

Chapter 4
Figure 4-5
How It Works
The pattern \w indicates that an ASCII alphabetic character (upperor lowercase A through Z or a through z), a numeric digit, or an underscore is to be matched. The quantifier {3} indicates that three successive “word” characters are to be matched.
The regular expression engine starts its attempts at matching at the position before the T of This. It first attempts to match a word character. Because the uppercase T is an alphabetic character, there is a match. It next attempts to find another word character. Because the h of This is an alphabetic character that too matches. Finally, it attempts to match a third word character. Because the i of This is also an alphabetic character, there is a third match. Because all components of the pattern match, the whole pattern matches. The sequence of three word characters Thi is therefore highlighted in pale green.
The term word character used to refer to the characters matched by the \w metacharacter is potentially misleading, because for many people, numeric digits and the underscore character won’t be thought of as word characters.
The \W Metacharacter
The \W metacharacter matches characters that are not matched by the \w metacharacter. In other words, the \W metacharacter matches any character other than ASCII alphabetic characters, numeric digits, or the underscore character.
82
Metacharacters and Modifiers
Try It Out |
Matching Using the \W Metacharacter |
1.Open the Komodo Regular Expression Toolkit, and delete any residual regular expression pattern and test text.
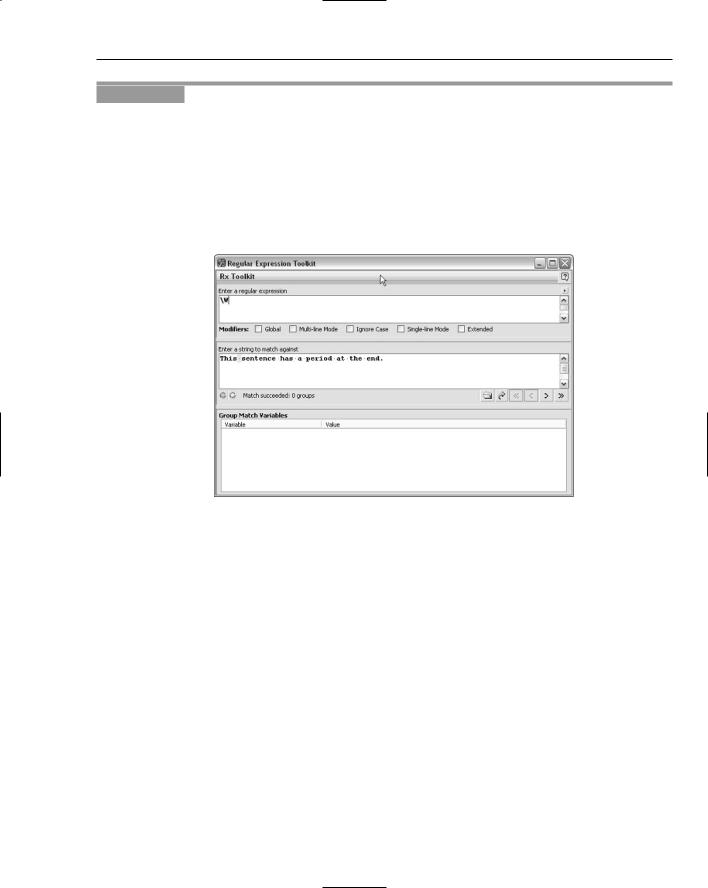
2.In the Enter a String to Match Against area, enter the text This sentence has a period at the end.
3.In the Enter a Regular Expression area, enter the pattern \W.
4.Inspect the results in the Enter a String to Match Against area and in the gray area below it. The expected result is that the space character after This and before sentence should be highlighted in pale green when viewed on-screen (see Figure 4-6).
Figure 4-6
How It Works
The regular expression engine starts at the position before the uppercase T of This. It first attempts to match the uppercase T of This against the pattern \W. There is no match. It attempts to match each of the remaining characters of This in turn, but none of them matches the \W pattern, because each of those characters are “word characters.” When the regular expression engine reaches the position after the final s of This, the match succeeds because the space character that follows is not a word character and therefore matches the \W metasequence. Therefore, the matching character (the space character that follows This and precedes sentence) is highlighted.
Digits and Nondigits
Many regular expression implementations have characters that signify numeric digits or characters other than numeric digits.
The metacharacter \d is widely used to signify numeric digits. The metacharacter \D is used to signify nondigits in implementations that support the \d metacharacter.
