

Рихтер Дж., Назар К. - Windows via C C++. Программирование на языке Visual C++ - 2009
.pdf14 Часть I Материалы для обязательного чтения
Табл. 2-1. Наборы символов Unicode для различных алфавитов
16-битный код |
Символы |
16-битныЙ код |
Символы |
0000-007F |
ASCII |
0300-036F |
Общие диакритические |
0080-00FF |
Символы Latin1 |
0400-04FF |
Кириллица |
0100-017F |
Европейские латинские |
0530-058F |
Армянский |
0180-01FF |
Расширенные латинские |
0590-05FF |
Иврит |
0250-02AF |
Стандартные фонетические |
0600-06FF |
Арабский |
02B0-02FF |
Модифицированные литеры |
0900-097F |
Деванагари |
Символьные и строковые типы данных для ANSI и Unicode
Уверен, вы знаете, что тип данных char в языке С представляет 8-битные ANSIсимволы. По умолчанию при объявлении в коде строки-литерала компилятор С преобразует составляющие строку символы в массив 8-битных значений типа char.
//8-битный символ char с = „A‟;
//массив 99 8-битных символов с нулем в конце (также 8-битным) char szBuffer[100] = “А String”;
Созданный Майкрософт компилятор С/С++ поддерживает встроенный тип данных wchar_t, представляющий 16-битные символы Unicode (в кодировке UTF16). Прежние версии компилятора Майкрософт не поддерживали этот тип данных как встроенный и работали с ним только при указании параметра компилятора /Zc:wchar_t. Этот параметр компилятора установлен по умолчанию при создании С++-проекта в Microsoft Visual Studio. Рекомендуется всегда устанавливать этот параметр, поскольку с Unicode-символами лучше работать с использованием встроенных примитивных типов, понятных компилятору без «посредников».
Примечание. Пока компилятор не поддерживал встроенный тип данных wchar_t, этот тип определялся в заголовочном файле С следующим образом:
typedef unsigned short wchar_t;
Объявить Unicode-символ как строку можно следующим образом:
// 16-битный символ wchar_t с = „A‟;
Глава 2. Работа с символами и строками.docx 15
// Массив 99 16-битных символов о нулем в конце (16-битным) wchar_t szBuffer[100] = L"A String";
Заглавная буква L перед литералом сообщает компилятору, что указанный литерал следует компилировать как Unicode-строку. В этом простом примере при размещении данной строки в секции данных программы компилятор кодирует ее в UTF-16, вставляя нулевые байты между ASCII-символами.
Разработчики Windows хотят определить собственный тип данных, чтобы в некоторой степени изолировать себя от языка С. Поэтому в заголовочном файле Windows, WinNT.h, определены следующие типы данных:
typedef |
char |
CHAR; |
// |
8-битный символ |
typedef |
wchar_t |
WCHAR; |
// |
16-битный символ |
Кроме того, в заголовочном файле WinNT.h определен ряд общих типов данных для работы с указателями на символы и строки:
//указатель на 8-битные символы и строки typedef CHAR *PCHAR;
typedef CHAR *PSTR; typedef CONST CHAR *PCSTR
//указатель на 16-битные символы и строки typedef WCHAR *PWCHAR;
typedef WCHAR *PWSTR; typedef CONST WCHAR ♦PCWSTR;
Примечание. В файле WinNT.h есть следующее определение:
typedef __nullterminated WCHAR *NWPSTR, *LPWSTR, *PWSTR;
Префикс __nullterminated представляет собой заголовочную аннотацию (header annotation), описывающую применение типов в качестве параметров и возвращаемых значений функций. В редакции Enterprise среды Visual Studio можно включить параметр Code Analysis в свойствах проекта. В результате в командную строку компилятора будет добавлен параметр /analyze. Он заставит компилятор проверять, не вызываются ли функции с нарушением семантики, предписанной аннотациями. Заметьте: только в версии Enterprise поддерживает параметр /analyze. Для простоты в этой книге заголовочные аннотации убраны из примеров кода. Подробнее о заголовочных аннотаци-
ях см. в статье MSDN «Header Annotations» (http://msd2.microsoft.com/EnUS/library/aa383701.aspx).
Независимо от того, какие именно типы данных вы используете в своем коде, рекомендую следить за их согласованностью ради удобства сопровождения вашего кода. Поскольку я программирую для Windows, я всегда использую типы данных Windows — они соответствуют документации MSDN, что существенно облегчает другим чтение моего кода.
