

Rivero L.Encyclopedia of database technologies and applications.2006
.pdfRaster Databases
Figure 5. Row-major linearization of a 2-D cell array, followed by compression; “X” cells show some region getting scattered on disk, thereby rendering all but horizontal access inefficient
significantly increasing storage need. Further, the core advantage, addressability without materializing coordinates, is lost at the moment compression is applied. Finally, depending on the linearization scheme chosen, access in a particular direction is favored (e.g., horizontal reading) while all other access patterns are severely degraded.
system generated partitioning is possible (Figure 6). A geo index is employed to quickly determine the tiles affected by a query. Optionally, tiles are compressed for storage using one of various choices; additionally, query results can be compressed for transfer to the client. Both tiling strategy and compression comprise database tuning parameters. Tiles and index are stored as BLOBs in a
•Sets of tuples containing (coordinate, value) pairs: relational database which also holds the data dictionary Obviously, this technique, which is used in relaneeded by rasdaman’s dynamic type system. Hence, the
tional OLAP (ROLAP), is particularly suitable for sparse data—the overhead of storing coordinates is more than compensated by avoiding materialization of non-existing values. Conversely, no one would seriously consider storing (dense) images this way.
•Hybrid, two-level approaches: There, MDD objects are partitioned into sub-arrays called tiles or chunks. Tiles are stored together with their coordinate extent; inside, each tile value is stored linearized. Tiles this way naturally form the unit of storage access. Cell access is fast, except when tile boundaries are crossed and another tile has to be loaded.
Note that the first two alternatives form special cases of this method. In the case that the partition consists of only one item, we obtain the linearized scheme; if each partition contains exactly one cell, we have the set-of-tuples case.
Actually, this partitioning method is not new at all; it has been used in the imaging community for decades to handle images larger than main memory.
In rasdaman, raster objects are maintained in a standard relational database following the tiling approach (Furtado, 1999). Aside from regular grids, any user or
Figure 6. Sample 2-D tilting
RDBMS simply acts as a persistent store for moderately sized BLOBs with OIDs, allowing use of virtually any DBMS.
Query Evaluation
Queries are parsed, optimized, and executed in the rasdaman server. The parser receives the query string and generates the operation tree. Query evaluation is tile based meaning that, whenever possible, each MDD object affected is inspected tile by tile. In many cases, this allows that at any given moment, only one tile per MDD has to be kept in server main memory. In some cases, like aggregate operations and predicate evaluation, there is a chance for premature termination of tile stream evaluation.
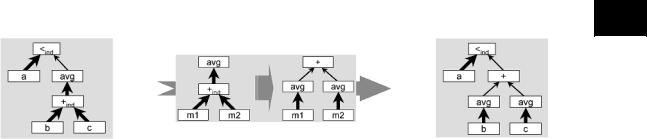
A number of optimizations (Ritsch, 1999) is applied to a query tree prior to its execution (Widmann, 2000). As an example, consider the query
SELECT a < avg_cells(b+c) FROM a, b, c
Figure 7 shows the pertaining operator tree where opind indicates that operation op is induced, that is, applied to all cells of the MDD operand. Obviously, such operations are particularly costly. Bold arrows in the tree denote that MDD tiles have to be streamed into the operator, and regular arrows denote scalars (like single numbers) flowing into the operator. The optimization rule applicable in this case, Figure 7, says “averaging over an MDD which is the sum of two MDDs is equivalent to first averaging over the MDDs and then summing.” Figure 7 shows the modified tree; we find that the original tree contained four tile streams while the optimized tree contains only three, yielding a performance gain by 25%.
520
TEAM LinG
Raster Databases
Figure 7. Original parse tree (left), optimization rule (center), optimized tree (right)
4
Altogether, rasdaman knows about 150 algebraic rewriting rules; 110 are actually optimizing while the other 40 serve to transform the query into canonical form.
Current work involves parallel evaluation of rasql queries (Hahn & Reiner, 2002), the idea being that tiles form a natural unit for assigning work to different processors. To accommodate arrays larger than disk space, hierarchical storage management (HSM) support is being investigated (Reiner & Hahn, 2002; Sarawagi & Stonebraker, 1994).
