

- •Introduction
- •Who This Book Is For
- •What This Book Covers
- •How This Book Is Structured
- •What You Need to Use This Book
- •Conventions
- •Source Code
- •Errata
- •p2p.wrox.com
- •What Are Regular Expressions?
- •What Can Regular Expressions Be Used For?
- •Finding Doubled Words
- •Checking Input from Web Forms
- •Changing Date Formats
- •Finding Incorrect Case
- •Adding Links to URLs
- •Regular Expressions You Already Use
- •Search and Replace in Word Processors
- •Directory Listings
- •Online Searching
- •Why Regular Expressions Seem Intimidating
- •Compact, Cryptic Syntax
- •Whitespace Can Significantly Alter the Meaning
- •No Standards Body
- •Differences between Implementations
- •Characters Change Meaning in Different Contexts
- •Regular Expressions Can Be Case Sensitive
- •Case-Sensitive and Case-Insensitive Matching
- •Case and Metacharacters
- •Continual Evolution in Techniques Supported
- •Multiple Solutions for a Single Problem
- •What You Want to Do with a Regular Expression
- •Replacing Text in Quantity
- •Regular Expression Tools
- •findstr
- •Microsoft Word
- •StarOffice Writer/OpenOffice.org Writer
- •Komodo Rx Package
- •PowerGrep
- •Microsoft Excel
- •JavaScript and JScript
- •VBScript
- •Visual Basic.NET
- •Java
- •Perl
- •MySQL
- •SQL Server 2000
- •W3C XML Schema
- •An Analytical Approach to Using Regular Expressions
- •Express and Document What You Want to Do in English
- •Consider the Regular Expression Options Available
- •Consider Sensitivity and Specificity
- •Create Appropriate Regular Expressions
- •Document All but Simple Regular Expressions
- •Document What You Expect the Regular Expression to Do
- •Document What You Want to Match
- •Test the Results of a Regular Expression
- •Matching Single Characters
- •Matching Sequences of Characters That Each Occur Once
- •Introducing Metacharacters
- •Matching Sequences of Different Characters
- •Matching Optional Characters
- •Matching Multiple Optional Characters
- •Other Cardinality Operators
- •The * Quantifier
- •The + Quantifier
- •The Curly-Brace Syntax
- •The {n} Syntax
- •The {n,m} Syntax
- •Exercises
- •Regular Expression Metacharacters
- •Thinking about Characters and Positions
- •The Period (.) Metacharacter
- •Matching Variably Structured Part Numbers
- •Matching a Literal Period
- •The \w Metacharacter
- •The \W Metacharacter
- •Digits and Nondigits
- •The \d Metacharacter
- •Canadian Postal Code Example
- •The \D Metacharacter
- •Alternatives to \d and \D
- •The \s Metacharacter
- •Handling Optional Whitespace
- •The \S Metacharacter
- •The \t Metacharacter
- •The \n Metacharacter
- •Escaped Characters
- •Finding the Backslash
- •Modifiers
- •Global Search
- •Case-Insensitive Search
- •Exercises
- •Introduction to Character Classes
- •Choice between Two Characters
- •Using Quantifiers with Character Classes
- •Using the \b Metacharacter in Character Classes
- •Selecting Literal Square Brackets
- •Using Ranges in Character Classes
- •Alphabetic Ranges
- •Use [A-z] With Care
- •Digit Ranges in Character Classes
- •Hexadecimal Numbers
- •IP Addresses
- •Reverse Ranges in Character Classes
- •A Potential Range Trap
- •Finding HTML Heading Elements
- •Metacharacter Meaning within Character Classes
- •The ^ metacharacter
- •How to Use the - Metacharacter
- •Negated Character Classes
- •Combining Positive and Negative Character Classes
- •POSIX Character Classes
- •The [:alnum:] Character Class
- •Exercises
- •String, Line, and Word Boundaries
- •The ^ Metacharacter
- •The ^ Metacharacter and Multiline Mode
- •The $ Metacharacter
- •The $ Metacharacter in Multiline Mode
- •Using the ^ and $ Metacharacters Together
- •Matching Blank Lines
- •Working with Dollar Amounts
- •Revisiting the IP Address Example
- •What Is a Word?
