

Dr.Dobb's journal.2006.02
.pdfExamining µC++
High-level object-oriented concurrency for C++
PETER A. BUHR AND
RICHARD C. BILSON
Concurrency is the most complex form of programming, with certain kinds of real-time programming being the most complex forms of concurrency.
Often the mechanisms for writing concurrent programs only exacerbate the complexity because they are too low level and/or independent from the language. Currently, concurrency is being thrust upon all programmers indirectly through the push for higher performance in hardware. To maintain Moore’s Law, it is becoming necessary to add parallelism at a number of hardware levels — instruction pipeline, multithreading, multicore processors, shared-memory multiprocessors, and distributed clusters. Some successful attempts have been made to implicitly discover concurrency in a sequential program; for instance, by parallelizing loops and access to data structures. While this approach is appealing because of the simple sequential programming model and ability to parallelize legacy code, there is a limit to how much parallelism can be found, and current techniques only work on certain kinds of programs. Therefore,
Peter is an associate professor in the School of Computer Science at the University of Waterloo. He can be contacted at pabuhr@ uwaterloo.ca. Richard is a research assistant in the School of Computer Science at the University of Waterloo, working in the Programming Languages Group. He can be contacted at rcbilson@ plg.uwaterloo.ca.
explicit concurrent mechanisms are necessary to achieve maximum concurrency potential. Luckily, approaches to this are complementary, and can appear together in a single programming language.
C++ Concurrency
Given the need for explicit concurrency, modern programming languages such as Beta, Ada, Modula-3, Java, and C#, among others, provide some direct support for concurrency. Surprisingly, however, C++ has no concurrency support. During C++’s 20-year history, many different concurrency approaches for C++ have been suggested and implemented with only varying degrees of adoption. As a result, there is no de facto standard dominating concurrent programming in C++. (In C, there are two dominant, but incompatible, concurrency libraries —Win32 and pthreads.) In this article, we argue that C++’s lack of concurrency is significantly limiting the language’s future. This deficiency has also been recognized by the C++ Standards committee, which is currently examining concurrency extensions. We also outline how high-level object-oriented concurrency can be added to C++ through a freely available concurrent dialect of C++ called “µC++” (http://plg.uwaterloo.ca/ usystem/uC++.html).
Concurrent Design Principles
There are a number of major design principles for adding concurrency to objectoriented languages, such as:
•Object-oriented design is built on the notion of the class. Hence, concurrency should be built on the class notion, allowing it to leverage other class-based language features.
•All concurrent systems must provide three fundamental properties: thread, a mechanism to sequentially execute statements, independently of (and possibly concurrently with) other threads; execution context, the state needed to permit independent execution, including a
separate stack; and mutual exclusion/synchronization (MES), mechanisms to exclusively access a resource and provide necessary timing relationships among threads. These properties cannot be expressed in an architectureindependent way through existing language constructs. (Even algorithms for MES, such as Dekker’s algorithm, do not
“µC++ was designed to provide high-level, integrated, lightweight, object-oriented concurrency
for C++”
always work without a sufficient memory model.) Therefore, any concurrency system must provide abstractions to implement these properties.
•Because MES causes the most errors for programmers and the greatest difficulty for safe code optimizations, it should be implicit through concurrent language constructs.
•If the routine call is the basis for normal object communication, it should also be used for concurrency. Mixing mechanisms, such as routine call with messagepassing/channels, is confusing and error prone, and may lose important capabilities such as static type checking.
Joining the fundamental concurrency properties with the class model is best done by associating thread and execu- tion-context with the class, and MES with member routines. This coupling and the
36 |
Dr. Dobb’s Journal, February 2006 |
http://www.ddj.com |
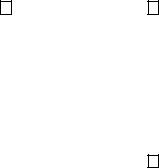
interactions among the concurrency properties generate the programming abstractions in Table 1.
•Case 1 in Table 1 is a standard C++ object. Its member routines do not provide MES, and the caller’s thread and stack are used to perform execution.
•Case 2 has all the properties of case 1 but only one thread at a time can be executing among the member routines with the MES property, called a “mutex member.” Within a mutex member, synchronization with other tasks can be performed. This abstraction is a monitor, which is well understood and appears in many concurrent languages (Java, for instance).
•Case 3 is an object that has its own execution context but no MES or thread; the execution context is associated with a distinguished member in the object. This abstraction is a coroutine, which goes back to the roots of C++ in Simula.
•Case 4 is like case 3 but deals with concurrent access by adding MES. This abstraction is a coroutine monitor.
•Cases 5 and 6 are a thread without a stack, which is meaningless because a thread must have a stack to execute.
•Case 7 is an object that has its own thread and execution context but no MES. This case is questionable because explicit locking is now required to handle calls from other threads, which violates design principle 3.
•Case 8 is like case 7 but deals with concurrent access by adding MES. This abstraction is a task, which is an active object and appears in many concurrent languages (Ada). Note, the abstractions are derived from fundamental properties and not ad hoc decisions by a language designer, and each has a particular set of problems it can solve well. Simulating one abstraction with the others often results in awkward solutions that are inefficient; therefore, each has a place in a programming language.
µC++: Concurrency in C++
µC++ was designed using these concurrency design principles and engineered to provide high-level, integrated, lightweight, object-oriented concurrency for C++. By being high level, you can code in a race-free style, which eliminates the need for a complex memory model. By being integrated into the C++ language, the compiler can understand precisely when it can safely perform optimizations. Currently, µC++ is a translator that converts to C++, but its design ultimately assumes it is part of C++.
