

Rivero L.Encyclopedia of database technologies and applications.2006
.pdfdomain is a set of heterogeneous sources. The view schema provides a uniform access to the domain, but each source must be linked to the view schema by view definitions that depend on the source. Although there are some variations, the principle of using a view mechanism is to simplify the access to data sources. Users querying a view schema will obtain results as if they were querying one simple database. View engines, implemented in database management systems, are in charge of translating the query against the view into queries against the data.
Once defined, views can be virtual or materialized, depending on the way data are stored in the data structure associated with the view (materialized) or if the view is just a virtual representation (portion) of data sources (virtual views or, simply, views). Materializing a view consists of computing the associated query once and storing its result. Querying a virtual view implies a translation of the query using view definition to retrieve data on sources. Virtual views are used when data are updated frequently on data sources and when data cannot be replicated.
Views are materialized typically to improve query performance (Goldstein & Larson, 2001) and data availability. Querying a materialized view is much faster than querying a virtual one: A query against a materialized view is like a query against an actual database. The speed difference may be critical in applications where the query rate is high and the view is complex (e.g., with aggregate functions or joining remote sources; Chaudhuri, Krishnamurthy, Potamianos, & Shim, 1995; Srivastava, Dar, Jagadish, & Levy, 1996; Zaharioudakis, Cochrane, Lapis, Pirahesh, & Urata, 2000). Materialized views are used in data warehouses (Hammer, Garcia-Molina, Widom, Labio, & Zhuge, 1995) and distributed and multidimensional databases. Nevertheless, using materialized views implies new problems such as view selection, i.e., which views to materialize, and view maintenance, i.e., refreshing data into the view when data change (Griffin & Libkin, 1995).
Views can also be used for data integration. A data integration system provides a uniform query interface to a multitude of autonomous, distributed, and heterogeneous data sources, which may reside within a local database (e.g., database of an enterprise) or on distributed databases. The idea is to free the user from having to deal with several sources to have a complete answer to his queries. Queries are formulated using a uniform query language against a uniform virtual view of the data (also known as a mediator) instead of querying different data schemas. The querying system translates the query against the view into queries against the sources, retrieves results on data sources, and finally presents them to the user (Lenzerini, 2002).
Data integration systems represent a good solution to the information retrieval problem such as a search of the
Using Views to Query XML Documents
Web. Users interested in finding information over the full Web use key-word-based search engines such as Altavista or Google.1 Such methods are often not precise enough and return a lot of useless URLs. Answering precise queries such as “find the names and addresses of Spanish museums that own a painting by Picasso” requires a lot of tedious browsing through useless pages.
There have been many research projects focusing on data integration for structured and semi-structured data sources. The common idea is to provide a global view as an interface between end users and data sources. A query is formulated on the global view and then translated in a union of queries against the different sources. The research projects can be distinguished according to the way global view and sources are connected. In a first approach called global-as-view (GAV), the global view is a collection of views defined over the schema of the local sources (Cluet, Simeon, & Delobel, 1998). A query translation algorithm can be very efficient, but the global view has to be changed whenever a local source is updated. In a second approach called local-as-view (LAV), local sources are defined as a view over the global view. Recently, a mixed approach known as GLAV has been proposed (Lenzerini, 2002).
The emergence of the XML language (W3C, 2000) as the new (and global) standard for data exchange on the Web may change things positively by adding structure where there was none. Many research projects have proposed XML as a language to express a common interface between existing databases or to integrate in a uniform view heterogeneous data sources (Manolescu, Florescu, & Kossman, 2001). Other database-like applications, such as data monitoring, document changing notifications, active databases, and electronic commerce, have taken or will take advantage of the XML technology.
This paper presents views and database models and reports the proposals of a view system presented in Aguilera, Cluet, Milo, Veltri, and Vodislav (2002) and in Veltri (2002) as a system to query large-scale heterogeneous XML data.
BACKGROUND
View definitions depend on the database model. In relational databases (Ullman, 1998), data is organized in tables (relations), each one with a schema which defines its structure (i.e., attributes and their base types such as integer, string, etc). The instance of a relation consists of a set of tuples, each containing attributes instances of the appropriate base types. For instance, the following set of relations contains data on employees and projects and belongs to the relational database of an enterprise:
730
TEAM LinG

Using Views to Query XML Documents
Employees (SocialSecurityNb, Name, Department, Salary, Personal_Address);
Projects (ProjectId, ProjectName, Manager, ProjectSite); WorkOnProject(EmployeeId, ProjId);
Relations are queried using SQL, the standard query language for the relational model. Relational databases can be composed of a large number of tables, while users may be interested only in small portion of data. Views allow one to create a virtual relation with data relative to such attributes, loaded from the database tables, which can be accessed as a database table.
