

Rivero L.Encyclopedia of database technologies and applications.2006
.pdf500
Query Operators in Temporal XML Databases
Kjetil Nørvåg
Norwegian University of Science and Technology, Norway
INTRODUCTION
The amount of data available in XML is rapidly increasing and at the same time the price of mass storage is rapidly decreasing, and this makes it possible to store larger amounts of data. The contents of a database or data warehouse are seldom static. New documents are created, documents are deleted and, more important, documents are updated. In many cases, one wants to be able to search in historical (old) versions, retrieve documents that were valid at a certain time, query changes to documents, and so forth. (Note that although this process is somewhat similar to general document versioning maintenance, the aspect of time makes possibilities and appropriate solutions different.) The “easiest” way to do this is to store all versions of all documents in the database and use a middleware layer to convert temporal query language statements into conventional statements, executed by an underlying database system (an example of such a system is TeXOR; Nørvåg, Limstrand, & Myklebust, 2003). Although this approach makes the introduction of temporal support easier, it can be difficult to achieve good performance: temporal query processing is in general costly, and the cost of storing the complete document versions can be high. Thus, a temporal XML database system is necessary.
In our group we have developed several database systems suitable for storing XML data, including V2 (Nørvåg, 2003b). An important issue is efficient query processing. To achieve this, appropriate query operators are needed. In this article, we describe the query operators necessary to execute such queries.
BACKGROUND
Related Work
A model for representing changes in semistructured data (i.e., DOEM) and a language for querying changes (i.e., Chorel) were presented by Chawathe, Abiteboul, and Widom (1998, 1999). Chorel queries are translated to Lorel (a language for querying semistructured data) and can therefore be viewed as a stratum approach.
An approach that is orthogonal, but still related to the work presented in this article, is to introduce valid time
features into XML documents, as presented by Grandi and Mandreoli (1999, 2000).
Many algorithms for execution of temporal query operators are based on the availability of temporal fulltext indexes (Nørvåg, 2002) that can support temporal text-containment queries. A number of such indexes have been proposed (e.g., see Nørvåg, 2004, 2003a).
Identity of Elements in Versioned XML
Documents
An important issues that poses some additional difficulties in the context of XML and, in particular, in the context of XML documents retrieved from the Web (such as from an XML data warehouse), is identity of elements.
XML documents have a quasi-persistent identifier: the URL (quasi-persistent because documents on the Web frequently are moved). However, in general the elements of a document do not have an identity of their own that persists from one version of a document to the next, which implies that many queries can be difficult to express as well as expensive to execute. Two simple examples are (a) a query for the create-time of elements, and (b) a query asking for the previous version of a certain element. Thus, although elements seen from “the outside” do not have persistent identifiers, the storage system should support this feature to make it a part of the data model for the query language. One particular system that provides such functionality is Xyleme (Marian, Abiteboul, Cobena, & Mignet, 2001). The persistent identifiers in Xyleme, called XIDs, identify an element in a particular document in a timeindependent manner and will not be reused when an element is deleted. The element ID (EID) is the concatenation of document ID and XID. Thus, an EID uniquely identifies a particular element in a particular document.
In a temporal XML database there will, in general, be more than one version of each element (i.e., different versions of an element have the same EID). In order to uniquely identify a particular version of an element, the timestamp can be used together with the EID. The identifier of a particular version of an element is the temporal EID (TEID) (i.e., the concatenation of EID and timestamp).
Copyright © 2006, Idea Group Inc., distributing in print or electronic forms without written permission of IGI is prohibited.
TEAM LinG
Query Operators in Temporal XML Databases
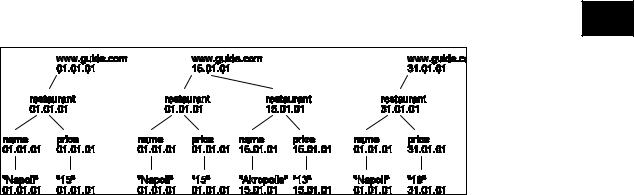
Figure 1. The restaurant list as retrieved on January 1, January 15, and January 31. The timestamps on each |
3 |
element is the time of update of the element or one of its children. |
Assumed Data Model
Documents in the database are often viewed as a forest of trees. Queries for certain versions of a document (or several documents) are similar to queries for a general set of XML documents, which can also be view as a forest of trees, or the forest of trees resulting from prefiltering (i.e., returning subtrees of documents, possibly more than one tree for each document).