Figure 1 shows the syntax for adding the programming abstractions in Table 1 to C++. There are two new type constructors _Coroutine and _Task, extensions
of class, implicitly associating the execution context and thread properties to objects. There are two new type qualifiers, _Mutex and _Nomutex, for qualifying member routines needing the mutual exclusion property and which contain synchronization. There are implicitly inherited members providing context-switch/synchro- nization, suspend( ), resume( ), wait( ), signal( ), signalBlock( ), and one new statement —_Accept. Each of these new constructs is explained through examples.
Coroutine
A coroutine is not a concurrent abstraction, but it appears directly from the combination of fundamental concurrency properties and supports direct implementation of finite-state machines (FSM). In µC++, the execution context (stack) for a coroutine object is associated with its distinguished member main; see Listing One.
A coroutine type implicitly inherits member routines resume and suspend, which provide control flow among coroutines. Like a class, a coroutine’s public members define its interface but also provide the interaction with the coroutine’s main; multiple public member routines allow complex, type-safe communication. The resume routine is called from the public members and the suspend routine is called directly or indirectly from the coroutine’s main. The first call to resume starts main, which executes on its own stack. Subsequent re-
sumes restart at the last suspend from main. Routine suspend restarts the last resume executed by a public member. A coroutine object becomes a coroutine when main starts (first resume); the coroutine becomes an object again when main ends.
Listing Two is a simple FSM for recognizing phone numbers of the form: (555)opt 123 – 4567. Characters of the phone number are passed one at a time to the next member, which returns the current status of the parse. Note how the coroutine main retains its execution location and restarts there when it is resumed; for example, when parsing groups of digits, the coroutine suspends in the middle of a for loop and restarts within the particular loop when resumed. The killer application for a coroutine is device drivers, which cause 70– 85 percent of failures in Windows/Linux. Many device drivers are FSMs parsing a protocol; for instance:
…STX…message…ESC ETX…message…
ETX 2-byte crc…
Here, a network message begins with the control character STX and ends with an ETX, followed by a 2-byte cyclic redundancy check. Control characters can appear in the message if preceded by an ESC. An Ethernet driver is just a complex version of this simple protocol, and the FSM for the Ethernet protocol can be directly coded as a coroutine. Because FSMs can be complex and occur frequently
|
|
|
|
object properties |
|
member routine properties |
|
|
|
||||||
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
thread |
stack |
|
No MES |
|
MES |
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
No |
No |
|
1 class |
|
|
2 monitor |
|
|
|
||
|
|
|
|
No |
Yes |
|
3 coroutine |
|
4 coroutine-monitor |
||||||
|
|
|
|
Yes |
No |
|
5 reject |
|
|
6 reject |
|
|
|
||
|
|
|
|
Yes |
Yes |
|
7 reject |
|
|
8 task |
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Table 1: Programming abstractions. |
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
No MES |
|
|
|
|
|
MES |
|
|
|
||
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
class c { |
|
|
|
2 |
|
Mutex class M { |
// or _Monitor |
||||
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
uCondition variables; |
|||
No Stack |
|
|
public: |
|
|
|
|
|
|
public: |
|
|
|
||
No Thread |
|
|
m() { } |
|
|
|
|
|
}; |
|
m() { wait/signal/accept } |
||||
|
|
}; |
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3 |
|
_Coroutine C { |
|
4 |
|
_Mutex _Coroutine CM { // or _Comonitor |
|||||||
|
|
|
|
|
|
|
|||||||||
Stack |
|
|
void main() { suspend } |
|
|
|
|
uCondition variables; |
|||||||
|
|
public: |
|
|
|
|
|
|
void main() { suspend/wait/signal/accept } |
||||||
No Thread |
|
|
|
|
|
|
|
|
|||||||
|
|
m() { resume } |
|
|
|
|
public: |
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
}; |
|
|
|
|
|
|
|
m() { resume/wait/signal/accept } |
|||||
|
|
|
|
|
|
|
|
|
|
}; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8 |
|
_Task T { |
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
Stack |
|
|
|
|
|
|
|
|
|
|
uCondition variables; |
||||
|
|
|
|
|
|
|
|
|
void main() { wait/signal/accept } |
||||||
Thread |
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
public: |
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
m() { wait/signal/accept } |
|||
|
|
|
|
|
|
|
|
|
|
}; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Figure 1: µC++ constructs.
http://www.ddj.com |
Dr. Dobb’s Journal, February 2006 |
37 |

in important domains, direct support of the coroutine is crucial, independent of concurrency.
Monitor
A monitor is a concurrency abstraction that encapsulates a shared resource with implicit mutual exclusion and provides for complex synchronization among tasks using the resource; see Listing Three.
Any member routine can be qualified with the MES qualifiers, _Mutex/_Nomutex, indicating the presence or absence of MES, respectively. Only one thread at a time can be executing among the mutex routines of a monitor object; other threads calling mutex routines of the same object implicitly block. Recursive entry is allowed for the thread currently using the monitor; that is, it may call other mutex members. The MES qualifiers can also qualify a class, which defines the default qualification for the public member routines. Hence, the presence of a single mutex member in a class makes it a monitor. Member variables cannot be MES qualified. The destructor of a monitor is always _Mutex, because the thread terminating a monitor object must wait if another thread is executing in it.
The mutex property ensures exclusive access to the monitor’s data by multiple threads. For simple cases, such as an atomic counter, exclusive access is sufficient and the order of access is unimportant. For complex cases, the order of access can be crucial for correctness; for example, one task may need to communicate information to another task and wait for a reply, or a resource may have strict ordering rules with respect to thread usage. Ordering is controlled by threads synchronizing among
(a)calling
shared data
wait |
signal |
condition c |
urgent |
|
|
signalBlock |
|
|
exit |
(b) mutex routines |
|
m1 |
m2 |
calling shared data
 urgent exit
urgent exit
Figure 2: Monitor synchronization: (a) condition variable; (b) accept statement.
themselves within a monitor using condition variables and operations wait( ), signal( ), signalBlock( ), or an _Accept statement on mutex members.
