

Rivero L.Encyclopedia of database technologies and applications.2006
.pdfBasic Transformations
A mutation is an SR transformation that changes the nature of an object. Considering the three main natures of object, namely, entity type, relationship type, and attribute, six mutation transformations can be defined (Figure 3). Mutations can solve many database engineering problems, but other operators are needed to model special situations.
Figure 3/bottom shows how a supertype/subtype hierarchy can be transformed by representing each source entity type by an independent entity type, then linking each subtype to its supertype through a one-to-one relationship type. The latter can, if needed, be further transformed into foreign keys by application of Σ2-direct (T2). Field studies suggest that about 30 basic operators suffice for most engineering activities.
Higher-Level Transformations
The transformations described so far are intrinsically atomic: One elementary operator is applied to one object instance, and none can be defined by a combination of others. The next sections describe two ways through which more powerful transformations can be developed.
Predicate-Driven Transformations
A predicate-driven transformation Σp applies an operator Σ to all the schema objects that meet a definite predicate p. It is specified by Σ(p), where p is a structural predicate that states the properties through which a class of structures can be identified.
We give in Figure 4 some useful transformations that are expressed in the specific language of the DBMAIN tool (Hainaut, Englebert, Henrard, Hick, & Roland, 1996), which follows the Σ(p) notation.
Most predicates are parametric; for instance, the predicate ROLE_per_RT(<n1> <n2>), where <n1> and <n2> are integers, states that the number of roles of the relationship type falls in the range [<n1>..<n2>]. The symbol “N” stands for infinity.
Model-Driven Transformations
A model-driven transformation is a goal-oriented chain of predicate-driven operators. It is designed to transform any schema expressed in model M into an equivalent schema in model M’.
Identifying the components of a model also leads to identifying the constructs that do not belong to it. An arbitrary schema S expressed in M may include con-
Transformation-Based Database Engineering
Figure 4. Three examples of predicate-driven transformations.
predicate-driven transformation |
interpretation |
|
RT_into_ET(ROLE_per_RT(3 N)) |
Transform each relationship type R into an |
|
|
entity type (RT_into_ET), if the number of |
|
|
roles of R (ROLE_per_RT) is in the range [3 |
|
|
N]; in short, convert all N-ary relationship |
|
|
types into entity types. |
|
RT_into_REF(ROLE_per_RT(2 2) and |
Transform each relationship type R into |
|
ONE_ROLE_per_RT(1 2)) |
reference attributes (RT_into_ET), if the |
|
number of roles of R is 2 and if R has from 1 |
||
|
||
|
to 2 one role(s), i.e., R has at least one role |
|
|
with max cardinality 1; in short, convert all |
|
|
one-to-many relationship types into foreign |
|
|
keys. |
|
INSTANTIATE(MAX_CARD_of_ATT(2 4)) |
Transform each attribute A into a sequence of |
|
|
single-value instances, if the max cardinality |
|
|
of A is between 2 and 4; in short, convert |
|
|
multivalued attributes with no more than 4 |
|
|
values into serial attributes. |
structs which violate M’. Each class of constructs that can appear in a schema can be specified by a structural predicate. Let PM denote the set of predicates that defines model M and PM’ that of model M’. In the same way, each potentially invalid construct can be specified by a structural predicate. Let PM/M’ denote the set of the predicates that identify the constructs of M that are not valid in M’. In the DB-MAIN language used in Figure 4, ROLE_per_RT(3 N) is a predicate that identifies N- ary relationship types that are invalid in DBTG CODASYL databases, while MAX_CARD_of_ATT(2 N) defines multivalued attributes that are invalid in the SQL2 database model. Finally, we observe that PM can be perceived as a single predicate formed by anding its components.
Let us now consider predicate p PM/M’, and let us choose a transformation Σ = <P,Q> such that:
(p P) (PM’ Q)
Clearly, the predicate-driven transformation Σp solves the problem of invalid constructs defined by p. Proceeding in the same way for each component of PM/ M’ provides us with a chain of operators that can transform any schema in model M into a schema in model M’. We express such a chain through a transformation plan, which is the practical form of any model-driven transformation.
If a plan comprises SR properties only, then the model-driven transformation that it implements is symmetrically reversible. When applied to any source schema, it produces a target schema semantically equivalent to the former. Figure 5 sketches a simple transformation plan intended to produce SQL2 logical schemas from ERA conceptual schemas. Actual plans are more complex but follow this approach.
