

Rivero L.Encyclopedia of database technologies and applications.2006
.pdfBreibart, Y., Garcia-Molina, H., & Silberschatz, A. (1992). Overview of multidatabase transaction management. VLDB Journal, 2, 181-239.
Franaszek, P., & Robinson, J. (1985). Limitations in concurrency in transaction processing. ACM TODS, 10(1).
Frank, L. (1999). Evaluation of the basic remote backup and replication methods for high availability databases.
Software - Practice & Experience, 29(15), 1339-1353.
Frank, L. (2004). Transaction design for databases with high performance and availability. Journal of Informaiton and Organizational Sciences, 28(1-2), 41-47.
Frank, L., & Kofod, U. (2002). Atomicity implementation in e-commerce systems. Proceedings of the Second International Conference on Electronic Commerce,Taipei, Taiwan, Republic of China.
Frank, L., & Zahle, T. (1998). Semantic ACID properties in multidatabases using remote procedure calls and update propagations. Software - Practice & Experience, 28, 77-98.
Garcia-Molina, H., & Salem, K. (1987). Sagas. Proceedings of the ACM SIGMOD Conference (pp. 249-259).
Gray, J., & Reuter, A. (1993). Transaction processing. Morgan Kaufman.
Hadzilacos, V., & Toueg, S. (1993). Fault-tolerant broadcasts and related problems. In S. Mullender (Ed.), Distributed systems (pp. 97-145). Addison-Wesley.
Kempster, T., Stirling, C., & Thanisch, P. (1999). Diluting ACID properties. SIGMOD Record, 28(4).
Mehrotra, S., Rastogi, R., Korth, H., & Silberschatz, A. (1992). A transaction model for multi-database systems. Proceedings of the International Conference on Distributed Computing Systems (pp. 56-63).
O’Neil, P. (1986). The escrow transaction mode. ACM TODS, 11(4).
Thomasian, A. (1998). Concurrency control: Methods, performance, and analyses. ACM Computing Surveys, 30(1).
Weikum, G., & Schek, H. (1992). Concepts and applications of multilevel transactions and open nested transactions. In A. Elmagarmid (Ed.), Database transaction models for advanced applications (pp. 515-553). Morgan Kaufmann.
Transaction Concurrency Methods
Zhang, A., Nodine, M., Bhargava, B., & Bukhres, O. (1994). Ensuring relaxed atomicity for flexible transactions in multidatabase systems. Proceedings of the ACM SIGMOD Conference (pp. 67-78).
KEY TERMS
ACID Properties: The properties imply that a transaction is atomic, transforms the database from one consistent state to another consistent state, is executed as if it were isolated from other concurrent transactions, and is durable after it has been committed.
Atomic Transaction: A transaction the updates of which are either all executed or removed (the “A” in the ACID properties). The atomicity property makes it easier to do database recovery.
Concurrency Control: Control method, which secures that a transaction is executed as if it were executed in isolation (the “I” in the ACID properties) from other concurrent transactions.
Hotspots: Records that are updated so frequently that they constitute bottlenecks if traditional concurrency control is used.
Isolation Anomalies: Inconsistencies that occur when transactions are executed without the isolation property.
Isolation Levels: Different degrees of isolation that use up to three different types of isolation anomalies, which are accepted when concurrent transactions are executed.
Long-Lived Transactions: Transactions that run for so long that they will block access to the records they have accessed if traditional concurrency control is used.
Multidatabases: Integrated databases managed by local database management systems without distributed ACID properties.
Transaction Abort: Removal of the updates of a transaction.
Two-Phase Locking: The most used concurrency control method for implementing the isolation property.
700
TEAM LinG
|
701 |
|
Transactional Support for Mobile Databases |
|
|
|
6 |
|
|
|
|
|
|
|
Hong Va Leong
The Hong Kong Polytechnic University, Hong Kong
INTRODUCTION
With the widespread deployment of wireless communication infrastructure in the past decade, accessing information online while a client is on the move becomes a concrete possibility. Such a computing environment is often referred to as a mobile environment (Imielinski & Badrinath, 1994). A typical group of applications that deserve strong support under the mobile environment would be database access. Database systems that support operations initiated from mobile clients are referred to as mobile databases (Leong & Si, 1997). We have witnessed a tremendous growth in mobile database research in the past ten years. Yet only the most primitive results have been incorporated in real applications. This is due to the additional dimensions of complexity that the mobile environment has introduced, beyond standard client/server computing environment.
Besides traditional issues to accessing a database system under a client/server setting, a mobile environment also suffers from problems such as low communication bandwidth and unreliable communication with occasional disconnection. To combat for the disconnection problem of mobile clients, database server will allow clients to cache data items that they may need in future, either performing caching on demand or prefetching cache in an anticipatory manner (Jing, Helal & Elmagarmid, 1999). In the context of the mobile file system Coda, this latter approach is called hoarding (Mummert, Ebling & Satyanarayanan, 1995).