For instance, to monitor the employees that work in projects located in Paris (as well as to protect salary information from unauthorized accesses), we can create a view with the project name, the employee name, and the department name. EmployeeInParis view can be defined by means of an SQL query as:
CREATE VIEW EmployeeInParis AS
SELECT Name AS EmpName,
Personal_Address AS Address,
Department AS DeptName
FROM Employees, Projects, WorkOnProject
WHERE ProjectSite = ‘Paris’
AND ProjectId = ProjId
AND EmployeeId = SocialSecurityNb
Users can query EmployeeInParis as if it were a base relation, using an SQL expression. For example, the following query retrieves the name of the employees in Paris:
SELECT EmpName
FROM EmployeeInParis
Processing a query against a view depends on the view implementation. As described above, if the view is materialized, then it is treated as a relation of the database and query processing is standard. If the view is virtual, it contains no data, meaning that values are not replicated, and thus represents a virtual source which users can query as if it had been stored in the database. For example, the previous query against EmployeeInParis is translated by the system into a query against actual data (i.e., the relations Projects, Employees, and WorkOnProject), combining the view definition with the query as follows:
SELECT EmpName
FROM ( SELECT Name AS EmpName,
Personal_Address AS Address,
Department AS DeptName
FROM Employees, Projects, WorkOnProject
WHERE ProjectSite = ‘Paris’
AND ProjectId = ProjId
AND EmployeeId = SocialSecurityNb )
and then evaluated by the query processor as a standard query. 7
Views are also defined in other database models, such as the object-oriented or semi-structured ones. Views are still characterized by their schema, definition, and domain. We here sketch some examples using other models. In object-oriented databases (OODBs; Cattell, 1997), data items are objects, instances of classes, and are identified by a couple (oid, value), where oid is a unique identifier and value is a list of properties primitive (as integer, string, etc.) or complex objects (e.g., a userdefined object).
Figure 2 shows an example of a database schema in an object-oriented database: Dashed lines represent the aggregate relations between properties and classes, while full lines represent inheritance relations.
Again, views have a domain, schema, and definition. View domain is defined selecting one or more classes of the database schema. The view schema is a new class, also called a virtual class, and the view definition language is, in most of the proposals, an extension of OQL, the standard query language for object-oriented databases, which allows the construction of new objects. For instance, a virtual class for the employees working for a department in Paris is defined as follows:
virtual class EmployeeInParis from Employee hide attributes salary
with extension EmployeeInParis = select e from e Employee
where e.department.location = “paris”
end;
where the “.” notation is used to navigate through the classes relationships. Note that, thanks to inheritance, defining a view on Employee also gives access to objects of its subclasses, i.e., Permanent and Invited classes. Given that, it is possible to limit the access to subclasses in a view with a “hide class” command.
Figure 2. An object-oriented database schema
Institute |
research-area |
name |
address |
group |
Project
research-area
name |
budget |
participant |
Address |
country |
city |
code |
street |
Team |
t-name |
budget |
teamMembers |
Employee |
name |
address |
department |
salary |
Department |
name |
location |
code |
secretary |
Permanent |
Invited |
|
status |
|
daily-wage |
|
|
|
monthly-wage |
|
research-center |
|
|
|
731
TEAM LinG

Figure 3. An OEM database |
|
|
|
|
|
||||||
|
|
|
|
|
|
Guide |
|
|
|
|
|
|
|
|
|
|
|
&12 |
|
|
|
|
|
|
|
|
|
|
restaurant |
restaurant |
restaurant |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
&19 |
nearby |
&35 |
zipcode |
&54 |
|
&77 |
|
|
|
|
|
nearby |
|
|
|
||||
|
|
|
|
|
|
|
92310 |
|
|
|
|
category |
name |
address |
category |
|
|
price |
|
name |
|||
|
|
|
|
||||||||
|
|
|
category |
||||||||
|
|
|
|
|
|
|
|
|
|||
&17 |
|
&13 |
|
&14 |
&66 |
&17 |
&23 |
&25 |
&55 |
&79 |
&80 |
|
|
Vietnamese |
Saigon |
Mountain |
Menlo |
||||||
gourmet |
Chef Chu |
|
|
cheap |
fast |
McDonald’s |
|||||
|
|
|
|
View |
Park |
||||||
|
|
|
|
|
|
|
|
|
|
food |
|
|
|
street |
|
city |
zipcode |
|
|
|
|
|
|
|
|
&44 |
|
&15 |
&16 |
nearby |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
El Camino |
Palo Alto |
92310 |
|
|
|
|
|
|
||
|
|
Real |
|
|
|
|
|
|
|
|
|
The semi-structured data model is based on the concept of data instances as a graph, with objects as the vertices and labels on the edges. Data entities are objects, each with a unique identifier oid. Some objects are atomic and contain a value from some base type (e.g., integer, string, gif image, audio, etc.); others are complex objects, denoted by a set of couples (label, oid). An example of a semi-structured database, borrowed from Abiteboul, Buneman and Suciu (2000), is shown in Figure 3 and represents restaurants in a tourist guide.