710
TEAM LinG
Transformation-Based Database Engineering
Figure 5. A simple transformation plan to derive a relational schema from any ERA conceptual schema. To make them |
|
|||||||
6 |
||||||||
more readable, the transformations have been expressed in natural language instead of in the DB-MAIN language. |
||||||||
|
|
|
|
|
|
|||
|
|
|
|
|
|
|||
|
step |
predicate-based |
comment |
|
|
|||
|
|
transformation |
|
|
|
|||
|
1 |
Transform IS-A relations into |
Operator Σ4-direct. |
|
|
|||
|
|
one-to-one rel-types. |
|
|
|
|
||
|
2 |
Transform complex rel-types |
Operator Σ1-direct; complex means N-ary or |
|
|
|||
|
|
into entity types. |
|
binary many-to-many or with attributes. |
|
|
||
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|||
|
3 |
Disaggregate level-1 compound |
Each compound attribute directly depending on |
|
|
|||
|
|
attributes. |
|
|
an entity type is replaced by its components. |
|
|
|
|
|
|
|
|
|
|||
|
4 |
Transform level-1 multivalued |
Operator Σ3-direct; each multivalued attribute |
|
|
|||
|
|
attributes into entity types. |
directly depending on an entity type is replaced |
|
|
|||
|
|
|
|
|
|
|
||
|
|
|
|
|
by an entity type. |
|
|
|
|
|
|
|
|
|
|||
|
5 |
Repeat steps 3 to 4 until the |
To cope with multilevel attribute structures. |
|
|
|||
|
|
schema |
does not |
include |
|
|
|
|
|
|
complex attributes anymore. |
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
6 |
Transform |
relationship |
types |
At this point, only one-to-many and one-to-one |
|
|
|
|
|
into reference groups. |
|
rel-types subsist; they are transformed into |
|
|
||
|
|
|
|
|
foreign keys (Σ2-direct). |
|
|
|
|
|
|
|
|
|
|||
|
7 |
If the schema still includes rel- |
Step 6 fails in case of missing identifier; a |
|
|
|||
|
|
types, add a technical identifier |
technical attribute is associated with the entity |
|
|
|||
|
|
to the relevant entity types and |
type that will be referenced by the future foreign |
|
|
|||
|
|
apply step 6. |
|
key. |
|
|
||
|
|
|
|
|
|
|
|
|
Figure 6. Transforming a conceptual schema into a SQL2-compliant logical schema through the plan of Figure 5.
|
PERSON |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
PERSON |
|
|
ATTENDED |
|
|||
|
PID |
|
|
|
|
|
|
attended |
|
|
|
|
|
PID |
|
|
SchoolName |
|
|||||||
|
|
0-N |
|
|
|
|
|||||||||||||||||||
|
Name |
|
|
|
|
|
Name |
|
|
PID |
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
id: PID |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
id: PID |
|
|
id: SchoolName |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
TEACHER |
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
PID |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0-N |
|
|
|
PID |
|
|
TEACH |
|
ref: PID |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
DateHired |
|
|
|
ref: SchoolName |
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
SchoolName |
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
id: PID |
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
SCHOOL |
|
|
ref |
|
|
FromDate |
|
|
|
|||||
|
TEACHER |
|
|
|
|
SchoolName |
|
|
|
|
|
PID |
|
SCHOOL |
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
DateHired |
|
|
|
|
Address |
|
|
|
|
|
id: SchoolName |
|
SchoolName |
|
|||||||||||
Competence[0-N] |
|
|
|
|
|
|
|
|
|
|
|
COMPETENCE |
|
ref |
|
Address |
|
||||||||
|
|
|
|
id: SchoolName |
|
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
PID |
|
ref: PID |
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
id: SchoolName |
|
|||||
|
|
|
|
|
|
|
teach |
|
|
|
|
|
|
|
Competence |
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
id: PID |
|
|
|
|
|
|
|||||
|
|
0-N |
|
|
|
|
|
0-1 |
|
|
|
|
|
|
|||||||||||
|
|
|
|
FromDate |
|
|
|
|
|
|
Competence |
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ref: PID |
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Figure 6 shows the application of this plan to a small ERA schema. Though model-driven transformations provide an elegant and powerful means of specification of many aspects of most database engineering processes, some other aspects still require human expertise that cannot be translated into formal rules.
NEW PERSPECTIVES FOR
DATABASE ENGINEERING
PROCESS MODELLING
The transformational approach provides us with an elegant paradigm through which standard and nonstandard engineering processes can be revisited and built.
