые успехи в таких системах, как рабочие станции, широкополосные линии коммуникаций, запоминающие устройства большой емкости, цветные мониторы высокого разрешения. Передача больших объемов данных в мультимедиа системах требует высокой скорости и широкой полосы передачи. Развитие коммуникационных стандартов ISDN и FDD1 и оптиковолоконных линий связи в локальных сетях позволяют в значительной степени удовлетворить эти потребности. Вводу того, что информация в мультимедиа системах по своей природе представляет данные очень большого объема, проблема их хранения носит ключевой характер. Здесь прорывным решением является технология использования различных типов оптических дисков (CD - ROM - только читаемых, WORM - с однократной записью, CD-I с перезаписью). Графика и изображения требуют адекватных средств отображения. Имеющиеся сегодня мониторы разрешением 1000х1000 с 256 цветами уже можно считать таковыми. Мультимедиа-технологии опираются не только на достижения в аппаратных средствах, но и на технологические успехи в программном обеспечении, среди которых отметим два важных момента. Технология сжатия изображений является неотъемлемой частью при обработке образов и изображений. Достигнутые уровни сжатия изображений 120:1 позволяют на современных рабочих станциях выйти на работу в реальном времени, что необходимо в мультимедиа системах. Для манипуляции с данными мультимедиа систем важное значение имеют графические редакторы и человеко-машинные интерфейсы.
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Для решения задач обработки данных используются различные статистические методы: проверка гипотез, оценивание параметров и числовых характеристик случайных величин и процессов, корреляционный и дисперсионный анализ. Чтобы решение задачи было проведено качественно, необходимо провести предварительную обработку данных, для того чтобы не возвращаться повторно к решению той или иной задачи после получения результатов на последующем этапе обработки. Чтобы понять, с помощью, какой программы, или каким методом проводить обработку данных, необходимо помнить, что при наблюдении и проведении эксперимента встречаются ошибки грубые, систематические и случайные. В зависимости от точности и сложности эксперимента выбираются и методы обработки данных. Если эксперимент не предполагает особой точности и сложности можно выбрать простую программу и провести статистическую обработку, если же необходима высокая точность измерения, то и программу необходимо выбирать более сложную. Другими словами технология обработки экспериментальных данных зависит от того результата, к которому Вы стремитесь. Обработке экспериментальных данных с целью построения моделей «сложных систем» (эмпирических зависимостей) должна предшествовать предварительная обработка, содержание которой, в основном, состоит в отсеивании грубых погрешностей измерений и в проверке соответствия распределения результатов нормальному закону. Следует помнить, что только после выполнения предварительной обработки можно с наибольшей эффективностью, а главное корректно, использовать более сложные экспериментально-статистические методы, позволяющие получать математические модели даже таких процессов, строгое детерминированное описание которых вообще отсутствует. Все методы количественной обработки принято подразделять на первичные и вторичные. Первичная статистическая обработка нацелена на упорядочивание информации об объекте и предмете изучения. На этой стадии «сырые» сведения группируются по тем или иным критериям, заносятся в сводные таблицы. Первично обработанные данные, представленные в удобной форме, дают исследователю в первом приближении понятие о характере всей совокупности данных в целом: об их однородности – неоднородности, компактности – разбросанности, четкости – размытости и т. д. Эта информация хорошо считывается с наглядных форм представления данных и дает сведения об их распределении. В ходе применения первичных методов статистической обработки получаются показатели, непосредственно связанные с производимыми в исследовании измерениями. К основным методам первичной статистической обработки относятся: вычисление мер центральной тенденции и мер разброса (изменчивости) данных. Первичный статистический анализ всей совокупности полученных в исследовании данных дает возможность охарактеризовать ее в предельно сжатом виде и ответить на два главных вопроса: 1) какое значение наиболее характерно для выборки; 2) велик ли разброс данных относительно этого характерного значения, т. е. какова «размытость» данных. Для решения первого вопроса вычисляются меры центральной тенденции, для решения второго – меры изменчивости (или разброса). Эти статистические показатели используются в отношении количественных данных, представленных в порядковой, интервальной или пропорциональной шкале. Меры центральной тенденции – это величины, вокруг которых группируются остальные данные. Данные величины являются как бы обобщающими всю выборку показателями, что, во-первых, позволяет судить по ним обо всей выборке, а во-вторых, дает возможность сравнивать разные выборки, разные серии между собой. К мерам центральной тенденции в обработке результатов психологических исследований относятся: выборочное среднее, медиана, мода. Выборочное среднее (М) – это результат деления суммы всех значений (X) на их количество (N).
Медиана (Me) – это значение, выше и ниже которого количество отличающихся значений одинаково, т. е. это центральное значение в последовательном ряду данных. Медиана не обязательно должна совпадать с конкретным значением. Совпадение происходит в случае нечетного числа значений (ответов), несовпадение – при четном их числе. В последнем случае медиана вычисляется как среднее арифметическое двух центральных значений в упорядоченном ряду. Мода (Мо) – это значение, наиболее часто встречающееся в выборке, т. е. значение с наибольшей частотой. Если все значения в группе встречаются одинаково часто, то считается, что моды нет. Если два соседних значения имеют одинаковую частоту и больше частоты любого другого значения, мода есть среднее этих двух значений. Если то же самое относится к двум несмежным значениям, то существует две моды, а группа оценок является бимодальной. Обычно выборочное среднее применяется при стремлении к наибольшей точности в определении центральной тенденции. Медиана вычисляется в том случае, когда в серии есть «нетипичные» данные, резко влияющие на среднее. Мода используется в ситуациях, когда не нужна высокая точность, но важна быстрота определения меры центральной тенденции. Вычисление всех трех показателей производится также для оценки распределения данных. При нормальном распределении значения выборочного среднего, медианы и моды одинаковы или очень близки. Меры разброса (изменчивости) – это статистические показатели, характеризующие различия между отдельными значениями выборки. Они позволяют судить о степени однородности полученного множества, его компактности, а косвенно и о надежности полученных данных и вытекающих из них результатов. Наиболее используемые в психологических исследованиях показатели: среднее отклонение, дисперсия, стандартное отклонение. Размах (Р) – это интервал между максимальным и минимальным значениями признака. Определяется легко и быстро, но чувствителен к случайностям, особенно при малом числе данных. Среднее отклонение (МД) – это среднеарифметическое разницы (по абсолютной величине) между каждым значением в выборке и ее средним.
где d = |Х – М |, М – среднее выборки, X – конкретное значение, N – число значений. Множество всех конкретных отклонений от среднего характеризует изменчивость данных, но если не взять их по абсолютной величине, то их сумма будет равна нулю и мы не получим информации об их изменчивости. Среднее отклонение показывает степень скученности данных вокруг выборочного среднего. Кстати, иногда при определении этой характеристики выборки вместо среднего (М) берут иные меры центральной тенденции – моду или медиану. Дисперсия (D) характеризует отклонения от средней величины в данной выборке. Вычисление дисперсии позляет избежать нулевой суммы конкретных разниц (d = Х – М) не через их абсолютные величины, а через их возведение в квадрат:
где d = |Х – М|, М – среднее выборки, X – конкретное значение, N – число значений. Стандартное отклонение (б). Из-за возведения в квадрат отдельных отклонений d при вычислении дисперсии полученная величина оказывается далекой от первоначальных отклонений и потому не дает о них наглядного представления. Чтобы этого избежать и получить характеристику, сопоставимую со средним отклонением, проделывают обратную математическую операцию – из дисперсии извлекают квадратный корень. Его положительное значение и принимается за меру изменчивости, именуемую среднеквадратическим, или стандартным, отклонением:
где d = |Х– М|, М – среднее выборки, X– конкретное значение, N – число значений. МД, D и б применимы для интервальных и пропорционных данных. Для порядковых данных в качестве меры изменчивости обычно берут полуквартильное отклонение (Q), именуемое еще полуквартильным коэффициентом. Вычисляется этот показатель следующим образом. Вся область распределения данных делится на четыре равные части. Если отсчитывать наблюдения начиная от минимальной величины на измерительной шкале, то первая четверть шкалы называется первым квартилем, а точка, отделяющая его от остальной части шкалы, обозначается символом Q.1Вторые 25 % распределения – второй квартиль, а соответствующая точка на шкале – Q2. Между третьей и четвертой четвертями распределения расположена точка Q3. Полуквартильный коэффициент определяется как половина интервала между первым и третьим квартилями:
При симметричном распределении точка Q2 совпадет с медианой (а, следовательно, и со средним), и тогда можно вычислить коэффициент Q для характеристики разброса данных относительно середины распределения. При несимметричном распределении этого недостаточно. Тогда дополнительно вычисляют коэффициенты для левого и правого участков:
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Системные требования — это описание примерных характеристик, которым должен соответствовать компьютер для того, чтобы на нём могло использоваться какое-либо определённое программное обеспечение. Эти характеристики могут описывать требования как к аппаратному обеспечению (тип и частота процессора, объём оперативной памяти, объём жёсткого диска), так и к программному окружению (операционная система, наличие установленных системных компонентов и сервисов и т. п.). Обычно такие требования составляются производителем или автором ПО. Типы системных требований. Для некоторого ПО различают минимальные и рекомендуемые системные требования: Минимальные системные требования — это набор условий, необходимых для возможности запуска и работы программного продукта. Однако, наличие минимальных системных требований не отменяет возможность запуска ПО на компьютерах, которые по характеристикам слабее минимальных. Рекомендуемые системные требования — набор характеристик, подразумевающих оптимальную работу большей части возможностей продукта. Однако, даже если компьютер и подходит под рекомендуемые системные требования, это не значит высокой производительности ПО, например, в некоторых играх невозможно играть на максимальных настройках графики. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
В многоуровневых моделях четко расписаны функции каждого уровня и взаимосвязь с соседними уровнями. Все сетевые протоколы разрабатываются в соответствии с сетевой моделью и принадлежат определенному ее уровню. Так, взяв для примера определенный протокол, можно с уверенностью говорить какие функции (глобальные) на него возложены, а какие он не может выполнять. Так же и сетевое оборудование можно отнести к определенному уровню модели, учитывая его функции. И что это нам дает? А то, что мы можем утверждать о распространении коллизий, широковещательных сообщений, возможности работы отдельных протоколов или общения двух хостов вообще и так далее, список довольно широкий. Сетевая модель помогает в поиске ошибок и неисправностей, так как по симптомам часто можно определить к какому уровню относится проблема. После чего существенно сужается область поиска (протоколы, оборудование и т.д.). Если же симптомы не наталкивают на решение, то можно систематически проходить по всей модели от нижних уровней к верхним, обращая внимание на функционирование сети. Нижний уровень, выявляющий неполадки (функции, возложенные на него, не выполняются или выполняются с ошибками) и есть проблемным. И напоследок, сетевая модель создает некий стандарт, гарантирующий совместимость протоколов и оборудования разных производителей. Среди основных сетевых моделей существуют две: модель OSI и модель TCP/IP. Иногда можно встретить их как теоретическую и практическую модели. Они являются многоуровневыми, что значит четкое разбиение на отдельные уровни. Как сказано выше, каждому уровню четко приписаны функции, которые в пределах одной модели не повторяются. Таким образом модель OSI разбита на 7 уровней, а модель TCP/IP на 4 уровня:
Модели так изображены не зря. Во первых, уровни модели OSI довольно часто упоминают по номерам (они пронумерованы снизу вверх), в то время как уровни модели TCP/IP называют по именам. А второе - это то, что модель TCP/IP можно описать терминами OSI. Как показано, обе модели имеют идентичные уровни Transport и Internet (Network), на которые возложены соответственно одинаковые задачи. Но, к примеру, модель TCP/IP не различает границы между физическим представлением сигналов, битов на проводах (или в другой среде передачи данных) и способом доступа к тем самым проводам. Это делает модель менее предпочтительной для поисков неполадок, так как, к примеру, битый кабель или разного рода помехи радио-волн не имеют ничего общего с заполненностью таблицы MAC-адресов на свиче. OSI детально описывает процесс общения двух приложений, а также взаимосвязь между соседними уровнями. Чтобы понять, что же все-таки это значит, рассмотрим поближе каждый уровень. Уровни можно рассматривать с точки зрения отправления данных или приема данных. Проще говоря сверху вниз или снизу вверх соответственно. Модель спроектирована так, что если рассматривать отправку сообщения каким-либо приложением, то оно проходит по уровням с самого верху и к самому низу. Для приема сообщение все с точностью наоборот. Дальше будет ясно... Лично я предпочитаю второй способ, так как привык смотреть на принятые данные целиком (т.е. весь сетевой кадр). Но в обучающих материалах, как правило, считают иначе. В них уровни излагаются от самого понятного и близкого пользователю уровня приложений, до самого далекого - физического уровня. Это должно вам помочь выбрать в каком порядке читать описание уровней.