Assume that:
•every element has a timestamp.
•every update of an element also implies update of the element it is contained in. Note that even if this logically has to be applied recursively up the document to the root, it does not have to be implemented in this way.
Note that the distinction between document timestamp and element timestamp is not significant for snapshot queries, only for change-oriented queries. An example of document versions can be seen in Figure 1. The document versions are versions of a restaurant guide database, as described in Chawathe et al. (1999). The restaurant guide will also be used in the examples below.
Note that in the physical storage model, it is unlikely that all versions of all documents are stored as complete versions. Instead, previous versions are stored as, for example, delta versions. In order to reconstruct these previous versions, we might have to retrieve and process the complete last versions as well as a number of delta documents.
Examples of Temporal XML Queries
The main purpose of this section is to describe the kinds of queries that can be expected in a temporal XML
database (note that the query operators and associated algorithms are in general independent of which query language is actually used). The query language is based on a mix of Lorel, the Xyleme query language (Aguilera, Cluet, Veltri, Vodislav, & Wattez, 2000), and elements of XPath and XQuery (World Wide Web Consortium, 2001). Note that even if Xyleme has support for historical versions or deltas, there is no special support for them in the query language. For example, a query returning all restaurants with prices less than $10 could be written as:
SELECT R
FROM doc(“http://guide.com/”)/restaurant R WHERE R/price < 10
Assume that the results of an “outer query” are delivered as default in a document with enclosing tags named <results>. Each result from the SELECT expression is delivered in one element with tags named <result>. In most of the following example queries, complete paths are used (i.e., not containing a // operator). However, when querying semistructured data such as XML, many queries can be expected to contain the // operator.
To retrieve documents that are valid at a particular time (i.e., snapshot query), a timestamp is given for the path in the FROM clause, filtering out only those element versions valid at the particular time:
SELECT R
FROM doc(“http://guide.com/”)/restaurant[26/01/ 2001] R
For more complex queries, or when more than one version to be selected is wanted, use the keyword EVERY instead of timestamp. For example, to retrieve the price history of the restaurant named Napoli:
501
TEAM LinG
SELECT TIME(R), R/price
FROM doc(“http://guide.com/”)/restaurant[EVERY] R WHERE R/name = “Napoli”
where TIME(R) returns the timestamp of the element R. Further predicates on time can be included in the SELECT clause, including the delete and create time of elements. In order to query time relative to another time, for example [NOW] (which denotes the “current time”) or a certain time DD/MM/YYYY, expressions such as NOW -14 DAYS or 26/01/2001 -2 WEEKS can be used.
ALGEBRA OPERATORS
Operators needed in temporal XML query processing are now considered and are described in terms of input, output, and operation. In addition to the operators described here, the availability of traditional operators is assumed (e.g., projection and join) but are not discussed further.
Two of the operators are extensions of the PatternScan operator described in Aguilera et al. (2000). The PatternScan operator takes as input a forest of trees (which can be a set of EIDs) that are XML documents or filtered elements (subtrees) from an XML document, and a pattern tree that each tree will be matched against. The pattern tree includes information on projection as well as isParentOf and isAscendantOf relationships. Informally, we can define the operator as PatternScan(F,pattern), where F is a forest of trees and pattern is the pattern tree. For more details on the PatternScan operator, see Aguilera et al. (2000).
Overview of the Operators
The temporal query operators to be added are as follows:
•TPatternScan(F,pattern,T): This is a temporal snapshot PatternScan operator. TPatternScan is similar to the PatternScan operator in Aguilera et al. (2000), except that it operates on the snapshot of documents valid at time T. The output of the operator is a set of TEIDs.
•TPatternScanAll(C,pattern): TPatternScanAll returns all matches for pattern for all versions of the documents in a collection C. The output of the operator is a set of TEIDs.
•DocHistory(document,TS,TE): Returns all the versions of a certain document valid in the interval [TS,TE>, where [TS ,TE> is short for the time interval from TS to TE , including TS but not TE (open-ended upper bound). The output of the op-
Query Operators in Temporal XML Databases
erator is a set of TEIDs, where the TEIDs are roots of documents.