A condition variable is a place where a task within the monitor can wait for an event to occur by another task using the monitor. Figure 2(a) illustrates the internal parts of a monitor object for synchronization with condition variables. Calling threads wait until no mutex member is active. A condition variable (for example, c) is a queue of waiting threads. The thread active in the monitor object waits on queue c by executing c.wait( ) (dotted line), which either implicitly restarts the last signalled thread, or if no signalled threads, releases the monitor lock so a new thread may enter. The active thread may execute c.signal( ) (dashed line) to restart a waiting thread at the front of a condition queue; the signalled thread can only restart after the signaler thread blocks or exits due to the mutual exclusion property, which is accomplished by having the signalled thread wait temporarily on the hidden urgent condition. Alternatively, the active thread may execute c.signalBlock( ) (solid line), which makes the active thread wait on the urgent queue and immediately starts the signalled thread at the front of the queue. Using these mechanisms, order of access within the monitor can be precisely controlled.
Tasks within the monitor can wait for an event to occur by a calling task using an accept statement. Figure 2(b) illustrates the internal parts of a monitor object for synchronization with an _Accept statement. _Accept selects which mutex member call to execute next (like Ada’s select). _Accept(m1) unblocks the thread on the front of the mutex queue after the accepter is implicitly blocked (like signalBlock). If there is no calling task, the accepter waits (on the hidden urgent queue) until a call to the specified member occurs. When the member call ends, the accepter implicitly restarts after the _Accept statement. _Accept can appear at any level of routine nesting in the monitor. The _Accept statement can check multiple mutex members for calls:
_Accept( m1, m2,…);
The call on the first nonempty mutex queue is selected (so the order of member names is important); if no calls are pending, the accepter waits until a call occurs. Finally, each selected member can be separated and supplied with a guard:
_When( conditional-expression ) _Accept( m1 ) statement
else _When( conditional-expression ) _Accept( m2 ) statement
…
else
statement
The guard must be true before a mutex queue is considered; if there is a terminating else, the accepter does not block, rather it polls for callers. The statement after an _Accept is executed by the accepter after the mutex call, allowing it to perform different actions depending on which call occurred.
Monitor Examples
Listing Four(a) shows the classic datingservice problem implemented with condition variables, where two kinds of tasks exchange information based on some criteria. In this case, there are girl and boy tasks exchanging phone numbers if they have matching compatibility codes (values 0 –19). A girl task checks if a boy with the same code is waiting. If not, she waits; otherwise, she copies her phone number to the shared variable GirlPhoneNo, and does a signalBlock to immediately restart the waiting boy while she waits on the urgent queue. The waiting boy restarts, copies his phone number to the shared variable BoyPhoneNo, and returns with the girl’s phone number. The waiting girl is then implicitly restarted from the urgent queue after the boy returns, and she now returns with the boy’s phone number. Listing Four(b) shows the classic read/write problem implemented with _Accept, where multiple reader tasks can simultaneously read a resource, but writer tasks must be serialized to write the resource. Tasks access the resource like this:
ReadersWriter rw; |
|
reader task |
writer task |
rw.StartRead(); |
rw.StartWrite(); |
// read resource |
// write resource |
rw.EndRead(); |
rw.EndWrite(); |
The variables rcnt and wcnt count the number of simultaneous reader or writer tasks using the resource. EndRead/EndWrite decrement the appropriate counter when a task finishes using the resource. StartRead checks if a writer is using the resource, and if so, accepts EndWrite, causing the reader task to wait on the urgent queue and preventing calls to any other mutex member. When the current writer finishes writing, it calls EndWrite; then the waiting reader implicitly restarts in
StartRead and increments rcnt. StartWrite begins with the same check for a writer and the same actions as for a reader if a writer is using the resource. Alternatively, if there are rcnt readers using the resource, the writer loops and performs rcnt accepts of EndRead, one for each of the completing reader tasks. After the last reader finishes reading and completes its call to EndRead, the waiting writer implicitly restarts and increments wcnt. Because the accept statement strictly controls entry into
38 |
Dr. Dobb’s Journal, February 2006 |
http://www.ddj.com |

the monitor, new (calling) tasks may not enter out of order.
Coroutine Monitor
The properties of a coroutine and monitor can be combined to generate a concurrency abstraction for resource sharing and synchronization along with retaining data and execution state; see Listing Five.
A coroutine monitor is ideal for an FSM used by multiple threads, such as a shared formatter printer. The printer is the shared resource called by multiple threads to print each thread’s data, and the printer can be a complex FSM organizing the data into rows and columns with appropriate markings and headings. Combining these fundamental properties into a single construct simplifies the job of developing the solution for a complex problem.
Task
The properties of a coroutine monitor can be combined with a thread to generate a concurrency abstraction for an active object that dynamically manages a resource; see Listing Six, for example.
Active objects appear in many concurrent languages. The use of both wait/signal on condition variables and accepting mutex members occurs frequently in a task (less so in a monitor). Finally, because the destructor is a mutex member, it can be accepted to determine when to terminate a task or monitor.
