

Информатика_140800 / 2011-2012-учебный год / 1_семестр / Сам_изуч / Кодовые_таблицы_символов_ЭВМ_Лекция3
.docМатериал для самостоятельного изучения по теме Лекции 2
Кодировка ASCII
Кодировочная таблица ASCII (ASCII - American Standard Code for Information Interchange - Американский стандартный код для обмена информацией).
Всего с помощью таблицы кодирования ASCII (рисунок 1) можно закодировать 256 различных символов. Эта таблица разделена на две части: основную (с кодами от OOh до 7Fh) и дополнительную (от 80h до FFh, где буква h обозначает принадлежность кода к шестнадцатеричной системе счисления).

Рисунок 1
Для кодировки одного символа из таблицы отводится 8 бит (1 байт). При обработке текстовой информации один байт может содержать код некоторого символа - буквы, цифры, знака пунктуации, знака действия и т.д. Каждому символу соответствует свой код в виде целого числа. При этом все коды собираются в специальные таблицы, называемые кодировочными. С их помощью производится преобразование кода символа в его видимое представление на экране монитора. В результате любой текст в памяти компьютера представляется как последовательность байтов с кодами символов.
Например, слово hello! будет закодировано следующим образом (таблица 1).
Таблица 1
|
Символ |
h |
e |
I |
I |
o |
! |
|
Код двоичный |
01001000 |
01100101 |
01101100 |
01101100 |
01101111 |
00100001 |
|
Код десятичный |
72 |
101 |
108 |
108 |
111 |
33 |
На рисунке 1 представлены символы, входящие в стандартную (английскую) и расширенную (русскую) кодировку ASCII.
Первая половина таблицы ASCII стандартизована. Она содержит управляющие коды (от 00h до 20h и 77h). Эти коды из таблицы изъяты, так как они не относятся к текстовым элементам. Здесь же размещаются знаки пунктуации и математические знаки: 2lh - !, 26h - &, 28h - (, 2Bh -+,..., большие и малые латинские буквы: 41h - A, 61h – а.
Вторая половина таблицы содержит национальные шрифты, символы псевдографики, из которых могут быть построены таблицы, специальные математические знаки. Нижнюю часть таблицы кодировок можно заменять, используя соответствующие драйверы - управляющие вспомогательные программы. Этот прием позволяет применять несколько шрифтов и их гарнитур.
Дисплей по каждому коду символа должен вывести на экран изображение символа – не просто цифровой код, а соответствующую ему картинку, так как каждый символ имеет свою форму. Описание формы каждого символа хранится в специальной памяти дисплея - знакогенераторе. Высвечивание символа на экране дисплея IBМ PC, например, осуществляется с помощью точек, образующих символьную матрицу. Каждый пиксел в такой матрице является элементом изображения и может быть ярким или темным. Темная точка кодируется цифрой 0, светлая (яркая)- 1. Если изображать в матричном поле знака темные пикселы точкой, а светлые - звездочкой, то можно графически изобразить форму символа.
Люди в разных странах используют символы для записи слов их родных зыков. В наши дни большинство приложений, включая системы электронной почты и вэб-браузеры, являются чисто 8-битными, то есть они могут показывать и корректно воспринимать лишь 8-битные символы, согласно стандарту ISO-8859-1.
Существует более 256 символов в мире (если учесть кириллицу, арабский, китайский, японский, корейский и тайский языки), а также появляются все новые и новые символы. И это создает следующие пробелы для многих пользователей:
Невозможно использовать символы различных наборов кодировок в одном и том же документе. Так как каждый текстовый документ использует свой собственный набор кодировок, то возникают большие трудности с автоматическим распознаванием текста.
Появляются новые символы (например: Евро), вследствие чего ISO разрабатывает новый стандарт ISO-8859-15, который весьма схож со стандартом ISO-8859-1. Разница состоит в следующем: из таблицы кодировки старого стандарта ISO-8859-1 были убраны символы обозначения старых валют, которые не используются в настоящее время, для того, чтобы освободить место под вновь появившиеся символы (такие, как Евро). В результате у пользователей на дисках могут лежать одни и те же документы, но в разных кодировках. Решением этих проблем является принятие единого международного набора кодировок, который называется универсальным кодированием или Unicode.
Кодировка Unicode
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.). Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становится ненужным переключение кодовых страниц.