There are claims that a mobile environment does possess a high broadcast bandwidth. It is this peculiar feature of asymmetric communication that leads to a good number of research works. For instance, it is quite intuitive to utilize the high bandwidth downlink channel to schedule useful data items to be broadcast to a large collection of mobile clients, thereby improving the scalability of database access, since the same bandwidth can serve a large client population (Si & Leong, 1999).
With downscaling of mobile clients from laptop computers to PDAs and even to smart phones, the relatively weak processing power of mainstream mobile clients cannot be solved in a satisfactory manner without considering a certain tradeoff. To reduce the processing stress on the small mobile clients, it is necessary to move the computation from the clients back to
the server. Under such environment, the clients often only implement the interface, passing the data back to the server for operation. However, one may not be willing to give up the autonomy of mobile clients by relinquishing the processing control to the server. The most acceptable variant that still favors client control is through the use of mobile agents (Yau, Leong & Si, 2003), which can act as surrogates on behalf of the mobile clients in performing possibly complex operations on the database and to prepare for handling processing results upon client disconnection. The captured results would only be conveyed back to the mobile clients upon reconnection.
BACKGROUND
Access needs from mobile clients to database server in a mobile environment should be backed by efficient mechanisms, which are specially designed for those mobile databases. To further complicate matters, clients in a mobile environment can physically move around. As a result, the database applications should be enriched by taking into consideration the client location as a special form of data in the database. As such, that gives rise to the need of providing client location management to be tracked through the use of a special kind of databases, namely, moving object databases (Wolfson et al., 1999). Location tracking and management performance can be improved by providing approximate moving object locations, which often suffice for most applications (Lee, Leong & Si, 2003). With object location in light, a new class of database queries whose result sets would depend on the client location need to be handled. These are often referred to as location-depen- dent queries (Madria et al., 2000).
Most common applications accessing mobile databases often access a collection of related data items for information purpose, that is, for inquiry. There are often only few updates to the databases. In such cases, it may be easy to provide a consistent view of data items to mobile clients, since the updates can be batched and installed to the databases in the background. This is also the philosophy behind many mobile file systems (such as Coda) that only provide the session semantics for remote accesses. However, there are certain applications that require a strong level of consistency to access-
Copyright © 2006, Idea Group Inc., distributing in print or electronic forms without written permission of IGI is prohibited.
TEAM LinG
ing a related set of data items, satisfying the referential integrity (accessing no phantom tuple) or other integrity constraints such as the mutual consistency of the item set (e.g., the total number of seats sold plus remaining seats should be constant in a show). This can be guaranteed via the execution of transactions, satisfying the four conditions of Atomicity, Consistency, Isolation, and Durability (Bernstein, Hadzilacos & Goodman, 1987). The widely accepted correctness criterion of executing concurrent transactions is the serializability of transactions. Transactions initiated by mobile clients that are executed on mobile databases are called mobile transactions (Dirckze & Gruenwald, 2000; Mok, Leong & Si, 1999).
Extending standard ACID mobile transactions further, there are occasions that one needs to access data not only from one database, but also from multiple databases residing on different sites, perhaps spanning different administrative domains. It becomes more difficult to ensure consistency, especially when the databases are managed by different organizations. The extension of serializability in such a context is called the global serializability (Breitbart, Garcia-Molina & Silberschatz, 1992), and the transaction spanning across different organizations is known as a global transaction. Tesch and Wäsch (1997) presented an implementation of global transactions on the ODMG-compliant multidatabase systems. Preserialization techniques were proposed to improve performance of global transactions in the mobile environment (Dirckze & Gruenwald, 2000).
Although global transactions ensure strong consistency, the cost of global transaction execution is very high, so they are not widely adopted in practice. Instead, a global transaction is often split into multiple smaller subtransactions for execution on individual databases. Each subtransaction can commit by itself under the Saga concept (Garcia-Molina & Salem, 1987). Such a collection of a logically related global transaction can be derived from the concept of a nested transaction (Moss, 1987). Alternatively, compensating transactions
(Chrysanthis & Ramamritham, 1994) can be executed to undo the effect of failed subtransactions. It has been argued that execution of compensating transactions is often more appropriate in a mobile environment to reduce blocking (Tesch & Wäsch, 1997), since mobile transactions are relatively long-lived.
SUPPORTING MOBILE
TRANSACTIONS
Transactional semantics to access a database satisfying the serializability of transactions can be enforced by means of concurrency control protocols, such as two-
Transactional Support for Mobile Databases
phase locking and timestamp ordering (Bernstein et al., 1987). Most practical database systems employ the strict two phase locking protocol as their concurrency control mechanism. In the context of a mobile database, it is often more common to implement a variant of the optimistic concurrency control protocol (Bernstein et al., 1987) and two-phase locking with lock caching (Franklin, Carey & Livny, 1997) in view of the high communication overhead. The benefits of optimistic concurrency control protocol lie in the reduction of communication overhead in acquiring locks, thereby deferring the detection of conflicts to the end of a transaction. This is appropriate under the assumption that data conflict is rare.