16 Часть I Материалы для обязательного чтения
Можно написать код так, чтобы он компилировался с ANSI- и Unicodeсимволами. В заголовочном файле WinNT.h определены следующие типы данных и макросы:
#ifdef UNICODE |
|
typedef WCHAR TCHAR, *PTCHAR, PTSTR; |
|
typedef CONST WCHAR *PCTSTR; |
|
#define __TEXT(quote) quote |
// r_winnt |
#define __TEXT(quote) L##quote |
|
#else |
|
typedef CHAR TCHAR, *PTCHAR, PTSTR; |
|
typedef CONST CHAR •PCTSTR; |
|
#define __TEXT(quote) quote |
|
#endif |
|
#define TEXT(quote) __JEXT(quote) |
|
Эти типы и макросы (и некоторые другие, менее востребованные и потому здесь не показанные) используются для создания код, который может компилироваться как с ANSI-, так и Unicode-символами, например:
//16-битный символ, если определен UNICODE,
//или 8-битный символ в противном случае
TCHAR с = ТЕХТ („А‟);
//массив 16-битных символов, если определен UNICODE,
//либо 8-битных символов в противном случае
TCHAR szBuffer[100] = TEXT("A String");
Unicode- и ANSI-функции в Windows
Начиная с Windows NT, все версии Windows создаются на основе, включающей Unicode. Иными словами, все ключевые функции для создания окон, вывода текста, манипулирования строками и т.д. требуют Unicode-строки. Если любой Windows-функции передать при вызове ANSI-строку (строку 1-байтовых символов), эта функция сначала преобразует ANSI-строку в Unicode, и только после этого передаст ее операционной системе. Если некоторая функция должна возвращать ANSI-строку, операционная система преобразует Unicode-строку в ANSI и возвращает результат вашему приложению. Все эти преобразования выполняются незаметно для программиста и, естественно, вызывают дополнительный расход памяти и времени.
Глава 2. Работа с символами и строками.docx 17
Я уже говорил, что существует две функции CreateWindowEx: одна принимает строки в Unicode, другая — в ANSI. Все так, но в действительности прототипы этих функций чуть-чуть отличаются:
HWND WINAPI CreateWindowExW (DWORD dwExStyle,
PCWSTR pClassName, |
// Unicode-строка |
PCWSTR pWindowName, |
// Unicode-строка |
DWORD dwStyle, |
|
int X, |
|
int Y, |
|
int nWidth, |
|
int nHeight, |
|
HWND hWndParent, |
|
HMENU hHenu, |
|
HINSTANCE hInstance, |
|
PVOID pParam); |
|
HWND WINAPI CreateWindowExA (DWORD dwExStyle, |
|
PCSTR pClassName, |
// ANSI-строка |
PCSTR pWindowName, |
// ANSI-строка |
DWORD dwStyle, |
|
int X, |
|
int Y, |
|
int nWidth, |
|
int nHeight, HWND hWndParent, HHENU hMenu,
HINSTANCE hInstance, PVOID pParam);
CreateWindowExW — это Unicode-версия. Буква W конце имени функции — аббревиатура слова wide (широкий). Символы Unicode занимают по 16 битов каждый, поэтому их иногда называют широкими символами (wide characters). Буква А в конце имени CreateWindowExA указывает, что данная версия функции принимает ANSI-строки.
Но обычно CreateWindowExW или CreateWindowExA напрямую не вызывают, а обращаются к CreateWindowEx — макросу, определенному в файле WinUser.h:
#ifdef UNICODE
#define CreateWindowEx CreateWindowExW #else
#define CreateWindowEx CreateWindowExA #endif
18 Часть I Материалы для обязательного чтения
Какая именно версия CreateWindowEx будет вызвана, зависит от того, определен ли UNICODE в период компиляции. Перенося 16-разрядное Windowsприложение на платформу Win32, вы, вероятно, не станете определять UNICODE. Тогда все вызовы CreateWindowEx будут преобразованы в вызовы CreateWindowExA — ANSI-версии функции. И перенос приложения упростится, ведь 16разрядная Windows работает только с ANSI-версией CreateWindowEx.
В Windows Vista функция CreateWindowExA — просто шлюз (транслятор), который выделяет память для преобразования строк из ANSI в Unicode и вызывает CreateWindowExW, передавая ей преобразованные строки. Когда CreateWindowExW вернет управление, CreateWindowExA освободит буферы и передаст вам описатель окна.
Таким образом, при вызове функций, заполняющих буферы строками система должна преобразовать Unicode-строки в их эквиваленты, прежде чем ваше приложение сможет обработать строки. Из-за необходимости этих преобразований ваши приложения требуют больше памяти и медленнее работают. Чтобы повысить быстродействие приложений, следует с самого начала писать их в расчете на работу с Unicode-строками. Кроме того, в функциях, преобразующих строки, найдены ошибки, так что отказ от их использования уменьшает число потенциальных сбоев в приложениях.