- •Identifying Word Boundaries
- •The \< Syntax
- •The \>Syntax
- •The \b Syntax
- •The \B Metacharacter
- •Less-Common Word-Boundary Metacharacters
- •Exercises
- •Grouping Using Parentheses
- •Parentheses and Quantifiers
- •Matching Literal Parentheses
- •U.S. Telephone Number Example
- •Alternation
- •Choosing among Multiple Options
- •Unexpected Alternation Behavior
- •Capturing Parentheses
- •Numbering of Captured Groups
- •Numbering When Using Nested Parentheses
- •Named Groups
- •Non-Capturing Parentheses
- •Back References
- •Exercises
- •Why You Need Lookahead and Lookbehind
- •The (? metacharacters
- •Lookahead
- •Positive Lookahead
- •Negative Lookahead
- •Positive Lookahead Examples
- •Positive Lookahead in the Same Document
- •Inserting an Apostrophe
- •Lookbehind
- •Positive Lookbehind
- •Negative Lookbehind
- •How to Match Positions
- •Adding Commas to Large Numbers
- •Exercises
- •What Are Sensitivity and Specificity?
- •Extreme Sensitivity, Awful Specificity
- •Email Addresses Example
- •Replacing Hyphens Example
- •The Sensitivity/Specificity Trade-Off
- •Sensitivity, Specificity, and Positional Characters
- •Sensitivity, Specificity, and Modes
- •Sensitivity, Specificity, and Lookahead and Lookbehind
- •How Much Should the Regular Expressions Do?
- •Abbreviations
- •Characters from Other Languages
- •Names
- •Sensitivity and How to Achieve It
- •Specificity and How to Maximize It
- •Exercises
- •Documenting Regular Expressions
- •Document the Problem Definition
- •Add Comments to Your Code
- •Making Use of Extended Mode
- •Know Your Data
- •Abbreviations
- •Proper Names
- •Incorrect Spelling
- •Creating Test Cases
- •Debugging Regular Expressions
- •Treacherous Whitespace
- •Backslashes Causing Problems
- •Considering Other Causes
- •The User Interface
- •Metacharacters Available
- •Quantifiers
- •The @ Quantifier
- •The {n,m} Syntax
- •Modes
- •Character Classes
- •Back References
- •Lookahead and Lookbehind
- •Lazy Matching versus Greedy Matching
- •Examples
- •Character Class Examples, Including Ranges
- •Whole Word Searches
- •Search-and-Replace Examples
- •Changing Name Structure Using Back References
- •Manipulating Dates
- •The Star Training Company Example
- •Regular Expressions in Visual Basic for Applications
- •Exercises
- •The User Interface
- •Metacharacters Available
- •Quantifiers
- •Modes
- •Character Classes
- •Alternation
- •Back References
- •Lookahead and Lookbehind
- •Search Example
- •Search-and-Replace Example
- •Online Chats
- •POSIX Character Classes
- •Matching Numeric Digits
- •Exercises
- •Introducing findstr
- •Finding Literal Text
- •Quantifiers
- •Character Classes
- •Command-Line Switch Examples
- •The /v Switch
- •The /a Switch
- •Single File Examples
- •Simple Character Class Example
- •Find Protocols Example
- •Multiple File Example
- •A Filelist Example
- •Exercises
- •The PowerGREP Interface
- •A Simple Find Example
- •The Replace Tab
- •The File Finder Tab
- •Syntax Coloring
- •Other Tabs
- •Numeric Digits and Alphabetic Characters
- •Quantifiers
- •Back References
- •Alternation
- •Line Position Metacharacters
- •Word-Boundary Metacharacters
- •Lookahead and Lookbehind
- •Longer Examples
- •Finding HTML Horizontal Rule Elements
- •Matching Time Example
- •Exercises
- •The Excel Find Interface
- •Escaping Wildcard Characters
- •Using Wildcards in Data Forms
- •Using Wildcards in Filters
- •Exercises
- •Using LIKE with Regular Expressions
- •The % Metacharacter
- •The _ Metacharacter
- •Character Classes
- •Negated Character Classes
- •Using Full-Text Search
- •Using The CONTAINS Predicate
- •Document Filters on Image Columns
- •Exercises
- •Using the _ and % Metacharacters
- •Testing Matching of Literals: _ and % Metacharacters
- •Using Positional Metacharacters
- •Using Character Classes
- •Quantifiers
- •Social Security Number Example