•ElementHistory(EID,TS,TE): Returns all versions of an element valid in the interval [TS ,TE>. The output of the operator is a set of TEIDs (with the EID in the TEID equal to the EID in the input parameters).
•CreTime(TEID): Returns the create time of an element. This is useful for retrieving elements created before or after a particular time, for example, as in:
SELECT R
FROM ...
WHERE CREATE TIME(R)>=11/01/2001.
Note that EIDs are unique, so that when an element is deleted, the EID will not be reused for a new element. Thus, we do not strictly need timestamps in the element identification for the CreTime and DelTime operators. However, as shown in the expanded version of this article (Nørvåg, 2002), the availability of timestamp can improve performance. The timestamps will in general be available in any case so that no extra cost is involved by assuming its availability.
•DelTime(TEID): DelTime returns the delete time of an element.
•PreviousTS(TEID)
•NextTS(TEID)
•CurrentTS(EID)
Returns the timestamp of the previous/next/current version of a given element (note that timestamp is not needed for the current version, as this is given implicitly). The timestamp, together with the EID (i.e., the TEID), can be used for retrieving the version itself. These operators can be used in constructions such as
SELECT DISTINCT CURRENT(R)/name FROM ...
WHERE ...,
which retrieves the current versions of elements (possibly generated from a temporal snapshot), and as in
SELECT PREVIOUS(R)
FROM ...
WHERE ...,
which retrieve the previous versions of elements.
•Reconstruct(TEID): Reconstructs the tree rooted at EID in TEID for a particular version. The
502
TEAM LinG
Query Operators in Temporal XML Databases
timestamp TS in the TEID can be, for example, the result of NextTS/PreviousTS/CurrentTS operations. If previous versions of documents are stored as deltas, this can imply accessing and processing a potentially large number of deltas in addition to one complete version (the exception is the current version, which will normally be stored as a complete version). If previous versions of documents are stored as complete documents, only the actual version needs to be read.
•Diff(E1, E2): In some cases, querying for changes between different versions of elements is wanted. These changes can conveniently be returned (and eventually post-processed by the application or in a separate query) as edit scripts. Edit scripts describe changes between two versions, similar to, for example, the information in RCS files. In this context, the edit scripts are XML trees. Note that as long as an edit script is represented in XML, this operator does not break closure properties of queries. E1 and E2 can be versions of the same element but can also represent different documents or subtrees of elements. Diff is useful in constructions such as:
SELECT DIFF(R1,R2)
FROM ...
WHERE ....
It is possible to support string equality and stringcontain queries with different operators and access structures. However, as described in Nørvåg (2002), the access methods for containment queries already exist so that there is little to gain from providing additional access methods for string equality. Therefore, we expect that there are no separate operators and access structures for equality queries and that the general containment operators/access methods are used, followed by equality testing.
Example Queries
The following three example queries based on the restaurant database example, together with the corresponding query operators, illustrate the use of the operators:
•Q1: List all restaurants in the list as of 26/01/ 2001:
SELECT R
FROM doc(“http://guide.com/”)/restaurant[26/01/ 2001] R
This is |
a snapshot query, listing the name in all |
|
|||
3 |
|||||
versions of |
restaurant elements valid |
at |
time 26/01/ |
||
2001 (i.e., |
versions created before or |
on |
26/01/2001 |
|
|
|
|||||
that are not further updated or deleted).
•Operators: TPatternScan, followed by Reconstruct.
•Q2: Retrieve the number of restaurants at 26/01/ 2001:
SELECT SUM(R)
FROM doc(“http://guide.com/”)/restaurant[26/01/ 2001] R
•Operators: TPatternScan followed by the traditional aggregate operator Sum. Note that reconstruction of the documents is not needed. This is important, and shows that in many cases the storage of only deltas of previous document versions does not create performance problems.
•Q3: List the price history of the restaurant “Napoli”:
SELECT TIME(R), R/price
FROM doc(“http://guide.com/”)/restaurant[EVERY] R WHERE R/name = “Napoli”
The use of EVERY instead of a particular timestamp retrieves all versions of restaurant. Note that the predicate in the WHERE clause acts on all versions, not only the current version of the elements. As a result, the price history of all restaurants through the history with the name Napoli will be listed.