При прохождении каждого уровня, к данным дописывается служебная информация. Этот процесс называется инкапсуляцией. Так например на сетевом уровне, если мы хотим использовать протокол IP, будет дописан в начало заголовок, содержащий IP адреса отправителя и получателя и т.п. Затем, проходя канальный уровень, к данным с заголовком IP в начало еще дописывается заголовок, содержащий MAC адреса, а в конец - так называемый трейлер с контрольной суммой. Таким образом мы рассмотрели инкапсуляцию на двух уровнях в сетях Ethernet. Обратный процесс к инкапсуляции - декапсуляция. Это процесс извлечения данных, путем отбрасывания служебной информации. Придерживаясь прошлого примера, представим, что получены некие данные. Декапсуляция на канальном уровне будет заключаться в отбросе заголовка, содержащего MAC адреса и трейлера. Полученные данные уже содержат заголовок IP в начале, они передаются на следующий сетевой уровень. Далее на сетевом уровне нету информации нижележащих уровней, что обеспечивает некую независимость от них. Аналогичным образом извлекается полезная нагрузка, путем отбрасывания заголовка и так далее. В самом конце цепочки получаем оригинальное сообщение. В рассмотренных примерах данные на каждом уровне имеют разную структуру, которая называется PDU (Protocol Data Unit). И, естественно, на каждом уровне PDU оригинального сообщения свой: 7. Уровень приложений - данные (data) 4. Транспортный уровень - сегмент (segment) 3. Сетевой уровень - пакет (packet) 2. Канальный уровень - кадр (frame) 1. Физический уровень - биты (bits) Особенно часто различают понятие кадра и пакета. Кадр будет содержать служебную информацию второго уровня, когда пакет уже нет. И для кадра пакет будет являться полезной нагрузкой, внутренняя сущность которого не рассматривается. Общение между двумя приложениями или просто хостами происходят между одинаковыми уровнями, используя для этого один протокол. Так, например, веб-браузер, запрашивая по протоколу HTTP (протокол седьмого уровня) страницу, общается с веб-сервером на седьмом уровне. Сервер в свою очередь знает структуру сообщения, соответствующую протоколу. Выбор протокола - это как выбор языка в устной речи (для понимания нужно говорить на одном). На этом этапе как сервер так и клиент не рассматривает нижележащие уровни, они просто обмениваются сообщениями. Если же рассмотреть с точки зрения отправки HTTP запроса в IP пакете, то операционные системы клиента и сервера общаются на третьем уровне. Они смотрят им ли предназначен пакет по IP адресу, собирают пакет воедино из фрагментов (если по пути пакет был фрагментирован). Но при этом они ничего не знают о втором уровне, через какую среду будут следовать данные и так далее. Полезная нагрузка содержит сегменты TCP, которые в свою очередь содержат данные HTTP. Но на этапе рассмотрения IP пакета вся полезная нагрузка рассматривается просто как последовательность байт, не более. Для жизненного примера вышеописанного, можно предложить примитивную модель для той же устной речи. Рассмотрим такие два уровня выдуманной модели: доставка собеседнику звуков и разбор речи. Таким образом вначале нужно договориться, каким образом принимать звуки. Протоколом здесь будут выступать правила и способы произношения звуков, чтобы собеседник их услышал. Затем услышанные звуки, не важно как и откуда, будут восприняты как отдельные слова, чтобы их понять, нужно договориться об использовании одного языка. Ведь если говорить на одном языке, а пытаться его понимать как другой, ничего не выйдет. Таким образом был продемонстрирован переход из первого уровня на второй, когда собеседник воспринимает речь, путем "декапсуляции" звуков в слова. Если же собеседник хочет что-то сказать, то он слова "инкапсулирует" в звуки, которые уже произносит. Применение Модель TCP/IP часто используется для описания стека протоколов. Например, стек протоколов TCP/IP. Где под стеком протоколов можно понимать множество взаимодействующих протоколов, обеспечивающих функциональность сети. Ведь сложно представить работу сети с одним лишь протоколом IP, в сети постоянно взаимодействуют разные протоколы, каждый реализуя свои задачи. Модель OSI используется для описания и выявления разного рода неполадок, для классификации сетевого оборудования или отдельного сетевого протокола. Например, рассмотрим разные виды сетевого оборудования: повторитель и концентратор (хаб), мост и коммутатор 2-го уровня (свич), маршрутизатор и коммутатор 3-го уровня. Как вы уже догадались эти три вида оборудования принадлежат трем нижним уровням модели оси: первому, второму и третьему соответственно. Что же мы можем сказать сходу об этих устройствах? Устройства первого уровня различают только сигналы. Они предназначены для расширения шины сети и усиления сигнала, предотвращая тем самым его затухание. Такие устройства только дублируют сигналы, таки образом расширяя домен коллизий (наложение сигналов). Устройства второго уровня уже считывают заголовок кадра и таким образом могут обнаружить коллизию или несоответствие контрольной сумме (если она присутствует в протоколе). Отбрасывая "испорченные" кадры, такое оборудование ограничивает домен коллизий. Устройства третьего уровня работают с пакетами. И потому они ограничивают широковещательный домен. Также знание по номерам и названиям уровней модели OSI позволяет общаться и понимать друг друга двум администраторам или разработчикам, да и просто людям, замешанным каким-либо образом с сетями. Основные сетевые приложения и сервисы сети Интернет Взаимодействие компьютеров между собой, а также с другим активным сетевым оборудованием, в TCP/IP-сетях организовано на основе использования сетевых служб, которые обеспечиваются специальными процессами сетевой операционной системы (ОС) — демонами в UNIX-подобных ОС, службами в ОС семейства Windows и т. п. Примерами сетевых сервисов являются веб-серверы (в т.ч. сайты всемирной паутины), электронная почта, FTP-серверы для обмена файлами, приложения IP-телефонии и многое другое. Основу работы сети составляют так называемые сетевые службы (или сервисы). Базовый набор сетевых служб любой корпоративной сети состоит из следующих служб:
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Сущность структурного подхода заключается в декомпозиции программы или программной системы по функциональному принципу. Все предлагаемые методы декомпозиции используют интерфейсы простейшего типа: примитивные интерфейсы и традиционные меню, и рассчитаны на анализ и проектирование как структур данных, так и обрабатывающих их программ. Причем в большинстве случаев первичным считают проектирование обрабатывающих компонентов, проектирование же структур данных выполняют параллельно. Существует и альтернативный подход, при котором первичным считают проектирование данных, а обрабатывающие программы получают, анализируя полученные структуры данных. В любом случае проектирование программного обеспечения начинают с определения его структуры. Процесс проектирования сложного программного обеспечения начинают с уточнения его структуры, т. е. определения структурных компонентов и связей между ними. Результат уточнения структуры может быть представлен в виде структурной и/или функциональной схем и описания (спецификаций) компонентов. Структурная схема разрабатываемого программного обеспечения. Структурной называют схему, отражающую состав и взаимодействие по управлению частей разрабатываемого программного обеспечения. Структурные схемы пакетов программ не информативны, поскольку организация программ в пакеты не предусматривает передачи управления между ними. Поэтому структурные схемы разрабатывают для каждой программы пакета, а список программ пакета определяют, анализируя функции, указанные в техническом задании. Самый простой вид программного обеспечения - программа, которая в качестве структурных компонентов может включать только подпрограммы и библиотеки ресурсов. Разработку структурной схемы программы обычно выполняют методом пошаговой детализации Структурными компонентами программной системы или программного комплекса могут служить программы, подсистемы, базы данных, библиотеки ресурсов и т. п. Структурная схема программного комплекса демонстрирует передачу управления от программы-диспетчера соответствующей программе, например
Структурная схема п р о г р а м м н о й с и с т е м ы, как правило, показывает наличие подсистем или других структурных компонентов. В отличие от программного комплекса отдельные части (подсистемы) программной системы интенсивно обмениваются данными между собой и, возможно, с основной программой. Структурная же схема программной системы этого обычно не показывает
Более полное представление о проектируемом программном обеспечении с точки зрения взаимодействия его компонентов между собой и с внешней средой дает функциональная схема. Функциональная схема. Функциональная схема или схема данных (ГОСТ 19.701-90) - схема взаимодействия компонентов программного обеспечения с описанием информационных потоков, состава данных в потоках и указанием используемых файлов и устройств. Для изображения функциональных схем используют специальные обозначения, установленные стандартом. Основные обозначения схем данных по ГОСТ 19.701-90 приведены в табл. Функциональные схемы, более информативны, чем структурные. Все компоненты структурных и функциональных схем должны быть описаны При структурном подходе особенно тщательно необходимо прорабатывать спецификации межпрограммных интерфейсов, так как от качества их описания зависит количество самых дорогостоящих ошибок. К самым дорогим относятся ошибки, обнаруживаемые при комплексном тестировании, так как для их устранения могут потребоваться серьезные изменения уже отлаженных текстов.
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
БИЛЕТ 17 |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Компью́терная гра́фика (также маши́нная графика) — область деятельности, в которой компьютеры используются в качестве инструмента, как для синтеза (создания) изображений, так и для обработки визуальной информации, полученной из реального мира. Двухмерная (2D — от англ. two dimensions — «два измерения») компьютерная графика классифицируется по типу представления графической информации, и следующими из него алгоритмами обработки изображений. Обычно компьютерную графику разделяют на векторную и растровую, хотя обособляют ещё и фрактальный тип представления изображений. Векторная графика Пример векторного рисунка Векторная графика представляет изображение как набор геометрических примитивов. Обычно в качестве них выбираются точки, прямые, окружности, прямоугольники, а также, как общий случай, кривые некоторого порядка. Объектам присваиваются некоторые атрибуты, например, толщина линий, цвет заполнения. Рисунок хранится как набор координат, векторов и других чисел, характеризующих набор примитивов. При воспроизведении перекрывающихся объектов имеет значение их порядок. Изображение в векторном формате даёт простор для редактирования. Изображение может без потерь масштабироваться, поворачиваться, деформироваться, также имитация трёхмерности в векторной графике проще, чем в растровой. Дело в том, что каждое такое преобразование фактически выполняется так: старое изображение (или фрагмент) стирается, и вместо него строится новое. Математическое описание векторного рисунка остаётся прежним, изменяются только значения некоторых переменных, например, коэффициентов. При преобразовании растровой картинки исходными данными является только описание набора пикселей, поэтому возникает проблема замены меньшего числа пикселей на большее (при увеличении, или большего на меньшее (при уменьшении). Простейшим способом является замена одного пикселя несколькими того же цвета (метод копирования ближайшего пикселя: Nearest Neighbour). Более совершенные методы используют алгоритмы интерполяции, при которых новые пиксели получают некоторый цвет, код которого вычисляется на основе кодов цветов соседних пикселей. Подобным образом выполняется масштабирование в программе Adobe Photoshop (билинейная и бикубическая интерполяция). Вместе с тем, не всякое изображение можно представить как набор из примитивов. Такой способ представления хорош для схем, используется для масштабируемых шрифтов, деловой графики, очень широко используется для создания мультфильмов и просто роликов разного содержания. Растровая графика Растровая графика всегда оперирует двумерным массивом (матрицей) пикселей. Каждому пикселю сопоставляется значение яркости, цвета, прозрачности — или комбинация этих значений. Растровый образ имеет некоторое число строк и столбцов. Без особых потерь растровые изображения можно только лишь уменьшать, хотя некоторые детали изображения тогда исчезнут навсегда, что иначе в векторном представлении. Увеличение же растровых изображений оборачивается «красивым» видом на увеличенные квадраты того или иного цвета, которые раньше были пикселями. В растровом виде представимо любое изображение, однако этот способ хранения имеет свои недостатки: больший объём памяти, необходимый для работы с изображениями, потери при редактировании. Фрактальная графика Фрактал — объект, отдельные элементы которого наследуют свойства родительских структур. Поскольку более детальное описание элементов меньшего масштаба происходит по простому алгоритму, описать такой объект можно всего лишь несколькими математическими уравнениями. Фракталы позволяют описывать целые классы изображений, для детального описания которых требуется относительно мало памяти. С другой стороны, фракталы слабо применимы к изображениям вне этих классов. Трёхмерная графика (3D — от англ. three dimensions — «три измерения») оперирует с объектами в трёхмерном пространстве. Обычно результаты представляют собой плоскую картинку, проекцию. Трёхмерная компьютерная графика широко используется в кино, компьютерных играх. Трехмерная графика бывает полигональной и воксельной. Воксельная графика, аналогична растровой. Объект состоит из набора трехмерных фигур, чаще всего кубов. А в полигональной компьютерной графике все объекты обычно представляются как набор поверхностей, минимальную поверхность называют полигоном. В качестве полигона обычно выбирают треугольники. Всеми визуальными преобразованиями в векторной (полигональной) 3D-графике управляют матрицы (см. также: аффинное преобразование в линейной алгебре). В компьютерной графике используется три вида матриц: - матрица поворота - матрица сдвига - матрица масштабирования Любой полигон можно представить в виде набора из координат его вершин. Так, у треугольника будет 3 вершины. Координаты каждой вершины представляют собой вектор (x, y, z). Умножив вектор на соответствующую матрицу, мы получим новый вектор. Сделав такое преобразование со всеми вершинами полигона, получим новый полигон, а преобразовав все полигоны, получим новый объект, повёрнутый/сдвинутый/масштабированный относительно исходного. Материальной основой любой САПР является программно-технический комплекс, включающий в себя технические и программно-методические средства. Технические средства САПР содержат следующие согласованные между собой элементы: устройства ввода информации в виде различного периферийного оборудования ЭВМ (дисплеи, cчитыватели графической информации, ввод с различных носителей информации); устройства хранения информации (внешние запоминающие устройства ЭВМ); устройства переработки информации (программное обеспечение и центральные процессоры ЭВМ); устройства отображения и вывода информации в удобной для проектировщика форме (чертежный автомат, дисплей, печатающие устройства); устройства управления процессами обработки информации при проектировании. Программно-методические средства включают в себя пакеты программ, базы данных и документацию по эксплуатации САПР. Функциональными составляющими САПР являются проектирующие и обслуживающие подсистемы. К первым из них относятся подсистемы, предназначенные для выполнения операций проектирования отдельных частей объекта или определенных стадий проектирования (например, подсистема выполнения расчетов). Обслуживающими называют подсистемы, обеспечивающие функционирование проектирующих подсистем. Это информационно-поисковая, подсистема графического отображения объектов, формирования документов и др. Проектирующие подсистемы САПР в большинстве случаев являются объектно-ориентированными, т. е. применимыми только для данного вида проектируемых объектов. Обслуживающие подсистемы чаще всего выполняют инвариантными, объектно-независимыми. Перечисленные подсистемы САПР обладают всеми свойствами систем, т. е. могут функционировать самостоятельно и подвергаться декомпозиции на составляющие элементы, которые принято называть компонентами САПР. В отечественной литературе обычно выделяют следующие обязательные компоненты САПР: методическое обеспечение, содержащее комплекс документов описания САПР, данные о составе, правила обслуживания и использования; лингвистическое обеспечение — совокупность специальных проблемно-ориентированных языков проектирования; математическое обеспечение — совокупность математических методов, моделей, алгоритмов, необходимых для выполнения проектных процедур; программное обеспечение — комплекс всех программ и эксплуатационной документации к ним; техническое обеспечение — совокупность всех технических средств, используемых при автоматизированном проектировании, диагностике и ремонте вычислительной техники; информационное обеспечение — совокупность информации, используемой проектировщиком непосредственно для получения проектных решений и содержащейся в машинных банках данных или в иных документах; организационное обеспечение — комплект документов, устанавливающих правила выполнения проектирования, в том числе: правила выпуска, корректирования и использования выходных документов, правила доступа к базам данных, приоритеты использования средств САПР, порядок взаимодействия всех проектирующих и обслуживающих подразделений. При разработке САПР, их подсистем и компонентов учитывают несколько основополагающих принципов: - принцип системного единства и совместимости, предполагающий взаимосвязь и взаимодействие подсистем в процессе функционирования САПР, стремление к достижению единой цели системы; - принцип развития, предусматривающий возможность пополнения и обновления подсистем и компонентов САПР; - принцип оптимального распределения процессов преобразования информации (задач проектирования) между человеком и ЭВМ с учетом возможностей их взаимодействия; - принцип унификации компонентов и инвариантности их по отношению к широкому кругу проектируемых объектов; - принцип смежности этапов проектирования, согласно которому выходная информация одного этапа проектирования является исходной для последующего (конвейерная обработка информации); - блочно-иерархический принцип построения подсистем САПР, естественно вытекающий из иерархического характера процесса проектирования. Перечисленные принципы позволили создать и успешно эксплуатировать системы автоматизированного проектирования, их подсистемы и элементы в различных областях проектной деятельности. Говоря о разработке и внедрении САПР, необходимо подчеркнуть динамичный, развивающийся характер автоматизации проектных работ. На ранних стадиях осуществляется привлечение машинных методов и средств к выполнению рутинных, повторяющихся операций. Далее разрабатываются модели и программы для решения с помощью ЭВМ частных проектных задач, создается некая взаимосвязанная система. Эта система расширяется и постепенно охватывает задачи все более высокого уровня формализации вплоть до задач, связанных с творческой стороной процесса проектирования. Наиболее сложным этапом создания САПР, определяющим при прочих равных условиях эффективность системы в целом, является разработка математического обеспечения. Несмотря на то что в явном виде этот компонент в автоматизированном проектировании не используется (используют производный компонент — программное обеспечение), его роль и значение трудно переоценить. В зависимости от назначения и способа реализации в математическом обеспечении выделяют две взаимосвязанные части. К первой относят математические методы и модели, описывающие объекты проектирования или их элементы и отражающие их специфику. Вторая часть включает в себя формализованное описание технологии автоматизированного проектирования и носит инвариантный или достаточно обобщенный характер по отношению к конкретному объекту. Разработка вопросов, относящихся ко второй части математического обеспечения, представляет собой сложную задачу в связи с необходимостью отражения в них всей логики технологии проектирования, включая творческие, слабо формализованные ее элементы. Развитие математического обеспечения САПР происходит по двум базовым направлениям: разработка и совершенствование методов получения оптимальных проектных решений в условиях автоматизированного проектирования; совершенствование и типизация процессов и элементов автоматизированного проектирования, инвариантных по отношению к объекту проектирования. Точные математические методы поиска оптимальных проектных решений малодоступны. Поэтому, как уже говорилось, эту задачу часто решают на основе использования банков (фондов) знаний и типовых эвристических методов. При оценке эффективности автоматизированного проектирования необходимо учитывать не только экономическую сторону вопроса, связанную с оценкой затрат, но и такие аспекты проблемы, как повышение качества проектного решения, большая глубина проработки проектной ситуации, более высокая вероятность получения принципиально новых решений, социальная сторона автоматизации умственной деятельности. К настоящему времени САПР и ее подсистемы широко используются при решении различных проектных задач. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Гипертекстовая структура получила исключительно широкое распространение, в основном, в информационно-справочных системах в различных областях знания. Такие программы обеспечивают электронный просмотр больших объемов иерархически организованной текстовой и графической информации. Гипертекстовая структура обеспечивает быстрый поиск информации по различным признакам. Гипертекст - это информационный массив, на котором заданы и автоматически поддерживаются связи между выделенными элементами. В виде гипертекста может быть представлена любая слабо формализованная совокупность текстов или изображений. Гипертекстовая форма представления информации является следствием эволюции средств общения людей между собой, и гипертекст соответствует природе мышления человека. Гипертекст в обобщенном смысле - это интерактивная информационная система, созданная на основе множества естественных и искусственных языков, гибких аппаратных и программных средств, позволяющих пользователю динамично и творчески взаимодействовать с изменяемым информационным массивом с целью получения нового для себя знания. Все большее распространение получают также системы гипермедиа. Под гипермедиа понимается способ организации мультимедиа. Мультимедиа предполагает объединение в компьютерной системе нескольких средств предоставления информации, а именно: текст, звук, графика, мультипликация, видео, пространственное моделирование. Гипермедиа состоит из узлов, которые являются основными единицами хранения информации и могут включать в себя страницы текста, графику, звуковую информацию, видеоклип или целый документ. Взаимное согласование голоса лектора, музыкального и шумового сопровождения с визуальным рядом способно обеспечить образное восприятие учебного материала, эмоциональное воздействие на ученика, что даёт не только более глубокие и "долгоживущие" знания, но сопряжено с гораздо меньшей нагрузкой на зрение учащихся. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Развитие теории семантической информации – семантическая инф-ция –центральное понятие инф-ки. Теория такой информации изучает элементарную и неэлементарную инф-цию и т.д. Проблема – на основе понятия неэлементарной информации исследовать вопросы матем. статистки, ввести и изучить понятие количества неэлементарной инф-ции. Развитие теории ультраоператоров – в инт. системах центральным элементом является преобразователь информации (ультрасистема). Ультраоператор – мат. модель такого преобразователя. Теория ультраоператоров изучает особенности отд. Классов у.оп-ров, способы постр. у.оп-ов и т.д. Проблема 1. – определить и изучить понятие сложности у.оператора. Проблема 2. – ввести и исследовать понятие у.оп-ра для неэлементарной информации, определить и изучить понятие информационной производной и сложности для такого у.оп-ра.