- •Exercises
- •The Interface to Metacharacters in Microsoft Access
- •Creating a Hard-Wired Query
- •Creating a Parameter Query
- •Using the ? Metacharacter
- •Using the * Metacharacter
- •Using the # Metacharacter
- •Using the # Character with Date/Time Data
- •Using Character Classes in Access
- •Exercises
- •The RegExp Object
- •Attributes of the RegExp Object
- •The Other Properties of the RegExp Object
- •The test() Method of the RegExp Object
- •The exec() Method of the RegExp Object
- •The String Object
- •Metacharacters in JavaScript and JScript
- •SSN Validation Example
- •Exercises
- •The RegExp Object and How to Use It
- •Quantifiers
- •Positional Metacharacters
- •Character Classes
- •Word Boundaries
- •Lookahead
- •Grouping and Nongrouping Parentheses
- •Exercises
- •The System.Text.RegularExpressions namespace
- •A Simple Visual Basic .NET Example
- •The Classes of System.Text.RegularExpressions
- •The Regex Object
- •Using the Match Object and Matches Collection
- •Using the Match.Success Property and Match.NextMatch Method
- •The GroupCollection and Group Classes
- •The CaptureCollection and Capture Class
- •The RegexOptions Enumeration
- •Case-Insensitive Matching: The IgnoreCase Option
- •Multiline Matching: The Effect on the ^ and $ Metacharacters
- •Right to Left Matching: The RightToLeft Option
- •Lookahead and Lookbehind
- •Exercises
- •An Introductory Example
- •The Classes of System.Text.RegularExpressions
- •The Regex Class
- •The Options Property of the Regex Class
- •Regex Class Methods
- •The CompileToAssembly() Method
- •The GetGroupNames() Method
- •The GetGroupNumbers() Method
- •GroupNumberFromName() and GroupNameFromNumber() Methods
- •The IsMatch() Method
- •The Match() Method
- •The Matches() Method
- •The Replace() Method
- •The Split() Method
- •Using the Static Methods of the Regex Class
- •The IsMatch() Method as a Static
- •The Match() Method as a Static
- •The Matches() Method as a Static
- •The Replace() Method as a Static
- •The Split() Method as a Static
- •The Match and Matches Classes
- •The Match Class
- •The GroupCollection and Group Classes
- •The RegexOptions Class
- •The IgnorePatternWhitespace Option
- •Metacharacters Supported in Visual C# .NET
- •Using Named Groups
- •Using Back References
- •Exercise
- •The ereg() Set of Functions
- •The ereg() Function
- •The ereg() Function with Three Arguments
- •The eregi() Function
- •The ereg_replace() Function
- •The eregi_replace() Function
- •The split() Function
- •The spliti() Function
- •The sql_regcase() Function
- •Perl Compatible Regular Expressions
- •Pattern Delimiters in PCRE
- •Escaping Pattern Delimiters
- •Matching Modifiers in PCRE
- •Using the preg_match() Function
- •Using the preg_match_all() Function
- •Using the preg_grep() Function
- •Using the preg_quote() Function
- •Using the preg_replace() Function
- •Using the preg_replace_callback() Function
- •Using the preg_split() Function
- •Supported Metacharacters with ereg()
- •Using POSIX Character Classes with PHP
- •Supported Metacharacters with PCRE
- •Positional Metacharacters
- •Character Classes in PHP
- •Documenting PHP Regular Expressions
- •Exercises
- •W3C XML Schema Basics
- •Tools for Using W3C XML Schema
- •Comparing XML Schema and DTDs
- •How Constraints Are Expressed in W3C XML Schema
- •W3C XML Schema Datatypes
- •Derivation by Restriction
- •Unicode and W3C XML Schema
- •Unicode Overview
- •Using Unicode Character Classes
- •Matching Decimal Numbers
- •Mixing Unicode Character Classes with Other Metacharacters
- •Unicode Character Blocks
- •Using Unicode Character Blocks
- •Metacharacters Supported in W3C XML Schema
- •Positional Metacharacters
- •Matching Numeric Digits
- •Alternation
- •Using the \w and \s Metacharacters
- •Escaping Metacharacters
- •Exercises
- •Introduction to the java.util.regex Package
