

ЭВУ 2 семестр / Презентации ЭВУ в пдф / метода моховикова
.pdfверсального общепринятого имени для этой промежуточной политики, хотя часто используется термин – главным образом, «инклюзивно».
Преимущество исключительных кэшей в том, что они хранят больше данных. Это преимущество больше, когда исключительный кэш L1 сопоста-
вим по размеру с кэшэм L2, и меньше, если кэш L2 – во много раз больше,
чем кэш L1. Когда L1 пропускает и L2 получает доступ в случае попадания,
строка кэша попадания в L2 обменивается со строкой в L1. Этот обмен рабо-
тают ненамного чаще, чем только копирование строки из L2 в L1, которое делает инклюзивный кэш.
Проблема синхронизации между различными кэшами (как одного, так и множества процессоров) решается когерентностью кэша. Существует три ва-
рианта обмена информацией между кэш-памятью различных уровней, или,
как говорят, кэш-архитектуры: инклюзивная, эксклюзивная и неэксклюзив-
ная. Инклюзивная архитектура предполагает дублирование информации кэ-
ша верхнего уровня в нижнем (предпочитает фирма Intel). Эксклюзивная кэш-память предполагает уникальность информации, находящейся в различ-
ных уровнях кэша (предпочитает фирма AMD).
Кэш жертв
«Кэш жертв» (англ. Victim cache или Victim buffer) – это небольшой спе-
циализированный кэш, хранящий те кэш-линии, которые были недавно вы-
теснены из основного кэша микропроцессора при их замещении. Данный кэш располагается между основным кэшем и его переходом (англ. refill path).
Обычно кэш жертв является полностью ассоциативным и служит для умень-
шения количества конфликтных промахов (conflict miss). Многие часто ис-
пользуемые программы не требуют полного ассоциативного отображения для всех попыток доступа к памяти. По статистике, только небольшая доля обращений к памяти потребует высокой степени ассоциативности. Именно для таких обращений служит кэш жертв, предоставляющий высокую ассо-
221

циативность для подобных редких запросов. Был предложен Norman Jouppi (DEC) в 1990 г. Размер такого кэша может составлять от 4 до 16 кэш-линий.
Кэш трасс
Одним из наиболее экстремальных случаев специализации кэшей можно считать кэш трасс (англ. trace cache), используемый в процессорах Intel Pentium 4. Кэш трасс – это механизм для увеличения пропускной способно-
сти загрузки инструкций и для уменьшения тепловыделения (в случае
Pentium 4) за счет хранения декодированных трасс-инструкций. Таким обра-
зом этот кэш исключал работу декодера при повторном исполнении недавно выполнявшегося кода.
Одной из ранних публикацией о кэше трасс была статья коллектива ав-
торов (Eric Rotenberg, Steve Bennett и Jim Smith), вышедшая в 1996 г. под на-
званием «Trace Cache: a Low Latency Approach to High Bandwidth Instruction
Fetching» («Кэш трасс: низколатентный подход для обеспечения высокой пропускной способности загрузки инструкций»). Digital Object Identifier :
10.1109/MICRO.1996.566447
Кэш трасс сохраняет декодированные инструкции либо после их деко-
дирования, либо после окончания их исполнения. Обобщая, инструкции до-
бавляются в кэш трасс в группах, представляющих собой либо базовые бло-
ки, либо динамические трассы. Динамическая трасса (путь исполнения) со-
стоит только из инструкций, результаты которых были значимы (использова-
лись впоследствии) и удаляет инструкции, которые находятся в не испол-
няющихся ветвях, кроме того, динамическая трасса может быть объединени-
ем нескольких базовых блоков. Такая особенность позволяет устройству под-
грузки инструкций в процессоре загружать сразу несколько базовых блоков без необходимости заботиться о наличии ветвлений в потоке исполнения.