83
Chapter 4
OpenOffice.org Writer does not support the \d and \D metacharacters and so can’t be used to demonstrate these features.
The \d Metacharacter
The \d metacharacter matches one numeric digit 0 through 9.
A sample file, Digits.txt, is shown here:
D1
AB8
DE9
7ED
6py
0EC
E3
D2
F4
GHI5
ABC89
Try It Out Matching against the \d Metacharacter
1.Open the Komodo Regular Expressions Toolkit, and clear any residual regular expression and test text.
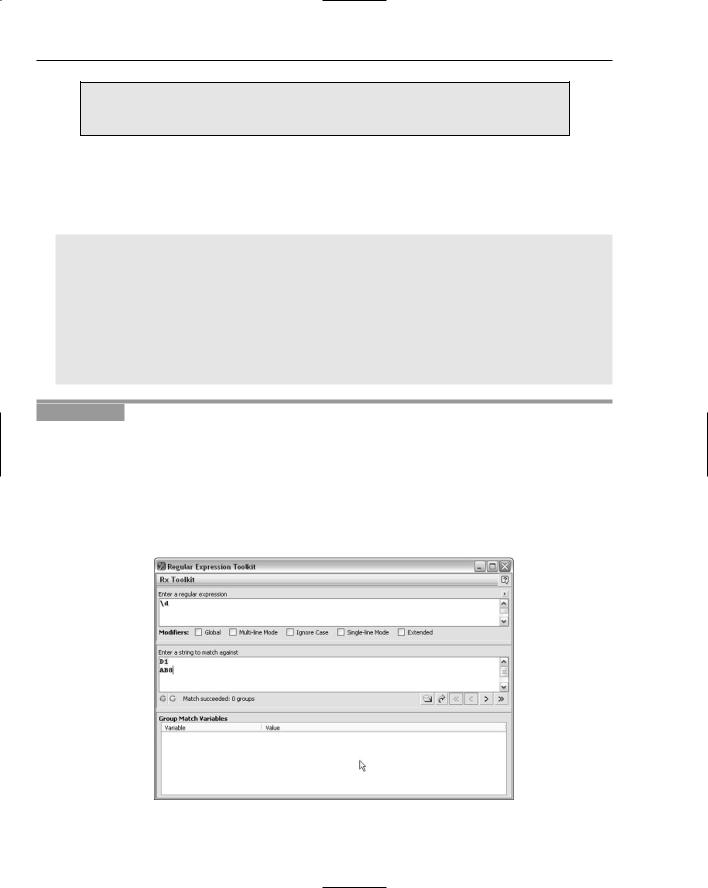
2.In the Enter a String to Match Against area, enter the first two lines from Digits.txt.
3.In the Enter a Regular Expression area, type the pattern \d.
4.Inspect the results in the Enter a String to Match Against area and in the gray area below it. Figure 4-7 shows the appearance expected after this step.
Figure 4-7
84

Metacharacters and Modifiers
How It Works
The \d metacharacter matches a numeric digit. The regular expression engine starts matching at the position before the D of D1. The first character, D, is not a numeric digit, and therefore, there is no match. The regular expression engine moves on to the position after the D and attempts to match the character that follows that position. Because the next character is the numeric digit 1, there is a match.
Canadian Postal Code Example
Canadian postcodes take the form A1A 1A1, with an alphabetic character preceding a numeric digit, which in turn is followed by an alphabetic character. That in turn is followed by a space character (usually one), which is followed by one numeric digit, followed by one alphabetic character, followed by a numeric digit.
To match a Canadian postal code, you can use the following problem definition:
Match an ASCII alphabetic character, followed by a numeric digit, followed by an ASCII alphabetic character, followed by an optional space character, followed by a numeric digit, followed by an ASCII alphabetic character, followed by a numeric digit.
The sample file CanPostcodes.txt has sample sequences of characters, some of which take the format just described, which are consistent with the structure of Canadian postal codes (although the examples in the file are simply character sequences). Not all alphabetic characters are currently used in the first position in a Canadian postal code. Further information is available at www.canadapost.com.
T3Z 3N7
D8R 8C4
RR4 88D
P9C 3Q4
V2X 3RU
V5R8S4
M8N 7LK J1M6U4 S1B 2R9 88B U2L D7R 7L2 F9Z6G4
A careful look at the sample data indicates that some lines have sequences of three alphanumeric characters, followed by a space character, followed by three more alphanumeric characters. Other lines have no space character. So if you are to detect all valid character sequences, you must allow for the optional nature of the space character.
