

- •Introduction
- •Who This Book Is For
- •What This Book Covers
- •How This Book Is Structured
- •What You Need to Use This Book
- •Conventions
- •Source Code
- •Errata
- •p2p.wrox.com
- •What Are Regular Expressions?
- •What Can Regular Expressions Be Used For?
- •Finding Doubled Words
- •Checking Input from Web Forms
- •Changing Date Formats
- •Finding Incorrect Case
- •Adding Links to URLs
- •Regular Expressions You Already Use
- •Search and Replace in Word Processors
- •Directory Listings
- •Online Searching
- •Why Regular Expressions Seem Intimidating
- •Compact, Cryptic Syntax
- •Whitespace Can Significantly Alter the Meaning
- •No Standards Body
- •Differences between Implementations
- •Characters Change Meaning in Different Contexts
- •Regular Expressions Can Be Case Sensitive
- •Case-Sensitive and Case-Insensitive Matching
- •Case and Metacharacters
- •Continual Evolution in Techniques Supported
- •Multiple Solutions for a Single Problem
- •What You Want to Do with a Regular Expression
- •Replacing Text in Quantity
- •Regular Expression Tools
- •findstr
- •Microsoft Word
- •StarOffice Writer/OpenOffice.org Writer
- •Komodo Rx Package
- •PowerGrep
- •Microsoft Excel
- •JavaScript and JScript
- •VBScript
- •Visual Basic.NET
- •Java
- •Perl
- •MySQL
- •SQL Server 2000
- •W3C XML Schema
- •An Analytical Approach to Using Regular Expressions
- •Express and Document What You Want to Do in English
- •Consider the Regular Expression Options Available
- •Consider Sensitivity and Specificity
- •Create Appropriate Regular Expressions
- •Document All but Simple Regular Expressions
- •Document What You Expect the Regular Expression to Do
- •Document What You Want to Match
- •Test the Results of a Regular Expression
- •Matching Single Characters
- •Matching Sequences of Characters That Each Occur Once
- •Introducing Metacharacters
- •Matching Sequences of Different Characters
- •Matching Optional Characters
- •Matching Multiple Optional Characters
- •Other Cardinality Operators
- •The * Quantifier
- •The + Quantifier
- •The Curly-Brace Syntax
- •The {n} Syntax
- •The {n,m} Syntax
- •Exercises
- •Regular Expression Metacharacters
- •Thinking about Characters and Positions
- •The Period (.) Metacharacter
- •Matching Variably Structured Part Numbers
- •Matching a Literal Period
- •The \w Metacharacter
- •The \W Metacharacter
- •Digits and Nondigits
- •The \d Metacharacter
- •Canadian Postal Code Example
- •The \D Metacharacter
- •Alternatives to \d and \D
- •The \s Metacharacter
- •Handling Optional Whitespace
- •The \S Metacharacter
- •The \t Metacharacter
- •The \n Metacharacter
- •Escaped Characters
- •Finding the Backslash
- •Modifiers
- •Global Search
- •Case-Insensitive Search
- •Exercises
- •Introduction to Character Classes
- •Choice between Two Characters
- •Using Quantifiers with Character Classes
- •Using the \b Metacharacter in Character Classes
- •Selecting Literal Square Brackets
- •Using Ranges in Character Classes
- •Alphabetic Ranges
- •Use [A-z] With Care
- •Digit Ranges in Character Classes
- •Hexadecimal Numbers
- •IP Addresses
- •Reverse Ranges in Character Classes
- •A Potential Range Trap
- •Finding HTML Heading Elements
- •Metacharacter Meaning within Character Classes
- •The ^ metacharacter
- •How to Use the - Metacharacter
- •Negated Character Classes
- •Combining Positive and Negative Character Classes
- •POSIX Character Classes
- •The [:alnum:] Character Class
- •Exercises
- •String, Line, and Word Boundaries
- •The ^ Metacharacter
- •The ^ Metacharacter and Multiline Mode
- •The $ Metacharacter
- •The $ Metacharacter in Multiline Mode
- •Using the ^ and $ Metacharacters Together
- •Matching Blank Lines
- •Working with Dollar Amounts
- •Revisiting the IP Address Example
- •What Is a Word?
