

Rivero L.Encyclopedia of database technologies and applications.2006
.pdfReplication Mechanisms Over a Set of Distributed UDDI Registries
try is independent in defining the announcements of providers that it accepts and the retrieval demands of users that it satisfies. In addition, each provider is independent in selecting the UDDI registries to which it submits its announcements of Web services.
In the next section, the rationale of using software agents in the management of the content of several UDDI registries is outlined. Afterwards, some of the related works are discussed. The different types of agents, which are responsible for deploying this management, are discussed. Finally, a conclusion is presented.
BACKGROUND
Besides the availability of several approaches and technologies related to the deployment of Web services (e.g., SOAP, UDDI, Salutation), they are all tailored to a wired context. In this context, the computing resources are fixed and connected through a permanent and reliable communication infrastructure. The application of these approaches and technologies to a wireless context is not straightforward. Indeed, major adjustments are required because of multiple obstacles such as potential disconnections of mobile devices, unrestricted mobility of persons, and power scarcity of mobile devices. These obstacles highlight the suitability of software agents as potential candidates to overcome them. First a software agent is autonomous. Thus, it can make decisions on the users’ behalf while they are disconnected (i.e., off-line). Second, a software agent can be mobile. Therefore, it can move from one host to another. Continuous network connectivity is not required. Third, a software agent is collaborative. Therefore, it can work with other agents that identify, for example, the providers of Web services. Last but not least, a software agent is reactive. Consequently, it can monitor the events that occur in the user’s environment so that relevant actions can be promptly taken.
Scenarios where people while on the move electronically interact with their surrounding environment have been reported in Jose, Moreira, and Rodrigues (2003). These scenarios back our approach of getting users transparently engaged in various operations such as updating UDDI registries. Our initiative is at the crossing point of several initiatives on Web services, UDDI registry, and wireless. While these concepts are being independently studied (except for Web services and UDDI), we aim at their combination in the same framework. In addition, it is mentioned that the new version of the UDDI specification supports the fact that several registries might be
present at the same time, thus, have to interact. With this kind of specification, various challenges are faced when dealing with hundreds of registries (if not thousands) during service publication and discovery.
In Valavanis et al. (2003), MobiShare project provides a middleware system for offering ubiquitous connectivity to mobile devices. A user’s mobile device is seen as a source of services, a requestor of services, or both. Service in MobiShare means the data that devices decide to publicly make available. Data availability depends on the status (on/off) and location (dependent on the coverage area) of a device. In DBGlobe project, the aim is to develop data and metadata management techniques in a global computing context (Karakasidis & Pitoura, 2002). DBGlobe considers mobile entities as primary data stores and broadens the data management focus to address various issues such as mobility, autonomy, and scalability. To make data widely available, DBGlobe relies on chained hierarchies of directories. In case of an unsatisfied request at the level of a directory, the request is forwarded to a higher geographical authority. In the eNcentive project (Ratsimor et al., 2003), peer-to-peer electronic marketing in mobile ad-hoc environments is studied. The eNcentive project employs an intelligent marketing scheme by allowing users to collect information like sales promotions and discounts. The marketing scheme relies on users who propagate promotions and discounts to other users with the same interests and preferences in the network. Users participating in eNcentive take advantage of circulating announcements since businesses that originally issued the announcements reward the active distributors with additional promotions and compensations.
The environment of Web services that is targeted in this article has some similarities with peer-to-peer configurations. There is no centralized component that manages and coordinates the UDDI registries. In addition, all UDDI registries have equivalent capabilities and responsibilities in terms of accepting the announcements of Web services and satisfying the retrieval requests of Web services. Because the communication infrastructure between the distributed UDDI registries is not predefined, the flooding solution was abandoned, and the use of messengers was promoted. The flooding practice should not be adopted in peer-to-peer environments. However, Castano et al. (2003) observe that the solutions proposed for content retrieval in these environments often exploit either flooding or broadcasting to disseminate the queries when the location of a searched content is unknown.