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Служба WAIS и Gopher WAIS (Wide Area Information Server) распределенная система поиска информации Поиск производится по базам данных, содержащим текстовые документы (но допустимы также графические, звуковые или видео документы). Тематика баз данных и поиска произвольны. Базы данных могут иметь любую структуру, но пользователю не нужно знать языка управления этими базами. WAIS использует естественный управляющий язык. WAIS доступен в Интернет. Для пользователей, имеющих доступ только к электронной почте, предназначен интерфейс, размещенный по адресу waismail@quake.think.com. В сети Интернет существует много серверов WAIS. Список депозитариев серверов достаточно широк, начать можно с анонимного FTP по адресу Think.com секция /wais, файл wais-sources.tar.Z (файл архивирован и пересылка должна осуществляться в режиме BINARY). В настоящее время многие WAIS-сервера интегрированы в сети WEB. Существуют клиент-серверы WAIS для систем MS-DOS, VMS, MVS, OS/2, UNIX и Macintosh, а также для GNU Emacs, NeXT, X-Windows, MS-Windows, Sunview и т.д. Эти продукты несколько отличаются друг от друга, но обычно процедура содержит следующие шаги:
GOPHER (RFC-1436) представляет собой систему для поиска и доставки документов, хранящихся в распределенных хранилищах-депозитариях. Система разработана в университете штата Миннесота (на гербе этого штата изображен хомяк, по-английски gopher). Программа Gopher предлагает пользователю последовательность меню, из которых он может выбрать интересующую его тему или статью. Объектом поиска может быть текст или двоичный файл (во многих депозитариях даже текстовые файлы хранятся в архивированном, а следовательно, двоичном виде), графический или звуковой образ. Gopher кроме того предлагает шлюзы в другие поисковые системы WWW, Wais, Archie, Whois, а также в сетевые утилиты типа telnet или FTP. Gopher может предложить больше удобств для работы с оглавлением файлов (directory), чем FTP. Для доступа в глобальную сеть Gopher использует модель клиент-сервер. Система Gopher в настоящее время устарела, многие ее серверы интегрированы в сеть WEB. Но gopher явился прототипом современных интерфейсов WWW и именно делает его интересным. Для реализации доступа пользователь должен работать в рамках протоколов TCP/IP и иметь на своей машине программу-клиент одной из версий gopher. Существуют версии Gopher на IBM/PC (MS-DOS), VMS, UNIX, X-Windows и т.д. Многие версии публично доступны с помощью анонимного FTP в различных депозитариях, например, boombox.micro.umn.eduсекция /pub/gopher. При постановке программы-клиента необходимо среди прочего указать адрес сервера-gopher. Большинство программ-клиентов позволяют пользователю делать "закладки" (bookmarks), которые содержат информацию о месте хранения объекта и пути доступа к нему. Закладки сохраняются и при выходе из Gopher, что облегчает продолжение поиска или нахождение объекта, найденного ранее. Набор функций программы-клиента зависит от ее конкретной реализации и от программного обеспечения ЭВМ, на которой она работает. Gopher обеспечивает простой и удобный интерфейс (лучше чем в обычном www с использованием меню, но хуже чем в MS internet explorer или netscape), позволяя работать с мышкой и предельно упрощая копирование найденных файлов. Обычно gopher имеет также автоматическую систему поиска объектов по ключевым словам в более чем 500 меню. Это крайне важно, так как пользователь не может знать все адреса серверов. Система носит имя Veronica (Very Easy Rodent-Oriented Net-wide Indexed Computerized Archives). Ключевое слово может быть набрано строчными или заглавными буквами. Veronica-сервер возвращает результат поиска в виде gopher-меню, где содержатся записи, в текстах которых присутствуют искомые ключевые слова. Доступ к Veronica возможен либо из базового меню или из из рубрики Other gopher servers... Для того чтобы ваш сервер стал известен окружающему миру, он должен быть зарегистрирован в сервере университета Миннесоты (США) или в любом другом уже зарегистрированном сервере. Объекты в меню обычно снабжаются символами-признаками, которые позволяют судить о типе объекта. Так, например, "<?>" означает полнотекстный индексный поиск, "/" - subdirectory, "<picture>" - указывает, что здесь хранится изображение, отсутствие какого-либо символа означает, что это текстовый файл. Если вы располагаете рабочей версией gopher, вызов программы можно выполнить командой Gopher или, например, gopher gopher.micro.umn.edu 70. В последнем случае обращение будет произведено к конкретному серверу, имя которого указано в качестве параметра команды. Число 70 указывает на номер порта (стандартное значение для gopher). Существует возможность доступа к GopherMail-серверам, которые пересылают заказчику текст базового меню. GopherMail включат в себя следующие возможности (что-то вроде игры в шахматы по переписке):
Электронная почта в Интернет. Первое почтовое сообщение было послано по сети ARPANet в 1971 году. Сегодня (2015г) существует много бесплатных почтовых серверов (RockerMail, Mail.ru, Яндекс.Почта, Gmail и т.д.). Каждый день отправляется 87,7 млрд. почтовых сообщений, самым популярным почтовым клиентом является iOS Mail (CHIP 3/2015 стр 69). Электронная почта - наиболее популярный и быстро развивающийся вид общения. Широко использовались протоколы электронной почты UUCP (unix-to-unix copy protocol, RFC-976), сегодня основным протоколом является SMTP (Simple Mail Transfer Protocol; RFC-821, -822, -1351, -1352). Один протокол (RFC-822) определяет формат почтовых сообщений, второй - RFC-821 управляет их пересылкой. Имея механизмы промежуточного хранения почты (spooling) и механизмы повышения надежности доставки, протокол SMTP базируется на TCP-протоколе в качестве транспортного и допускает использование различных транспортных сред. Он может доставлять сообщения даже в сети, не поддерживающие протоколы TCP/IP. Протокол SMTP обеспечивает как транспортировку сообщений одному получателю, так и размножение нескольких копий сообщения для передачи по разным адресам. Обычно в любом узле Интернет имеется почтовый сервер (MX), который принимает все сообщения и устанавливает их в очередь. Далее производится раскладка сообщений по почтовым ящикам ЭВМ пользователей. Если какая-то ЭВМ не включена, сервер попытается доставить почту позднее (например, через 30 мин). После заданного числа неудачных попыток или по истечении определенного времени (> 4-5 дней) сообщение может быть утрачено. При этом отправитель должен получить уведомление об этом. Над SMTP располагается почтовая служба конкретных вычислительных систем (например, POP3(RFC-1460), IMAP (RFC-2060), sendmail (UNIX), pine, elm (надстройка над sendmail), mush, mh и т.д.). Схема пересылки электронных почтовых сообщений (RFC-821) показана на рис. 4.5.10.1. Существует множество реализаций электронной почты. Имеются версии практически для всех ЭВМ, операционных систем и сред. Структура адреса и электронного сообщения. Адреса электронной почты уникальны и однозначно определяют адресата, обладая иногда даже некоторой избыточностью. Символьные адреса электронной почты вполне соответствуют IP-нотации. Электронный почтовый адрес содержит две части, местную и доменную, например, vanja.ivanov@itep.ru (vanya.ivanov - местная). Доменная часть обычно совпадает с символьным IP-именем домена. Если между отправителем и приемником имеется непосредственная связь, адрес имеет вид имя_пользователя@имя_ЭВМ. Когда приемник находится на ЭВМ, которая не поддерживает SMTP и передача происходит через промежуточный почтовый сервер, то адрес может иметь вид, например, ivanov%имя_удаленной_ЭВМ@имя_сервера (благодаря быстрому развитию Интернет в мире и даже в России такая схема используется сейчас крайне редко). Местная часть адреса определяется пользователем и часто совпадет с его именем или фамилией. Электронный адрес несравненно компактнее традиционных почтовых адресов, которые мы пишем на конвертах. Да и сами возможности электронной почты несравненно богаче почты традиционной. По этой причине можно утверждать, что традиционная почта постепенно будет в ближайшем будущем вытеснена ее электронным аналогом. Схема взаимодействия различных объектов электронной почты показана на рис. 4.5.10.1
Рис. 4.5.10.1. Схема пересылки электронных почтовых сообщений Со временем можно ожидать, что электронные адреса станут универсальными, но это произойдет не скоро. Для этого нужно чтобы транспорт и другие службы научились работать с такими адресами. Электронные (IP) адреса удобнее для ЭВМ, чем традиционные, а принимая во внимание, что применение вычислительной техники повсеместно, вывод напрашивается сам собой. То что удобно для ЭВМ, удобно в конечном итоге для всех. Любое почтовое сообщение можно разделить на три части: "конверт" (RFC-821), заголовки (RFC-822) и собственно текст. Конверт используется почтовым сервером и содержит две команды (тексты после двоеточия приведены в качестве примера): MAIL From: semenov@cl.itep.ru RCPT To: <king_penguin@antarctic.edu> Существует девять полей заголовка, используемые почтовой программой пользователя: Received, From, To, Date, Subject, Message-Id, X-Phone, X-Mailer, Reply-To. Каждое из этих полей содержит имя, за которым после двоеточия следует его значение. Документ RFC-822 определяет формат и интерпретацию полей заголовка. Заголовки, начинающиеся с X- являются полями, определяемые пользователем. При вызове почты (командой mail или mailx) на экране будет распечатан служебный текст, который зависит от конкретной реализации mail, но практически непременным атрибутом любой версии будет являться полное число полученных вами почтовых сообщений (если таковые были). Это могут быть и сообщения, оставленные вами там после предшествующего чтения почты. Непрочитанные вами сообщения так или иначе помечаются (например, символом U на левом поле строки-описания сообщения или N для новых). Далее следует аннотация сообщения, по одной строке на сообщение. Аннотация обычно содержит номер сообщения (нумерация всегда начинается с 1), имя и адрес отправителя, дата и время отправки. После этого следуют (в некоторых реализациях) два числа, разделенных косой чертой ("/"). Они характеризуют размер сообщения в строках и полное число символов. В заключение следует, если еще есть место, предмет сообщения (Subject:). Практически все пакеты электронной почты имеют возможность переадресовать сообщение другому адресату (Forward); отправить ответ (Replay) пославшему вам сообщение человеку (в этом случае в заголовке появится поле Replay-To); стереть сообщение не читая; в случае смены места работы или длительной командировки установить постоянную переадресацию (на ЭВМ SUN для этого нужно указать адрес нового почтового ящика в файле .forward); записать сообщение в файл (Save имя_файла) или отпечатать его на принтере. Структура электронной почты в Интернет. Путь электронного письма через почтовую систему, построенную на базе протокола SMTP , показан на рис
С Mail User Agent ( MUA ) – пользовательский агент, или клиентская почтовая программа - MUA предназначен для подготовки, отправки, получения и просмотра электронных писем. Это программа, установленная на компьютере пользователя. Задача электронной почты, по сути дела, сводится к тому, чтобы доставить сообщение от MUA отправителя на MUA получателя. Подготовка к отправке заключается в приведении сообщения к принятому в Internet формату, описанному в RFC 2822 . MUA отправителя должен сформировать заголовок сообщения, а также закодировать и оформить его тело в соответствии со стандартом, чтобы MUA принимающей стороны смог правильно интерпретировать и представить как текст, так и вложения письма. Так как MUA обычно устанавливается на машине пользователя, он, как правило, запускается только на время работы пользователя, а компьютер, на котором запущен MUA , может не иметь постоянного подключения к Internet . Поэтому MUA не может выступать в качестве сервера – он может быть только инициатором соединения, то есть клиентом. MUA посылает сообщения по протоколу SMTP через MSA или MTA, используемый для отправки почты.
Протокол SMTP и POP Главной целью протокола simple mail transfer protocol (SMTP, RFC-821, -822) служит надежная и эффективная доставка электронных почтовых сообщений. SMTP является довольно независимой субсистемой и требует только надежного канала связи. Средой для SMTP может служить отдельная локальная сеть, система сетей или весь Интернет. SMTP базируется на следующей модели коммуникаций: в ответ на запрос пользователя почтовая программа-отправитель устанавливает двухстороннюю связь с программой-приемником (TCP, порт 25). Получателем может быть оконечный или промежуточный адресат. SMTP-команды генерируются отправителем и посылаются получателю. На каждую команду должен быть отправлен и получен отклик. Когда канал организован, отправитель посылает команду MAIL, идентифицирую себя. Если получатель готов к приему сообщения, он посылает положительное подтверждение. Далее отправитель посылает команду RCPT, идентифицируя получателя почтового сообщения. Если получатель может принять сообщение для оконечного адресата, он выдает снова положительное подтверждение В противном случае он отвергает получение сообщения для данного адресата, но не вообще почтовой посылки. Взаимодействие с почтовым сервером возможно и в диалоговом режиме SMTP-отправитель и SMTP-получатель могут вести диалог с несколькими оконечными пользователями (рис. 4.4.14.1). Любое почтовое сообщение завершается специальной последовательностью символов. Если получатель успешно завершил прием и обработку почтового сообщения, он посылает положительное подтверждение.
