

Ajax Patterns And Best Practices (2006)
.pdfC H A P T E R 8 ■ P E R S I S T E N T C O M M U N I C A T I O N S P A T T E R N |
259 |
protected void service( javax.servlet.http.HttpServletRequest request, javax.servlet.http.HttpServletResponse response) throws javax.servlet.ServletException, java.io.IOException {
String user = request.getRequestURI().substring( _baseDirectory.length());
if(user.length() == 0) {
UserIdentification userid = _userIdentification.identifyUser(request);
if(userid.isIdentified()) { response.sendRedirect(request.getRequestURI()
+"/"
+userid.getIdentifier());
return;
}
else { response.setStatus(500,
"User could not be identified"); return;
}
}
super.service(request, response);
}
The new bolded code in the service method illustrates the extraction of the user identifier from the called URL that is assigned the user variable. If the user variable has no length, the root resource URL has been called and therefore a redirect is appropriate. In Java servletspeak, a redirection is performed by using the method sendRedirect, which results in an HTTP 302 code being generated. If no redirection is made, a specific URL is being requested and hence processing can continue as usual.
The modified implementation of the method doPost is as follows:
protected void doPost(HttpServletRequest req, HttpServletResponse resp)
throws javax.servlet.ServletException, java.io.IOException {
// Do something with the URL
}
What is new in the implementation of the method doPost is that there is no implementation. This is because the implementation of doPost is completely specific to the application. In the case of the server push, it means receiving data on the writing stream that is used to update a specific resource. In the case of the example, that means processing the sent data and assigning it to the UserState object instance.
260 |
C H A P T E R 8 ■ P E R S I S T E N T C O M M U N I C A T I O N S P A T T E R N |
As a side note, remember that the HTTP server handles authentication. Therefore, if the methods doGet, doPost, and so on are reached, the programmer can be assured that the user has been authenticated and allowed access to that URL. Most web servers, such as Apache and Tomcat, allow a great deal of fine-tuning of the authentication. If that is not enough, or your HTTP server does not support such fine-tuning, you will need to write an authentication filter. The authentication code should under no circumstances be added to the ServerCommunicator.
The modified implementation of doGet is as follows:
private int getSentVersion(HttpServletRequest request, String user) {
Cookie[] cookies = request.getCookies();
String cookieIdentifier = "VersionId" + user; if(cookies != null) {
for(int c1 = 0; c1 < cookies.length; c1 ++) { if(cookies[ c1].getName().compareTo(
cookieIdentifier) == 0) {
return Integer.parseInt(cookies[cl].getValue())
}
}
}
return 0;
}
private UserState getUser(String user) { Iterator iter = _users.iterator(); while(iter.hasNext()) {
UserState userstate = (UserState)iter.next(); if(userstate.getUserIdentifier().compareTo(user) == 0) {
return userstate;
}
}
return null;
}
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
UserState userstate = getUser( request.getRequestURI().substring( _baseDirectory.length()));
if(userstate != null) {
int sentVersion = getSentVersion(
request, userstate.getUserIdentifier()); int waitCount = 0;
while(waitCount < 10) {
if(sentVersion < userstate.getVersion()) { PrintWriter out = response.getWriter(); out.println("User (" + userstate.toString() +
")");
C H A P T E R 8 ■ P E R S I S T E N T C O M M U N I C A T I O N S P A T T E R N |
261 |
String cookieIdentifier = "VersionId" + userstate.getUserIdentifier();
response.addCookie(
new Cookie(cookieIdentifier, new Integer(
userstate.getVersion()).toString())); return;
}
try { Thread.sleep(1000);
}
catch (InterruptedException e) { } waitCount ++;
}
}
response.setStatus(408, "No change");
}
else {
response.setStatus(500, "Could not find user state");
}
}
In the doGet method implementation, there are several new aspects. Because any request that reaches doGet or doPost has a user identifier associated with it, extracting the user identifier from the URL is necessary. The user identifier cannot be associated with the user authentication information at the doGet or doPost stage because the user identifier represents a unique identifier. The user authentication at the doGet or doPost stage might be same as is the case if an administrator is verifying some specific URLs. After having extracted the user information from the URL, the method getUser is called to retrieve the state of the user. In the example, that means iterating the _users array list. However, in your application that might mean loading the user state from a database or a file. The key point to notice is that there is a separate function to handle loading the user state.