Views on semi-structured data can also be defined to increase the flexibility of a database system by adapting the data to user or application needs. In Abiteboul et al. (1995), views are defined and queried using an extension of OQL. The view is a subgraph of the graph database, and objects in the view (i.e., nodes) can be a copy of the source objects (i.e., materialized) or can refer to existing objects in the database. Again, in the latter case, queries against view are rewritten using the view definition.
XML is now the accepted standard semi-structured model (Abiteboul et al., 2000). Interestingly, it has been developed in parallel to the database efforts towards a semi-structured model. XML is used to define views to export data as XML views over the Web, keeping their internal data structure. XML views are queried using Xquery,2 the standard XML query language, and then translated in the query language supported by the underlying data models. As we will see in the next section, XML views can be used as a global view for data integration.
VIEWS ON XML DOCUMENTS
In this section we report a proposal of using views to access heterogeneous and large-scale XML documents. The proposal, presented in Aguilera et al. (2002), is implemented in a real system, Xyleme, (2001).
Let us consider the query “find the work of art of van Gogh in the Orsay museum.” Knowing the structure of the
Using Views to Query XML Documents
(XML) document, the query can be formulated as expressed in Figure 4, where bounding label are target node and condition (“van Gogh” and “Orsay”) are in leaf nodes. To formulate this query users have to know the structure of the queried document. In the case of a large-scale XML database, where documents have different structures, users have to know all of them to formulate queries. Now we sketch how views can be used to avoid users having to know the structure of all queried documents.
The idea of Aguilera et al. (2002) is to create an abstract document (a view) that allows users to navigate through a simpler document and relay to the system the translation of the query into query on concrete (i.e., contained in databases) documents. Suppose documents are structured, e.g., XML documents, and contained in repositories of data. Documents can be represented as tree as in XML.
Considering a large volume of data sets and of XML documents, the view domain is a subset of data sources, while the view schema is an abstract tree representing a document that is not in the repository but is representative of the view domain, i.e., of a set of documents. The tree on the left side of Figure 5 is a possible abstract document representing the concrete document structure reported on the right side. The view definition, i.e., how queries on views are translated on queries against real data, of Aguilera et al. (2002) is based on a “path-to-path” mapping, i.e., a view specifies mappings between paths in the abstract and concrete tree document structures. Table 1 shows some examples of path-to-path mappings between the abstract and concrete trees of Figure 5. The “/” symbol refers to parent/child relations in the tree representing the document.3
There exist other possible mappings such as (1) label- to-label mappings, where view and documents are related by a set of mappings from an abstract label of a node in the view (e.g., “painting” in the abstract tree of Figure 5) and a concrete label of a node in some document tree (e.g., “WorkOfArt” or “painting” in the concrete document on the right side of Figure 5) and (2) building a data set of correspondence between all possible abstract subtrees and concrete trees in the data sets (Aguilera et al., 2002).
As in a standard database, the query engine uses view definition (mappings) to generate queries on documents of the database. Remember that the common goal is precision in query results.
Figure 4. Query on document structure
|
WorkOfArt |
|
|
|
|
artist |
gallery |
||
title |
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
“van Gogh” |
“Orsay” |
||
732
TEAM LinG

Using Views to Query XML Documents
Table 1. Path-to-path mappings
Abstract path |
Concrete path |
painting |
workOfArt |
|
artistic-Works/painting |
|
... |
painting/author |
workOfArt/artist |
|
artistic-Works/painting/description/author-of- |
|
painting |
|
... |
painting/museum |
workOfArt/gallery |
|
artistic-Works/exhibition |
|
artistic-Works/exhibition/gallery |
|
... |
... |
... |
In path-to-path mappings a mapping is context sensitive, e.g., node “name” belonging to path “workOfArt/ period/name” has a different interpretation from the leaf node of the “person/student/name” path.