Benchmark Results
The following benchmark (Table 1), based on a real-world GIS scenario, is taken from Baumann (2001); see there for details. They have been obtained on a a Pentium III based Linux notebook (650 MHz) with 256 MB main memory. It ran an Oracle 8.1.7 server together with the rasdaman server and the query client, plus the X server. Data sets used were a 36,000×36,000 aerial image (Ortho), a 48,000×47,000 topographical map (1:10,000) containing nine thematic layers (Tk10), and a Digital Elevation Model (Dem). The JPEG images generated by the queries varied between 10 kB and 25 kB in size. Aerial image zoom factors were chosen randomly; no difference was observed in response time.
FUTURE TRENDS
Research on database support for multidimensional raster support is still in its infancy. While basic concepts have been clarified and first reference implementations are available, there is a wealth of open research topics; the following non-exhaustive list indicates some of them:
•unified modeling for statistical and sensor/image databases;
•design methodologies;
•expressiveness of raster languages;
•optimization of complex queries; while there is a large body of research for statistics databases, the field is rather new for sensor/image databases;
•orchestration of MDD with other data types to form comprehensive real-world descriptions;
•improved understanding of tuning parameters;
•standardized benchmarks; and
•best-practice know-how for application modeling in the various application fields.
CONCLUSION
There is a strong application pull for raster data management in various fields, such as geo-services, life science,
Table1. Benchmark results for selected real-life queries
|
|
Query type |
Average |
|
|
|
elapsed time |
SELECT |
jpeg( scale( Ortho[x0:x1,y0:y1], f ) * {1c,1c,1c} ) |
0.381 sec |
|
FROM |
Ortho |
|
|
SELECT |
jpeg( |
|
0.360 sec |
scale( bit(Tk10[x0:x1,y0:y1],streets), f ) * {255c,0c,0c} |
|
||
|
) |
|
|
FROM |
Tk10 |
|
|
SELECT |
(Dem < |
5.0) * {255c,0c,0c} |
0.887 sec |
|
+ (Dem > |
5.0 AND Dem < 100.0) * {0c,255c,0c} |
|
|
+ (Dem > 100.0) * {0c,0c,255c} |
|
|
FROM |
Dem |
|
|
521
TEAM LinG
and grid computing. They all have huge assets in common, and research has shown that unified, cross-domain support is feasible. The ultimate goal should be similar to what has been achieved with full-text search and databases: information systems where raster objects are seamlessly embedded in general document structures, raster retrieval forming an integral part of overall retrieval facilities.
REFERENCES
Arya, M., Cody, W., Faloutsos, C., Richardson, J., & Toga, J. (1994). QBISM: Extending a DBMS to support 3D medical images. Proceedings of the 10th International Conference on Data Engineering (ICDE’94).
Baumann, P. (1994). On the management of multidimensional discrete data. VLDB Journal, Special Issue on Spatial Database Systems, 4(3), 401-444.
Baumann, P. (1999). A database array algebra for spatiotemporal data and beyond. Proceedings of the 5th Workshop on Next Generation Information Technologies and Systems (NGITS’99), Zikhron-Yaakov, Israel.
Baumann, P. (2001). Web-enabled raster GIS services for large image and map databases. Proceedings of the 5th International Workshop on Query Processing and Multimedia Issues in Distributed Systems (QPMIDS 2001),
Munich, Germany.
Buneman, P. (1993). The discrete fourier transform as a database query (Tech. Rep. No. MS-CIS-93-37). University of Pennsylvania.
Chock, M., Cardenas, A., & Klinger, (1984). Database structure and manipulation capabilities of a picture database management system (PICDMS). IEEE ToPAMI, 6(4), 484-492.
Furtado, P. (1999). Storage management of multidimensional arrays in database management systems. PhD thesis, Technische Universität München.
Hahn, K., & Reiner, B. (2002). Parallel query support for multidimensional sata: Inter-object parallelism. Proceedings of the DEXA, Aix en Provence, France.
Joseph, T., & Cardenas, A. (1988). PICQUERY: A high level query language for pictorial database management. IEEE ToSE, 14(5), 630-638.