To improve the performance of variants of optimistic concurrency control protocol as applied in the mobile environment, especially when the degree of conflict is not very low, the server may issue a certification report periodically to mobile clients (Barbara, 1997). The certification report contains data items belonging to the read set and write set of active transactions that have successfully been certified for commitment. In other words, the report conveys information about conflicts in data items from transactions that have been validated. Mobile clients that execute transactions conflicting with those in the certification report can choose to abort those transactions that are destined to fail. To further facilitate early detection of conflicts, relevant information can be conveyed to clients when the latter issue requests for data items. This enables early partial validation to be performed at the server (Lee & Lam, 1999) since the read set of the requesting mobile transaction is known. Another way to reduce the number of mobile transactions being aborted is to reduce the time interval between the availability of updated values of data items to the time the corresponding update transactions commit. This is resolved by introducing the prewrite operation that allows early availability of updated values (Madria & Bhargava, 2001). The corresponding pre-read operation allows return of the value updated by a pre-write operation.
A very special property in a mobile environment is the availability of the high bandwidth broadcast media. As a result, database items can be scheduled to be broadcast over the downlink channel, thereby allowing efficient processing of transactions, especially those read-only transactions (Pitoura & Chrysanthis, 1999). However, one must ensure that the set of data items constituting a broadcast cycle are mutually consistent by taking a consistent snapshot of the database. Furthermore, an invalidation report can be broadcast at the beginning of a broadcast cycle to allow a mobile client to abort transactions that have read an old data value, which has subsequently been overwritten (i.e., reading
702
TEAM LinG

Transactional Support for Mobile Databases
outdated value). Read-only transaction performance can be further improved by means of multi-version broadcast, since reading older and yet consistent versions can avoid invalidation caused by update transactions. It is simple to construct a consistent snapshot of broadcast items by executing a large read-only transaction. However, this large long-lived read-only transaction will generate excessive blocking to concurrent update transactions. To improve efficiency, the snapshot is often taken by means of some special internal database mechanism. This action must be handled with great care in the presence of update transactions, since inconsistency can easily arise (Ammann, Jajodia & Mavuluri, 1995).
To process update transactions in a broadcast environment where data items are broadcast, updates must be conveyed back to the server via the uplink channel. As such, it is beneficial to classify the data items into hot items and cold items. Hot data items commonly needed by many clients can be scheduled for broadcast in order to capitalize on the high broadcast bandwidth, whereas cold data items can be requested on demand via the uplink channel. The hybrid protocol by Mok et al. (1999) takes advantage of the broadcast channel for delivering a consistent snapshot of hot items while making use of the uplink channel to request for items not available over the broadcast. The protocol ensures serializability by performing validation for update transactions against values stored at the database server. As with previous work, updates are installed at the server in an atomic step with short-duration conservative two-phase locking. Consistency across database items is ensured through the use of timestamps, and update transactions are serialized in timestamp order.
Although the use of broadcast with multi-versioning can improve commit rate of read-only transactions, further performance improvement can be gained by relaxing the strong serializability requirement a little bit. It is intuitive that mobile clients are not interested in observing a global serialization order on all transactions. Instead, they are only concerned about their views on transactions that they can see to be guaranteed consistent. This is captured in the notion of update consistency (Shanmugasundaram et al., 1999) in which all update transactions are serializable, but each mobile client only needs to ensure that the projection of transactions that it can observe is serializable. Update consistency can be enforced by the cycle-based algorithm through the use of F-matrix. Values of committed updates to data items are broadcast in each cycle, together with control information that allows a mobile client to determine the consistency of the set of data items that it reads. While update consistency can guarantee the logical consistency of transactions with respect to the server and each mobile client, isolation-only transaction (Lu & Satyanarayanan,
1995) was proposed to reduce the impact of client disconnection by focusing on the isolation property of trans- 6 actions. In isolation-only transaction, the new second
class transactions can be executed and conditionally committed under a disconnected environment. Upon reintegration, it is possible that those second class transactions can be converted to first class transactions if there are no conflicts (unlikely) or the conflicts can be repaired semantically. Second class transactions could miss all non-local transactions, but first class transactions are serializable among themselves.
Going one step further from update consistency and isolation-only transactions, which still guarantee consistency under favorable conditions, it is often acceptable for a mobile client not to see the updates made by concurrently executing mobile clients, if transactions can be executed at a higher efficiency. In this regard, one can relax the isolation property of a transaction that it is allowed to miss at most N concurrently executing transactions under the correctness criterion of N-ignorance (Krishnakumar & Bernstein, 1994). Intuitively, N concurrent transactions can be executed without any concurrency control. If more transactions are executed, only limited constraints need to be imposed. Observing that it is the deviation of data values from the correct values that is more important than the actual number of transactions ignored during an execution, it would be more acceptable to control the degree of deviation of data values returned by a read operation. As long as the deviation on a data item x is within a prescribed threshold e, conflicting weaker transactions (called ε-transactions) on x can still commit under the correctness criterion of ε-serializability (Wu, Yu & Pu, 1997) through the use of divergence control methods. Wong, Agrawal, and Mak (1997) generalized the notion of controlled deviation into bounded inconsistency. Instead of considering only the simple read and write operations, general operations such as “increment” or “insert”, executed by concurrent conflicting transactions, return data values in the form of a resolution set. As long as the resolution set satisfies the correctness criteria indicating the allowable deviation, conflicting transactions can be committed with bounded amount of inconsistency. As a result, operations can be executed out of order in some controlled manner to improve concurrency and hence performance.