A query is formulated on the view and translated using mappings. Figure 6 shows the query of Figure 4 formulated against the view (left side) and the corresponding queries against documents obtained by a translation process using mappings of Table 1. During the translation phase, the system combines concrete paths, focusing on those generating a subtree of some concrete document in the database. The result is the union of concrete queries built from valid tree combinations. Finally, in Xyleme (2001), concrete queries are evaluated using an XQuerylike query language.
FUTURE TRENDS
XML view mechanisms, such as that presented in this article, can be used in all applications extensively based on data exchange and data integration, where data is large
Figure 5. Abstract (view) and concrete documents
|
|
|
|
|
|
workOfArt |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
painting |
|
artist |
gallery |
title |
period |
||
|
|
|
|
|
|
|
|
|
|
title |
|
author |
museum |
|
|
|
name |
… |
|
|
Abstract tree |
|
|
|
|
|
|
|
|
|
(view schema) |
|
|
|
artistic-Works |
|
|||
|
|
|
|
|
painting |
exhibition |
|||
|
|
|
|
description |
address |
name |
|||
|
|
|
name |
|
|
author-of- |
|
||
|
|
|
|
|
|
painting |
|
||
Concrete documents
Figure 6. Query translation |
|
7 |
|
|
|
|
|
|
|
workOfArt |
|
painting |
artist |
gallery |
title |
|
“van Gogh” |
”Orsay” |
|
ttitle |
museum |
|
|
author |
|
|
|
“van Gogh” |
”Orsay” |
|
|
Artisti-Works
Query against view
|
painting |
exhibition |
|
description |
name |
name |
Author-of- |
”Orsay” |
|
painiting |
|
|
“van Gogh” |
|
Queries against data
and heterogeneous in contents and structure. This is what today happens, for instance, in Web applications, where data flow is intensive and huge in dimension.
Continuously endless data sources are producing large-scale databases, which raise a completely new set of data management problems. Examples of such continuous data flows are: phone companies’ call databases, astronomical daily digital sky surveys, audio and video surveillance devices’ data, and ISPs’ data. In this evolving scenario, new technologies have been coming out to simplify data flow management: search engines, Webbased applications, XML dialects and technologies, and grid applications. Most of these technologies relay on the XML standard, thanks to its system-independent and cross-application features. Applying the concepts presented here would allow data reorganization and optimization, allowing different views on data for different users or even application profiles, achieving data integration, and simplifying information retrieval.
Finally we imagine a word where different applications, such as business-to-business ones, may automatically exchange information using XML-based views that will automatically translate data from heterogeneous databases presenting different data schemas and structures.
CONCLUSION
This article treats views and their use for data integration. An example of a view mechanism for structured documents is reported. The hypotheses are that document
733
TEAM LinG
structures are known off line and that ontology semiautomatic mechanisms are used to define views. The view mechanism reported is the one presented in Aguilera et al. (2002) and fully implemented in Xyleme (2001).
ACKNOWLEDGMENTS
Authors are grateful to Serge Abiteboul, Tova Milo, and Sergio Greco for their comments.
REFERENCES
Abiteboul, S., Buneman, P., & Suciu, P. (2000). Data on the Web. San Francisco: Morgan Kaufmann.
Abiteboul, S., Hull, R., & Vianu, V. (1995). Foundations of databases. Reading, MA: Addison-Wesley.
Aguilera, V., Cluet, S., Milo, T., Veltri, P., & Vodislav, D. (2002). Views in a large-scale XML repository. Very Large Databases Journal, 11(3).
Cattell, R. G. (1997). The object database standard: ODMG 2.0. San Mateo, CA: Morgan Kaufmann.
Chaudhuri, S., Krishnamurthy, R., Potamianos, S., & Shim, K. (1995). Optimizing queries with materialized views. In
Proceedings of International Conference on Database Theory, ICDT, Delphi, Greece (pp. 190-200). IEEE Computer Society Press.
Cluet, S., Simeon, J., & Delobel, C. (1998). Your mediators need data conversion! In Proceedings of the ACM SIGMOD-SIGACT-SIGART International Conference on Management of Data. Seattle, WA: ACM Press.
Goldstein, J., & Larson, P. (2001). Optimizing queries using materialized views. In Proceedings of the ACM SIGMOD-SIGACT-SIGART International Conference on Management of Data. Santa Barbara, CA: ACM Press.