Listing Seven(a) shows a basic worker task, Adder, generating the subtotals for each row of a global matrix by summing the elements of a particular row. (Global variables are used to simplify the example.) In µC++, the member routine uMain::main serves as the program’s main (starting) routine. This routine reads the matrix and starts a block that creates an array of Adder tasks, one for each row of the matrix. Each task’s main starts implicitly after its constructor completes — no explicit start is needed. Similarly, no explicit join is needed because the block containing the array of tasks cannot end until all the tasks in the array terminate, otherwise, the storage for the tasks could be deallocated while threads are executing. After all tasks in the block terminate, the block allocating the array of tasks ends, and the subtotals generated by each worker task can be safely summed to obtain the total. The constructor for each Adder task selects a specific row to sum by incrementing a shared variable; no mu-
tual exclusion is necessary for the selection as each task of the array is created serially. The main member of each Adder task adds the matrix elements for its particular row in its corresponding subtotal location.
Listing Seven(b) shows a classic administrator server, where clients call different members for service. The server may provide multiple interface members for different kinds of clients and client requests. A client’s call may be serviced immediately or delayed using condition variables. The server’s main loops accept client calls using the _Accept statement; an accepted call may complete immediately or require subsequent servicing and signalling of the delayed client. Finally, the server’s destructor is also being accepted to know when the server is being deleted by another thread.
Miscellaneous µC++ Features
µC++ has a number of other features that integrate concurrency with C++:
•Both termination and resumption exception handling are supported, as well as the ability to raise exceptions among coroutines and tasks; see Listing Eight(a). For resumption, the stack is not unwound, and control returns after the _Resume when the handler completes. The _At clause provides nonlocal delivery of an exception to another coroutine or task. Nonlocal delivery of exceptions is controlled by _Enable and _Disable statements; see Listing Eight(b). Specifying no exceptions enables/disables all exceptions.
•The execution environment can be structured into multiple clusters of tasks and processors. Each cluster has a scheduler to control selection of its tasks to run on its processors; tasks and processors can migrate among clusters.
•C++ streams and UNIX files/sockets are augmented to be thread safe, ob- ject-oriented, and nonblocking; for example, safe stream I/O is performed like this:
isacquire( cin ) >> . . .; osacquire( cout ) << ...<< endl;
The declaration at the start of the I/O expression provides necessary locking of the specified stream for the duration of the expression. There are three classes for accessing sockets: uSocketServer, uSocketAccept, and uSocketClient, which hide most of the socket complexity and
support connectionless and connected protocols with timeout capabilities.
•Basic real-time programming is available through three extensions of the task:
_RealTimeTask R {…}; _PeriodicTask P {…}; _SporadicTask S {…};
Fixed and dynamic priority schedulers are provided for use with clusters, including a transitive priority-inheritance protocol. The _Accept statement is extended to handle timeouts:
_Accept( M1, M2 ) {…} else _Accept ( M3 ) {…}
else _Timeout( 1 ) {…} // restart after // 1 second if // no call
•There is a debug mode for testing with many assertions and runtime checks, and µC++ also generates reasonable error messages. µC++ compiles on GCC 3.2 or greater and Intel icc 8.1/9.0; for Linux Intel x86/Itanium and AMD 32/64; Solaris 8/9/10 SPARC; and IRIX 6.x MIPS.
Conclusion
Providing concurrency via low-level libraries such as pthreads makes no sense for C++. This approach is error prone and does not integrate with existing C++ mechanisms. Medium-level approaches that attempt to leverage existing language features with a concurrency library also fall short, as programmers still struggle with multiple coding conventions and limitations of use, and some primitive concurrency properties are still hidden from the compiler. To truly help you and the compiler, concurrent programming requires high-level concurrency models and constructs. The three fundamental properties in concurrency— thread, execution context, and mutual-exclusion/ synchronization— can be integrated directly into C++’s core programming notion— the class — and subsequently work with other C++ mechanisms. This approach retains the language’s object-oriented programming model and provides multiple concurrency approaches and models, while requiring only a few new keywords and mechanisms in C++. µC++ is a full implementation of these ideas, providing a system that lets you tackle complex concurrent projects.
DDJ
Listing One
_Coroutine C {
void main() { // distinguished member / executes on coroutine's stack
...suspend()... // restart last resume
}
public:
void m1(...) {... resume();...} // restart last suspend void m2(...) {... resume();...} // restart last suspend
};
(continued on page 40)
http://www.ddj.com |
Dr. Dobb’s Journal, February 2006 |
39 |

(continued from page 39)
Listing Two
_Coroutine Phone { public:
enum status { MORE, GOOD, BAD }; private:
char ch; status stat; void main() {
int i;
stat = MORE; // continue passing characters if ( ch == '(') { // optional area code ?
for ( i = 0; i < 3; i += 1 ) { suspend();
if ( ! isdigit(ch) ) { stat = BAD; return; }
}
suspend();
if ( ch != ')') { stat = BAD; return; } suspend();
}
for ( i = 0; i < 3; i += 1 ) { // region code ? if ( ! isdigit(ch) ) { stat = BAD; return; }
suspend();
}
if ( ch != '-') { stat = BAD; return; } // separator ? for ( i = 0; i < 4; i += 1 ) { // local code ?
