

Иерархическая кластеризация
В иерархических методах кластеризации каждый элемент исследования образовывает сначала свой отдельный кластер. На первом шаге два самых близкорасположенных кластера, содержащих пока по одному элементу, объединяются в один кластер. Далее процесс слияния кластеров продолжается до тех пор, пока не получится один кластер. Каждый факт слияния характеризуется некоторым значением расстояния, при котором оно произошло. Если установлено правило Nearest neighbor (ближайший сосед; простая кластеризация), то будут получаться кластеры в виде цепочек. Правило Furthest neighbor (самый дальний сосед; полная кластеризация) дает компактные кластеры, а правило Between groups linkage (межгрупповая связь; кластеризация по среднему расстоянию) занимает промежуточное положение между первыми двумя. Правда, следует отметить, что, как и всегда, когда вычисления основаны на большом числе данных, результаты, полученные с помощью последнего правила, менее чувствительны к случайным ошибкам при сборе данных.
Для получения кластеров из точек, изображенных на рис.5, выполните следующие действия.
Откройте файл Internet.sav.
Выберите Analyze Classify Hierarchical cluster… (АнализироватьКлассифицироватьИерархический кластерный [анализ]).
В появившемся окне выберите переменные PriceиNawed(см. табл. П.5) и выберите их для анализа, нажав кнопку со стрелкой. Выбранные переменные должны попасть в окно, расположенное правее и имеющее названиеVariable(s) (переменные).
Текстовую переменную Companyаналогичным образом переместите в полеLabel cases by:(пометить наблюдения как).
Проверьте установку основных режимов расчета.
В рамке Clusterс помощью радиокнопок можно выбрать, что группировать: наблюдения (кнопкаCases) или переменные (кнопкаVariables).В рамкеDisplay(отображать) можно снять флажокStatistics(статистики),чтобы не перегружать окно результатов, если от анализа потребуется только график. Если же не требуется вывод графиков, то снимается флажокPlots.
Задайте вывод статистик. Щелчком по кнопке Statistics...откройте диалоговое окноHierarchical Cluster Analysis: Statistics(Иерархический кластерный анализ: Статистики) и установите флажокAgglomeration schedule(последовательность слияния).
Задайте режимы вывода графической информации. Для этого щёлкните по кнопке Plots...(Диаграммы). Установите флажокDendrogram(древовидная диаграмма) и посредством радиокнопкиNone(Нет) в рамкеIcicle(сосулькообразная16[диаграмма]) отмените вывод диаграммы кластеризации.
Вызовите окно задания метода кластеризации, нажав кнопку Method…В полеCluster method (метод кластеризации) выберитеBetween groups linkage(связь между группами), в рамкеMeasure (мера [расстояния]) около выделенной радиокнопкиInterval (интервальная [шкала])17выберитеSquared Euclidian distance(квадрат евклидова расстояния)18.
Для использования стандартизации переменных в рамке Transform Values(преобразовывать переменные) выберите в полеStandartize(стандартизировать) значениеZ-scores(z-шкалы) и установите радиокнопкуBy variable(по переменной): в данном случае требуется нормализировать положение элементов исследования на осях координат.
Выполните анализ. Вернувшись в главное диалоговое окно, начните расчёт нажатием кнопки ОК. Найдите в окне результатов
Agglomeration schedule (ход объединения) рис. 6;
Dendrogram (дендрограмма) рис.7.
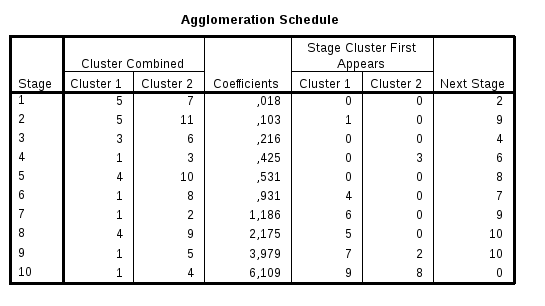
Рис. 6.Таблица хода объединения
Для определения, выбираемого количества кластеров решающее значение имеет показатель, выводимый под заголовком Coefficient(коэффициент).

Рис. 7. Дендрограмма кластеризации
В примере это квадрат евклидового расстояния между объединяемыми на каждом шаге кластерами, определенный с использованием стандартизованных значений.
Если оказывается, что на каком-либо шаге коэффициент увеличивается скачкообразно, кластеризацию обычно прекращают, так как далее происходит объединение элементов, находящихся на относительно большом расстоянии друг от друга.
Изменение коэффициента по шагам кластеризации отображено на рис. 8. Такой график можно построить с помощью Excel, скопировав в нее столбец значений коэффициента.
Видно, что резкого скачка не происходит. Однако можно условно считать, что девятый шаг уже заметно увеличивает коэффициент, поэтому он и является «лишним»: кластеризацию следует остановить на шаге 8. Количество кластеров, которые получаются в данном случае, равно числу элементов исследования (исследовалось11организаций, которые и объединялись в кластеры) минус номер последнего шага (8). Таким образом, рекомендованное число кластеров равно3, что совпадает с исходным визуальным наблюдением.
Дендрограмма (рис.7) визуализирует процесс слияния, приведенный в обзорной таблице хода кластеризации. Для каждого шага кластеризации она показывает объединённые кластеры и значения коэффициентов, приведенные к шкале от 0 до 25.
Некоторые типы дендрограмм и соответствующие им расположения точек элементов исследования изображены на рис.9.
Рис. 9, а отражает ситуацию, когда элемент 1близок к элементу3,о чем говорит близость соединяющей их линии к левому краю дендрограммы. Расстояние между элементами2и4также мало, но они расположены чуть дальше друг от друга: линия, соединяющая их, расположена правее. Элемент5довольно близок к элементам2и4(линия, связывающая кластер2—4и элемент5расположена довольно низко). Наконец, пара элементов1и3далеко отстоит от всех остальных (линия, связывающая кластер1—3и кластер2—4—5расположена справа). Таким образом, в качестве основы для сегментирования элементов можно взять пару1—3, а также тройку2—4—5.

Рис. 8. Зависимость величины коэффициента от шага кластеризации
Рис. 9, б аналогичен, но элемент 5дальше от расположенных близко друг к другу элементов2и4. Поэтому вопрос о том, включать ли элемент5в кластер2—4, или выделять его в отдельный кластер, требует дополнительного исследования другими методами. Но все же большую часть работы кластерный анализ сделал: другие элементы нашли свои места.
Рис. 9, в показывает ситуацию, когда элементы 1и3расположены рядом, элемент2близок к элементу4, но элемент5расположен далеко от всех других. Таким образом, видны три кластера.
Наконец, рис. 9, г не показывает наличия компактных групп: элементы 1и3близки, чуть дальше от них расположен элемент2, еще чуть дальше от всех рассмотренных элементов находится элемент4. Наконец, элемент5стоит особняком от всех других. В этом случае количество кластеров может определяться такими соображениями как количество сегментов, с которыми может работать организация. Если их, например, три, то выбирается такой уровень на дендрограмме, на котором имеются3ветви (показан пунктиром). Тогда первый кластер будет представлен элементами1, 2и3, второй –4, третий –5.
Найдите на дендрограмме рис. 7 три кластера, которые были видны на рис. 5.

Рис. 9. Основные виды дендрограмм