Разрабатывая DLL, которую будут использовать и другие программисты, предусматривайте в ней по две версии каждой функции — для ANSI и для Unicode. В ANSI-версии просто выделяйте память, преобразуйте строки и вызывайте Unicode-версию той же функции. (Этот процесс я продемонстрирую позже.)
Некоторые функции Windows API (например, WinExec или OpenFile) существуют только для совместимости с 16-разрядными программами, и их надо избегать. Лучше заменить все вызовы WinExec и OpenFile вызовами CreateProcess и CreateFile соответственно. Тем более что старые функции просто обращаются к новым. Самая серьезная проблема с ними в том, что они не принимают строки в Unicode, — при их вызове вы должны передавать строки в ANSI. С другой стороны, в Windows 2000 у всех новых или пока не устаревших функций обязательно есть как ANSI-, так и Unicode-версия.
Некоторые функции Windows API, такие как WinExec и OpenFile, существуют исключительно для преемственной совместимости с 16-разрядными Windowsприложениями, поддерживающими исключительно ANSI-строки. Использовать их в современных программах не следует. Вызовы WinExec и OpenFile следует заменять вызовами CreateProcess и CreateFile, устаревшие функции все равно вызывают новые функции. Основная проблема с устаревшими функциями в том, что они не принимают Unicode-строки и предоставляют меньше возможностей, при вызове им необходимо передавать ANSI-строки. В Windows Vista для большинства функций, не успевших устареть, существуют как Unicode-, так и ANSI-версии. Однако Майкрософт проявляет тенденцию к созданию функций, поддерживаю-
щих только Unicode, примерами могут быть ReadDirectoryChangesW и CreateProcessWithLogonW.
Глава 2. Работа с символами и строками.docx 19
При переносе СОМ из 16-разрядных версий Windows на Win32 руководство Майкрософт решило сделать так, чтобы все методы интерфейсов СОМ, требующие строки, принимали только Unicode-строки. Это было правильное решение, поскольку СОМ обычно применяют для организации «общения» различных компонентов, а Unicode обеспечивает максимум возможностей для передачи строковых данных. Таким образом, использование Unicode в приложении облегчает и взаимодействие с СОМ.
В итоге компилятор ресурсов обрабатывает все ваши ресурсы, записывая их в выходной файл в двоичном формате. Строковые ресурсы (таблицы, шаблоны диалоговых окон, меню и пр.) всегда записываются в файлы ресурсов в виде Unicodeстрок. Если в приложении не определен макрос UNICODE, в Windows Vista соответствующие преобразования выполняет система. Например, если при компиляции модуля не определен UNICODE, в результате вызова LoadString в действительности будет вызвана функция LoadStringA. LoadStringA прочитает Unicodeстроку из ресурса и преобразует ее в ANSI, а LoadString вернет приложению ANSI-представление строки.
Unicode- и ANSI-функции в библиотеке С
Подобно Windows, библиотека языка С поддерживает два набора функций: один для манипулирования ANSI-строками и символами, а другой — для работы с Un- icode-строками и символами. Однако, в отличие от Windows, здесь ANSI-функции выполняют свою работу. Они не преобразуют внутренне полученные строки в Unicode и не вызывают затем Unicode-версии тех же функций. Ну, и, конечно, Un- icode-версии сами делают то, что им положено, а не вызывают ANSI-версии.
Примером С-функции времени выполнения, возвращающей длину ANSI-строк, может служить strlen, а эквивалентной функции для Unicode-строк —wcslen. Прототипы обеих функций объявлены в String.h. В код, который может компилироваться как с ANSI-, так и с Unicode-строками, необходимо импортировать заголовочный файл TChar.h, в котором определен следующий макрос:
#ifdef _UNIC00E |
|
#define _tcslen |
wcslen |
#else |
|
#define _tcslen |
strlen |
#endif |
|
Теперь вызовите в коде _tcslen. Если определен _UNICODE, вызов разрешается в вызов wcslen, в противном случае — в strlen. По умолчанию в но-
вых C++-проектах Visual Studio определен _UNICODE (как и UNICODE).
В библиотеке С времени выполнения все идентификаторы, которые не входят в стандарт С++, предваряются символами подчеркивания (_), тогда как разработчики Windows этого не делают. Таким образом, следует определять
20 Часть I Материалы для обязательного чтения
приложениях либо оба параметра (UNICODE и _UNICODE), либо ни дин из них. Подробнее о заголовочном файле CmnHdr.h, использованном во всех примерах из этой книги, рассказывается в приложении А.