S Схема взаимодействия различных частей почтовой системы Для небольших организаций невыгодно держать у себя систему для передачи сообщений (message transport system). Это связано с тем, что в небольших, не специализирующихся на компьютерных технологиях организациях, как правило, рабочие станции клиентов сети не имеют достаточно ресурсов (производительности или дискового пространства) для обеспечения работы полного SMTP-сервера. Кроме того, таким пользователям электронной почты может быть просто невыгодно держать персональный компьютер постоянно подключенным к Internet. Для решения этой проблемы был разработан почтовый протокол для работы в офисе — POP (Post Office Protocol). Его наиболее распространенный вариант — РОРЗ (Протокол почтового отделения версия 3). Этот протокол позволяет рабочим станциям динамически получать доступ к своим почтовым ящикам, расположенным на сервере, предназначенном для обслуживания электронной почты в данной организации. РОРЗ — это простейший протокол для работы пользователя с содержимым своего почтового ящика. Он позволяет только забрать почту из почтового ящика сервера на рабочую станцию клиента и удалить ее из почтового ящика на сервере. Всю дальнейшую обработку почтовое сообщение проходит на компьютере клиента. РОРЗ -сервер не отвечает за отправку почты, он работает только как универсальный почтовый ящик для группы пользователей. Когда пользователю необходимо отправить сообщение, он должен установить соединение с каким-либо SMTP-сервером и отправить туда свое сообщение по SMTP. Этот SMTP-сервер может быть тем же хостом, где работает РОРЗ -сервер, а может располагаться совсем в другом месте. Как правило, при работе с электронной почтой небольшие организации используют для получения своей корреспонденции РОРЗ -сервер, установленный на каком-либо компьютере в офисе, а отправляют почту по SMTP на один из хорошо доступных общеизвестных SMTP-серверов города (найти такие совсем несложно). РОРЗ- сервис, как правило, устанавливается на 110-й ТСР -порт сервера, который будет находится в режиме ожидания входящего соединения. Когда клиент хочет воспользоваться РОРЗ -сервисом, он просто устанавливает TCP-соединение с портом 110 этого хоста. После установления соединения сервис РОРЗ отправляет подсоединившемуся клиенту приветственное сообщение. После этого клиент и сервер начинают обмен командами и данными. По окончании обмена РОРЗ -канал закрывается. Команды РОРЗ состоят из ключевых слов, состоящих из ASCII-символов, и одним или несколькими параметрами, отделяемыми друг от друга символом "пробела" — <SP>. Все команды заканчиваются символами "возврата каретки" и "перевода строки" — <CRLF>. Длина ключевых слов не превышает четырех символов, а каждого из аргументов может быть до 40 символов. Ответы РОРЗ -сервера на команды состоят из строки статус- индикатора, ключевого слова, строки дополнительной информации и символов завершения строки — <CRLF>. Длина строки ответа может достигать 512 символов. Строка статус -индикатора принимает два значения: положительное ("+ОК") и отрицательное ("-ERR"). Любой сервер РОРЗ обязан отправлять строки статус- индикатора в верхнем регистре, тогда как другие команды и данные могут приниматься или отправляться как в нижнем, так и в верхнем регистрах. Ответы РОРЗ -сервера на отдельные команды могут составлять несколько строк. В этом случае строки разделены символами <CRLF>. Последнюю строку информационной группы завершает строка, состоящая из символа "." (код — 046) и <CRLF>, т. е. последовательность "CRLF.CRLF". РОРЗ -сессия состоит из нескольких частей. Как только открывается TCP-соединение и РОРЗ -сервер отправляет приветствие, сессия должна быть зарегистрирована — состояние аутентификации (AUTHORIZATION state). Клиент должен зарегистрироваться в РОРЗ -сервере, т. е. ввести свой идентификатор и пароль. После этого сервер предоставляет клиенту его почтовый ящик и открывает для данного клиента транзакцию — состояние начала транзакции обмена (TRANSACTION state). На этой стадии клиент может считать и удалить почту своего почтового ящика. После того как клиент заканчивает работу (передает команду QUIT), сессия переходит в состояние UPDATE — завершение транзакции. В этом состоянии РОРЗ -сервер закрывает транзакцию данного клиента (на языке баз данных — операция COMMIT) и закрывает TCP-соединение. В случае получения неизвестной, неиспользуемой или неправильной команды, РОРЗ -сервер должен ответить отрицательным состоянием индикатора. РОРЗ -сервер может использовать в своей работе таймер контроля времени соединения. Этот таймер отсчитывает время "бездействия" ("idle") клиента в сессии от последней переданной команды. Если время сессии истекло, сервер закрывает TCP-соединение, не переходя в состояние UPDATE (иными словами, откатывает транзакцию или на языке баз данных — выполняет ROLLBACK). Транзакция протоколов SMTP и POP Для работы через протокол SMTP клиент создаёт TCP соединение с сервером через порт 25. Затем клиент и SMTP сервер обмениваются информацией пока соединение не будет закрыто или прервано. Основной процедурой в SMTP является передача почты (Mail Procedure). Далее идут процедуры форвардинга почты (Mail Forwarding), проверка имён почтового ящика и вывод списков почтовых групп. Самой первой процедурой является открытие канала передачи, а последней - его закрытие. Команды SMTP указывают серверу, какую операцию хочет произвести клиент. Команды состоят из ключевых слов, за которыми следует один или более параметров. Ключевое слово состот из 4-х символов и разделено от аргумента одним или несколькими пробелами. Каждая командная строка заканчивается символами CRLF. Вот синтаксис всех команд протокола SMTP (SP - пробел): HELO MAIL FROM: RCPT TO: DATA RSET SEND FROM: SOML FROM: SAML FROM: VRFY EXPN HELP NOOP QUIT Перед работой через протокол POP3 сервер прослушивает порт 110. Когда клиент хочет использовать этот протокол, он должен создать TCP соединение с сервером. Когда соединение установлено, сервер отправляет приглашение. Затем клиент и POP3 сервер обмениваются информацией пока соединение не будет закрыто или прервано. Команды POP3 состоят из ключевых слов, за некоторыми следует один или более аргументов. Все команды заканчиваются парой CRLF (в Visual Basic константа vbCrLf). Ключевые слова и аргументы состоят из печатаемых ASCII символов. Ключевое слово и аргументы разделены одиночным пробелом. Ключевое слово состоит от 3-х до 4-х символов, а аргумент может быть длиной до 40-ка символов. Ответы в POP3 состоят из индикатора состояния и ключевого слова, за которым может следовать дополнительная информация. Ответ заканчивается парой CRLF. Существует только два индикатора состояния: "+OK" - положительный и "-ERR" - отрицательный. Ответы на некоторые команды могут состоять из нескольких строк. В этих случаях каждая строка разделена парой CRLF, а конец ответа заканчивается ASCII символом 46 (".") и парой CRLF. POP3 сессия состоит из нескольких режимов. Как только соединение с сервером было установлено и сервер отправил приглашение, то сессия переходит в режим AUTHORIZATION (Авторизация). В этом режиме клиент должен идентифицировать себя на сервере. После успешной идентификации сессия переходит в режим TRANSACTION (Передача). В этом режиме клиент запрашивает сервер выполнить определённые команды. Когда клиент отправляет команду QUIT, сессия переходит в режим UPDATE. В этом режиме POP3 сервер освобождает все занятые ресурсы и завершает работу. После этого TCP соединение закрывается. У POP3 сервера может быть INACTIVITY AUTOLOGOUT таймер. Этот таймер должен быт, по крайней мере, с интервалом 10 минут. Это значит, что если клиент и сервер не взаимодействуют друг с другом, сервер автоматически прерывает соединение и при этом не переходит в режим UPDATE. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Сервис-менеджмент ИТ — это структурированный подход, позволяющий сделать работу подразделения ИТ эффективной и рациональной, Этот подход стал стандартом де-факто в мире при формировании ИТ-службы как современного бизнес-подразделения, постоянно ориентированного на потребности своих пользователей, нацеленного на решение изменяющихся задач при сохранении прозрачности для руководства с точки зрения достигнутого уровня качества и используемых ресурсов. Опыт показывает, что рассматриваемые принципы организации деятельности актуальны как для небольших, так и для крупных компаний и не зависят от того, передается ли сопровождение ИТ на аутсорсинг или организуется внутренними силами. Качественно работающий ИТ-департамент — это задача, ставшая актуальной для многих современных российских компаний. Сервис-менеджмент ИТ стал необходимым инструментом для поддержки основных бизнес-процессов компаний. Вопросы разработки и эксплуатации систем все больше формируются под влиянием «точки зрения бизнеса». Кроме того, во многих организациях и индустрии в целом общий курс движения был выбран на профессиональное развитие практических методов и постоянно предъявлялись требования к краткосрочным и долгосрочным показателям надежности, масштабируемости, гибкости и развитию понимания между пользователями и организациями. Причин, по которым руководство остается недовольным качеством корпоративных информационных систем, много. Часть из них находится в области управления проектами внедрения ИС. Далеко не всегда проекты завершаются в заданный срок и в рамках выделенных бюджетов. Но даже тогда, когда проекты заканчиваются, становятся актуальными ежедневные вопросы, связанные с использованием ИС, которые во многом формируют мнение о качестве работы ИТ службы компании. За последние десятилетия на информационные технологии оказали влияние большое число компьютеров, локальных сетей, использование технологий «клиент-сервер» и Интернета позволило организациям быстрее выводить на рынок свои продукты и услуги. Данные разработки возвестили о переходе от промышленного века к веку информации. В информационном веке все происходит намного динамичнее. В рамках традиционных иерархических организаций часто бывает трудно реагировать на условия быстроменяющихся рынков, и это привело к появлению более гибких компаний с меньшей степенью иерархичности. В самих организациях основной акцент сместился от вертикальных функций или отделов к горизонтальным процессам, которые работают в рамках всей организации, а право принятия решения все больше переходит на более низкие уровни. На таком фоне развивались процессы управления ИТ-услугами. В 1980-х гг. качество ИТ-услуг, предоставляемых британскому правительству, было таким, что существовавшее в то время Центральное агентство по вычислительной технике и телекоммуникациям получило указание разработать принципы эффективного и рентабельного использования ИТ—ресурсов в министерствах и других государственных учреждениях Великобритании. Целью данной кампании была разработка единого подхода, не зависящего от поставщика услуг. Результатом усилий явилась Библиотека передового опыта организации ИТ (ITInfrastructure Library - ITIL), которая выросла из собрания лучших методов, существовавших в индустрии ИТ-услуг. Библиотека ITIL предоставляет подробное описание наиболее важных видов деятельности в работе ИТ, а также полный перечень сфер ответственности, задач, процедур и контрольных списков действий, которые могут быть адаптированы для любой организации. В тех случаях, когда это возможно, виды деятельности определены как процессы, охватывающие сервисные ИТ-службы. Широкая предметная область публикаций ГПЬ делает полезным регулярное обращение к ним и использование при определении целей для совершенствования ИТ-организаций. На базе библиотеки ITIL некоторые коммерческие компании разработали свои структурированные подходы к управлению ИТ-услугами. Среди них НР ITSM компании HP, IT Process Model компании IBM и многие другие. Это стало одной из причин, по которым библиотека ITIL фактически стала стандартом в описании процессов ИТ-сервис-менеджмента (IT Servise Management - ITSM) Принципы ИТ-сервис-менеджмента Основными принципами, заложенными в ИТСМ (ITSM), являются услуги, качество и процессы. Услуги предоставляются при непосредственном взаимодействии с заказчиком. Качество услуги нельзя оценить заранее, это делается только при ее предоставлении. Качество в определенной степени Зависит от того, как поставщик взаимодействует с заказчиком. В отличие от процесса производства услугу можно изменить на этапе ее предоставления заказчику. Как заказчик воспринимает услугу и что думает поставщик о своих поставках — все это в значительной степени зависит от их личного опыта и ожиданий. Непрерывный диалог с заказчиком является необходимым условием для усовершенствования услуги, а также для того, чтобы и заказчик, и поставщик знали, чего стоит ожидать. В ресторане официант вначале расскажет о меню и при подаче нового блюда поинтересуется, все ли нормально. Официант активно координирует спрос и предложение на протяжении всего времени посещения ресторана клиентом, а затем использует полученный опыт для улучшения обслуживания других посетителей. Качество услуги — это показатель того, насколько услуга отвечает требованиям и ожиданиям заказчика. Для обеспечения качества поставщик должен постоянно оценивать, как услуга воспринимается заказчиком и что клиент ожидает получить в будущем. То, что для одного заказчика является обычным, для другого будет чем-то особенным И в конечном итоге заказчик может привыкнуть к тому, что в самом начале считалось особенным. Результаты оценки можно использовать для определения того, нужно ли модифицировать услугу, предоставлять ли заказчику больше информации о ней или стоит изменить ее цену. Таким образом, при предоставлении услуг общее качество обслуживания складывается из качества составляющих процессов, которые вместе образуют услугу. Такие составляющие процессы формируют цепочку, звенья которой влияют одно на другое и на качество услуги в целом. Для эффективной координации составляющих процессов требуется не только адекватное качество при выполнении каждого процесса, но еще и качество согласования процессов между собой. Для эффективного и своевременного управления необходимо разделение видов деятельности в ходе предоставления услуг на процессы, для которых имеются свои планы и возможности контроля. В организации должно быть четко определено, кто отвечает за данный вид деятельности и кто может изменять планы и процедуры не только для каждого из видов работ, но и для каждого из процессов.