Transformation-Based
Database Design
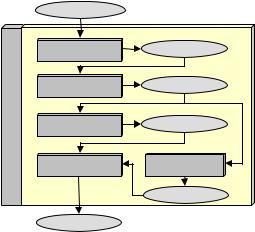
Figure 7 describes the standard approach to database design as the transformation of users’ requirements into DDL code. This transformation itself comprises five processes that, in turn, are transformations. Ignoring the view design process for simplicity, database design can be modelled by (the structural part of) transformation
DB-design:
DDL-code = DB-design(Users-requirements)
711
TEAM LinG
Transformation-Based Database Engineering
Figure 7. The standard strategy for database design |
CONCLUSION |
|
Users requirements |
|
|
Conceptual design |
Conceptual schema |
design |
Logical design |
Logical schema |
Database |
Physical design |
Physical schema |
|
||
|
Coding |
View design |
|
|
Users views |
|
DDL code |
|
We can refine this expression as follows:
Conceptual-schema =Conceptual-design(Users-require- ments)
Logical-schema = Logical-design(Conceptual-schema) Physical-schema = Physical-design(Logical-schema) DDL-code = Coding(Physical-schema)
Clearly, all these processes are model-driven transformations and can then be described by transformation plans. The level of formality of these processes depends on the methodology, on the availability of a CASE tool, and on nonfunctional requirements, such as performance and robustness, that generally require human expertise. For instance, conceptual design is a highly informal process based on human interpretation of complex information sources, while logical design can be completely described by a transformation plan (such as that of Figure 5 for relational databases). Anyway, these processes can be decomposed into subprocesses, which, in turn, can be modelled by transformations and described by transformation plans, and so forth, until the latter is reduced to elementary operators.
Transformation-Based Database
Reverse Engineering
Modelling database design in this way provides us with an elegant basis to describe database reverse engineering. Indeed the latter can be perceived to be the inverse of database design. An in-depth analysis of reverse engineering can be found in Hainaut (2002).
In this article, we have shown that schema transformations can be used as a major paradigm in database engineering. In particular, being formally defined, it can be used to precisely model complex processes and to reason on their properties such as semantics preservation. It has also been used to derive new processes from former ones, as illustrated by the formalization of database reverse engineering as the inverse of database design.
Due to their formality, transformations can be implemented in CASE tools, either as implicit operators or as tools that are explicitly made available to the developer. Two implementations are worth being mentioned, namely, Rosenthal and Reiner (1994) and Hainaut et al. (1996). The latter reference describes the DB-MAIN CASE environment, which includes a transformation toolbox as well as special engines for user-defined predicate-driven and model-driven transformations. Further information can be found at http://www.info.fundp.ac.be/libd.
Transformations also have a great potential in other domains such as database interoperability, in which mediation between existing databases (McBrien & Poulovassilis, 2003) and data wrapping (Thiran & Hainaut, 2001) can be formalized and automated through transformational operators. In this domain, data instance transformations are modelled by the t part of the transformations. Specifying how the source schema is transformed into the target schema automatically provides a chain of instance transformations that are used to generate the data conversion code that is at the core of data migrators (ETL processors), wrappers, and mediators.
REFERENCES
Balzer, R. (1981). Transformational implementation: An example. IEEE TSE, SE-7(1).
Casanova, M., & Amaral De Sa, A. (1984). Mapping uninterpreted schemes into entity-relationship diagrams: Two applications to conceptual schema design. IBM Journal of Research & Development, 28(1).
Fikas, S. F. (1985). Automating the transformational development of software. IEEE TSE, SE-11.
Hainaut, J.-L. (1995, September). Transformation-based database engineering. VLDB’95 Tutorial notes. University of Zürich, Switzerland. Retrieved from http:// www.info.fundp.ac.be/libd
Hainaut, J.-L. (1996). Specification preservation in schema transformations: Application to semantics and statistics.
Data & Knowledge Engineering, 11(1).
712
TEAM LinG

Transformation-Based Database Engineering
Hainaut, J.-L. (2002). Introduction to database reverse engineering In LIBD lecture notes, University of Namur, Belgium. Retrieved Sept 2004 from http://www.info.fundp.ac.be/ ~dbm/publication/2002/DBRE-2002.pdf
Hainaut, J.-L., Chandelon, M., Tonneau, C., & Joris, M. (1993). Contribution to a theory of database reverse engineering. In Proceedings of the IEEE Working Conference on Reverse Engineering, Los Alamitos, CA (pp. 161170). IEEE Computer Society Press.
Hainaut, J.-L., Englebert, V., Henrard, J., Hick, J.-M., & Roland, D. (1996). Database reverse engineering: From requirements to CASE tools. Journal of Automated Software Engineering, 3(1).
Halpin, T. A., & Proper, H. A. (1995). Database schema transformation and optimization. In Proceedings of the 14th International Conference on ER/OO Modelling (ERA) ( Vol. 1021, pp. 191-203). Berlin/Heidelberg, Germany: Springer LNCS.
Jajodia, S., Ng, P. A., & Springsteel, F. N. (1983). The problem of equivalence for entity-relationship diagrams.
IEEE TSE, SE-9(5).
Kobayashi, I. (1986). Losslessness and semantic correctness of database schema transformation: Another look of schema equivalence. Information Systems, 11(1), 41-59.
McBrien, P., & Poulovassilis, A. (2003). Data integration by bi-directional schema transformation rules. In Proceedings of the 19th International Conference on Data Engineering (ICDE’03), Los Alamitos, California (pp. 227-238). IEEE Computer Society Press.