Безопасные строковые функции в библиотеке С
Любая функция, модифицирующая строку, несет потенциальную угрозу безопасности: если результирующая строка больше, чем предназначенный для нее буфер, содержимое памяти будет испорчено. Рассмотрим пример:
//Этот код записывает 4 символа в буфер
//длиной 3 символа, повреждая содержимое памяти
WCHAR szBuffer[3] = L“”;
wcscpy(szBuffer, L“abc”); // Концевой 0 - тоже символ!
Проблема с функциями strcpy и wcscpy (как и с большинством других функций, манипулирующих строками) состоит в том, что у них нет параметра, задающего максимальный размер буфера. Следовательно, такая функция не сможет «узнать», не испортит ли она память. Если же функция не «узнает», повредит ли она содержимое памяти, то не сможет и сообщить об ошибке коду приложения, а вы не узнаете о том, что память испорчена. Конечно же, было бы лучше, если вызов функции просто завершался неудачей, оставляя память в целости и сохранности.
В прошлом эти сбои активно использовались вредоносными программами. Майкрософт заменила в хорошо знакомой и любимой программистами библиотеке С времени выполнения, небезопасные функции для манипулирования строками (такие, как вышеописанная wcscat) новыми функциями. Чтобы писать безопасный код, необходимо отказаться от традиционных С-функций, модифицирующих строки. (Впрочем, к таким функциям, как strlen, wcslen и _tcslen, это не относится: эти функции не пытаются изменить переданную им строку, хоть и предполагают, что эта строка заканчивается 0, что не всегда так.) Вместо них используйте новые безопасные функции для манипулирования строками, определенные Майкрософт в заголовочном файле StrSafe.h.
Примечание. Майкрософт изменила внутреннее устройство своих библиотек классов ATL и MFC, добавив в них поддержку безопасных строковых функции. Поэтому для укрепления защиты программ, использующих эти библиотеки, достаточно просто перекомпилировать их.
Защита кода на С/С++ выходит за рамки этой книги, поэтому приведу лишь ссылки на источники дополнительных сведений по данному вопросу:
■статья Мартина Лоуэлла (Martyn Lovell) в MSDN Magazine «Repel Attacks on Your Code with the Visual Studio 2005 Safe C and C++ Libraries»
(http://msdn.microsoft.com/msdninag/issucs/05/05/SafeCandC/default.aspx);
Глава 2. Работа с символами и строками.docx 21
■презентация Мартина Лоуэлла на Channel9 (видео, см. http://channel9.msdn.com/Showpost.aspx?postid-186406);
■раздел по защите работы со строками в MSDN Online (см. http://msdn2.microsoft.com/en-us/library/ms647466.aspx);
■полный список безопасных С-функций времени выполнения см. в MSDN Online (http://msdn2.microsoft.com/en-us/library/wd3wzwts(VS.80).spx).
Однако некоторые вопросы все же стоит обсудить здесь. Я начну с описания общих особенностей новых функций. Затем я расскажу о «подводных камнях», подстерегающих программистов при переходе к использованию новых, безопасных версий строковых функций, например о применении _tcscpy_s вместо _tcscpy. В завершение я покажу, когда имеет смысл вызывать новые функции StringC*.
Введение в безопасные строковые функции
Вместе с StrSafe.h импортируется String.h, но прежние функции для манипулирования строками из библиотеки С времени выполнения, например из макроса _tcscpy, помечаются как устаревшие и генерируют предупреждения во время компиляции. Учтите, что импортировать StrSafe.h в исходном коде следует в последнюю очередь после импорта других заголовочных файлов. Рекомендую также использовать предупреждения, сгенерированные при компиляции, как ориентир для замены всех устаревших функций их безопасными версиями. В каждом случае следует продумать обработку переполнения буфера, а если восстановление после этой ошибки невозможно, то способ корректного завершения программы.
Для каждой из существующих строковых функций, таких как _tcscpy и _tcscat, предусмотрена новая версия, имя которой включает имя старой функции и суффикс _s (от англ. secure — безопасный). Новые функции имеют ряд общих особенностей, которые нужно пояснить. Проанализируем их прототипы на примере следующего листинга с парой определений обычных строковых функций:
PTSTR _tcscpy (PTSTR strDestination, PCTSTR strSource);
errno_t _tcscpy_s (PTSTR strDestination, size_t numberOfCharacters, PCTSTR strSource);
PTSTR _tcscat (PTSTR strDestination, PCTSTR strSource); errno_t _tcscat_s (PTSTR strDestination, size_t numberOfcharacters,
PCTSTR strSource);
Если функции передается в качестве параметра буфер, доступный для записи, то одновременно необходимо передать и его размер. Размер буфера задают как число знаков, чтобы узнать его, достаточно вызвать макрос _countof, определен-
ный в stdlib.h.