•Operator: TPatternScanAll.
Which Version?
An issue related to time is the assumed content at a particular time. Assume there is one document version from time T1, and another version of the document from T2 (where T2 > T1). What can we assume is the content at time T, where T1 < T < T2? Two possible options follow:
•Assume the contents for all T, where T1 < T < = T2 is the same as the contents at time T1.
•Assume that the document closest in time is the most appropriate (i.e., choose document version with timestamp Tx that minimizes |T - Tx|).
Frequently, it is possible to know the reasonable time approximation/version approximation to use because the information can be included in the query. This can be done
503
TEAM LinG
by extending the time expression that, as previously described, had the form [T] or [EVERY], where T is a timestamp:
•[T MOST_RECENT]: Assume the contents for all T, where T1 < T < = T2 is the same as the contents of time T1. This is expected to be the most common time approximation, and it is also similar to the previous approach. Therefore, it should be possible to denote by the short form [T].
•[T NEAREST]: Choose the document version with timestamp Tx, which minimizes |T - Tx|.
These language options can also be represented in the parameters to the operators.
FUTURE TRENDS
The query operators described in this article, together with traditional query operators, are sufficient to execute temporal XML queries. However, several issues ramain. First, efficient access methods are necessary. Second, whether ranking operations should also be included in the operator set should be studied further.
CONCLUSION
This article has described how temporal queries can be executed in an XML database system. Issues related to time and identity, in this context, and described an appropriate data model as the basis of a temporal XML query language has been described. Temporal support in an XML query language implies that new operators are needed in query processing, and operators that will be useful to support typical queries in temporal XML databases have been identified. To achieve the desired performance in such databases, efficient execution of query operators are needed. For a more detailed discussion on these issues, see Nørvåg (2002), which also describes algorithms for execution of the operators presented in this article.
REFERENCES
Aguilera, V., Cluet, S., Veltri, P., Vodislav, D., & Wattez, F. (2000). Querying XML documents in Xyleme (Tech. Rep. 182). Rocquencourt, France: Verso/INRIA.
Query Operators in Temporal XML Databases
Chawathe, S. S., Abiteboul, S., & Widom, J. (1998). Representing and querying changes in semistructured data.
Proceedings of the Fourteenth International Conference on Data Engineering (pp. 4-13).
Chawathe, S. S., Abiteboul, S., & Widom, J. (1999). Managing historical semistructured data. Theory and Practice of Object Systems, 5(3), 143-162.
Grandi, F., & Mandreoli, F. (1999). The valid Web: It’s time to go (Tech. Rep. TR-46). TimeCenter. Retrieved April 14, 2005, from http://www.cs.aau.dk/TimeCenter/pub.htm
Grandi, F., & Mandreoli, F. (2000). The valid Web: An XML/XSL infrastructure for temporal management of web documents. Proceedings of Advances in Information Systems, First International Conference, Izmir, Turkey.
Marian, A., Abiteboul, S., Cobena, G., & Mignet, L. (2001). Change-centric management of versions in an XML warehouse. Proceedings of 27th International Conference on Very Large Data Bases (pp. 581-590).
Nørvåg, K. (2002). Algorithms for temporal query operators in XML . Paper presented at the XML-Based Data Management and Multimedia Engineering EDBT 2002 Workshops, EDBT 2002 Workshops XMLDM, MDDE, and YRWS (pp. 169-183).
Nørvåg, K. (2003a). Space-efficient support for temporal text indexing in a document archive context. Proceedings of the 7th European Conference on Digital Libraries,
Trondheim, Norway.
Nørvåg, K. (2003b). V2: A database approach to temporal document management. Proceedings of the 7th International Database Engineering and Applications Symposium, (pp. 212-221).
Nørvåg, K. (2004). Supporting temporal text-containment queries in temporal document databases. Journal of Data & Knowledge Engineering, 49(1), 105-125.
Nørvåg,K.,Limstrand,M.,&Myklebust,L.(2003).TeXOR: Temporal XML database on an object-relational database system. Proceedings of Perspectives of System Informatics.