suspend();
if ( ! isdigit(ch) ) { stat = BAD; return; }
}
stat = GOOD;
}
public:
status next( char c ) { // pass one character at a time to FSM ch = c;
resume(); // activate coroutine return stat;
}
};
Listing Three
_Mutex class M { // default MES for public member routines // SHARED DATA ACCESSED BY MULTIPLE THREADS
uCondition c1, c2[10], *c3 = new uCondition; //different condition variables // default for private/protected is no MES
void m1(...) {... /* MES statements */...} // no MES _Mutex void m2(...) {... /* MES statements */...}; // MES
public:
void m3(...) {.../* MES statements */...} // MES _Nomutex void m4(...) {...} // no MES
... // destructor is ALWAYS mutex
};
Listing Four
(a)
_Mutex class DatingService { uCondition Girls[20], Boys[20]; int GirlPhoneNo, BoyPhoneNo;
public:
int Girl( int PhoneNo, int code ) { if ( Boys[code].empty() ) {
Girls[code].wait(); GirlPhoneNo = PhoneNo;
} else {
GirlPhoneNo = PhoneNo; Boys[code].signalBlock();
}
return BoyPhoneNo;
}
int Boy( int PhoneNo, int code ) { if ( Girls[code].empty() ) { Boys[code].wait();
BoyPhoneNo = PhoneNo; } else {
BoyPhoneNo = PhoneNo; Girls[code].signalBlock();
}
return GirlPhoneNo;
}
};
(b)
_Mutex class ReadersWriter { int rcnt, wcnt;
public:
void ReadersWriter() { rcnt = wcnt = 0;
}
void EndRead() { rcnt -= 1;
}
void EndWrite() { wcnt -= 1;
}
void StartRead() {
if ( wcnt == 1 ) _Accept( EndWrite ); rcnt += 1;
}
void StartWrite() {
if ( wcnt == 1 ) _Accept( EndWrite ); else while ( rcnt > 0 )
_Accept( EndRead ); wcnt += 1;
}
};
Listing Five
_Mutex _Coroutine CM { // default MES for public member routines
uCondition c1,c2[10],*c3 = new uCondition; // different condition variables void m1(...) {.../* MES statements */ ...} // no MES
_Mutex void m2(...) { .../* MES statements */ ...}; // MES void main() {...} // distinguished member / has its own stack
public:
void m3(...) { ...resume()/* MES statements */ ...} // MES _Nomutex void m4(...) { ...resume(); ...} // no MES
...// destructor is ALWAYS mutex
};
Listing Six
_Task T { // default MES for public member routines
uCondition c1,c2[10],*c3 = new uCondition; // different condition variables void m1( ... ) {.../* MES statements */ ... } // no MES
_Mutex void m2(...) {.../* MES statements */...}; // MES
void main() {...} // distinguished member/has own stack/thread starts here public:
void m3(...) {.../* MES statements */ ...} // MES _Nomutex void m4(...) {...} // no MES
...// destructor is ALWAYS mutex
};
Listing Seven
(a)
const int rows = 10, cols = 10; int M[rows][cols], ST[rows];
_Task Adder { // add specific row
static int row; // sequential access int myrow, c;
void main() {
ST[myrow] = 0; // subtotal location for ( c = 0; c < cols; c += 1 )
ST[myrow] += M[myrow][c];
}
public:
Adder() { myrow = row++; } // choose row
};
int Adder::row = 0; void uMain::main() {
// read matrix
{
Adder adders[rows]; // create threads } // wait for threads to terminate
int total = 0; // sum subtotals
for ( int r = 0; r < rows; r += 1 ) total += ST[r];
cout << total << endl;
}
(b)
_Task Server { uCondition delay; void main() {
for ( ;; ) { // for each client request _Accept( ~Server ) { // terminate ?
break;
// service each kind of client request
}else _Accept( workReq1 ) {
...
delay.signalBlock(); // restart client
...
}else _Accept( workReq2 ) {
...
}
}
// shut down
}
public:
void workReq1( Req1_t req ) {
...delay.wait();...// service not immediate? // otherwise service request
}
void workReq2( Req2_t req ) { ... }
...
};
Listing Eight
(a)
_Throw [ throwable-exception [ _At coroutine/task-id ] ] ; // termination _Resume [ resumable-exception [ _At coroutine/task-id ] ] ; // resumption
(b)
_Enable <E1><E2>... {
// exceptions E1, E2, ... delivered
}
_Disable <E1><E2>... {
// exceptions E1, E2, ... not delivered
}
DDJ
40 |
Dr. Dobb’s Journal, February 2006 |
http://www.ddj.com |

Native Queries for Persistent Objects
Conquering the shortcomings of string-based APIs
WILLIAM R. COOK
AND CARL ROSENBERGER
While today’s object databases and object-relational mappers do a great job in making object persistence feel native to developers,
queries still look foreign in object-oriented programs because they are expressed using either simple strings or object graphs with strings interspersed. Let’s take a look at how existing systems would express a query such as “find all Student objects where the student is younger than 20.” This query (and other examples in this article) assume the Student class defined in Example 1. Different data access APIs express the query quite differently, as illustrated in Example 2. However, they all share a common set of problems:
•Modern IDEs do not check embedded strings for syntactic and semantic errors. In Example 2, both the field age and the value 20 are expected to be numeric, but no IDE or compiler checks that this is actually correct. If you mistyped the query code — changing the name or type of the field age, for example — all of the queries in Example 2 would break at runtime, without a single notice at compile time.
•Because modern IDEs will not automatically refactor field names that appear in strings, refactorings cause class model and query strings to get out of
William is an assistant professor of computer science at the University of Texas in Austin. Carl is chief software architect at db4objects. They can be contacted at wcook@cs.utexas.edu and carl@db4o.com, respectively.
sync. Suppose the field name age in the class Student is changed to _age because of a corporate decision on standard coding conventions. Now all existing queries for age would be broken, and would have to be fixed by hand.
•Modern agile development techniques encourage constant refactoring to maintain a clean and up-to-date class model that accurately represents an evolving domain model. If query code is difficult to maintain, it delays decisions to refactor and inevitably leads to lowquality source code.
•All the queries in Example 2 operate against the private implementation of the Student class student.age instead of using its public interface student.getAge( )/student.Age (in Java/C#, respectively). Consequently, they break objectoriented encapsulation rules, disobeying the principle that interface and implementation should be decoupled.
