

2.1.Синтез реляционных баз данных.
База данных состоит из множества атрибутов и ключей. С точки зрения теоретико-множественного описания реляционной базой данных d называется такая совокупность отношений {R1, R2, ...,Rp}, в которой каждое отношение имеет вид Ri= (Si,Ki), где Si- множество атрибутов, а Ki - множество атрибутов образующих ключ.
Предположим на входе задано множество F- зависимостей F над R. С их помощью требуется создать базу данных R=( R1, R2, ...,Rp). Эта БД должна удовлетворять следующим требованиям:
Множество F полностью характеризуется с помощью R , т.е.
![]()
где К – выделенный ключ Ri.
Каждое отношение Ri находится в третьей нормальной форме.
Не существует базы данных с меньшим числом отношений, удовлетворяющим пунктам 1 и 2.
Соединение всех полученных отношений Ri дает исходное отношение R.
Алгоритм порождающий базу данных из заданных F-зависимостей называется алгоритмом синтеза.
Определение. Если R – база данных и на ней задано множество F-зависимостей G, то в ней существует по крайней мере |EG| отношений. Это означает, что в R столько же отношений, сколько и классов эквивалентности. Из этого следует следующее.
Пусть F - множество F – зависимостей. Любая база данных должна иметь |EF’| отношений, где F’ неизбыточное покрытие для F.
Исходя из этого строится способ построения структуры базы данных.
Сначала находится неизбыточное покрытиеF’ для F и в EF’ вычисляем классы эквивалентности. Для каждого EF’(X) строим отношение, состоящее из всех атрибутов, появляющихся в EF’(X). При этом атрибуты левой части каждого класса эквивалентности образуют выделенный ключ.
Реализация этого способа позволяет получить следующий алгоритм:
Вход: множество F – зависимостей F над R.
Выход: полная схема баз данных для F.
Наити для F редуцированное минимальное покрытие G.
Д
 ля
каждойCF
– зависимости (X1,X2,…,Xk)
Y
из G
построить отношение Rj=
X1X2…XkY
с выделенными ключами K={X1,X2,…Xk).
ля
каждойCF
– зависимости (X1,X2,…,Xk)
Y
из G
построить отношение Rj=
X1X2…XkY
с выделенными ключами K={X1,X2,…Xk).Вернуться к п. 2.
Для всякой предметной области можно построить несколько эквивалентных F-описаний. Опираясь на некоторое исходное F-описание заданной предметной области, можно найти для F эквивалентное неизбыточное представление. Неизбыточное представление – представление, лишенное избыточных ФЗ и посторонних атрибутов. Для этого существуют соответствующие алгоритмы «чистки» F-описания.
«Чистка» исходного F-описания выполняется в два этапа:
вначале из F удаляются все избыточные ФЗ (они логически следуют из оставшихся). Полученное в результате множество ФЗ называют неизбыточным покрытием F и обозначают Fнеизб;
далее из Fнеизб удаляются посторонние атрибуты. Этот процесс называется редуцированием, а полученное в результате множество ФЗ называется редуцированным покрытием и обозначается Fред.
Множество ФЗ Fред. не всегда является самым экономным (оптимальным) представлением семантической структуры предметной области. Тем не менее, использование Fред. для синтеза схемы БД обеспечивает в достаточной мере неизбыточность получаемой БД.
Известно, что к организации БД предъявляются три требования: неизбыточность, непротиворечивость, независимость. Последнее из них – независимость данных от приложений достигается в основном средствами СУБД. Неизбыточность и непрворечивость БД можно обеспечить путём выбора подходящей схемы БД.
В теории нормализации доказано, что БД будет неизбыточной и средствами СУБД можно достичь её непротиворечивого состояния, если её схема будет эффективной относительно заданного F-описания предметной области.
Пусть R – множество имен атрибутов, значения которых требуется хранить в БД, и F – множество ФЗ, описывающих связи между атрибутами.

Схема БД над R называется эффективной относительно F, если:
она сохраняет F (разбиение R на R1, R2, …, Rm не приводит к потере зависимостей из F, а значит, связей между атрибутами);
обладает свойствами соединения без потерь информации (представления БД в виде одной таблицы r(R) или в виде совокупности таблиц r1(R1), r2(R2), …, rm(Rm) равносильны). Последнее означает, что любое допустимое состояние таблицы r(R) всегда можно получить из таблиц r1(R1), r2(R2), …, rm(Rm) с помощью операции естественного соединения
к(К)
= к1(К1)
![]() к2(К2)
к2(К2)
![]() …
…![]() кь(Кь)
кь(Кь)
3)
все подсхемы
Ri![]() ρ
нормализованы,
то есть находятся в НФБК(нормальной
форме Бойса–Кодда). Это означает, что
всякая ФЗ, действующая в рамках таблицы
ri(Ri)
в левой части имеет ключ таблицы ri(Ri),
i
=1, 2, …, m.
ρ
нормализованы,
то есть находятся в НФБК(нормальной
форме Бойса–Кодда). Это означает, что
всякая ФЗ, действующая в рамках таблицы
ri(Ri)
в левой части имеет ключ таблицы ri(Ri),
i
=1, 2, …, m.
Теорема.
Для любого
множества ФЗ F,
заданного на конечном множестве атрибутов
R,
всегда существует схема БД

обладающая свойством соединения без потерь, сохраняющая все ФЗ из F и находящаяся в 3НФ.
Свойства схемы БД, удовлетворяющей условиям данной теоремы, вполне приемлемы для практики, так как они гарантируют непротиворечивость БД. 3НФ допускает определённое избыточное дублирование данных, но с этим приходится мириться и учитывать в программах ввода и редактирования данных.
На рисунке 1.1 показана схема получения БД методом синтеза.
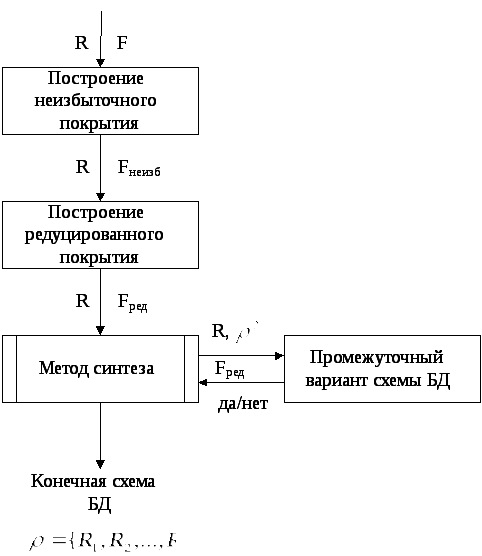
Рис.1.1. Схема получения БД методом синтеза.