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
БИЛЕТ 18 |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Человеко-компьютерное взаимодействие (HCI) — это изучение, планирование и разработка взаимодействия между людьми (пользователями) и компьютерами. Взаимодействие между пользователями и компьютерами происходит на уровне пользовательского интерфейса (или просто интерфейса), который включает в себя программное и аппаратное обеспечение. Основной задачей человеко-компьютерного взаимодействия является улучшение взаимодействия между человеком и компьютером, делая компьютеры более удобными (usability) и восприимчивыми к потребностям пользователей. В частности, человеко-компьютерное взаимодействие занимается: методологией и развитием проектирования интерфейсов (т. е., исходя из требований и класса пользователей, проектирование наилучшего интерфейса в заданных рамках, оптимизация под требуемые свойства, такие как обучаемость и эффективность использования);
Долгосрочной задачей человеко-компьютерного взаимодействия является разработка системы, которая снизит барьер между человеческой когнитивной моделью того, чего они хотят достичь, и пониманием компьютером поставленных перед ним задач. При оценке текущего пользовательского интерфейса или разработке нового интерфейса следует иметь в виду следующие принципы разработки: С самого начала необходимо акцентировать своё внимание на пользователях и задачах: установить количество пользователей, требуемых для выполнения задачи и определить подходящих пользователей; кто-либо никогда не использовавший интерфейс, либо тот, кто никогда не будет его использовать в будущем является неподходящим пользователем. Кроме того, необходимо определить какие задачи и как часто будут выполнять пользователи. Эмпирические измерения : на ранней стадии провести тест интерфейса с реальными пользователями, которые используют интерфейс каждый день. Имейте в виду, что результаты могут измениться, если уровень производительности пользователя не является точным отображением реального человеко-компьютерного взаимодействия. Установить количественные особенности практичности, такие как: количество пользователей, выполняющих задачи, время выполнения задачи, и количество ошибок, сделанных в ходе выполнения задачи. Итеративное проектирование : после определения количества пользователей, поставленных задач, эмпирических измерений, выполните следующие шаги итеративной разработки:
Повторяйте итеративную разработку до тех пор, пока не создадите практичный, удобный для пользователя интерфейс. Разнообразные методики, излагающие техники проектирования человеко-компьютерного взаимодействия, начали появляться во времена развития данной области в 1980-х годах. Большинство методик разработки произошли от модели взаимодействия пользователей, разработчиков и технических систем. Ранние методики, например, трактовали когнитивные процессы пользователей как предсказуемые и поддающиеся количественному определению, и предлагали разработчикам при проектировании пользовательских интерфейсов рассматривать результаты когнитивных исследований в таких областях как память и внимание. Современные модели имеют тенденцию акцентировать внимание на постоянной обратной связи и диалоге между пользователями, разработчиками и инженерами, и прилагать усилия к тому, что технические системы крутятся вокруг желаний пользователей, нежели желания пользователей вокруг уже готовой системы. Ориентированное на пользователя проектирование: разработка, ориентированная на пользователя в данный момент является современной, широко практикующейся философией, суть которой заключается в том, что пользователи должны занимать центральное место в разработке любой компьютерной системы. Пользователи, разработчики и технические специалисты работают вместе чтобы чётко выразить желания, потребности и границы, и создать систему, отвечающую этим требованиям. Ориентированные на пользователя проекты часто пользуются исследованиями этнографической среды, в которой пользователи будут работать с системой. Эта практика является аналогичной, но не является совместной разработкой, которая подчёркивает возможность для пользователей активно сотрудничать посредством сессий и семинаров. Принципы разработки пользовательского интерфейса (англ. Principles of user interface design): эти семь принципов могут рассматриваться в любое время, в любом порядке в течение всего времени разработки, это: привычность, простота, очевидность, допустимость, последовательность, структура и обратная связь. Интерфейс, по определению - это правила взаимодействия операционной системы с пользователями, с другими ЭВМ и др. От интерфейса обычно зависит технология общения человека с компьютером. Человеко-машинный интерфейс обеспечивает связь между пользователем и компьютером - он позволяет достигать поставленных целей, успешно находить решение поставленной задачи. Взаимодействие - обмен действиями и реакциями на эти действия между компьютером и пользователем. Лет десять назад основным видом взаимодействия был текст (так называемые терминальные или командные системы). В настоящее время, взаимодействие может также включать графику и иконки (знаки) вместо текста. Имеется ряд стилей взаимодействий, которые делятся на два основных вида. Первый – это использование интерфейса языка команд - ввод команд текстовыми средствами; и второй – это непосредственное манипулирование. Таким образом, имеется ряд способов, которыми пользователь мог бы связываться с компьютером:
Основными принципами создания интерфейса являются:
Разнообразные методики, излагающие техники проектирования человеко-компьютерного взаимодействия, начали появляться во времена развития данной области в 1980-х годах. Большинство методик разработки произошли от модели взаимодействия пользователей, разработчиков и технических систем. Ранние методики, например, трактовали когнитивные процессы пользователей как предсказуемые и поддающиеся количественному определению, и предлагали разработчикам при проектировании пользовательских интерфейсов рассматривать результаты когнитивных исследований в таких областях как память и внимание. Современные модели имеют тенденцию акцентировать внимание на постоянной обратной связи и диалоге между пользователями, разработчиками и инженерами, и прилагать усилия к тому, что технические системы крутятся вокруг желаний пользователей, нежели желания пользователей вокруг уже готовой системы. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
WWW – это распределенная среда, состоящая из автономных систем, узлы которой все чаще формируются как реляционные базы данных. Точно так же пользование электронными публикациями предполагает наличие распределенной системы, в которой имеется довольно низкий уровень доверия между клиентом и сервером. Хотя исследовательское сообщество весьма интенсивно занималось вопросами распределенных баз данных, и плоды этих усилий находят отражение в коммерческих продуктах, новая среда, возникшая в рамках WWW, заставляет переосмыслить многие концепции существующей технологии распределенных баз данных. Информационные ресурсы могут использоваться для решения разнообразных научных и прикладных задач: от поиска необходимой информации до задач принятия управленческих решений. При этом, в зависимости от вида учреждений, пользователю сети этого учреждения должны предоставляться свои собственные виды информационных услуг. Так, например, в образовательных структурах важнейшей информационной услугой будет дистанционное образование, в банках и на биржах - проведение электронных сделок, на производствах - реклама своей продукции, на вокзалах, аэропортах - выдача информации о наличии билетов и заказ билетов и т.д. Развитие сети научного учреждения связано, прежде всего, с развитием информационных ресурсов, направленных на обеспечение среди ученых общего информационного пространства и доступа к различного рода электронным библиотекам, каталогам электронных публикации и т.д. При этом научное учреждение должно стремится к обеспечению в своей сети следующего набора информационных услуг:
Создание этих видов информационных услуг основывается на применении современных программных продуктов и технологий таких как: - базовые технологии Internet(WWW, E-mail и т.д.) - гипертекстовый язык HTML - архитектура клиент - сервер - использование инструментальных средств Java, CGI, JavaScript, и т.д. - SQL-ориентированные системы управления базами данных (СУБД) |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Основной проблемой разработчиков программного обеспечения с увеличением числа распределенных систем стала организация взаимодействия между различными системами и их компонентами. Само собой, такие проблемы существовали и за много лет до этого, поэтому для их решения уже существовали некоторые стандарты и архитектуры, с разной степенью успеха справляющиеся с ними. Такие проблемы принято делить на две общие категории: programming in the small (локальное программирование) и programming in the big (глобальное программирование). Остановимся на них подробнее. Локальное программирование В локальном программировании проблемы и их решения в некотором смысле отличаются по своей сложности и организации. Проблемы системы типов. Самая простая задача, такая как, к примеру, передача целочисленного значения переменной из одной программы в другую, очень часто становится крупной проблемой. Многие языки программирования представляют себе по разному что такое целочисленное значение. Но даже если обе программы написаны на одном языке, в одной среде, то сам язык может иметь не совсем точное определение, чем является целочисленное значение. Например, в стандарте языка C++ сказано, что значение целочисленного типа int всегда меньше или равно значению целочисленного типа long, но в то же время больше или равно значению целочисленного типа short всегда для любой платформы, но в стандартене указан размер (и, как следствие, диапазон) типа. Это значит, что значение целочисленного типа может иметь длину 64 бит на одном компьютере или в одной программе, но в другой программе или на другом компьютере с иной архитектурой длина такого значения равна 16 битам. Само собой разумеется, что это ничего не говорит о порядке расположения наиболее значимых битов на разных компьютерах. А вот при попытке передачи значений между разными языками программирования, даже в том случае, если они расположены на одном компьютере, ситуация становится гораздо сложнее. Одни языки, например Java, рассматривают целочисленное значение как последовательность битов, либо как объект (т.е. int или Integer), другие, например C++, только как последовательность битов, а третьи, например, SmallTalk, — как объект. Ситуация усложняется в разы при передаче определенных пользователем типов еще и между разными компьютерами. Передача значений членов-данных при всем при этом осуществляется заметно проще, чем передача методов этого типа. Проблемы с метаданными. Описание типа обычно хранится в специальних файлах, в языке C++, например для хранения этой информации существуют специальные заголовочные файлы с расширением *.h. После компиляции заголовочных файлов многие компиляторы встраивают в исполняемый файл предельно небольшое количество метаданных, описывающих типы. В результате чего в исполняемых файлах остается совсем мало, а бывает, что и вообще никакой информации о типах, которая другими компиляторами могла бы использоваться для изучения метаданных (данных о данных). По мере того, как языки и архитектуры начинали поддерживать динамическое определение типов и динамический вызов методов, что начало появляться только в последние 5-8 лет, отсутствие метаданных становилось все более важной проблемой, требующей скорейшего решения. В языке C++ частично решалась эта проблема, в нем появились средства Runtime Type Information (RTTI), которые определяли информацию о типах в процессе выполнения. В технологиях, о которых мы говорили в предыдущей статье, таких как СОМ и CORBA предусмотрены библиотеки типов и существовали репозитории интерфейсов, действующие как независимые от используемого языка, решения. Но в ситуации, при которой тип и его метаданные находятся в разных файлах и, вероятнее всего, генерируются в разное время, поддерживать непротиворечивость описания типов достаточно сложно, и, помимо этого, такая задача потенциально повышает возможность увеличения числа ошибок. Проблемы выполнения. В том случае, когда разработчику приходится использовать тип из другого языка программирования, то каким же образом среда выполнения сможет дать доступ к этому типу? В большей части архитектур предусмотрены средства вызова методов из других языков программирования, но это врядли можно назвать самым лучшим из доступных на сегодняшний день решений. Средства межъязыкового вызова методов дают полезный набор инструментов, но его реализация это крайне сложный и трудоемкий процесс, затрудняющий разработку программного обеспечения. И возникает еще один немаловажный вопрос: каким образом программные конструкции такие как исключительные ситуации (Exceptions), перенести из одного языка на другой или с одного компьютера на другой не меняя структуры самой программы? А если учесть еще и то, что программы обязательно будут выполняться на разных аппаратных платформах с разными ОС, то значение этой проблемы станет ясным как белый день. Настоящее межъязыковое взаимодействие просто обязано обладать большими возможностями, чем один только вызов методов из других языков. Если классы C++ можно унаследовать (inherit) от других классов языка C++, разработанных другими людьми, а затем расширить их функционал, переопределяя их методы, то класс C++ должен также обладать способностью унаследовать классы других языков и правильно управлять ими. Но к сожалению на данный момент объектно-ориентированные модели и модели выполнения, предлагаемые нам современными языками программирования, значительно отличаются и для них практически невозможно создать единую среду выполнения. Глобальное программирование При работе с программными компонентами, написанными разными программистами и при помощи разных языков программирования в различных средах, и последующих попытках собрать эти компоненты в одну распределенную систему, программисту придется решить бесчисленное множество проблем глобального программирования. - Проблема именования (Naming). Если разработчики из географически разных мест хотят повторно использовать разработанные ими классы, появляется проблема создания разных классов с одинаковыми именами. - Обработка ошибок (error handling). В одних языках программирования и архитектурах для представления информации об ошибках используются возвращаемые значения (Return), а в других — исключительные ситуации(Exception). Для взаимодействия между такими языками потребуется создать схему, позволяющую транслировать информацию об ошибках с сохранением семантических структур разных языков, архитектур. - Безопасность (security). Большие распределенные системы пересекают чаще всего несколько языковых, архитектурных, организационных и международных границ. Поэтому в такой сложной среде почти нереально гарантировать, что данное ПО не будет использовано злонамеренно. - Контроль версий (versioning). Все, кому когда-либо пришлось столкнуться с несовместимыми обновлениями системного программного обеспечения, то есть проблемой несовместимости DLL-библиотек (такая проблема называется программистами "ад DLL"), прекрасно понимают, что эволюция архитектур является главной проблемой, делающией сложнее создание программного обеспечения на основе подключаемых компонентов. - Масштабируемость (scalability). Это скорее самая неизвестная и наиболее плохо понимаемая проблема создания широких распределенных систем. Распределенная система может прекрасно работать для сотен пользователей во внутренней сети организации, но просто сходит с ума, когда с ней начинают работать миллионы пользователей в Internet. Решение проблем программирования Конечно, недавняя эволюция и постоянное развитие программных языков и архитектур имеют цель решения именно проблем глобального программирования. Добавленные в C++ компоненты, которых не было ни в каком виде в языке С, например пространства имен и исключительные ситуации, а в технологии СОМ - неизменность интерфейсов и использование GUID (Globally Unique Identifier, что по русски звучит как "глобально уникальный идентификатор") в качестве имен, позволяют решить некоторые проблемы. В технологии CORBA для предоставления масштабируемых высокопроизводительных серверных приложений был разработан портативный адаптер объектов (Portable Object Adapter — РОА). • Стандарты представления (representation standards). На данный момент используются стандарты внешнего представления данных (external Data Representation — XDR) и стандарты сетевого представления данных (Network Data Representation — NDR), решающие проблему передачи типов данных между разными компьютерами, компенсируя проблему прямого/обратного порядка следования байтов в размерах типов данных и их размеры. • Языковые стандарты (language standards). Стандарт ANSI С, способствует распространению исходного кода среди разных компиляторов и компьютеров и позволяет перекомпилировать исходный код на разных компьютерах и с разными библиотеками без внесения изменений в исходные файлы. • Архитектурные стандарты (architecture standards). ОС Microsoft Windows прекрасно работает с одним из детищ архитектурных стандартов - удаленным вызовом процедур (Remote Procedure Call — RPC). Всецело используются так же и стандарты распределенной вычислительной среды (Distributed Computing Environment — DCE), технология CORBA группы OMG, а также технологии COM (Component Object Model) и DCOM (Distributed Component Object Model) компании Microsoft, решающие проблему вызова методов из разных процессов, языков и компьютеров. • Исполняющие среды (execution environments), например язык SmallTalk и все более часто используемые виртуальные машины Virtual Machines (VM) языка Java, позволяют выполнять код на физически разных компьютерах за счет того, что код исполняется в стандартизованной исполняющей среде, пусть и виртуальной. Все эти технологии, безусловно, помогают разработчикам, но ни одна из них всецело не решает все проблемы, связанные с разработкой распределенной вычислительной среды. С целью достижения взаимодействия между различными языками, средами и архитектурами, использования классов и объектов одного языка в другом языке наравне с его классами и объектами и была разработана платформа .NET Framework компании Microsoft. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