- •Obtaining and Installing Java
- •The Pattern Class
- •Using the matches() Method Statically
- •Two Simple Java Examples
- •The Properties (Fields) of the Pattern Class
- •The CASE_INSENSITIVE Flag
- •Using the COMMENTS Flag
- •The DOTALL Flag
- •The MULTILINE Flag
- •The UNICODE_CASE Flag
- •The UNIX_LINES Flag
- •The Methods of the Pattern Class
- •The compile() Method
- •The flags() Method
- •The matcher() Method
- •The matches() Method
- •The pattern() Method
- •The split() Method
- •The Matcher Class
- •The appendReplacement() Method
- •The appendTail() Method
- •The end() Method
- •The find() Method
- •The group() Method
- •The groupCount() Method
- •The lookingAt() Method
- •The matches() Method
- •The pattern() Method
- •The replaceAll() Method
- •The replaceFirst() Method
- •The reset() Method
- •The start() Method
- •The PatternSyntaxException Class
- •Using the \d Metacharacter
- •Character Classes
- •The POSIX Character Classes in the java.util.regex Package
- •Unicode Character Classes and Character Blocks
- •Using Escaped Characters
- •Using Methods of the String Class
- •Using the matches() Method
- •Using the replaceFirst() Method
- •Using the replaceAll() Method
- •Using the split() Method
- •Exercises
- •Obtaining and Installing Perl
- •Creating a Simple Perl Program
- •Basics of Perl Regular Expression Usage
- •Using the m// Operator
- •Using Other Regular Expression Delimiters
- •Matching Using Variable Substitution
- •Using the s/// Operator
- •Using s/// with the Global Modifier
- •Using s/// with the Default Variable
- •Using the split Operator
- •Using Quantifiers in Perl
- •Using Positional Metacharacters
- •Captured Groups in Perl
- •Using Back References in Perl
- •Using Alternation
- •Using Character Classes in Perl
- •Using Lookahead
- •Using Lookbehind
- •Escaping Metacharacters
- •A Simple Perl Regex Tester
- •Exercises
- •Index

Regular Expressions in Perl
Figure 26-17
How It Works
The test string is assigned to the variable $myString:
my $myString = “I attended a Star Training Company training course.”;
The variable $oldString is used to hold the original value for later display:
my $oldString = $myString;
The first occurrence of the character sequence Star in the test string is replaced by the character sequence Moon:
$myString =~ s/Star/Moon/;
The user is informed of the original and replaced strings:
print “The original string was: \n’$oldString’\n\n”;
print “After replacement the string is: \n’$myString’\n\n”; if ($oldString =~ m/Star/)
{
print “The string ‘Star’ was matched and replaced in the old string”;
}
Using s/// with the Global Modifier
Often, you will want to replace all occurrences of a character sequence in the test string. The example of the Star Training Company earlier in this book is a case in point. To specify that all occurrences of a pattern are replaced, the global modifier, g, is used.
To achieve global replacement, you write the following:
$myTestString =~ s/pattern/replacementString/g
The g modifier after the third forward slash indicates that global replacement is to take place.
Try It Out |
Using s/// with the Global Modifier |
1.Type the following code in a text editor:
#!/usr/bin/perl -w use strict;
679

Chapter 26
print “This example uses the global modifier, ‘g’\n\n”;
my $myTestString = “Star Training Company courses are great. Choose Star for your training needs.”;
my $myOnceString = $myTestString; my $myGlobalString = $myTestString; my $myPattern = “Star”;
my $myReplacementString = “Moon”;
$myOnceString =~ s/$myPattern/$myReplacementString/; $myGlobalString =~ s/$myPattern/$myReplacementString/g; print “The original string was ‘$myTestString’.\n\n”;
print “After a single replacement it became ‘$myOnceString’.\n\n”; print “After global replacement it became ‘$myGlobalString’.\n\n”;
2.Save the code as GlobalReplace.pl.