Линии трасс хранятся в кэше трасс по адресам, соответствующим счет-
чику инструкций первой машинной команды из трассы, к которым добавлен набор признаков предсказания ветвлений. Такая адресация позволяет хранить различные трассы исполнения, начинающиеся с одного адреса, но представ-
222
ляющие различные ситуации по результату предсказания ветвлений. На ста-
дии подгрузки инструкции (instruction fetch) конвейера инструкций для про-
верки попадания в кэш трасс используется как текущий счетчик инструкций
(program counter), так и состояние предсказателя ветвлений. Если попадание свершилось, линия трассы непосредственно подается на конвейер без необ-
ходимости опрашивать обычный кэш (L2) или основное ОЗУ. Кэш трасс по-
дает машинные команды на вход конвейера, пока не кончится линия трассы,
либо пока не произойдет ошибка предсказания в конвейере. В случае прома-
ха кэш трасс начинает строить следующую линию трассы, загружая машин-
ный код из кэша или из памяти.
13.6. Способы отображения основной памяти на кэш
Алгоритм поиска и алгоритм замещения данных в кэше непосредствен-
но зависят от того, каким образом основная память отображается на кэш-
память. Принцип прозрачности требует, чтобы правило отображения основ-
ной памяти на кэш-память не зависело от работы программ и пользователей.
При кэшировании данных из оперативной памяти широко используются две основные схемы отображения: случайное и детерминированное.
В кэшах, построенных на основе случайного отображения, вытеснение старых данных происходит только в том случае, когда вся кэш-память запол-
нена и нет свободного места. Выбор данных на выгрузку осуществляется среди всех записей кэша. Обычно этот выбор основывается на тех же прие-
мах, что и в алгоритмах замещения страниц, например выгрузка данных, к
которым дольше всего не было обращений, или данных, к которым было меньше всего обращений. При случайном отображении элемент оперативной памяти в общем случае может быть размещен в произвольном месте кэш-
памяти. Для того чтобы в дальнейшем можно было найти нужные данные в кэше, они помещаются туда вместе со своим адресом, т. е. тем адресом, ко-
торый данные имеют в оперативной памяти. При каждом запросе к опера-
223

тивной памяти выполняется поиск в кэше, причем критерием поиска высту-
пает адрес оперативной памяти из запроса.
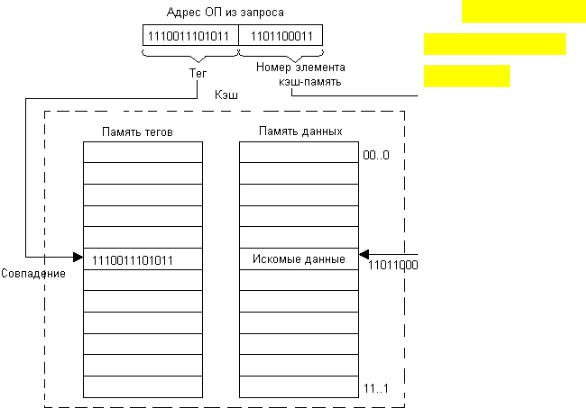
Очевидная схема простого перебора для поиска нужных данных в случае кэша оказывается непригодной из-за недопустимо больших временных за-
трат. Для кэшей со случайным отображением используется так называемый ассоциативный поиск, при котором сравнение выполняется не последова-
тельно с каждой записью кэша, а параллельно со всеми его записями (рис.
88). Признак, по которому выполняется сравнение, называется тегом (tag).
Рис. 88. Ассоциа-
тивный поиск в кэше со случайным отображе-
нием
В данном случае тегом является адрес данных в оперативной памяти.
Электронная реализация такой схемы приводит к удорожанию памяти, при-
чем стоимость существенно возрастает с увеличением объема запоминающе-
го устройства. Поэтому ассоциативная кэш-память используется в тех случа-
ях, когда для обеспечения высокого процента попадания достаточно неболь-
шого объема памяти.