Griffin, T., & Libkin, L. (1995). Incremental maintenance of views with duplicates. In Proceedings of the ACM SIGMOD-SIGACT-SIGART International Conference on Management of Data. San Jose, CA: ACM Press.
Hammer, J., Garcia-Molina, H., Widom, J., Labio, W., & Zhuge, Y. (1995). The Stanford data warehousing project.
IEEE Quarterly Bulletin on Data Engineering: Special Issue on Materialized Views and Data Warehousing, 18(2).
Lenzerini, M. (2002). Data integration: A theoretical perspective. In Proceedings of the International Conference on Database Theory (PODS). Madison, WI: ACM Press.
Using Views to Query XML Documents
Manolescu, I., Florescu, D., & Kossman, D. (2001). Answering XML queries over heterogeneous data sources. In Proceedings of 27th International Conference on Very Large Databases (VLDB), Rome, Italy. Morgan Kaufmann.
Srivastava, D., Dar, S., Jagadish, H. V., & Levy, A. Y., (1996). Answering queries with aggregation using views. In Proceedings of 22th International Conference on Very Large Databases (VLDB), Bombay, India. Morgan Kaufmann.
Ullman, J. D. (1988). Principles of database and knowl- edge-base systems. New York: Computer Science Press.
Veltri, P. (2002). A view mechanism for large scale XML Repositories: Design and implementation. Unpublished doctoral thesis, University of Paris XI-Orsay.
W3C. (2000). Extensible Markup Language (XML) 1.0 (2nd ed.) specification. Retrieved from http:// www.w3.org/TR/REC-xml
Xyleme S.A.(2001). Xyleme system. Retrieved from http:/ /www.xyleme.com
Zaharioudakis, M., Cochrane, R., Lapis, G., Pirahesh, H., & Urata, M. (2000). Answering complex SQL queries using automatic summary table. Proceedings of the ACM SIGMOD-SIGACT-SIGART International Conference on Management of Data, Dallas, Texas (pp. 105-116). ACM Press.
KEY TERMS
Materialized View: A materialized view physically stores data. Data is extracted from the database source (view domain) at view definition time. Data are thus duplicated in the view, and query evaluation is more efficient. Nevertheless, every database update operation must be reported on materialized views to guarantee data consistency.
Query on Views: A query on a view is defined using a view query language. Usually such a query language is the same as the one used for data sources. For instance, to query relational views defined on a relational database, the view query language is SQL.
View: A view is a logical representation of information contained in a database. It is an abstract vision of source data.
View Definition: Maps the view schema into view domain (data sources) using a view definition language.
734
TEAM LinG

Using Views to Query XML Documents
Typically an SQL-like query language is used to map data from sources to views.
View Domain: Defines the data sources on which views are built and contains the origins of data.
View Schema: Describes how data are represented in the view both structurally and logically.
Virtual View: A view that does not contain data is a virtual view. Generally views are virtual and data can only be find in the data sources. Queries against such views are evaluated using view definition to retrieve results on demand from data sources (view domain).
Xyleme: Xyleme is a dynamic warehouse for XML
data of the Web supporting query evaluation, change 7 control, and data integration. The Xyleme Project ended
in 2001 and the system is now owned by Xyleme S.A. company.
ENDNOTES
1Altavista: http://www.altavista.com; Google: http:/ /www.google.com
2XQuery: http://www.w3c.org/TR/xquery
3See XPath: http://www.w3c.org/TR/xpath
735
TEAM LinG
736
Vertical Database Design for Scalable Data Mining
William Perrizo
North Dakota State University, USA
Qiang Ding
Concordia College, USA
Masum Serazi
North Dakota State University, USA
Taufik Abidin
North Dakota State University, USA
Baoying Wang
North Dakota State University, USA
INTRODUCTION
For several decades and especially with the preeminence of relational database systems, data is almost always formed into horizontal record structures and then processed vertically (vertical scans of files of horizontal records). This makes good sense when the requested result is a set of horizontal records. In knowledge discovery and data mining, however, researchers are typically interested in collective properties or predictions that can be expressed very briefly. Therefore, the approaches for scan-based processing of horizontal records are known to be inadequate for data mining in very large data repositories (Han & Kamber, 2001; Han, Pei, & Yin, 2000; Shafer, Agrawal, & Mehta, 1996).
