


Regular Expressions in StarOffice/OpenOffice.org Writer
How It Works
The initial character class, [0-9], matches the same characters as the character class [0123456789]. The dash in [0-9] represents a range, so [0-9] represents the range of numeric digits from 0 to 9 inclusive. Because OpenOffice.org Writer does not support the \d metacharacter, which in most regular expression implementations matches numeric digits, the use of a character class to match numeric digits is needed.
The character class [A-Z], similarly, matches the same characters as the character class as the pattern [ABCDEFGHIJKLMNOPQRSTUVWXYZ] but is much more succinct. Because the Match Case check box is checked (see Step 3), only uppercase alphabetic characters are matched.
The character class [a-z] matches the same characters as the character class [abcdefghijklmnopqrs tuvwxyz]. With the Match Case check box checked, only lowercase alphabetic characters are matched.
When the Match Case check box is unchecked in Step 10, the pattern [a-z] matches all alphabetic characters, both lowercase and uppercase.
Alternation
OpenOffice.org Writer supports the | character (often called the pipe character), which conveys the notion of alternation or the logical OR.
A test document, Licenses.txt, is shown here:
This licence has expired.
Friday is the day that the licensing authority meets.
Licences are essential before you can do that legally.
License is morally questionable.
Licensed practitioners only should apply.
The aim is to match any occurrence of licence, license, or licensing while allowing for the possibility (not occurring in the test document) that the form licencing might also be used.
The problem definition can broadly be expressed as follows:
Match any occurrence of the word licence or licensing, allowing for possible variations in how each word is spelled.
Refining that initial attempt at a problem definition would give something like the following:
Match, case insensitively, the literal character sequence l, i, c, e, n followed by either c or s, in turn followed by e or the character sequence i, n, and g.
A pattern that would, when applied case insensitively, satisfy the problem definition follows:
licen(c|s)(e|ing)
So let’s try it out.
289
Chapter 12
Try It Out |
Alternation |
1.Open OpenOffice.org Writer, and open the test file Licenses.txt.
2.Check the Regular Expressions check box. Because the aim is case-insensitive matching, ensure that the Match Case check box is unchecked.
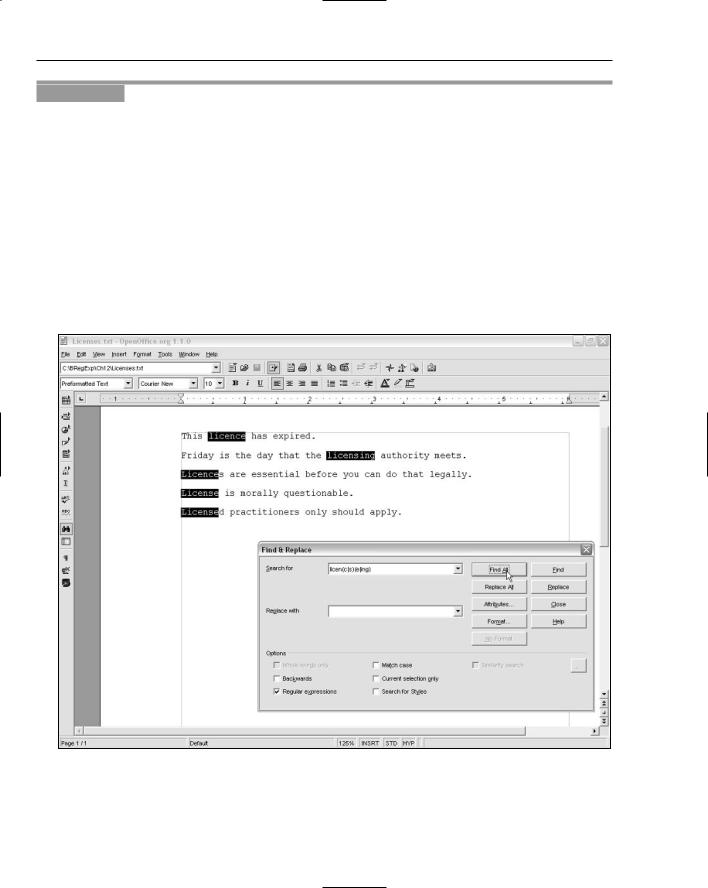
3.In the Search For text box, enter the pattern licen(c|s)(e|ing).