Второй, детерминированный способ отображения предполагает, что лю-
бой элемент основной памяти всегда отображается в одно и то же место кэш-
224
памяти. В этом случае кэш-память разделена на строки, каждая из которых предназначена для хранения одной записи об одном элементе данных и име-
ет свой номер. Между номерами строк кэш-памяти и адресами оперативной памяти устанавливается соответствие «один ко многим»: одному номеру строки соответствует несколько (обычно достаточно много) адресов опера-
тивной памяти. В качестве отображающей функции может использоваться простое выделение нескольких разрядов из адреса оперативной памяти, ко-
торые интерпретируются как номер строки кэш-памяти (такое отображение называется прямым). Например, пусть в кэш-памяти может храниться 1 024
записи, т. е. кэш имеет 1 024 строки, пронумерованные от 0 до 1 023. Тогда любой адрес оперативной памяти может быть отображен на адрес кэш-
памяти простым отделением 10 двоичных разрядов (рис. 89).
Рис. 89. Де-
терминированное
отражение
Если же произошел кэш-промах, то данные считываются из оперативной памяти и копируются в кэш. Если строка кэш-памяти, в которую должен быть скопирован элемент данных из оперативной памяти, содержит другие
225
данные, то последние вытесняются из кэша. Заметим, что процесс замещения данных в кэш-памяти на основе прямого отображения существенно отлича-
ется от процесса замещения данных в кэш-памяти со случайным отображе-
нием. Во-первых, вытеснение данных происходит не только в случае отсут-
ствия свободного места в кэше, во-вторых, никакого выбора данных на за-
мещение не существует.
Во многих современных процессорах кэш-память строится на основе со-
четания этих двух подходов, что позволяет найти компромисс между сравни-
тельно низкой стоимостью кэша с прямым отображением и интеллектуально-
стью алгоритмов замещения в кэше со случайным отображением. При сме-
шанном подходе произвольный адрес оперативной памяти отображается не на один адрес кэш-памяти (как это характерно для прямого отображения) и
не на любой адрес кэш-памяти (как это делается при случайном отображе-
нии), а на некоторую группу адресов. Все группы пронумерованы. Поиск в кэше осуществляется вначале по номеру группы, полученному из адреса опе-
ративной памяти из запроса, а затем в пределах группы путем ассоциативно-
го просмотра всех записей в группе на предмет совпадения старших частей адресов оперативной памяти (рис. 90).
При промахе данные копируются по любому свободному адресу из однозначно заданной группы. Если свободных адресов в группе нет, то вы-
полняется вытеснение данных. Поскольку кандидатов на выгрузку несколько
– все записи из данной группы – алгоритм замещения может учесть интен-
сивность обращений к данным и тем самым повысить вероятность попаданий в будущем.
226

Рис. 90. Комбинирова-
ние прямого и случайного отображения
Таким образом, в данном способе комбинируется прямое отображение на группу и случайное отображение в пределах группы.
13.7.Архитектуры кэша
Впорядке ухудшения (увеличения длительности проверки на попада-
ние) и улучшения (уменьшения количества промахов):
кэш прямого отображения (англ. direct mapped cache) – наи-
лучшее время попадания, и, соответственно, лучший вариант для
больших кэшей;
2-канальный множественно-ассоциативный кэш (англ. 2-way set associative cache);
2-канальный skewed ассоциативный кэш (англ. the best tradeoff for caches whose sizes are in the range 4K-8K byte» – André Seznec);
227
4-канальный множественно-ассоциативный кэш (англ. 4-way set associative cache);
полностью ассоциативный кэш (англ. fully associative cache –
наилучший (самый низкий) процент промахов (miss rate), и лучший ва-
риант при чрезвычайно высоких затратах при промахе (miss penalty).
В зависимости от способа определения взаимного соответствия строки кэша и области основной памяти различают три архитектуры кэш-памяти:
кэш прямого отображения, полностью ассоциативный кэш и их комбинация – частичноили наборно-ассоциативный кэш.