On the contrary, more and more advantages of using vertical data organization have been realized. For example, it makes hardware caching work well, it makes compression easy to do, and it may greatly increase the effectiveness of the I/O device since only participating fields are retrieved instead of the whole record. The vertical decomposition of a relation also permits a number of transactions to execute concurrently. Recently, much effort has been focused on subsampling and indexing to address problems of scalability. However, subsampling requires that the subsampler knows enough about the large data set in the first place, to subsample “representatively.” That is, subsampling representatively presupposes considerable knowledge about the data. For many large data sets, such knowledge may be inadequate or nonexistent.
Index files are vertical structures and they are vertical access paths to sets of horizontal records. Some indices, such as the bit-sliced index (BSI; Chan & Ioannidis, 1998; O’Neil & Quass, 1997; Rinfret, O’Neil, & O’Neil, 2001) and encoded bitmap index (EBI; Wu, 1998; Wu & Buchmann, 1998), do address the scalability problem in many cases, but they do so at the cost of creating and maintaining additional index files separate from the data files.
Another approach, which is different from the above conceptually, is to build the whole database vertically. Such a database can be used not only for routine data management, but also for data mining. Unlike the horizontal databases, which are stored horizontally and processed vertically, vertical databases are stored vertically and processed horizontally. With other characteristics, vertical databases are shown to address the scalability issues.
BACKGROUND
The concept of vertical data files, in fact, is not new at all. Copeland and Khoshafian (1985) presented an at- tribute-level decomposition storage model called DSM, similar to the attribute transposed file model (ATF; Batory, 1979) that stores each column of a relational table into a separate table. However, DSM was shown to perform well. It utilizes surrogate keys to map individual attributes together, hence requiring a surrogate key to be associated with each attribute of each record in the database. Attribute-level vertical decomposition is also
Copyright © 2006, Idea Group Inc., distributing in print or electronic forms without written permission of IGI is prohibited.
TEAM LinG

Vertical Database Design for Scalable Data Mining
used in remotely sensed imagery, e.g., Landsat Thematic Mapper imagery, where it is called band sequential (BSQ) format. Beyond attribute-level decomposition, Wong, Liu, Olken, Rotem, and Wong (1985) presented the bit transposed file model (BTF), which further partitioned each column into bit level and utilized encoding methods to reduce the storage space. Due to the difficulty of accessing files directly in an operating system, a higher layer of accessing known as database is invented. In most cases, databases are stored horizontally, which is suitable for data retrieval but not data mining purposes. On the other hand, vertical databases can achieve both data retrieval and data mining purposes.
MAIN THRUST OF THE ARTICLE
Vertical Databases
In vertical databases, data are stored vertically and processed horizontally through fast, multi-operand logical operations, such as AND, OR, XOR, and complement. Predicate tree (P-tree1) is one of lossless vertical structures that can meet the requirement. P-tree is suitable to represent numerical and categorical data and has been successfully used in OLAP operations (Wang et al., 2003) and various data mining applications, including classification (Khan, Ding, & Perrizo, 2002), clustering (Denton, Ding, Perrizo, & Ding, 2002), and association rule mining (Ding, Ding, & Perrizo, 2002).
A vertical database consists of a set of P-trees rather than a set of relational tables. To convert a relational table of horizontal records to a set of vertical P-trees, the table has to be projected into columns, one for each attribute, retaining the original record order in each. Then each attribute column is further decomposed into separate bit vectors, one for each bit position of the values in that attribute. Figure 1 shows a relational table with three attributes, in which all of the attributes are numeric. Figure 2 shows the decomposition process from the relational table R to a set of bit vectors.
After the decomposition process, each bit vector is then converted into a P-tree. P-trees can be one-dimen- sional, two-dimensional, and multidimensional. If the data has a natural dimension, for instance, spatial data, the P-tree dimension is matched to the data dimension. Otherwise, the dimension can be chosen to optimize the compression ratio. Figure 3 shows the construction of 3 one-dimensional P-trees from the bit vectors of the second attribute A2. They are built by recording the truth of the predicate “purely 1-bits” recursively on halves of the bit vectors until purity is reached.