- •Identifying Word Boundaries
- •The \< Syntax
- •The \>Syntax
- •The \b Syntax
- •The \B Metacharacter
- •Less-Common Word-Boundary Metacharacters
- •Exercises
- •Grouping Using Parentheses
- •Parentheses and Quantifiers
- •Matching Literal Parentheses
- •U.S. Telephone Number Example
- •Alternation
- •Choosing among Multiple Options
- •Unexpected Alternation Behavior
- •Capturing Parentheses
- •Numbering of Captured Groups
- •Numbering When Using Nested Parentheses
- •Named Groups
- •Non-Capturing Parentheses
- •Back References
- •Exercises
- •Why You Need Lookahead and Lookbehind
- •The (? metacharacters
- •Lookahead
- •Positive Lookahead
- •Negative Lookahead
- •Positive Lookahead Examples
- •Positive Lookahead in the Same Document
- •Inserting an Apostrophe
- •Lookbehind
- •Positive Lookbehind
- •Negative Lookbehind
- •How to Match Positions
- •Adding Commas to Large Numbers
- •Exercises
- •What Are Sensitivity and Specificity?
- •Extreme Sensitivity, Awful Specificity
- •Email Addresses Example
- •Replacing Hyphens Example
- •The Sensitivity/Specificity Trade-Off
- •Sensitivity, Specificity, and Positional Characters
- •Sensitivity, Specificity, and Modes
- •Sensitivity, Specificity, and Lookahead and Lookbehind
- •How Much Should the Regular Expressions Do?
- •Abbreviations
- •Characters from Other Languages
- •Names
- •Sensitivity and How to Achieve It
- •Specificity and How to Maximize It
- •Exercises
- •Documenting Regular Expressions
- •Document the Problem Definition
- •Add Comments to Your Code
- •Making Use of Extended Mode
- •Know Your Data
- •Abbreviations
- •Proper Names
- •Incorrect Spelling
- •Creating Test Cases
- •Debugging Regular Expressions
- •Treacherous Whitespace
- •Backslashes Causing Problems
- •Considering Other Causes
- •The User Interface
- •Metacharacters Available
- •Quantifiers
- •The @ Quantifier
- •The {n,m} Syntax
- •Modes
- •Character Classes
- •Back References
- •Lookahead and Lookbehind
- •Lazy Matching versus Greedy Matching
- •Examples
- •Character Class Examples, Including Ranges
- •Whole Word Searches
- •Search-and-Replace Examples
- •Changing Name Structure Using Back References
- •Manipulating Dates
- •The Star Training Company Example
- •Regular Expressions in Visual Basic for Applications
- •Exercises
- •The User Interface
- •Metacharacters Available
- •Quantifiers
- •Modes
- •Character Classes
- •Alternation
- •Back References
- •Lookahead and Lookbehind
- •Search Example
- •Search-and-Replace Example
- •Online Chats
- •POSIX Character Classes
- •Matching Numeric Digits
- •Exercises
- •Introducing findstr
- •Finding Literal Text
- •Quantifiers
- •Character Classes
- •Command-Line Switch Examples
- •The /v Switch
- •The /a Switch
- •Single File Examples
- •Simple Character Class Example
- •Find Protocols Example
- •Multiple File Example
- •A Filelist Example
- •Exercises
- •The PowerGREP Interface
- •A Simple Find Example
- •The Replace Tab
- •The File Finder Tab
- •Syntax Coloring
- •Other Tabs
- •Numeric Digits and Alphabetic Characters
- •Quantifiers
- •Back References
- •Alternation
- •Line Position Metacharacters
- •Word-Boundary Metacharacters
- •Lookahead and Lookbehind
- •Longer Examples
- •Finding HTML Horizontal Rule Elements
- •Matching Time Example
- •Exercises
- •The Excel Find Interface
- •Escaping Wildcard Characters
- •Using Wildcards in Data Forms
- •Using Wildcards in Filters
- •Exercises
- •Using LIKE with Regular Expressions
- •The % Metacharacter
- •The _ Metacharacter
- •Character Classes
- •Negated Character Classes
- •Using Full-Text Search
- •Using The CONTAINS Predicate
- •Document Filters on Image Columns
- •Exercises
- •Using the _ and % Metacharacters
- •Testing Matching of Literals: _ and % Metacharacters
- •Using Positional Metacharacters
- •Using Character Classes
- •Quantifiers
- •Social Security Number Example