Kleese, K. (2000). A national data management centre.
Proceedings of the 1st International Workshop on Advanced Data Storage/Management Techniques for High Performance Computing, Daresbury Laboratory, UK.
Raster Databases
Libkin, L., Machlin, R., & Wong, L. (1996). A query language for multidimensional arrays: Design, implementation, and optimization techniques. Proceedings of the ACM SIGMOD (pp. 228-239).
Lorie, R.A. (1982). Issues in databases for design applications. In J. Encarnaçao & F.L. Krause (Eds.), File structures and databases for CAD. North-Holland.
Marathe, A.P., & Salem, K. (1997). A language for manipulating arrays. Proceedings of the VLDB’97 (pp. 46-55).
Marathe, A.P., & Salem, K. (1999). Query processing techniques for arrays. Proceedings of the ACM SIGMOD ’99 (pp. 323-334).
Reiner, B., & Hahn, K. (2002). Hierarchical storage support and management for large-scale multidimensional array database management systems. Proceedings of the DEXA, Aix en Provence, France.
Ritsch, R. (1999). Optimization and evaluation of array queries in database management systems. PhD thesis, Technische Universität München.
Ritter, G., Wilson, J., & Davidson, J. (1990). Image algebra: An overview. Computer Vision, Graphics, and Image Processing, 49(3), 297-331.
Sarawagi, S., & Stonebraker, M. (1994). Efficient organization of large multidimensional arrays. Proceedings of the ICDE’94 (pp. 328-336).
Tamura, H. (1980). Image database management for pattern information processing studies. In F. Chang (Ed.),
Pictorial information systems (pp. 198-227). LNCS 80. Springer.
Vandenberg, S., & DeWitt, D. (1991). Algebraic support for complex objects with arrays, identity, and inheritance.
Proceedings of the ACM SIGMOD Conference (pp. 158167).
Widmann, N. (2000). Efficient operation execution on multidimensional array data. PhD thesis, Technische Universität München.
KEY TERMS
Array: An item of this information category consists of a nonempty set of (point,value) pairs where the points have n-D integer coordinates and together completely cover an n-D interval, the so-called spatial domain of the array.
BLOB: “Binary large object”; a (usually large, i.e., MB to GB) byte string stored in the database; the DBMS does
522
TEAM LinG

Raster Databases
not have any knowledge about the semantics of the byte string; hence, it cannot offer semantically adequate functionality and query optimization.
Hierarchical Storage Management (HSM): An extension of storage management to include tape media as “tertiary storage”, thereby extending “primary storage” (main memory) and “secondary storage” (disks) by an additional hierarchy level. For management of spatiotemporal objects such as raster data, spatial clustering on tape is an issue to minimize data access and tape load cycles.
MDD (Multidimensional Discrete Data): Array.
Raster Data: The information category of arrays, also called MDD.
Raster Database (Management) System: A DBMS which offers support for storage and retrieval of 4 raster data.
Tiling: The technique of decomposing raster data objects into smaller raster items (“tiles”) for storage purposes. Tiling should not be visible to the user but should be resolved internally by the database system.
Spatial Clustering: Storage techniques to place data items which have spatio-temporal proximity at neighboured storage locations. Based on the assumption that data access patterns convey some locality behavior, access performance can be improved.
523
TEAM LinG
524
Real-Time Databases
Alejandro Buchmann
Technische Universität Darmstadt, Germany
INTRODUCTION
A variety of applications in the areas of control, navigation, mobile systems, telecommunications, and simulation depend on the timely and predictable delivery of data. Aircraft and spacecraft control are characterized by small main-memory databases with extremely short mean-latency requirements. Onboard navigation systems tend to combine a small portion of dynamic data with large amounts of static data, e.g., maps and landmark information. The same is true for many simulation environments, e.g., flight simulators or virtual test benches, where some parts of the system are simulated and some parts are physical components. In telecommunications the notion of real time is interpreted mostly statistically, i.e., a predetermined percentage of transactions must meet their deadline. Demanding requirements are imposed by mobile networks with extremely high transaction rates and short response times. A requirements analysis of real-time database systems can be found in Buchmann and Liebig (2001); Locke (1997); Purimetla, Sivasankaran, Ramamritham, and Stankovic (1995); and Raatikainen (1997).