•You are constantly required to switch contexts between implementation language and query language. Queries cannot use code that already exists in the implementation language.
•There is no explicit support for creating reusable query components. A complex query can be built by concatenating query strings, but none of the reusability features of the programming language (method calls, polymorphism, overriding) are available to make this process manageable. Passing a parameter to a string-based query is also awkward and error prone.
•Embedded strings can be subject to injection attacks.
Design Goals
Our goal is to propose a new approach that solves many of these problems. This article is an overview of the approach, not a complete specification. What if you could simply express the same query in plain Java or C#, as in Example 3? You could write queries without having to think about a custom query language or API. The IDE could actively help to reduce typos. Queries would be fully typesafe and accessible to the refactoring features of the IDE. Queries could also be prototyped,
tested, and run against plain collections in memory without a database back end.
At first, this approach seems unsuitable as a database query mechanism. Naively executing Java/C# code against the complete extent of all stored objects of a class would incur a huge performance penalty
“Queries should be expressed in the implementation language, and they should obey language semantics”
because all candidate objects would have to be instantiated from the database. A solution to this problem was presented in “Safe Query Objects” by William Cook and Siddhartha Rai [3].
The source code or bytecode of the Java/C# query expression can be analyzed and optimized by translating it to the underlying persistence system’s query language or API (SQL [6], OQL [1,8], JDOQL [7], EJBQL [1], SODA [10], and so on), and thereby take advantage of indexes and other optimizations of a database engine. Here, we refine the original idea of safe query objects to provide a more concise and natural definition of native queries. We also examine integrating queries into Java and .NET by leveraging recent features of those language environments, including anonymous classes and delegates.
Therefore, our goals for native queries include:
•100-percent native. Queries should be expressed in the implementation language (Java or C#), and they should obey language semantics.
•100-percent object oriented. Queries should be runnable in the language
http://www.ddj.com |
Dr. Dobb’s Journal, February 2006 |
41 |

itself, to allow unoptimized execution against plain collections without custom preprocessing.
•100-percent typesafe. Queries should be fully accessible to modern IDE features such as syntax checking, type checking, refactoring, and so on.
•Optimizable. It should be possible to translate a native query to a persistence architecture’s query language or API for performance optimization. This could be done at compile time or at load time by source code or bytecode analysis and translation.
Defining the Native Query API
What should native queries look like? To produce a minimal design, we evolve a simple query by adding each design attribute, one at a time, using Java and C# (.NET 2.0) as the implementation languages.
(a)
// Java
public class Student { private String name; private int age;
public String getName(){ return name;
}
public int getAge(){ return age;
}
}
(b)
// C#
public class Student { private string name; private int age; public string Name {
get { return name; }
}
public int Age {
get{ return age; }
}
}
Example 1: (a) Java class; (b) C# class.
Let’s begin with the class in Example 1. Furthermore, we assume that we want to query for “all students that are younger than 20 where the name contains an f.”
1.The main query expression is easily written in the programming languages; see Example 4.
2.We need some way to pass a Student object to the expression, as well as a way to pass the result back to the query processor. We can do this by defining a student parameter and returning the result of our expression as a Boolean value; see Example 5.
3.Now we have to wrap the partial construct in Example 5 into an object that is valid in our programming languages. That lets us pass it to the database engine, a collection, or any other query processor. In .NET 2.0, we can simply use a delegate. In Java, we need a named method, as well as an object of some class to put around the method. This requires, of course, that we choose a name for the method as well as a name for the class. We decided to follow the example that .NET 2.0 sets for collection filtering. Consequently, the class name is Predicate and the method name is match; see Example 6.
4.For .NET 2.0, we are done designing the simplest possible query interface. Example 6 is a valid object. For Java, our querying conventions should be standardized by designing an abstract base class for queries — the Predicate class (Example 7). We still have to alter our Java query object slightly by adding the extent type to comply with the generics contract (Example 8).
5.Although Example 8 is conceptually complete, we would like to finish the
(a)
String oql = "select * from student in AllStudents where student.age < 20"; OQLQuery query = new OQLQuery(oql);
Object students = query.execute();
(b)
Query query = persistenceManager.newQuery(Student.class, "age < 20"); Collection students = (Collection)query.execute();
(c)
Query query = database.Query(); query.Constrain(typeof(Student)); query.Descend("age").Constrain(20).Smaller(); IList students = query.Execute();
Example 2: (a) Object Query Language (OQL); (b) JDO Query Language (JDOQL); and (c) db4o SODA (using C#).
(a)
// Java
student.getAge() < 20 && student.getName().contains("f")
(b)
// C#
student.Age < 20 && student.Name.Contains("f")
Example 4: (a) Java; (b) C#.
derivation of the API by providing a full example. Specifically, we want to show what a query against a database would look like, so we can compare it against the string-based examples given in the introduction. Example 9 completes the core idea. We have refined Cook/Rai’s concept of safe queries by leveraging anonymous classes in Java and delegates in .NET. The result is a more concise and straightforward description of queries.
Adding all required elements of the API in a step-by-step fashion lets us find the most natural and efficient way of expressing queries in Java and C#. Additional features, such as parameterized and dynamic queries, can be included in native queries using a similar approach [4]. We have overcome the shortcomings of existing string-based query languages and provided an approach that promises improved productivity, robustness, and maintainability without loss of performance.
Specification Details
A final and thorough specification of native queries is only possible after practical experience. Therefore, this section is speculative. We would like to point out where we see choices and issues with the native query approach and how they might be resolved.
Regarding the API alone, native queries are not new. Without optimizations, we have merely provided “the simplest concept possible to run all instances of a class against a method that returns a Boolean value.” Such interfaces are well known: Smalltalk-80 [2, 5], for instance, includes methods to select items from a collection based on a predicate.