FUTURE TRENDS
With the rapid advancement in communication devices in recent years, it is anticipated that smart phones and PDAs will overtake laptop computers to become the predominated mobile devices. They now possess in-
703
TEAM LinG
creasing processing power and storage capacity. Smart phones are programmable so that they approach simple mobile clients in terms of functionality. Furthermore, with the increasing popularity of Web services such as .NET and SOAP, new mobile applications would likely be built upon such platforms. All these will change the landscape of accesses to mobile databases, including transactional accesses. Although it is likely still based on the clientserver access paradigm so that most existing concurrency control protocols would work, there are recurring limitations on mobile clients in terms of connectivity and battery life. As such, it is reasonable that some of the complex coordination work would be migrated to the proxy server or to Web services components, thereby alleviating the processing need on the mobile clients. Transaction processing mechanisms, including concurrency control protocols, would more likely be performed at the proxy server and be decoupled from the application logic. The application logic can further be delivered conveniently through the adoption of mobile agents (Yau et al., 2003) that can migrate with respect to client movement and may even hop from devices to devices. On the other hand, more research and development efforts would be dedicated to intelligent agents that can make sensible decisions on behalf of the client, especially in the event of disconnection. In particular, mobile agents are highly useful for event-driven transactions like stock selling transactions or auctioning, since they can make proper decisions without suffering from the delay through the wireless network for user input and the disconnection problem. Compensating transactions and global transactions for intelligent agents should also be considered. Since some compensating transactions expect user intervention, proper actions performed by the agent in the lack of physical user presence would be required.
CONCLUSION
In this paper, we have presented the characteristics of mobile databases and their inherent limitation and difference from traditional databases. In particular, the difference in communication bandwidth, asymmetric communication infrastructure, disconnection as well as physical client movement issues need to be addressed. We focused more on one important class of applications on the databases, namely, atomic database accesses in terms of transactions, which guarantee consistent accesses across different data items. To generalize the transactions, we presented the notion of global transactions, which guarantee consistency not only across data items, but also across multiple database systems, perhaps even under different administrative domains.
Transactional Support for Mobile Databases
Transactions can be supported through appropriate concurrency control protocols to ensure their correctness. In the context of mobile transactions, traditional concurrency control protocols should be adapted for the low bandwidth environment with disconnection. Furthermore, it is important to capitalize on the scalable broadcast channel to deliver data items from database to improve performance. Weaker consistency requirements for transactions were also proposed to allow performance to be boasted at the expense of allowing a controlled degree of inconsistency. In the future, we expect the rise of smaller mobile devices that would depend more heavily on Web services and the use of agents with transactional support provided at proxy.
REFERENCES
Ammann, P., Jajodia, S., & Mavuluri, P. (1995). On-the- fly reading of entire databases. IEEE Transactions on Knowledge and Data Engineering, 7(5), 834-838.
Barbara, D. (1997). Certification reports: Supporting transactions in wireless systems. Proceedings of the 17th International Conference on Distributed Computing Systems (pp. 466-473).
Bernstein, P.A., Hadzilacos, V., & Goodman, N. (1987).
Concurrency control and recovery in database systems. Reading, MA: Addison-Wesley.
Breitbart, Y., Garcia-Molina, H., & Silberschatz, A. (1992). Overview of multidatabase transaction management. VLDB Journal, 1(2), 181-239.
Chrysanthis, P.K., & Ramamritham, K. (1994). Synthesis of extended transaction models using ACTA. ACM Transactions on Database Systems, 19(3), 450-491.
Dirckze, R.A., & Gruenwald, L. (2000). A pre-serializa- tion transaction management technique for mobile multidatabases. Mobile Networks and Applications Journal, 5(4), 311-321.
Franklin, M.J., Carey, M.J., & Livny, M. (1997). Transactional client-server cache consistency: Alternatives and performance. ACM Transactions on Database Systems, 22(3), 315-363.
Garcia-Molina, H., & Salem, K. (1987). Sagas. Proceedings of the ACM SIGMOD International Conference on Management of Data (pp. 249-259).
Imielinski, T., & Badrinath, B.R. (1994). Mobile wireless computing: Challenges in data management. Communications of the ACM, 37(10), 18-28.
704
TEAM LinG

Transactional Support for Mobile Databases
Jing, J., Helal, A.S., & Elmagarmid, A. (1999). Client-server computing in mobile environments. ACM Computing Surveys, 31(2), 117-157.
Krishnakumar, N., & Bernstein, A.J. (1994). Bounded ignorance: A technique for increasing concurrency in a replicated system. ACM Transactions on Database Systems, 19(4), 586-625.
Lee, C.K., Leong, H.V., & Si, A. (2003). Approximating object location for moving object database. Proceedings of the International Conference on Distributed Computing Systems Workshop on Mobile Distributed Computing (pp. 402-407).