Figure 1. Relational table R
8
R (A1, A2, A3)
5 |
2 |
7 |
2 |
3 |
2 |
7 |
2 |
2 |
7 |
2 |
5 |
2 |
5 |
5 |
4 |
7 |
1 |
3 |
2 |
1 |
1 |
3 |
4 |
Figure 2. Vertical decomposition of the table R
|
R (A1, A2, A3) |
|
A1 |
A2 |
A3 |
101 |
010 |
111 |
010 |
011 |
010 |
111 |
010 |
010 |
111 |
010 |
101 |
010 |
101 |
101 |
100 |
111 |
001 |
011 |
010 |
001 |
001 |
011 |
100 |
A11 A12 A13 |
A21 A22 A23 |
A31 A32 A33 |
||||||
1 |
0 |
1 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
1 |
0 |
0 |
1 |
0 |
1 |
1 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
0 |
With various built-in engines, such as the query engine, OLAP engine, and data mining engine, vertical databases can be used to accomplish SPJ queries (Ding et al., 2002), OLAP operations (Wang et al., 2003), and various data mining applications. The detailed description of system structure is discussed in the next section.
A System Prototype
As a proof of concept, a prototype system has been developed and tested successfully for scalable data mining on the top of the vertical database concept. The multilayered software framework approach has been taken to design the prototype. The system is formally named as DataMIMETM (Serazi et al., 2004).
The layers of the system include Data Mining Interface (DMI), Data Capture and Data Integration Interface (DCI/DII), Data Mining Algorithm (DMA), and Distributed Ptree Management Interface (DPMI). DMI does counting, the most important operation for data mining provided by P-trees, including basic P-trees, value P-
737
TEAM LinG
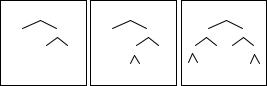
Figure 3. P-trees of attributes A21, A22 and A23
0 |
|
0 |
|
|
|
0 |
|
|
0 |
0 |
1 |
0 |
|
0 |
|
0 |
|
1 |
0 |
0 |
1 |
0 |
0 |
1 |
|
0 |
|
|
0 |
1 |
0 |
1 |
|
0 |
1 |
(a) P21 |
(b) P22 |
(c) P23 |
Vertical Database Design for Scalable Data Mining
perform fast, efficient, and effective data mining on large data sets by organizing data in vertical layouts and conducting logical operations on vertical partitioned data without scanning.
Vertical databases can be easily built in distributed systems to facilitate parallel data mining. With a large enough number of clusters, distributed vertical databases will not only lead to an efficient data mining process, but also solve the curse of high-dimension problem to a great extent.
trees, tuple P-trees, interval P-trees, and cube P-trees. DMI also provides the P-tree algebra, which has four opera- tions—AND, OR, NOT (complement), and XOR—to implement the point-wise logical operations on P-trees for DMA. DCI/DII allows the user to capture and to integrate data to system-required format (P-tree format). The DPMI layer provides access, location, and concurrency transparency by hiding the fact that data representation may differ, resource access protocol may vary, and resources may be located in different places and shared by several competitive users. The DMA layer contains a collection of data mining tools, e.g., P-KNN (Khan et al., 2002), PINE (Perrizo et al., 2003), P-BAYESIAN (Perera, Serazi, & Perrizo, 2002), P-SVM (Pan et al., 2003), and P-ARM (Ding et al., 2002). Besides all those core layers, the system provides a graphical user interface that adds flexible user interaction with the system.
In order to comprehend how the vertical database concept affects the system, there are some key concepts that must be grasped. Unlike traditional databases, data is not stored as horizontal row-based format rather they are stored as compressed vertical P-tree format. The DPMI layer is responsible for storing and managing this P- tree–based vertical data in the system. The efficient bitwise operations on vertical data offer the scalability for data mining algorithms, and these are achieved through the DMI layer. Finally, this uniform, efficient vertical data structure at the lowest layer can take advantage of the latest hardware.
FUTURE TRENDS
Vertical databases will become more and more important as many data sets have become extremely large. Research has shown that scanning the entire data set horizontally to be inefficient and nonscalable. Vertical databases have been exposed to be a scalable methodology that can be used to
CONCLUSION
Horizontal data structure has been proven to be inefficient for data mining on very large sets due to the large cost of scanning. It is of importance to develop vertical data structures and algorithms to solve the scalability issue. Various structures have been proposed, among which P-tree is a very promising vertical structure. This database model is not a set of indexes but is a collection of representations of the data set itself. P- trees have shown great ability to process data containing a large number of tuples due to the fast logical AND operation without scanning (Ding et al., 2002). In general, horizontal data organization is preferable for transactional data with intended output as a relation, and vertical data structure is more appropriate for data mining on very large data sets.
REFERENCES
Batory, D. S. (1979). On searching transposed files.
ACM Transactions on Database Systems, 4(4), 531544.
Chan, C. Y., & Ioannidis, Y. (1998). Bitmap index design and evaluation. Proceedings of the ACM SIGMOD
(pp. 355-366).