First, let’s design a pattern that will match the sequences of characters that omit the space character. You want to match an alphabetic character first, which you can express using the metacharacter \w, followed by a numeric digit, which is matched by the metacharacter \d. If you don’t make allowance for the optional existence of a space character, you could use the following pattern:
\w\d\w\d\w\d
It matches the character, digit, character, digit, character, digit sequence that forms a Canadian postal code.
85
Chapter 4
To allow for an optional space character, you can simply add a space character to the pattern with a ? quantifier, if you assume that only a single space character is possible, or a * quantifier if you assume that optionally, there may be multiple space characters. Assuming that there is no space character or a single space character, you would have the following pattern:
\w\d\w ?\d\w\d
Try It Out |
Matching Canadian Postcode 1 |
1.Open the Komodo Regular Expression Toolkit, and clear any residual regular expression and test text.
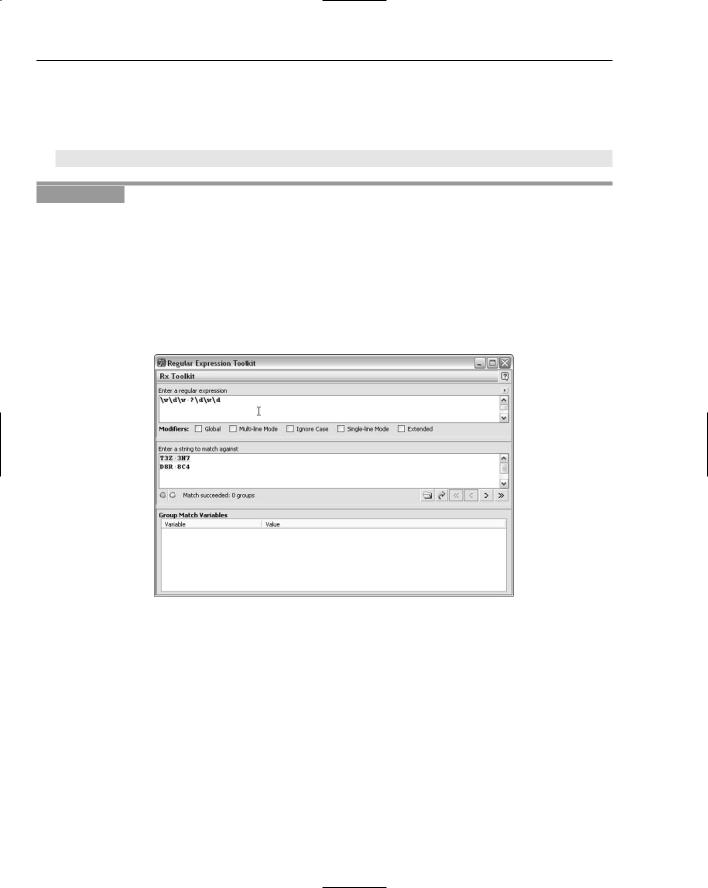
2.In the Enter a String to Match Against area, enter the first two lines of CanPostcodes.txt as the test string.
3.In the Enter a Regular Expression area, enter the pattern \w\d\w ?\d\w\d.
4.Inspect the results in the Enter a String to Match Against area and in the gray area below it, as shown in Figure 4-8.
Figure 4-8
How It Works
The text T3Z 3N7 matches. The regular expression engine starts at the position before the uppercase T and attempts to match the character following that position against the first metacharacter, \w. That matches because T is an ASCII alphabetic character. It next attempts to match the \d metacharacter against the numeric digit 3. That too matches. The next attempt is to match the pattern \w against the
86

Metacharacters and Modifiers
uppercase character Z. That too matches. Next, an attempt is made to match the pattern ? (a space character followed by the ? quantifier) against a single space character (displayed as a mid dot in the Komodo Regular Expression Toolkit). That matches. Next, it attempts to match the pattern \d against the second numeric digit 3. That too matches. Next, it attempts to match the pattern \w against the uppercase N. Because that is an alphabetic character, there is a match. Finally, it attempts to match the metacharacter \d against the numeric digit 7. Because all components of the regular expression pattern match, the whole pattern matches. The matching text is highlighted in pale green in the Komodo Regular Expression Toolkit.
If you wish to match characters sequences that require at least one space character, you can use the + quantifier, which matches one or more occurrences of the preceding character or group.