Navathe, S. B. (1980). Schema analysis for database restructuring. ACM TODS, 5(2).
Omelayenko, B., & Klein, M. (Eds.). (2003). Knowledge transformation for the Semantic Web. Amsterdam, The Netherlands: IOS Press.
Partsch, H., & Steinbrüggen, R. (1983). Program transformation systems. Computing Surveys, 15(3).
Rauh, O., & Stickel, E. (1995). Standard transformations for the normalization of ER schemata. In Lecture notes in computer science. Proceedings of the CAiSE95 Conference (Vol. 932, pp. 313-326). Berlin/Heidelberg, Germany: Springer-Verlag.
Rosenthal, A., & Reiner, D. (1994). Tools and transforma- tions—rigourous and otherwise—for practical database design. ACM TODS, 19(2).
Thiran, P., & Hainaut, J.-L. (2001). Wrapper development for legacy data reuse. In Proceedings of WCRE’01, Los Alamitos, CA (pp. 198-207). IEEE Computer Society Press.
van Bommel, P. (Ed.). (2004). Transformation of knowl-
edge, information and data: Theory and applications. 6
Hershey, PA: Idea Group.
KEY TERMS
Inverse Transformation: Considering schema transformation Σ, the transformation Σ’ is the inverse of Σ if its application undoes the result of the application of Σ. The instance mapping of Σ’ can be used to undo the effect of applying the instance mapping of Σ on a set of data.
Model-Driven Transformation: A goal-oriented chain of transformations made up of predicate-driven operators. It is designed to transform any schema expressed in model M into an equivalent schema in model M’.
Mutation Transformation: A schema transformation that changes the nature (entity type, relationship type, attribute) of a schema construct. For instance, an entity type is transformed into a relationship type and conversely.
Predicate-Driven Transformation: A couple <Σ,p> where Σ is a schema transformation and p a structural predicate that identifies schema patterns. The goal of a predicate-based transformation is to apply Σ to the patterns that meet p in the current schema.
Schema Transformation: A transformation is a rewriting rule through which the instances of some pattern of an abstract or concrete specification are replaced with instances of another pattern. The concept also applies to database schemas where the rewriting rule replaces a set of constructs of a database schema with another set of constructs. Such a transformation comprises two parts—a schema rewriting rule (structural mapping) and a data conversion rule (instance mapping). The latter transforms the data according to the source schema into data complying with the target schema.
Semantics-Preserving Transformation: A schema transformation that does not change the information contents of the source schema. Both schemas describe the same universe of discourse.
Transformational Software Engineering: A view of software engineering through which the production and evolution of software can be modelled, and practically carried out, by a chain of transformations which preserve some essential properties of the source specifications. Program compiling but also transforming tail recursion into an iterative pattern are popular examples. This approach is currently applied to software renovation, reverse engineering, and migration.
713
TEAM LinG
714
Ubiquitous Computing and Databases
George Roussos
University of London, UK
Michael Zoumboulakis
University of London, UK
INTRODUCTION
The concept of the so-called ubiquitous computing was introduced in the early 1990s as the third wave of computing to follow the eras of the mainframe and the personal computer. Unlike previous technology generations, ubiquitous computing recedes into the background of everyday life:
It activates the world, makes computers so imbedded, so fitting, so natural, that we use it without even thinking about it, and is invisible, everywhere computing that does not live on a personal device of any sort, but is in the woodwork everywhere. (Weiser & Brown, 1997, p. 81)
Ubiquitous computing is often referred to using different terms in different contexts. Pervasive, 4G mobile, and sentient computing or ambient intelligence also refer to the same computing paradigm. Several technical developments come together to create this novel type of computing; the main ones are summarized in Table 1 (Davies & Gellersen 2002; Satyanarayanan 2001).
BACKGROUND
One of the major challenges in turning the ubiquitous computing vision into reality is the development of distributed system architectures that will support effectively and efficiently the ability to instrument the physical world (Estrin et al., 2002; National Research Council, 2001). Such architectures are being developed around two core concepts: self-organizing networks of embedded devices with wireless communication capabilities and data-centricity. To augment physical artifacts with computational and communications capabilities, it is necessary to enable miniaturized hardware components capable of wireless communication. However, these same characteristics that allow for instrumentation of physical objects also impose significant constraints. Systems architectures require significant changes due to the severely limited resources available on these
devices. One possible solution is offered by the emergence of data-centric systems. In this context, datacentric refers to in-network processing and storage, carried out in a decentralized manner (Estrin et al., 2000).