Стандарт состоит из двух основных разделов: универсальный набор символов (англ. UCS, universal character set) и семейство кодировок (англ. UTF, Unicode transformation format). Универсальный набор символов задаёт однозначное соответствие символов кодам — элементам кодового пространства, представляющим неотрицательные целые числа. Семейство кодировок определяет машинное представление последовательности кодов UCS.
Стандарт Unicode был разработан с целью создания единой кодировки символов всех современных и многих древних письменных языков. Каждый символ в этом стандарте кодируется 16 битами, что позволяет ему охватить несравненно большее количество символов, чем принятые ранее 8-битовые кодировки. Еще одним важным отличием Unicode от других систем кодировки является то, что он не только приписывает каждому символу уникальный код, но и определяет различные характеристики этого символа, например:
-
тип символа (прописная буква, строчная буква, цифра, знак препинания и т.д.);
-
атрибуты символа (отображение слева направо или справа налево, пробел, разрыв строки и т.д.);
-
соответствующая прописная или строчная буква (для строчных и прописных букв соответственно);
-
соответствующее числовое значение (для цифровых символов).
Весь диапазон кодов от 0 до FFFF разбит на несколько стандартных подмножеств, каждое из которых соответствует либо алфавиту какого-то языка, либо группе специальных символов, сходных по своим функциям. На приведенной ниже схеме содержится общий перечень подмножеств Unicode 3.0 (рисунок 2).
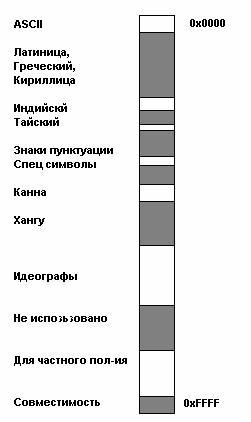
Рисунок 2
Стандарт Unicode является основой для хранения и текста во многих современных компьютерных системах. Однако, он не совместим с большинством Интернет-протоколов, поскольку его коды могут содержать любые байтовые значения, а протоколы обычно используют байты 00 - 1F и FE - FF в качестве служебных. Для достижения совместимости были разработаны несколько форматов преобразования Unicode (UTFs, Unicode Transformation Formats), из которых на сегодня наиболее распространенным является UTF-8. Этот формат определяет следующие правила преобразования каждого кода Unicode в набор байтов (от одного до трех), пригодных для транспортировки Интернет-протоколами.
|
Диапазон Unicode |
Двоичный код символа |
Байты UTF-8 (двоичные) |
|
0000 - 007F |
00000000 0zzzzzzz |
0zzzzzzzz |
|
0080 - 07FF |
00000yyy yyzzzzzz |
110yyyyy 10zzzzzz |
|
0800 - FFFF |
xxxxyyyy yyzzzzzz |
1110xxxx 10yyyyyy 10zzzzzz |
Здесь x,y,z обозначают биты исходного кода, которые должны извлекаться, начиная с младшего, и заноситься в байты результата справа налево, пока не будут заполнены все указанные позиции.
Дальнейшее развитие стандарта Unicode связано с добавлением новых языковых плоскостей, т.е. символов в диапазонах 10000 - 1FFFF, 20000 - 2FFFF и т.д., куда предполагается включать кодировку для письменностей мертвых языков, не попавших в таблицу, приведенную выше. Для кодирования этих дополнительных символов был разработан новый формат UTF-16.
Таким образом, существует 4 основных способа кодировки байтами в формате Unicode:
UTF-8: 128 символов кодируются одним байтом (формат ASCII), 1920 символов кодируются 2-мя байтами ((Roman, Greek, Cyrillic, Coptic, Armenian, Hebrew, Arabic символы), 63488 символов кодируются 3-мя байтами (Китайский, японский и др.) Оставшиеся 2 147 418 112 символы (еще не использованы) могут быть закодированы 4, 5 или 6-ю байтами.
UCS-2: Каждый символ представлен 2-мя байтами. Данная кодировка включает лишь первые 65 535 символов из формата Unicode.
UTF-16:Является расширением UCS-2, включает 1 114 112 символов формата Unicode. Первые 65 535 символов представлены 2-мя байтами, остальные - 4-мя байтами.
USC-4: Каждый символ кодируется 4-мя байтами.