Lee, V.C.S., & Lam, K.W. (1999). Optimistic concurrency control in broadcast environments: Looking forward at the server and backward at the clients. Proceedings of First International Conference on Mobile Data Access,
(pp. 97-106).
Leong, H.V., & Si, A. (1997). A semantic caching mechanism for mobile databases. International Journal of Computers and Their Applications, 4(2), 21-34.
Lu, Q., & Satyanarayanan, M. (1995). Improving data consistency in mobile computing using isolation-only transactions. Proceedings of the 5th Workshop on Hot Topics in Operating Systems.
Madria, S.K., Bhargava, B.K., Pitoura, E., & Kumar, V. (2000). Data organization issues for location-dependent queries in mobile computing. Proceedings of International Conference on Database Systems for Advanced Applications (pp. 142-156).
Madria, S.K., & Bhargava, B.K. (2001). A transaction model to improve data availability in mobile computing.
Journal of Distributed and Parallel Databases, 10(2), 127-160.
Mok, E., Leong, H.V., & Si, A. (1999). Transaction processing in an asymmetric mobile environment. Proceedings of First International Conference on Mobile Data Access (pp. 71-81).
Moss, J.E.B. (1987). Log-based recovery for nested transactions. Proceedings of the International Conference on Very Large Data Bases (pp. 427-432).
Mummert, L.B., Ebling, M., & Satyanarayanan, M. (1995). Exploiting weak connectivity for mobile file access. Proceedings of the 15th ACM Symposium on Operating System Principles (pp. 143-155).
Pitoura, E., & Chrysanthis, P.K. (1999). Scalable processing of read-only transactions in broadcast push. Proceed-
ings of the 19th International Conference on Distributed |
6 |
Computing Systems (pp. 432-439). |
Shanmugasundaram, J., Nithrakashyap, A., Sivasankaran, R., & Ramamritham, K. (1999). Efficient concurrency control for broadcast environments. Proceedings of the ACM SIGMOD International Conference on Management of Data (pp. 85-96).
Si, A., & Leong, H.V. (1999). Query optimization for broadcast database. The Data and Knowledge Engineering Journal, 29(3), 351-380.
Tesch, T., & Wäsch, J. (1997). Global nested transaction management for ODMG-compliant multi-database systems. Proceedings of International Conference on Information and Knowledge Management (pp. 67-74).
Wolfson, O., Sistla, A.P., Xu, B., Zhou, J., & Chamberlain, S. (1999). DOMINO: Databases fOr MovINg Objects tracking. Proceedings of the ACM SIGMOD International Conference on Management of Data (pp. 547-549).
Wong, M.H., Agrawal, D., & Mak, H.K. (1997). Bounded inconsistency for type-specific concurrency control.
Journal of Distributed and Parallel Databases, 5(1), 31-75.
Wu, K.L, Yu, P.S., & Pu, C. (1997). Divergence control algorithms for epsilon serializability. IEEE Transactions on Knowledge and Data Engineering, 9(2), 262274.
Yau, S.M.T., Leong, H.V., & Si, A. (2003). Distributed agent environment: Application and performance. Information Sciences Journal, 154(1-2), 5-21.
KEY TERMS
Broadcast Database: A broadcast database is a mobile database whose contents are being broadcast, fully or partially, to a population of mobile clients.
Compensating Transaction: A compensating transaction is a transaction that is executed to undo the effect of another committed transaction. Unlike ordinary transaction rollback or abort, both original and compensating transactions are visible in the committed projection of the execution history.
Concurrency Control Protocol: A concurrency control protocol is executed to ensure that the proper correctness criterion, usually serializability, is upheld for a set of concurrently executing transactions by controlling whether a certain operation can be performed, delayed, or
705
TEAM LinG
rejected and whether the transaction can be committed or has to be aborted.
Database Snapshot: A consistent collection of values of data items in a database that correspond to what a readonly transaction would collect. The snapshot can be used as a checkpoint for recovering a database upon a crash failure and for consistent database broadcast.
Mobile Agent: A mobile agent is a piece of code capable of migrating to different sites for execution, making use of local resources, and acting on behalf of its launching site. The agent will carry along with its execution state and data upon migration.
Mobile Database: A mobile database is a database accessible to mobile clients. There are appropriate mechanisms to take into account of the limitation of the wireless bandwidth, the use of downlink broadcast channel, and the effect of client mobility.
Moving Object Database: A moving object database is a database that maintains efficiently the location infor-
Transactional Support for Mobile Databases
mation about moving objects with proper indexing on the object location to support advanced queries such as location-dependent queries and continuous queries.
Serializability/Global Serializability: Seriali zability is the generally accepted correctness criterion for concurrent execution of transactions. The concurrent execution should produce the same effect and lead to the same database state as one possible sequential execution of the same set of transactions. Global serializability is the correctness criterion for concurrent execution of global transactions over many database systems. It is a stronger correctness criterion than serializability.
Transaction/Global Transaction: A transaction is a sequence of operations on a database that should appear as if they were executed non-interfered, even in the presence of other concurrent transactions. A transaction should satisfy the ACID properties, namely, Atomicity, Consistency, Isolation, and Durability. A global transaction is a distributed transaction that is executed on two or more database systems.