550
TEAM LinG
Replication Mechanisms Over a Set of Distributed UDDI Registries
AGENTS FOR UDDI REGISTRIES
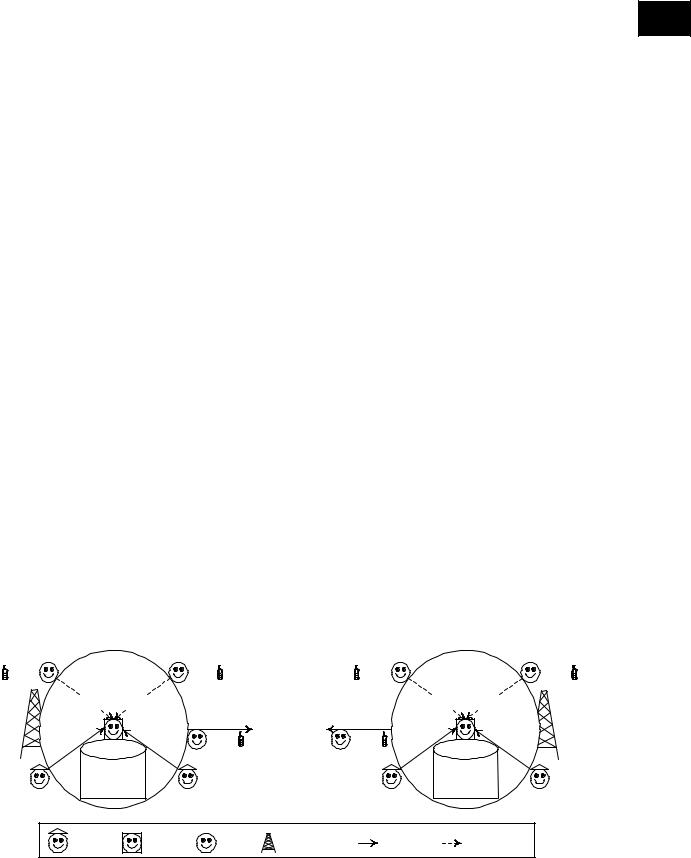
The agentification of the dynamic management of the UDDI registries results in the identification of three types of software agents: provider-agent, UDDI-agent, and user-agent. Figure 1 illustrates the agents according to the clusters of Web services, the UDDI registries, and the mobile support stations. Usually, the coverage areas (represented by circles in Figure 1) of the mobile support stations overlap. However, to keep the figure clear, the overlapping is not represented. We recall that there is no predefined communication infrastructure between the clusters of Web services. Figure 1 also depicts the notion of messenger, which is the couple (user, user-agent) while on the move. Users with their mobile devices are always under the management of a particular mobile support station. When a user moves to a different place, which is outside the coverage area of a mobile support station, a handover occurs between this station and the new mobile support station, which is responsible for covering this place. The messenger-based operation for the dynamic management of the content of several UDDI registries is decomposed into three stages. The first stage consists of storing the description of the Web services that satisfy the needs of users. The second stage, which is the core of this research initiative, consists of updating the UDDI registries using messengers. Finally, the third stage consists of identifying the Web services that satisfy the needs of users considering that several UDDI registries with different contents are deployed.
A provider-agent identifies a provider (i.e., a business) that posts its Web services on the UDDI registries of the multiple clusters. However, a provider is only authorized to connect to one master cluster so that it can use its UDDI registry. The services announced in the UDDI registry of a master cluster are labeled as internal. This labeling helps in (1) identifying the UDDI registry
where the services are announced for the first time; (2) |
4 |
knowing the location of the providers to whom the ser- |
vices belong; (3) denying all the operations of useragents that aim at updating the description of the services; and (4) naming the UDDI-agent that ensures that the parameters of the services (e.g., execution cost, execution time, QoS) are satisfied during execution.
Since a provider only announces its Web services in one UDDI registry, messengers take care of the UDDI registries of the remaining slave clusters. For announcement purposes in the slave clusters, the messengers adopt certain policies. The services posted on the UDDI registry of a slave cluster are labeled as external. This labeling helps (1) indicate that a certain messenger has announced the services, (2) inform that the services can always be subject to unpredicted changes, and (3) state that the UDDI-agent cannot guarantee the service execution parameters.
Because users are heavily engaged in the announcement of external Web services, the agreement of the respective providers of these Web services is required. For various reasons such as privacy (e.g., a provider does not want to announce all its services in a certain UDDI registry) and security (e.g., a provider is afraid that its announcements of services will be altered in a certain UDDI registry), a provider states in the description of a Web service that is submitted to an UDDI registry of a master cluster if this service can be announced in the UDDI registries of the slave clusters.
A user-agent resides in the mobile device of a user constituting a messenger when they move. The main duty of a user-agent is to satisfy its user’s needs (e.g., car rental, hotel booking) after it identifies and selects the Web services with the help of an UDDI registry. To this purpose, the user-agent initiates interactions with the UDDI-agent of an UDDI registry. The consideration of a specific UDDI registry depends on the current location of
Figure 1. Agentification of distributed UDDI registries
|
Cluster 1 |
|
user + |
of Web services |
+ user |
|
Retrievals |
|
|
Announcements |
|
|
|
|
Announcements |
Messenger |
|
Announcements |
+ user |
||
|
UDDI 1 |
|
|
Web services |
|
|
|
Legend |
|
|
|
provider-agent |
UDDI-agent |
User-agent |
|
|
Cluster 2 |
|
user + |
of Web services |
+ user |
|
|
Retrievals |
|
Announcements |
|
Messenger |
|
Announcements |
+ user |
Announcements |
|
|
|
UDDI 2 |
|
Web services |
|
Mobile support station |
Wired connection |
Wireless connection |
551
TEAM LinG
Replication Mechanisms Over a Set of Distributed UDDI Registries
the user with regard to the mobile support station that manages the mobile device. Once the services are identified and triggered for execution, the user-agent caches in the user’s mobile device various information such as the identifier of the services, the UDDI registry with whom the user-agent has dealt with to obtain the services, and the providers of services and their location according to the master clusters. This information can be potentially announced to distinct UDDI registries of slave clusters. This is conducted after verifying the authorization policies of the announcements.