One objective of data-centricity is to let systems exploit the anticipated high node densities to achieve longer unsupervised operating lifetimes. Indeed, smaller form factor wireless sensor nodes have limited resources and often cannot afford to transfer all the collected data to the network edge and forward to centralized information processing systems. A practical example of the data-centric approach for network routing is directed diffusion (Intanagonwiwat, Govindan & Estrin, 2000). This mechanism employs in-network processing by routing data along aggregation paths, thus, removing the need for an address-centric architecture. It exploits data naming as the lowest level of system organization and supports flexible and efficient in-network processing.
In summary, databases have a dual role to play in ubiquitous computing: in the short term, they need to provide the mapping between physical and virtual entities and space in a highly distributed and heterogeneous environment. In the longer term, database management systems need to provide the infrastructure for the development of data-centric systems. Each of the two phases is discussed in turn in the following sections.
DATABASES IN UBIQUITOUS COMPUTING
As noted earlier, a key requirement of ubiquitous computing is the use of contextual information to adapt system behavior on-the-fly and deliver services that fit the specific user situation, a feature that has become known as context-awareness (Abowd & Mynatt, 2000). Context-aware systems need to combine three elements: details of the physical environment must be sourced from embedded sensors, user profiles must be retrieved from distributed repositories holding fragments of identity information, and these data must be correlated to a domain-specific knowledge model that can be used to
Copyright © 2006, Idea Group Inc., distributing in print or electronic forms without written permission of IGI is prohibited.
TEAM LinG

Ubiquitous Computing and Databases
Table 1. Elements of ubiquitous computing
7
1. Physical and Virtual Integration
Sensing
Information gathering in the physical world and its representation in the virtual world
Actuation
Decisions in the virtual world and their tangible results in the physical world
Awareness and Perception
Using sensed data to maintain a higher level model of the physical world and argue about it
Ambient Displays
Display information from the virtual world on physical artifacts
World Modeling
Representations of physical spaces
2. System Components
Platforms
Mobile, wearable or implantable hardware devices with small form factor
Sensors and Actuators
Hardware and software platforms for sensing and actuation
Software Architectures
Adaptable, large scale, complex software infrastructures and development
Connectivity
High-speed, low power wired and wireless communications systems
3. Deployment
Scalability
System adaptation to cater for massive scale in terms of space, devices, and users
Reliability
Security and redundancy technologies for continuous operation
Maintenance
Structured maintenance processes for reliability and updates
Evaluation
Methods to evaluate the effectiveness of information systems outside the laboratory
reason about the specific situation. In these circumstances, databases must support two aspects of the virtual-physical integration: on the one hand, provide mappings between physical artifacts and associated digital resources and, on the other, hold profile, historical, and state data. This functionality is best illustrated in a case study, for example, ubiquitous retail (Kourouthanassis & Roussos, 2003).
Database Systems Challenges
The introduction of ubiquitous computing technologies in a retail environment can help develop a number of novel applications that can transform the shopping experience and at the same time create value for retailers. Some of the possibilities that appear attractive to consumers include the smart shopping cart, in-store navigational assistance, shelf displays, and offers and promotions targeted to the individual. At the same time, retailers can use these applications to gather data to help optimize the supply chain and increase profit margins, while at the
same time improving consumer satisfaction. A core ingredient for such ubiquitous retail systems is the augmentation of consumer products with information processing capabilities and the development of supporting infrastructures.
To this end, several new technologies have been recently introduced. The Electronic Product Code (EPC) is a globally unique identifier that is attached to a particular product item stored in a radio frequency identification (RFID) tag. Unlike barcodes that are used to identify product classes, the EPC distinguishes a particular product instance, for example a specific can of cola rather the class of cola cans, and may be used to trace additional information about it. This information is retrieved by querying the Object Naming Service (ONS), which matches the EPC to the production server that holds information about the item in Product Markup Language (PML), for example, its ingredients and date of production (Mealling, 2003). Using these technologies, a smart shopping cart will identify the products placed into it using the EPC, retrieve additional information about the
715
TEAM LinG
product via ONS and PML, and provide personalized feedback to the consumer. For example, product information can be checked against the user profile retrieved from the consumer’s identity management service provider for specific medical counter indications, for example, lactose intolerance.
This example highlights some of the immediate challenges of ubiquitous computing for database technology. Firstly, database management must address the demands of a highly heterogeneous environment, both from a technical and an organizational point of view. Indeed, data resources are highly geographically distributed, and different service providers control access to specific segments of the data space. Moreover, data generation and query insertion may move rapidly from one location to another to the extend that almost every object in the system is transient. Finally, these requirements put novel demands on system architectures, and we will discuss each of these issues in turn in the remainder of this section.
Ubiquitous computing databases need to cater for the physical distribution of data production, data consumption, and data storage over wide geographic regions. Indeed, geographic distribution affects both data sources and applications, which are mobile to a very high degree. In the ubiquitous retail scenario introduced previously, a product item, for example, a single can of cola, is a data source that may travel thousands of miles from its production plant until consumed and discarded. In the same scenario, consumers would wish to access personalized information services irrespective of their location in the world.