World Wide Web Consortium. (2001). XQuery: A query language for XML. Retreived August 10, 2004, from http:/ /www.w3.org/TR/xquery/
Xyleme, L. (2001). A dynamic warehouse for XML data of the Web. IEEE Data Engineering Bulletin, 24(2), 40-47.
504
TEAM LinG

Query Operators in Temporal XML Databases
KEY TERMS
Current Document Version: The most recent version of a temporal document. Note that a deleted document has no current version.
Full-Text Index: An index supporting retrieval of identifiers from documents containing a particular word.
Historical Document Version: A non-current document version. This is versions that have later been updated, and the last version that existed before the document was deleted.
Temporal Document: A document in which the currently valid version and also the previously valid versions of the document are kept in the system,. Every document version has an associated time period in which it was valid.
Temporal Document Database Management System:
A system capable of storing, retrieving and querying
temporal documents. Typically, a document name or docu-
ment identifier is used to distinguish documents from 3 each other, and timestamp is used to distinguish particu-
lar versions of a document, as well.
Temporal Full-Text Index: An index supporting retrieval of identifiers from documents that contained a particular word at a particular point in time.
Transaction-Time Temporal Document Database:
Every document version that is stored is assigned a timestamp (the commit time) by the system. The time period a particular version is valid, is from commit time until the document is deleted or updated by a new version.
Valid-Time Temporal Document Database: Every document that is stored is explicitly given a time period in which it is valid. The start and end timestamps of this period can be in the past, present, or future.
505
TEAM LinG
506
Query Processing for RDF Data
Heiner Stuckenschmidt
Vrije Universiteit Amsterdam, The Netherlands
INTRODUCTION
The World Wide Web today is a huge network of information resources which was built in order to broadcast information for human users. Consequently, most of the information on the Web is designed to be suitable for human consumption: the structuring principles are weak, many different kinds of information co-exist, and most of the information is represented as free text.
With the increasing size of the Web and the availability of new technologies, such as mobile applications or smart devices, there is a strong need for making the information on the World Wide Web accessible to computer programs which search, filter, convert, interpret, and summarize the information for the benefit of the user. The Semantic Web is a synonym for a World Wide Web whose accessibility is similar to a deductive database where programs can perform well-defined operations on well-defined data or even derive new information from existing data (Berners-Lee, Hendler & Lassila, 2001).
One of the main developments connected with the Semantic Web is the resource description framework RDF. RDF is an XML-based language for creating metadata about information resources on the Web. The metadata model is based on a resource which could be any piece of information with a unique name called URI (uniform resource identifier). URIs can either be unique resource locators (URLs)—well known from conventional Web pages—but also tagged information contained on a page or on other RDF definitions. The structure of RDF is very simple: a set of statement forms a labeled, directed graph where resources are represented by nodes and relations between resources by arcs. These are labeled with the name of the relation (Klyne & Carroll, 2004).
RDF, as such, only provides the user with a language for metadata. It does not make any commitment to a conceptual structure or a set of relations to be used. The RDF schema model defines a simple frame system structure by introducing standard relations like inheritance and instantiation, standard resources for classes, relations as well as a small set of restrictions on objects in a relation. Using these primitives, it is possible to define terminological knowledge about resources and
relations mentioned in an RDF model (Brickley & Guha, 2004).
BACKGROUND
A characteristic property of an RDF model is that its statements form a labeled, directed graph. The resources mentioned in the statements can be seen as nodes in such a graph (this may include properties as special kinds of resources). Subject and object of each statement are connect by a directed link labeled with the name of the property acting as predicate.
Based on the graph-based view on an RDF model, we can characterize some properties of RDF models that are relevant for query answering. The first basic property of RDF is the fact that a graph entails all its subgraphs. The RDF data model described above and its associated semantics provides us with a basis for defining queries on RDF models in a straightforward way. The idea that has been proposed elsewhere and is adopted here is to use graphs with unlabeled nodes as queries. The unlabeled elements in a query graph can be seen as variables of the query. Answers to a query can be defined as:
•A subgraph of the given RDF model that is an instantiation of the query graph.
•The set of resources used to instantiate unlabeled nodes in the query graph.