Users are always attached to one cluster because of the mobile support station. The type of cluster (master or slave) is not relevant. When a user moves to a different place, which is outside the coverage of the current support station, the user’s mobile device becomes under the management of a new mobile support station. This means that the user-agent can now deal with the UDDI registry of the new cluster of Web services. The user-agent keeps track of all the clusters that it has visited in the past, its last date of visit, and the kind of information it submitted previously to their respective UDDI registry. If the user-agent notes that the information it caches is valuable to the UDDI-agent (what it was submitted vs. what it can now be submitted), a wireless communication is established between the two agents on a request basis from the user-agent. The rationale of the communication is to transfer the information on the Web services to the UDDI registry so that its content can get updated. The transfer obeys three categories of policies: provider-defined, UDDI registry-defined, and user-defined.
An UDDI-agent is deployed on top of an UDDI registry. The UDDI-agent interacts through wired connections with provider-agents for their announcements of services of type internal. In addition, the UDDI-agent interacts through wireless connections with user-agents for their retrieval requests of services and announcements of services of type external.
FUTURE TRENDS
One of the trends in the dynamic management of UDDI registries consists of integrating ad-hoc networking into the operation of messengers. This is motivated by the fact that messengers can constitute the components of this type of network, besides the compliance of messengers with the definition of what an ad-hoc network is. As a prerequisite, the messengers have to get the authorizations to set up such a network from their respective users and are in the vicinity of each other. Because
routes of users and user-defined policies constrain the messengers in their information exchange on service descriptions with UDDI registries, this exchange can be boosted by allowing messengers to collect further information from their peers. It is noted that the current configuration in Figure 1 illustrates a messenger conveying information related to one user. The future configuration, which relies on ad-hoc networking, enables messengers to convey information related to multiple users. For security reasons, messengers do not accept anything from their peers that can be executed on the mobile devices.
Another future trend consists of enhancing messengers with contextual information (Brezillon, 2003). This is motivated by the fact that different factors can contextualize the information exchange that will occur between messengers and UDDI registries. Several factors can be cited, among them, location of exchange, period of exchange, and type of policy violation. Because of the contextual information that can embed UDDI registries and messengers, several types of questions can be handled such as which messengers are attached to which UDDI registry? What services is a messenger submitting to a UDDI registry? And, what routes has a messenger passed by?
CONCLUSION
In this article, we outlined our approach for ensuring the replication across a set of distributed UDDI registries. The approach relies on the fact that users are mobile and the latest developments happening in the field of mobile devices (more storage capacity, more computing resources, and more advanced features). To manage the content of the UDDI registries, different types of policies were put forward stating, for example, where to announce, what to announce, and what to accept. These policies allow considering several aspects in the announcement of Web services such as security, privacy, and trustworthiness. Because of the lack of a predefined communication infrastructure that connect the UDDI registries, a flooding-based solution was discarded. Acting as messengers, users and their software agents support the exchange of content between the UDDI registries.
ACKNOWLEDGMENTS
The author acknowledges the contributions of H. Yahyaoui and Q. Mahmoud to the research initiative presented in this paper.
552
TEAM LinG

Replication Mechanisms Over a Set of Distributed UDDI Registries
REFERENCES
Benatallah, B., Sheng, Q.Z., & Dumas, M. (2003). The selfserv environment for Web services composition. IEEE Internet Computing, 7(1), 62-66.
Berardi, D., Calvanese, D., De Giacomo, G., Lenzerini, M., & Mecella, M. (2003). A foundational vision for e-ser- vices. Proceedings of The Workshop on Web Services, e- Business, and the Semantic Web (WES’2003) in conjunction with the 15th International Conference on Advanced Information Systems Engineering (CAiSE’2003), Klagenfurt/Velden, Austria.
Brezillon, P. (2003). Focusing on context in human-cen- tered computing. IEEE Intelligent Systems, 18(3), 29-34.
Casati, F., Shan, E., Dayal, U., & Shan, M.C. (2003). Business-oriented management of Web services. Communications of the ACM, 46(10).
Castano, A., Ferrara, S., Montanelli, S., Pagani, E., & Rossi, G.P. (2003). Ontology-addressable contents in P2P networks. Proceedings of the 1st Workshop on Semantics in Peer-to-Peer and Grid Computing in conjunction with the 12th International World Wide Web Conference (WWW’2003), Budapest, Hungary.
Curbera, F., Khalaf, R., Mukhi, N., Tai, S., & Weerawarana, S. (2003). The next step in Web services.
Communications of the ACM, 46(10), 29-34.
Huhns, M. (2002). Agents as Web services. IEEE Internet Computing, 6(4), 93-95.
Jennings, N., Sycara, K., & Wooldridge, M. (1998). A roadmap of agent research and development. Autonomous Agents and Multi-Agent Systems, 1(1), 7-38.