In addition to geographic distribution, ubiquitous computing infrastructures are also logically distributed since they integrate multiple independently controlled components and subsystems. It is not rare that one subsystem may be in operation in some form for decades but would still have to interoperate with newly developed technologies. For example, the shopping cart application discussed earlier retrieves data from the user’s identity management service provider, the ONS system, the manufacturer PML servers, and the retailer databases and still has to perform without significant delays for the user while also providing up-to-date information. This data source heterogeneity demands that management and acceleration architectures must adapt to accommodate application requirements.
Further, the origin of a particular query may also have considerable impact on the organization and performance of a distributed query-processing architecture. To be sure, distribution of queries and the rate at which they are initiated will affect system performance. For example, reading the EPC of a new item placed inside a smart shopping cart will generate a new query to the PML server at the rate at which the consumer adds new items in the cart. To improve performance, some systems may
Ubiquitous Computing and Databases
correlate data distribution with query distribution to control their overhead. Alternatively, systems may restrict the set of available queries and thus limit their impact on system throughput. One solution to this problem is the construction lower-cost overlay networks for processing queries. Such overlays, currently referred to as service-oriented architectures, allow for data sources and sinks to connect to the system via the closest access point.
Ubiquitous computing devices will also typically communicate over unreliable networks. Thus, failure should be a feature of the system and should be taken into account in designing appropriate query-processing architectures. For example, all objects in the database may be persistent so that when a client reconnects to the network, the system may replicate the object closer to the new location of the client and thus reduce latency. This feature would also support correlation of application queries and the data they carry, as is the case of a client that initiates a specific query for data but also becomes a source for the data after the query is satisfied.
Finally, developing optimized architectures for ubiquitous computing systems requires a better understanding of typical workload patterns. Consider the case of the smart shopping cart, which generates data and queries for data. In a realistic scenario of a supermarket chain, the pattern of the generated workload is rather unique and would induce considerable stress on existing database system architectures primarily due to the high utilization of scarce resources. Because of the limited experience we have with realistic workloads, it may be inappropriate to optimize systems architectures. At the same time, the stress that ubiquitous computing systems will put on public resources, for example, the ONS, will demand that massively distributed infrastructures are developed at a scale orders of magnitude larger to that available today.
Sensor Databases
A particularly important development for databases in ubiquitous computing is the emergence of the socalled sensor and actuator databases. Recent advances in micro-electro-mechanical systems (MEMS) and wireless communication, coupled with significant improvements in electronics manufacturing processes have enabled the development of low-cost, low-power, multi-functional sensor and actuator nodes (Akyildiz et al., 2002). Such nodes are small in size and can communicate untethered in relatively short distances, and thus it has become practical for these devices to be embedded into an increasing range of physical artifacts. Moreover, sensor and actuator nodes can be linked together in dense, self-configurable, and adaptively co-
716
TEAM LinG

Ubiquitous Computing and Databases
ordinated networks, often called sensor and actuator networks. These systems are also referred to as Smart Dust, wireless networks of sensors and actuators, motes, embedded wireless networks, or smart-its. The name Smart Dust seems to have particular appeal with the term dust justified on the basis that many of these nodes are expected to be less than one cubic millimeter in volume (currently 2.5mm3 sensors are in production, with 0.15mm3 nodes in laboratory testing).
Because individual nodes are embedded in objects, sensor and actuator networks are tightly coupled to the physical world. In this sense, they represent a realization of ubiquitous computing’s Holy Grail to provide a “connection of things in the world with computation” (Weiser, 1991). Although the same goal can be achieved using alternative technologies, sensors and actuators offer a competitive candidate for the deployment of ubiquitous, self-organizing networks of artifacts. Indeed, their cost and performance characteristics combined with their in- frastructure-free operation, and their low or no dependence on supporting computational and communications fabric offers distinct advantages in deployment and operation.
Yet, such flexibility does not come without constraints. Sensor and actuator nodes are also highly resource constrained and often create massively concurrent, complex, networked, computational systems. Moreover, they are integrated into objects and systems that are likely to function for long periods of time unsupervised and used by individuals who are not technology experts. Finally, they assemble information processing and communication systems with significantly greater size and scale compared to those that exist today.
Sensor and actuator networks operate unsupervised with individual nodes making decisions independently in a decentralized manner. Applications frequently operate in one of either modes:
1.In event-driven applications, for example, detection of forest fires, the system remains inactive until an event is generated in one of the nodes. Then, the event propagates through the system and causes the activation of appropriate behavior.
2.In demand-driven applications, for example, inventory tracking, activity is initiated in response to external requests, usually in the form of queries.