Going back to the implementation of doGet, after the user state has been retrieved, the cookie is retrieved from the URL. It is important to realize that there is not a single cookie, but a cookie for each user. This is important because if you are an administrator watching multiple users, those users need multiple version numbers. The simplest way to do this is to create a cookie identifier for each user. Or more generally, create a cookie version identifier for each specific URL. Another approach is to create an encoded cookie that identifies the version of each specific URL, but the exact specifics are an implementation detail. The important bit is that it is not possible to use a single version number to track all specific URLs. Having retrieved the user state and version number, and identified that the client does not have the latest version of the state, a response can be generated.
Take a moment to look at this example and consider the individual pieces because it represents a full implementation of the Persistent Communications pattern. Notice how little we edited the ClientCommunicator piece. This is because the ClientCommunicator needs a full implementation from the first example. The ClientCommunicator is not aware of whether the accessed resource is global anonymous, global authenticated, or unique. The client knows only that there is some information it is interested in.
262 |
C H A P T E R 8 ■ P E R S I S T E N T C O M M U N I C A T I O N S P A T T E R N |
Version Numbers and Updates
The version number is not a common programming concept. Generally speaking, we don’t track whether data changes. Yet we should because it is a great way to manage changes. For example, Subversion, which is a great version control system, uses version numbers. Many software programs use build numbers that represent changes in the software. It really begs the question, why not state?
Ajax applications are based on data that has a specific state, and therefore it is a good idea to associate version numbers. Imagine the extended abilities of web applications. For example, say that while you are booking a flight, you try out various permutations and get various results.
After seven permutations, your brain begins to fry. It would be fantastic to be able to go back to a state of the web application that represents an earlier request. Current web applications are simply not cut out for that job.
Version numbers in the context of Ajax applications could be defined as their own pattern. But it was decided to not create a specific pattern because the Persistent Communications pattern requires version numbers. Therefore, it was decided that version numbers are an implementation detail, albeit a pretty darn crucial implementation detail.
Performance Considerations
I am not going to pretend that this pattern is not resource intensive. It can be resource intensive if used extensively. The resource drain on the server side is the holding of resources by the reading stream. As was indicated, Jetty has figured out how to deal with the problem as effectively as possible. But if there are thousands of users accessing various global and unique resources, resources will be held in the memory of the server. One rule of thumb to manage resources more effectively is to limit an HTML page to a single Persistent Communications pattern. There is nothing blocking multiple instances, but that could result in a resource explosion on both the client and server. Using the rule of thumb, it effectively means that if there are 100 clients, there will be 100 active connections doing nothing but waiting. Therefore, when implementing this pattern, do a prototype to see how the system will react.
Pattern Highlights
The purpose of the Persistent Communications pattern is to provide a mechanism for the client and server to communicate with each other, whereby data can be sent from the server to the client, without “asking” for it. The pattern illustrates three key scenarios: status updates, presence detection, and server push.
The following points are the important highlights of the Persistent Communications pattern:
•A two-stream mechanism is used to send the data from the server to the client, and from the client to the server.
•The server is responsible for delaying the request if there is no new data for the client to process.
•The data that is sent between the client and server is not processed or managed by the Persistent Communications pattern implementation (ClientCommunicator or ServerCommunicator).
C H A P T E R 8 ■ P E R S I S T E N T C O M M U N I C A T I O N S P A T T E R N |
263 |
•Implementing the Persistent Communications pattern means implementing the Permutations pattern. It may be that only one set of data is sent to the client, but the ServerCommunicator should check what types of data the client is interested in.