Jose,R.,Moreira,A.,&Rodrigues,H.(2003).TheAROUND architecture for dynamic location-based services. Mobile Networks and Applications, 8(4), 377-387.
Karakasidis, A., & Pitoura, E. (2002). DBGlobe: A datacentric approach to global computing. Proceedings of the 22nd International Conference on Distributed Computing Systems Workshops (ICDCSW’2002),
Vienna, Austria.
Kuno, H, & Sahai, A. (2002). My agent wants to talk to your service: Personalizing Web services through agents (Technical Report No. HPL-2002-114). HP Laboratories, Palo Alto, California, USA.
Maamar, Z., Ben-Younes, K., & Al-Khatib, G. (2003). Scenarios of supporting mobile users in wireless networks. Proceedings of the 2nd International Workshop on Wireless Information Systems (WIS’2003) in
conjunction with the 5th International Conference on Enterprise Information Systems (ICEIS2003), Angers, 4
France.
Papazoglou, M., & Georgakopoulos, D. (2003). Introduction to the special issue on service-oriented computing.
Communications of the ACM, 46(10).
Ratsimor, O., Joshi, A., Finin, T., & Yesha, Y. (2003). eNcentive: A framework for intelligent marketing in mobile peer-to-peer environments. Proceedings of the 5th International Conference on Electronic Commerce (ICEC’2003), Pittsburgh, Pennsylvania.
Valavanis, E., Ververidis, C., Vazirgiannis, M., Polyzos, G.C., & Norvag, K. (2003). MobiShare: Sharing contextdependent data & services from mobile sources. Proceedings of the 2003 IEEE/WIC International Conference on Web Intelligence (WI’2003), Halifax, Canada.
KEY TERMS
Ad-Hoc Network: It is a local area network or other small network, especially one with wireless or temporary plug-in connections, in which some of the network devices (sometimes mobile) are part of the network only for the duration of a communication session or because some of the devices are in some close proximity, so a communication session can take place.
Context: It is the information that characterizes the interaction between humans, applications, and the surrounding environment. Context can be decomposed into three categories: (i) computing context (e.g., network connectivity, communication cost); (ii) user context (e.g., user profile, location, nearby people); and (iii) physical context (e.g., lighting, noise levels).
Mobile Support Station: It is an equipment that manages mobile devices in terms of identifying their physical location and handling their incoming and outgoing messages/calls. A mobile support station always communicates with mobile users within its radio coverage area.
Software Agent: It is a piece of software that autonomously acts to carry out tasks on users’ behalfves. In agent-based applications, it is accepted that users only need to specify high-level goals instead of issuing explicit instructions, leaving the decisions of how and when to their respective agent. A software agent exhibits a number of features that make it different from other traditional components including autonomy, goal-orientation, collaboration, flexibility, self-starting, temporal continuity,
553
TEAM LinG
Replication Mechanisms Over a Set of Distributed UDDI Registries
character, communication, adaptation, and mobility. It should be noted that not all these features have to embody an agent.
UDDI Registry: The UDDI specifications define a way to publish and discover information on Web services. At a conceptual level, the information provided in a UDDI business registration consists of three components. First, the white pages component includes address, contact, and known identifiers. Second, the yellow pages component includes industrial categorization based on standard taxonomies. Finally, the green pages component includes the technical information about services that a business exposes. At a business level, the UDDI business registry can be used for checking whether a given partner has particular Web service interfaces, finding companies in a given industry with a given type of service, and locating information about how a partner or intended partner has exposed a Web service. The objective is to get aware of the technical details required for interacting with that service.
Web Service: It is an accessible application that other applications and humans can discover and trigger. The following properties define a Web service: (i1) independent as much as possible from specific platforms and computing paradigms; (ii2) developed mainly for inter-
organizational situations rather than for intra-organiza- tional situations; and (iii3) easily composable so that its composition with other Web services does not require developing complex adapters.
Wireless Environment: More and more people are equipped with handheld devices such as cell phones, PDAs, and laptops. To manage all these devices, a computing model is deployed. It consists of two entities: mobile clients and fixed hosts. Some of the fixed hosts, called mobile support stations, are augmented with wireless interfaces. A mobile support station communicates with the mobile clients within its radio coverage area called wireless cell. Each cell has an identifier that is periodically broadcasted to each mobile client residing in the cell. The aim is to be fully aware of the mobile clients that are under the management of the cell. Mobile clients get information from information servers, through the mobile support stations. As long as a mobile client stays in the coverage area of the same mobile support station, there are no major issues in pushing information to the client’’s mobile device. As soon as the client leaves that coverage area, another mobile support system has to be in charge of the information transfer.