3.Run the code and inspect the results, as shown in Figure 26-18. Notice that without the g modifier, only one occurrence of the character sequence Star has been replaced. With the g modifier present, all occurrences (in this case, there are two) are replaced.
Figure 26-18
How It Works
The test string is assigned to the variable $myTestString:
my $myTestString = “Star Training Company courses are great. Choose Star for your
training needs.”;
The value of the original test string is copied to the variables $myOnceString and $myGlobalString:
my $myOnceString = $myTestString;
my $myGlobalString = $myTestString;
The pattern Star is assigned to the variable $myPattern:
my $myPattern = “Star”;
The replacement string, Moon, is assigned to the variable $myReplacementString:
my $myReplacementString = “Moon”;
680

Regular Expressions in Perl
One match is replaced in $myOnceString:
$myOnceString =~ s/$myPattern/$myReplacementString/;
All matches (two, in this example) are replaced in $myGlobalString, because the g modifier is specified:
$myGlobalString =~ s/$myPattern/$myReplacementString/g;
Then the original string, the string after a single replacement, and the string after global replacement are displayed:
print “The original string was ‘$myTestString’.\n\n”;
print “After a single replacement it became ‘$myOnceString’.\n\n”; print “After global replacement it became ‘$myGlobalString’.\n\n”;
Using s/// with the Default Variable
The default variable, $_, can be used with s/// to search and replace the value held in the default variable.
Two forms of syntax can be used. You can use the normal s/// syntax, with the variable name, the =~ operator and the pattern and replacement text:
$_ =~ s/pattern/replacementText/modifiers;
The alternative, more succinct, syntax allows the name of the default variable and =~ operator to be omitted. So you can simply write the following:
s/pattern/replacementText/modifiers
Try It Out |
Using s/// with the Default Variable |
1.Type the following code in a text editor:
#!/usr/bin/perl -w use strict;
$_ = “I went to a training course from Star Training Company.”; print “The default string, \$_, contains ‘$_’.\n\n”;
if (s/Star/Moon/)
{
print “A replacement has taken place using the default variable.\n”;
print “The replaced string in \$_ is now ‘$_’.”;
}
2.
3.
Save the code as ReplaceDefaultVariable.pl.
Run the code, and inspect the displayed result, as shown in Figure 26-19.
681
Chapter 26
Figure 26-19
How It Works
The test string is assigned to the default variable, $_:
$_ = “I went to a training course from Star Training Company.”;
The value contained in the default variable is displayed:
print “The default string, \$_, contains ‘$_’.\n\n”;
The test of the if statement uses the abbreviated syntax for carrying out a replacement on the default variable:
if (s/Star/Moon/)
You might prefer to use the full syntax:
if ($_ =~ s/Star/Moon/)
Whichever syntax you use, the user is then informed that a replacement operation has taken place and is informed of the value of the string after the replacement operation:
print “A replacement has taken place using the default variable.\n”;
print “The replaced string in \$_ is now ‘$_’.”;
Using the split Operator
The split operator is used to split a test string according to the match for a regular expression.
The following example shows how you can separate a comma-separated sequence of values into its component parts.
Try It Out |
Using the split Operator |
1.Type the following code into a text editor:
#!/usr/bin/perl -w use strict;
my $myTestString = “A, B, C, D”;
print “The original string was ‘$myTestString’.\n”; my @myArray = split/,\s?/, $myTestString;
682
Regular Expressions in Perl
print “The string has been split into four array elements:\n”; print “$myArray[0]\n”;
print “$myArray[1]\n”; print “$myArray[2]\n”; print “$myArray[3]\n”;
print “Displaying array elements using the ‘foreach’ statement:\n”; foreach my $mySplit (split/,\s?/, $myTestString)
{
print “$mySplit\n”;
}
2.
3.
Save the code as SplitDemo.pl.
