

Кодирование
Кодирование – категоризация данных и представление их в условном виде (обычно – числовом). Это принципиально неавтоматизируемая процедура.
Иногда ответ бывает единственным (возраст), иногда ответов может быть несколько (причины покупки, любимые телепередачи). Кодирование может производиться как самим респондентом (например, путем выбора одного из предложенных ответов), так и интервьюером.
Наиболее сложно кодировать ответы на открытые вопросы. Чаще всего, ответы некоторым образом группируются по смыслу. Например, 1– отрицательные (негативные),2– нейтральные,3– положительные (позитивные),9– отсутствие ответа. Главное здесь – добиться единообразия в кодировании. Лучше, если ответы на один открытый вопрос по всем анкетам кодирует один человек. Если такое кодирование невозможно произвести в одиночку из-за того, что анкет слишком много, каждому кодировщику дается выборка ответов, обработанных коллегой, чтобы проверить единообразие их работы. Например, если общее число анкет равно1000, и ответы на один вопрос обрабатываются двумя исследователями, то каждый обрабатывает по600анкет. По двумстам ответам, обработанным обоими исследователями, производится сверка единообразия их работы.
При обработке собранных данных удобно пронумеровать заполненные анкеты. Обычно каждой анкете будет впоследствии отведена одна запись базы данных.
Кодирование можно производить буквами или цифрами. Возраст лучше оставлять в годах. Обязательно составление ключа – списка использованных кодов121.
Итак, в процессе кодирования технико-экономической информации решаются две задачи:
кодируемому объекту присваивается уникальное обозначение;
дается информация о свойствах объекта.
Существует множество методов кодирования [16]. Описание основных методов приведено в [20].
Регистрационный методнаиболее прост. Каждый элемент исходного кодируемого множества обозначается с помощью кода – текущего номера. Символы, использованные для образования текущего номера, образуют алфавит кода. Число различных символов в алфавите называют основанием кода. Например, при кодировании с помощью десятичных цифр основание кода равно10, так как используется10различных цифр.
Недостаток данного метода кодирования – отсутствие дополнительной информации об элементе исследования. Трудно также проводить поиск закодированной информации в базе данных. Поэтому метод применяют для кодирования небольших объемов информации.
Типичный пример использования данного метода – нумерация анкет.
Классификацияявляется не только удобной основой кодирования. Использование классификации позволяет сгруппировать элементы исследования, что облегчает поиск закономерностей, выявление причинно-следственных связей.
Классификация – разбиение элементов исследования на группы по значеням определенных признаков.
Каждому признаку соответствует свой уровень разделения всего множества элементов исследования на группы. Далее процесс повторяется для полученных групп, уже по другому признаку.
Глубина классификации – общее число уровней классификации.
Если каждый последующий признак зависит от предыдущего, то последовательность их использования на уровнях классификации должна быть строго определена. В этом случае каждый последующий признак обеспечивает дальнейшую конкретизацию объекта. Такие признаки называются соподчиненными,а классификация на их основе –иерархической.
Пример. Все живое на Земле разделяется на растительный и животный мир. Дальнейшая классификация идет по признакам, различным для растений и животных.
Несоподчиненныепризнаки могут быть расположены по уровню классификации произвольно, так как они характеризуют объекты с разных, не зависимых друг от друга, сторон. Соответствующая классификация получила названиефасетной.
Пример. Легковые автомобили можно классифицировать по типу кузова, типу двигателя и его мощности.
Последовательное кодированиеосновывается на иерархической классификации, использующей соподчиненные признаки122. Достоинства получаемого кода – малая значность и большая информационная емкость. Недостатком является его «жесткость», так как последовательность кодируемых признаков строго фиксирована и изменение кода на любом уровне приводит к необходимости его изменения на всех других уровнях. Это вызывает определенные сложности при введении новых признаков.
При параллельном кодированиииспользуется фасетная классификация, согласно которой заданное множество объектов делится на независимые друг от друга группировки (фасеты).
Пример. Сведения о поступивших в университет студентах можно заносить в базу данных в виде следующего кода.
1.01.7403.2.1.080011.
где (по порядку слева направо) 1.– пол (мужской); .01.– национальность (русский); .9403.– дата рождения (1994 год, март); .2.– семейное положение (холостой/не замужем); .1.– образование (среднее); .080011– специальность (маркетинг).
Такое кодирование, хотя и дает несколько более длинные коды, обеспечивает достаточную гибкость123.
На практике чаще всего применяют комбинации различных методов классификации и кодирования.
Рассмотренные методы кодирования представлены на рис.Рис. 16.
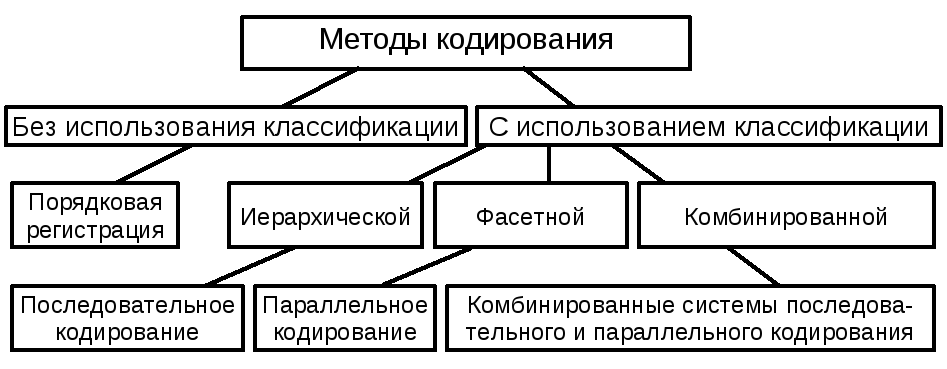
Рис. 16. Классификация методов кодирования
Закодированные ответы респондентов, снабженные ключом и сохраняемые обычно в базе данных, являются «золотым фондом», полученным при исследованиях.
Сводные таблицы и графики, конечно, более наглядны, но в них могут вкрасться ошибки, от чисто арифметических до нечеткого понимания взамиосвязи измеренных параметров. Из базы данных ответов можно получить информацию для проверки правильности итоговых сведений, а также для проведения дополнительного, более глубокого анализа.