From a theoretical point of view, these two definitions are exchangeable as one can easily be derived from the other by either extracting instantiated resources from the answer graph or by instantiating the query graph with the resources from the answer set, respectively.
One of the main features of RDF is the idea to enrich metadata descriptions with explicit models of their intended meaning. These models are defined in terms of a schema definition. We want to exploit this semantic information for query answering as it provides us with background information for computing more complete results. For this purpose, the RDF schema language contains properties with a standardized interpretation
Copyright © 2006s, Idea Group Inc., distributing in print or electronic forms without written permission of IGI is prohibited.
TEAM LinG
Query Processing for RDF Data
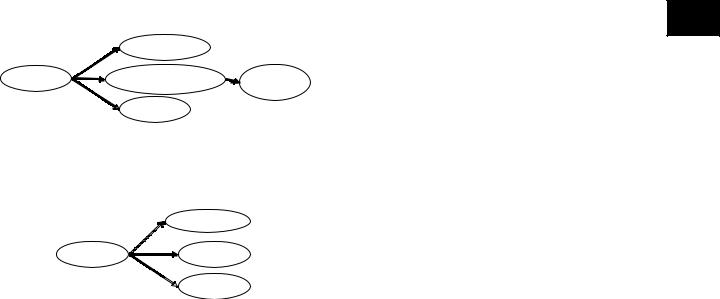
Figure 1. An example RDF graph
rdf:ty |
|
inProceedings |
|
|
|
affiliation |
|
|
|
|
|
fqas2004 |
author |
H. Stuckenschmidt |
Vrije |
|
|||
|
|
|
Universitei |
keyword |
|
RDF |
|
Figure 2. An example RDF query
Publication
rdf:type

X |
author |
Y |
|
about 

 RDF
RDF
JENA and RDQL
3
The JENA system is a JAVA-based RDF infrastructure for parsing, storing, and accessing RDF data (http:// jena.sourceforge.com). JENA is developed by the HP research labs in Bristol and implements the RDQL query language for accessing stored RDF data (http:// www.hpl.hp.com/semweb/rdql.htm). An RDQL query consists of a SELECT part that specifies return variables, a WHERE part that refers to the RDF model to be accessed, a FROM part that provides a set of statement patterns that have to be matched by the RDF data in the model, a set of constraints on the variables occurring in the statement patterns, as well as a USING part where abbreviations for XML namespaces can be defined to simplify the query (Seabourne, 2004). In RDQL, schema awareness is not directly integrated in the language specification but has to be provided by the underlying data source.
for defining hierarchies of classes and properties as well as domain and range restrictions for user-defined properties. The intended meaning of these constructs and their impact on an RDF model is defined by the RDF semantics specification. The specification describes a model theoretic semantics and the notion of entailment for arbitrary RDF models (Hayes, 2004). It also defines a set of inference rules that can be used to derive implicit statements from a given RDF model. This implicit information should be taken into account when querying an RDF model making the query processing in the sense of a deductive database. A common approach is to compute the deductive closure of the model to be queried and execute the query on the resulting expanded model.
Figure 1 shows an RDF graph that represents a query. The nodes labeled X and Y are unlabeled nodes in the sense of the RDF model that acts as query variables. Assuming that inProceedings is a subclass of Publication and keyword is a subproperty of about, we see that the graph in Figure 1 represents a result of the query in Figure 2.
RDF QUERY LANGUAGES
AND SYSTEMS
A number of RDF query languages have been proposed that implement the general approach mentioned in the last section. Due to space limitations, we cannot discuss all of these languages. We focus on languages implemented in freely available RDF storage and retrieval systems.
RDFSuite and RQL
The RDFSuite (Alexaki et al., 2002) is a toolkit for parsing, storing, and querying RDF data developed by ICS-FORTH in Greece (http://139.91.183.30:9090/ RDF/). The RQL query language implemented in this suite is probably the most widely known and used RDF query language (http://139.91.183.30:9090/RDF/RQL/). RQL is based on functional query languages for objectoriented databases (in particular, OQL). Different from RDQL, the language provides a rich set of operators for specifying the query result that can freely be combined as a result of the functional nature of the language. These include explicit operators for navigating the schema (retrieving all super-classes or just the direct super-classes). Another distinguishing feature of RQL is the use of path expressions for navigating the RDF graph (Karvounarakis, Christophides & Plexousakis, 2001). This significantly reduces the number of equality constraints that are necessary in languages like RDQL for defining complex statement schemes.