13.7.1. Кэш прямого отображения
В кэш-памяти прямого отображения адрес памяти, по которому проис-
ходит обращение, однозначно определяет строку кэша, в которой может на-
ходиться требуемый блок. Принцип работы такого кэша рассмотрим на при-
мере несекторированного кэша объемом 256 Кбайт с размером строки 32
байт и объемом кэшируемой основной памяти 64 Мбайт. Структуру памяти в такой системе иллюстрирует рис. 91.
В начале каждого обращения к кэшируемой памяти контроллер первым делом считывает ячейку каталога с соответствующим индексом, сравнивает биты адреса тега со старшими битами адреса памяти и анализирует признак действительности. Этот анализ выполняется в специальном цикле слежения,
который иногда называют циклом запроса. Если в результате анализа выяс-
няется, что требуемого блока нет в кэше, генерируется цикл обращения к ос-
новной памяти – кэш-промах. В случае попадания запрос обслуживается кэш-памятью.
В случае промаха после считывания основной памяти приемником ин-
формации новые данные помещаются в строку кэша при условии, что она чистая, а в ее тег помещаются старшие биты адреса и устанавливается при-
228

знак действительности данных. Независимо от объема затребованных данных в кэш из основной памяти строка переписывается вся целиком. Если кон-
троллер кэша реализует упреждающее считывание, то в последующие сво-
бодные циклы шины обновляется также следующая строка, при условии, что она была чистой. Чтение «про запас» позволяет при необходимости осуще-
ствлять пакетный цикл чтения из кэша через границу строки.
Рис. 91. Кэш прямого отображения
Кэшируемая основная память условно разбивается на страницы (в дан-
ном случае по 256 Кбайт), размер которых совпадает с размером кэш-памяти
(256 Кбайт). Кэш-память делится на строки (256 Кбайт/32 байт = 8 К строк).
Архитектура прямого отображения подразумевает, что каждая строка кэша может отображать из любой страницы кэшируемой памяти только соответст-
вующую ей строку (на рис. 91 они находятся на одном горизонтальном уров-
не). Поскольку объем основной памяти больше объема кэша, на каждую строку кэша может претендовать множество блоков памяти с одинаковой
229
младшей частью адреса (смещение внутри страницы). Одна строка в опреде-
ленный момент может, естественно, содержать копию только одного из этих блоков. Номер (адрес) строки в кэш-памяти – это индекс (Index). Тег несет информацию о том, какой именно блок занимает данную строку (т. е. стар-
шая часть адреса или номер страницы). Память тегов должна иметь количе-
ство ячеек, равное количеству строк кэша, а ее разрядность должна быть дос-
таточной, чтобы вместить старшие биты адреса кэшируемой памяти, не по-
павшие на шину адреса кэш-памяти. Кроме адресной части тега, с каждой строкой кэша связаны биты признаков действительности и модифицирован-
ности данных.
Такой кэш имеет самую простую аппаратную реализацию и применяется во вторичном кэше большинства системных плат. Однако ему присущ серь-
езный недостаток, вполне очевидный при рассмотрении рис. 91. Если в про-
цессе выполнения программы процессору поочередно будут требоваться блоки памяти, смещенные относительно друг друга на величину, кратную размеру страницы (на рис. эти блоки расположены на одной горизонтали в разных страницах), то кэш будет «буксовать» – работать интенсивно, но вхо-
лостую.
Очередное обращение будет замещать данные, считанные в предыдущем и необходимые в последующем обращении, т. е. будет иметь место сплошная череда кэш-промахов. Переключение страниц в многозадачных операцион-
ных системах также снижает количество кэш-попаданий, что отражается на производительности системы. Увеличение размера кэша при сохранении ар-
хитектуры прямого отображения даст не очень существенный эффект, по-
скольку разные задачи будут претендовать на одни и те же строки кэша.
Объем кэшируемой памяти (Mcached) при архитектуре прямого отображения определяется объемом кэш-памяти (Vcache) и разрядностью памяти тегов
(N):
230