Some regular expression implementations (for example, OpenOffice.org Writer) don’t support the \w and \d metacharacters and require the use of character classes, which are described in more detail in Chapter 5.
The following character class corresponds to the metacharacter \w:
[A-Za-z0-9_]
And the following character class corresponds to the metacharacter \d:
[0-9]
Assume that Canadian postal codes use only uppercase alphabetic characters. Using character classes, the following pattern would give the same results as the previous pattern, except that only uppercase alphabetic characters are matched:
[A-Z][0-9][A-Z] ?[0-9][A-Z][0-9]
Try It Out |
Alternative Approach to Canadian Postcodes |
1.Open OpenOffice.org Writer, and open the test file CanPostcodes.txt.
2.Use the Ctrl+F keyboard shortcut to open the Find and Replace dialog box.
3.Check the Regular Expressions and Match Case check boxes.
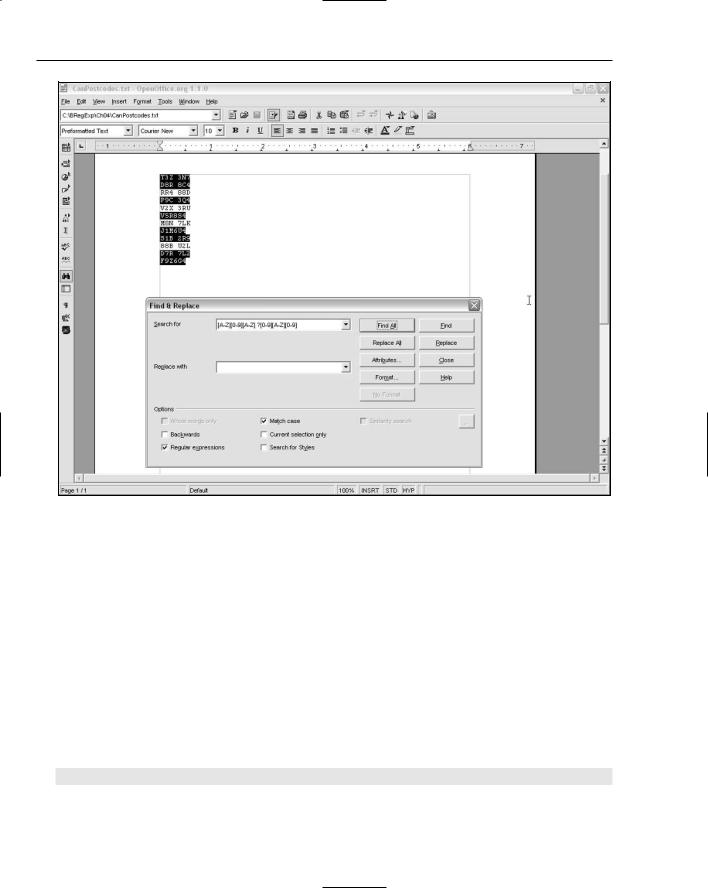
4.Enter the pattern [A-Z][0-9][A-Z] ?[0-9][A-Z][0-9] in the Search For text box.
5.Inspect the highlighted text, which indicates matches for the regular expression pattern. Figure 4-9 shows this pattern used in OpenOffice.org Writer on CanPostcodes.txt.
87
Chapter 4
Figure 4-9
How It Works
The text T3Z 3N7 matches. The regular expression engine starts at the position before the uppercase T and attempts to match the character following that position against the first metacharacter, [A-Z]. That matches. It next attempts to match the [0-9] character class metacharacter against the numeric digit 3. That too matches. The next attempt is to match the pattern [A-Z] against the character Z. That too matches. Next, an attempt is made to match the pattern ? (a space character followed by the ? quantifier) against a single space character. That matches. Next, it attempts to match the pattern [0-9] against the second numeric digit 3. That too matches. Next, it attempts to match the pattern [A-Z] against the uppercase N. Because that is an alphabetic character, there is a match. Finally, it attempts to match the metacharacter [0-9] against the numeric digit 7. Because all components of the regular expression pattern match, the whole pattern matches. The matching text is highlighted in OpenOffice.org Writer.
If you assumed that lowercase alphabetic characters were also allowed, a pattern like this would be required to allow for the possible existence of upperand lowercase characters:
[A-Za-z][0-9][A-Za-z] ?[0-9][A-Za-z][0-9]
88