

Ajax Patterns And Best Practices (2006)
.pdfC H A P T E R 1 0 ■ I N F I N I T E D A T A P A T T E R N |
309 |
As already indicated, using the CGI parameter as a task identifier is an example of a necessity practice. Regardless of the client calling the server and using the same task identifier, the same results would be generated. The problem with using a task identifier of 20 is that the task identifier has to be determined by the server, and not the client, adding a wrinkle to the solution.
The implementation of the pattern is a server push, without user authentication. Looking back at the Persistent Communications pattern implementation, the server push used authentication, and that would seem to be a conflict in this implementation. The Infinite Data pattern uses a shopping cart approach, where the identification of the user will use an HTTP cookie.
Using cookies or authentication is not a necessity, but a nice-to-have feature. Otherwise, anybody can access a specific task. For example, if the URL is /ajax/chap08/PrimeNumberHandler. ashx?task=1234, not using an HTTP cookie as an authorization mechanism would allow everybody to retrieve the results for task 1234.
Implementing the HTML Client
For the scope of the prime number application, the HTML client is used to define and process the prime number. The HTML client presents an HTML form consisting of a text box and button. The text box is used to define the maximum number for which all prime numbers are calculated. The button is used to submit the maximum number to the server. The results area displays the generated numbers.
Figure 10-2 is the HTML page used to process two prime numbers.
Figure 10-2. HTML page that processes two prime numbers
310 |
C H A P T E R 1 0 ■ I N F I N I T E D A T A P A T T E R N |
Figure 10-2 shows two text boxes; one text box has the value of 200, and the other has the value of 1000. Each text box represents the maximum number to find all primes. The result area is where the text No Result is displayed. The Send Data buttons are used to send the maximum number value to the server. The Start Communications and End Communications buttons are used to start and stop the Persistent Communications pattern. These two buttons are not necessary and can be automatically controlled by the Send Data buttons. They were kept in the HTML page to illustrate how the Persistent Communications and Infinite Data patterns work seamlessly together.
Overall Implementation Details of the HTML Page
The implementation of the HTML page will be presented as a series of code segments. The first code segment is the overall HTML page, with most of the implementation missing for clarity purposes. Then as needed each missing code segment will be illustrated and explained.
The overall structure of the HTML page illustrated in Figure 10-2 is as follows:
<html>
<head>
<title>Infinite Data</title>
<script language="JavaScript" src="../lib/factory.js"></script> <script language="JavaScript" src="../lib/asynchronous.js"></script> <script language="JavaScript" src="../lib/xmlhelpers.js"></script>
<script language="JavaScript" src="../lib/clientcommunicator.js"></script> <script language="JavaScript" type="text/javascript">
var client = new ClientCommunicator();
client.baseURL = "/ajax/chap08/PrimeNumberHandler.ashx";
</script>
</head>
<body>
<button onclick="StartCommunications()">Start Communications</button> <button onclick="EndCommunications()">End Communications</button> <table border="1">
<tr>
<td>Number</td>
<td><input type="text" size="10" id="number1" /></td> <td><button onclick="SendData1()">Send Data</button></td>
</tr>
<tr>
<td colspan="4"><span id="result1">No Result</span></td> </tr>
<tr>
<td>Number</td>
<td><input type="text" size="10" id="number2" /></td> <td><button onclick="SendData2()">Send Data</button></td>
</tr>
C H A P T E R 1 0 ■ I N F I N I T E D A T A P A T T E R N |
311 |
<tr>
<td colspan="4"><span id="result2">No Result</span></td> </tr>
</table>
</body>
</html>
The HTML page implementation, like previous pattern implementations, includes a number of JavaScript files referenced by using the script HTML tag. Unlike previous patterns, on the client side the Infinite Data pattern does not reference any script files that implement a generic Infinite Data infrastructure. There is no Infinite Data infrastructure; the activity diagram illustrated in Figure 10-1 shows that all of the logic is application specific.