554
TEAM LinG

|
555 |
|
Replication Methods and Their Properties |
|
|
|
4 |
|
|
|
|
|
|
|
Lars Frank
Copenhagen Business School, Denmark
INTRODUCTION
The most important evaluation criteria for replication methods are availability, performance, consistency, and costs. Performance and response time may be improved by substituting remote data accesses with local data accesses to replicated data. The availability of the system can be increased by using replicated data in case a local failure or disaster should occur. The major disadvantages of data replication are the additional costs of updating replicated data and the problems related to managing the consistency of the replicated data. Tables 1 and 2 give an overview of the evaluation of the replication methods described in this article. Frank (1999) described how such replication overviews may be used to optimize databases in practice. This article evaluates many more replication methods and therefore, it is possible to optimize even more. However, the evaluation criteria previously described have to be subdivided to illustrate the different properties of the different replication methods.
BACKGROUND
Different versions of the 1-safe and 2-safe designs have been described in Garcia-Molina and Polyzois (1990); Polyzois and Garcia-Molina (1994); Gallersdörfer and Nicola (1995); and Humborstad, Sabaratnam, Hvasshovd, and Torbjornsen, (1997). The 0-safe design with local commit has been used in practice for a number of years and was described by Frank and Zahle (1998). The 2-safe design, the basic 1-safe design, the 1-safe design with commutative updates, and the 0-safe design with local commit have all been described and evaluated in detail by Frank (1999), and where it is possible, the evaluations will be reused in this article. The countermeasure transaction model is the first transaction model that systematically tries to describe how to eliminate or reduce the consistency and anomaly problems, which some replication methods may cause. This transaction model owes many of its properties to Garcia-Molina and Salem (1987), Mehrotra, Rastogi, Korth, and Silberschatz (1992), Weikum and Schek (1992), and Zhang, Nodine, Bhargava, and Bukhres (1994). Many new versions of the classic replication designs have
Table 1. Evaluation overview of some of the most important table replication designs
Evaluation |
|
DBMS supported replication methods |
|
|||
criteria |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n-safe |
n-safe |
1-safe design. |
1-safe design |
0-safe design |
0-safe |
|
design |
design |
Basic solution |
with com- |
with |
designs with |
|
with the |
with the |
|
mutative |
local commit |
deferred |
|
ROWA |
quorum |
|
updates |
|
commit |
|
protocol |
protocol |
|
|
|
|
Read |
Best |
Worst |
Average |
Average |
Best |
Best |
performance/ |
|
|
|
|
|
|
capacity |
|
|
|
|
|
|
Write |
Worst |
Above worst |
Average |
Average |
Best |
Below best |
performance |
|
|
|
|
|
|
Ease of failure |
Average |
Average |
Worst |
Average |
Best |
Best |
recovery |
|
|
|
|
|
|
Ease of disaster |
Best |
Below best |
Above worst |
Average |
Average |
Average |
recovery |
|
|
|
|
|
|
Probability of |
Best. |
Below best |
Worst |
Average |
Average |
Average |
lost data1 |
pn |
p n/2 |
p |
|
|
|
|
|
|
|
|
|
|
Logging of the |
Not |
Not |
Not supported |
Recom- |
Recom- |
Recom- |
update |
supported |
supported |
|
mended |
mended |
mended |
transaction2 |
|
|
|
|
|
|
Availability3 |
1-qn |
1-qn |
1-qn |
1-qn |
1-qn |
1-qn |
Atomicity |
Best |
Best |
Worst |
Best |
Best |
Best |
Consistency |
Best |
Best |
Average |
Average |
Worst |
Worst |
Isolation |
Best |
Best |
Average |
Average |
Worst |
Worst |
Durability |
Best |
Best |
Worst |
Best |
Best |
Best |
Development |
Best |
Best |
Best |
Average |
Worst |
Worst |
costs |
|
|
|
|
|
|
been described in recent years. The most important versions are described after the corresponding classic design. How to use different replication methods to optimize and integrate ERP and e-commerce system have been described in detail by Frank (2004).
In the following, I will first describe the criteria used to evaluate the replication methods. Next, I will describe the most important replication methods used in practice. I do not prove that the evaluations illustrated in Tables 1 and 2 are correct, but arguments for the evaluations are presented. However, Frank (1999) has proved that the evaluations are correct for some of the described replication methods, and I believe that Frank’s
Table 2. Evaluation overview of operating system replication methods
Evaluation criteria |
|
|
Operating system replication methods |
|
||
|
|
|
|
|
||
|
Mirroring with disk |
Mirroring without |
Remote caching in a |
Local caching in |
||
|
volume ownership |
disk volume |
fast storage |
the user location |
||
|
|
|
ownership |
|
|
|
Read performance/ |
Average |
|
Best |
|
Average |
Best |
capacity |
|
|
|
|
|
|
Write performance |
Average |
|
Above worst |
Average |
Average |
|
Ease of failure recovery |
Average |
|
Average for roll back |
Average |
Not supported |
|
|
|
|
recovery |
|
|
|
Ease of disaster |
Below best |
Below best |
Not supported |
Not supported |
||
recovery |
|
|
|
|
|
|
The probability of lost |
Best |
pn |
Best |
pn |
Worst |
Worst |
data |
|
|
|
|
|
|
Availability |
1-qn |
|
1-qn |
|
1-q2 |
1-q2 |
Atomicity |
Best |
|
Not supported |
Best |
Not supported |
|
Consistency |
Best |
|
Not supported |
Best |
Not supported |
|
Isolation |
Best |
|
Not supported |
Best |
Not supported |
|
Durability |
Best |
|
Not supported |
Best |
Not supported |
|
Development costs |
Best |
|
Best |
|
Best |
Best |
Copyright © 2006, Idea Group Inc., distributing in print or electronic forms without written permission of IGI is prohibited.