Sesame and SeRQL
The Sesame system (Broekstra, Kampman & van Harmelen, 2002) developed by the Dutch company Aduna is an RDF infrastructure that aims at providing RDF support on top of different information sources such as databases, search engines, and Web services (http:// www.openrdf.org/). Besides providing support for the two above-mentioned languages, Sesame also implements its own query language SeRQL (http://www.openrdf.org/ publications/users/ch05.html). The SeRQL language
507
TEAM LinG
combines features of RDQL and RQL aiming at ease of use rather than maximal expressiveness. A SeRQL query is structured similar to an RDQL query, but instead of a set of statement patterns, it uses path expressions that are similar to the ones used in RQL. SeRQL does not use rich operators as found in RQL and relies on the underlying information source to provide schema awareness. A special feature of SeRQL is the possibility to define the output format using a path expression which makes it possible to use SeRQL as a transformation language between different RDF model structures.
A common feature of most of the current systems is that they seek strong links with relational database technologies, both on the technical and conceptual level. All of the systems mainly use relational databases to store RDF data and try to push down complex queries into the database engine to make use of its optimization techniques. Normally, queries are translated into an equivalent SQL that is then executed on the underlying database. The translation varies significantly between the different systems, not only due to the differences in the RDF query languages but also due to different relational schemes used to store the RDF data.
FUTURE TRENDS
While the work on defining the RDF data model and language is mainly finished by now, RDF query languages are still heavily discussed in the Semantic Web community. The same holds for RDF query processing. We can perceive some general lines of work that are in the focus of attention at the moment and will dominate upcoming research on RDF query processing.
Standardization
In contrast to representation languages such as RDF and RDF schema, RDF querying currently suffers from a lack of agreement between the different approaches. Important query languages such as the ones described above are developed by individual groups and do not necessarily reflect the needs of a broader audience. As a result, the W3C has recently launched the RDF data access working group. The aim of the group is to create a standardized query language for RDF data and clarify its relationship to XML query languages.
Optimization and Scalability
Compared to modern database systems, RDF storage technology still lacks sophisticated optimization methods for query processing. Current work in this direction is mainly
Query Processing for RDF Data
focussed on exploiting the optimization mechanisms of underlying database systems and on index structures for speeding up the access on triple level or for special queries. There are some attempts to fill this gap. Current work includes the definition of Algebras for RDF (Fransincar, Houben, Vdovjak & Barna), query planning, and result caching (Stuckenschmidt, 2004).
Distributed Query Processing
Despite the inherently distributed nature of the Semantic Web, most current RDF infrastructures store information locally as a single knowledge repository; that is, RDF models from remote sources are replicated locally and merged into a single model. Distribution is virtually retained through the use of name spaces to distinguish between different models. Researchers only recently started to address the problem of querying distributed RDF data sources. Such a distributed setting requires additional mechanisms for data location, query planning, and result integration (Stuckenschmidt, Vdovjak, Broekstra & Houben, 2004).
Ontology-Based Querying
Another recent trend is to investigate query processing with richer background knowledge than provided by the RDF schema language. Extensions of RDF schema with richer conceptual modelling features have been developed. The most important one is the Web Ontology Language OWL. The language consists of three increasingly expressive sublanguages. The weakest sublanguage, OWL lite, is similar to UML-like conceptual modelling languages. OWL DL, the second language is equivalent to expressive description logic (Borgida, 1995). The most expressive language combines description logic semantics with meta-modeling facilities. There are already results on querying databases with background knowledge (Peim, Franconi, Paton & Goble, 2002) and systems like JENA support limited support for OWL reasoning. Further, there are first proposals for a query language that allows the use of richer operators in queries (Fikes, Hayes & Horrocks, 2003).
