

Chapter 7
So if you had data that included the form:
Temperature:22.2
and you wanted to capture the temperature in a variable named MeanTemp, you could use the following pattern, assuming that temperature is in the range 10 to 99 degrees and is recorded to one decimal place:
Temperature:(?<MeanTemp>\d{2}\.\d
Non-Capturing Parentheses
Some regular expression implementations provide support for non-capturing parentheses.
Another term for non-capturing parentheses is grouping-only parentheses.
Suppose that you want to capture two sequences of characters, the first sequence of interest being a form of Doctor and the second being the doctor’s surname. Assume that the data is structured as follows:
Doctor Firstname LastName
Dr FirstName LastName
Dr. FirstName LastName
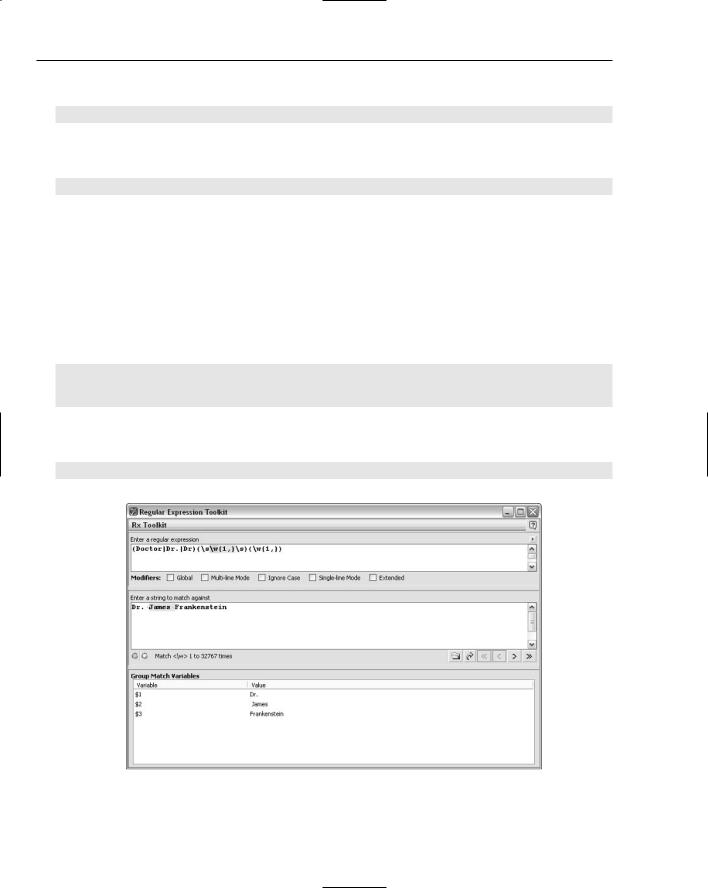
You can use the following pattern to capture the form of Doctor or one of its abbreviations and have the form of address as $1 and the surname as $2, as you can see in Figure 7-11:
(Doctor|Dr.|Dr)(\s\w{1,}\s)(\w{1,})
Figure 7-11
188
Parentheses in Regular Expressions
The pattern (Doctor|Dr.|Dr) has created the group $1 and has captured the form of Doctor or its abbreviation. The pattern (\s\w{1,}\s) has created the group $2 and has captured a space character, the doctor’s first name, and another space character. The pattern (\w{1,}) creates the group $3 and has captured the doctor’s surname.
The pattern to create non-capturing parentheses is as follows:
(?:the-non-captured-content)
In other words, when an opening parenthesis is followed by a question mark, then followed by a colon character, the parentheses do not capture the content.
If you modify the pattern to:
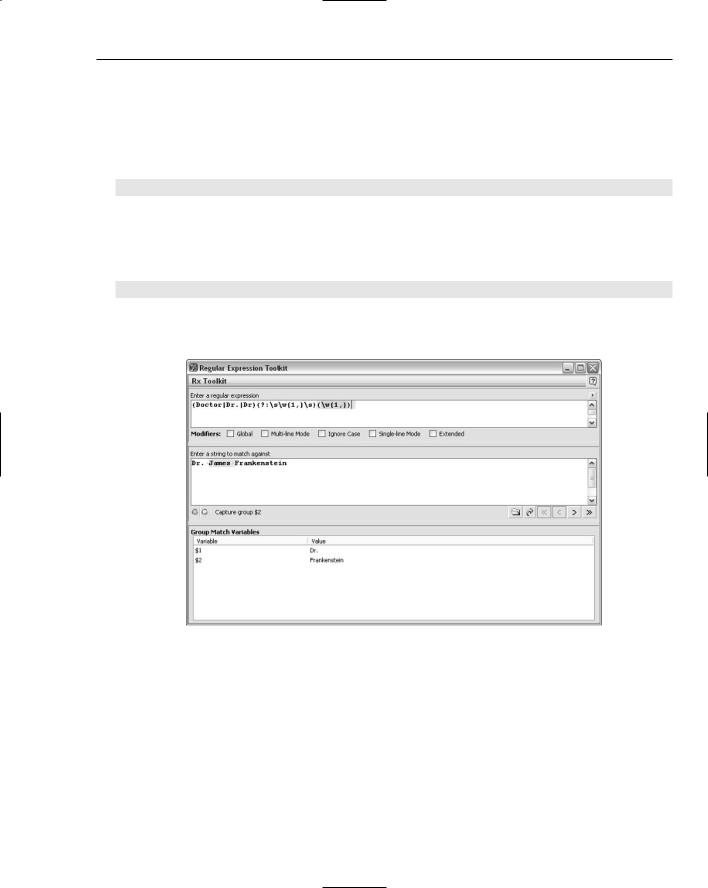
(Doctor|Dr.|Dr)(?:\s\w{1,}\s)(\w{1,})
$1 is the form of doctor and $2 is the surname, as you can see in Figure 7-12. The pattern (?:\s\w{1,}) does not capture a group containing the first name.