The Infinite Data pattern does instantiate the ClientCommunicator type that is an implementation of the Persistent Communications pattern. The instantiated Persistent Communications pattern is assigned to the variable client, and the property baseURL is assigned to the file /ajax/ chap08/PrimeNumberHandler.aspx. The file /ajax/chap08/PrimeNumberHandler.aspx represents the server-side implementation of the Infinite Data pattern.
The HTML page contains the HTML element table that contains four rows used to send and receive the Infinite Data state. When the buttons that have the onclick event handlers defined as SendData1 or SendData2 are clicked, the structure is assembled and sent for processing to the server. The sent structure is stored in the input elements with the identifiers number1 and number2. When the result structures are received, they are processed and inserted into the span elements with the identifiers result1 and result2.
Defining the Sending and Receiving Contract
Before further illustrating the code on the client and server sides, the contract between the two sides needs to be defined. The contract in an Ajax application is the data that is sent between the client and the server. In the Infinite Data pattern implementation, there are two contracts: what the client sends as a structure to be processed by the server, and the result structures sent by the server and processed by the client.
The state for the structure is stored in the HTML form input fields, which happen to be text fields, number1 and number2. When the appropriate button is clicked, the function SendData1 or SendData2 is called. What you should notice is that all of the identifiers are appended with a number to indicate whether the button represents the first task or the second task (or more appropriately called the first or second transaction identifier).
When the results are generated using the transaction identifier, we know which span element, result1 or result2, the result structures are destined for. Let’s say that the text field with the identifier number1 contains 20, and the button associated with the function SendData1 is clicked. The generated structure that is sent to the server is represented using the following XML:
<Action>
<TransactionIdentifier>1</TransactionIdentifier>
<Number>20</Number>
</Action>
312 |
C H A P T E R 1 0 ■ I N F I N I T E D A T A P A T T E R N |
In the XML, the element TransactionIdentifier has an associated value of 1, and the XML element Number has an associated value of 20. When a result structure is generated, the XML will appear similar to the following:
<PrimeNumber>
<Result>success</Result>
<TransactionIdentifier>1</TransactionIdentifier>
<Number>9</Number>
</PrimeNumber>
The main difference between the XML to be sent and received is the additional XML element Result to indicate a success. The Result element is necessary so that the client knows what to do with the XML content. For example, imagine sending a state that has incorrect data. The error condition is not generated on the sending of the data, but on the receiving of the data. This is due to the requirement of the Persistent Communications pattern and asynchronous communications. To indicate that an error has occurred, a result has to be sent with the error. Another reason for using the Result element is to indicate a finished operation, indicating that all results have been found and that the client will not receive any more results.
There is one weakness with using simple transaction identifiers 1 and 2: if a user sends an Action XML document with transaction identifier 1, and then shortly thereafter sends another Action XML document with the same transaction identifier, the results will be corrupted. The results are corrupted because two tasks would generate data using the same transaction identifier even though the state for each transaction identifier may be different.
The solution is to create a unique transaction identifier for each and every sending of structured data that generates results. The following modified Action XML document references the corrected transaction identifier:
<Action> <TransactionIdentifier>1_1</TransactionIdentifier> <Number>20</Number>
</Action>
In the modified XML, the transaction identifier has encoding so that the first digit represents the first or second result field, and the second digit is the transaction identifier counter. The encoding of the transaction identifier seems arbitrary, and is arbitrary from the perspective of the server because only the client knows how to decipher the identifier. The server, when presented with the transaction identifier, does not attempt to decipher what the identifier means. The server is responsible only for cross-referencing the transaction identifier with the received and result data.
Generating the Content for the Contract
Having defined the contract between the client and server, the next step is to generate the content for the contract. The JavaScript code used to generate the state will be illustrated first, and then the code used to process the received results. For this explanation, it is assumed that the server sends and receives the data without any errors or problems.