Real-time database systems have two distinct properties that set them aside from conventional generalpurpose database systems: The data in the database has time semantics associated with it, and the DBMS must be time-cognizant in order to meet the timing requirements of the transactions. Therefore, the correctness criteria of a real-time database system, in addition to those of conventional databases, include the temporal consistency of data and the time-constrained execution of transactions. A major difference between conventional and real-time databases is the focus on individual transactions. While conventional database systems stress fairness and throughput, real-time systems must ensure that critical transactions are executed in a timely manner. An excellent discussion of common misconceptions about real-time databases is found in Stankovic, Son, and Hansson (1999). Good surveys and background information can be found in Bestavros, Lin, and Son (1997); Ramamritham (1993); and Ramamritham, Son, and DiPippo (2004).
Real-time databases are used in real-time systems that consist of a controlled system, the environment, and a controlling system, the computational system that
coordinates the activities of the controlled system. The state of the environment is typically captured by sensors, whose readings make up a significant portion of the data in a real-time database. For the controlling system to have an accurate view of the state of the controlled system, the monitoring of the environment must occur in a timely fashion. For the actions prescribed by the controlling system to arrive and be executed in time, it is necessary to process the data under timing constraints. Timing constraints in a real-time database system are thus derived both from the limited temporal validity of data and the timing requirements of the environment (Ramamritham, 1993; Ramamritham et al., 2004).
TEMPORAL CONSISTENCY
Temporal consistency of data has two aspects. Absolute temporal consistency defines the consistency between the state of the environment and the data in the database describing the state of the observed physical system at a given time. Relative temporal consistency refers to the temporal proximity of data that is used for deriving other data and reflects the fact that measurements of data used together in a computation should be taken within a specified time interval.
All time-sensitive data in a real-time database must carry a time stamp (ts). In addition to the time stamp, data values have a validity interval associated during which data is deemed to be sufficiently fresh to accurately reflect the state of the environment. We call this the absolute validity interval (avi). Absolute temporal consistency is thus defined as a triplet d:(value, avi, ts). If at any time t the difference between t and ts is smaller than avi, the data value has absolute temporal consistency.
If a computation uses data collected by multiple sensors at different times, relative temporal consistency ensures that these readings were not taken too far apart in time and thus ensures that the result is still meaningful. The relative consistency set R includes all the data involved in a computation. R has a relative validity interval (rvi) which specifies the maximum permissible difference between the time stamps of the data in R. For the data in R to possess relative temporal consistency, the difference between the time stamps of
Copyright © 2006, Idea Group Inc., distributing in print or electronic forms without written permission of IGI is prohibited.
TEAM LinG

Real-Time Databases
the data in R taken pair-wise must be smaller than rvi. Note that relative temporal consistency is only required for data being used together in deriving other data or some triggering condition for an action.
We can now state that d in a given relative consistency set R is temporally consistent if it fulfils the conditions for:
Absolute temporal consistency: (t-ts) ≤ avi
Relative temporal consistency: di R, | tsi – tsj | ≤ rvi
A real-time database is consistent if it fulfils the normal consistency criteria and is temporally consistent. However, while in a standard database system consistency is preserved by not executing a transaction, in a real-time database consistency must be actively restored since the progress of time causes temporal inconsistency independent of the execution of transactions.
TIMING CONSTRAINTS
In a real-time database system there are two sources of timing constraints: the freshness requirement of the data given by their respective avi and the dynamics of the system that require that computations be available at a given time. For example, a robot navigating a factory floor must have completed its computation (possibly involving data from the real-time database) before it gets to the point at which it must turn.
Absolute validity intervals translate into timing constraints on the sampling process, i.e., the sensor reading must be updated with a frequency proportional to the avi (typically avi/2). However, if data is used with other data in a relative consistency set R, then the highest sampling frequency, i.e. the lowest avi in the set R, must be applied to all data in R. Similarly, if one data item belongs to multiple relative consistency sets, the lowest rvi prevails. A detailed discussion on deriving timing constraints from the data’s time semantics can be found in Ramamritham (1993). Timing constraints derived from the temporal consistency requirements of the data are usually periodic.