Optimization is the key new component of native queries. Users should be able to write native query expressions and the database should execute them with performance on par with the string-based queries that we described earlier.
Although the core concept of native queries is simple, the work needed to provide a solution is not trivial. Code written in a query expression must be analyzed and converted to an equivalent database query format. It is not necessary for all code in a native query to be translated. If the optimizer cannot handle some or all code in a query expression, there is always the fallback to instantiate the actual
(a)
// Java student.getAge() < 20
(b)
// C# student.Age < 20
Example 3: (a) Java query; (b) C# query.
42 |
Dr. Dobb’s Journal, February 2006 |
http://www.ddj.com |

objects and to run the query expression code, or part of it, with real objects after the query has returned intermediate values. Because this may be slow, it is helpful to provide developers with feedback at development time. This feedback might include how the optimizer “understands” query expressions, and some description of the underlying optimization plan created for the expressions. This will help developers adjust their development style to the syntax that is optimized best and will enable developers to provide feedback about desirable improved optimizations.
How will optimization actually work? At compile or load time, an enhancer (a separate application or a plug-in to the compiler or loader) inspects all native query expressions in source code or bytecode, and will generate additional code in the most efficient format the database engine supplies. At runtime, this substituted code will be executed instead of the original Java/C# methods. This mechanism will be transparent to developers after they add the optimizer to their compilation or build process (or both).
Our peers have expressed doubts that satisfactory optimization is possible. Because both the native query format and the native database format are well defined, and because the development of an optimizer can be an ongoing task, we are very optimistic that excellent results are achievable. The first results that Cook/Rai produced with a mapping to JDO implementations are very encouraging. db4objects (http://www.db4o.com/) already shows a first preview of db4o with unoptimized native queries today and plans to ship a
//pseudoJava (Student student){
return student.getAge() < 20
&&student.getName().contains("f");
}
//pseudoC#
(Student student){
return student.Age < 20
&& student.Name.Contains("f");
}
Example 5: PseudoJava and pseudoC#.
(a)
// Java
new Predicate(){
public boolean match(Student student){ return student.getAge() < 20
&& student.getName().contains("f");
}
}
(b)
// C#
delegate(Student student){ return student.Age < 20
&& student.Name.Contains("f");
}
Example 6: (a) Java; (b) C#.
production-ready Version 5.0 with optimized native queries.
Ideally, any code should be allowed in a query expression. In practice, restrictions are required to guarantee a stable environment, and to place an upper limit on resource consumption. We recommend:
•Variables. Variable declarations should be legal in query expressions.
•Object creation. Temporary objects are essential for complex queries so their
creation should also be supported in query expressions.
•Static calls. Static calls are part of the concept of OO languages, so they should be legal.
•Faceless. Query expressions are intended to be fast. They should not interact with the GUI.
•Threads. Query expressions will likely be triggered in large numbers. Therefore, they should not be allowed to create threads.
// Java
public abstract class Predicate <ExtentType> { public <ExtentType> Predicate (){}
public abstract boolean match (ExtentType candidate);
}
Example 7: Predicate class.
http://www.ddj.com |
Dr. Dobb’s Journal, February 2006 |
43 |

•Security restrictions. Because query expressions may actually be executed with real objects on the server, there need to be restrictions on what they are allowed to do there. It would be reasonable to allow and disallow method execution and object creation in certain namespaces/packages.
•Read only. No modifications of persistent objects should be allowed within running query code. This limitation guarantees repeatable results and keeps transactional concerns out of the specification.
•Timeouts. To allow for a limit to the use of resources, a database engine may choose to timeout long-running query code. Timeout configuration does not have to be part of the native query specification, but it should be recommended to implementors.
•Memory limitation. Memory limitations can be treated like timeouts. A configurable upper memory limit per query expression is a recommended feature for implementors.
•Undefined actions. Unless explicitly not permitted by the specification, all constructs should be allowed.
It seems desirable that processing should continue after any exception oc-
new Predicate <Student> () {
public boolean match(Student student){ return student.getAge() < 20
&& student.getName().contains("f");
}
}
Example 8: Adding the Java extent type.
curs in query expressions. A query expression that throws an uncaught exception should be treated as if it returned False. There should be a mechanism for developers to discover and track exceptions. We recommend that implementors support both exception callback mechanisms and exception logging.
The sort order of returned objects might also be defined using native code. An exact definition goes beyond the scope of this article but, using a Java comparator, a simple example might look like Example 10. This code should be runnable both with and without an optimization processor. Querying and sorting could be optimized to be executed as one step on the database server, using the sorting functionality of the database engine.
Conclusion
There are compelling reasons for considering native queries as a mainstream standard. As we have shown, they overcome the shortcomings of string-based APIs. The full potential of native queries will be explored with their use in practice. They have already been demonstrated to provide high value in these areas:
•Power. Standard object-oriented programming techniques are available for querying.
•Productivity. Native queries enjoy the benefits of advanced development tools, including static typing, refactoring, and autocompletion.
•Standard. What SQL has never managed to achieve because of the diversity of
(a)
// Java
List <Student> students = database.query <Student> ( new Predicate <Student> () {
public boolean match(Student student){ return student.getAge() < 20
&& student.getName().contains("f");
}
});
(b)
// C#
IList <Student> students = database.Query <Student> ( delegate(Student student){
return student.Age < 20
&& student.Name.Contains("f");
});
Example 9: (a) Java; (b) C#.