The data sent from the client to the server is created in either the function SendData1 or SendData2. For explanation purposes, the implementation of SendData1 is outlined. It is not necessary to explain SendData2 because it is nearly identical to SendData1. The main difference
C H A P T E R 1 0 ■ I N F I N I T E D A T A P A T T E R N |
313 |
between SendData1 and SendData2 is that one function uses the identifier 1, and the other uses the identifier 2. For those readers who are cringing because of using the hard-coded numeric identifiers 1 and 2, well, you are right. There is a better way of writing the code, but it will not be illustrated here because that would make the explanation of the pattern more difficult. Here is the implementation of SendData1:
function SendData1() { transactionIdentifier1Counter ++;
document.getElementById( "result1").innerHTML = "No Result";
var buffer = GenerateActionData( "1_" + transactionIdentifier1Counter, document.getElementById( 'Number1').value);
client.send( "application/xml", buffer.length, buffer);
}
Calling SendData1 means creating a new task on the server, thus invalidating the results of the old tasks that may be executing. The implementation of SendData1 begins with the incrementing of the first task transaction identifier (transactionIdentifier1Counter). Using a static random transaction identifier would result in the scenario where multiple requests would be sending results with the same transaction identifier, thus corrupting the results. As a new task is being created, the content of the result span element (result1) is cleared. The XML buffer that is sent is created by using the function GenerateActionData. The function GenerateActionData has two parameters; the first parameter is the transaction identifier, and the second parameter is the maximum number to calculate all primes for. The generated XML buffer is sent to the server by using the method client.send.
Following is the implementation of GenerateActionData that generates the XML buffer:
function GenerateActionData( transactionIdentifier, number) { return
"<Action>" +
"<TransactionIdentifier>" + transactionIdentifier + "</TransactionIdentifier>" +
"<Number>" + number + "</Number>" + "</Action>";
}
The implementation of GenerateActionData is a straightforward string concatenation. When the buffer is sent by using the client.send method, the server is responsible for
translating the XML buffer into a task. The client.send method does not wait for a response and returns immediately without a response. The caller of client.send does not know if the task has been started or is working. The caller assumes everything went okay and will expect some results in the receiving part of the HTML page.
Deciphering the Protocol
The receiving of the results is started when the method client.start() is called as per the explanation in the Persistent Communications pattern. When a result is retrieved, the method reference of client.listen is called, which is implemented as follows:
314 C H A P T E R 1 0 ■ I N F I N I T E D A T A P A T T E R N
client.listen = function( status, statusText, responseText, responseXML) { if( status == 200 && responseXML != null) {
var objData = new Object(); objData.didFind = false; objData.verify = IterateResults;
XMLIterateElements( objData, objData, responseXML); if( objData.didFind == true &&
IsActiveTransactionIdentifier( objData.transactionIdentifier) == true) { var spanElement = document.getElementById(
GetResultField( objData.transactionIdentifier)); spanElement.innerHTML += "(" + objData.number + ")";
}
}
}
The implementation of client.listen is a bit more complicated because the function has to process the received XML and ensure that the results are not stale. A stale result is a result that does not belong to the currently executing transaction identifier. The first step in the implementation of the client.listen method is to ensure that results have been successfully retrieved, where the HTTP response code is 200, and that the responseXML parameter is not null. As the contract relies on XML if the responseXML parameter is null, most likely the response was not encoded using XML and thus is not applicable in the context of the pattern.
If the responseXML field can be processed, the XML data needs to be iterated by using the function XMLIterateElements. The results of the iteration are written to data members of the variable objData. Specifically, the data members transactionIdentifier, didFind, and number are manipulated. The data member transactionIdentifier represents the received transaction identifier, and number represents the prime number found. The purpose of the data member didFind is to indicate whether the data members transactionIdentifier and number are valid. If the data member didFind is assigned a value of true, a result was found. But to process and display the result, the function IsActiveTransactionIdentifier first verifies that the result is not stale and belongs to an active transaction identifier. The implementation of the function IsActiveTransactionIdentifier will be covered shortly. If the retrieved result can be processed,
the data member’s objData.number value is added to the destination span element. To know which span element to update (results1 or results2), the function GetResultField is called to extract the span element identifier from the received transaction identifier. The found span element instance is assigned to the variable spanElement, and the value of the spanElement. innerHTML property is appended with the found prime number (objData.number).