706
TEAM LinG
|
707 |
|
Transformation-Based Database Engineering |
|
|
|
6 |
|
|
|
|
|
|
|
Jean-Luc Hainaut
University of Namur, Belgium
INTRODUCTION
Modelling software design as the systematic transformation of formal specifications into efficient programs and building CASE tools that support it has long been considered one of the ultimate goals of software engineering. For instance, Balzer (1981) and Fikas (1985) consider that the process of developing a program [can be] formalized as a set of correctness-preserv- ing transformations [...] aimed to compilable and efficient program production. In this context, according to Partsch and Steinbrüggen (1983), a transformation is a relation between two program schemes P and P’ (a program scheme is the [parameterized] representation of a class of related programs; a program of this class is obtained by instantiating the scheme parameters). It is said to be correct if a certain semantic relation holds between P and P’.
These definitions still hold for database schemas, which are a special kind of abstract program schemes. The concept of transformation is particularly attractive in this realm, though it has not often been made explicit (for instance, as a user tool) in current CASE tools.
A (schema) transformation is most generally considered to be an operator by which a data structure S1 (possibly empty) is replaced by another structure S2 (possibly empty) which may have some sort of equivalence with S1. Some transformations change the information contents of the source schema, particularly in schema building (adding an entity type or an attribute) and in schema evolution (removing a constraint or extending a relationship type). Others preserve it and will be called semantics-preserving or reversible.
Transformations that are proved to preserve the correctness of the original specifications have been proposed in practically all the activities related to schema engineering: schema normalization (Rauh & Stickel, 1995), DBMS schema translation (Rosenthal & Reiner, 1994), schema integration (McBrien & Poulovassilis, 2003), schema equivalence (Jajodia, Ng, & Springsteel, 1983; Kobayashi, 1986), data conversion (Navathe, 1980), reverse engineering (Casanova & Amaral De Sa, 1984; Hainaut, Chandelon, Tonneau, & Joris, 1993), schema optimization (Halpin & Proper, 1995), database interoperability (McBrien & Poulovassilis; Thiran & Hainaut, 2001), and others. The reader will find in
Hainaut (1995) an illustration of numerous application domains of schema transformations.
Though it has been explored for more than 25 years, this concept has only been gaining wider acceptance for two years, as witnessed by the recent references Omelayenko and Klein (2003) and van Bommel (2004).
The goal of this paper is to develop and illustrate a general framework for database transformations in which most processes mentioned above can be formalized and analyzed in a uniform way. Section 2 describes the basics of schema transformations. Section 3 explains how practical transformations can be used for database engineering. The database design and reverse engineering processes are revisited in Section 4, where we give them a transformational interpretation. Section 5 concludes the article.
BACKGROUND
This section describes a general transformational theory that will be used as a basis for modelling database engineering processes. First, we define a wide-spec- trum model from which operational models (i.e., those which are of interest for practitioners) can be derived. Then, we describe the concept of transformation and its semantics-preserving property.
A Data Structure Specification Model
Database engineering is concerned with building, converting, and transforming database schemas at different levels of abstraction and according to various paradigms. Some processes, such as normalization, integration, and optimization operate within a single model and require intra-model transformations. Other processes, such as logical design, use two distinct models, namely, source and target. Finally, some processes—among others, reverse engineering and federated database de- velopment—can operate on an arbitrary number of models (or on a hybrid model made up of the union of these models) as we will see later on. The generic entityrelationship model (GER) is a wide-spectrum formalism intended to encompass most popular operational models, whatever their abstraction level and their underlying paradigms (Hainaut, 1996).
Copyright © 2006, Idea Group Inc., distributing in print or electronic forms without written permission of IGI is prohibited.
TEAM LinG
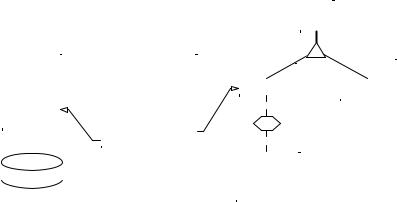
The GER includes, among others, the concepts of schema, entity type, entity collection, domain, attribute, relationship type, key, as well as various constraints. In this model, a schema is a description of data structures (Figure 1). It is made up of specification constructs, which can be, for convenience, classified into the usual three abstraction levels, namely, conceptual, logical, and physical:
•A conceptual schema comprises entity types, super/subtype (is-a) hierarchies, relationship types, roles, attributes (multi/single-valued; atomic/compound), identifiers (or unique keys), and various constraints.
•A logical schema comprises such constructs as record types, fields, arrays, foreign keys, redundant fields, etc.
•A physical schema comprises files, record types, fields, access keys (a generic term for index, calc key, etc), physical data types, bag and list multivalued attributes, and other implementation details.
Since it includes the main concepts of most operational models, the GER can be used to precisely specify each of them thanks to a specialization mechanism. According to the latter, each construct of model M is a specialization of a construct of the GER model. For instance, tables, columns, primary keys, and foreign
Transformation-Based Database Engineering
keys are specializations of, respectively, entity types, attributes, primary identifiers, and referential attributes. In addition, schemas in M must satisfy specific assembly rules, such as the following: each entity type has at least one attribute. As an important consequence, all intraand inter-model transformations are specializations of GER-to-GER transformations. For instance, the standard ERA-to-SQL transformation is modelled by a chain of transformations from the ERA specialization of the GER to its SQL specialization.