Both cases include a data transmission step, which may be either proactive or reactive. That is, data transmission may be in response to a particular query inserted to the network by an external device or it may be triggered by a condition that is checked at a particular node subset inside the network itself. Furthermore, in both cases,
system behavior is defined in terms of high-level state-
ments of logical interests over the entire network, and 7 they might be represented either in an appropriate query definition language (Gehrke & Madden, 2004) or as event- condition-action triplets (Zoumboulakis, Roussos & Poulovassilis, 2004).
In the traditional embedded software development model, each node would be treated as a separate computational unit and programmed in a C-derived language. This model cannot be effectively extended to sensor and actuator networks where there is a clear need of a higher-level language to define system behavior in terms of a more amenable programming framework. To this end, query processing has attracted considerable interest and is rapidly becoming a popular computational paradigm for a plethora of sensor network applications. This approach has been seen to address well the complex requirements of application development in sensor networks in a variety of applications including environmental monitoring, distributed mapping, and vehicle tracking. Prototype sensor network query processors have been implemented in Tiny DB (Madden et al., 2003) and Cougar (Yao & Gerhke, 2002) systems. A second database technology that provides an appropriate computational model for event-based sensor and actuator network applications is event-condition-action (ECA) rules (Zoumboulakis, Roussos & Poulovassilis, 2004).
Both technologies viewed as a computational paradigm for sensor and actuator networks are successful in freeing developers from lower level concerns by transferring responsibility of data management, collection, and processing to the system (Bonnet, Gehrke & Seshadri, 2001). Despite their early successes, there are still several challenges associated with the design and development of such sensor databases:
•Node resource management: Sensor and actuator nodes are resource-constrained, and any system should carefully manage their consumption, especially power. Communication and sensing tend to dominate demands on the battery while computation places a relatively lower burden.
•Network topology management: Sensor and actuator networks have a fundamentally transient nature due to moving nodes, signal degradation, changing interference patterns, and nodes running out of power.
•Data aggregation: Due to the high cost of communication and the possible very high data collection rates, it is desirable to summarize or abstract the recorded data as they propagate through the network. For example, decomposable operators may be
717
TEAM LinG
computer in the fly by intermediate nodes and only the aggregates forwarded.
•Simple and expressive language: To preserve node resources, the query or the ECA language used to interact with the sensor network should be simple enough to support a lightweight implementation and expressive enough to be useful in building applications.
•Management tools: In addition to an appropriate conceptual framework, a system becomes useful when it also offers a collection of tools to assist users in management and interaction.
One implication of these requirements is that it is often necessary for the nodes to perform collaborative signal processing to effectively analyze the sensed data (Estrin, Govidan et al., 1999). Furthermore, the high probability of node failures implies that sensor data will be noisy, and thus managing sensor data uncertainty should be adequately addressed. Another critical concern is the designing of efficient routing mechanisms that cater for the particular requirements of query processing and reactive functionality. As a result, it is often necessary to develop database systems that bypass the traditionally distinct network layers.
A further implication is that query dissemination or corresponding construction of an event channel for ECA rule execution often requires two phases. First is the preprocessing of a routing tree that defines the pathways along which data travels. This routing tree is constructed online as nodes forward notifications to their selected neighbors in the network. When signals are generated at sensor nodes, the recorded data is possibly aggregated with information received by other sensors and subsequently forward to parent nodes until data reaches its intended destination. The details of such routing algorithms are beyond the scope of this article, but the interested reader may consult Gherke and Madden (2004) for full details.
FUTURE TRENDS
In the next decade, databases employed in support of ubiquitous computing systems will be extended to cater for geographically decentralized operation, both in terms of data generation and application access, the transient nature of ubiquitous computing objects and entities, the fundamentally heterogeneous nature of such a system, and the need for correlation and coordination of physical and virtual resources. New systems architectures will be developed to support ubiquitous computing systems and the novel workloads they bring with them.
Ubiquitous Computing and Databases
A particularly interesting ubiquitous computing system that is expected to attract considerable interest over the next years is sensor databases. Sensor databases consist of numerous tiny embedded computing devices capable of wireless communication. Such systems have extremely limited resources and must take advantage of in-network processing and storage to survive for longer periods of time. Database management systems for sensor network offer distinct advantages from a user interaction perspective but also face considerable challenges for efficient system operation.
CONCLUSION
Ubiquitous computing offers the promise of pervasive information and communications infrastructures that provide their services whenever required while taking into account the particular context of the user. Ubiquitous computing also blurs the boundaries between the physical and the virtual worlds through sensing and actuation technologies. To realize this vision, developments in several technical areas are required, and database management systems have a critical role to play in supporting ubiquitous computing services.
REFERENCES
Abowd, G., & Mynatt, E. (2000). Charting past, present, and future research in ubiquitous computing. ACM Transactions on Computer-Human Interaction, 7(1), 29-58.
Akyildiz, I.F., Su, W., Sankarasubramaniam, Y., & Cayirci, E. (2002). Wireless sensor networks: A survey. Computer Networks, 38, 393-422.