The function IsActiveTransactionIdentifier is used to determine whether the retrieved result is active and is implemented as follows:
function IsActiveTransactionIdentifier( transactionIdentifier) { var reference = transactionIdentifier.charAt( 0);
var valIdentifier = parseInt( transactionIdentifier.substring( 2));
if( reference == "1" && valIdentifier == transactionIdentifier1Counter) { return true;
}
C H A P T E R 1 0 ■ I N F I N I T E D A T A P A T T E R N |
315 |
else if( reference == "2" && valIdentifier == transactionIdentifier2Counter) { return true;
}
else {
return false;
}
}
In the implementation of IsActiveTransactionIdentifier, the parameter transactionIdentifier is from the result, where an example would be 1_101. The transaction identifier parameter is encoded and needs to be separated into two pieces; the first piece is the destination span element, and the second piece is the transaction identifier (transactionIdentifier1Counter or transactionIdentifier2Counter). The two pieces are verified, and if the destination span element references an active transaction identifier, a true is returned; otherwise, a false is returned. Returning true allows a result to be processed.
If the result is processed, the destination of the result needs to be extracted by using the function GetResultField, which is implemented as follows:
function GetResultField( transactionIdentifier) {
var reference = transactionIdentifier.charAt( 0); if( reference == "1") {
return "result1";
}
else if( reference == "2") { return "result2";
}
throw new Error("Invalid transaction identifier value");
}
In the implementation of GetResultField, the code used to extract the field reference is identical to the code used in the function IsActiveTransactionIdentifier, and this is done for illustration purposes only. The decision block tests to see if the variable reference has the value 1 or 2, and if so returns the appropriate HTML identifier. If the variable reference is neither 1 or 2, an exception is thrown to indicate an incorrectly formatted transactionIdentifier parameter.
Earlier it was mentioned that on the client side there is no reusable code because the implementation of the pattern is specific to the problem being solved. This is not entirely correct, because some pieces of the HTML client code could have been combined into a small library. The small library could be have been used in this context, but probably could not be reused in another context. An example would have been the functions IsActiveTransactionIdentifier and GetResultField.
Be wary of adding small libraries of reusable code. Often there is no real advantage to using the functions because doing so does not save you much coding time or logic. It does not mean that all client-side Infinite Data implementations will be hard-coded as in the example prime number application. Some things could be abstracted, but it very much depends on the specifics of the applications that you are creating. What could be useful is the creation of helper routines.
Helper routines are encapsulated pieces of code that make it quicker to implement certain functionalities. Going back to the illustrative example of functions, they could be abstracted to a set of helper functions used to create and decipher the transaction identifier. The helper
316 |
C H A P T E R 1 0 ■ I N F I N I T E D A T A P A T T E R N |
functions should be implemented only after you have determined what a standard transaction identifier is.
Implementing the Task Manager
On the server side, two pieces of functionality are implemented: the task manager and the implementation of the task. In the case of the prime number algorithm, that means implementing a task to find all prime numbers. Interfaces are used so that there are no dependencies between the task manager, results, and tasks. The task manager, prime number task, and prime number result algorithms each implement one of the interfaces. The role of the task manager is to wire all of the interfaces together and provide a working solution to the Infinite Data pattern on the server side.
Defining the Task Manager Interfaces
There are three main interfaces for the Task Manager: ITask, ITaskManager, and IResult. The three interfaces are defined as follows:
public interface ITask {
long TransactionIdentifier { get; set;} void Execute( ITaskManager taskManager);
}
public interface IResult { string Result {
get;
}
long TransactionIdentifier { get;
}
}
public interface ITaskManager {
void AddResult( IResult result);
}
The interface ITask is implemented by the individual tasks, with an example being the prime number algorithm. The ITask interface has one property and one method. The property TransactionIdentifier contains the value of the client-provided transaction identifier (for example, 1_101). The method Execute is called by the task manager to run the task. The parameter taskManager is a callback interface used by the task to save the generated results.