The GER model has been given a formal semantics in terms of an extended NF2 model (Hainaut, 1996). This semantics allows us to analyze the properties of transformations and particularly to precisely describe how and under which conditions they propagate and preserve the information contents of schemas.
Transformation: Definition
The definitions that will be stated are model-indepen- dent. In particular, they are valid for the GER model, so that the examples will be given in the latter. We denote by M the model in which the source and target schemas are expressed, by S the schema on which the transformation is to be applied, and by S' the schema resulting from this application.
A transformation Σ consists of two mappings T and t (Figure 2):
Figure 1. A typical hybrid schema made up of conceptual constructs (e.g., entity types PERSON, CUSTOMER, EMPLOYEE, and ACCOUNT; relationship type of; identifiers Customer ID of CUSTOMER); logical constructs (e.g., record type ORDER, with various kinds of fields, including an array, foreign keys ORIGIN and DETAIL.REFERENCE); and physical objects (e.g., table PRODUCT with primary key PRO_CODE and indexes PRO_CODE and CATEGORY, table space PRODUCT.DAT). The identifier of ACCOUNT, stating that the accounts of a customer have distinct Account numbers, makes ACCOUNT a dependent, or weak, entity type. The cardinality constraint of a role follows the participation interpretation and not the UML look-across semantics.
|
|
|
|
|
|
|
|
|
|
PERSON |
|
|
|
|
|
|
|
|
|
|
|
|
Name |
|
|
|
|
|
|
|
|
|
|
|
|
Address |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
T |
|
|
PRODUCT |
|
ORDER |
|
|
|
|
|
|
|
|
|
EMPLOYEE |
PRO_CODE |
|
ORD-ID |
|
|
CUSTOMER |
|
|
|
Employe Nbr |
|||
CATEGORY |
|
DATE_RECEIVED |
|
|
Customer ID |
|
|
|
||||
|
|
|
|
|
|
Date Hired |
||||||
DESCRIPTION |
|
ORIGIN |
|
|
id: Customer ID |
|
|
|
||||
|
|
|
|
|
|
id: Employe Nbr |
||||||
UNIT_PRICE |
|
DETAIL[1-5] array |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
id: PRO_CODE |
|
REFERENCE |
|
|
|
0-N |
|
|
|
|
|
|
acc |
|
QTY-ORD |
|
|
|
|
|
|
|
|
|
|
acc: CATEGORY |
|
id: ORD-ID |
|
|
|
|
of |
|
|
|
||
|
|
ref: ORIGIN |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ref: DETAIL[*].REFERENCE |
|
|
|
|
|
|
|
|
|
|
|
|
1-1 |
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
PRODUCT.DAT |
|
|
|
|
ACCOUNT |
|
|
|
||||
|
|
|
|
Account NBR |
|
|
|
|||||
PRODUCT |
|
|
|
Amount |
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
id: of.CUSTOMER |
|
|
|
|||||
|
|
|
|
|
Account NBR |
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
708
TEAM LinG
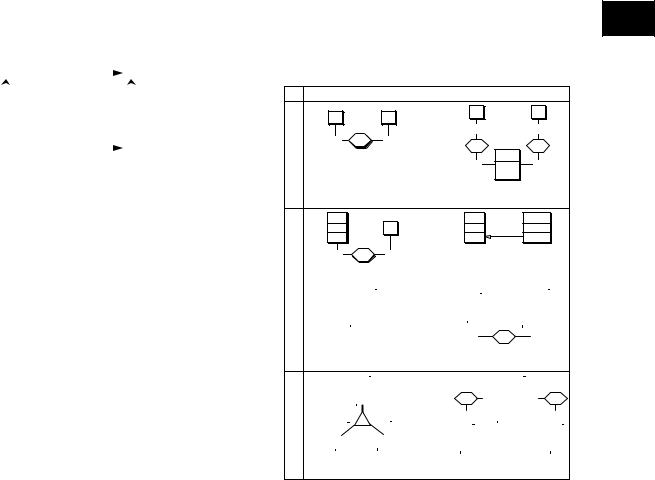
Transformation-Based Database Engineering
Figure 2. The two mappings of schema transformation Σ=<T,t>. The inst_of arrow from x to X indicates that x is an instance of X.
C |
|
T |
C' = T(C) |
||
|
|
||||
|
inst_of |
|
|
inst_of |
|
|
|
|
|||
|
|
|
t |
|
|
c |
|
c' = t(c) |
|||
|
|
||||
•T is the structural mapping that replaces source construct C in schema S with construct C’. C’ is the target of C through T and is noted C’ = T(C). In fact, C and C’ are classes of constructs that can be defined by structural predicates. T is therefore defined by the minimal precondition P that any construct C must satisfy in order to be transformed
by T, and the maximal postcondition Q that T(C) satisfies. T specifies the rewriting rule of Σ.