The timing constraints on reactions to a change of state in the system typically are aperiodic. This could be a reaction to an observed movement of a ship. From the application’s point of view, the timing constraint specifies the maximum time that may pass before a given (corrective) action is completed, i.e., the deadline. Given that most controlled systems include other components, for example, mechanical components with con-
siderable lag time, we must deduct those time requirements to calculate the available time for computation. 4 From the point of view of a real-time database, we are
only interested in the time available for performing database transactions, be these write-only transactions used for writing sensor data, read-only transactions that retrieve data and pass them on to actuators, or update transactions that read from the database, derive new data, and store these back in the database.
Deadlines and the corresponding timing constraints are best characterized through a value function. It indicates the value for the overall system that a task is completed at a given time. If the task or transaction is completed before its deadline, the full value is derived from it. But if the deadline cannot be met, three different situations can arise:
•a smaller positive value is derived from the late execution of a transaction, in which case we speak of soft deadlines and soft real-time constraints;
•no value is derived from late execution, i.e., the value function drops to zero at the deadline;
•a (potentially large) negative value results from late execution; in some cases this is associated with the loss of life and property.
Some authors distinguish between firm and hard deadlines, others consider any transaction without a positive value if completed late to be hard real-time. Within the same system, tasks with soft and hard deadlines can coexist.
Dealing with deadlines raises one important question: How can we determine if a transaction will meet its deadline? This issue has been at the heart of many controversies in the real-time database community. To predict whether a transaction will complete before the deadline or not, it is necessary to know its time of execution. If the real-time database system must give guarantees that a transaction will complete before its deadline, the worst-case execution time is required. If no execution times can be determined, then the only alternative is to evaluate after completion whether the deadline was met or not.
One important difference between conventional and real-time database systems is the fact that in conventional systems, transactions carry no timing information beyond an arrival time stamp. They don’t have deadlines and, consequently, execution times of individual transactions are immaterial. Performance of the system is measured by throughput irrespective of individual transactions. Real-time databases, on the other hand, are concerned with the timely execution of individual transactions which have individual deadlines that must be met. Therefore, execution times of individual
525
TEAM LinG
transactions are important and necessary for the timecognizant protocols (schedulers, concurrency control protocols) to work properly.
DETERMINING EXECUTION TIMES
Execution times depend on a variety of factors (Buchmann, Dayal, McCarthy, & Hsu, 1989). We can dissect the contributions to the total execution time of an application task with an embedded transaction as follows:
texec = tdb + tI/O + tint + tappl + tcomm
where tdb is the portion of the time consumed by the processing of the database operators, e.g., selections, projections or joins; tI/O is the portion spent on I/O, e.g., disk accesses; tint is the time due to transaction interfer-
ence, e.g., waiting for locks; tappl is the time spent processing the non-database part of the application code;
and tcomm is the time consumed by communication. To determine worst-case execution times in a deterministic
manner, each of these contributing elements must have an upper bound.
The duration of database operations depends on the data. To establish an upper bound for tdb it is necessary to limit the size of data, e.g., the number of tuples in a relation. This is commonly done in real-time systems
since it is also the basis for calculating tappl. The path an execution takes also depends on the data. To constrain
unpredictability one should avoid recursive or dynamically constructed data structures and unbounded loops.
Determining a reasonable upper bound for tI/O is difficult, if not impossible, for disk-resident databases. Assuming for the worst case one page fault for every access, the time estimates become unrealistically large, since disk access time is orders of magnitude slower than main memory access. The result would be that nothing gets scheduled because the bloated worst-case execution time suggests that the deadlines could not be met. Pre-execution—an approach proposed in O’Neil, Ramamritham, and Pu (1996) in which the transaction executes once without acquiring locks to determine what data is needed and to set the buffer, followed by the real execution in a second step—postpones the problem but doesn’t guarantee end-to-end predictability. Any diskbased approach can at best provide statistical values for the expected execution time. In addition, many real-time applications require mean read and write latencies in the sub-millisecond range, something not achievable with disk-resident data. Therefore, the only feasible solution for
Real-Time Databases
systems that must give guarantees is avoiding disk I/O altogether by using main memory database systems. 64bit address spaces and a drastic drop in memory costs make it feasible to accommodate the structured data needed by real-time applications. Large-volume static data and streaming multimedia data that is accessed without transactional semantics can be accommodated by a hybrid approach with large buffers for data staging.