•Version numbers are necessary so that state can be tracked and the server knows when to send data to the client.
•It is possible to generate version numbers by using HTTP headers, but HTTP cookies are preferred.
•Although synchronization was only briefly discussed, for your implementations synchronization is very important because the Persistent Communications pattern has a tendency to use shared data.
•Today’s HTTP servers are not capable of providing a persistent running thread that will update the global or specific resource when necessary. A solution is to write an HTTP client that posts the updates to the HTTP server using HTTP POST or PUT.

C H A P T E R 9
■ ■ ■
State Navigation Pattern
Intent
The State Navigation pattern provides an infrastructure in which HTML content can be navigated, and the state is preserved when navigating from one piece of content to another.
Motivation
Web applications have major state and consistency problems, and some Ajax applications amplify those problems. To illustrate, let’s go through the process of buying a plane ticket and note the problems.
I fly regularly for business and as such am always looking for the best price. Because of my ticket-searching capabilities, I have become the travel agent for my wife and a few other people. I search many travel sites and use the permutations and combinations strategy to find the cheapest or most convenient ticket. If I find a ticket, I then try to find a better ticket by moving the dates forward or back, switching to a different airport, or even switching travel sites. Trying to find the best ticket by using a web browser has its challenges because of the way many travel websites “remember” the ticket information. The main problem is that travel websites may not remember my original flying times when I click the Back button, or may not remember old flight information when I open a second browser. And worse yet, some sites perform redirections to other sites not asked for, or require you to fly from certain airports. All travel sites at the time of this writing have one problem or another.
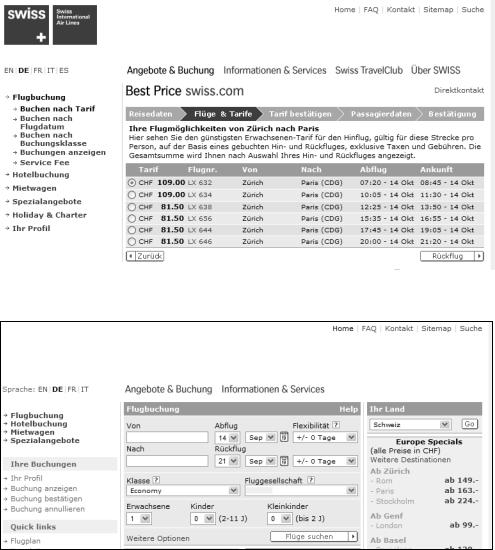
Consider Figure 9-1, which is a snapshot from one travel site. I have blanked out the travel site details because the figure is used to illustrate a problem. Figure 9-1 is the result of selecting the starting and ending points of the initial leg of a flight and being offered a set of times and conditions to choose from.
Figure 9-1 shows found flight details, and the user needs to choose one flight before continuing. To continue and to select the return leg of the flight, the user clicks Rueckflug. To go back and start again, the user clicks Zurueck. For interest sake, let’s click Zurueck and see what happens. Figure 9-2 shows the resulting HTML page.
265
266 |
C H A P T E R 9 ■ S T A T E N A V I G A T I O N P A T T E R N |
|
|
|
|
|
|
|
Figure 9-1. Found flight details
Figure 9-2. Initial search page
Figure 9-2 shows that by going back to start a search, you reset all of your search parameters and have to start from scratch again. This is irritating. The process becomes even more confusing if the user decides to use the navigation buttons and clicks the Back button of the web browser. Figure 9-3 illustrates what happens if the Back and Forward web browser buttons or a combination of those is pressed.