Copeland, G., & Khoshafian, S. (1985). Decomposition storage model. Proceedings of the ACM SIGMOD
(pp. 268-279).
Denton, A., Ding, Q., Perrizo, W., & Ding, Q. (2002). Efficient hierarchical clustering of large data sets using P-trees. Proceedings of International Conference on Computer Applications in Industry and Engineering
(pp. 138-141).
Ding, Q., Ding, Q., & Perrizo, W. (2002). Association rule mining on remotely sensed images using P-trees. Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining (pp. 66-79).
738
TEAM LinG

Vertical Database Design for Scalable Data Mining
Han, J., Pei, J., & Yin, Y. (2000). Mining frequent patterns without candidate generation. Proceedings of the ACM SIGMOD (pp. 1-12).
Han, J., & Kamber, M. (2001). Data mining: Concepts and techniques. San Francisco: Morgan Kaufmann.
Khan, M., Ding, Q., & Perrizo, W. (2002). K-nearest neighbor classification on spatial data stream using P-trees.
Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining (pp. 517-528).
O’Neil, P., & Quass, D. (1997). Improved query performance with variant indexes. Proceedings of the ACM SIGMOD (pp. 38-49).
Pan, F., Wang, B., Ren, D., Hu, X., Perrizo, W. (2003). Efficient proximal support vector machine for spatial data.
Proceedings of the International Conference on Computer Applications in Industry and Engineering (pp. 292-297).
Perera, A., Serazi, M., & Perrizo, W. (2002). Performance improvement for Bayesian classification on spatial data with P-trees. Proceedings of International Conference on Computer Applications in Industry and Engineering
(pp. 20-24).
Perrizo, W., Ding, Q., Denton, A., Scott, K., Ding, Q., & Khan, M. (2003). Podium incremental neighbor evaluator for spatial data using P-trees. ACM Symposium on Applied Computing, (pp. 503-508).
Rinfret, D., O’Neil, P., & O’Neil, E. (2001). Bit-sliced index arithmetic. Proceedings of the ACM SIGMOD (pp. 47-57).
Serazi, M., Perera, A., Ding, Q., Malakhov, V., Rahal, I., Pan, F., et al. (2004). DataMIME™. Proceedings of the ACM International Conference on Management of Data
(pp. 923-924).
Shafer, J., Agrawal, R., & Mehta, M. (1996). SPRINT: A scalable parallel classifier for data mining. Proceedings of the International Conference on Very Large Data Bases (pp. 544-555).
Wang, B., Pan, F., Ren, D., Cui, Y., Ding, Q., & Perrizo, W. (2003). Efficient OLAP operations for spatial data using P- trees. Eighth ACM SIGMOD Workshop on Research Issues in Data Mining and Knowledge Discovery (pp. 2834).
Wong, H. K. T., Liu, H.-F., Olken, F., Rotem, D., & Wong, L. (1985). Bit transposed files. Proceedings of the International Conference on Very Large Data Bases (pp. 448457).
Wu, M.-C. (1998). Query optimization for selections us-
ing bitmaps (Tech. Rep. No. DVS98-2, DVS1). Technische 8 Universitat Darmstadt, Computer Science Department.
Wu, M.-C., & Buchmann, A. (1998). Encoded bitmap indexing for data warehouses. Proceedings of IEEE International Conference on Data Engineering (pp. 220230).
KEY TERMS
DataMIMETM: A prototype system that has been designed and implemented on top of vertical database technology and multilayered software framework by DataSURG group at North Dakota State University, USA.
Multilayered Software Framework: A layer-based software environment where each layer is a group of entities dedicated to perform a particular task.
P-Tree Algebra: The set of logical operations, functions, and properties of P-trees. Basic logical operations include AND, OR, and complement.
Predicate Tree (P-tree)1: A lossless tree that is vertically structured and horizontally processed through fast multi-operand logical operations.
Vertical Data Mining: A process of finding pattern and knowledge from data that is organized in vertical structures, which aims to address the scalability issues.
Vertical Database Design: A process of developing a vertical data model, usually with intended data mining functionality that utilizes logical operations for fast data processing.
Vertical Decomposition: A process of partitioning a relational table of horizontal records to separate vertical data files, either to attribute level or bit level, usually retaining the original record order in each.
ENDNOTE
1P-tree is a patent-pending technology developed by Dr. William Perrizo’s DataSURG research group at North Dakota State University.
739
TEAM LinG