TEAM LinG
proof can be expanded to encompass all the replication methods described in this article.
Description of the Evaluation Criteria for Replication Methods
In this article, the properties of the replication designs are normally described as best, average, below average, worst, and so forth, which allows us to compare the designs relatively. In general, it is not possible to select one of the replication designs as the best because all the designs have very different properties. However, if the requirements of an application are known, it is possible to select the most inexpensive design that fulfills the needs of the application. Next is a short description of the evaluation criteria used in this article.
The read performance/capacity property of a table design is evaluated to be best if remote readings always can be substituted by local readings. The n-safe design with the quorum protocol has the worst read performance/capacity because it is always necessary to lock a majority of the record copies to implement the isolation property.
The write performance/capacity property of a table design is evaluated to be best if a global table update always can be committed locally without communication with other locations. The n-safe design with the read one, write all (ROWA) protocol is evaluated to be worst in terms of write performance because it is always necessary to lock all the record copies to implement the isolation property.
After a local failure, the local database and its log files are not physically destroyed, and in contrast to database disasters, it is always possible to repair the site in such a way that operation may continue by using the failed site. Ease of failure recovery is evaluated to be best if the system automatically can make recovery without aborting all noncommitted transactions in case of a site failure. Ease of failure recovery is evaluated to be average if the system always has to abort noncommitted transactions in case of a site failure. The basic 1-safe design is evaluated to have the worst ease of failure recovery because even committed transactions may be lost after a failure in which a secondary copy is used as the primary copy (lost transactions).
A database disaster is as a situation in which a local database and its log files are destroyed. Ease of disaster recovery is evaluated to be best if it is possible to repair the database automatically. The no replication design is evaluated to be worst in terms of ease of disaster recovery because, at best, only an old, remote database copy can be used for recovery.
In case of a disaster, data may be lost. The probability
Replication Methods and Their Properties
of avoiding lost data is evaluated to be better the lower the probability.
In case of a disaster, committed transactions may be lost, except in the n-safe designs. Therefore, the evaluation criteria, that is, ease of disaster recovery and availability, depend on the evaluation criterion, logging of the update transactions in the locations of the clients.
The availability of a database can be defined as the probability of having access to the database.
An update transaction is atomic if all or none of its updates are executed. The atomicity property of a table design is evaluated to be best if the database management systems (DBMSs) and the transaction model can guarantee the property, even in case of failure. The basic 1-safe design is evaluated to be worst in terms of the atomicity property because lost transactions may occur after the commitment of a transaction.
A database is consistent if the data in the database complies with some user-defined consistency rules. Transactions have by definition the consistency property if they fulfill the following condition:
“If a database is consistent when a transaction starts, the database must also be consistent when the transaction has been committed.”
The consistency property of a table design is evaluated to be best if the DBMSs and the transaction model can guarantee the property even in case of failure. The 0- safe designs are evaluated as worst in terms of consistency property, because in these designs the distributed database is normally inconsistent, and therefore only asymptotic consistency can be implemented( i.e., the database converges towards a consistent state).
Transactions are executed in isolation if the updates of each transaction can be seen only by other transactions after the updates have been committed or aborted. The isolation property of a table design is evaluated to be best if the DBMSs and the transaction model can guarantee the property even in case of failure. The 0- safe designs are evaluated to be worst in terms of isolation property because all types of isolation anomalies may occur if they are not managed by adopting countermeasures (Frank & Zahle, 1998).
The updates of transactions are said to be durable if they are stored in stable storage and secured by a log recovery system. The durability property of a table design is evaluated to be best if the DBMSs and the transaction model can guarantee the property even in case of failure. The basic 1-safe design is evaluated to be worst in terms of the durability property, because lost transactions may occur after the commitment of a transaction (i.e., the updates are not durable in case of a failure where a secondary copy is used as the primary copy).
556
TEAM LinG

Replication Methods and Their Properties
The development costs of a table design are evaluated to be best if no special application programming is needed (i.e., all replication problems are managed by using DBMS tools). Therefore, the development costs of the n-safe designs, the no-replication design, and the basic 1-safe design have the best rating in Table 1. The development costs of the 0-safe designs are evaluated as worst because in these designs one has to select and implement countermeasures against the lost update anomaly, the dirty read anomaly, the nonrepeatable read anomaly, and the phantom anomaly (Berenson et al., 1995; Breibart, Garcia-Molina, & Silberschatz, 1992). The development costs of the 1-safe design with commutative updates are evaluated as average because in this design it is only necessary to implement countermeasures against the lost update anomaly.