•t is the instance mapping that states how to produce the T(C) instance that corresponds to any instance of C. If c is an instance of C, then c’ = t(c) is the corresponding instance of T(C). t can be specified through any algebraic, logical, or procedural expression.
According to the context, Σ will be noted either <T,t> or <P,Q,t>.
Each transformation Σ is associated with an inverse transformation Σ’, which can undo the result of the former under certain conditions.
Reversibility of a Transformation
The extent to which a transformation preserves the information contents of a schema is an essential issue. Some transformations appear to augment the semantics of the source schema (e.g., adding an attribute), some remove semantics (e.g., removing an entity type), while others leave the semantics unchanged (e.g., replacing a relationship type with an equivalent entity type). The latter are called reversible, or semantics-preserving. If a transformation is reversible, then the source and the target schemas have the same descriptive power.
•A transformation Σ1 = <T1,t1> = <P1,Q1,t1> is reversible, iff there exists a transformation Σ2 =
<T2,t2> = <P2,Q2,t2> such that for any construct C and any instance c of C: P1(C) ([T2(T1(C))=C] and [ t2(t1(c)=c]). Σ2 is the inverse of Σ1, but the
Figure 3. The six mutation transformations Σ1 to Σ3. Σ4 transforms an is-a hierarchy into one-to-one relationship 6 types and conversely. The term rel-type stands for relationship type.
|
source schema |
|
target schema |
|
|
|
|
A |
|
B |
T1 |
A |
|
B |
|
|
|
|
|||
|
|
|
|
0-N |
|
0-5 |
0-N |
r |
0-5 |
|
rA |
|
rB |
Σ1 |
|
|
|
|||
|
|
T1' |
|
R |
|
|
|
|
|
|
1-1 |
id: rA.A |
1-1 |
|
|
|
|
|
rB.B |
|
Comment. Transforming rel-type r into entity type R (T1) and conversely (T1'). Note that R entities are identified by any couple (a,b) AxB through rel-types rA and rB (id:ra.A,rB.B).
A |
T2 |
A |
B |
A1 |
|
B |
|
A1 |
A1[0-5] |
id: A1 |
|
|
|
id: A1 |
ref: A1[*] |
Σ2 |
r |
0-5 |
|
|
|
0-N |
T2' |
|
|
||
|
|
|
|
|
Comment. Transforming rel-type r into reference attribute B.A1 (T2) and conversely
(T2'). |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
T3 |
|
|
|
|
|
|
|
|
|
|
|
A |
|
|
|
|
|
EA2 |
|
||||
|
|
|
|
A |
|
|
|
|
|
|
|
|
|
A1 |
|
|
|
A2 |
|
||||||
|
|
A1 |
|
|
|
|||||||
|
|
|
|
|
|
|
|
|||||
|
A2[0-5] |
|
|
A3 |
|
|
id: ra2.A |
|
||||
|
A3 |
|
|
|
|
A2 |
|
|||||
Σ3 |
|
|
|
|
|
|
|
|||||
|
T3' |
|
|
|
ra2 |
|
|
|
|
|
||
|
|
0-5 |
|
|
1-1 |
|
|
|||||
Comment. Transforming attribute A2 into entity type EA2 (T3) and conversely (T3'). Note that the EA2 entities depending on the same A entity have distinct A2 values (id:ra2.A,A2).
|
|
|
A |
|
|
T4 |
|
|
|
|
|
|
A |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
A1 |
|
|
r |
|
|
A1 |
|
|
|
s |
|
|||||
|
|
|
A2 |
|
|
|
0-1 |
|
A2 |
|
0-1 |
|
|
||||||
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
excl: s.C |
|
|
|
|
|
|
|
|
|
|
D |
|
1-1 |
|
|
|
|
r.B |
|
|
|
1-1 |
|
||||
Σ4 |
|
|
|
|
C |
T4' |
|
|
|
|
|
|
|
|
|
|
|
|
|
B |
|
|
|
|
B |
|
|
|
|
|
|
|
C |
|
|||||
|
B1 |
|
|
|
C1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
B1 |
|
|
|
|
|
|
|
C1 |
|
|||||
|
B2 |
|
|
|
C2 |
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
B2 |
|
|
|
|
|
|
|
C2 |
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Comment. An is-a hierarchy is replaced by one-to-one rel-types. The exclusion constraint (excl:s.C,r.B) states that an A entity cannot be simultaneously linked to a B entity and a C entity. It derives from the disjoint property (D) of the subtypes.
converse is not true. For instance, an arbitrary instance c’ of T(C) may not satisfy the property c’=t1(t2(c’)).
•If Σ2 is reversible as well, then Σ1 and Σ2 are called symmetrically reversible. In this case, Σ2 = <Q1,P1,t2>. Σ1 and Σ2 are called SR transformations for short.
Thanks to the formal semantics of the GER, a proof system has been developed to evaluate the reversibility of a transformation (Hainaut, 1996).
TRANSFORMATIONS FOR
DATABASE ENGINEERING
In this section, some important basic transformations are described, as well as higher-level operators.
709
TEAM LinG