4.Click the Find All button, and inspect the highlighted text. Figure 12-7 shows the appearance after Step 4.
You can see that the d or s at the end of Licensed and Licenses, respectively, are not matched. If the desire is to match the whole word, the pattern can be modified to achieve that. When the character sequences licens or licenc are followed by an e, you want to allow an optional choice of d or s. So licence, license, licenced, licensed, licences, and licenses would all be matched. However, when the match is licensing or licencing, you don’t want to allow an s or a d as the following character.
Figure 12-7
290
Regular Expressions in StarOffice/OpenOffice.org Writer
The problem definition would be modified like this:
Match, case insensitively, the literal character sequence l, i, c, e, n followed by either c or s, in turn followed by either e followed by a choice of d or s, each of which is optional, or the character sequence i, n, and g.
So the pattern is modified to licen(c|s)(e(s|d)?|ing) to express the preceding problem definition.
As you can see from the preceding problem definition and pattern, it can become difficult to clearly express nested options.
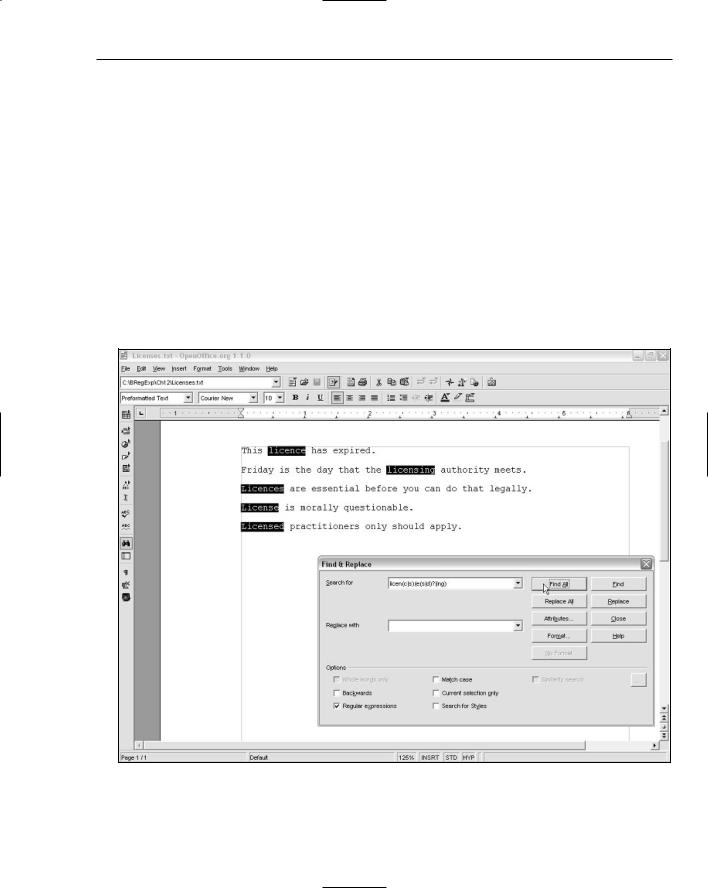
5.Edit the pattern in the Search For text box to licen(c|s)(e(s|d)?|ing).
6.Click the Find All button, and inspect the results Figure 12-8 shows the appearance after this step.
How It Works
Let’s look at how the pattern licen(c|s)(e(s|d)?|ing) matches in each of the lines of the test text.
Figure 12-8
291
Chapter 12
In the first line, the relevant text that matches is licence. When the regular expression engine reaches the position immediately before the initial l of licence, the first five characters of the word match the first five literal characters of the pattern. Then the second c of licence matches the first option in (c|s). And the final e of licence matches the first option in (e(s|d)?|ing) — in other words, e(s|d)?, which is an e followed optionally by an s or a d.
In the second line, the relevant text that matches is licensing. When the regular expression engine reaches the position immediately before the initial l of licensing, the first five characters of the word match the first five literal characters of the pattern. Then the s of licensing matches the second option in (c|s). Then the final character sequence ing matches the second option in (e(s|d)?|ing), which is the sequence of literal characters ing.