// Java
List <Student> students = database.query <Student> ( new Predicate <Student> () {
public boolean match(Student student){
return student.getAge() < 20 && student.getName().contains("f");
}
});
Collections.sort(students, new Comparator <Student>(){ public int compare(Student student1, Student student2) {
return student1.getAge() - student2.getAge();
}
});
Example 10: Defining the sort order of returned objects.
SQL dialects may be achievable for native queries: Because the standard is well defined by programming-language specifications, native queries can provide 100-percent compatibility across different database implementations.
•Efficiency. Native queries can be automatically compiled to traditional query languages or APIs to leverage existing high-performance database engines.
•Simplicity. As shown, the API for native queries is only one class with one method. Hence, native queries are easy to learn, and a standardization body will find them easy to define. They could be submitted as a JSR to the Java Community Process.
Acknowledgments
Thanks to Johan Strandler for his posting to a thread at TheServerSide that brought the two authors together, Patrick Roomer for getting us started with first drafts of this paper, Rodrigo B. de Oliveira for contributing the delegate syntax for .NET, Klaus Wuestefeld for suggesting the term “native queries,” Roberto Zicari, Rick Grehan, and Dave Orme for proofreading drafts of this article, and to all of the above for always being great peers to review ideas.
References
[1]Cattell, R.G.G., D.K. Barry, M. Berler, J. Eastman, D. Jordan, C. Russell, O. Schadow, T. Stanienda, and F. Velez, editors. The Object Data Standard ODMG 3.0. Morgan Kaufmann, 2000.
[2]Cook, W.R. “Interfaces and Specifications for the Smalltalk Collection Classes.” OOPSLA, 1992.
[3]Cook, W.R. and S. Rai. “Safe Query Objects: Statically Typed Objects as Remotely Executable Queries.” G.C. Roman, W.G. Griswold, and B. Nuseibeh, editors. Proceedings of the 27th International Conference on Software Engineering (ICSE), ACM, 2005.
[4]db4objects (http://www.db4o.com/).
[5]Goldberg, A. and D. Robson. Small- talk-80: The Language and Its Implementation. Addison-Wesley, 1983.
[6]ISO/IEC. Information technology — database languages — SQL — Part 3: Call-level interface (SQL/CLI). Technical Report 9075–3:2003, ISO/IEC, 2003.
[7]JDO (http://java.sun.com/products/ jdo/).
[8]ODMG (http://www.odmg.org/).
[9]Russell, C. Java Data Objects (JDO) Spec-
ification JSR-12. Sun Microsystems, 2003. [10]Simple Object Database Access (SODA) (http://sourceforge.net/projects/
sodaquery/).
[11]Sun Microsystems. Enterprise JavaBeans Specification, Version 2.1. 2002 (http://java.sun.com/j2ee/docs.html).
DDJ
44 |
Dr. Dobb’s Journal, February 2006 |
http://www.ddj.com |

Dynamic Bytecode
Instrumentation
A new way to profile Java applications
IAN FORMANEK
AND GREGG SPORAR
Profiling Java applications is often considered a black art. There are tools available to help you track down performance bottlenecks and memory-allocation problems, but they are not always easy to use, particularly when profiling large applications. Because large applications tend to be those that most need profiling, this presents a significant problem. It is therefore not surprising that Java applications have a reputation for running slowly — in many cases, this is solely because no performancerelated analysis and
tuning has been done.
Dynamic bytecode instrumentation is an innovative solution to these problems. It lets you control precisely which parts of an application are profiled. As a result, only relevant information is reported, and the impact on application performance is reduced so that even large applications can be profiled easily.
Gregg is a technology evangelist for Sun Microsystems and Ian is project lead and architect of the NetBeans Profiler. They can be contacted at gregg.sporar@sun
.com and ian.formanek@sun.com, respectively.
Obstacles to Profiling
The two biggest obstacles to profiling have been runtime overhead and interpretation of the results.
The runtime overhead imposed by a Java profiler can be a showstopper. The instrumentation added by the profiler can cause the application to run differently — which may change the performance problem symptoms, making it harder to find the cause of the problem. At the very least, if the application is running more slowly, it will take longer for it to get to the point where problems occur. In a worst-case scenario, the application might not even run correctly at all — unexpected timeouts caused by slower performance could result in an application crash.
After wrestling with those issues, you then have to interpret the results produced by the profiler. This can be overwhelming, even when working on a small application. For large applications, it can be a serious impediment to tracking down the cause of the problem. The larger the application, the higher the likelihood it has code in it that you did not write and therefore might not understand. This is particularly true for web and enterprise applications with several layers of abstraction that are specifically designed to be hidden from developers. Additionally, larger applications tend to have larger heaps and more threads. Profilers will deliver information on all of these things, which is usually more information than you can interpret efficiently. Filters are provided, but frequently are not precise enough and can therefore end up excluding useful information.
Traditional Profiler Technologies
There are two Java APIs available for profiling — the Java Virtual Machine Profiling Interface (JVMPI) and Java Virtual Machine Tool Interface (JVMTI). Most Java profiling tools use one of these APIs for doing instrumentation of an application and for notification of Virtual Machine (VM) events.
“Dynamic bytecode instrumentation lets you control precisely which parts of an application are profiled”
The most widely used profiling technique is bytecode instrumentation. The profiler inserts bytecode into each class. For CPU performance profiling, these bytecodes are typically methodEntry( ) and methodExit( ) calls. For memory profiling, the bytecodes are inserted after each new or after each constructor. All of this insertion of bytecodes is done either by a postcompiler or a custom class loader.
The key limitation of this technique is that once a class has been modified, it does not change. That lack of flexibility causes problems. If you choose to profile the entire application, the overhead of all
http://www.ddj.com |
Dr. Dobb’s Journal, February 2006 |
45 |