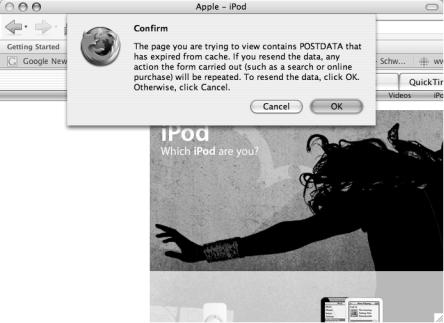
C H A P T E R 9 ■ S T A T E N A V I G A T I O N P A T T E R N |
267 |
|
|
|
|
|
|
|
Figure 9-3. Error that results from pressing the wrong web browser buttons
Figure 9-3 illustrates how clicking the web browser Back button when pages have been posted using the HTTP POST method can cause the browser to generate errors and dialog boxes asking for further help. In these situations, depending on your actions, either the web application works or you bought a second plane ticket. The user experience is inconsistent and problematic.
To solve these experience inconsistencies, web browsers “remember” what the user entered. The web browser solution involves remembering the state contained within the form elements of the HTML page. This remembering of state causes the web browser to automatically fill in logins or form details without requiring the user to type everything in yet again. Yet the web browser solution does not always work because the state is not always consistently remembered. We can’t blame the web browsers for not remembering a correct state because it is not the fault of the web browser. The web browser is just trying to make the best of a bad situation that many web application developers and web application frameworks have forced upon us.
Where heck broke out was when software vendors decided to fix the inherent statelessness of the HTTP protocol. These fixes very often conflict with the functionality of the web browser and introduce their own navigation paradigm. One of the reasons we deviated from the original intention of the Web and the HTTP protocol is our desire to improve and mold things to our liking. Put all of these factors to work and you have the reasons why page navigation is broken.
Applicability
The State Navigation pattern applies in all of those contexts where editable state is associated with an HTML page(s). In most cases, that means workflow or business process operations. It does not mean that only HTML forms that create a workflow are applicable. The state must not
268 |
C H A P T E R 9 ■ S T A T E N A V I G A T I O N P A T T E R N |
be editable in the HTML representation form, because the Representation Morphing pattern can be applied to convert a static representation into an editable representation.
Not all states are created equally. There is binding state and nonbinding state. Binding state is the focus in this pattern. Nonbinding state is used to represent the binding state. For example, the nonbinding state associated with a mailbox could indicate how to sort the e-mails that are displayed in the mailbox. The resource that represents the e-mails is a listing and is considered a binding state. Nonbinding state can be lost without ramifications to the binding state. If the sorting order were to be lost, the resulting e-mails would have another ordering but no information would be lost. At the worst, the end user is inconvenienced.
Associated Patterns
The State Navigation pattern uses the materials presented in Chapter 2 that define the Asynchronous type. When the State Navigation pattern is implemented, it is assumed that the Permutations pattern is used. The State Navigation pattern does assume the state is defined as a chunk, as defined by the Content Chunking pattern, and that the state of the HTML page uses the Representation Morphing pattern. Where the State Navigation and Content Chunking pattern deviate is that a State Navigation implementation is a single chunk only.
Architecture
When implementing the State Navigation pattern, the primary focus is to manage the state associated with an HTML page. The State Navigation pattern infrastructure is responsible only for serving and receiving the state content. The HTML page is responsible for processing and generating the state. The HTML page is in control of calling the State Navigation pattern infrastructure. If the HTML page does not implement any calls to the State Navigation pattern infrastructure, there is no state managed. The State Navigation pattern infrastructure is defined on a per-HTML page basis. This makes it possible for a web application to have mixed state, where some pages are associated with a state, and other pages are not.
Moving Toward an Ideal Solution from the User’s Perspective
It would be simple to say, “This is the way that the State Navigation pattern is designed regardless of how the HTTP or HTML infrastructure functions.” However, that is not possible because the HTTP and HTML infrastructure has its own rules. Therefore, the State Navigation pattern solution is entirely dependent on what works best with HTML and HTTP.
Before I illustrate a solution at the technical level, I am going to show you the desired solution from a user’s perspective that involves manipulating and navigating HTML pages in a simplistic and fictitious workflow application. Figure 9-4 shows the first HTML page of the workflow application.