- •Exercises
- •The Interface to Metacharacters in Microsoft Access
- •Creating a Hard-Wired Query
- •Creating a Parameter Query
- •Using the ? Metacharacter
- •Using the * Metacharacter
- •Using the # Metacharacter
- •Using the # Character with Date/Time Data
- •Using Character Classes in Access
- •Exercises
- •The RegExp Object
- •Attributes of the RegExp Object
- •The Other Properties of the RegExp Object
- •The test() Method of the RegExp Object
- •The exec() Method of the RegExp Object
- •The String Object
- •Metacharacters in JavaScript and JScript
- •SSN Validation Example
- •Exercises
- •The RegExp Object and How to Use It
- •Quantifiers
- •Positional Metacharacters
- •Character Classes
- •Word Boundaries
- •Lookahead
- •Grouping and Nongrouping Parentheses
- •Exercises
- •The System.Text.RegularExpressions namespace
- •A Simple Visual Basic .NET Example
- •The Classes of System.Text.RegularExpressions
- •The Regex Object
- •Using the Match Object and Matches Collection
- •Using the Match.Success Property and Match.NextMatch Method
- •The GroupCollection and Group Classes
- •The CaptureCollection and Capture Class
- •The RegexOptions Enumeration
- •Case-Insensitive Matching: The IgnoreCase Option
- •Multiline Matching: The Effect on the ^ and $ Metacharacters
- •Right to Left Matching: The RightToLeft Option
- •Lookahead and Lookbehind
- •Exercises
- •An Introductory Example
- •The Classes of System.Text.RegularExpressions
- •The Regex Class
- •The Options Property of the Regex Class
- •Regex Class Methods
- •The CompileToAssembly() Method
- •The GetGroupNames() Method
- •The GetGroupNumbers() Method
- •GroupNumberFromName() and GroupNameFromNumber() Methods
- •The IsMatch() Method
- •The Match() Method
- •The Matches() Method
- •The Replace() Method
- •The Split() Method
- •Using the Static Methods of the Regex Class
- •The IsMatch() Method as a Static
- •The Match() Method as a Static
- •The Matches() Method as a Static
- •The Replace() Method as a Static
- •The Split() Method as a Static
- •The Match and Matches Classes
- •The Match Class
- •The GroupCollection and Group Classes
- •The RegexOptions Class
- •The IgnorePatternWhitespace Option
- •Metacharacters Supported in Visual C# .NET
- •Using Named Groups
- •Using Back References
- •Exercise
- •The ereg() Set of Functions
- •The ereg() Function
- •The ereg() Function with Three Arguments
- •The eregi() Function
- •The ereg_replace() Function
- •The eregi_replace() Function
- •The split() Function
- •The spliti() Function
- •The sql_regcase() Function
- •Perl Compatible Regular Expressions
- •Pattern Delimiters in PCRE
- •Escaping Pattern Delimiters
- •Matching Modifiers in PCRE
- •Using the preg_match() Function
- •Using the preg_match_all() Function
- •Using the preg_grep() Function
- •Using the preg_quote() Function
- •Using the preg_replace() Function
- •Using the preg_replace_callback() Function
- •Using the preg_split() Function
- •Supported Metacharacters with ereg()
- •Using POSIX Character Classes with PHP
- •Supported Metacharacters with PCRE
- •Positional Metacharacters
- •Character Classes in PHP
- •Documenting PHP Regular Expressions
- •Exercises
- •W3C XML Schema Basics
- •Tools for Using W3C XML Schema
- •Comparing XML Schema and DTDs
- •How Constraints Are Expressed in W3C XML Schema
- •W3C XML Schema Datatypes
- •Derivation by Restriction
- •Unicode and W3C XML Schema
- •Unicode Overview
- •Using Unicode Character Classes
- •Matching Decimal Numbers
- •Mixing Unicode Character Classes with Other Metacharacters
- •Unicode Character Blocks
- •Using Unicode Character Blocks
- •Metacharacters Supported in W3C XML Schema
- •Positional Metacharacters
- •Matching Numeric Digits
- •Alternation
- •Using the \w and \s Metacharacters
- •Escaping Metacharacters
- •Exercises
- •Introduction to the java.util.regex Package