DESCRIPTION OF THE MOST IMPORTANT REPLICATION METHODS
In Table 1, the replication methods described by Frank (1999) are evaluated together with the main types of the n-safe design and a group of 0-safe designs that have deferred commit. This article will also evaluate replication designs that can be implemented as part of the operating system, and, therefore, cannot automatically support ACID properties.
All the n-safe designs described in this article can be optimized by using the so called atomic broadcast protocol (Hadzilacos & Toueg, 1993; Weismann, Pedone, Schiper, Kemme, & Alonso, 2000). This is a group communication technique in which messages from the coordinator are delivered in the same order in all the participating locations. This property can simplify the distributed concurrency control if the coordinator uses the atomic broadcast protocol to transfer the execution order in the coordinator location to the locations of the participants. This is possible if data are replicated in such a way that the coordinator can execute transactions locally and, only at the end, uses the atomic broadcast protocol to coordinate the update of replicated data. At the same time, performance is improved, as there is communication between the involved locations once per transaction and not once per data access. However, the improved performance possibilities are not reflected in Table 1, as the atomic broadcast protocol has not been implemented in any commercial DBMS product. All the n-safe designs described have eager replication (i.e., the updates of transactions are propagated to any replicated copies before the commit of the transactions).
Performance of the 1-safe and 0-safe designs can be optimized by lazy replication, by which the updates to any replicated copies are propagated after the commitment of the updating transaction. This improves the
response time at the cost of the consistency between replicated data. The atomic broadcast protocol described 4 cannot improve the performance of the lazy replication designs, as the transactions have already been commit-
ted when the update of replicated data takes place. However, the performance of the 1-safe designs and 0- safe designs can be improved in the same way as the n- safe designs by replicating data in such a way that transactions can run locally until commitment.
The n-Safe Design with the ROWA Protocol and the 2-Safe Design
The 2-safe design is a special case of the n-safe design, in which only two copies of a file exist. In the 2-safe design (Gray & Reuter, 1993), the primary/coordinating transaction manager involves the backup/participant system in the commit. If the participant system is up, the coordinating transaction manager sends the log records of the transaction at the end of commit phase 1. The coordinating transaction manager will not commit until the participant responds (or is declared down). The 2-safe design has good ratings in read capacity, consistency, isolation and easiness of failure/disaster recovery. The main problem is the poor write performance and a high risk of transaction restarts in case of major failures in one of the database locations or in the network connecting the locations. The 2-safe design may easily be generalized to the n-safe design, where n>2. In the n-safe design, the coordinating transaction manager commits an update as a function of the n-1 participating transaction managers’ responses. There are many versions of the n-safe design. However, in all the versions it is possible to optimize the write performance if the participating transaction managers answer immediately without first forcing the log records to durable storage. This is acceptable in the n-safe design because, in case of a disaster, it is extremely unlikely that all n copies of the log are involved in the disaster. Anyway, the n-safe design still has a relatively low write performance.
ROWA means that in terms of reading, only one copy of the record is read, and in terms of writing, all the copies must be written/updated. The n-safe design with the ROWA protocol has the best read perfor-
Figure 1. 2-safe database design
|
Coordinator location |
Participant location |
Client |
Log records |
|
|
||
Commit |
Commit |
|
|
|
|
557
TEAM LinG

mance, as a local record copy often can be used. The write performance is evaluated as worst, as all record copies must be locked before an update can be executed. The ROWA protocol is very vulnerable to both communication and site failures. The read one, write all available (ROWAA) protocol is a new version of the ROWA protocol. It is tolerant to both communication and site failures at the cost of controlling all participating copies available when the transaction is committed (e.g., Coulouris, Dollimore, & Kindberg, 2001). However, this extra control reduces the performance for all transactions. In stable networks, where failures are rare, it is therefore much better to restart the traditional ROWA protocol with a new value of n in case of communication or site failures.
The n-Safe Design with the Quorum Consensus Protocol
The quorum consensus protocol is tolerant to both communication and site failures, as only a number of locations with a quorum is necessary for accessing data. In the quorum consensus protocol, a number of votes is assigned to each copy. Each read operation must obtain a read quorum R before it can execute the read operation, and each write/update operation must obtain a write quorum W before it can execute the write/update. To obtain the isolation property, R and W must be selected in such a way that W is greater than half the amount of votes, and R + W are greater than the total number of votes. If R = 1, W = the number of locations with a copy, and each location has one vote, the quorum consensus protocol specializes itself to the ROWA protocol, and therefore it is assumed in the following that R is greater than 2. In this case, the ROWA protocol has a better read performance than the quorum consensus protocol as the ROWA protocol only has to read one copy. The quorum consensus protocol has a better write performance than the ROWA protocol as the quorum consensus protocol only has to lock W copies before it is possible to write/update replicated data. The quorum consensus protocol provides better availability than the ROWA protocol as the quorum consensus protocol can tolerate some communication and site failures.
