


Parentheses in Regular Expressions
a match. Then the literal ) matches the pattern \). Next, the literal space character is matched against the sixth character of the test string, which is a space character. There is a match. Next, the pattern \d{3} is matched against the seventh, eighth, and ninth characters of the test string, 133. Because each of those characters is a numeric digit, there is a match. Next, a literal hyphen in the pattern is matched against a hyphen in the test string, which, of course, matches. Finally, the pattern \d{4} is matched against the final four characters of the test string, 4477. Because each of those is a numeric digit, there is a match. All components of the regular expression match; therefore, the whole regular expression matches.
There is no match for the test string 123-456-7890, because the first metacharacter in the regular expression, \(, has no match.
There is no match for the test string (898 123-1234. Assuming that the regular expression engine is at the position immediately before the opening parenthesis, the metacharacter \( is matched successfully, and the pattern \d{3} is matched by the sequence of characters 898. However, there is no match for the \) metacharacter; therefore, matching of the whole regular expression fails.
Alternation
One important and straightforward use of parentheses is in expressing alternatives. Making choices among alternatives involves using the parentheses metacharacters and the | metacharacter, sometimes called the bar metacharacter, which expresses the idea of the logical OR.
Strictly speaking, you can have no more than two alternatives. When there is a choice of three or more choices, those are options, not alternatives. However, the term alternation is well established in regular expression terminology for options of two or more, so the term alternative or alternation will be used in this section whether there are two options or more.
The simplest usage is to select either of two literal options. For example, you might have to deal with documents in U.S. and British English, where the color gray is spelled two different ways: gray in U.S. English and grey in British English.
The problem definition could be expressed as follows:
Match a lowercase g, followed by an r, followed by either an a OR an e, followed by a y.
You might wonder why I specify lowercase for the initial g. If, for example, your data contains the surnames Grey or Gray, or the name of a place beginning with either combination of four letters, you don’t want to replace the e in text such as Mr. Grey to achieve consistent U.S. spelling, because changing someone’s surname will likely have undesired effects.
You could express the problem definition as the following pattern:
(gray|grey)
Or as follows:
gr(a|e)y
177

Chapter 7
These have the same logical meaning. In fact, you could equally use a character class in the following pattern, if you wished. Using a character class rather than alternation typically will offer efficiency benefits:
gr[ae]y
Try It Out |
Choosing Two Literal Alternatives |
This example demonstrates how to choose between two alternatives expressed literally. Suppose that you want to make selections from a list of part numbers, as shown in the sample document,
PartNums.txt:
ABC03
ABC08
ABC11
ABC13
ABC18
ABC25
ABC45
ABC12
ABC19
ABC88
ABC71
ABC04
ABC02
ABC55
As you can see, the part numbers are not ordered. Suppose that you want to select part numbers between ABC01 and ABC19. One way to do that is to use parentheses in the following regular expression pattern:
ABC(0|1)[0-9]
1.Open OpenOffice.org Writer, and open the test file PartNums.txt.
2.Open the Find & Replace dialog box using the Ctrl+F keyboard shortcut.
3.Check the Regular Expressions and Match Case check boxes.
4.Enter the pattern ABC(0|1)[0-9] in the Search For text box.
5.Click the Find All button, and inspect the result. As you can see in Figure 7-4, all the part numbers in the sample document that lie between ABC01 and ABC19 (there are gaps in the data) are highlighted.
Part numbers with a first numeric digit that is neither 0 nor 1 are not matched.
178

Parentheses in Regular Expressions
Figure 7-4
How It Works
Matching of ABC03 in the first line is achieved as follows. Assuming that the regular expression engine is starting at the position before the initial A of ABC03, it first attempts to match the first character in the pattern, A, against the first character in the test text, A. There is a match. Matches also are achieved when attempting to match the second character, B, and the third character, C. Next, a match is sought for the pattern (0|1). This is tested against the fourth character of the test text, the numeric digit 0. There is a match. Finally, the character class [0-9] is matched against the numeric digit 3. There is a match. Because all components of the regular expression match, the whole regular expression matches.
The test text ABC11 matches. The first three characters match as described in the preceding paragraph. When the pattern (0|1) is matched against the numeric digit 1, there is a match. The character class [0-9] matches the numeric digit 1, the fifth character of the test text.
The test text ABC25 does not match, because the pattern (0|1) cannot successfully be matched against the numeric digit 2.
179