- •Obtaining and Installing Java
- •The Pattern Class
- •Using the matches() Method Statically
- •Two Simple Java Examples
- •The Properties (Fields) of the Pattern Class
- •The CASE_INSENSITIVE Flag
- •Using the COMMENTS Flag
- •The DOTALL Flag
- •The MULTILINE Flag
- •The UNICODE_CASE Flag
- •The UNIX_LINES Flag
- •The Methods of the Pattern Class
- •The compile() Method
- •The flags() Method
- •The matcher() Method
- •The matches() Method
- •The pattern() Method
- •The split() Method
- •The Matcher Class
- •The appendReplacement() Method
- •The appendTail() Method
- •The end() Method
- •The find() Method
- •The group() Method
- •The groupCount() Method
- •The lookingAt() Method
- •The matches() Method
- •The pattern() Method
- •The replaceAll() Method
- •The replaceFirst() Method
- •The reset() Method
- •The start() Method
- •The PatternSyntaxException Class
- •Using the \d Metacharacter
- •Character Classes
- •The POSIX Character Classes in the java.util.regex Package
- •Unicode Character Classes and Character Blocks
- •Using Escaped Characters
- •Using Methods of the String Class
- •Using the matches() Method
- •Using the replaceFirst() Method
- •Using the replaceAll() Method
- •Using the split() Method
- •Exercises
- •Obtaining and Installing Perl
- •Creating a Simple Perl Program
- •Basics of Perl Regular Expression Usage
- •Using the m// Operator
- •Using Other Regular Expression Delimiters
- •Matching Using Variable Substitution
- •Using the s/// Operator
- •Using s/// with the Global Modifier
- •Using s/// with the Default Variable
- •Using the split Operator
- •Using Quantifiers in Perl
- •Using Positional Metacharacters
- •Captured Groups in Perl
- •Using Back References in Perl
- •Using Alternation
- •Using Character Classes in Perl
- •Using Lookahead
- •Using Lookbehind
- •Escaping Metacharacters
- •A Simple Perl Regex Tester
- •Exercises
- •Index

Chapter 24
Unicode Character Class |
Description |
|
|
Pd |
Dashes |
Pe |
Closing punctuation |
Pf |
Final quotes |
Pi |
Initial quotes |
Po |
Other forms of punctuation |
Ps |
Opening punctuation |
S |
Symbols |
Sc |
Currency symbols |
Sk |
Modifier symbols |
Sm |
Mathematical symbols |
So |
Other symbols |
Z |
Separators |
Zl |
Line breaks |
Zp |
Paragraph breaks |
Zs |
Spaces |
|
|
The following sections briefly illustrate the use of several Unicode character classes.
Matching Decimal Numbers
The Nd character class matches decimal numbers. So if you have a simple document such as the following DocumentUnicode.xml, you can use that Unicode character class to specify allowed values of the Section element’s number attribute:
<?xml version=”1.0” encoding=”UTF-8”?>
<Document xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance”
xsi:noNamespaceSchemaLocation=”C:\BRegExp\Ch24\DocumentUnicode.xsd”> <Section number=”1”>Content</Section>
<Section number=”2”>Content</Section> <Section number=”3”>Content</Section>
</Document>
The corresponding schema document, DocumentUnicode.xsd, uses the Nd Unicode character class :
<?xml version=”1.0” encoding=”UTF-8”?>
<xs:schema xmlns:xs=”http://www.w3.org/2001/XMLSchema” elementFormDefault=”qualified”>
<xs:element name=”Document”> <xs:complexType>
<xs:sequence>
<xs:element ref=”Section” maxOccurs=”unbounded”/> </xs:sequence>
606

Regular Expressions in W3C XML Schema
</xs:complexType>
</xs:element>
<xs:element name=”Section”> <xs:complexType>
<xs:simpleContent>
<xs:extension base=”xs:string”> <xs:attribute name=”number” use=”required”>
<xs:simpleType>
<xs:restriction base=”xs:NMTOKEN”> <xs:pattern value=”\p{Nd}” /> </xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:element>
</xs:schema>
Notice that the value of the xs:pattern element’s value attribute is \p{Nd}, which specifies that the value of the Section element’s number attribute is a single decimal number.