Источники формирования информационных ресурсов организации. Любая организация существует в некоторой внешней среде. Эта же организация порождает свою внутреннюю среду. Внутренняя среда формируется совокупностью структурных подразделений предприятия и работающих там людей технологическими, социальными, экономическими и другими отношениями между ними. В зависимости от источника возникновения в рамках организации имеется внутренняя и внешняя информация, составляющая ее информационные ресурсы. Информация внутренней среды, как правило, точная, полно отражает финансово-хозяйственное состояние. Ее обработка часто может осуществляться с помощью стандартных формализованных процедур. Внутренняя информация: о людях, продуктах, затратах, жалобах, услугах, технологических процессах, сферах применения продукта, методах сбыта и технике продаж, поставках, каналах сбыта. Внешняя среда – экономические и политические субъекты, действующие за пределами предприятия, и отношения с ними. Это экономические, социальные, технологические, политические и другие отношения предприятия с клиентами, поставщиками, посредниками, конкурентами, государственными органами и т.п. Информация из внешней среды часто приблизительна, неточна, неполна и противоречива. В таком случае она требует нестандартных процедур обработки. Внешняя информация: о рынке, конкурентах, тенденциях изменений в деловой среде страны и состоянии международных рынков, покупателях, спросе, требованиях клиентов и конкурентов, изменении законодательства. Анализ различных источников показывает, что в настоящее время широко для оценки информационных ресурсов используются следующие основные параметры: содержание; охват; время; источник; качество; соответствие потребностям; способ фиксации; язык; стоимость. Информационный менеджмент – управление информацией с целью повышения эффективности принимаемых управленческим аппаратом решений. Практическую работу по построению современных систем управления информационными потоками в организациях предлагается проводить с использованием методологии информационного менеджмента. Менеджер отвечает за то, чтобы компания использовала информацию в соответствии со своей стратегией. Одной из главных задач информационного менеджмента является составление четкого представления о следующем [4]: - какая информация (по содержанию); - кому (какой категории потребителей); - когда (к какому сроку или на каком этапе работы); - в какой форме (на каком уровне свертывания) следует информацию представить, чтобы потребитель в имеющееся у него время смог ее с пользой усвоить. Очень часто, после того как вся информация собрана и предоставлена специалистам, она оказывается практически бесполезной, так как собрано абсолютно не то, что требовалось. Причина этому: достаточно большой объем информации, которая может соответствовать по смыслу, и освоить ее все не всегда возможно, да и во всем предоставленном информационном потоке нет именно того, что так необходимо для решения задачи. Подобная ситуация сложилась потому, что очень часто считается, что чем больше выдается информации, тем лучше, а что с этой информацией делает специалист, - неважно. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
HTML (HyperText Markup Language) - язык гипертекстовой разметки документов. Назначение HTML в том, чтобы сделать документы пригодными для чтения с экрана монитора. Для создания HTML документов используют текстовые редакторы (например Блокнот), текстовые процессоры (Word), редакторы тегов HTML и визуальные HTML-редакторы. Вы можете создать HTML документ в простом Блокноте. Придерживаясь определённого стандарта и записав в текстовом файле HTML код, сохранив на жёстком диске и изменив расширение на .html или .htm вы получите полноценную web страничку. Теги - это инструменты разметки текста. Теги могут прописываться как строчными, так и прописными буквами, разницы никакой нет. Теги бывают парными и не парными. В качестве примера парного тега можно привести тег<html></html>, этот тег начинает и заканчивает любой HTML документ. Вторая часть парного тега отличается от первой только наличием символа "/", однако первая часть тега может содержать и дополнительные параметры. Например в теге <font size="4"></font>, параметр size="4"определяет размер текста. Примером непарного тега является <hr> - тег вставки в HTML документ горизонтальной линии, такой как в конце этого абзаца. Обязательные теги языка HTML Любой HTML документ должен содержать следующие теги <html></html>, <head></head>, <body></body>, <title></title>. Порядок расположения тегов в HTML документе представлен ниже <html> <head> <title>Название вашей страницы</title> </head> <body> Тело вашего документа </body> </html> Внутри тега <head></head> располагается название вашего HTML документа (чаще всего именно его вы видите в качестве ссылки в результатах поиска поисковыми машинами), помимо этого тега внутри конструкции <head></head> могут располагаться так называемые Мета Теги. Их назначение и описание смотри в справочнике по Мета Тегам. Заголовки Заголовки в языке HTML выделяются тегами <h1></h1>, <h2></h2>, ... , <h6></h6>. Таким образом существует 6 уровней заголовков. Можете поэкспериментировать - Вставьте вместо "Тело документа" предыдущем примере <h1>HTML - это просто</h1>, сохраните в текстовом формате, измените расширение документа с .txt на .html и откройте его в браузере. Ну как? По моему приятно когда начинает получаться, можете попробовать то же самое с заголовками других уровней. Абзацы в языке HTML Абзац в HTML документе заключается в тег <P></P>. Выделение текста в HTML Для выделения текста, или области текста в HTML используют теги <b></b>, <i></i>, <u></u>, таким образом строка <b>жирный</b> <i>курсив</i> <u>подчёркнутый</u> <u><i><b>жирный подчёркнутый курсив</b></i></u> Ненумерованные списки в HTML Ненумерованные списки прописывают в HTML коде следующим образом <UL><LI>пункт 1<LI>пункт 2<LI>пункт 3</UL> Нумерованные списки в HTML Нумерованные списки прописывают следующими тегами <OL><LI>пункт 1<LI>пункт 2<LI>пункт 3</OL> Специальные символы в тексте документа Специальные символы в тексте документа прописываются следующим образом < - левая скобка (<) > - правая скобка (>) & - (&) " - кавычки (") Прерывание строки в тексте HTML документа Прерывание строки осуществляется тегом <BR>. Гиперссылки Гиперссылка в языке HTML прописывается тегом <a></a>. Например запись вида <a href="html.rar">Скачать учебник языка HTML</a> Параметр href определяет место документа на который ссылается ссылка, в нашем примере ссылка относительная она ссылается на документ html.rar расположенный в той же директории что и страница HTML. Абсолютная ссылка прописывается следующим образом <a href="http://webdesign.net-soft.ru/html.rar">Скачать учебник языка HTML</a> Выглядит она аналогично предыдущей ссылке, но определяет точное местоположение документа. Правила расстановки относительных ссылок в языке HTML Если документ на который ссылается ссылка расположен в директории (папке) на уровень ниже, скажемdir, то ссылка параметр href будет иметь видhref="dir/html.rar" , а если документ расположен в директории на уровень выше, то нам необходимо будет записать href="../html.rar". Вставка рисунков в HTML страницу Рисунок в HTML документ вставляется следующим образом <img src="ris.jpg" width="100" height="140" alt="Учебник по языку HTML">. Разберем, каково значение параметров тега <img>. Как видите, это одиночный тег. Параметр src задаёт путь к изображению (абсолютный или относительный). Правила указания относительного пути, такие же как и для ссылки. Параметры width и height определяют ширину и высоту рисунка в пикселях в HTML документе. Параметр altзадаёт альтернативный текст - тот текст который отображается в браузере если отключена загрузка графики. Фреймы в HTML документе Фрейм - это рамка, в которую загружается другой HTML документ. Многие сайты имеют фреймовую структуру, наш не исключение. Меню нашего сайта загружается во фрейм. Как это делается? Смотрите <iframe name="I2" src="menu.htm" width="200" scrolling="no" height="500" marginwidth="2" marginheight="2">Ваш браузер не поддерживает фреймы</iframe> Параметр name - имя фрейма, src - путь к загружаемой во фрейм странице width, height соответственно ширина и высота рамки. Параметр scrolling определяет отображаются ли полосы прокрутки во фрейме, если этот параметр не прописан в HTML коде, то полосы прокрутки отображаются при необходимости, если он равен "no", то полосы прокрутки не отображаются, если - "yes", то - отображаются в любом случае. Параметр nameиспользуется для задания конечной рамки по умолчанию - рамки в которую будут загружаться страницы при переходе по гиперссылкам HTML документа. Это осуществляется добавлением в HTML код тега <base>между тегами <head></head>. Для нашей рамки <base target="I2">. Таблицы в языке HTML Таблицы в HTML документ вставляются следующим образом <table border="1" style="border-collapse: collapse" bordercolor="#111111"> <tr><td>Ячейка11<td>Ячейка12</tr> <tr><td>Ячейка21<td>Ячейка22</tr> </table> Таблицу открывает и закрывает тег <table></table>, тег<tr></tr> - определяет столбец, одиночный тег <td>определяет ячейку в столбце, таким образом представленный код прописывает таблицу размером 2х2, которая в HTML документе будет выглядеть следующим образом
Теги style и bordercolor определяют соответственно стиль отображения таблицы и цвет границы. Более подробно смотрите в учебнике по HTML. |
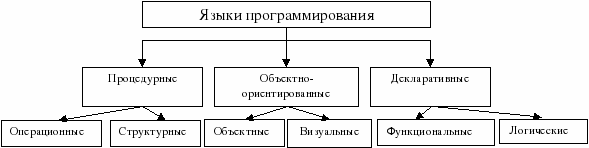

 ринятие
решения о внедрении информационной
системы имеет статус стратегической
инвестиции, поэтому некоторые компании
разрабатывают ИТ-стратегию только
для реализации этой программы. В таком
контексте используется термин SISP
(Strategic Information Systems Planning — планирование
стратегических информационных систем).
В случае SISP область действия сужается
до внедрения информационной системы,
поэтому существует обособленный ряд
методологий SISP, таких как BSP (Business
Systems Planning — планирование бизнес-
систем), SSP (Strategic Systems Planning — планирование
стратегических систем), IE (Information
Engineering — информационный инжиниринг).
ИТ-стратегию характеризуют возможности
ИТ как на рынке технологий, так и на
предприятии, а также роль, отведенная
ИТ в организации. Область действия
ИТ-стратегии можно подразделить на
две составляющие: ИТ-архитектуру и
организационную часть. В круг задач
стратегии входят: • выравнивание
ИТ-стратегии с бизнес-стратегией; •
определение целевых бизнес-единиц
для использования различных
информационных компонент; • определение
приложений для использования в работе
с этими бизнес-единицами; • установление
архитектурных вариантов для системы;
• определение бизнес-процессов и их
увязка с архитектурой; • установление
стратегий работы с данными; • описание
технологической инфраструктуры; •
объяснение организационных изменений.
Исходя из перечня задач, дадим
определение ИТ-стратегии: это
функциональная стратегия, формирование
которой характеризуется ролью ИТ в
организации и степенью зрелости
возможностей ИТ, в зависимости от
которых находятся цели и задачи
стратегии. Для разработки стратегии
процессов управления ИТ-ресурсами
необходимо знать планы предприятия,
которые потребуют развития инфраструктуры,
обеспечения необходимого уровня
ИТ-сервисов и возможных вариантов
обеспечения ресурсами. С точки зрения
стратегии изменения портфеля прикладных
систем, необходимо опреде- лить планы,
связанные с новыми бизнес-процессами,
интеграцией приложений и поддерживанием
этих аспектов людскими ресурсами и
программным обеспечением. Основная
деятельность ИТ-служб направлена на
создание и управление приложениями
(прикладными системами), т.е. предоставление
ИТ-услуг, и эксплуатацию инфраструктуры,
т.е. поддержку ИТ-услуг. Разделение
обязанностей связано с различием в
деятельности по со- зданию систем и
их сопровождению. Каждая из групп
имеет свои цели: • приложения определяют
то, как выполняется работа, поэтому
разработка приложений тесно связана
с основным бизнесом компании или
деятельностью государственной
организации, а знание приложений —
это прежде всего понимание бизнес-
процессов; • эксплуатация инфраструктуры
— деятельность, относительно слабо
связанная с ключевыми функциями
организации, сфокусированная в основном
на технологиях. Таким образом, необходимо
различать две разные стратегии в
области ИТ: прикладные системы и
эксплуатация ИТ-инфраструктуры: •
приложения как элемент стратегии ИТ
— это зона ответственности бизнеса.
Основой функционирования организации
явля- ются бизнес-процессы, которые
поддерживаются прикладными системами.
Руководство компании должно оценивать
стратегию в области прикладных систем
с точки зрения качества и результативности
поддержки ключевых функций; •
эксплуатация инфраструктуры
сфокусирована на сегодняшних, ежедневных
проблемах. Бизнес-руководство оценивает
стратегию в области ИТ-инфраструктуры
с точки зрения эффективности
(максимальная отдача при минимальных
затратах). Gartner Group предлагает следующий
подход к составным элементам ИТ-стратегии
и определяет 9 этапов реализации: 1.
Согласование понимания требований
бизнеса к ИТ (понимание направлений
развития бизнеса). 2. Определение
процессов управления и контроля, выбор
финансовых критериев для принятия
решений и сравнительного анализа
вариантов стратегии. 3. Определение
будущего состояния архитектуры
предприятия (высокоуровневое описание).
4. Анализ текущего состояния ИТ и оценка
вариантов реализаций с учетом
существующих ограничений, накладываемых
имеющейся инфраструктурой ИТ. 5.
Разработка стратегии развития/изменения
приложений. Применение знаний,
полученных на предыдущих этапах. 6.
Формирование стратегии развития
процессов и операций управления
ИТ-ресурсами. Стратегическим направлением
здесь может являться переход к сервисной
модели предоставления ИТ-услуг. 7.
Определение стратегии и задач по
развитию необходимых кадровых
ИТ-ресурсов и позиционированию
аутсорсинга. 8. Подготовка документа
с описанием стратегии ИТ и представление
результатов для формального обсуждения.
9. Организация управленческого процесса
поддержания стратегии в актуальном
состоянии.
ринятие
решения о внедрении информационной
системы имеет статус стратегической
инвестиции, поэтому некоторые компании
разрабатывают ИТ-стратегию только
для реализации этой программы. В таком
контексте используется термин SISP
(Strategic Information Systems Planning — планирование
стратегических информационных систем).
В случае SISP область действия сужается
до внедрения информационной системы,
поэтому существует обособленный ряд
методологий SISP, таких как BSP (Business
Systems Planning — планирование бизнес-
систем), SSP (Strategic Systems Planning — планирование
стратегических систем), IE (Information
Engineering — информационный инжиниринг).
ИТ-стратегию характеризуют возможности
ИТ как на рынке технологий, так и на
предприятии, а также роль, отведенная
ИТ в организации. Область действия
ИТ-стратегии можно подразделить на
две составляющие: ИТ-архитектуру и
организационную часть. В круг задач
стратегии входят: • выравнивание
ИТ-стратегии с бизнес-стратегией; •
определение целевых бизнес-единиц
для использования различных
информационных компонент; • определение
приложений для использования в работе
с этими бизнес-единицами; • установление
архитектурных вариантов для системы;
• определение бизнес-процессов и их
увязка с архитектурой; • установление
стратегий работы с данными; • описание
технологической инфраструктуры; •
объяснение организационных изменений.
Исходя из перечня задач, дадим
определение ИТ-стратегии: это
функциональная стратегия, формирование
которой характеризуется ролью ИТ в
организации и степенью зрелости
возможностей ИТ, в зависимости от
которых находятся цели и задачи
стратегии. Для разработки стратегии
процессов управления ИТ-ресурсами
необходимо знать планы предприятия,
которые потребуют развития инфраструктуры,
обеспечения необходимого уровня
ИТ-сервисов и возможных вариантов
обеспечения ресурсами. С точки зрения
стратегии изменения портфеля прикладных
систем, необходимо опреде- лить планы,
связанные с новыми бизнес-процессами,
интеграцией приложений и поддерживанием
этих аспектов людскими ресурсами и
программным обеспечением. Основная
деятельность ИТ-служб направлена на
создание и управление приложениями
(прикладными системами), т.е. предоставление
ИТ-услуг, и эксплуатацию инфраструктуры,
т.е. поддержку ИТ-услуг. Разделение
обязанностей связано с различием в
деятельности по со- зданию систем и
их сопровождению. Каждая из групп
имеет свои цели: • приложения определяют
то, как выполняется работа, поэтому
разработка приложений тесно связана
с основным бизнесом компании или
деятельностью государственной
организации, а знание приложений —
это прежде всего понимание бизнес-
процессов; • эксплуатация инфраструктуры
— деятельность, относительно слабо
связанная с ключевыми функциями
организации, сфокусированная в основном
на технологиях. Таким образом, необходимо
различать две разные стратегии в
области ИТ: прикладные системы и
эксплуатация ИТ-инфраструктуры: •
приложения как элемент стратегии ИТ
— это зона ответственности бизнеса.
Основой функционирования организации
явля- ются бизнес-процессы, которые
поддерживаются прикладными системами.
Руководство компании должно оценивать
стратегию в области прикладных систем
с точки зрения качества и результативности
поддержки ключевых функций; •
эксплуатация инфраструктуры
сфокусирована на сегодняшних, ежедневных
проблемах. Бизнес-руководство оценивает
стратегию в области ИТ-инфраструктуры
с точки зрения эффективности
(максимальная отдача при минимальных
затратах). Gartner Group предлагает следующий
подход к составным элементам ИТ-стратегии
и определяет 9 этапов реализации: 1.
Согласование понимания требований
бизнеса к ИТ (понимание направлений
развития бизнеса). 2. Определение
процессов управления и контроля, выбор
финансовых критериев для принятия
решений и сравнительного анализа
вариантов стратегии. 3. Определение
будущего состояния архитектуры
предприятия (высокоуровневое описание).
4. Анализ текущего состояния ИТ и оценка
вариантов реализаций с учетом
существующих ограничений, накладываемых
имеющейся инфраструктурой ИТ. 5.
Разработка стратегии развития/изменения
приложений. Применение знаний,
полученных на предыдущих этапах. 6.
Формирование стратегии развития
процессов и операций управления
ИТ-ресурсами. Стратегическим направлением
здесь может являться переход к сервисной
модели предоставления ИТ-услуг. 7.
Определение стратегии и задач по
развитию необходимых кадровых
ИТ-ресурсов и позиционированию
аутсорсинга. 8. Подготовка документа
с описанием стратегии ИТ и представление
результатов для формального обсуждения.
9. Организация управленческого процесса
поддержания стратегии в актуальном
состоянии.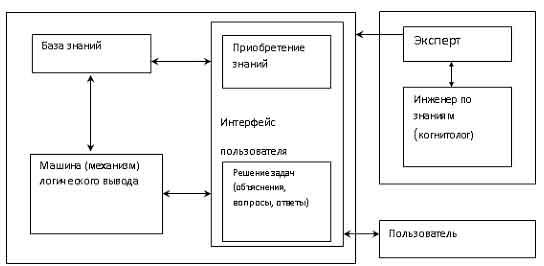 нтерфейс
пользователя.