Time of interference tint refers to the time a transaction waits for resources held by another transaction or the time required for rollback and restart due to transaction abort. Disk-based database systems must schedule transactions in parallel in order to maximize the use of resources, such as CPU, while slow accesses to disk are performed. To increase intertransaction parallelism it is necessary to minimize the size of the locking unit, for example, at the tuple level. Since the tuples that are accessed by a transaction may depend on previous operations of the transaction, dynamic lock acquisition has become the method of choice in conventional DBMSs to guarantee small locking granules and increase parallelism. Dynamic lock acquisition necessarily results in scheduling policies based on conflict detection and conflict resolution. The bulk of the real-time database research has followed this approach because the basic assumptions of disk-based systems have never been challenged. However, moving to main memory databases opens new perspectives: Since the data is available in main memory, no lengthy disk accesses are needed, and passing control from one transaction to another with all the overhead of context switching becomes counterproductive. Instead, transactions should be allowed to run with as few interruptions as possible. Since intertransaction parallelism becomes less important, bigger data units, e.g., complete tables, can be locked. This in turn makes it possible to determine the needed resources before execution starts (e.g., by looking at the FROM clause in an SQL statement). This syntactic analysis can be done offline for the transaction classes used in real-time systems. Once data resources are known, a whole new class of conflict-avoiding schedulers becomes feasible (Ulusoy & Buchmann, 1998). The main advantage of these schedulers is that tint due to blocking and rollback is eliminated, since a transaction starts execution only when it has acquired all the needed resources. Waiting time in the queue can be predicted from the execution times of the tasks ahead in the queue.
Since tappl and tcomm are not database specific but part of all real-time processes and have been widely ana-
lyzed in the real-time community, they are not considered here.
526
TEAM LinG

Real-Time Databases
TRANSACTION PROCESSING
Transaction processing in a real-time database system is quite different from its counterpart in conventional systems: To be effective, the protocols involved must be time-cognizant. This includes the scheduler, the concurrency control mechanism, and the recovery subsystem.
What scheduling policy can be used depends on the availability of timing and resource information. Timing information comprises time of arrival, deadline, a value function, and worst-case execution time. If no execution time is available, then the evaluation of the value function can only be done at arrival time and degenerates to a priority. Resources, from a database point of view, are read sets and write sets.
What protocols work best depends on the transaction workload and its real-time requirements, i.e., whether the transactions arrive periodically or aperiodically, and on the nature of the timing constraints. Often these go hand in hand.
The vast majority of transactions with hard timing constraints are periodic, for example, sensor update transactions, the calculation of derived data, and the reactions when certain threshold conditions are met. While reactions may occur only sporadically, the necessary resources must be reserved in each cycle. A common misconception is that aperiodic transactions can be reduced to periodic transactions using the shortest possible time between two arrivals as the period. This approach only works when arrival times of aperiodic transactions are multiples of the minimum, i.e., it is reduced to the sporadic case discussed above. Totally aperiodic transactions with hard timing constraints usually cannot be handled unless resources are specifically set aside. Those systems that handle aperiodic transactions with hard deadlines only guarantee that such transactions, once scheduled, will be executed to completion (O’Neil et al., 1996; Ulusoy & Buchmann, 1998). Periodic transactions can be scheduled using either a static table-driven or a preemptive priority-driven approach. In the former, time slots are reserved based on worstcase execution times, and if a transaction executes faster, the resources either idle or are used for non-hard deadline tasks. Among the preemptive priority schedulers, the rate monotonic approach (Shah, Rajkumar, & Lehoczky, 1988) is quite popular. It assigns the task with the smallest periodicity the highest priority and works well if periodicity is deterministic and there are no data dependencies among tasks.