Bonnet, P., Gehrke, J.E., & Seshadri, P. (2001). Towards sensor database systems. Proceedings of the 2nd International Conference on Mobile Data Management, Hong Kong, China, January.
Davies, N., & Gellersen, H. (2002). Beyond prototypes: Challenges in deploying ubiquitous systems. IEEE Pervasive Computing, 1(1), 29-35.
Estrin, D., Culler, D., Pister, K., & Sukhatme, G. (2002). Connecting the physical world with pervasive networks.
IEEE Pervasive Computing, 1(1), 59-69.
Estrin, D., Govindan, R., Heidemann, J., & Kumar, S. (1999). Next century challenges: Scalable coordination in sensor networks. Proceedings of the ACM/IEEE International Conference on Mobile Computing and Networking (pp. 263-270). Seattle, Washington.
718
TEAM LinG

Ubiquitous Computing and Databases
Gehrke, J., & Madden, S. (2004). Query processing in sensor networks. IEEE Pervasive Computing, 3(1), 46-55.
Intanagonwiwat, C., Govindan, R., & Estrin, D. (2000). Directed diffusion: A scalable and robust communication paradigm for sensor networks. Proceedings of the 6th Annual International Conference on Mobile Computing and Networking (MobiCOM’00), Boston, August.
Kourouthanassis, P., & Roussos, G. (2003). Developing consumer-friendly pervasive retail systems. IEEE Pervasive Computing, 2(2), 32-39.
Madden, S., Franklin, M.J., Hellerstein, J.M., & Hong, W. (2003). The design of an acquisitional query processor for sensor networks. Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data (pp. 491-502), San Diego, California.
Mealling, M. (2003). Object name service (ONS) 1.0.
Auto-ID Center, Boston.
National Research Council. (2001). Embedded, everywhere: A research agenda for networked systems of embedded computers. National Academy Press, Washington DC, USA.
Satyanarayanan, M. (2001). Pervasive computing: Vision and challenges. IEEE Personal Communications, 8(4), 10-17.
Weiser, M. & Brown, J.S. (1997). The coing age of calm technology. In P. Denning, R.M. Metcalf (Eds.), Beyond calculation (pp. 75-85).
Yao, Y., & Gehrke, J.E. (2002). The cougar approach to innetwork query processing in sensor networks. Sigmod Record, 31(3).
Zoumboulakis, M., Roussos, G., & Poulovassilis, A. (2004).
Asene: Active sensor networks. Proceedings of the International Workshop on Data Management for Sensor Networks (VLDB 2004), Toronto, Canada, August 30.
KEY TERMS
Data Aggregation: The process in which information is gathered and expressed in a summary form. In case the aggregation operator is decomposable, partial aggregation schemes may be employed in which intermediate results are produced that contain sufficient information to compute the final results. If the aggregation operator is non-decomposable, then partial aggregation schemes can still be useful to provide approximate summaries.
In-Network Processing: A technique employed in sensor database systems whereby the data recorded is 7 processed by the sensor nodes themselves. This is in contrast to the standard approach, which demands that
data is routed to a so-called sink computer located outside the sensor network for processing. In-network processing is critical for sensor nodes because they are highly resource constrained, in particular, in terms of battery power, and this approach can extend their useful life quite considerably.
Sensor and Actuator Networks: An ad-hoc, mobile, wireless network consisting of nodes of very small size either embedded in objects or freestanding. Some nodes have sensing capabilities, which frequently include environmental conditions, existence of specific chemicals, motion characteristics, and location. Other nodes have actuation capabilities; for example, they may provide local control of mechanical, electrical, or biological actuators and optical long-range communications.
Sensor Databases: The total of stored sensor data in a sensor and actuator networked is called a sensor database. The data contain metadata about the nodes themselves, for example, a list of nodes and their related attributes, such as their location, and sensed data. The types and the quantity of sensed data depends on the particular types of sensors that participate in the network.
Sensor Query Processing: Sensor query processing is the design of algorithms and their implementations used to run queries over sensor databases. Due to the limited resources of sensor and actuator nodes query processing must employ in-network processing and storage mechanisms.
Service-Oriented Architectures: A service is an information technology function that is well defined, self-contained, and does not depend on the context or state of other services. A service-oriented architecture is an approach to building information technology systems as a collection of services which communicate with each other. The communication may involve either simple data passing between services, or it could involve infrastructure services which coordinate service interaction. SOA is seen as a core component of ubiquitous computing infrastructures.
Ubiquitous Computing: A vision of the future and a collection of technologies where information technology becomes pervasive, embedded in the everyday environments and thus invisible to the users. According to this vision, everyday environments will be saturated by computation and wireless communication capacity, and yet they would be gracefully integrated with human users.
719
TEAM LinG