Chapter 7
Choosing among Multiple Options
Suppose that you have some text about people, including information about individuals who practice medicine. You want to find all references to individuals who are doctors.
You may find text that uses the term Doctor (or doctor) or that uses one or both of the abbreviations Dr. (with a period) and Dr (without a period). Whether or not you want to include the word doctor in your search depends on its purpose. Assume that you only want to find mention of doctors when the word has an uppercase initial D. The problem definition could be stated as follows:
Match the sequence of characters D, o, c, t, o, and r OR match the sequence of characters D and r OR match the sequence of characters D, r, and . (a period).
The following pattern will satisfy the requirements specified in the problem definition:
(Doctor|Dr|Dr\.)
Remember that the period in a pattern is a metacharacter that matches a wide range of alphanumeric characters. To restrict the match to the literal period character in the test text, you must escape the period character in the pattern \.. An alternative pattern to match the same options is as follows:
(Doctor|Dr\.?)
Try It Out |
Matching Multiple Options |
The test text, Doctors.txt, is shown here:
Doctor
Drf
Dr
Dr.
Drs
Doctors
1.Open OpenOffice.org Writer, and open the test file Doctors.txt.
2.Open the Find & Replace dialog box using the Ctrl+F keyboard shortcut.
3.Check the Regular Expressions and Match Case (choosing not to match the text doctor) check boxes.
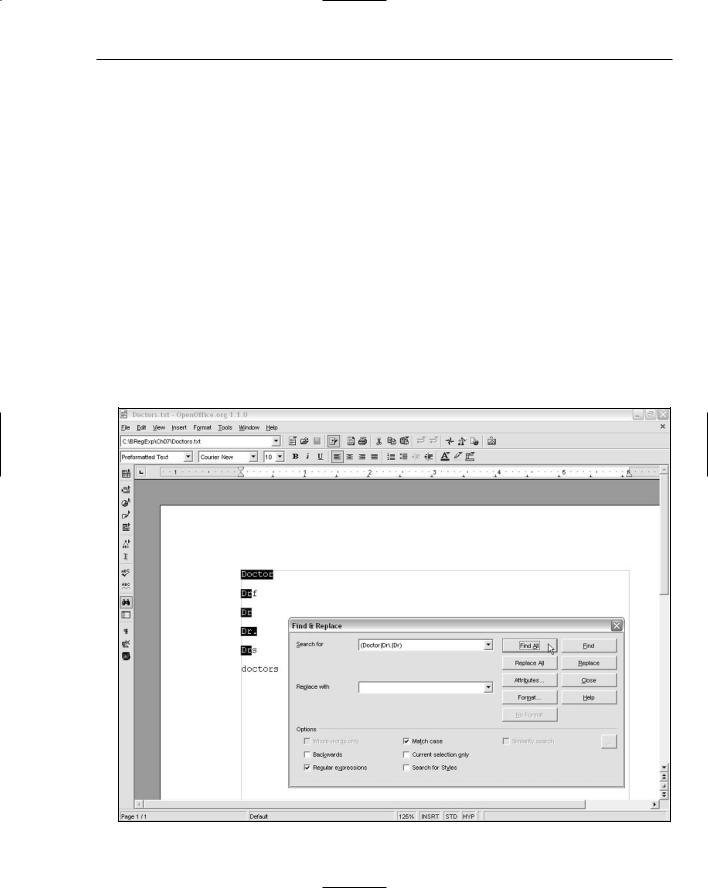
4.Enter the pattern (Doctor|Dr\.|Dr) in the Search For text box.
5.Click the Find All button, and inspect the results, as shown in Figure 7-5. Notice that only the Dr of Dr. is matched.
6.Add the test text Drive at the end of the test file, and click the Find All button.
180
Parentheses in Regular Expressions
7.Inspect the results. Notice that the Dr of Drf is matched, reflecting our earlier attempt at a problem definition, but as you can see, undesired text is matched. A revised and more specific problem definition is shown here:
Match the sequence of characters D, o, c, t, o, and r OR match the sequence of characters D and r OR match the sequence of characters D, r, and . (a period). Following the previously described options, there must be a word-boundary position.
However, there is a subtle trap in the preceding problem definition, because the period character is a nonword character. So a better problem definition is as follows:
Match the sequence of characters D, o, c, t, o, and r OR match the sequence of characters D and r. Following the previously described options, there must be a word-boundary position.
The problem definition could have been more precise and specified an end word boundary position. However, because it specified that the options that precede the word boundary are all alphabetic (word) characters, it can only be an end-of-word boundary.
8.Modify the pattern so that it reads (Doctor|Dr)\>.
9.Click the Find All button, and inspect the results. Notice that the initial Dr of Drive is no longer matched. Notice, too, that the whole of Dr. is now matched.
Figure 7-5
181