Mixing Unicode Character Classes with Other Metacharacters
It is possible to mix Unicode character classes with other metacharacters in the same regular expression. The following example illustrates how this can be done (in a rather contrived way) to match a U.S. Social Security number. The XML instance file, PersonsSSNUnicode.xml, is shown here:
<?xml version=”1.0” encoding=”UTF-8”?>
<PersonsSSN xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance” xsi:noNamespaceSchemaLocation=”C:\BRegExp\Ch24\PersonsSSNUnicode.xsd”>
<Person>
<Name>Peter Schmidt</Name> <SSN>123-45-6789</SSN>
</Person>
<Person>
<Name>Yasmin Brown</Name> <SSN>987-65-4321</SSN>
</Person>
</PersonsSSN>
The corresponding W3C XML Schema document, PersonsSSNUnicode.xsd, is shown here:
<?xml version=”1.0” encoding=”UTF-8”?>
<xs:schema xmlns:xs=”http://www.w3.org/2001/XMLSchema” elementFormDefault=”qualified”>
<xs:element name=”Name” type=”xs:string”/> <xs:element name=”Person”>
<xs:complexType>
<xs:sequence>
<xs:element ref=”Name”/> <xs:element ref=”SSN”/>
</xs:sequence>
</xs:complexType>
</xs:element>
607

Chapter 24
<xs:element name=”PersonsSSN”> <xs:complexType>
<xs:sequence>
<xs:element ref=”Person” maxOccurs=”unbounded”/> </xs:sequence>
</xs:complexType>
</xs:element> <xs:element name=”SSN”>
<xs:simpleType>
<xs:restriction base=”xs:string”>
<xs:pattern value=”\p{Nd}{3}-[0-9]{2}-\d{4}” /> </xs:restriction>
</xs:simpleType>
</xs:element>
</xs:schema>
Notice the pattern specified as the value of the xs:pattern element’s value attribute. It uses three different ways of expressing numeric digits: a Unicode character class, a regular expression character class, and the metacharacter \d. The \p{Nd}{3} matches three numeric digits, using a Unicode character class. It is followed by a literal hyphen. Then [0-9]{2} uses a range in a conventional character class to match two numeric digits. Again, it is followed by a literal hyphen. Finally, the \d{4} matches four numeric digits.
Unicode Character Blocks
Unicode character blocks refer to blocks of Unicode characters that are relevant to a particular use. A Unicode character block may refer to a language or group of languages, or may refer to a specialized use, such as box drawing or geometric elements.
The following table illustrates some of the many Unicode character blocks available for use.
Block Name |
Start Code |
End Code |
|
|
|
BasicLatin |
#x0000 |
#x007F |
Latin-1 Supplement |
#x0080 |
#x00FF |
LatinExtended-A |
#x0100 |
#x017F |
Cyrillic |
#x0400 |
#x04FF |
Hebrew |
#x0590 |
#x05FF |
Arabic |
#x0600 |
#x06FF |
Greek |
#x0370 |
#x03FF |
Cherokee |
#x13A0 |
#x13FF |
SuperscriptsAndSubscripts |
#x2070 |
#x209F |
Mathematical Operators |
#x2200 |
#x22FF |
|
|
|
608

Regular Expressions in W3C XML Schema
Using Unicode Character Blocks
This example illustrates the effect of combining a Unicode character block with a Unicode character class.
Try It Out |
Using a Unicode Character Block |
1.Type the following XML markup or open the file WordUnicode.xml in the code download:
<?xml version=”1.0” encoding=”UTF-8”?>
<Word xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance” xsi:noNamespaceSchemaLocation=”C:\BRegExp\Ch24\WordUnicode.xsd”>Führer</Word>
2.Type the following W3C XML Schema document or open the file WordUnicode.xsd in the code download:
<?xml version=”1.0” encoding=”UTF-8”?>
<xs:schema xmlns:xs=”http://www.w3.org/2001/XMLSchema” elementFormDefault=”qualified”>
<xs:element name=”Word” type=”UnicodeType”/> <xs:simpleType name=”UnicodeType”>
<xs:restriction base=”xs:string”> <xs:pattern value=”\w+”/>
</xs:restriction>
</xs:simpleType>
</xs:schema>
3.Attempt to validate WordUnicode.xml against WordUnicode.xsd. Figure 24-7 shows the appearance when validating in XMLSpy. As you can see in the lower part of the figure, the XML instance document is valid according to its associated schema document.