Transactions with soft timing constraints have a value function associated that has a positive value after the deadline. However, many approaches reported in the literature use only a degenerate form of the value func-
tion, which is reflected in the metric for success that is
used. For example, if the same constant value function 4 is used for all transactions and it is a step function that
drops to zero at the deadline, then the success metric is reduced to number of transactions completing before the deadline. Similarly, the scheduling policy that can be used depends on the availability of execution time information for each transaction. If this is not known, the scheduler can only decide based on the deadlines of a transaction. The most popular deadline-based approach is earliest deadline first. If worst case or average execution times are known, other more sophisticated scheduling policies can be applied, such as highest value first, which schedules first the transaction contributing most to the total value of the system; highest value density first, which schedules first the transaction with the highest value per unit of computation time; longest time first, which schedules first the transaction with the longest execution time; or total value, which schedules transactions maximizing the total system value.
A large number of time-cognizant concurrency control mechanisms have been proposed. Here we will comment only on a representative selection. Most of them assume dynamic locking and are therefore conflict resolving. These algorithms vary mainly in the conflict resolution strategy they apply. Priority abort (Abbott & Garcia-Molina, 1992) resolves data conflicts always in favour of high priority transactions. If a lock conflict occurs and the lock-holding transaction has higher priority, the requesting transaction is blocked. Otherwise the lock-holding transaction is aborted. Provided all transactions have different priority, this algorithm is deadlock free. In the priority inheritance protocol (Shah, Rajkumar, & Lehoczky 1990), the problem of a transaction with a higher priority waiting for a lower priority transaction is solved by letting the low priority transaction execute at the priority of the higher priority transaction that is waiting. In a better performing variant of priority inheritance, a conflicting low priority transaction is aborted unless it is close to completion, in which case it inherits the higher priority to finish faster (Shah, Rajkumar, Son, & Chang, 1992). This obviously requires some knowledge of the total execution time. Optimistic Wait-50 (Haritsa, Carey, & Livny, 1990) is an optimistic protocol that executes first and validates before the commit. A finishing transaction is validated against the executing transactions. If half or more of the conflicting transactions have higher priority, then the validating transaction waits; otherwise it may commit and the conflicting transactions are aborted. The preclaiming algorithm presented in Ulusoy and Buchmann (1998) is a conflict-avoiding protocol that only starts a transaction when it has secured all its resources. An arriving transaction tries to acquire all its resources and
527
TEAM LinG
if successful is enqueued in the ready queue. Otherwise it is enqueued in the wait queue. Whenever a transaction commits and frees its resources, the transactions in the wait queue are reexamined and if they complete their resources are transferred to the ready queue. It has been shown that this algorithm outperforms the others discussed above in main memory environments.
Overload management deals with the trade-offs that can be made to ensure timeliness at the expense of another property. Rather than aborting a transaction that can’t meet its deadline or refusing to schedule it, often a transaction of lesser cost but lower quality results can be executed. Typical trade-offs are timeliness vs. precision, completeness, currency, or consistency (Hou, Ozsoyoglu, & Taneja, 1989; Ramamritham, 1993).
Recovery is a difficult task that is made more complex in the presence of deadlines. Aborting and undoing the changes of a transaction due to lock conflicts or because they miss their deadline can be a time-consum- ing task that jeopardizes other transactions that may not even be involved in a lock conflict. It has been observed in conventional database systems that a high percentage of aborted transactions may cause a system to thrash. In real-time systems, where we have, in addition to the aborts due to deadlock, the aborts due to time-con- straint violation, the threshold is much lower. These arguments speak in favour of conflict-avoiding protocols. Improved logging mechanisms that use nonvolatile high speed memory are presented in Sivasankaran, Ramamritham, and Stankovic (2001), and logging approaches that treat data differently according to their criticality and achieve bounded recovery time are introduced in Shu, Stankovic, and Son (2002).