Figure 7-12
Non-capturing parentheses do make the pattern look more complex. But in complex situations, they can reduce the number of groups that you work with and can make programming a little easier.
In addition, when the regular expression engine has fewer groups to keep track of, there can be an efficiency gain.
189

Chapter 7
Back References
A common use of capturing parentheses is in back references, which is also sometimes written as one word, backreferences.
One situation where back references come in handy is where you have inadvertently doubled the the definite article in a sentence, as I have deliberately done in this sentence. In documents of significant length, it can be a fairly major task to pick up doubled words.
A sample document, DoubledWords.txt, is shown here:
Paris in the the spring.
The theoretical viewpoint is of little value here.
I view the theoretical viewpoint as being of little value here.
I think that that is often overdone.
This sentence contains contains a doubled word or two two.
Fear fear is a fearful thing.
Writing successful programs requires that the the programmer fully understands the problem to be solved.
Included in the sample document are sentences that have doubled words with the same case and with different case and examples where a sequence of characters has been doubled but legitimately so. In the fourth sentence is a doubled word that is entirely acceptable and was probably intended.
Try It Out Detecting Doubled Words
This exercise explores detecting repeated strings.
In OpenOffice.org Writer, the variable representing the first group captured is designated \1 rather than $1 as it was in the Komodo Regular Expression Toolkit.
The following regular expression pattern uses parentheses to capture sequences of alphabetic characters, defined by the character class [A-Za-z]:
([A-Za-z]+) +\1
After one or more matches for the character class, there follows a space character with the quantifier +, indicating that there must be one or more space characters between the content of the parentheses and what is to follow. The final part of the regular expression pattern is \1, which is a back reference to the contents of the first pair (in this example the only pair) of capturing parentheses.
190
Parentheses in Regular Expressions
1.Open DoubledWords.txt in OpenOffice.org Writer.
2.Open the Find & Replace dialog box, and check the Regular Expressions and Match Case check boxes.
3.Enter the pattern ([A-Za-z]+) +\1 in the Search For text box.
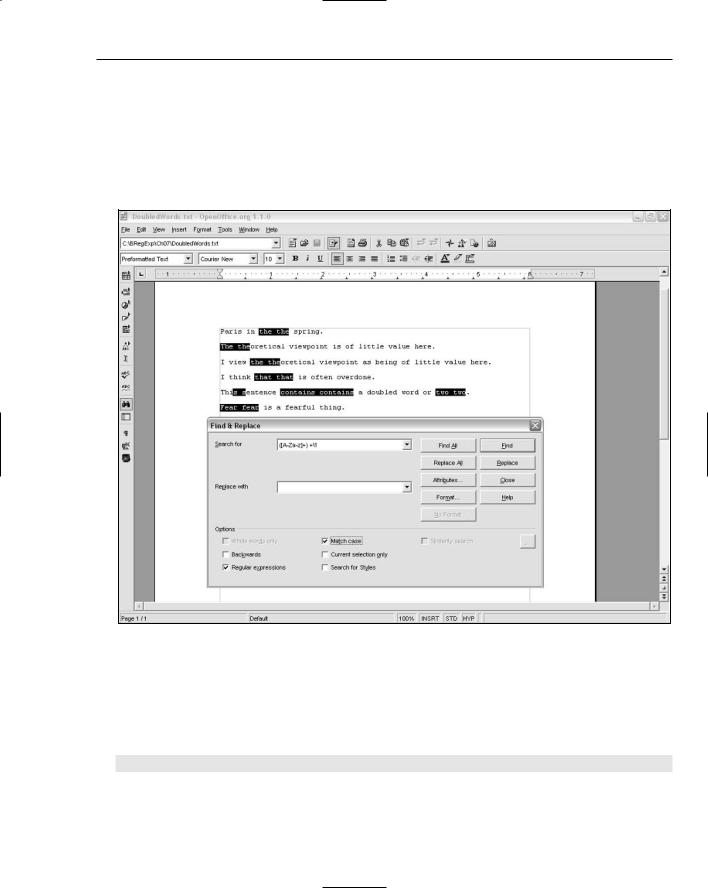
4.Click the Find All button, and inspect the results. Figure 7-13 shows the result of applying the regular expression pattern to DoubledWords.txt in OpenOffice.org Writer.
Figure 7-13
As you can see from the figure, you have some undesired matches in DoubledWords.txt, principally because the chosen regular expression pattern selects repeated character sequences rather than repeated words.
So you need to modify the pattern so that the beginning of the first word is made explicit and the end of the possibly repeated word is made explicit, too. The following pattern achieves this:
\<([A-Za-z]+) +\1\>
191
Chapter 7
5.Modify the pattern in the Search For text box to \<([A-Za-z]+) +\1\>.
6.Click the Find All button, and inspect the results. As you can see in Figure 7-14, the selection now focuses only on repeated words and ignores repeated sequences of characters that are not words.
Figure 7-14
How It Works
First, let’s look at what happens with the pattern ([A-Za-z]+) +\1.
The problem definition that corresponds to this pattern could be expressed as follows:
Match one or more ASCII alphabetic characters followed by one or more spaces. Then attempt to match the preceding sequences of ASCII alphabetic characters.
There is nothing that specifies that the sequence of alphabetic characters is a word. So you find that in Line 3 the sequence of characters the, which occurs in the word the, also occurs as the first three characters of the word theoretical. That is a match, but an undesired match.
192