4.Type the following XML markup or open the file WordUnicode2.xml in the code download:
<?xml version=”1.0” encoding=”UTF-8”?>
<Word xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance”
xsi:noNamespaceSchemaLocation=”C:\BRegExp\Ch24\WordUnicode2.xsd”>Führer</Word>
5.Type the following W3C XML Schema document or open the file WordUnicode2.xsd in the code download:
<?xml version=”1.0” encoding=”UTF-8”?>
<xs:schema xmlns:xs=”http://www.w3.org/2001/XMLSchema” elementFormDefault=”qualified”>
<xs:element name=”Word” type=”UnicodeLetterType”/> <xs:simpleType name=”UnicodeLetterType”>
<xs:restriction base=”xs:string”> <xs:pattern value=”\p{L}+”/>
</xs:restriction>
</xs:simpleType>
</xs:schema>
609

Chapter 24
Figure 24-7
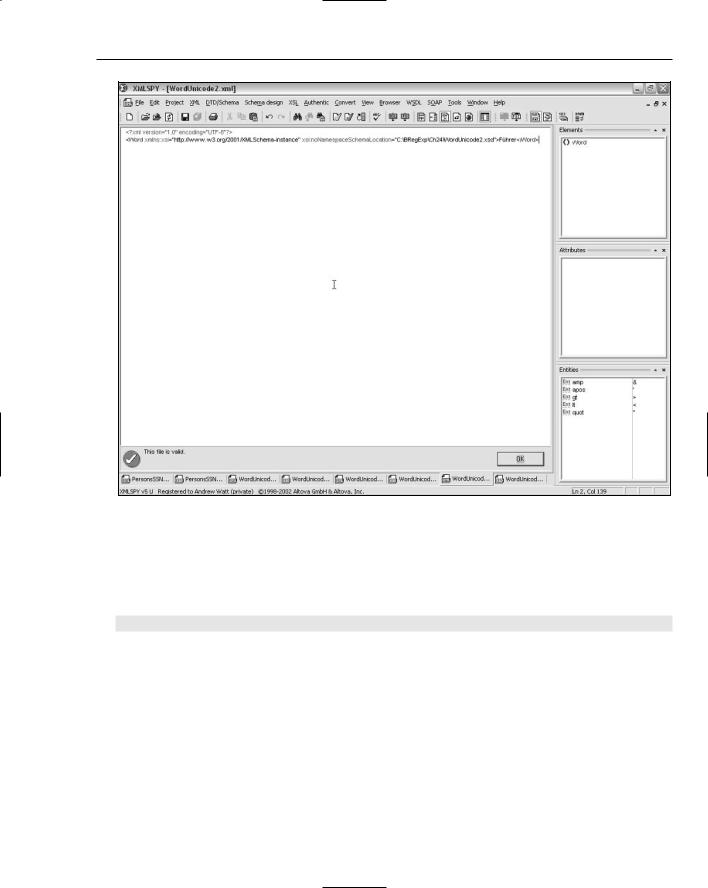
6.Attempt to validate WordUnicode2.xml against WordUnicode2.xsd. Figure 24-8 shows the screen’s appearance. This attempts to match Führer against the pattern \p{L}, which is all Unicode letters. There is a match.
Next, attempt to match the word Führer against Basic Latin letters. It won’t match, because the character ü is Unicode U+00FC, which is outside the range U+0000 to U+007F for the
BasicLatin code group.
7.Type the following XML markup or open the file WordUnicode3.xml in the code download:
<?xml version=”1.0” encoding=”UTF-8”?>
<Word xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance” xsi:noNamespaceSchemaLocation=”C:\BRegExp\Ch24\WordUnicode3.xsd”>Führer</Word>
610
Regular Expressions in W3C XML Schema
Figure 24-8
8.Type the following W3C XML Schema document or open the file WordUnicode3.xsd in the code download:
<?xml version=”1.0” encoding=”UTF-8”?>
<xs:schema xmlns:xs=”http://www.w3.org/2001/XMLSchema” elementFormDefault=”qualified”>
<xs:element name=”Word” type=”UnicodeBasicLatinType” /> <xs:simpleType name=”UnicodeBasicLatinType” >
<xs:restriction base=”xs:string”> <xs:simpleType>
<xs:restriction base=”xs:string”> <xs:pattern value=”\p{IsBasicLatin}” /> </xs:restriction>
</xs:simpleType> <xs:pattern value=”\p{L}”/> </xs:restriction>
</xs:simpleType>
</xs:schema>
Notice how you specify the intersection of the Unicode character class specified by the pattern \p{L} and the Unicode character block specified by \p{IsBasicLatin}.
611