CONCLUSION AND OUTLOOK
Real-time data management is transcending the world of real-time databases. As many applications view data as flowing and the network as the database, real-time data services are gaining interest, particularly in sensor network applications, mobile real-time databases, and Webbased real-time data services. Many of the ideas and insights developed for real-time databases can be adapted to these new areas. A deep understanding of the underlying technologies and their interactions is needed to define the abstractions that will allow us to provide a platform for real-time data services.
Real-Time Databases
REFERENCES
Abbott, R., & Garcia-Molina. (1992). Scheduling realtime transactions: A performance evaluation. ACM Transactions on Database Systems, 17(3), 513-560.
Bestavros, A., Lin, K.-J., & Son, S. (1997). Real-time database systems: Issues and applications. Boston: Kluwer Academic Publishers.
Buchmann, A., Dayal, U., McCarthy, D., & Hsu, M. (1989). Time-critical database scheduling: A framework for integrating real-time scheduling and concurrency control.
Proceedings of the Fifth International Conference on Data Engineering (pp. 470-480).
Buchmann, A., & Liebig, C. (2001). Distributed, objectoriented, active, real-time DBMSs: We want it all—Do we need them (at) all? Annual Reviews in Control (Vol. 25, pp. 147-155).
Haritsa, J. R., Carey, M. J., & Livny, M. (1990). Dynamic real-time optimistic concurrency control. Proceedings of the 11th Real-Time Symposium (pp. 94-103).
Hou, W.-C., Ozsoyoglu, G., & Taneja, B. K. (1989). Processing aggregate relational queries with hard time constraints. Proceedings of the 1989 ACM SIGMOD International Conference on Management of Data (pp. 68-77).
Locke, D. (1997). Real-time databases: Real-world requirements. In A. Bestavros, K. Lin, & S. Song (Eds.), Real-time database systems: Issues and applications. Boston: Kluwer Academic Publishers.
O’Neil, P., Ramamritham, K., & Pu, C. (1996). A two-phase approach to predictably scheduling real-time transactions. In Performance of concurrency control mechanisms in centralized database systems (pp. 494-522). Englewood Cliffs, NJ: Prentice Hall.
Purimetla, B., Sivasankaran, R., Ramamritham, K., & Stankovic, J. A. (1995). Real-time databases: Issues and applications. In S. Son (Ed.), Advances in real-time systems. Englewood Cliffs, NJ: Prentice Hall.
Raatikainen, K. (1997). Real-time databases in telecommunications. In A. Bestavros, K. Lin, & S. Son (Eds.), Realtime database systems: Issues and applications. Boston: Kluwer Academic Publishers.
Ramamritham, K. (1993). Real-time databases. Distributed and Parallel Databases, 1, 199-226.
528
TEAM LinG

Real-Time Databases
Ramamritham, K., Son, S., & DiPippo, L. C. (2004). Realtime databases and data services. Real Time Systems Journal, 28, 179-215.
Shah, L., Rajkumar, R., & Lehoczky, J. P. (1988, March). Concurrency control for distributed real-time databases. ACM SIGMOD Record (Vol. 17, pp. 179-215).
Shah, L., Rajkumar, R., & Lehoczky, J. P. (1990). Priority inheritance protocols: An approach to real-time synchronization. IEEE Transactions on Computers, 39(9), 11751185.
Shah, L., Rajkumar, R., Son, S. H., & Chang, C. H. (1992). A real-time locking protocol. IEEE Transactions on Computers, 40(7), 793-800.
Shu, L., Stankovic, J., & Son, S. H. (2002). Achieving bounded and predictable recovery using real-time log- 4 ging. IEEE Real Time Technology and Applications Symposium (RTAS’02).
Sivasankaran, R., Ramamritham, K., & Stankovic, J. (2001). System failure and recovery. Real-Time Database Systems, (pp. 109-124). Boston: Kluwer Academic Publishers.
Stankovic, J. A., Son, S. H., & Hansson, J. (1999, June). Misconceptions about real-time databases. IEEE Computer (Vol. 32, No. 6, pp. 29-36).
Ulusoy, O., & Buchmann, A. A real-time concurrency control protocol for main-memory database systems.
Information Systems, 23(2), 109-125.
529
TEAM LinG