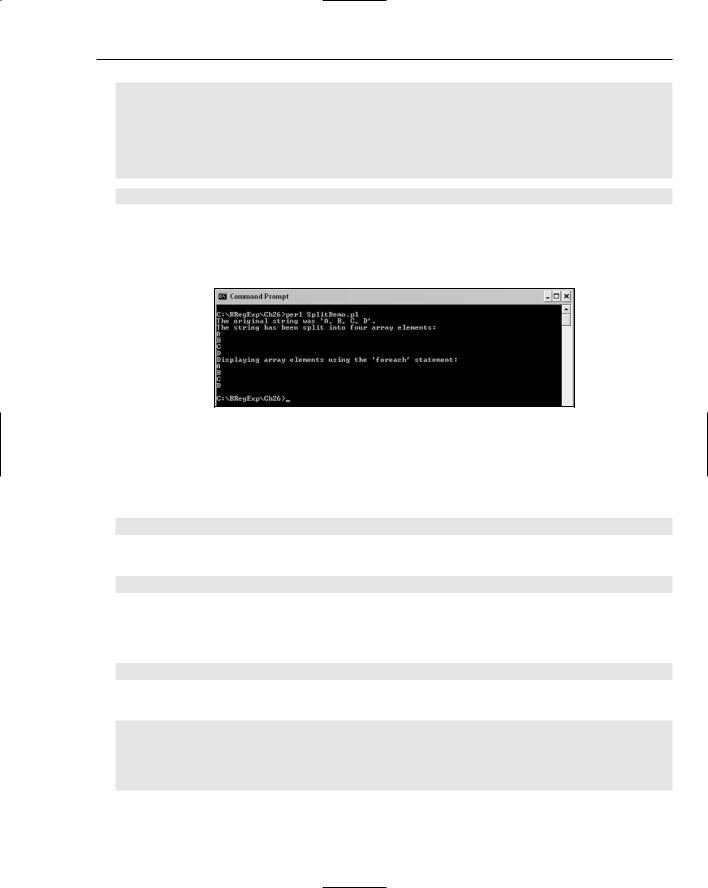
Run the code, and inspect the displayed results, as shown in Figure 26-20.
Figure 26-20
How It Works
A sequence of values separated by commas and a space character is assigned to the variable $myTestString:
my $myTestString = “A, B, C, D”;
The value of the original string is displayed:
print “The original string was ‘$myTestString’.\n”;
The @myArray array is assigned the result of using the split operator. The pattern that is matched against is a comma optionally followed by a whitespace character. The target of the split operator is the variable $myTestString:
my @myArray = split/,\s?/, $myTestString;
Then you can use array indices to display the components into which the string has been split:
print “The string has been split into four array elements:\n”; print “$myArray[0]\n”;
print “$myArray[1]\n”; print “$myArray[2]\n”; print “$myArray[3]\n”;
683

Chapter 26
Or, more elegantly, you can use a foreach statement to display each result of splitting the $myTestString variable:
print “Displaying array elements using the ‘foreach’ statement:\n”;
foreach my $mySplit (split/,\s?/, $myTestString)
{
print “$mySplit\n”;
}
The Metacharacters Suppor ted in Perl
Perl supports a useful range of metacharacters, as summarized in the following table.
Metacharacter |
Description |
|
|
. (period character) |
Matches any character (with the exception, according to mode, of the new- |
|
line character). |
\w |
Matches a character that is alphabetic, numeric, or an underscore character. |
|
Sometimes called a “word character.” Equivalent to the character class |
|
[A-Za-z0-9_]. |
\W |
Matches a character that is not alphabetic, numeric, or an underscore char- |
|
acter. Equivalent to the character class [^A-Za-z0-9_] or [^\w]. |
\s |
Matches a whitespace character. |
\S |
Matches a character that is not a whitespace character. |
\d |
Matches a character that is a numeric digit. Equivalent to the character |
|
class [0-9]. |
\D |
Matches a character that is not a numeric digit. Equivalent to the character |
|
class [^0-9]. |
? |
Quantifier. Matches if the preceding character or group occurs zero or one |
|
time. |
* |
Quantifier. Matches if the preceding character or group occurs zero or more |
|
times. |
+ |
Quantifier. Matches if the preceding character or group occurs one or more |
|
times. |
{n,m} |
Quantifier. Matches if the preceding character or group occurs a minimum |
|
of n times and a maximum of m times. |
(...) |
Capturing parentheses. |
$1 etc |
Variables that allow access to captured groups |
| |
Alternation character. |
684