ЭС содержат языковой процессор для
общения между пользователем и
компьютером. Это общение может быть
организовано с помощью естественного
языка, сопровождаться графикой или
многооконным меню. Интерфейс пользователя
должен обеспечивать два режима работы:
режим приобретения знаний и режим
решения задач.
нтерфейс
пользователя.
ЭС содержат языковой процессор для
общения между пользователем и
компьютером. Это общение может быть
организовано с помощью естественного
языка, сопровождаться графикой или
многооконным меню. Интерфейс пользователя
должен обеспечивать два режима работы:
режим приобретения знаний и режим
решения задач.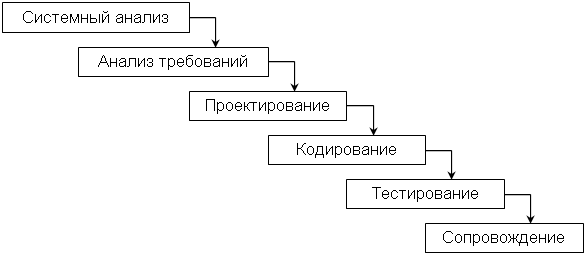 едостатки
модели:
едостатки
модели: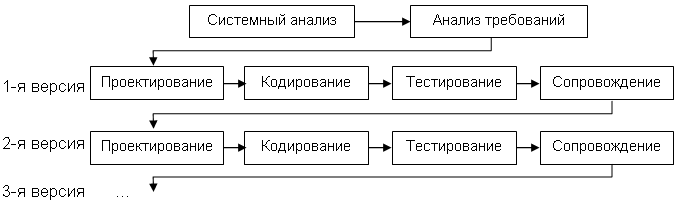 начале работы над проектом определяются
все основные требования к системе,
после чего выполняется ее разработка
в виде последовательности версий. При
этом каждая версия является законченным
и работоспособным продуктом. Первая
версия реализует часть запланированных
возможностей, следующая версия
реализует дополнительные возможности
и т. д., пока не будет получена полная
система.
начале работы над проектом определяются
все основные требования к системе,
после чего выполняется ее разработка
в виде последовательности версий. При
этом каждая версия является законченным
и работоспособным продуктом. Первая
версия реализует часть запланированных
возможностей, следующая версия
реализует дополнительные возможности
и т. д., пока не будет получена полная
система.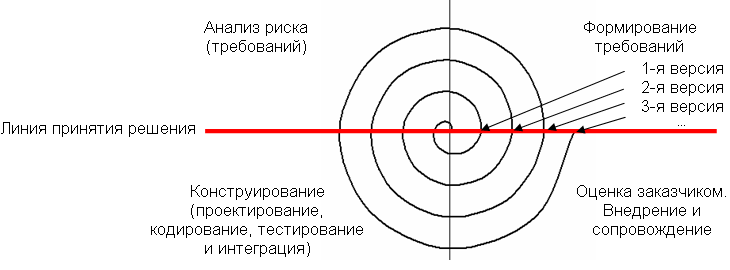 анная
модель жизненного цикла характерна
при разработке новаторских (нетиповых)
систем. В начале работы над проектом
у заказчика и разработчика нет четкого
видения итогового продукта (требования
не могут быть четко определены) или
стопроцентной уверенности в успешной
реализации проекта (риски очень
велики). В связи с этим принимается
решение разработки системы по частям
с возможностью изменения требований
или отказа от ее дальнейшего развития.
Как видно из рис.3, развитие проекта
может быть завершено не только после
стадии внедрения, но и после стадии
анализа риска.
анная
модель жизненного цикла характерна
при разработке новаторских (нетиповых)
систем. В начале работы над проектом
у заказчика и разработчика нет четкого
видения итогового продукта (требования
не могут быть четко определены) или
стопроцентной уверенности в успешной
реализации проекта (риски очень
велики). В связи с этим принимается
решение разработки системы по частям
с возможностью изменения требований
или отказа от ее дальнейшего развития.
Как видно из рис.3, развитие проекта
может быть завершено не только после
стадии внедрения, но и после стадии
анализа риска.

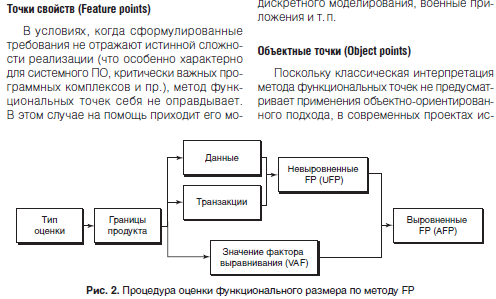

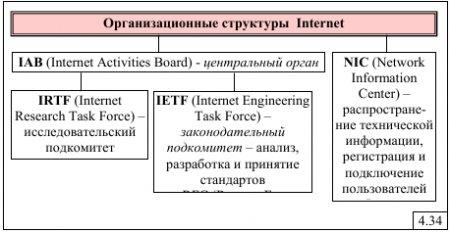
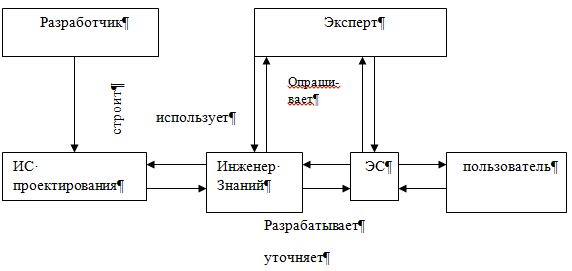 ассмотрим
компетентность ЭС, сравнивая систему
человеческого интеллекта и систему
ИИ.
ассмотрим
компетентность ЭС, сравнивая систему
человеческого интеллекта и систему
ИИ.
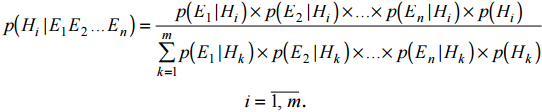

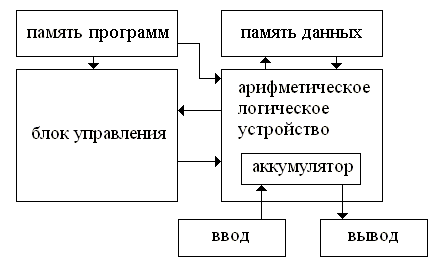
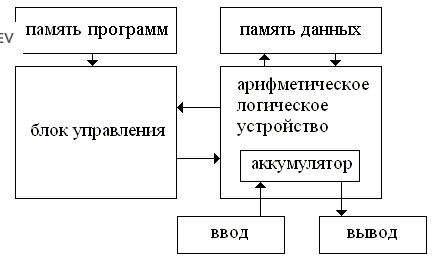 современных ВС Гарвардская архитектура
используется в сигнальных (DSP) процессорах
и в микроконтроллерах. Микроконтроллер
- микропроцессор для встраиваемых и
разнообразных специализированных
ВС. Микроконтроллер отличается от
обычного процессора пониженным
энегропотреблением, часто малым
размером и малым числом выводов на
корпусе. Также он может иметь
дополнительные возможности, таке как
оцифровка аналогового сигнала,
интегрированный интерфейс для связи.
Типичный микроконтроллер (PIC, Atmel AVR8)
имеет модифицированную Гарвардскую
архитектуру. Для программного
обеспечения микроконтроллеров
надежность гораздо важнее возможности
построения самомодифицирующихся
программ. Размещение программ в
отдельной памяти, которая может
записываться только при программировании
микроконтроллера, исключает возможность
случайной порчи программ.
современных ВС Гарвардская архитектура
используется в сигнальных (DSP) процессорах
и в микроконтроллерах. Микроконтроллер
- микропроцессор для встраиваемых и
разнообразных специализированных
ВС. Микроконтроллер отличается от
обычного процессора пониженным
энегропотреблением, часто малым
размером и малым числом выводов на
корпусе. Также он может иметь
дополнительные возможности, таке как
оцифровка аналогового сигнала,
интегрированный интерфейс для связи.
Типичный микроконтроллер (PIC, Atmel AVR8)
имеет модифицированную Гарвардскую
архитектуру. Для программного
обеспечения микроконтроллеров
надежность гораздо важнее возможности
построения самомодифицирующихся
программ. Размещение программ в