22 Часть I Материалы для обязательного чтения
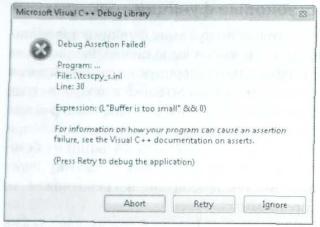
Все безопасные (имеющие в названии суффикс _s) функции первым делом проверяют переданные им аргументы. В частности, проверяются указатели (не равны ли они NULL), целочисленные значения (находятся ли они в допустимом диапазоне), перечислимые (допустимы ли их значения), а также размер буфера (достаточен ли он для хранения результирующих данных). Если хоть одна из проверок окончиться неудачей, функция устанавливает локальную С-переменную времени выполнения потока errno и возвращает значение errno_t, указывающее успешное или неудачное завершение функции. Однако при возникновении ошибки безопасные функции на самом деле не возвращают управление коду приложения, а вызывают окно с неудобоваримым содержимым (рис. 2-1), после чего приложение завершается (это происходит в отладочной сборке, а в случае окончательной сборки приложение завершается сразу).
Puc. 2-1. Окно, отображаемое в случае ошибки при вызове функции
В действительности библиотека С позволяет определять собственные функции, которые будут вызываться при обнаружении недопустимого параметра. В этой функции можно занести ошибку в журнал или выполнить любые другие действия. Чтобы это работало, прежде всего, необходимо определить функцию, соответствующую следующему прототипу:
void InvalidParameterHandler(PCTSTR expression, PCTSTR function, PCTSTR file, unsigned int line, uintptr_t /*pReserved*/);
Параметр expression предоставляет описание ошибки, которое будет использоваться в реализации функции, например (L”Buffer is too small” && 0). Он не слишком понятен неспециалистам, поэтому не следует показывать его конечным пользователям. То же верно для следующих трех параметров, function, file и line, представляющих, соответственно, имя функции, файл с исходным кодом и номер строки, в которой возникла ошибка.
Глава 2. Работа с символами и строками.docx 23
Примечание. Если не определен параметр DEBUG, у всех этих аргументов будет значение NULL. Таким образом, использовать данный разработчик для регистрации ошибок можно лишь при тестировании отладочных версий. В окончательной сборке вывод окна, показанного на рис. 2-1, можно заменить более понятным пользователю сообщением, например о том, что работа приложения прервана из-за неожиданной ошибки, возможно, после имеет смысл занести ошибку в журнал и перезапустить приложение. Если данные состояния приложения в памяти были испорчены, его исполнение следует прервать. Впрочем, рекомендуется проверить errno_t, чтобы определить, можно ли исправить эту ошибку.
Далее следует зарегистрировать этот обработчик, вызвав _set_invalid_parameter_handler. Однако это еще не все, поскольку при возникновении ошибки по-прежнему будет появляться системное окно. В начале исполнения приложения следует вызвать CrtSetReportMode(_CRT_ASSERT, 0); чтобы отключить все системные оповещения об ошибках, выводимые библиотекой С во время выполнения.
Теперь при сбое строковых функций, определенных в String.h, можно будет узнать причину ошибки, проверив errno_t. Только значение S_OK свидетельствует об успешном вызове функции. Остальные значения (см. errno.h) говорят о различных ошибках, например EINVAL — о недопустимых аргументах, таких как указатель, содержащие NULL.
Рассмотрим пример с копированием строки в буфер слишком малого размера:
TCHAR szBefore[5] = {
ТЕХТ(„В‟), TEXT(„B‟), ТЕХТ(„В‟), TEXT(„B‟), „\0‟
};
TCHAR szBuffer[10] = {
TEXT('-'), TEXT('-'), TEXT('-'), TEXT('-'), TEXT('-'), TEXT('-'), TEXT('-'), TEXT('-'), TEXT('-'), '\0'
};
TCHAR szAfter[5] = {
TEXT('A*), TEXT('A'), TEXT('A'), TEXT('A'), '\0' };
errno_t result = _tcscpy_8(8zBuffer, _countof(szBuffer), TEXT("0123456789"));
Содержимое переменных перед вызовом _tcscpy_s показано на рис. 2-2.