Replication Methods and Their Properties
Figure 2. 1-safe database design
Primary location |
Secondary location |
Client
Commit
Log records
Commit
continue by selecting one of the secondary copies as a new primary copy. When the failure in the old primary copy location has been repaired, the log records from this location cannot always be used to update the new primary location (former secondary copy) because the records in the new primary copy may have been updated. Lost transactions are defined as the updates committed in the failed old primary copy and not in the new primary copy at the time production restarts in the new primary location. The main problem with the 1-safe design is that the lost transactions must be reconstructed and reexecuted before the recovery process is finished. Discontinuing production after a failure may prevent this problem. Therefore, selection of a new primary copy is only used in case of a disaster or a very serious failure.
The 0-Safe Design with Local Commit
The 0-safe design with local commit is defined as n table copies in different locations, where each transaction first will go to the nearest database location where it is executed and committed locally. If the transaction is an update transaction, the transaction propagates asynchronously to the other database locations where the transaction is reexecuted without user dialogue and committed locally at each location. This means that all the table copies normally are inconsistent and not up to date under normal operation. The inconsistency must be managed by using countermeasures against the isolation anomalies. For example, to prevent lost updates in the 0- safe design, all update transactions must be designed to be commutative (Frank & Zahle, 1998). From a performance and disconnection point of view, the 0-safe de-
The Basic 1-Safe Design
In the basic 1-safe design (Gray & Reuter, 1993), the primary transaction manager goes through the standard commit logic and declares completion when the commit record has been written to the local log. In a 1-safe design, the log records are asynchronously spooled to the locations of the secondary copies. In case of a primary site failure in the 1-safe design, production may
Figure 3. 0-safe database design
|
Nearest location |
Remote location |
Client |
Trans. record |
|
Commit |
|
|
|
|
|
|
Commit |
|
558
TEAM LinG

Replication Methods and Their Properties
sign with local commit is the best choice and, therefore it is recommended for mobile computing. Other versions of the 0-safe design where commitment is deferred are described later.
The 1-Safe Design with Commutative Updates
The 1-safe design can transfer updates to the secondary copies in the same way as the 0-safe design. In this design, lost transactions cannot occur because the transaction transfer of the 0-safe design makes the updates commutative. The properties of this mixed design will come from either the 1-safe or the 0-safe design. The 1- safe design with commutative updates does not have the high update performance and capacity of the 0-safe design. On the other hand, in this design the isolation property may be implemented automatically as long as the primary copy does not fail. Normally, this makes it much cheaper to implement countermeasures against the isolation anomalies, because it is only necessary to secure that the lost transactions are not lost in case of a primary copy failure.
The 0-Safe Designs with Deferred Commit
The 0-safe designs with deferred commit are defined as a group of replication methods in which a global transaction first must update the local copy closest to the user by using a compensatable subtransaction. Later, the local update may be committed globally by using one of the following designs:
•0-safe design with primary copy commit, in which the global transaction may be committed/rejected in a (remote) primary copy location. If the update of the primary copy is committed, retriable subtransactions will be propagated to the rest of the secondary copy locations, which must be updated and committed sooner or later. However, if the update of the primary copy is rejected, a compensating subtransaction must be propagated to the location where the transaction was first created.
•0-safe design with all participants commit, in which the global transaction may be committed if all the participating locations with local copies can accept the original compensatable updating.
•0-safe design with token commit, in which the global transaction may be committed when the user who initiated the compensatable
subtransaction receives a “token” that excludes all
other users from committing global transactions. 4
Mirroring
Mirroring techniques enable the operating system (eventually supported by hardware) to write the data simultaneously on different disks in such a way that the data is replicated two or more times, as needed. Mirroring methods may be grouped the same way as the n-safe, 1- safe and 0-safe designs. However, this article only evaluates n-safe mirroring methods, as these methods have the most interesting properties compared to the corresponding n-safe designs. Mirroring replication methods can also be grouped according to the processes that can access data under normal operations. In mirroring with disk-volume ownership, a single concurrency managing process owns a disk volume and its mirrored data as long as the process is operative. Therefore, read performance is average, as all reads must go through this process. However, in this situation it is also possible optimize write performance to average, as distributed locking is not necessary. Failure recovery is the same as in a central database, except that a database copy may fail without any problems. Therefore, it does not matter that mirroring does not support ACID properties in this situation. In mirroring without disk-volume ownership, concurrent processes with their own local DBMS may lock data in a ROWA-like fashion, and therefore the read performance is best and the write performance close to worst.
Caching
Cached data is a snapshot of some frequently used data. Normally, cached data is incomplete, and therefore it is not suited for disaster recovery. In remote caching, a primary copy of the frequently used data is normally stored on a very fast medium to optimize access to data. In local caching, an often-inconsistent secondary copy of the frequently used data is stored in or close to the location of some users to optimize their access to the data. The local cache may be updated periodically or when a local user makes an update. Therefore, the local cache is often inconsistent.
FUTURE TRENDS
Many new versions of the classic replication designs have been described in recent years, and I believe that this process will continue. However, a new important trend is that hybrid replication protocols ( e.g., see Irún, Muñoz, & Bernabéu, 2003) can be developed in such a
559
TEAM LinG