отдельной памяти, которая может
записываться только при программировании
микроконтроллера, исключает возможность
случайной порчи программ.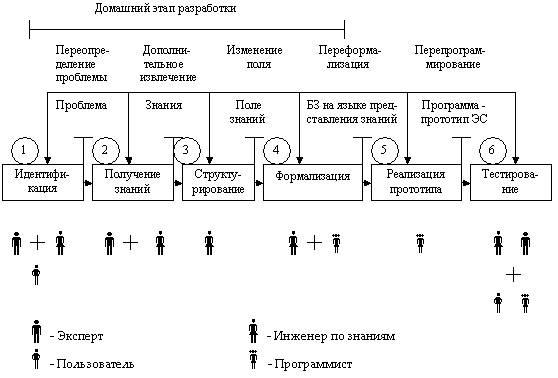
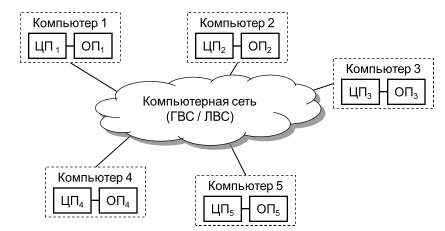
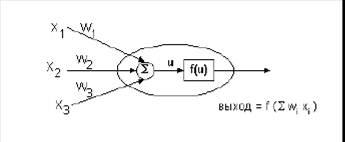 десь
Xi – входные признаки; Wi – степень
влияния входного признака на выходной;
U – взвешенная сумма значений входных
признаков; f(u) – решающая функция; Y –
выходные признаки (сигналы).
десь
Xi – входные признаки; Wi – степень
влияния входного признака на выходной;
U – взвешенная сумма значений входных
признаков; f(u) – решающая функция; Y –
выходные признаки (сигналы).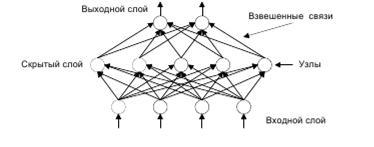 бучение
нейронной сети сводится к определению
связей (синапсов) между нейронами и
установлению силы этих связей (весовых
коэффициентов). Алгоритмы обучения
нейронной сети упрощенно сводятся к
определению зависимости весового
коэффициента связи двух нейронов от
числа примеров, подтверждающих эту
зависимость.
бучение
нейронной сети сводится к определению
связей (синапсов) между нейронами и
установлению силы этих связей (весовых
коэффициентов). Алгоритмы обучения
нейронной сети упрощенно сводятся к
определению зависимости весового
коэффициента связи двух нейронов от
числа примеров, подтверждающих эту
зависимость.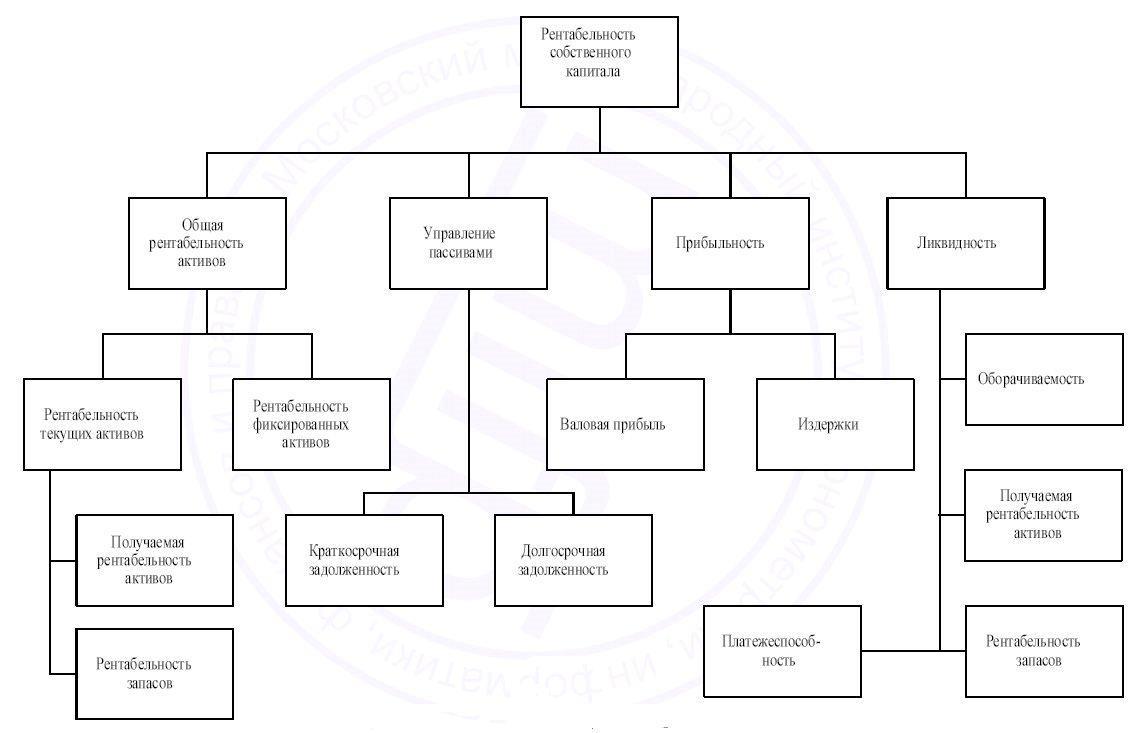
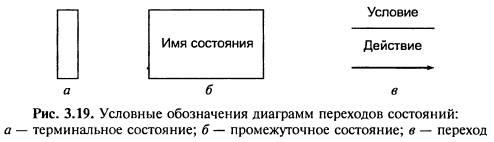
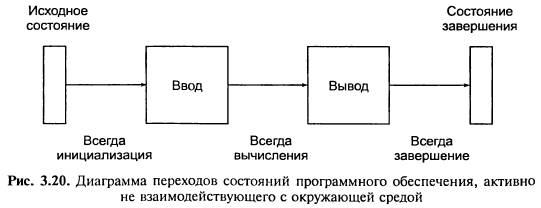
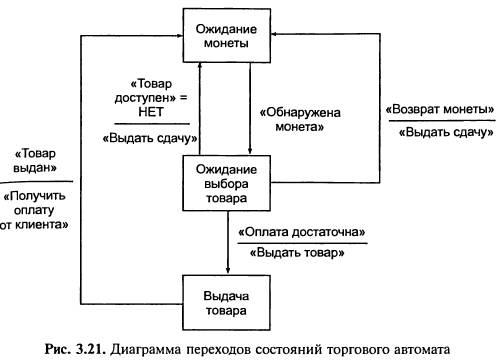
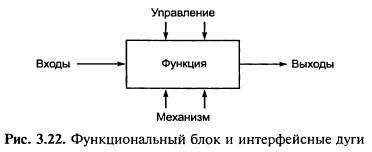
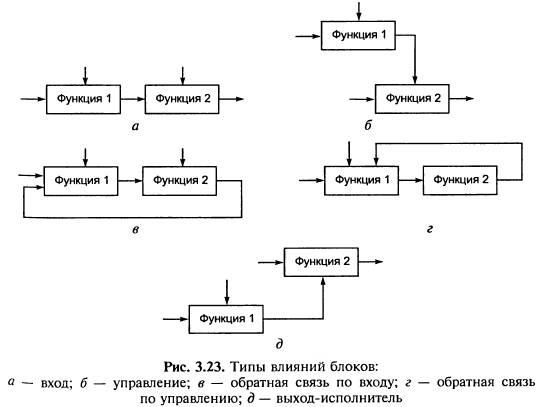


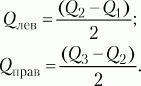

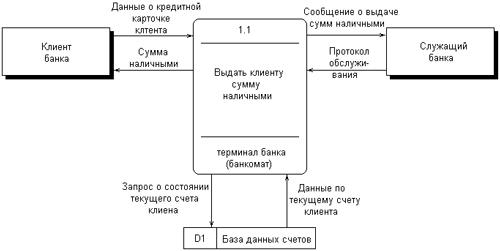
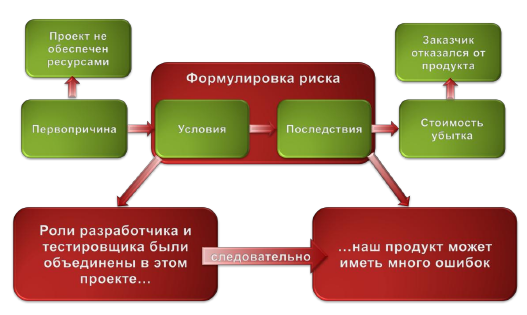
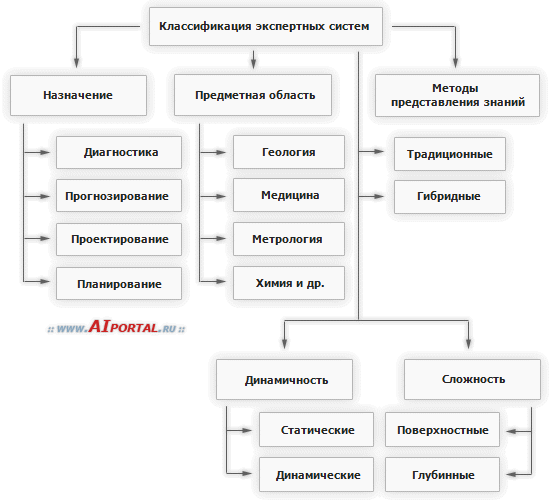
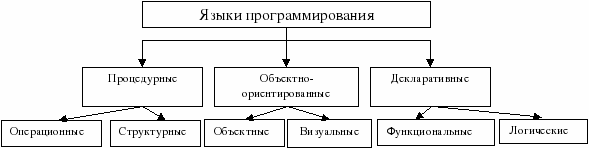
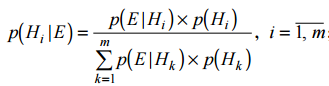
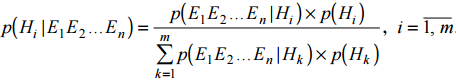
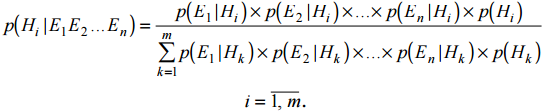
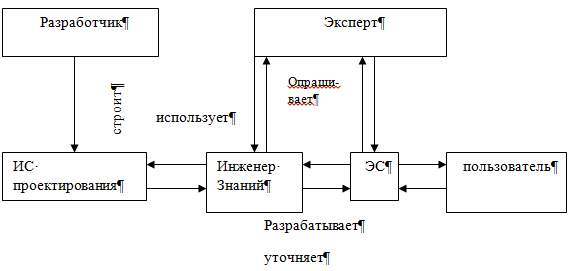


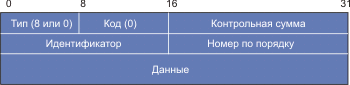
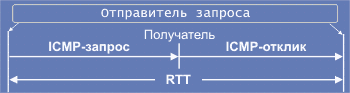
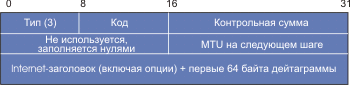


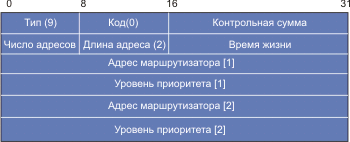


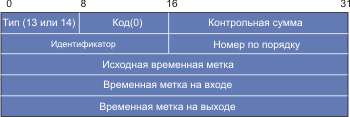


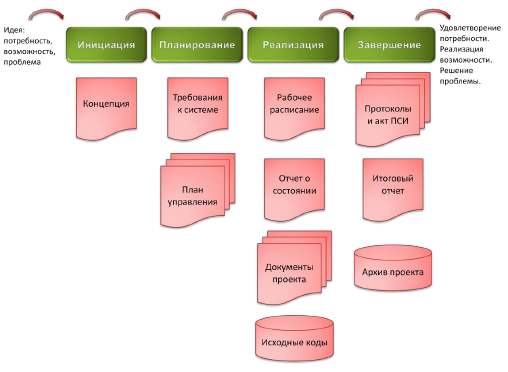
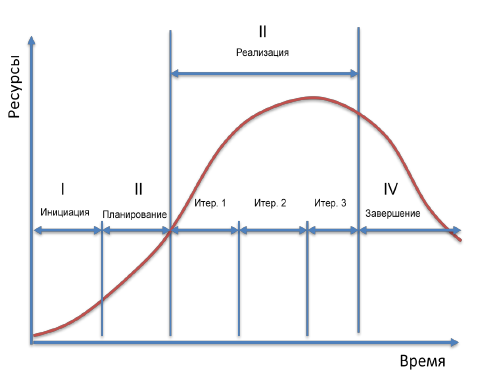
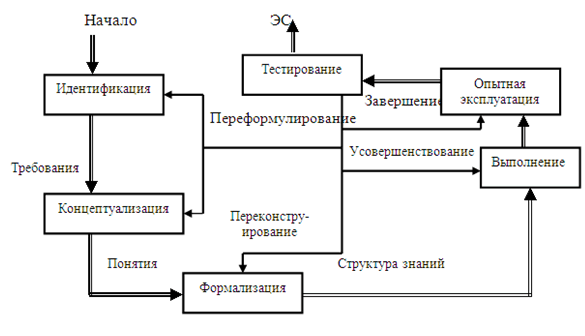
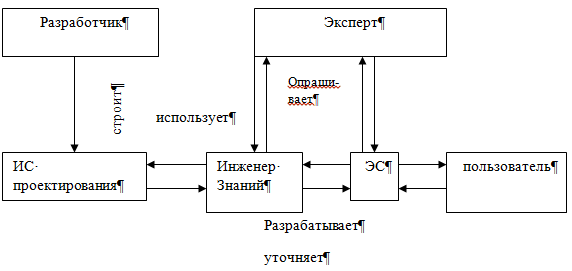
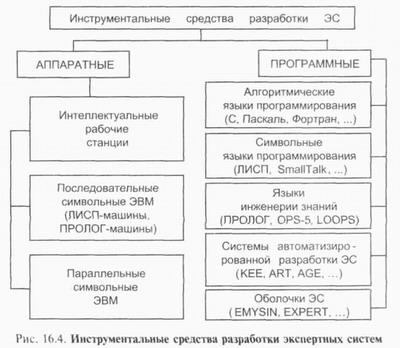
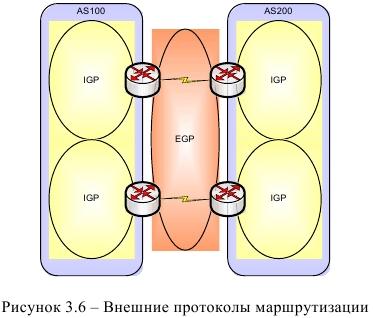 ротоколы
EGP
только распознают автономные системы
в иерархии маршрутизации, игнорируя
внутренние протоколы маршрутизации.
Граничные маршрутизаторы различных
AS
обычно поддерживают, во-первых,
какой-либо тип IGP
через интерфейсы внутри своих AS,
и, во-вторых, BGP
или иной тип внешнего протокола через
внешние интерфейсы, соединяющие
собственную AS
с удаленной.
ротоколы
EGP
только распознают автономные системы
в иерархии маршрутизации, игнорируя
внутренние протоколы маршрутизации.
Граничные маршрутизаторы различных
AS
обычно поддерживают, во-первых,
какой-либо тип IGP
через интерфейсы внутри своих AS,
и, во-вторых, BGP
или иной тип внешнего протокола через
внешние интерфейсы, соединяющие
собственную AS
с удаленной.
 В
модифицированной Гарвардской
архитектуре (см. рис. 4) добавлена связь
между памятью программ и АЛУ, что
позволяет хранить в памяти команд
константы, например, строки.
В
модифицированной Гарвардской
архитектуре (см. рис. 4) добавлена связь
между памятью программ и АЛУ, что
позволяет хранить в памяти команд
константы, например, строки.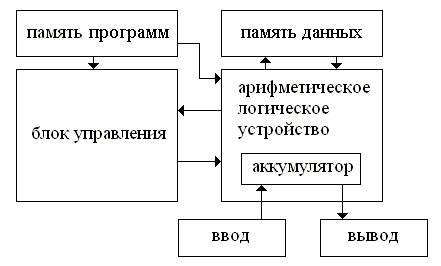


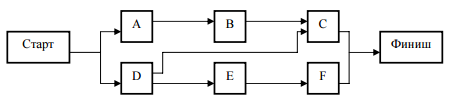
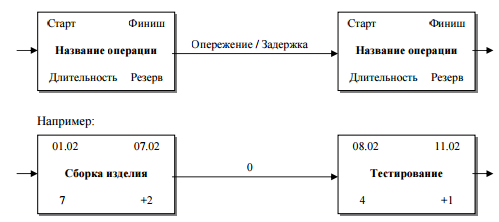
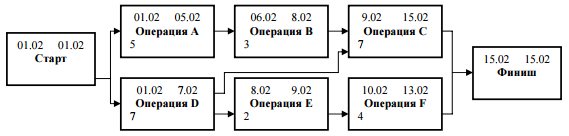
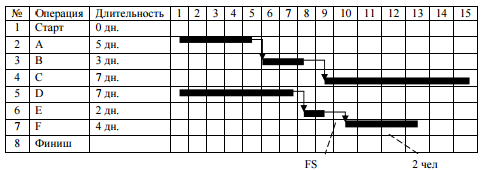
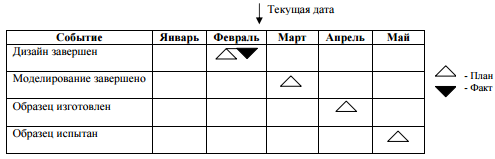
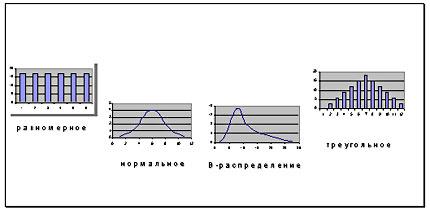
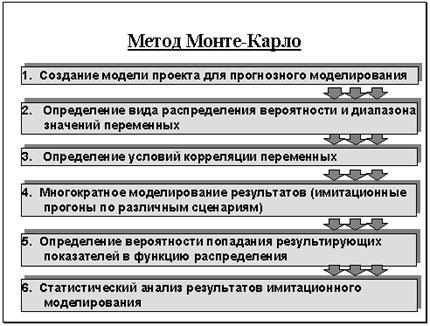


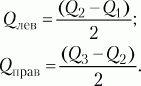
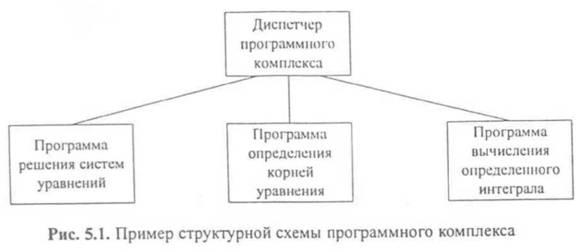
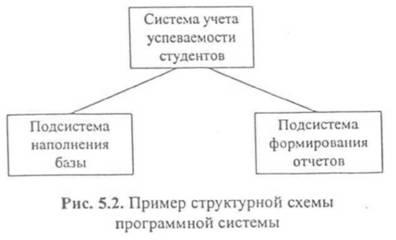
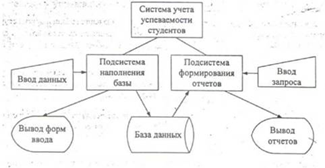
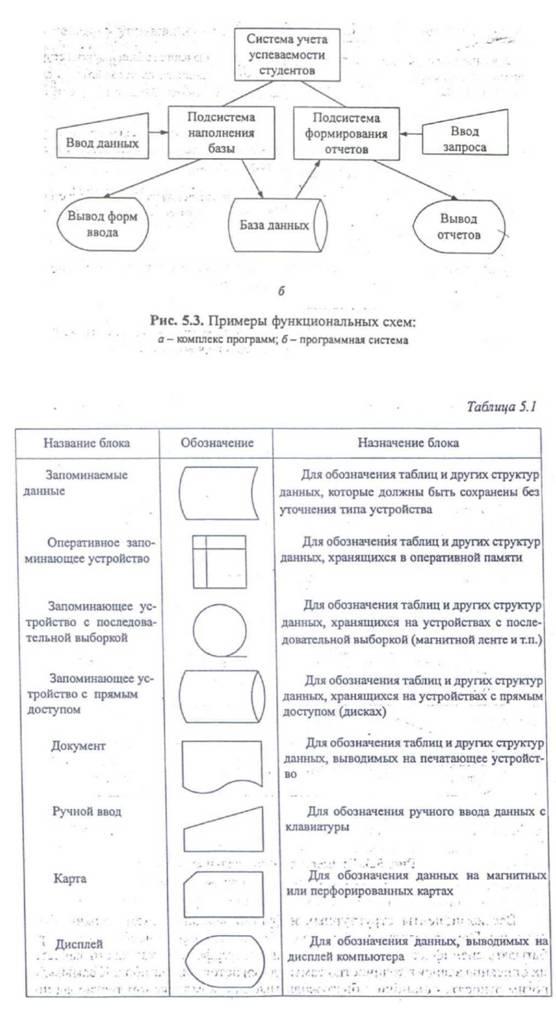





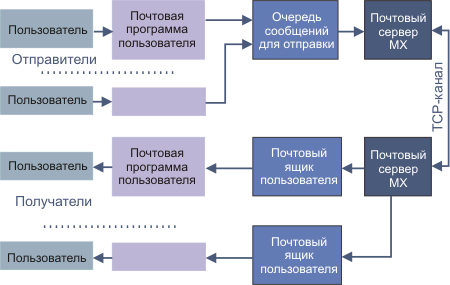
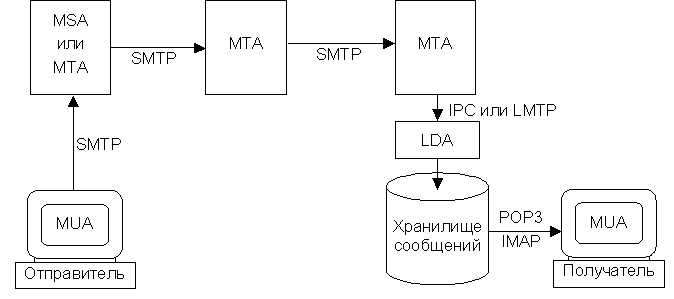 окращенно
обозначены следующие компоненты
электронной почты:
окращенно
обозначены следующие компоненты
электронной почты: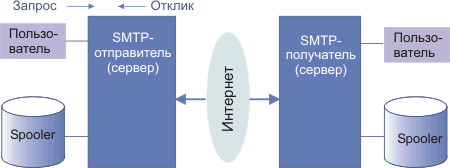 MTP
обеспечивает передачу почтового
сообщения непосредственно конечному
получателю, когда они соединены
непосредственно. В противном случае
пересылка может выполняться через
одного или более промежуточных
"почтовых станций".
MTP
обеспечивает передачу почтового
сообщения непосредственно конечному
получателю, когда они соединены
непосредственно. В противном случае
пересылка может выполняться через
одного или более промежуточных
"почтовых станций".