The interface IResult is composed entirely of properties that represent the status of the result (Result) and the transaction identifier (TransactionIdentifier). The IResult interface’s definition is incomplete, allowing a developer to subclass IResult by adding properties specific to the task. The idea of the IResult interface is to provide a common interface and a placeholder that can be referenced by other parts of the Infinite Data implementation without having to know the type of the result. The consumer of the IResult interface would know the different result implementations and if necessary be able to perform a type cast.
The interface ITaskManager is implemented by the task manager and has a single method, AddResult. The AddResult method is used by an ITask interface instance to pass an IResult
C H A P T E R 1 0 ■ I N F I N I T E D A T A P A T T E R N |
317 |
instance to the task manager. When the task manager receives an IResult instance, it is saved and passed to the calling client when asked for.
Before describing the implementation of the task manager interfaces, I will illustrate the code that uses the interfaces. Understanding how the interfaces are used makes it simpler to understand the implementations. The following code is going to implement an ASP.NET handler, which translated into Java would be a Java servlet. The handler or servlet would be responsible for interacting with the defined interfaces. Additionally, the handler or servlet needs to fulfill the server-side requirements of the Persistent Communications pattern. This means that the handler or servlet must process the HTTP GET to send results to the client, and HTTP PUT or POST to process client-sent structure instances.
Packaging the Implementations
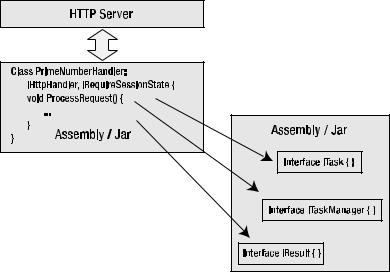
When implementing the server-side part of the Infinite Data pattern using an ASP.NET handler or a Java servlet, it is possible to put everything into one distribution unit that is a jar or assembly. Another approach would be to split the logic so that some is in the handler or servlet and the rest is in another distribution unit. Creating multiple distribution units makes it simpler to update each unit independently. For example, the general task handler infrastructure would not be updated as often as the task implementations. Figure 10-3 illustrates an example distribution unit structure.
Figure 10-3. Packaging structure of handler and interface implementations
In Figure 10-3, the HTTP server calls the handler PrimeNumberHandler.ProcessRequest. That call in turn generates a series of calls to the interfaces ITask, ITaskManager, and IResult. Even though the diagram references the interfaces, types that implement the interfaces process the calls. What is being illustrated is how one distribution unit references another distribution unit. The interfaces in the one distribution unit provide the common reference points for the
318 |
C H A P T E R 1 0 ■ I N F I N I T E D A T A P A T T E R N |
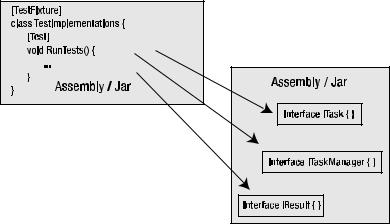
two distribution units. The separation of the two distribution units makes it possible for the task implementations to be called directly from unit tests or other application servers.
Figure 10-4 illustrates how the distribution unit can be called by the NUnit testing framework.
Figure 10-4. Testing package structure of the interfaces
Calling the Interface Implementations
Having resolved how to separate the code, the class PrimeNumberHandler is an HTTP handler that calls the distribution unit and implements the task interfaces. PrimeNumberHandler is implemented as follows (with code pieces removed for clarity):
<%@ WebHandler Language="C#" Class="PrimeNumberHandler" %> using System;
using System.Web;
using System.Web.SessionState; using System.Threading;
using PrimeNumberCalculator; using TaskManager;
public class PrimeNumberHandler : IHttpHandler, IRequiresSessionState {
public void ProcessRequest (HttpContext context) { TaskManagerImpl taskManager = GetTaskManager( context);
if (context.Request.HttpMethod.CompareTo("GET") == 0) { // Abbreviated for clarity
}
else if (context.Request.HttpMethod.CompareTo("PUT") == 0 || context.Request.HttpMethod.CompareTo("POST") == 0) {
// Abbreviated for clarity
}
}