CONCLUSION
RDF technology is rapidly gaining importance as a standard for exchanging and accessing data in Web-based applications. In contrast to XML, RDF provides an application independent data model that eases the exchange of information between different systems on a syntactic
508
TEAM LinG

Query Processing for RDF Data
level. The ability to explicitly represent and access the underlying schema also helps to align information on a semantic level. These features, on the other hand, impose new challenges on the query processing for RDF data. Existing implementations already provide stable querying functionality and scale up to reasonably large models; RDF querying has not yet reached the level of maturity of traditional relational database systems. The standardization effort that is currently underway could be an important driver for work towards technologies that are comparable to traditional database technology.
REFERENCES
Alexaki, S., Athanasi, N., Christophides, V., Karvounarakis, G., Maganaraki, A., Plexousakis, D., & Tolle, K. (2002). The ICS-FORTH RDFSuite: High-level scalable tools for the Semantic Web. Proceedings of the 11th International World Wide Web Conference (WWW2002), Honolulu, Hawaii, May 7-11.
Berners-Lee, T., Hendler, J., & Lassila, O. (2001). The Semantic Web. Scientific American, 5(1).
Borgida, A. (1995, October). Description logics in data management. IEEE Transactions on Knowledge and Data Engineering, 7(5), 671-682.
Brickley, D., & Guha, R.V. (2004). RDF vocabulary description language 1.0: RDF schema. Retrieved January 23, 2005, from http://www.w3.org/TR/2004/REC- rdf-schema-20040210/
Broekstra, J., Kampman, A., & van Harmelen, F. (2002). Sesame: A generic architecture for storing and querying RDF and RDF schema. Proceedings of the Semantic Web (ISWC 2002), 2342 of LNCS (pp. 54-68).
Fikes, R., Hayes, P., & Horrocks, I. (2003). OWL-QL - A language for deductive query answering on the Semantic Web. Knowledge Systems Laboratory, Stanford University, Stanford, CA.
Frasincar, F., Houben, G.-J., Vdovjak, R., & Barna, P. (2004, March). RAL: An algebra for querying RDF.
World Wide Web, 7(1), 83-109.
Hayes, P. (2004). RDF semantics. Retrieved January 23, 2005, from http://www.w3.org/TR/2004/REC-rdf-mt- 20040210/
Karvounarakis, G., Christophides, V., & Plexousakis, D. (2001, December). RQL: A declarative query language for RDF. D-Lib Magazine, 7(12).
Klyne, G., & Carroll, J.J. (2004). Resource description framework (RDF): Concepts and abstract syntax. Re- 3 trieved January 23, 2005, from http://www.w3.org/TR/ 2004/REC-rdf-concepts-20040210/
McGuinness, D., & van Harmelen, F. (2004). OWL Web ontology language overview. Retrieved January 23, 2005, from http://www.w3.org/TR/2004/REC-owl-features- 20040210/
Peim, M., Franconi, E., Paton, N., & Goble, C. (2002, July). Query processing with description logic ontologies over object-wrapped databases. Proceedings of the 14th International Conference on Scientific and Statistical Database Management (SSDBM-02), Edinburgh, UK.
Seaborne, A. (2004). RDQL - A query language for RDF. 9 Retrieved January 23, 2005, from http://www.w3.org/ Submission/2004/SUBM-RDQL-20040109/
Stuckenschmidt, H. (2004). Similarity-based query caching. In Christiansen et al. (Eds.), Flexible query answering systems, 6th international conference (FQAS 2004), Lyon, France, June.
Stuckenschmidt, H., Vdovjak, R., Broekstra, J., & Houben, G.-J. (2004). Data structures and algorithms for querying distributed RDF repositories. Proceedings of the International World Wide Web Conference (WWW’04), New York, USA.
KEY TERMS
Blank Node: A blank node is a node in the RDF graph that does not correspond to a Web resource. Blank nodes are normally used to refer to a set of resources or an entire statement. With respect to querying, they can be used to represent variable in an RDF query.
OWL: The Web Ontology Language, OWL, is a W3C recommendation for modeling complex conceptual models and background information in a Web-based setting. The language extends RDF schema with richer operators for defining classes of objects.
RDF Graph: An RDF model can be seen as a graph structure build-up by triples. The nodes of the graph are all resources and atomic values mentioned in the model. Nodes are linked by edges if they occur as subject and object in a triple contained in the corresponding RDF model.
509
TEAM LinG