In the third line, the relevant text that matches is Licences. Remember that the matching is being carried out case insensitively, so the initial licen of the pattern matches the initial character sequence Licen. The second c in Licences matches the first option in (c|s). The final es matches the first of the two options in (e(s|d)?|ing). In other words, it matches a literal e followed by zero or one s.
The matching in the fourth line is the same, except that there is no final s to be matched. Because the (s|d)? means that the s or d is optional, there is a match.
In the fifth line, the relevant text that matches is Licenced. The matching is being carried out case insensitively, so the initial licen of the pattern matches the initial character sequence Licen. The second c in Licenced matches the first option in (c|s). The final ed matches the first of the two options in (e(s|d)?|ing). In other words, it matches a literal e followed by zero or one d. So in this line, e(s|d)? matches the character sequence ed.
Back References
OpenOffice.org Writer doesn’t support back references in a standard way, but the & metacharacter provides a limited back-reference-like functionality, which can be used in search and replace.
Suppose that you want to modify all occurrences of words such as walk and sulk with walking, sulking, and so on. You can match on the literal character sequence lk and then add ing to each such matched character sequence. The & metacharacter allows you to do that.
The test file, Walk.txt, is shown here:
Walk
talk
sulk
milk
292
Regular Expressions in StarOffice/OpenOffice.org Writer
Try It Out |
The & Metacharacter |
1.Open OpenOffice.org Writer, and open the test file Walk.txt.
2.Use the Ctrl+F keyboard shortcut to open the Find & Replace dialog box.
3.Check the Regular Expressions check box. Leave the Match Case check box unchecked.
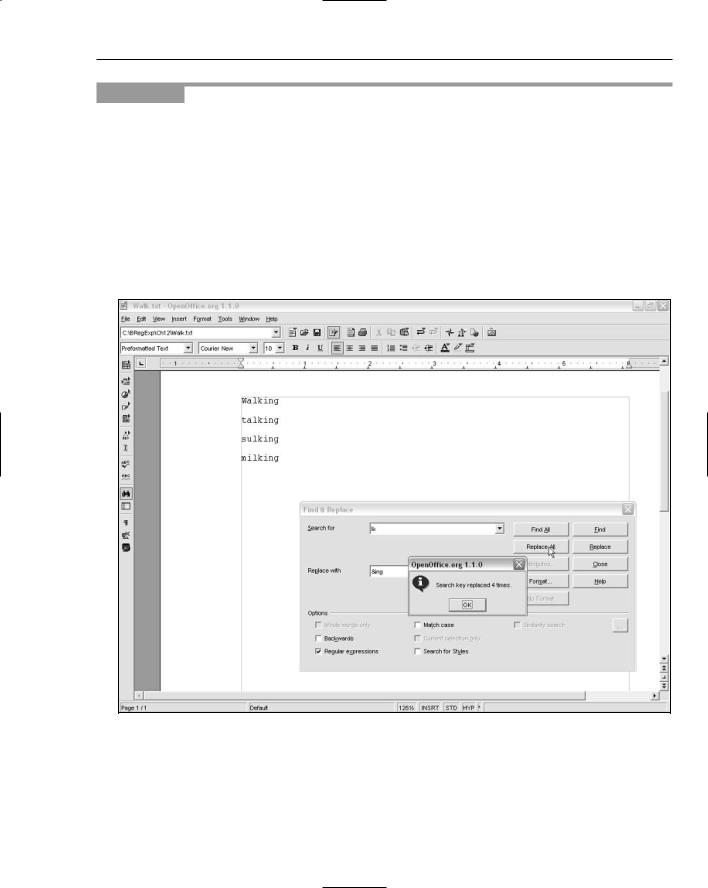
4.Enter the literal pattern lk in the Search For text box.
5.In the Replace With text box, enter the pattern &lk.
6.Click the Replace All button, and inspect the result.
Figure 12-9 shows the appearance after Step 6. As you can see, each word that has the character sequence lk in it has had the character sequence ing added to it.
Figure 12-9
293